Yandex verfügt über einen Suchkomponenten-Entwicklungsdienst, der eine Suchbasis auf MapReduce aufbaut, Daten für den Satz zum Rendern bereitstellt, Algorithmen und Datenstrukturen generiert und ML-Probleme des Qualitätswachstums löst. Alexey Shlyunkin, der Leiter einer der Gruppen innerhalb dieses Dienstes, erklärt, woraus die Suchlaufzeit besteht und wie wir sie verwalten.
Willst du in ML stöbern - stöbern? Sie möchten nur MapReduce - ok. Willst du Laufzeit - Laufzeit.
- Was ist heute eine Suche? Yandex begann mit einer Suche und entwickelte sie. 20 Jahre sind vergangen. Wir haben eine Suchbasis für Hunderte von Milliarden von Dokumenten.
Wir nennen ein Dokument jede Seite im Internet, aber nicht nur sie. Dennoch - seine Inhalte, verschiedene Statistiken darüber, welche Benutzer gerne darauf zugreifen, wie viele von ihnen. Plus die Daten, die wir berechnet haben.
Es handelt sich auch um Zehntausende von Instanzen, die als Antwort auf jede Anforderung Daten verarbeiten, nach etwas suchen und die Suchantwort bereichern. Einige Instanzen suchen nach Bildern, andere nach normalen Textdokumenten, andere nach Videos usw. Das heißt, Zehntausende von Maschinen werden für jede Anforderung aktiviert. Sie alle versuchen, etwas zu finden und das Ergebnis zu verbessern, das Ihnen gezeigt wird. Dementsprechend bedienen Zehntausende von Maschinen Tausende von Anforderungen pro Sekunde. Diese Zehntausende von Instanzen werden zu Hunderten von Diensten kombiniert, um ein Problem zu lösen.

Es gibt einen Suchkern - einen Websuchdienst. Und es gibt einen Videosuchdienst usw. Dementsprechend gibt es eine Sache, die die Antworten verschiedener Suchanfragen kombiniert und versucht zu wählen, welche und in welcher Reihenfolge es besser ist, den Benutzer zu zeigen. Wenn dies eine Art Anfrage zu Musik ist, ist es wahrscheinlich besser, zuerst Yandex.Music und dann zum Beispiel eine Seite über diese Musikgruppe zu zeigen. Dies wird als Mixer bezeichnet. Es gibt bereits Hunderte solcher Dienste, und sie tun für jede Anfrage etwas und versuchen, den Benutzern irgendwie zu helfen. Und natürlich nutzt dies alles maschinelles Lernen aller Art, von einfachen Statistiken über lineare Modelle bis hin zu Gradientenverstärkungen, neuronalen Netzen und so weiter.
Ich werde jetzt über Infrastruktur und ML sprechen.
Meine Gruppe wird als neue Laufzeitentwicklungsgruppe bezeichnet und ist Teil des Entwicklungsdienstes für Suchkomponenten. Damit Sie eine Idee haben, erzähle ich Ihnen ein wenig, was unser Service tut.

In der Tat an alle. Wenn Sie eine Suche einreichen, haben wir fast alles in die Hand genommen, angefangen beim Aufbau einer Suchbasis. Das heißt, wir haben MapReduce, wir sammeln dort alle Daten über Dokumente, kochen sie, bauen alle Arten von Datenstrukturen auf, damit wir bei der Abfrage effizient etwas berechnen können. Dementsprechend arbeiten wir von unten, wenn das Dokument gerade bei uns ankommt, von der ersten Phase an, wenn diese Dokumente etwas erhalten und bewerten, bis ganz oben, wo das Layout bedingtes JSON empfängt und es mit allen Bildern und schönen Dingen zeichnet. Von unten nach oben entwickeln wir etwas auf dem gesamten Stapel.
