Heute werde ich Ihnen erzählen, wie wir es geschafft haben, das Problem der Portierung von
Spark Structured Streaming-Anwendungen auf
Kubernetes (K8s) und der Implementierung von CI-Streaming zu lösen.
Wie hat alles angefangen?
Streaming ist eine Schlüsselkomponente der FASTEN RUS BI-Plattform. Echtzeitdaten werden vom Datumsanalyseteam verwendet, um Betriebsberichte zu erstellen.
Streaming-Anwendungen werden mithilfe von
Spark Structured Streaming implementiert. Dieses Framework bietet eine praktische Datentransformations-API, die unsere Anforderungen hinsichtlich der Geschwindigkeit von Verbesserungen erfüllt.
Die Streams selbst stiegen im
AWS EMR- Cluster an. Daher wurde beim Auslösen eines neuen Streams zum Cluster ein SSH-Skript zum Senden von Spark-Jobs erstellt, wonach die Anwendung gestartet wurde. Und zuerst schien uns alles zu passen. Mit der zunehmenden Anzahl von Streams wurde jedoch immer deutlicher, dass CI-Streaming implementiert werden muss, was die Autonomie des Befehls "Analysedatum" beim Starten von Anwendungen zum Bereitstellen von Daten für neue Entitäten erhöhen würde.
Und jetzt schauen wir uns an, wie wir dieses Problem durch Portierung von Streaming auf Kubernetes gelöst haben.
Warum Kubernetes?
Kubernetes als Ressourcenmanager hat unsere Anforderungen am besten erfüllt. Dies ist eine Bereitstellung ohne Ausfallzeiten und eine breite Palette von CI-Implementierungstools auf Kubernetes, einschließlich Helm. Darüber hinaus verfügte unser Team über ausreichend Fachwissen bei der Implementierung von CI-Pipelines auf K8. Daher war die Wahl offensichtlich.
Wie ist das Kubernetes-basierte Spark-Anwendungsverwaltungsmodell organisiert?

Der Client führt Spark-Submit auf K8s aus. Ein Anwendungstreiber-Pod wird erstellt. Kubernetes Scheduler bindet einen Pod an einen Clusterknoten. Anschließend sendet der Treiber eine Anforderung zum Erstellen von Pods zum Ausführen von Führungskräften. Pods werden erstellt und an Clusterknoten angehängt. Danach wird ein Standardsatz von Operationen ausgeführt, mit der anschließenden Konvertierung des Anwendungscodes in DAG, der Zerlegung in Stufen, der Aufteilung in Aufgaben und deren Start auf ausführbaren Dateien.
Dieses Modell funktioniert recht erfolgreich, wenn Spark-Anwendungen manuell gestartet werden. Der Ansatz, Spark-Submit außerhalb des Clusters zu starten, passte jedoch nicht zu uns hinsichtlich der CI-Implementierung. Es musste eine Lösung gefunden werden, mit der Spark direkt auf den Knoten des Clusters ausgeführt werden kann (Spark-Submit ausführen). Und hier hat das Kubernetes Operator-Modell unsere Anforderungen voll erfüllt.
Kubernetes Operator als Spark Application Lifecycle Management-Modell
Kubernetes Operator ist ein von
CoreOS vorgeschlagenes Konzept zur Verwaltung von Statefull-Anwendungen in Kubernetes, das die Automatisierung von Betriebsaufgaben umfasst, z. B. das Bereitstellen von Anwendungen, das Neustarten von Anwendungen bei Dateien und das Aktualisieren der Konfiguration von Anwendungen. Eines der wichtigsten Kubernetes-Operatormuster ist CRD (
CustomResourceDefinitions ), bei dem dem K8s-Cluster benutzerdefinierte Ressourcen hinzugefügt werden, mit denen Sie wiederum mit diesen Ressourcen wie mit nativen Kubernetes-Objekten arbeiten können.
