Wir beschäftigen uns mit dem Kauf von Traffic von AdWords (einer Werbeplattform von Google). Eine der regelmäßigen Aufgaben in diesem Bereich ist die Erstellung neuer Banner. Tests zeigen, dass Banner mit der Zeit an Wirksamkeit verlieren, wenn sich Benutzer an das Banner gewöhnen. Jahreszeiten und Trends ändern sich. Darüber hinaus haben wir das Ziel, verschiedene Zielgruppennischen zu erfassen, und eng gezielte Banner funktionieren besser.
Im Zusammenhang mit der Einreise in neue Länder trat das Problem der Lokalisierung von Bannern auf. Für jedes Banner müssen Sie Versionen in verschiedenen Sprachen und mit verschiedenen Währungen erstellen. Sie können Designer bitten, dies zu tun, aber diese manuelle Arbeit erhöht eine zusätzliche Belastung für eine bereits knappe Ressource.
Es sieht aus wie eine Aufgabe, die einfach zu automatisieren ist. Zu diesem Zweck reicht es aus, ein Programm zu erstellen, das dem Banner einen lokalisierten Preis für das "Preisschild" auferlegt und auf der Schaltfläche zum Handeln aufruft (ein Satz wie "Jetzt kaufen"). Wenn das Drucken von Text in einem Bild einfach genug ist, ist es nicht immer trivial zu bestimmen, wo Sie ihn ablegen müssen. Pfefferkörner fügt hinzu, dass der Knopf in verschiedenen Farben und in einer etwas anderen Form erhältlich ist.
Dieser Artikel ist gewidmet: Wie finde ich das angegebene Objekt im Bild? Beliebte Methoden werden aussortiert; Anwendungsbereiche, Funktionen, Vor- und Nachteile. Die oben genannten Methoden können für andere Zwecke verwendet werden: Entwickeln von Programmen für Überwachungskameras, Automatisierung des Testens der Benutzeroberfläche und dergleichen. Die beschriebenen Schwierigkeiten treten bei anderen Aufgaben auf, und die verwendeten Methoden können für andere Zwecke verwendet werden. Beispielsweise wird der Canny Edge Detector häufig zur Vorverarbeitung von Bildern verwendet, und die Anzahl der Schlüsselpunkte kann zur Bewertung der visuellen „Komplexität“ eines Bildes verwendet werden.
Ich hoffe, dass die beschriebenen Lösungen Ihr Arsenal an Tools und Tricks zur Lösung von Problemen auffüllen.
Der Code befindet sich in Python 3.6 ( Repository ). OpenCV-Bibliothek erforderlich. Vom Leser wird erwartet, dass er die Grundlagen der linearen Algebra und des Computer-Sehens versteht.
Wir werden uns darauf konzentrieren, den Knopf selbst zu finden. Wir werden uns daran erinnern, Preisschilder zu finden (da das Finden eines Rechtecks auch auf einfachere Weise gelöst werden kann), aber lassen Sie es weg, da die Lösung genauso aussieht.
Vorlagenübereinstimmung
Der erste Gedanke, der mir in den Sinn kommt, ist, warum nicht einfach den Bereich auswählen und im Bild finden, der der Schaltfläche in Bezug auf den Pixelfarbunterschied am ähnlichsten ist. Dies macht den Vorlagenabgleich aus - eine Methode, die darauf basiert, Platz auf dem Bild zu finden, der der Vorlage am ähnlichsten ist. Die „Ähnlichkeit“ eines Bildes wird durch eine bestimmte Metrik definiert. Das heißt, die Vorlage wird dem Bild „überlagert“, und die Diskrepanz zwischen dem Bild und der Vorlage wird berücksichtigt. Die Position der Vorlage, an der diese Diskrepanz minimal ist, gibt die Position des gewünschten Objekts an.
Sie können verschiedene Optionen als Metrik verwenden, z. B. die Summe der quadratischen Unterschiede zwischen einer Vorlage und einem Bild (Summe der quadratischen Unterschiede, SSD) oder die Kreuzkorrelation (CCORR) verwenden. Sei f und g das Bild und Muster mit den Dimensionen (k, l) bzw. (m, n) (wir werden die Farbkanäle vorerst ignorieren); i, j - Position auf dem Bild, an das wir die Vorlage "angehängt" haben.
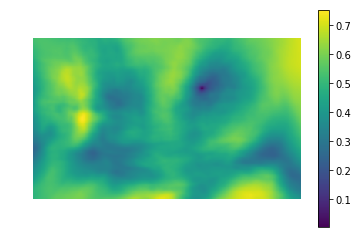
Versuchen wir, die Differenz der Quadrate anzuwenden, um ein Kätzchen zu finden

