Jeder Betrieb mit Big Data erfordert viel Rechenleistung. Ein typischer Umzug von Daten aus einer Datenbank nach Hadoop kann Wochen dauern oder so viel kosten wie ein Flugzeugflügel. Möchten Sie nicht warten und sich verwöhnen lassen? Verteilen Sie die Last auf verschiedenen Plattformen. Eine Möglichkeit ist die Pushdown-Optimierung.
Ich habe Alexei Ananyev, einen führenden russischen Trainer für die Entwicklung und Verwaltung von Informatica-Produkten, gebeten, über die Pushdown-Optimierungsfunktion in Informatica Big Data Management (BDM) zu sprechen. Haben Sie jemals gelernt, mit Informatica-Produkten zu arbeiten? Höchstwahrscheinlich war es Alex, der Ihnen die Grundlagen von PowerCenter erklärte und erklärte, wie Sie Zuordnungen erstellen.
Alexey Ananiev, Ausbildungsleiter bei der DIS Group
Was ist Pushdown?
Viele von Ihnen sind bereits mit Informatica Big Data Management (BDM) vertraut. Das Produkt kann Big Data aus verschiedenen Quellen integrieren, zwischen verschiedenen Systemen verschieben, bietet einfachen Zugriff darauf, ermöglicht die Profilierung und vieles mehr.
In geschickten Händen kann BDM Wunder wirken: Aufgaben werden schnell und mit minimalem Rechenaufwand erledigt.
Willst du es auch? Erfahren Sie, wie Sie die Pushdown-Funktion in BDM verwenden, um die Rechenlast auf mehrere Plattformen zu verteilen. Mit der Pushdown-Technologie können Sie die Zuordnung in ein Skript umwandeln und die Umgebung auswählen, in der dieses Skript ausgeführt wird. Die Möglichkeit einer solchen Auswahl ermöglicht es Ihnen, die Stärken verschiedener Plattformen zu kombinieren und ihre maximale Leistung zu erzielen.
Wählen Sie den Pushdown-Typ aus, um die Skriptlaufzeit zu konfigurieren. Das Skript kann vollständig auf Hadoop ausgeführt oder teilweise zwischen der Quelle und dem Empfänger verteilt werden. Es gibt 4 mögliche Arten von Pushdowns. Die Zuordnung kann nicht in ein Skript (native) umgewandelt werden. Die Zuordnung kann so oft wie möglich an der Quelle (Quelle) oder vollständig an der Quelle (Voll) durchgeführt werden. Die Zuordnung kann auch in ein Hadoop-Skript (keine) umgewandelt werden.
Pushdown-Optimierung
Die aufgeführten 4 Typen können auf verschiedene Arten kombiniert werden - optimieren Sie den Pushdown für die spezifischen Anforderungen des Systems. Beispielsweise ist es häufig ratsamer, Daten mit eigenen Funktionen aus einer Datenbank zu extrahieren. Und um die Daten zu transformieren - von Hadoop, damit die Datenbank selbst nicht überlastet wird.
Schauen wir uns den Fall an, in dem sich sowohl die Quelle als auch der Empfänger in der Datenbank befinden und die Transformationsausführungsplattform ausgewählt werden kann: Abhängig von den Einstellungen handelt es sich um Informatica, einen Datenbankserver oder Hadoop. Ein solches Beispiel wird es ermöglichen, die technische Seite dieses Mechanismus am genauesten zu verstehen. Im wirklichen Leben tritt diese Situation natürlich nicht auf, aber sie ist am besten geeignet, um die Funktionalität zu demonstrieren.
