
Die Verbesserung der CPU-Geschwindigkeit verlangsamt sich, und wir sehen, dass die Halbleiterindustrie auf Beschleunigerkarten umstellt, sodass sich die Ergebnisse weiterhin deutlich verbessern. Nvidia hat am meisten von diesem Übergang profitiert, ist jedoch Teil desselben Trends und treibt die Forschung zu Beschleunigern für neuronale Netze, FPGAs und Produkten wie den TPUs von Google voran. Diese Beschleuniger haben die Geschwindigkeit der Elektronik in den letzten Jahren unglaublich erhöht, und viele begannen zu hoffen, dass sie im Zusammenhang mit der Verlangsamung von Moores Gesetz einen neuen Entwicklungspfad darstellen. Eine neue wissenschaftliche Arbeit legt jedoch nahe, dass tatsächlich nicht alles so rosig ist, wie manche es gerne hätten.
Spezielle Architekturen wie GPUs, TPUs, FPGAs und ASICs verwenden immer noch dieselben Funktionsknoten wie x86-, ARM- oder POWER-Prozessoren, auch wenn sie ganz anders funktionieren als Allzweck-CPUs. Dies bedeutet, dass die Geschwindigkeitssteigerung dieser Beschleuniger auch in gewissem Maße von den Verbesserungen abhängt, die mit der Skalierung von Transistoren verbunden sind. Welcher Anteil dieser Verbesserungen hing jedoch von der Verbesserung der Produktionstechnologien und der mit dem Mooreschen Gesetz verbundenen Zunahme der Dichte ab, und welcher Teil von den Verbesserungen in den Zielbereichen, für die diese Prozessoren bestimmt sind? Wie viel Prozent der Verbesserungen beziehen sich nur auf Transistoren?
David Wenzlaf, Associate Professor für Elektrotechnik an der Princeton University, und sein Doktorand Adi Fuchs haben ein Modell erstellt, mit dem sie die Geschwindigkeit der Verbesserung messen können. Ihr Modell verwendet die Eigenschaften von 1612 CPUs und 1001 GPUs mit unterschiedlichen Kapazitäten, die auf der Grundlage verschiedener Funktionseinheiten hergestellt wurden, um die mit Verbesserungen der Einheiten verbundenen Vorteile numerisch zu bewerten. Wenzlaf und Fuchs haben eine
Metrik zur Verbesserung der Leistung im Zusammenhang mit dem CMOS-Fortschritt (CMOS-Driven Return, CDR) erstellt, die mit Verbesserungen verglichen werden kann, die durch die Chip Specialization Return (CSR) erzielt wurden.
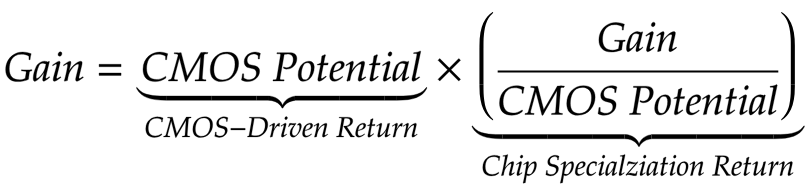
Das Team kam zu einem entmutigenden Ergebnis. Die Vorteile, die sich aus der Spezialisierung von Chips ergeben, hängen im Wesentlichen mit der Anzahl der Transistoren zusammen, die langfristig in einem Millimeter Silizium angeordnet sind, sowie mit den Verbesserungen dieser Transistoren, die mit jeder neuen Funktionseinheit verbunden sind. Schlimmer noch, es gibt grundlegende Einschränkungen hinsichtlich der Geschwindigkeit, die wir aus der Verbesserung der Beschleunigerschaltung ohne Verbesserung der CMOS-Skala ziehen können.
Es ist wichtig, dass alle oben genannten Punkte auf lange Sicht zutreffen. Eine Studie von Wenzlaf und Fuchs zeigt, dass die Geschwindigkeit bei der ersten Inbetriebnahme von Beschleunigern häufig dramatisch ansteigt. Im Laufe der Zeit, wenn sich herausstellt, dass optimale Beschleunigungsmethoden untersucht und bewährte Verfahren beschrieben werden, kommen die Forscher zum optimalen Ansatz. Darüber hinaus sind bei Beschleunigern genau definierte Aufgaben aus einem gut untersuchten Bereich, der parallelisiert werden kann (GPU), gut gelöst. Dies bedeutet jedoch auch, dass die gleichen Eigenschaften, aufgrund derer die Aufgabe für Beschleuniger angepasst werden kann, den Vorteil dieser Beschleunigung auf lange Sicht begrenzen. Das Team nannte dieses Problem "Deadlock-Beschleuniger".
