 ProxylessNAS optimiert direkt die Architektur neuronaler Netze für eine bestimmte Aufgabe und Ausrüstung, wodurch die Produktivität im Vergleich zu früheren Proxy-Ansätzen erheblich gesteigert werden kann. In einem ImageNet-Dataset wird ein neuronales Netzwerk in 200 GPU-Stunden entworfen (200–378-mal schneller als seine Gegenstücke), und das automatisch entworfene CNN-Modell für mobile Geräte erreicht die gleiche Genauigkeit wie MobileNetV2 1.4 und arbeitet 1,8-mal schneller.
ProxylessNAS optimiert direkt die Architektur neuronaler Netze für eine bestimmte Aufgabe und Ausrüstung, wodurch die Produktivität im Vergleich zu früheren Proxy-Ansätzen erheblich gesteigert werden kann. In einem ImageNet-Dataset wird ein neuronales Netzwerk in 200 GPU-Stunden entworfen (200–378-mal schneller als seine Gegenstücke), und das automatisch entworfene CNN-Modell für mobile Geräte erreicht die gleiche Genauigkeit wie MobileNetV2 1.4 und arbeitet 1,8-mal schneller.Forscher am Massachusetts Institute of Technology haben einen effektiven Algorithmus zum automatischen Entwerfen von Hochleistungs-Neuronalen Netzen für bestimmte Hardware entwickelt,
schreibt die Veröffentlichung
MIT News .
Algorithmen für den automatischen Entwurf maschineller Lernsysteme sind ein neues Forschungsfeld auf dem Gebiet der KI. Diese Technik wird als neuronale Architektursuche (NAS) bezeichnet und als schwierige Rechenaufgabe angesehen.
Automatisch entworfene neuronale Netze haben ein genaueres und effizienteres Design als die von Menschen entwickelten. Die Suche nach neuronaler Architektur erfordert jedoch sehr umfangreiche Berechnungen. Beispielsweise benötigt der moderne NASNet-F-Algorithmus, der kürzlich von Google für die Ausführung auf GPUs entwickelt wurde, 48.000 Stunden GPU-Computing, um ein neuronales Faltungsnetzwerk zu erstellen, mit dem Bilder klassifiziert und erkannt werden. Natürlich kann Google Hunderte von GPUs und anderer spezialisierter Hardware parallel ausführen. Bei tausend GPUs dauert diese Berechnung beispielsweise nur zwei Tage. Aber nicht alle Forscher haben solche Möglichkeiten, und wenn Sie den Algorithmus in der Google Computing Cloud ausführen, kann er zu einem hübschen Cent werden.
MIT-Forscher haben einen Artikel für die Internationale Konferenz über lernende Repräsentationen,
ICLR 2019 , vorbereitet, die vom 6. bis 9. Mai 2019 stattfinden wird. Der Artikel
ProxylessNAS: Direkte Suche nach neuronaler Architektur auf Zielaufgabe
und Hardware beschreibt den ProxylessNAS-Algorithmus, mit dem spezielle spezialisierte Faltungsnetzwerke für bestimmte Hardwareplattformen direkt entwickelt werden können.
Bei Ausführung mit einem großen Satz von Bilddaten entwarf der Algorithmus die optimale Architektur in nur 200 Stunden GPU-Betrieb. Dies ist zwei Größenordnungen schneller als die Entwicklung der CNN-Architektur unter Verwendung anderer Algorithmen (siehe Tabelle).
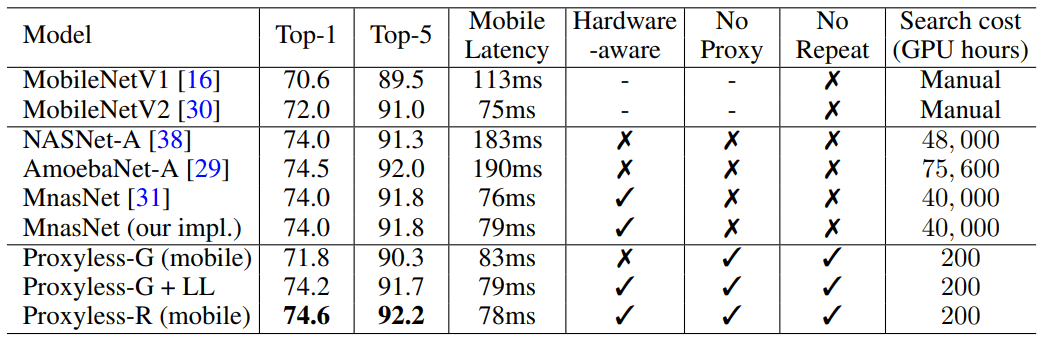
Forscher und Unternehmen mit begrenzten Ressourcen werden von dem Algorithmus profitieren. Ein allgemeineres Ziel ist die „Demokratisierung der KI“, sagt der Songwriter Song Han, Assistenzprofessor für Elektrotechnik und Informatik an den Microsystems Technology Laboratories des MIT.