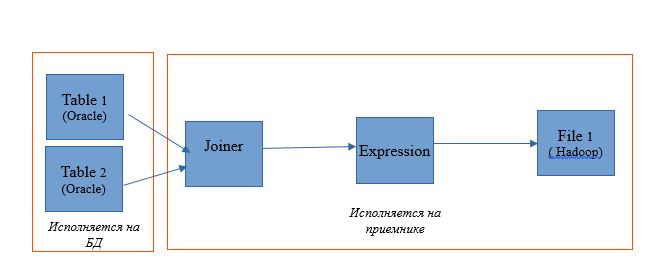
Verwenden Sie die Zuordnung, um zwei Tabellen in einer einzelnen Oracle-Datenbank zu lesen. Lassen Sie die Leseergebnisse in eine Tabelle in derselben Datenbank schreiben. Das Zuordnungsschema lautet wie folgt:

In Form einer Zuordnung unter Informatica BDM 10.2.1 sieht es folgendermaßen aus:
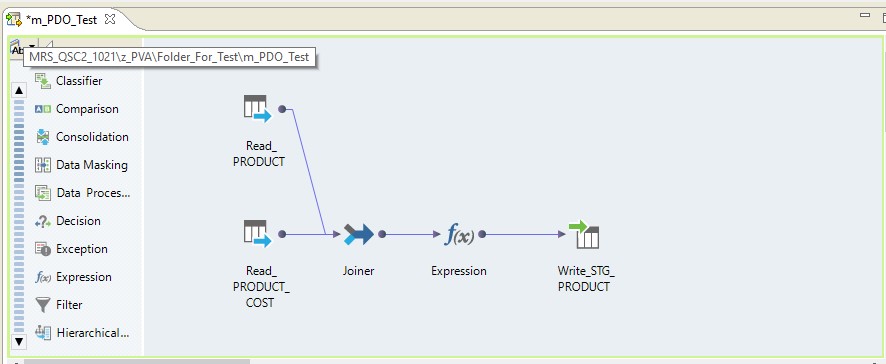
Geben Sie pushdown - native ein
Wenn wir den nativen Pushdown-Typ auswählen, wird die Zuordnung auf dem Informatica-Server durchgeführt. Die Daten werden vom Oracle-Server gelesen, auf den Informatica-Server übertragen, dort transformiert und an Hadoop übertragen. Mit anderen Worten, wir erhalten einen regulären ETL-Prozess.
Geben Sie pushdown - source ein
Bei der Auswahl der Typquelle haben wir die Möglichkeit, unseren Prozess zwischen dem Datenbankserver (DB) und Hadoop zu verteilen. Wenn Sie einen Prozess mit dieser Einstellung ausführen, werden Anforderungen zur Auswahl von Daten aus Tabellen an die Datenbank gesendet. Und der Rest wird in Form von Schritten auf Hadoop erledigt.
Das Ausführungsschema sieht folgendermaßen aus:
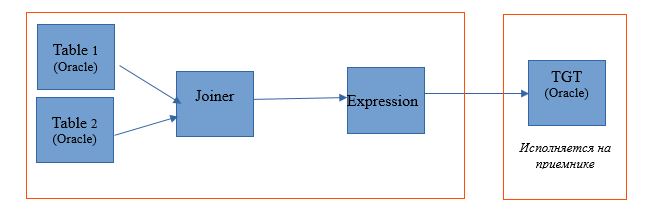
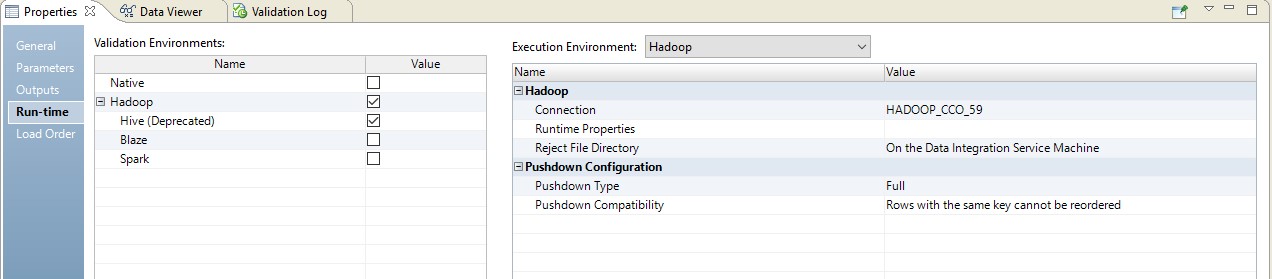
Unten finden Sie ein Beispiel für die Einrichtung der Laufzeit.