Und der Markt für Hochleistungscomputer hat dies wahrscheinlich schon seit einiger Zeit gespürt. 2013 haben wir über den
schwierigen Weg zu Ex-Scale-Supercomputern geschrieben. Und selbst dann sagte Top500 voraus, dass Beschleuniger einen einmaligen Sprung in der Leistungsbewertung bewirken würden, aber die Geschwindigkeit der Geschwindigkeitssteigerung nicht erhöhen würden.

Die Konsequenzen dieser Entdeckungen gehen jedoch über den Markt für Hochleistungscomputer hinaus. Zum Beispiel stellten Wenzlaf und Fuchs nach dem Studium der GPU fest, dass die Vorteile, die nicht auf ein verbessertes CMOS zurückzuführen waren, sehr gering waren.
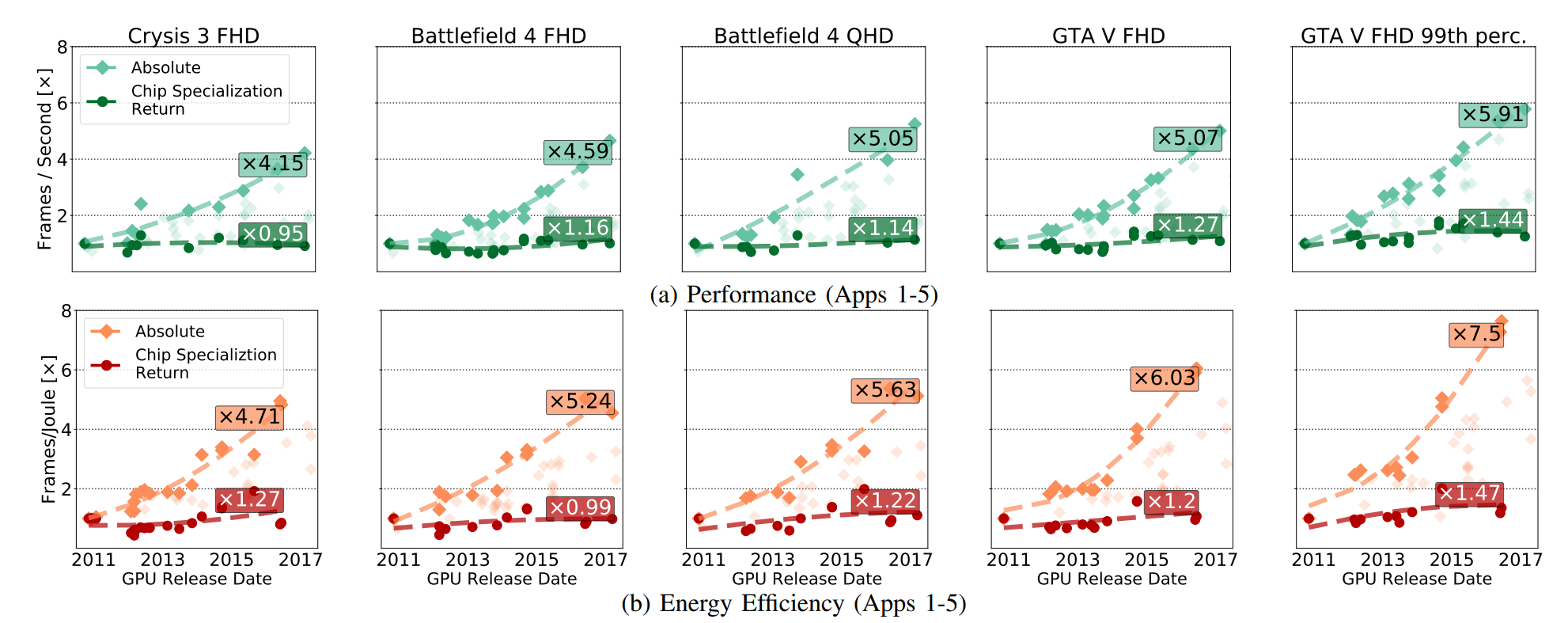
In Abb. Es wurde ein absolutes Leistungswachstum der GPU gezeigt (einschließlich der Vorteile, die sich aus der Entwicklung von CMOS ergeben), und diese Vorteile sind ausschließlich aus der Entwicklung von CSR hervorgegangen. Bei CSRs geht es um die Verbesserungen, die bestehen bleiben, wenn Sie alle Durchbrüche in der CMOS-Technologie aus der GPU-Schaltung entfernen.