Operator ist ein Daemon, der sich im Pod des Clusters befindet und auf die Erstellung / Änderung des Status einer benutzerdefinierten Ressource reagiert.
Berücksichtigen Sie dieses Konzept für das Spark-Anwendungslebenszyklusmanagement.
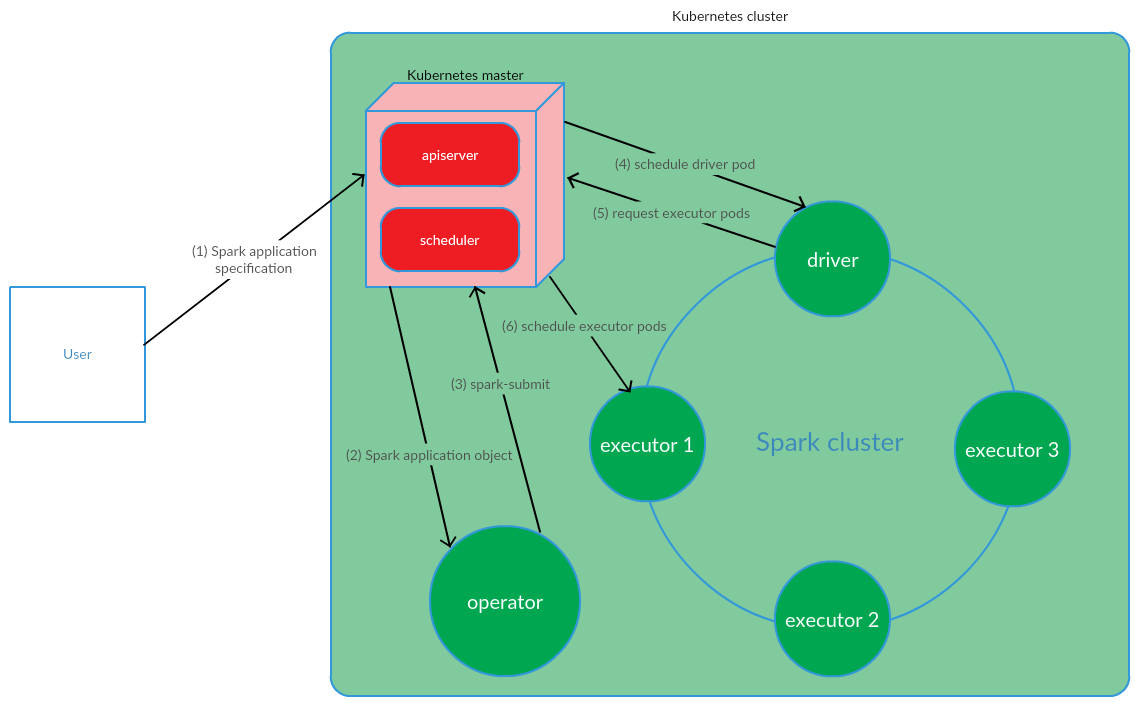
Der Benutzer führt den Befehl kubectl apply -f spark-application.yaml aus, wobei spark-application.yaml die Spezifikation der Spark-Anwendung ist. Der Bediener empfängt das Spark-Anwendungsobjekt und führt die Spark-Übermittlung aus.
Wie wir sehen können, umfasst das Kubernetes-Operator-Modell die Verwaltung des Lebenszyklus einer Spark-Anwendung direkt im Kubernetes-Cluster, was ein ernstes Argument für dieses Modell im Zusammenhang mit der Lösung unserer Probleme war.
Als Kubernetes-Operator für die Verwaltung von Streaming-Anwendungen wurde die Verwendung des
Spark-on-k8s-Operators beschlossen . Dieser Operator bietet eine recht praktische API sowie Flexibilität bei der Konfiguration der Neustartrichtlinie für Spark-Anwendungen (was im Zusammenhang mit der Unterstützung von Streaming-Anwendungen sehr wichtig ist).