Wir schreiben aber nicht nur Code und tun dies dementsprechend auch in der Infrastruktur. Wir trainieren tatsächlich neuronale Netze, CatBoost. Und andere ML-Dinge, die Sie sich vorstellen und verbrennen können, lehren wir auch. Da wir große Lasten und große Datenmengen haben, stöbern wir natürlich in Algorithmen und Datenstrukturen und halten uns niemals davon ab, sie irgendwo einzuführen. Zum Beispiel verwenden wir an mehreren Stellen Segmentbäume. Wir haben unsere eigene Komprimierung von Indizes, die Bor bilden, und berücksichtigen dementsprechend die Dynamik, wie Wörterbücher am besten erstellt werden können.
Im Allgemeinen waren wir mit einem so großen Koloss wie einer Suche mit so einfachen Aufgaben gesättigt. Deshalb lieben wir natürlich etwas Komplexes, Neues, etwas, das uns herausfordert. Und wir haben nicht wie üblich zehn Codezeilen geschrieben. Wir müssen über einige Experimente nachdenken. Im Allgemeinen stehen die Aufgaben, die wir uns stellen, oft am Rande der Fiktion. Manchmal denkst du: Es ist wahrscheinlich nicht möglich. Aber dann haben Sie vielleicht irgendwie experimentiert - Experimente können ein ganzes Jahr dauern -, aber am Ende stellt sich etwas heraus. Dann fangen wir an, etwas vorzustellen, neu zu machen.
Neben Projekten, Fähigkeiten usw. sind wir im Allgemeinen eines der ehrgeizigsten und am schnellsten wachsenden Teams in Yandex. Zum Beispiel kam ich vor zwei Jahren, war die neunte Person in unserem Dienst. Jetzt haben wir einen Service von fast 60 Personen. Dies ist in der Tat bei den Praktikanten der Fall, aber im Allgemeinen sind wir in zwei Jahren genau viermal gewachsen. Dies soll Ihnen eine Vorstellung davon geben, was unser Service tut.
Jetzt möchte ich Ihnen ein wenig über unsere Aufgaben und die Richtung erzählen, in die wir in naher Zukunft immer relevanter werden. Dazu müssen Sie jedoch zunächst kurz beschreiben, wie die grundlegendste Suchebene funktioniert.