Die folgende Abbildung verdeutlicht das Mengenverhältnis:
Eine Verringerung der CSR bedeutet nicht, dass die GPU in absoluten Zahlen verlangsamt wird. Wie Fuchs schrieb:
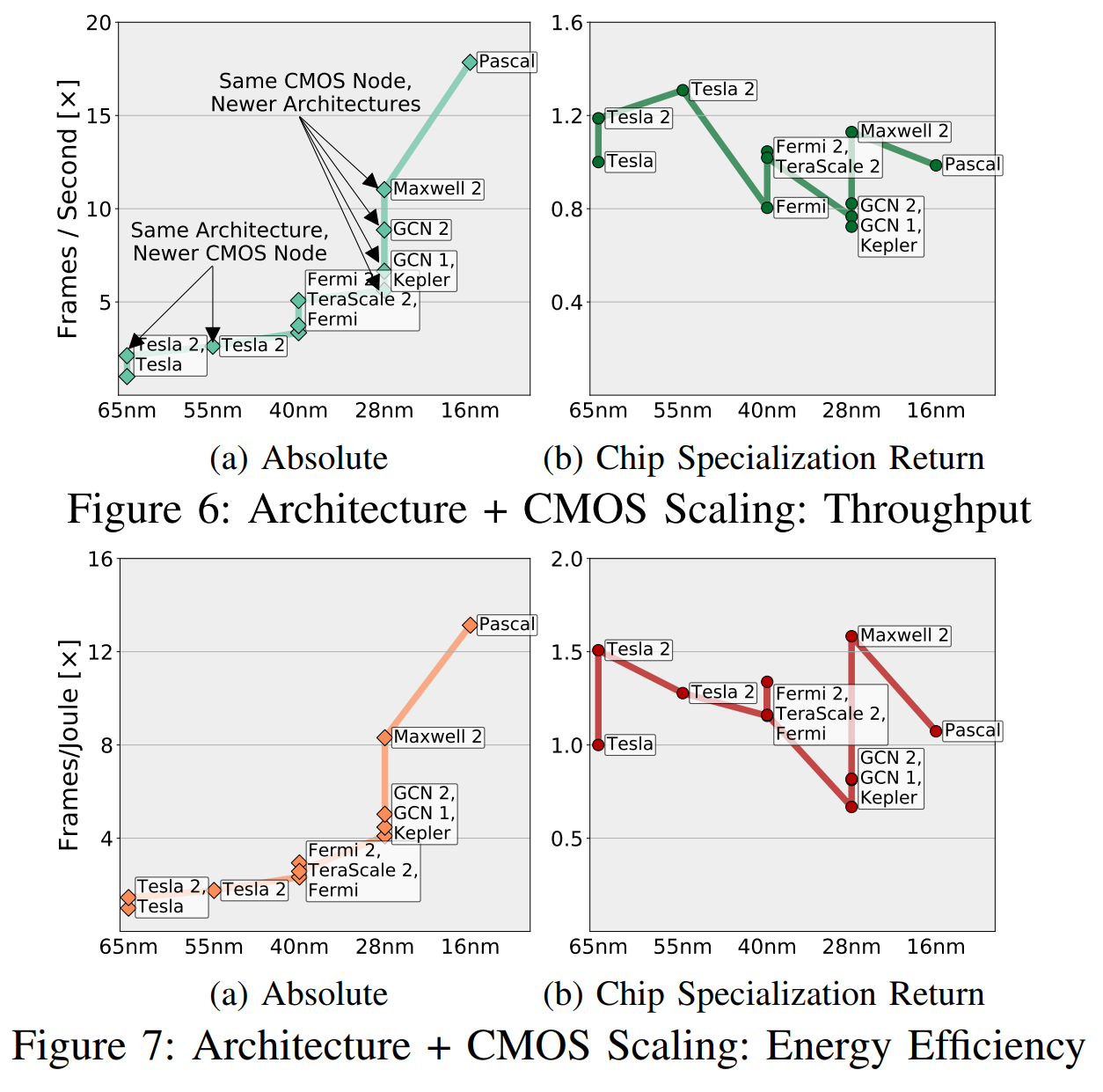
CSR normalisiert den Gewinn "basierend auf dem Potenzial von CMOS", und dieses "Potenzial" berücksichtigt die Anzahl der Transistoren und den Unterschied in Geschwindigkeit, Effizienz bei der Nutzung von Energie, Fläche usw. (in verschiedenen Generationen von CMOS). In Abb. In 6 haben wir einen ungefähren Vergleich der Kombinationen „Architektur + CMOS-Knoten“ gegeben, indem wir die gemessenen Geschwindigkeiten aller Anwendungen auf verschiedene Kombinationen trianguliert und transitive Beziehungen zwischen den Kombinationen angewendet haben, die nicht genügend gemeinsame Anwendungen haben (weniger als fünf).
Intuitiv können diese Graphen wie in Fig. 1 verstanden werden. 6a zeigt, was „Ingenieure und Manager sehen“, und Abb. 6b ist "was wir sehen, ohne das Potenzial von CMOS." Ich möchte vorschlagen, dass Sie sich mehr Gedanken darüber machen, ob Ihr neuer Chip dem vorherigen voraus ist, als ob dies aufgrund besserer Transistoren oder aufgrund einer besseren Spezialisierung der Fall ist.
Der GPU-Markt ist gut definiert, konzipiert und spezialisiert, und sowohl AMD als auch Nvidia haben allen Grund, sich gegenseitig zu übertreffen und die Schaltkreise zu verbessern. Trotzdem sehen wir, dass Beschleunigungen größtenteils auf CMOS-bezogene Faktoren und nicht auf CSR zurückzuführen sind.