Auf dem Bild

(Foto von PETA Caring for Cats).
Das linke Bild ist der metrische Wert der Ähnlichkeit der Stelle im Bild mit der Vorlage (d. H. Die SSD-Werte für verschiedene i, j). Der dunkle Bereich ist der Ort, an dem der Unterschied minimal ist. Dies ist ein Zeiger auf die Stelle, die einer Vorlage am ähnlichsten ist - im rechten Bild ist diese Stelle eingekreist.

Kreuzkorrelation ist eigentlich eine Faltung zweier Bilder. Faltungen können mithilfe der schnellen Fourier-Transformation schnell implementiert werden. Nach dem Faltungssatz wird die Faltung nach der Fourier-Transformation zu einer einfachen elementweisen Multiplikation:
Wo - Faltungsoperator. Auf diese Weise können wir die Kreuzkorrelation schnell berechnen. Dies ergibt die Gesamtkomplexität von O (kllog (kl) + mnlog (mn)) gegenüber O (klmn) bei frontaler Implementierung. Das Quadrat der Differenz kann auch durch Faltung realisiert werden, da es nach dem Öffnen der Klammern zur Differenz zwischen der Summe der Quadrate der Pixelwerte des Bildes und der Kreuzkorrelation wird:
Details können in dieser Präsentation gesehen werden .
Fahren wir mit der Implementierung fort. Glücklicherweise haben sich Kollegen aus der Intel-Abteilung in Nischni Nowgorod um uns gekümmert, indem sie die OpenCV-Bibliothek erstellt haben. Sie implementiert bereits eine Vorlagensuche mit der matchTemplate-Methode (übrigens verwendet sie die Implementierung über FFT, obwohl dies in der Dokumentation nicht erwähnt wird), wobei unterschiedliche Diskrepanzmetriken verwendet wurden :
- CV_TM_SQDIFF - die Summe der Quadrate der Differenz der Pixelwerte
- CV_TM_SQDIFF_NORMED - die Summe des Quadrats der Farbunterschiede, normalisiert auf den Bereich 0..1.
- CV_TM_CCORR - die Summe der Element-für-Element-Produkte der Vorlage und des Bildsegments
- CV_TM_CCORR_NORMED - Die Summe der Elemente funktioniert, normalisiert auf den Bereich -1..1.
- CV_TM_CCOEFF - Kreuzkorrelation von Bildern ohne Durchschnitt
- CV_TM_CCOEFF_NORMED - Kreuzkorrelation zwischen Bildern ohne Durchschnitt, normalisiert auf -1..1 (Pearson-Korrelation)
Wir werden sie verwenden, um ein Kätzchen zu finden:

Es ist ersichtlich, dass nur TM_CCORR seine Aufgabe nicht bewältigte. Dies ist verständlich: Da es sich um ein skalares Produkt handelt, ist der größte Wert dieser Metrik der Vergleich einer Vorlage mit einem weißen Rechteck.
Möglicherweise stellen Sie fest, dass diese Metriken eine pixelweise Musterübereinstimmung im gewünschten Bild erfordern. Jede Abweichung von Gamma, Licht oder Größe führt dazu, dass die Methoden nicht funktionieren. Ich möchte Sie daran erinnern, dass dies genau unser Fall ist: Die Tasten können unterschiedliche Größen und Farben haben.
Das Problem unterschiedlicher Farben und Lichte kann durch Anwendung eines Kantenerkennungsfilters gelöst werden. Diese Methode hinterlässt nur Informationen darüber, wo im Bild scharfe Farbänderungen aufgetreten sind. Wenden wir Canny Edge Detector (wir werden es etwas weiter analysieren) auf Schaltflächen mit unterschiedlichen Farben und Helligkeiten an. Auf der linken Seite befinden sich die Originalbanner und auf der rechten Seite das Ergebnis der Anwendung des Canny-Filters.