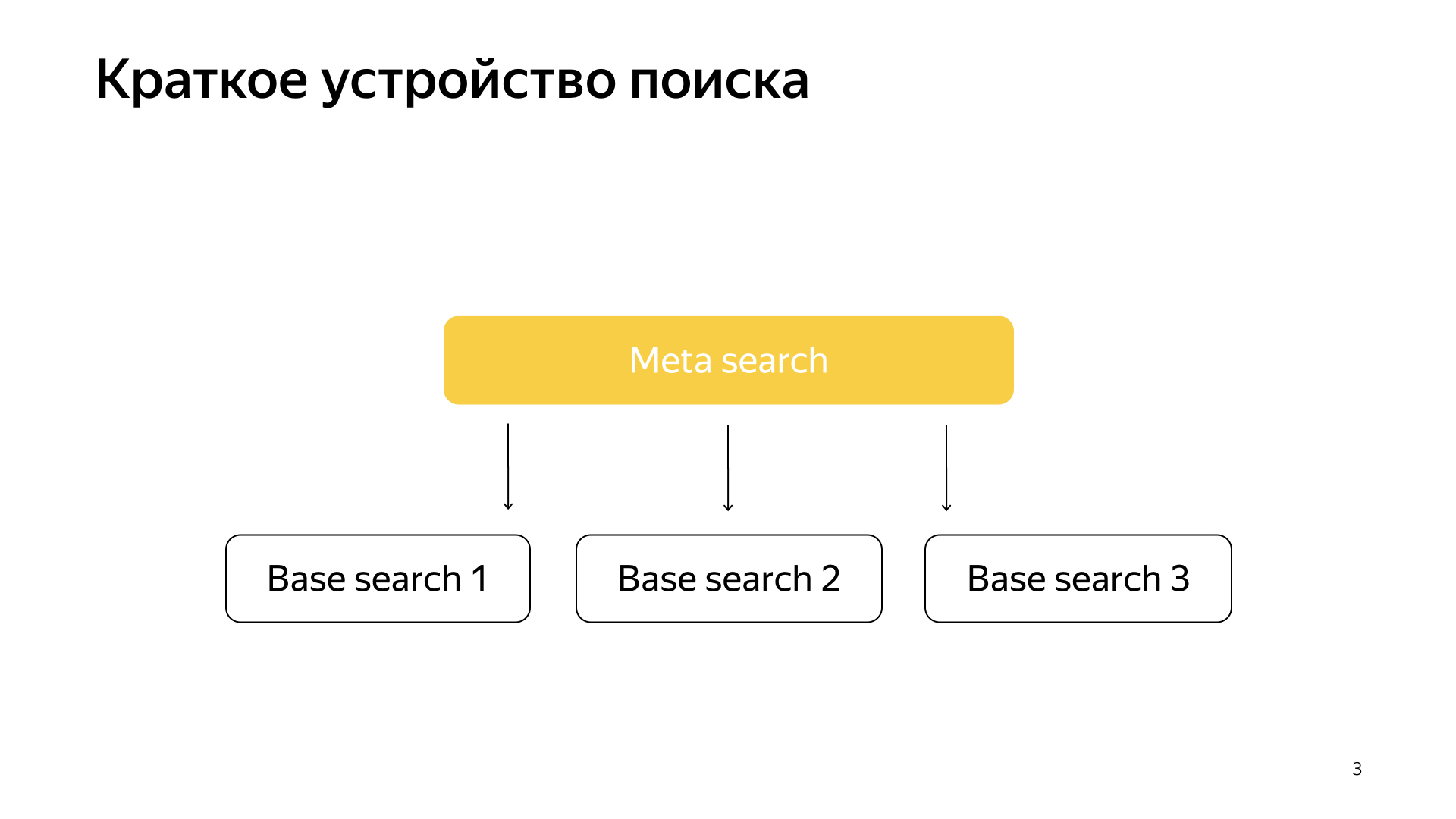
Generell funktioniert alles sehr einfach. Wir haben unsere Suchbasis, wir haben alle Dokumente und wir teilen alle diese Dokumente mehr oder weniger gleichmäßig in N Teile auf. Sie werden Scherben genannt. Und ein Programm namens "Basic Search" wird über den Shard gestartet. Ihre Aufgabe ist es, entsprechend nach diesem Teil des Internets zu suchen. Das heißt, sie weiß, wie man danach sucht und weiß nichts mehr über das andere Internet. Und wir haben so N Scherben. Über ihnen werden grundlegende Suchvorgänge gestartet, und dementsprechend gibt es darüber eine Metasuche. Die Anfrage des Benutzers fällt hinein und geht dementsprechend einfach an alle Shards, und jeder Shard führt eine Suche durch, dann gibt jeder ein Ergebnis zurück, führt eine Art Zusammenführung durch und gibt eine Antwort.
So wurde die Suche für fast alle 20 Jahre organisiert, und im Allgemeinen dachten sie lange Zeit, dass dies so bleiben würde und nichts Besseres getan werden könnte. Aber alles ändert sich, neue Technologien entstehen, und durch maschinelles Lernen können Sie nicht nur die Qualität steigern, sondern auch Infrastrukturprobleme lösen. In letzter Zeit wurden bei unserer Suche sehr viele Projekte an der Schnittstelle von Infrastruktur und maschinellem Lernen gedreht. Wenn zwei solcher Mastodons verschmelzen, werden sehr interessante Ergebnisse erhalten.

Vor kurzem sind neuronale Netze erschienen. Wir haben den Text der Anfrage, da ist der Text des Dokuments. Wir möchten einen Zahlenvektor aus der Anforderung abrufen, um einen Zahlenvektor aus dem Dokument abzurufen, damit das Skalarprodukt den gewünschten Wert vorhersagt. Zum Beispiel möchten wir das Skalarprodukt trainieren, um die Wahrscheinlichkeit vorherzusagen, mit der ein Benutzer auf dieses Dokument klickt. Ziemlich verständlich.
