In diesem Beitrag werden wir über eine Pilot-ML-Studie für den Online-Hypermarkt von Utkonos sprechen, in der wir den Rückkauf verderblicher Waren vorhergesagt haben. Gleichzeitig berücksichtigten wir nicht nur die Daten zu den Lagerbeständen, sondern auch den Produktionskalender mit Wochenenden und Feiertagen und sogar Wetter (Hitze, Schnee, Regen und Hagel sind nichts anderes als Taft Three Weathers, aber nicht für Kunden). Jetzt wissen wir zum Beispiel, dass die „mysteriöse russische Seele“ samstags besonders fleischhungrig ist und weiße Eier über braune schätzt. Aber das Wichtigste zuerst.

Einzelhandelspilot mehr als Pilot
Im Einzelhandel befindet sich maschinelles Lernen in einer doppelten Position. Einerseits haben Einzelhändler über sehr beeindruckende Zeiträume beeindruckende Datenmengen gesammelt: individuelle Kaufbelege, Daten von Kundenkarten ... Andererseits gibt es Einzelhändler so lange, dass das Problem der Nachfrageprognose lange vor dem Auftreten der datenwissenschaftlichen Mode gelöst wurde und heute zur Verfügung steht notwendige BI-Tools.
Es stellt sich heraus, dass der Einzelhandel eines der vielversprechendsten Bereiche für Experimente von Datenwissenschaftlern und die Einführung des maschinellen Lernens ist, aber das Geschäft betrachtet dies alles mit Skepsis: Ist es wirklich gut für mich? Immerhin gibt es bereits funktionierende Lösungen, die sich durch langjährige Erfahrung bewährt haben.
Und dann ist es Zeit, sich auf eine Pilotstudie zu einigen!
Die Piloten selbst haben im Vergleich zu einem vollwertigen ML-Projekt verständliche Einschränkungen und Besonderheiten.
- Für eine Pilotstudie wird genügend Zeit aufgewendet, um den Kunden die Möglichkeiten des maschinellen Lernens anhand ihrer Daten aufzuzeigen, jedoch nicht einmal, um Geld zu verlieren.
- Darüber hinaus haben Datasaintists in der Regel keine zweite Chance mehr: Wenn die ersten Ergebnisse des Geschäfts nicht interessant erscheinen, bleibt es skeptisch und bleibt den alten Prognosemethoden treu. Sie müssen also genau zielen.
- Während des Pilotprojekts darf keine vertrauensvolle Beziehung zwischen dem Kunden und dem Rechenzentrum entstehen. Und die Einheiten und Spezialisten, denen die für die Interpretation wichtigen Daten gehören, sind während des Pilotprojekts höchstwahrscheinlich nicht zugänglich, ebenso wie wirtschaftlich wichtige Erkenntnisse.
Natürlich manifestieren sich diese Merkmale nicht in jedem Pilotprojekt, aber sie bilden einen wichtigen Teil seiner Risiken.
Ein bisschen über die Aufgabe
Lange bevor Utkonos sich mit maschinellem Lernen vertraut machte, verwendete es bereits ein eigenes Analysesystem, das die Rückzahlung von Waren für eine Woche mit sehr hoher Genauigkeit vorhersagte. Der Einzelhändler ist jedoch an der Möglichkeit interessiert, die Effektivität der Planung zu erhöhen. Dies betraf vor allem verderbliche Produkte, von denen viele auch sehr teuer sind. Traditionelle Gabel: Wenn Sie viel kaufen - es kommt zu Verlusten, wenn Sie nicht genug kaufen - geht der Käufer zum Konkurrenten, um sein geliebtes Kälberfilet zu kaufen, das bei Vollmond und leichtem Nieselregen geerntet wurde. Für eine ausreichend genaue Prognose für übermorgen sind auf maschinellem Lernen basierende Lösungen besser geeignet, sodass mehr Faktoren berücksichtigt werden können als bei klassischen BI-Tools. Utkonos erklärte sich bereit, als unser Partner für ein Experiment zu fungieren, das darauf abzielt, die Hypothesen der Anwendbarkeit von maschinellem Lernen auf E-Commerce zu testen.