Khan fügte hinzu, dass solche NAS-Algorithmen niemals die intellektuelle Arbeit von Ingenieuren ersetzen werden: "Das Ziel ist es, die sich wiederholende und mühsame Arbeit, die mit dem Entwerfen und Verbessern der Architektur neuronaler Netze verbunden ist, zu entlasten."
In ihrer Arbeit fanden die Forscher Möglichkeiten, unnötige Komponenten eines neuronalen Netzwerks zu entfernen, die Rechenzeit zu verkürzen und nur einen Teil des Hardwarespeichers zum Ausführen des NAS-Algorithmus zu verwenden. Dies stellt sicher, dass das entwickelte CNN auf bestimmten Hardwareplattformen effizienter arbeitet: CPU, GPU und mobile Geräte.
Die CNN-Architektur besteht aus Schichten mit einstellbaren Parametern, die als "Filter" bezeichnet werden, und möglichen Beziehungen zwischen ihnen. Filter verarbeiten Bildpixel in quadratischen Gittern (z. B. 3 × 3, 5 × 5 oder 7 × 7), wobei jeder Filter ein Quadrat abdeckt. Tatsächlich bewegen sich die Filter um das Bild und kombinieren die Farben des Pixelrasters zu einem Pixel. In verschiedenen Schichten haben Filter unterschiedliche Größen, die auf unterschiedliche Weise miteinander verbunden sind, um Daten auszutauschen. Die CNN-Ausgabe erzeugt ein komprimiertes Bild, das aus allen Filtern kombiniert wird. Da die Anzahl möglicher Architekturen - der sogenannte "Suchraum" - sehr groß ist, erfordert die Verwendung von NAS zum Erstellen eines neuronalen Netzwerks auf massiven Bilddatensätzen enorme Ressourcen. In der Regel führen Entwickler NAS auf kleineren Datensätzen (Proxys) aus und übertragen die resultierenden CNN-Architekturen auf das Ziel. Diese Methode verringert jedoch die Genauigkeit des Modells. Darüber hinaus gilt für alle Hardwareplattformen dieselbe Architektur, was zu Leistungsproblemen führt.
MIT-Forscher trainierten und testeten den neuen Algorithmus für die Aufgabe, Bilder direkt im ImageNet-Datensatz zu klassifizieren, der Millionen von Bildern in tausend Klassen enthält. Zunächst erstellten sie einen Suchraum, der alle möglichen „Pfade“ für CNN-Kandidaten enthält, damit der Algorithmus die optimale Architektur unter ihnen findet. Um den Suchraum in den Speicher der GPU einzupassen, verwendeten sie eine Methode namens Binärisierung auf Pfadebene, bei der jeweils nur ein Pfad und Speicher um eine Größenordnung gespeichert werden. Die Binarisierung wird mit dem Bereinigen auf Pfadebene kombiniert, einer Methode, mit der traditionell untersucht wird, welche Neuronen in einem neuronalen Netzwerk sicher entfernt werden können, ohne das System zu beschädigen. Nur anstatt Neuronen zu entfernen, entfernt der NAS-Algorithmus ganze Pfade und verändert die Architektur vollständig.
Am Ende schneidet der Algorithmus alle unwahrscheinlichen Pfade ab und speichert nur den Pfad mit der höchsten Wahrscheinlichkeit - dies ist die ultimative CNN-Architektur.
Die Abbildung zeigt Beispiele für neuronale Netze zur Klassifizierung von Bildern, die ProxylessNAS für GPUs, CPUs und mobile Prozessoren entwickelt hat (jeweils von oben nach unten).