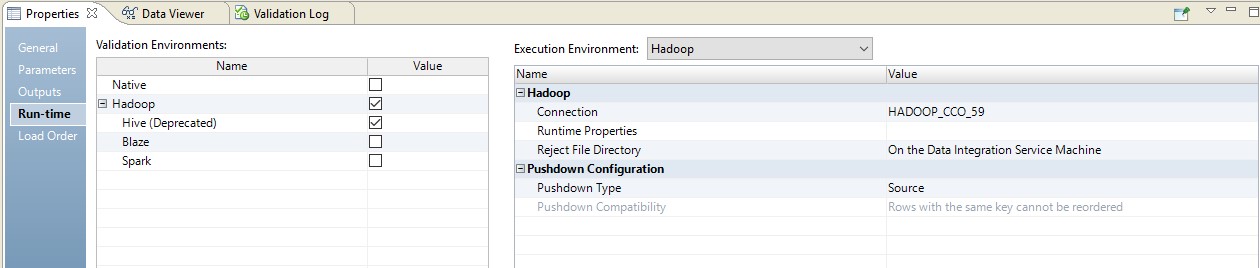
In diesem Fall erfolgt die Zuordnung in zwei Schritten. In seinen Einstellungen werden wir sehen, dass er sich in ein Skript verwandelt hat, das an die Quelle gesendet wird. Darüber hinaus wird die Kombination von Tabellen und Datenkonvertierung in Form einer überschriebenen Abfrage an der Quelle durchgeführt.
In der Abbildung unten sehen wir eine optimierte Zuordnung auf BDM und auf der Quelle - eine überschriebene Anforderung.
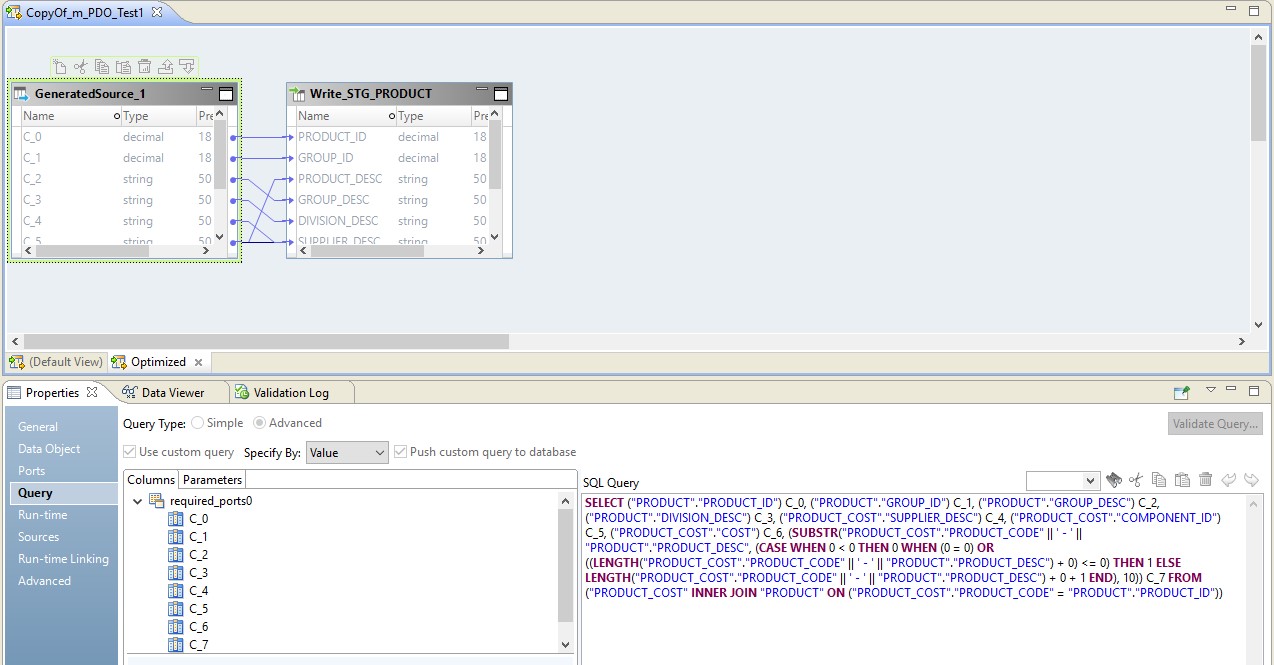
Die Rolle von Hadoop in dieser Konfiguration besteht darin, den Datenfluss zu verwalten und durchzuführen. Das Ergebnis der Anfrage wird an Hadoop gesendet. Nach dem Lesen wird die Datei von Hadoop auf den Empfänger geschrieben.