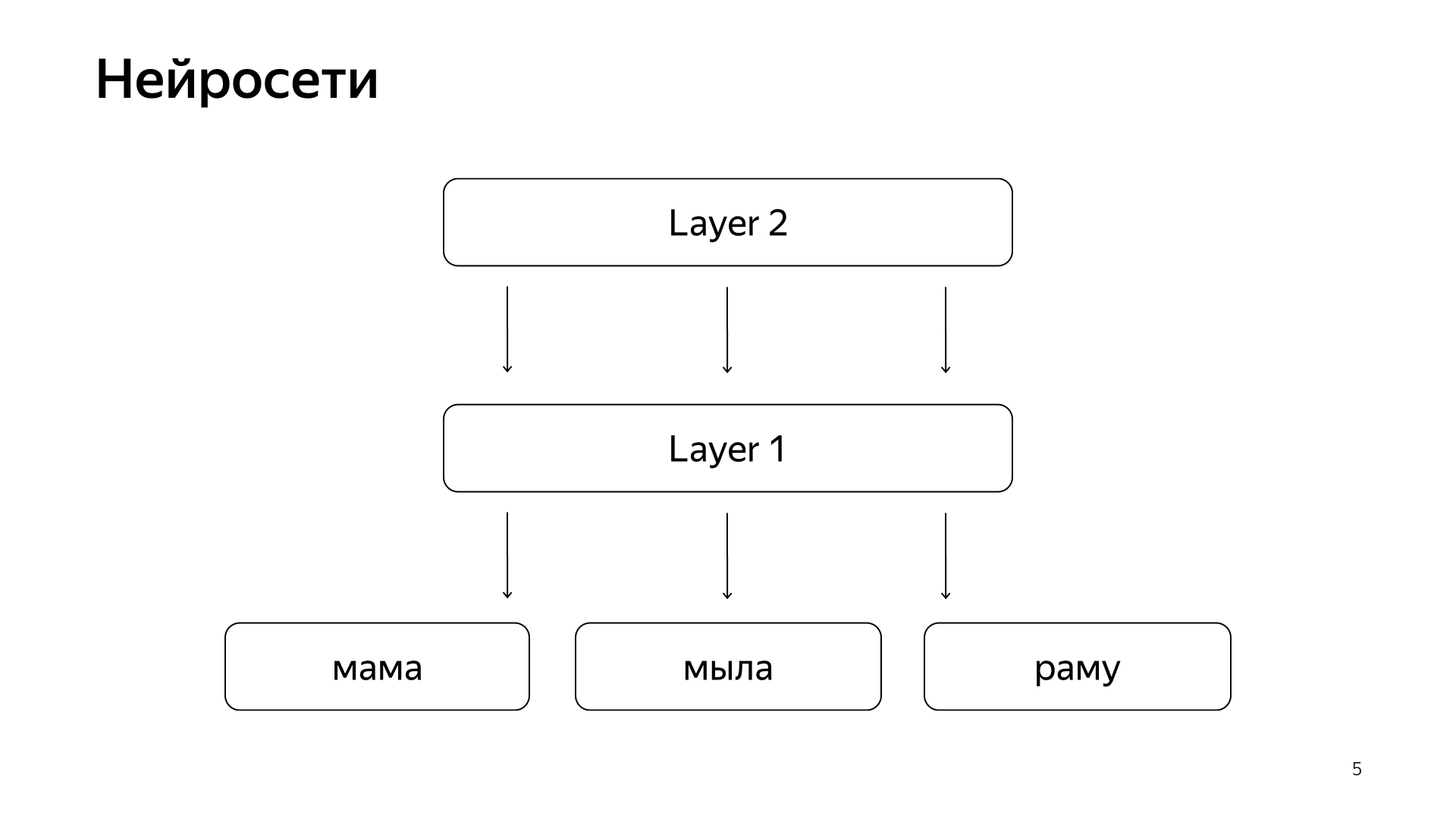
Es ist ungefähr so angeordnet. Wenn sehr, sehr unhöflich, dann haben wir einige Wörter auf der untersten Ebene, und dann gibt es mehrere Ebenen des Netzwerks. Tatsächlich nimmt jede Schicht einen Vektor als Eingabe. Das heißt, die unterste Schicht ist ein so spärlicher Vektor, bei dem jedes Wort eine Anforderung ist. Multipliziert es mit einer Matrix, erhält eine Art Vektor und wendet dementsprechend eine gewisse Nichtlinearität auf jede Komponente an, und dies mehrmals. Und die letzte Ebene, dies wird nur der Vektor genannt, den wir gerade aufgenommen haben, hat solche Ebenen angewendet, und hier ist die letzte Ebene genau der Anforderungsvektor.