Um die Möglichkeiten des maschinellen Lernens zur Lösung dieses Problems aufzuzeigen, wurden in Übereinstimmung mit dem Unternehmen mehrere Handelsnamen ausgewählt:
- zwei Produkte aus der Kategorie „Gekühltes Fleisch“ - als verderbliche Produkte, deren Daten für eine sofortige Aktualisierung am wichtigsten sind;
- und zwei Produkte aus der Kategorie „Hühnerei“ - als Produkte mit einer bestimmten saisonalen Nachfrage, die nicht einfach als „am Donnerstag kauft jeder X und am Freitag - X multipliziert mit einem Faktor“ vorhergesagt werden kann. Obwohl Hühnereier nicht schwer vorhersehbar sind und nur für sie der wöchentliche Planungshorizont durchaus akzeptabel ist, musste bei diesen Produkten gezeigt werden, dass maschinelles Lernen wirklich komplexe Zusammenhänge erkennt und eine nicht triviale Prognose erstellt.
Wir haben bestimmte Produkte nach unserem Geschmack ausgewählt und uns dabei auf die Vollständigkeit der historischen Daten verlassen. Einige Waren wurden erst vor kurzem in die Produktlinie aufgenommen, andere - im Gegenteil - wurden einmal verkauft, aber im Moment wurden sie bereits aus dem Sortiment genommen, sodass der Wert der Daten auf ihnen nur historisch war.
Die von Utkonos zur Verfügung gestellten Daten enthielten Informationen zum Verkauf von vier Warennamen in den letzten zwei Jahren und zur Verfügbarkeit dieser Waren auf Lager in den relevanten Zeiträumen. Aus dem allgemeinen Datensatz haben wir die letzten sechs Monate von Anfang November bis Ende April sofort „abgeschnitten“ - dies wird unser Testsatz sein. Es umfasste sowohl relativ ruhige Herbstmonate als auch eine Reihe von Winter- und Frühlingsferien.
Ein kurzes aber aufregendes Abenteuer erwartete uns.
Daten aus Lagern: geheimnisvoll und notwendig
Bei der Arbeit mit historischen Daten stellte sich zunächst die Frage, wie der tatsächliche Umsatz vom „maximal verfügbaren Umsatz“ getrennt werden kann (dh in Fällen, in denen die im Lager endenden Waren zu 100% eingelöst wurden, das Verkaufsvolumen jedoch, falls verfügbar, möglich ist höher sein)? Solche unerfüllten Käuferwünsche werden schließlich in keiner Weise in den Daten angezeigt.
Verfügbarkeit von Waren auf Lager. Aus den Erfahrungen früherer Projekte im Einzelhandel haben wir übrigens erwartet, dass dies Salden in Maßeinheiten sind. In diesem Fall handelte es sich jedoch um den relativen Indikator „Zugänglichkeit“, der tagsüber in Prozent gemessen wurde. Was die Verfügbarkeit von Waren im Lager betrifft, ist dieser Indikator sehr relativ: Die Tatsache, dass zu keinem Zeitpunkt Waren vorhanden waren, bedeutete nicht, dass sie diese kaufen wollten.
Nachdem wir mit verschiedenen Optionen experimentiert hatten (Rekonstruktion des „realen Bedarfs“ basierend auf unterschiedlich berechneten Koeffizienten und Filtern des Verkaufsdatensatzes mit unterschiedlichen Zugänglichkeitsschwellen), haben wir schließlich den optimalen Schwellenwert ausgewählt, der den Datensatz nicht zu eng machte. Das Ideal - die Verfügbarkeit von Waren über den Tag hinweg - reduzierte die Daten selbst für die meistverkauften Waren erheblich.
Punkt 1: gekühltes Fleisch (ungewöhnliches Geflügel)
Wir begannen mit gekühltem Fleisch zu arbeiten, da wir nicht an der Vorhersagefähigkeit des Modells zweifelten, sobald es in Entwurfsform fertig war. (Spoiler: aber vergebens - im Datensatz mit Eierverkäufen wartete eine interessante Überraschung auf uns, aber dazu später mehr).
Um Zeit zu sparen, haben wir eine vorgefertigte Bibliothek, die gut mit Zeitreihen funktioniert - Prophet von Facebook .

