Interaktive Systeme verwenden viele verschiedene Verzeichnisse, Datenwörterbücher. Dies sind verschiedene Status, Codes, Namen usw. In der Regel gibt es viele davon und jedes ist nicht groß. In der Struktur haben sie häufig gemeinsame Attribute: Code, ID, Name usw. Im Anwendungscode gibt es viele verschiedene Suchvorgänge, Vergleiche nach Code und Referenz-ID. Die Suche kann beispielsweise erweitert werden: Suche nach ID, Code, Abrufen einer Liste nach Kriterium, Sortierung usw. Infolgedessen werden Verzeichnisse zwischengespeichert, wodurch der häufige Zugriff auf die Datenbank verringert wird. Hier möchte ich ein Beispiel zeigen, wie Spring Data Key-Value-Repositorys für diese Zwecke nützlich sein können. Die Hauptidee ist folgende: Eine erweiterte Suche in der Schlüsselwert-Repositorie und, falls kein Objekt vorhanden ist, eine Suche in den Spring-Daten-Repositorys in der Datenbank und deren Platzierung in den Schlüsselwert-Repositorys.
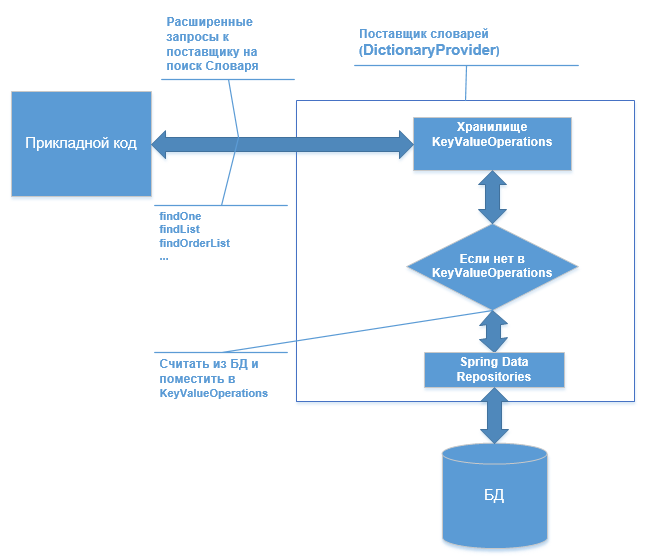
Und so gibt es im Frühjahr KeyValueOperations, das dem Spring Data-Repository ähnelt, jedoch nach dem Konzept des Schlüsselwerts arbeitet und die Daten in einer HashMap-Struktur platziert (ich habe hier
über Spring Data-Repositorys geschrieben ). Die Objekte können von jedem Typ sein. Hauptsache, der Schlüssel wird angegeben.
public class Status { @org.springframework.data.annotation.Id private long statusId; private String code; private String name; ....
Hier lautet der Schlüssel statusId, und der vollständige Pfad der Anmerkung wird speziell angegeben. In Zukunft werde ich JPA Entity verwenden, und dort gibt es auch eine ID, die sich jedoch bereits auf die Datenbank bezieht.
KeyValueOperations verfügt über ähnliche Methoden wie in Spring Data-Repositorys
interface KeyValueOperations { <T> T insert(T objectToInsert); void update(Object objectToUpdate); void delete(Class<?> type); <T> T findById(Object id, Class<T> type); <T> Iterable<T> find(KeyValueQuery<?> query, Class<T> type); .... .
Sie können also die Java KeyValueOperations-Konfiguration für Spring Bean angeben
@SpringBootApplication public class DemoSpringDataApplication { @Bean public KeyValueOperations keyValueTemplate() { return new KeyValueTemplate(keyValueAdapter()); } @Bean public KeyValueAdapter keyValueAdapter() { return new MapKeyValueAdapter(ConcurrentHashMap.class); }
Die Wörterbuchspeicherklasse ist hier aufgelistet - ConcurrentHashMap
Und da ich mit JPA Entity-Wörterbüchern arbeiten werde, werde ich zwei davon mit diesem Projekt verbinden.
Dies ist ein Wörterbuch mit "Status" und "Karte"
@Entity public class Status { @org.springframework.data.annotation.Id private long statusId; private String code; private String name; @Id @Column(name = "STATUS_ID") public long getStatusId() { return statusId; } .... @Entity public class Card { @org.springframework.data.annotation.Id private long cardId; private String code; private String name; @Id @Column(name = "CARD_ID") public long getCardId() { return cardId; } ...
