
In diesem Artikel werde ich über meine Lösung für den Textteil der Aufgabe
SNA Hackathon 2019 sprechen. Einige der vorgeschlagenen Ideen werden für die Teilnehmer des Vollzeit-Teils des Hackathons nützlich sein, der vom 30. März bis 1. April im Moskauer Büro der Mail.ru Group stattfinden wird. Darüber hinaus kann diese Geschichte für Leser von Interesse sein, die die praktischen Probleme des maschinellen Lernens lösen. Da ich keine Preise beanspruchen kann (ich arbeite bei Odnoklassniki), habe ich versucht, die einfachste, aber gleichzeitig effektive und interessante Lösung anzubieten.
Wenn ich über neue Modelle des maschinellen Lernens lese, möchte ich verstehen, wie der Autor bei der Arbeit an einer Aufgabe argumentiert hat. Daher werde ich in diesem Artikel versuchen, alle Komponenten meiner Lösung im Detail zu begründen. Im ersten Teil werde ich über die Problemstellung und die Einschränkungen sprechen. Im zweiten - über die Entwicklung des Modells. Der dritte Teil ist den Ergebnissen und der Analyse des Modells gewidmet. Schließlich werde ich in den Kommentaren versuchen, alle aufgetretenen Fragen zu beantworten. Ungeduldige Leser können sich sofort die
endgültige Architektur ansehen.
Herausforderung
Die Organisatoren des Hackathons schlugen vor, das Problem der Bildung eines Smartbands zu lösen. Für jeden Benutzer muss der Satz von Beiträgen so sortiert werden, dass die maximale Anzahl von Beiträgen, für die der Benutzer die „Klasse“ festgelegt hat, ganz oben in der Liste steht. Um den Ranking-Algorithmus zu konfigurieren, sollten historische Daten des Formulars (Benutzer, Beitrag, Feedback) verwendet werden. Die Tabelle enthält eine kurze Beschreibung der Daten aus dem Textteil und der Notation, die ich in diesem Artikel verwenden werde.
Quelle
| Bezeichnung
| Typ
| Beschreibung
|
|---|
der Benutzer
| user_id
| kategorisch
| Benutzer-ID
|
Post
| post_id
| kategorisch
| Post-ID
|
Post
| Text
| kategoriale Liste
| Liste der normalisierten Wörter
|
Post
| Funktionen
| kategorisch
| Gruppe von Merkmalen des Beitrags (Autor, Sprache usw.)
|
Rückkopplung
| Feedback
| binäre Liste
| verschiedene Aktionen, die der Benutzer mit dem Beitrag ausführen kann (Ansicht, Klasse, Kommentar usw.)
|
Bevor ich mit dem Erstellen des Modells begann, habe ich einige Einschränkungen für die zukünftige Lösung eingeführt. Dies war notwendig, um die Anforderungen an Einfachheit und Praktikabilität sowie meine Interessen zu erfüllen und die Anzahl der möglichen Optionen zu verringern. Hier sind die wichtigsten dieser Einschränkungen.
Vorhersage der Wahrscheinlichkeit von "Klasse" . Ich entschied sofort, dass ich dieses Problem als Klassifizierungsproblem lösen würde. Man könnte die im Ranking verwendeten Methoden anwenden, um beispielsweise die Reihenfolge in Beitragspaaren vorherzusagen. Aber ich habe mich für eine einfachere Formulierung entschieden, bei der die Beiträge nach der vorhergesagten Wahrscheinlichkeit sortiert werden, eine "Klasse" zu erhalten. Es ist erwähnenswert, dass der unten beschriebene Ansatz erweitert werden kann, um das Ranking zu formulieren.
Monolithisches Modell . Trotz der Tatsache, dass Modellensembles dazu neigen, Wettbewerbe zu gewinnen, ist es schwieriger, ein Ensemble in einem Kampfsystem zu halten als ein einzelnes Modell. Außerdem wollte ich zumindest einige Nicht-Black-Box-Interpretationsfunktionen haben.