Die Ergebnisse des Modells auf den Trainingsdaten zeigen sofort sowohl Vor- als auch Nachteile. Das Modell nimmt die Saisonalität der Nachfrage gut auf, aber schlecht. Auch Feiertage, die standardmäßig vom Propheten verkabelt werden. Die relative Abweichung beträgt 31,36%, wir werden sie weiterhin als Basisergebnis verwenden.
Mit dem integrierten Tool zur Visualisierung der Saisonalität, das Prophet sieht, erhalten Sie sofort einen kleinen Einblick darüber, wie sich die Käufe eines der Produkte über zwei Jahre verändert haben und welche Funktionen sie während des Jahres und während der Woche haben:

Unser gekühltes Fleisch weist einen deutlichen Aufwärtstrend bei der Gesamtzahl der Einkäufe auf, die Anzahl der Einkäufe steigt von Montag bis Samstag und fällt am Sonntag, im Sommer sinken die Einkäufe merklich. Es ist schlecht, dass der Sommer nicht in unsere Testphase fällt; Denken Sie andererseits daran, dass die Zeit der Ferien und Ferien für das Umsatzniveau wichtig ist, da die Sommerferien bei weitem nicht die einzigen in Russland sind.
Die logische Frage ist: Ist es möglich, dieses Modell sofort für Prognosen für die nächsten sechs Monate zu verwenden?
Intuitiv scheint es nicht. Das Experiment hat gezeigt, dass es so ist. Das allgemeine Muster der Saisonalität während der Woche ist korrekt. Es wurde jedoch sofort klar, dass es eine Million Abweichungen vom allgemeinen saisonalen Muster gibt, sowohl nach oben als auch nach unten, und die durchschnittliche Abweichung von 45,71% ist viel höher als die Ergebnisse der Trainingsdaten. Es ist klar, dass dies nicht gut ist.
Lassen Sie uns zunächst versuchen, das Modell täglich zu trainieren, wobei wir uns vorstellen, dass der Datensatz jeden Tag nach Fertigstellung des Geschäfts durch Verkäufe für „heute“ ergänzt wird. Wir wissen bereits, dass es im Vertrieb generell einen Aufwärtstrend gibt - es ist möglich, dass der Umsatz mit unseren Testdaten aufgrund aktiverer Marketingaktivitäten mit größerer Intensität wächst als mit dem Trainingsset.
Relativer Erfolg: Bei täglicher Umschulung des Modells beträgt die relative Abweichung 33,79%. Wir haben die Modellparameter durch Informationen zu den verschobenen Wochenenden, religiösen Fasten und Feiertagen ergänzt, die für Russland traditionell sind (wie Neujahr, Ostern und eine Reihe anderer). Plötzliche Wetteränderungen wurden ebenfalls hinzugefügt: Tage, an denen die Temperatur um mehr als 10 Grad stieg oder fiel oder einfach merklich höher oder niedriger war als an anderen Tagen dieses Monats. Jetzt, im Durchschnitt für sechs Monate, weicht unsere Prognose um 28,48% vom realen Umsatz ab, und im Allgemeinen begann das Modell, die Zunahme der Verbraucheraktivität besser zu berücksichtigen. Wir haben die durchschnittliche Abweichung um fünf Prozent verbessert! Trotz der Tatsache, dass der Prophet im Prinzip schlecht funktioniert und es empfohlen wird, Daten von ihnen zu löschen, war dies eine bemerkenswerte Vorwärtsbewegung.