Dementsprechend wurden diese neuronalen Netze in den letzten Jahren aktiv in die Suche eingeführt, sie brachten viele Vorteile für die Qualität. Sie haben jedoch das Problem, dass alle Größen, die wir vorhersagen möchten, gut, aber grob genug sind, denn um ein solches neuronales Netzwerk zu trainieren, ist die unterste Schicht sehr groß - alle Wörter stammen aus zig Millionen Wörtern, sodass Sie schreiben können müssen Sie gab mehrere Milliarden Daten ein.
Zum Beispiel können wir einige Benutzerklicks trainieren und so weiter. Das wichtigste Signal, das bei unserer Suche als das wichtigste angesehen wird, ist die manuelle Kennzeichnung durch bestimmte Personen. Sie nehmen die Anfrage entgegen, nehmen das Dokument, lesen es, verstehen, wie gut es ist, und markieren, dh wie sehr dieses Dokument zu dieser Anfrage passt. Lange Zeit konnten wir eine solche Größenordnung von neuronalen Netzen nicht vorhersagen, da wir immer noch Millionen von Schätzungen haben, weil es sehr teuer ist, den gesamten Planeten einzustellen, um ständig alles zu markieren. Deshalb haben wir einen Hack gemacht.
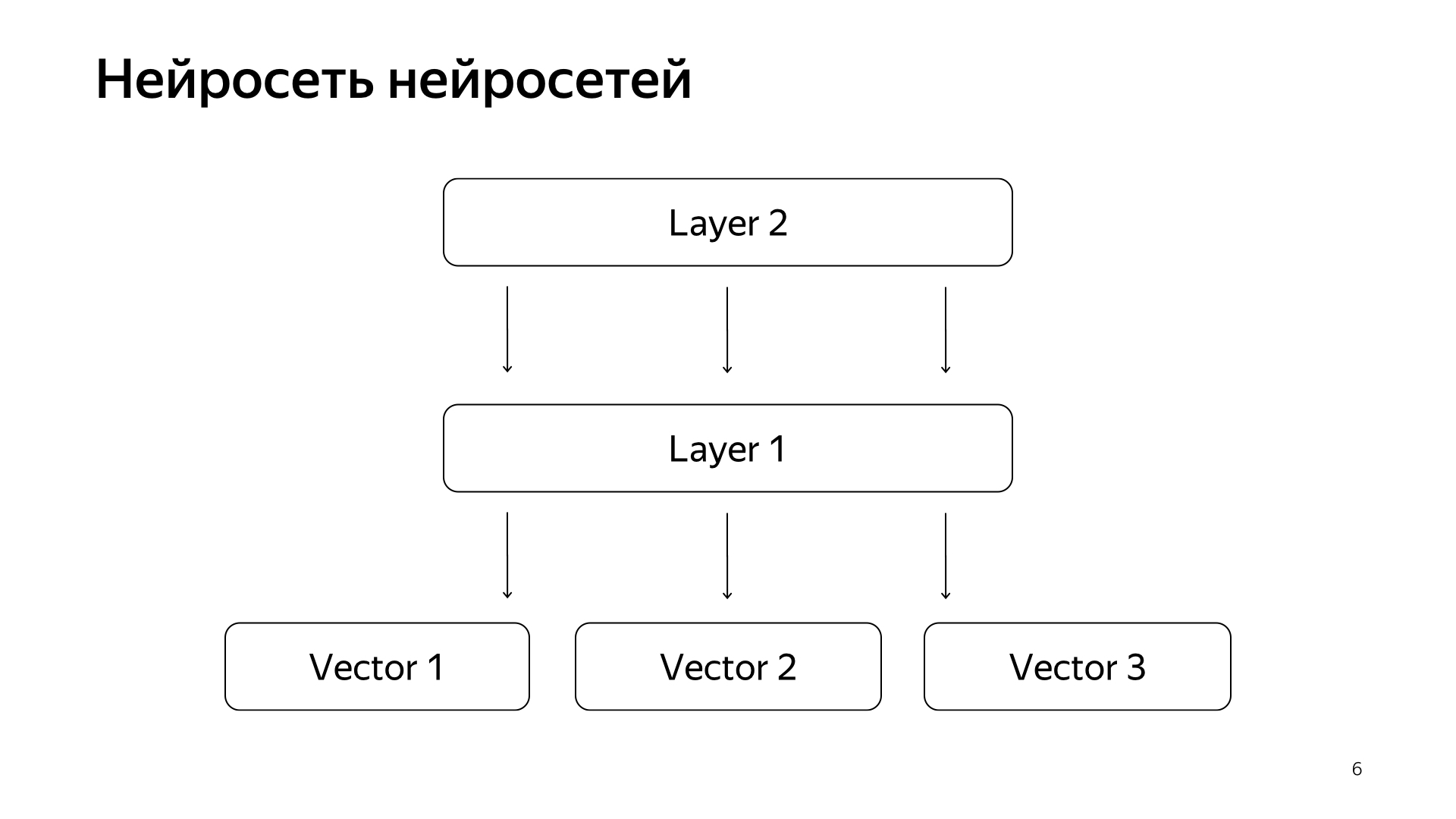
Neuronales Netz neuronaler Netze. In den letzten Jahren haben wir eine Menge neuronaler Netze angesammelt, die gute Signale vorhersagen, aber etwas rauer als die Einschätzung spezieller Personen. Dementsprechend haben wir beschlossen, die vorgefertigten Vektoren dieser Netzwerke an die untere Schicht zu senden, und dann werden wir das neuronale Netzwerk trainieren, um unsere Suchrelevanz für das kleinere Datennetz vorherzusagen.