Differenzierbarer Rechengraph . Erstens bestimmen Modelle dieser Klasse (neuronale Netze) den Stand der Technik bei vielen Aufgaben, einschließlich solcher, die sich auf die
Analyse von Textdaten beziehen. Zweitens ermöglichen moderne Frameworks, in meinem Fall
Apache MXNet , die Implementierung sehr unterschiedlicher Architekturen. Daher können Sie mit verschiedenen Modellen experimentieren, indem Sie nur wenige Codezeilen ändern.
Minimale Arbeit mit Schildern . Ich wollte, dass das Modell einfach mit neuen Daten erweitert werden kann. Dies kann im Vollzeitbereich erforderlich sein, wo nur wenig Zeit für die Vorbereitung der Schilder bleibt. Daher habe ich mich für den einfachsten Ansatz zur Identifizierung von Attributen entschieden:
- Binärdaten werden durch ein Tag mit dem Wert 1 oder 0 dargestellt.
- numerische Daten bleiben entweder unverändert oder werden in Kategorien diskretisiert;
- kategoriale Daten werden durch Einbettungen dargestellt.
Nachdem ich mich für die allgemeine Strategie entschieden hatte, fing ich an, verschiedene Modelle auszuprobieren.
Modellentwicklung
Ausgangspunkt war der Ansatz der Matrixfaktorisierung, der häufig bei Empfehlungsaufgaben verwendet wird:
pi,j= sigma(ui cdotvj)
Verlust(yi,j,pi,j) rightarrowminu,v
In der Sprache der Berechnungsgraphen bedeutet dies, dass die Schätzung der Wahrscheinlichkeit, dass Benutzer
i eine "Klasse" auf Post
j setzt, das Sigmoid aus dem Skalarprodukt der Einbettungen der Benutzer-ID und der Post-ID ist. Das gleiche kann durch ein Diagramm ausgedrückt werden:

Ein solches Modell ist nicht sehr interessant: Es nutzt nicht alle Funktionen, ist für niederfrequente Kennungen nicht allzu nützlich und leidet unter dem Problem eines Kaltstarts. Nachdem wir die Aufgabe in Form eines Rechengraphen formuliert haben, haben wir „unsere Hände losgebunden“ und können nun Probleme schrittweise lösen. Zunächst werden wir für niederfrequente Werte die einzige Einbettung
außerhalb des Wortschatzes erstellen. Beseitigen Sie als Nächstes die Notwendigkeit von Einbettungen mit derselben Dimension. Dazu ersetzen wir das Skalarprodukt durch ein flaches Perzeptron, das verkettete Merkmale als Eingabe empfängt. Das Ergebnis ist im Diagramm dargestellt:

Sobald wir eine feste Dimension entfernt haben, hindert uns nichts mehr daran, neue Attribute hinzuzufügen. Indem wir den Beitrag mit allen möglichen Merkmalen (Sprache, Autor, Text, ...) darstellen, werden wir das Problem des Kaltstarts von Beiträgen lösen. Das Modell erfährt beispielsweise, dass ein Benutzer mit
user_id = 42 "Klassen" auf Beiträge in russischer Sprache setzt, die das Wort "Teppich" enthalten. In Zukunft können wir diesem Benutzer alle russischsprachigen Beiträge zu Teppichen empfehlen, auch wenn diese nicht in den Trainingsdaten enthalten sind. Für die Texteinbettung werden wir vorerst einfach die Einbettungen der darin enthaltenen Wörter mitteln. Infolgedessen sieht das Modell folgendermaßen aus:
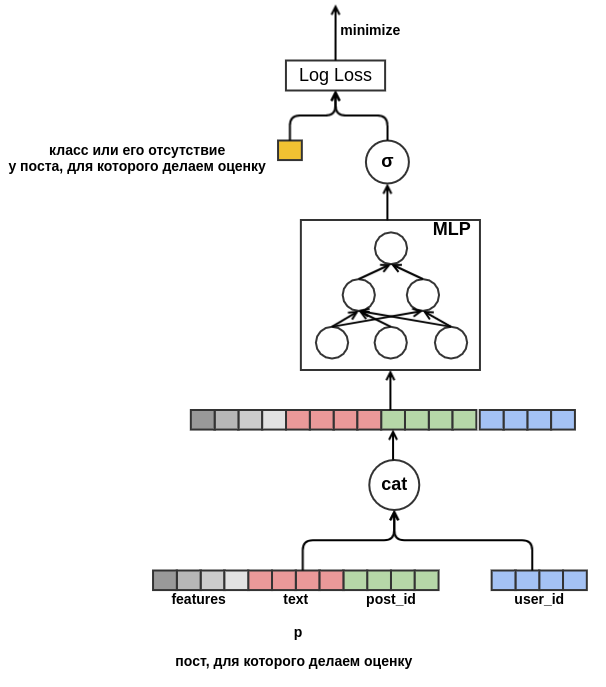
Abschließend möchte ich mich mit dem Kaltstart der Benutzer befassen. Es wäre möglich, Features aus historischen Daten in Benutzeransichten von Posts zu erstellen. Dieser Ansatz entspricht nicht der gewählten Strategie: Wir haben beschlossen, die manuelle Erstellung von Attributen zu minimieren. Daher bot ich dem Modell die Möglichkeit, die Präsentation des Benutzers unabhängig aus der Reihenfolge der Beiträge zu lernen, die vor dem Beitrag angezeigt wurden, für den die Wahrscheinlichkeit der „Klasse“ bewertet wird. Im Gegensatz zu dem Beitrag, der ausgewertet wird, ist jedes Feedback für jeden Beitrag in der Sequenz bekannt. Dies bedeutet, dass das Modell Zugriff auf Informationen darüber hat, ob der Benutzer die "Beiträge" auf vorherige Beiträge gesetzt oder im Gegenteil aus dem Feed gelöscht hat.

Es bleibt zu entscheiden, wie Sequenzen von Pfosten unterschiedlicher Länge zu einer Darstellung fester Breite kombiniert werden sollen. Als solche Kombination habe ich die gewichtete Summe der Darstellungen der einzelnen Beiträge verwendet. In der Tabelle wird das
Nachgewicht j mit
α_j bezeichnet . Die Gewichte wurden unter Verwendung des Abfrageschlüsselwert-Aufmerksamkeitsmechanismus berechnet, ähnlich dem im
Transformator oder
NMT verwendeten . Somit wird die gelernte Präsentation des Benutzers auch für den Beitrag konfiguriert, für den die Bewertung durchgeführt wird. Hier ist ein Teil des Diagramms, der für die Berechnung von
α_j verantwortlich ist :
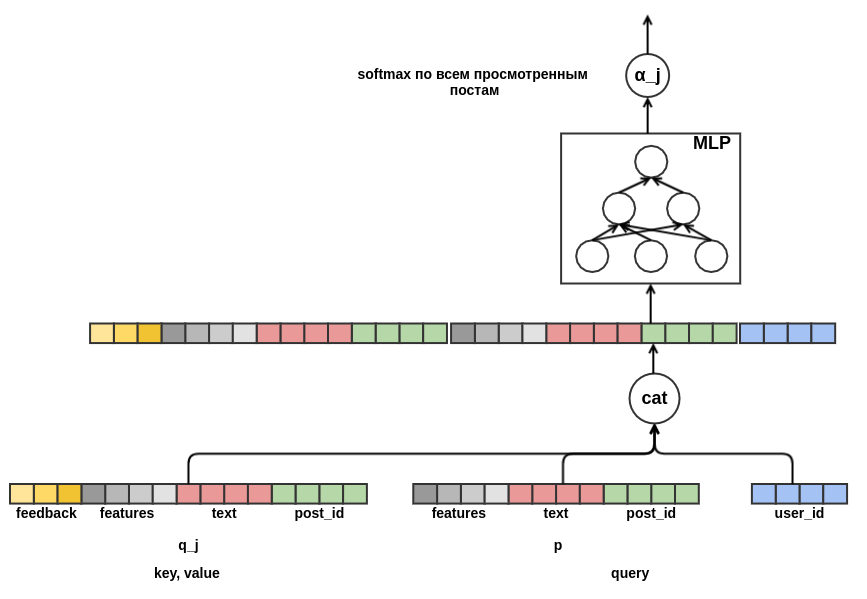
Nachdem ich