Typ Pushdown - voll
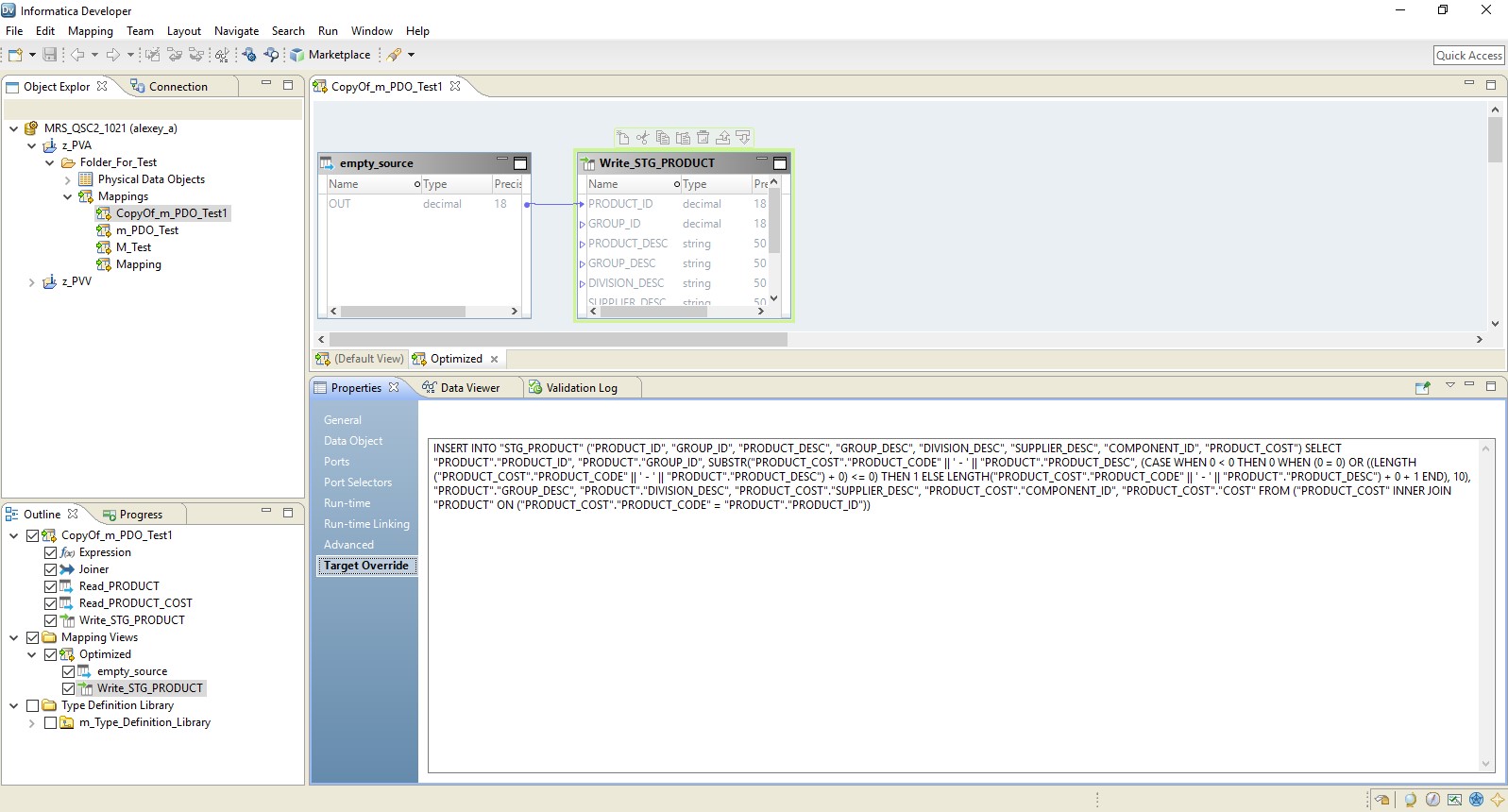
Bei Auswahl des vollständigen Typs wird die Zuordnung vollständig zu einer Datenbankanforderung. Das Abfrageergebnis wird an Hadoop weitergeleitet. Ein Diagramm eines solchen Prozesses ist unten dargestellt.