Das Ergebnis war ein sehr gutes Modell. Sie bringt die Anforderungen von Dokumenten in einen Vektor und ihr skalares Produkt sagt direkt die tatsächliche Relevanz voraus, die wir schon lange vorhersagen wollten.
Außerdem hatten wir eine Idee, wie wir die Suche ein wenig wiederholen können. Das Projekt wird als KNN-Basis bezeichnet (englische k-nächste Nachbarn, k-nächste Nachbarn-Methode).

Die Grundidee ist dies. Wir haben einen Abfragevektor und einen Dokumentvektor. Wir müssen den nächsten finden. Wir haben jedes Dokument durch einen Vektor dargestellt. Lassen Sie uns N Cluster hervorheben, die den gesamten Dokumentraum charakterisieren. Grob gesagt. Stark kleiner als die Anzahl der Dokumente, aber zum Beispiel charakterisieren sie Themen. In einfachen Worten, es gibt eine Gruppe von Katzen, eine Gruppe von Lebensmitteln, eine Gruppe von Programmen und so weiter.
Dementsprechend werden wir Dokumente nicht wie zuvor zufällig in Shards streuen, sondern das Dokument in diesen Shard legen, dh dessen Schwerpunkt dem Dokument am nächsten liegt. Dementsprechend werden wir solche Dokumente nach Themen in Shard gruppiert haben.
Und weiter, nur für eine Anfrage, können wir jetzt nicht zu allen Scherben gehen, sondern nur zu einer kleinen Teilmenge derer, die dieser Anfrage am nächsten sind.