Bevor die vorläufigen Ergebnisse gezeigt wurden, stellte sich die Frage: Können wir die Prognose etwas weiter verbessern? Wenn Sie sich die Korrelation zwischen Produktverkäufen und dem Durchschnittspreis pro Tag ansehen, ist klar, dass dies verwandte Merkmale sind und der Preis beim Erstellen des Modells nicht berücksichtigt wird. Dem Datensatz nach zu urteilen, konnten wir jedoch nur einen bestimmten „Durchschnittspreis pro Einheit“ annehmen: Bei Bestellungen variierte dieser häufig am selben Tag, d. H. wurde mit einem persönlichen Rabatt des Käufers erfasst, und "Storefront" -Preise wurden nicht in den Datensatz aufgenommen.

Der Korrelationskoeffizient zwischen dem Durchschnittspreis pro Einheit pro Tag und der Anzahl der verkauften Mengen dieser Art von gekühltem Fleisch betrug ¬ - 0,61 bei p <0,01. Es ist klar, dass der „durchschnittliche Stückpreis“ kein idealer Indikator ist: Wenn tagsüber beispielsweise viele Einkäufe von Partnern mit einem konstant hohen Rabatt getätigt wurden, schleicht sich gefährliches Rauschen in die Daten ein. Wir wollten jedoch die Tage hervorheben, an denen es Auswirkungen auf das Marketing gab: allgemeine Rabatte auf eine Warengruppe, Rabatte für alle, die einen Werbecode für die kostenlose Verteilung einführen usw.
Selbst nachdem die Tage mit dem Durchschnittspreis im 5% -Quantil als Werbetage zugewiesen wurden, konnte die Genauigkeit des Modells nicht erhöht werden. Die Genauigkeit stieg an Tagen mit extremen Verkäufen und die durchschnittliche relative Abweichung für sechs Monate blieb gleich.
Die Idee eines ausgeprägten statistischen Verhältnisses zum Preis ist jedoch für die Zukunft erhalten geblieben.

Wir waren sehr zufrieden mit dem vorläufigen Ergebnis, es war Zeit, zu anderen Waren überzugehen, bevor die für das Pilotprojekt vorgesehene Zeit abgelaufen war.
Punkt 2: Hühnerei
Wir wurden sofort gewarnt, dass Eier eine der indikativsten Produktkategorien in Bezug auf die Auswirkungen externer Ereignisse sind. Erstens wächst das Einkaufsvolumen an Ostern: Eier werden bemalt und mit Eiern gekocht. Aber mehr ist natürlich gemalt. Dies ist leicht zu verstehen, wenn man den Verkauf von weißen und braunen Eiern vergleicht.

Im Allgemeinen geht unser Modell davon aus, dass die Nachfrage zu Ostern leicht ansteigen wird, aber seine Prognose liegt fast zweimal unter dem tatsächlichen Indikator (und diese Abweichung von ~ 100% während der Osterwoche macht die durchschnittliche Abweichung für sechs Monate unglaublich groß). Warum? Immerhin findet die Osterwoche jährlich statt - die Daten der letzten 2 Jahre müssen ein Muster enthalten!
Forschungsanalysen haben gezeigt, dass es kein Muster gibt. Im Jahr 2018 (dies sind unsere Testdaten) fällt der Höchststand der Einkäufe die ganze Woche vor Ostern bis zum 7. April. An Ostern selbst (8. April 2018) fallen immer Eierkäufe, was das Modell richtig sieht. Aber im Jahr 2017 fällt Ostern auf den 16. April, und der Höhepunkt der Einkäufe in historischen Daten ist der 8. April, und in diesem Jahr ist der Höhepunkt ein Tag. Im Jahr 2016 fällt Ostern auf den 1. Mai. Der Höhepunkt der Einkäufe ist der 29. April, mit einem Anstieg einen Tag vorher und einen Tag danach. Im Jahr 2015 fällt Ostern auf den 12. April, der Höhepunkt der Einkäufe ist wieder ein Tag, der 9. April.