Ein Beispiel-Setup ist unten dargestellt.
Als Ergebnis erhalten wir ein optimiertes Mapping ähnlich dem vorherigen. Der einzige Unterschied besteht darin, dass die gesamte Logik in Form einer Überschreibung seiner Einfügung an den Empfänger übertragen wird. Ein Beispiel für eine optimierte Zuordnung ist unten dargestellt.
Hier fungiert Hadoop wie im vorigen Fall als Dirigent. Hier wird jedoch die Quelle vollständig gelesen, und dann wird auf Empfängerebene die Datenverarbeitungslogik ausgeführt.
Geben Sie pushdown - null ein
Nun, die letzte Option ist der Pushdown-Typ, innerhalb dessen unser Mapping in ein Hadoop-Skript umgewandelt wird.
Das optimierte Mapping sieht nun folgendermaßen aus:
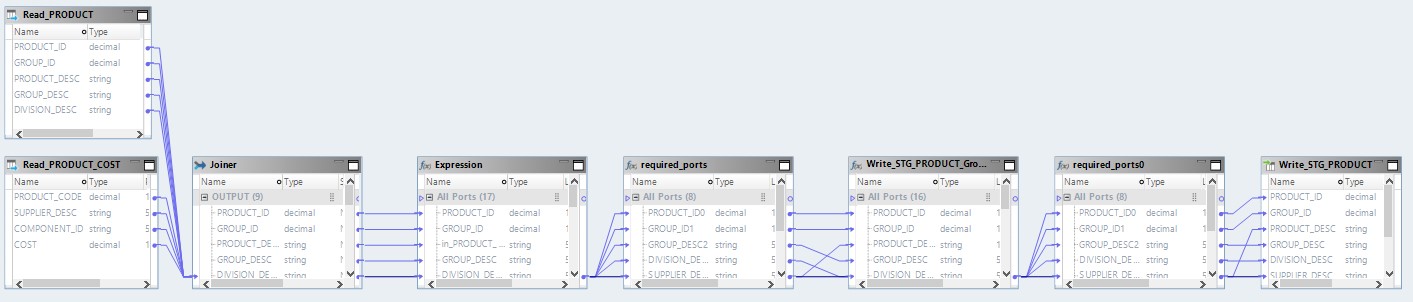
Hier werden die Daten aus den Quelldateien zuerst auf Hadoop gelesen. Dann werden diese beiden Dateien auf eigene Faust kombiniert. Danach werden die Daten konvertiert und in die Datenbank hochgeladen.
Wenn Sie die Prinzipien der Pushdown-Optimierung verstehen, können Sie viele Prozesse für die Arbeit mit Big Data sehr effektiv organisieren. So hat erst kürzlich ein großes Unternehmen in nur wenigen Wochen große Datenmengen aus dem Speicher auf Hadoop hochgeladen, die es bereits vor einigen Jahren gesammelt hatte.