einen Festgesang verspürt hatte, war ich von der Wirksamkeit des Aufmerksamkeitsansatzes überzeugt. Es wurde beschlossen, die Aufmerksamkeit bei der Präsentation von Texten zu verwenden. Um Zeit und Eisen zu sparen, habe ich beschlossen, nicht wie im selben Transformator auf sich selbst zu achten, sondern die Wortgewichte im Text direkt wie folgt zu trainieren:
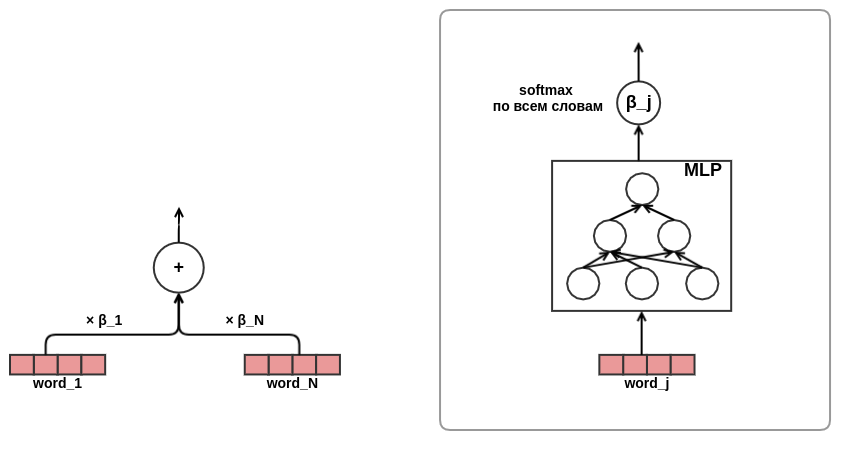
Damit war die Entwicklung der Architektur des Modells abgeschlossen. Infolgedessen ging ich von der klassischen Matrixfaktorisierung zu einem ziemlich komplexen Sequenzmodell über.
Ergebnisse und Analyse
Ich habe meine Lösung für ein Siebtel der Daten auf einem Laptop mit 16 GB Speicher und einer GeForce 930MX-Grafikkarte entwickelt und getestet. Vollständige Datenexperimente wurden auf einem dedizierten Server mit 256 GB Speicher und einer Tesla T4-Karte durchgeführt. Zur Optimierung wurde der Adam-Algorithmus mit den Standardparametern von MXNet verwendet. Die Tabelle zeigt die Ergebnisse für ein abgespecktes Modell - die Länge der Folge von Beiträgen war auf zehn begrenzt. Bei der Einreichung des Wettbewerbs habe ich Sequenzen mit einer Länge von fünfzig verwendet.
Modell
| Protokollverlust
| Verbesserung gegenüber der vorherigen Zeile
| Trainingszeit
|
|---|
Zufällig
| 0,4374 ± 0,0009
| | |
Perceptron
| 0,4330 ± 0,0010
| 0,0043 ± 0,0002
| 7 min
|
Perceptron mit Zeichen
| 0,4119 ± 0,0008
| 0,0212 ± 0,0003
| 44 min
|
Perceptron mit einer Folge von Beiträgen
| 0,3873 ± 0,0008
| 0,0247 ± 0,0003
| 4 Stunden 16 Minuten
|
Perceptron mit einer Folge von Beiträgen und Aufmerksamkeit in den Texten
| 0,3874 ± 0,0008
| 0,0001 ± 0,0001
| 4 Stunden 43 Minuten
|
Die letzte Zeile erwies sich für mich als die unerwartetste: Die Verwendung von Aufmerksamkeit bei der Präsentation von Texten führt zu keiner sichtbaren Verbesserung des Ergebnisses. Ich erwartete, dass das Aufmerksamkeitsnetzwerk die Gewichte von Wörtern in Texten lernen würde, so etwas wie
idf . Vielleicht ist dies nicht geschehen, weil die Organisatoren die Stoppwörter im Voraus entfernt haben und Wörter von ungefähr gleicher Bedeutung in den vorbereiteten Listen verblieben sind. Daher ergab das „intelligente“ Wiegen keinen greifbaren Vorteil gegenüber der einfachen Mittelwertbildung. Ein weiterer möglicher Grund ist, dass das Aufmerksamkeitsnetzwerk für Wörter recht klein war: Es enthielt nur eine schmale verborgene Schicht. Vielleicht fehlte ihr die Repräsentationsfähigkeit, um etwas Nützliches zu lernen.