Unsere erste Version war der Einfluss der Wochentage (und die Fantasie malte die Eltern, die bis morgen ein Dutzend Eier malen müssen, weil die thematische Lektion und das Kind dies heute sagten). Leider ist das nicht so. Wahrscheinlich gibt es zu Ostern einige Faktoren, die wir noch nicht gefunden haben (und die wir nicht berücksichtigt haben) - sowohl extern als auch im Zusammenhang mit der Vermarktung des Unternehmens selbst.
Wir können es besser machen!
In dieser Geschichte geht es darum, für eine begrenzte Zeit mit Händlerdaten zu arbeiten, und nicht um verdeckte Techniken des maschinellen Lernens. Bei der Arbeit mit Daten besteht jedoch die Möglichkeit, das Ergebnis zu verbessern.
Nach der Arbeit mit Produkten aus der Kategorie „Hühnerei“ wurde klar, dass das Modell durch Hinzufügen von Faktoren verbessert werden kann, die wir im Pilotprojekt nicht verwendet haben. Daher wurde beschlossen, ein kleines Experiment mit einem zufälligen Wald und Daten durchzuführen, die wir aus offenen Quellen sammeln können. Außerdem können wir sehen, wie sich das Modell verhält, wo an den Verkaufstagen verschiedene Zeichen und nicht nur eine Reihe von „Sondertagen“ auf der einen oder anderen Basis vergeben werden.
Die folgenden Informationen wurden im Datensatz über die „Außenwelt“ gesammelt:
- einen vollständigen Produktionskalender für jedes Jahr;
- religiöse Posten und Feiertage, weltliche Feiertage;
- Wetterbedingungen und ihre Abweichungen von den Durchschnittswerten für einen Monat in der Region sowie Schwankungen während des letzten Monats, Tages und der letzten Woche;
- Dollar- und Euro-Wechselkurse für die Zentralbank und ihre Schwankungen als Indikatoren für die allgemeine Wirtschaftslage.
Separat wurden Schilder hinzugefügt, um separate Marketingkampagnen und den Preis pro Wareneinheit durchzuführen.
Aus dem erweiterten Datensatz haben wir erneut ein Modell erstellt, das täglich neue Daten trainiert und jetzt RandomForestRegressor verwendet. Die relative Abweichung verbesserte sich leicht: auf 27,29%. Die Grafik zeigt, dass das neue Modell die Auswirkungen von Marketingkampagnen besser vorhersagt, aber schlechter - die wöchentliche Saisonalität.

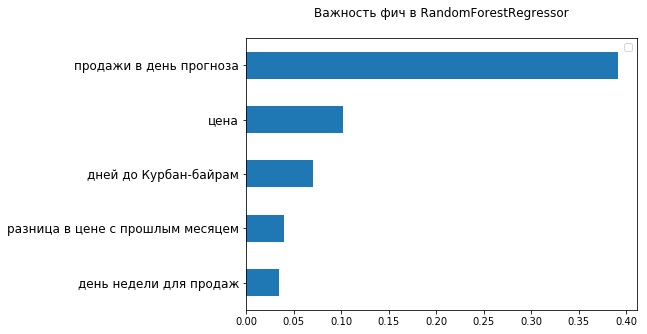
Wenn Sie sich die 5 wichtigsten Zeichen aus Sicht des verwendeten RandomForestRegressor ansehen, können Sie sicherstellen, dass es bereits zwei Zeichen gibt, die sich auf den Wert der Waren beziehen - den aktuellen Preis und seine Änderungen im Vergleich zum letzten Monat. Offensichtlich beeinträchtigte die Tatsache, dass die Preisspanne im FB Prophet nicht gut festgelegt werden konnte, seine Genauigkeit.
Nachdem geprüft wurde, ob wir etwas mehr nachdenken und das Ergebnis verbessern können, wurde die Pilotstudie abgeschlossen. Die Hauptziele wurden erreicht: Wir haben gezeigt, dass maschinelles Lernen grundsätzlich auf Händlerdaten anwendbar ist und auch im Schnellstartmodus gute Ergebnisse zeigt.
Alexandra Tsareva, Spezialistin, Intelligente Analyse, Jet Infosystems