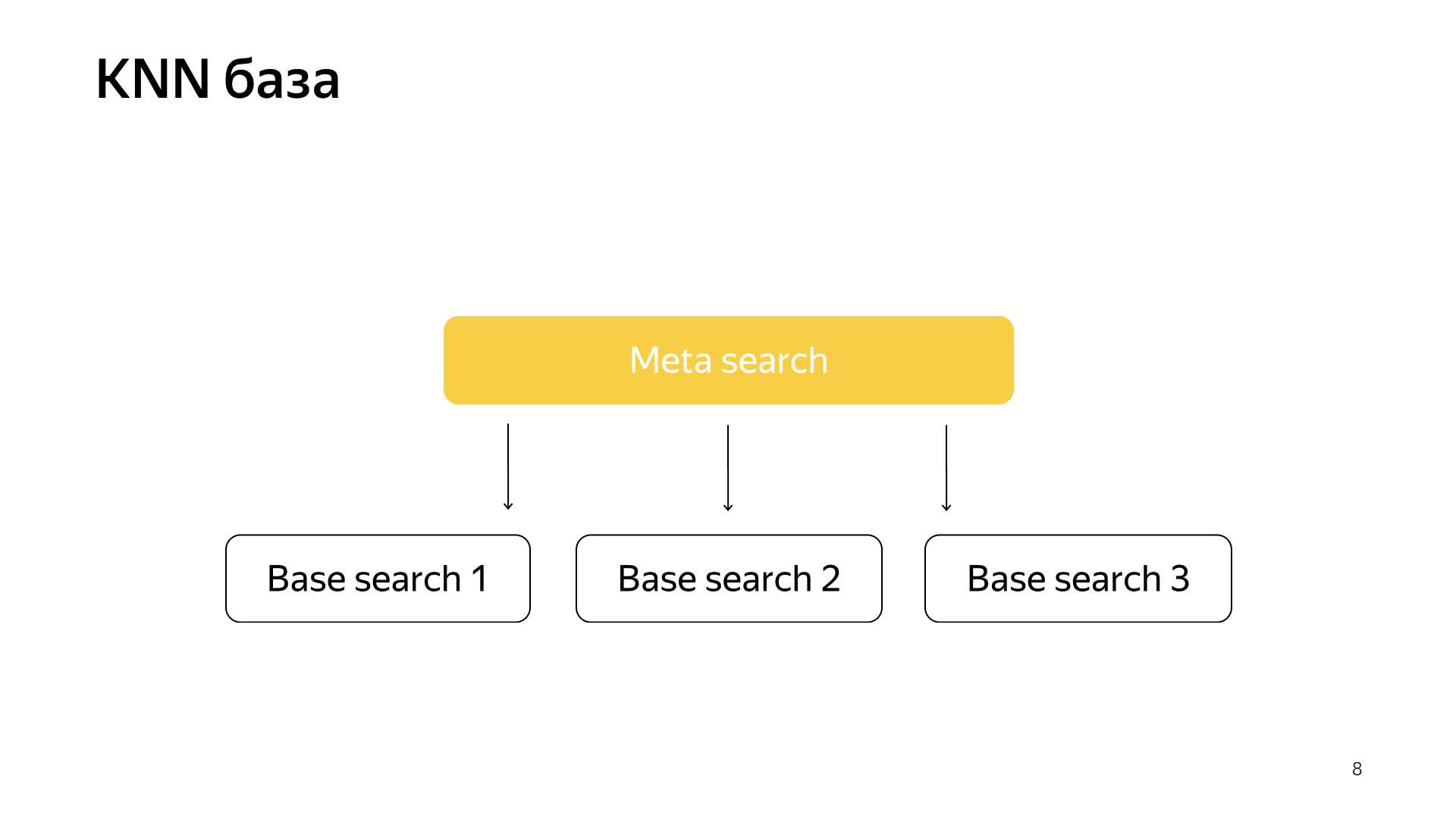
Dementsprechend hatten wir ein solches Schema, Metasuche ist in allen Shards enthalten. Und jetzt muss er zu einer viel kleineren Nummer gehen, und gleichzeitig werden wir immer noch nach den nächsten Dokumenten suchen.
Was bekommen wir eigentlich von diesem Design? Dies reduziert den Verbrauch von Computerressourcen erheblich, einfach weil wir weniger Cluster verwenden. Dies ist, wie ich bereits sagte, einer der Höhepunkte unseres Service. Dies ist die Legierung aus Infrastruktur und maschinellem Lernen, die solche Ergebnisse liefert, an die niemand zuvor denken konnte.

Und am Ende ist es einfach eine ziemlich lustige Sache, denn Sie haben die Modelle hier und dann haben Sie die gesamte Suche überarbeitet, die Petabyte an Daten deaktiviert und die Suche funktioniert für Sie. Sie verbraucht zehnmal weniger Ressourcen. Sie haben eine Milliarde Dollar für das Unternehmen gespart, alle sind glücklich.