CI-Implementierung
Zur Implementierung des CI-Streamings wurde
GitLab CI / CD verwendet . Die Bereitstellung von Spark-Anwendungen auf K8s wurde mit
Helm- Tools durchgeführt.
Die Pipeline selbst umfasst zwei Stufen:
- Test - Syntaxprüfung wird durchgeführt, sowie das Rendern von Helm-Vorlagen;
- Bereitstellen - Bereitstellung von Streaming-Anwendungen in Test- (Entwickler) und Produktumgebungen (Produktumgebungen).
Lassen Sie uns diese Phasen genauer betrachten.
In der Testphase wird die Spark-Anwendungs-
Helmvorlage (CRD -
SparkApplication ) mit umgebungsspezifischen Werten
gerendert .
Die wichtigsten Abschnitte der Helm-Vorlage sind:
- Funke:
- version - Apache Spark-Version
- image - Verwendetes Docker-Image
- nodeSelector - enthält eine Liste (Schlüssel → Wert), die den Beschriftungen der Herde entspricht.
- Toleranzen - Gibt die Liste der Toleranzen der Spark-Anwendung an.
- mainClass - Spark-Anwendungsklasse
- applicationFile - lokaler Pfad, in dem sich das Spark-Anwendungsglas befindet
- restartPolicy - Richtlinie zum Neustart der Spark-Anwendung
- Niemals - Die abgeschlossene Spark-Anwendung wird nicht neu gestartet
- Immer - Die abgeschlossene Spark-Anwendung wird unabhängig vom Grund für den Stopp neu gestartet.
- OnFailure - Die Spark-Anwendung wird nur im Falle einer Datei neu gestartet
- maxSubmissionRetries - maximale Anzahl von Übermittlungen einer Spark-Anwendung
- Treiber / Executor:
- Kerne - Die Anzahl der Kernel, die dem Treiber / Executor zugewiesen sind
- Instanzen (nur für die Konfiguration von Führungskräften verwendet) - Die Anzahl der Führungskräfte
- Speicher - Die Menge an Speicher, die dem Treiber / Executor-Prozess zugewiesen ist
- memoryOverhead - Die Menge an Off-Heap-Speicher, die dem Treiber / Executor zugewiesen ist
- Streams:
- name - Name der Streaming-Anwendung
- Argumente - Argumente für die Streaming-Anwendung
- sink - der Pfad zu den Data Lake-Datensätzen in S3
Nach dem Rendern der Vorlage werden Anwendungen mit Helm in der Entwicklertestumgebung bereitgestellt.
Die CI-Pipeline wurde ausgearbeitet.
Dann starten wir den Deployment-Prod-Job - das Starten von Anwendungen in der Produktion.
Wir sind von einer erfolgreichen Arbeitsleistung überzeugt.
Wie wir unten sehen können, werden die Anwendungen ausgeführt, die Pods befinden sich im Status RUNNING.

Fazit
Durch die Portierung von Spark-strukturierten Streaming-Anwendungen auf K8s und die anschließende Implementierung von CI konnte der Start von Streams für die Bereitstellung von Daten an neue Entitäten automatisiert werden. Um den nächsten Stream auszulösen, reicht es aus, eine Zusammenführungsanforderung mit einer Beschreibung der Konfiguration der Spark-Anwendung in der yaml-Wertedatei vorzubereiten. Wenn der Job für die Bereitstellung gestartet wird, wird die Datenübermittlung an Data Lake (S3) initiiert. Diese Lösung stellte die Autonomie des Befehls "Analysedatum" sicher, wenn Aufgaben im Zusammenhang mit dem Hinzufügen neuer Entitäten zum Repository ausgeführt wurden. Darüber hinaus hat die Portierung des Streamings auf K8s und insbesondere die Verwaltung von Spark-Anwendungen mit dem Kubernetes-Operator spark-on-k8s-operator die Ausfallsicherheit des Streamings erheblich erhöht. Aber mehr dazu im nächsten Artikel.