In unserem Fall gibt es auch ein Problem unterschiedlicher Größe, das jedoch bereits behoben wurde. Die logarithmische Polarumwandlung verwandelt ein Bild in einen Raum, in dem Zoomen und Drehen als Versatz angezeigt werden. Mit dieser Transformation können wir Skalierung und Winkel wiederherstellen. Anschließend können Sie durch Skalieren und Drehen der Vorlage die Position der Vorlage im Originalbild ermitteln. Sie können während dieses Vorgangs auch FFT verwenden, wie unter Eine FFT-basierte Technik für die Übersetzung, Rotation und skalierungsinvariante Bildregistrierung beschrieben . In der Literatur wird der Fall betrachtet, wenn die horizontalen und vertikalen Muster proportional geändert werden, während der Skalierungsfaktor innerhalb kleiner Grenzen variiert (2,0 ... 0,8). Leider kann die Größenänderung einer Schaltfläche groß und unverhältnismäßig sein, was zu einem falschen Ergebnis führen kann.
Wir wenden die resultierende Konstruktion an (Canny-Filter, der nur die Skala durch die logarithmische Polartransformation wiederherstellt und die Position durch Finden des Ortes mit der minimalen quadratischen Diskrepanz erhält), um die Schaltfläche in drei Bildern zu finden. Wir werden den großen gelben Knopf als Vorlage verwenden:

Gleichzeitig haben die Schaltflächen auf den Bannern unterschiedliche Typen, Farben und Größen:

Bei der Größenänderung der Schaltfläche funktionierte die Methode nicht richtig. Dies liegt an der Tatsache, dass bei dieser Methode die Größe von Schaltflächen horizontal und vertikal gleich oft geändert wird. Dies ist jedoch nicht immer der Fall. Im rechten Bild hat sich die Größe der Schaltfläche nicht vertikal geändert, sondern horizontal stark verringert. Wenn die Größenänderung zu groß ist, machen die durch die logarithmische Polartransformation verursachten Verzerrungen die Suche instabil. In dieser Hinsicht konnte das Verfahren die Schaltfläche im dritten Fall nicht erkennen.
Schlüsselpunkterkennung
Sie können einen anderen Ansatz ausprobieren: Anstatt nach der gesamten Schaltfläche zu suchen, suchen wir nach den typischen Teilen, z. B. den Ecken der Schaltfläche oder den Randelementen (entlang der Schaltflächenkontur befindet sich ein dekorativer Strich). Es scheint, dass es einfacher ist, Ecken und einen Rand zu finden, da es sich um kleine (und daher einfache) Objekte handelt. Was zwischen den vier Ecken und dem Rand liegt, wird ein Knopf sein. Die Klasse von Methoden zum Auffinden von Schlüsselpunkten wird als "Schlüsselpunkterkennung" bezeichnet, und die Algorithmen zum Vergleichen und Suchen von Bildern unter Verwendung von Schlüsselpunkten werden als "Schlüsselpunktabgleich" bezeichnet. Beim Suchen nach einem Muster in einem Bild kommt es darauf an, einen Algorithmus zum Erkennen von Schlüsselpunkten auf ein Muster und ein Bild anzuwenden und Schlüsselpunkte eines Musters und eines Bildes zu vergleichen.
Normalerweise werden „Schlüsselpunkte“ automatisch gefunden, indem Pixel gefunden werden, deren Umgebung bestimmte Eigenschaften aufweist. Viele Methoden und Kriterien, um sie zu finden, wurden erfunden. Alle diese Algorithmen sind Heuristiken, die in der Regel einige charakteristische Bildelemente finden - Winkel oder scharfe Farbänderungen. Ein guter Detektor sollte schnell arbeiten und gegen Bildtransformationen resistent sein (beim Ändern des Bildes sollten wichtige Punkte nicht aufhören, sich zu bewegen).
Harris Eckendetektor
Einer der grundlegendsten Algorithmen ist der Harris-Eckendetektor . Für das Bild (im Folgenden wird angenommen, dass wir mit „Intensität“ arbeiten - einem in Graustufen übersetzten Bild) versucht er, Punkte zu finden, in deren Nähe die Intensitätsunterschiede größer als ein bestimmter Schwellenwert sind. Der Algorithmus sieht folgendermaßen aus:
Von der Intensität sind Ableitungen entlang der x- und y-Achse ( und jeweils). Sie können zum Beispiel durch Anwenden des Sobel-Filters gefunden werden.
Betrachten Sie für ein Pixel das Quadrat Quadrat und funktioniert und . Einige Quellen bezeichnen sie als , und - was keine Klarheit schafft, da man denken könnte, dass dies die zweiten Ableitungen der Intensität sind (und dies ist nicht so).
Für jedes Pixel betrachten wir die Summen in einer bestimmten Nachbarschaft (mehr als 1 Pixel) mit den folgenden Eigenschaften:
Wie bei der Vorlagenerkennung kann dieses Verfahren für große Fenster unter Verwendung des Faltungssatzes effizient ausgeführt werden.
Berechnen Sie für jedes Pixel den Wert Heuristik R.
Wert empirisch ausgewählt im Bereich [0,04, 0,06] If Einige Pixel haben eine bestimmte Schwelle, dann die Nachbarschaft Dieses Pixel enthält einen Winkel und wir markieren ihn als Schlüsselpunkt.
Mit der vorherigen Formel können Cluster von Schlüsselpunkten erstellt werden, die nebeneinander liegen. In diesem Fall lohnt es sich, sie zu entfernen. Dies kann erreicht werden, indem für jeden Punkt geprüft wird, ob er einen Wert hat Maximum unter unmittelbaren Nachbarn. Wenn nicht, wird der Schlüsselpunkt herausgefiltert. Diese Prozedur wird als nicht maximale Unterdrückung bezeichnet .
Formel so aus einem Grund gewählt. - Komponenten der strukturellen Tensormatrix, die das Verhalten des Gradienten in der Nachbarschaft beschreiben:
H = \ begin {pmatrix} A & C \\ C & B \ end {pmatrix}
Diese Matrix ähnelt in vielerlei Hinsicht ihrer Kovarianzmatrix. Zum Beispiel sind beide positiv semidefinite Matrizen, aber die Ähnlichkeit ist nicht darauf beschränkt. Ich möchte Sie daran erinnern, dass die Kovarianzmatrix eine geometrische Interpretation hat. Die Eigenvektoren der Kovarianzmatrix geben die Richtungen der größten Varianz der Quelldaten an (für die die Kovarianz berechnet wurde), und die Eigenwerte geben die Streuung entlang der Achse an:

Bild aufgenommen von http://www.visiondummy.com/2014/04/geometric-interpretation-covariance-matrix/
Ebenso verhalten sich die Eigenwerte des Strukturtensors: Sie beschreiben die Ausbreitung der Gradienten. Auf einer ebenen Fläche sind die Eigenwerte des Strukturtensors klein (weil die Streuung der Gradienten selbst gering ist). Die Eigenwerte des strukturellen Tensors, der auf einem Bildstück mit einer Fläche aufgebaut ist, variieren stark: Eine Zahl ist groß (und entspricht ihrem eigenen Vektor, der senkrecht zur Fläche gerichtet ist), und die zweite ist klein. Auf dem Winkeltensor sind beide Eigenwerte groß. Auf dieser Grundlage können wir eine Heuristik erstellen ( Sind die Eigenwerte des Strukturtensors).
Der Wert dieser Heuristik ist groß, wenn beide Eigenwerte groß sind.
Die Summe der Eigenwerte ist die Spur der Matrix, die als Summe der Elemente auf der Diagonale berechnet werden kann (und wenn Sie sich die Formeln A und B ansehen, wird klar, dass dies auch die Summe der Quadrate der Längen der Gradienten in der Region ist):
Das Produkt der Eigenwerte ist die Determinante einer Matrix, die auch bei 2x2 leicht zu schreiben ist:
Somit können wir effektiv berechnen und drückt es in Form der Komponenten des strukturellen Tensors aus.
Schnell
Harris 'Methode ist gut, aber es gibt viele Alternativen dazu. Wir werden nicht alles auf die gleiche Weise wie die obige Methode betrachten, wir werden nur einige beliebte erwähnen, um interessante Tricks zu zeigen und sie in Aktion zu vergleichen.