Ich habe über eines der Projekte gesprochen, die in unserer Suche erscheinen und die zusammen mit allen Experimenten für ein suspendiertes Jahr umgesetzt und durchgeführt werden. Unsere anderen typischen Aufgaben sind die Verdoppelung der Suchbasis, da das Internet ständig wächst und wir es einholen und auf allen Seiten im Internet suchen möchten. Und dies ist natürlich die Beschleunigung der Basisschicht, in der es die meisten Fälle gibt, das meiste Eisen. Wenn Sie beispielsweise Ihre Basissuche um ein Prozent beschleunigen, sparen Sie etwa eine Million Dollar.
Wir sind auch als Startup-Inkubator an der Suche beteiligt. Ich werde es erklären. Die Suche wird seit 20 Jahren durchgeführt. Es hat schon viele Dinge getan, oft sind wir auf eine Sackgasse gestoßen und dachten, dass nichts mehr getan werden könnte. Dann gab es eine lange Reihe von Experimenten. Wir haben diese Sackgasse wieder durchbrochen. Und in dieser Zeit haben wir viel Fachwissen gesammelt, wie man große und coole Dinge macht. Dementsprechend werden die meisten neuen Anweisungen in Yandex jetzt in der Suche ausgeführt, da die Suchenden bereits wissen, wie dies alles zu tun ist, und es logisch ist, sie zu bitten, zumindest ein neues System zu entwerfen. Und maximal - mach es selbst.
Nun hoffe ich, dass Sie eine kleine Vorstellung von unserer Arbeit haben. Ich werde schnell den thematischen Teil meiner Geschichte über Praktikanten in unserem Dienst erzählen. Wir lieben sie sehr. Wir haben viele davon, letzten Sommer gab es nur in meiner Gruppe 20 Auszubildende, und ich finde das gut. Wenn Sie ein oder drei Praktikanten nehmen, fühlen sie sich ein wenig einsam, manchmal haben sie Angst, ältere Kameraden zu fragen. Und wenn es viele von ihnen gibt, kommunizieren sie als Kameraden im Unglück miteinander. Wenn sie Angst haben, Entwickler etwas zu fragen, werden sie gehen und in die Ecke flüstern. Eine solche Atmosphäre hilft, alles effizient zu machen.
Wir haben eine Million Aufgaben, das Team ist nicht sehr groß, daher sind unsere Praktikanten voll ausgelastet. Wir bitten den Auszubildenden nicht, die ganze Zeit am Protokoll zu sitzen, Tests zu schreiben, den Code zu überarbeiten, sondern geben sofort eine komplizierte Produktionsaufgabe: Beschleunigen Sie die Suche, verbessern Sie die Indexkomprimierung. Natürlich helfen wir. Wir wissen, dass sich das alles auszahlt, deshalb teilen wir gerne unser Fachwissen. Da unser Tätigkeitsfeld sehr umfangreich ist, wird jeder von uns eine Aufgabe für sich finden, die ihm gefällt. Willst du in ML stöbern - stöbern? Sie möchten nur MapReduce - ok. Willst du Laufzeit - Laufzeit. Da ist alles.
Was brauchen Sie, um zu uns zu kommen? Wir machen alles hauptsächlich in C ++ und Python. Es ist nicht notwendig, beide zu kennen. Man kann eines wissen. Wir begrüßen die Kenntnis von Algorithmen. Es bildet einen bestimmten Denkstil und hilft sehr. Dies ist aber auch nicht notwendig: Auch hier sind wir bereit, alles zu lehren, wir sind bereit, unsere Zeit zu investieren, weil wir wissen, dass es sich auszahlt. Die wichtigste Anforderung, die wir stellen, unser Motto, ist, vor nichts und vielen Zahlen Angst zu haben. Haben Sie keine Angst, die Produktion einzustellen, haben Sie keine Angst, etwas Kompliziertes zu tun. Deshalb brauchen wir Menschen, die auch vor nichts Angst haben und bereit sind, Berge zu verwandeln. Vielen Dank.