Mit dem Abfrageschlüsselwert-Aufmerksamkeitsmechanismus können Sie in das Modell schauen und herausfinden, worauf es bei einer Entscheidung „achtet“. Um dies zu veranschaulichen, habe ich einige Beispiele ausgewählt:
, http://ollston.ru/2018/02/10/uznajte-kakogo-cveta-vasha - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.16] 2016 2016 GZ8btjgY_Q0 https: - [0.16] . Nike http://ollston.ru/2018/02/04/istorii-yspeha-nike/ - : - [0.09] - 5 - 5 O3qAop0A5Qs https://ww - [0.09] ... , - [0.22] Microsoft Windows — http://ollston.ru/2018/02/06/microsoft-windows-istoriia-yspeha/ - [0.20] , 6 . , ? http://ollston.ru/2018/02/08/buddisty-g
Die erste Zeile zeigt den Text des Beitrags, der ausgewertet werden muss, dann die zuvor angezeigten Beiträge und die entsprechende Aufmerksamkeitsbewertung. Mit Erleichterung stellen wir fest, dass das Modell gelernt hat, das Auffüllen zu ignorieren. Das Modell betrachtete Beiträge als die wichtigsten über Seelentypen und über Windows. Es sollte bedacht werden, dass die Aufmerksamkeit entweder positiv (der Benutzer antwortet auf einen Beitrag über eine Aura ähnlich wie ein Beitrag über Seelentypen) oder negativ (wir bewerten einen Beitrag über eine Aura - daher ist die Reaktion nicht die gleiche wie die Reaktion auf den Beitrag über Technologie). Das folgende Beispiel ist Aufmerksamkeit "in ihrer ganzen Pracht":
- [0.20] 2018 (), , . - [0.08] ... !!! - [0.04] ))) - [0.18] ! , . 10 - [0.18] 2- , 5 , , 2 , . . - [0.07] ! - () - [0.03] "". . - [0.13] , - [0.05] , ... - [0.05] ...
Hier sah das Modell deutlich das Thema Sommerferien. Sogar Kinder und Kätzchen blieben auf der Strecke. Das folgende Beispiel zeigt, dass das Interpretieren von Aufmerksamkeit nicht immer möglich ist. Manchmal ist sogar gar nichts klar:
! - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.02] PADDING - [0.15] , ! !!! - [0.16] ! http://gifok.ru/dobryj-vecher/ - [0.20] http://gifq.ru/aforizmy/ - [0.25] . . - [0.15] , . : 800 250-300
Nachdem ich mir einige solcher Listen angesehen hatte, kam ich zu dem Schluss, dass das Modell lernen konnte, was ich erwartet hatte. Als nächstes habe ich mir die Einbettung von Wörtern angesehen. In unserem Problem können wir nicht erwarten, dass Einbettungen so schön werden wie beim Erlernen eines
Sprachmodells : Wir versuchen, eine ziemlich verrauschte Variable vorherzusagen, außerdem haben wir kein kleines Kontextfenster - die Einbettungen aller Wörter werden einfach gemittelt, ohne ihre Reihenfolge im Text zu berücksichtigen. Beispiele für Token und ihre nächsten Nachbarn im Einbettungsbereich:
- : , , , , - : , , , , - : , , , , - : , , , , - : , , , ,
Einige dieser Listen sind leicht zu erklären (program - bl), etwas ist rätselhaft (iPhone - youki), aber im Allgemeinen hat das Ergebnis wieder meine Erwartungen erfüllt.
Fazit
Ich mag den Ansatz, Modelle basierend auf differenzierbaren Graphen zu erstellen (
viele sind sich einig ). Sie können sich von der mühsamen manuellen Auswahl von Funktionen lösen und sich auf die korrekte Formulierung des Problems und das Entwerfen interessanter Architekturen konzentrieren. Und obwohl mein Modell bei der Textaufgabe SNA Hackathon 2019 nur den zweiten Platz belegte, bin ich mit diesem Ergebnis aufgrund seiner Einfachheit und nahezu unbegrenzten Erweiterungsmöglichkeiten sehr zufrieden. Ich bin sicher, dass es in Zukunft immer interessantere und anwendbarere Modelle in Kampfsystemen geben wird, die auf ähnlichen Ideen basieren.