Dies sind Standardentitäten, die Tabellen in der Datenbank entsprechen. Ich mache auf zwei ID-Annotationen für jede Entität aufmerksam, eine für JPA und eine für KeyValueOperations
Die Struktur der Wörterbücher ist ähnlich, ein Beispiel für eines von ihnen
create table STATUS ( status_id NUMBER not null, code VARCHAR2(20) not null, name VARCHAR2(50) not null );
Spring Data Repositories für sie:
@Repository public interface CardCrudRepository extends CrudRepository<Card, Long> { } @Repository public interface StatusCrudRepository extends CrudRepository<Status, Long> { }
Und hier ist das DictionaryProvider-Beispiel selbst, in dem wir Spring Data-Repositorys und KeyValueOperations verbinden
@Service public class DictionaryProvider { private static Logger logger = LoggerFactory.getLogger(DictionaryProvider.class); private Map<Class, CrudRepository> repositoryMap = new HashMap<>(); @Autowired private KeyValueOperations keyValueTemplate; @Autowired private StatusCrudRepository statusRepository; @Autowired private CardCrudRepository cardRepository; @PostConstruct public void post() { repositoryMap.put(Status.class, statusRepository); repositoryMap.put(Card.class, cardRepository); } public <T> Optional<T> dictionaryById(Class<T> clazz, long id) { Optional<T> optDictionary = keyValueTemplate.findById(id, clazz); if (optDictionary.isPresent()) { logger.info("Dictionary {} found in keyValueTemplate", optDictionary.get()); return optDictionary; } CrudRepository crudRepository = repositoryMap.get(clazz); optDictionary = crudRepository.findById(id); keyValueTemplate.insert(optDictionary.get()); logger.info("Dictionary {} insert in keyValueTemplate", optDictionary.get()); return optDictionary; } ....
Auto-Injects werden darin für Repositorys und für KeyValueOperations installiert, und dann suchen wir im KeyValueTemplate-Wörterbuch nach einer einfachen Logik (hier ohne Überprüfung auf Null usw.), wenn dies der Fall ist, kehren wir zurück, andernfalls extrahieren wir aus der Datenbank über crudRepository und platzieren sie in keyValueTemplate und geben raus.
Aber wenn all dies nur auf eine Schlüsselsuche beschränkt wäre, dann gibt es wahrscheinlich nichts Besonderes. Daher verfügt KeyValueOperations über eine breite Palette von CRUD-Operationen und -Anforderungen. Hier ist ein Beispiel für eine Suche in derselben keyValueTemplate, jedoch bereits nach Code mithilfe der KeyValueQuery-Abfrage.
public <T> Optional<T> dictionaryByCode(Class<T> clazz, String code) { KeyValueQuery<String> query = new KeyValueQuery<>(String.format("code == '%s'", code)); Iterable<T> iterable = keyValueTemplate.find(query, clazz); Iterator<T> iterator = iterable.iterator(); if (iterator.hasNext()) { return Optional.of(iterator.next()); } return Optional.empty(); }
Und es ist verständlich, dass, wenn ich früher nach ID gesucht habe und das Objekt in keyValueTemplate gelangt ist und die Suche nach dem Code desselben Objekts es von keyValueTemplate zurückgibt, kein Zugriff auf die Datenbank besteht. Spring Expression Language wird verwendet, um die Anforderung zu beschreiben.
Testbeispiele:
ID-Suche
private void find() { Optional<Status> status = dictionaryProvider.dictionaryById(Status.class, 1L); Assert.assertTrue(status.isPresent()); Optional<Card> card = dictionaryProvider.dictionaryById(Card.class, 100L); Assert.assertTrue(card.isPresent()); }
Suche nach Code
private void findByCode() { Optional<Card> card = dictionaryProvider.dictionaryByCode(Card.class, "VISA"); Assert.assertTrue(card.isPresent()); }
Sie können Listen von Daten durch erhalten
<T> Iterable<T> find(KeyValueQuery<?> query, Class<T> type);
Sie können die Sortierung in der Anforderung angeben
query.setSort(Sort.by(DESC, "name"));
Material:
Federdaten-SchlüsselwertGithub-Projekt