Die von Wissenschaftlern untersuchten FPGAs und Spezialkarten für die Verarbeitung von Videocodecs fallen ebenfalls unter solche Eigenschaften, selbst wenn die relative Verbesserung im Laufe der Zeit mehr oder weniger auf den wachsenden Markt zurückzuführen ist. Dieselben Eigenschaften, mit denen Sie aktiv auf Beschleunigungen reagieren können, schränken letztendlich die Fähigkeit von Beschleunigern ein, ihre Effizienz zu verbessern. Fuchs und Wenzlaf schreiben über GPUs: „Obwohl sich die Bildrate von GPU-Grafiken um das 16-fache erhöht hat, gehen wir davon aus, dass weitere Verbesserungen der Geschwindigkeit und Energieeffizienz das 1,4- bis 2,4-fache bzw. das 1,4- bis 1,7-fache erreichen werden.“ . AMD und Nvidia haben keinen speziellen Handlungsspielraum, in dem Sie die Geschwindigkeit durch Verbesserung des CMOS erhöhen können.
Die Implikationen dieser Arbeit sind wichtig. Sie sagt, dass bestimmte Architekturbereiche keine signifikanten Geschwindigkeitsverbesserungen mehr bewirken werden, wenn Moores Gesetz nicht mehr funktioniert. Und selbst wenn sich Chipdesigner auf die Verbesserung der Leistung bei einer festen Anzahl von Transistoren konzentrieren können, werden diese Verbesserungen durch die Tatsache begrenzt, dass gut untersuchte Prozesse kaum verbessert werden können.
Die Arbeit zeigt die Notwendigkeit, einen grundlegend neuen Ansatz für das Rechnen zu entwickeln. Eine mögliche Alternative ist die
Intel Meso-Architektur . Fuchs und Wenzlaf
schlugen auch
vor , alternative Materialien und andere Lösungen zu verwenden, die über den Rahmen von CMOS hinausgehen, einschließlich der Untersuchung der Möglichkeit, nichtflüchtigen Speicher als Beschleuniger zu verwenden.