Vom FAST-Algorithmus verifizierte Pixel
Eine Alternative zu Harris 'Methode ist SCHNELL . Wie der Name schon sagt, ist FAST viel schneller als die oben beschriebene Methode. Dieser Algorithmus versucht, die Punkte zu finden, die an den Kanten und Ecken von Objekten liegen, d. H. an Orten mit Kontrastunterschied. Ihre Position ist wie folgt: FAST bildet einen Kreis mit dem Radius R um das Kandidatenpixel und prüft, ob es ein kontinuierliches Segment von Pixeln der Länge t aufweist, das um K Einheiten dunkler (oder heller) des Kandidatenpixels ist. Wenn diese Bedingung erfüllt ist, wird das Pixel als „Schlüsselpunkt“ betrachtet. Für bestimmte t können wir diese Heuristik effizient implementieren, indem wir einige vorläufige Überprüfungen hinzufügen, die Pixel abschneiden, die garantiert keine Ecken sind. Zum Beispiel wenn und Es reicht aus zu prüfen, ob es 3 aufeinanderfolgende Pixel unter den 4 extremen Pixeln gibt, die streng dunkler / heller als die Mitte auf K sind (im Bild - 1, 5, 9, 13). Diese Bedingung ermöglicht es Ihnen, Kandidaten effektiv abzuschneiden, die definitiv keine Schlüsselpunkte sind.
SIFT
Beide vorherigen Algorithmen sind nicht resistent gegen Bildgrößenänderung. Sie ermöglichen es Ihnen nicht, eine Vorlage im Bild zu finden, wenn der Maßstab des Objekts geändert wurde. SIFT (Scale-Invariant Feature Transform) bietet eine Lösung für dieses Problem. Nehmen Sie das Bild, aus dem wir die Schlüsselpunkte extrahieren, und beginnen Sie, seine Größe mit einem kleinen Schritt schrittweise zu verringern. Für jede Skalierungsoption finden wir die Schlüsselpunkte. Das Skalieren ist ein schwieriges Verfahren, aber das Reduzieren um 2/4/8 / ... kann effizient durch Überspringen von Pixeln erfolgen (in SIFT werden diese mehreren Skalierungen als "Oktaven" bezeichnet). Zwischenskalen können durch Anwenden eines Gaußschen Blaus mit einer anderen Kerngröße auf das Bild angenähert werden. Wie oben beschrieben, kann dies rechnerisch effizient durchgeführt werden. Das Ergebnis sieht so aus, als hätten wir das Bild zuerst verkleinert und dann auf seine ursprüngliche Größe vergrößert - kleine Details gehen verloren, das Bild wird „unscharf“.
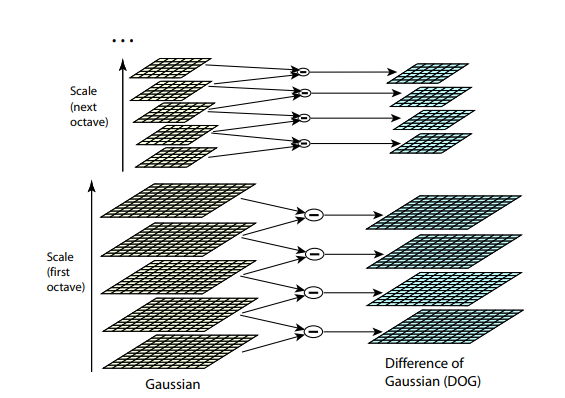
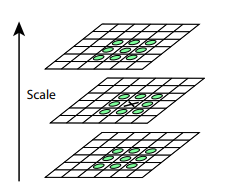
Nach diesem Verfahren berechnen wir die Differenz zwischen benachbarten Skalen. Große (in absoluten Werten) Werte in dieser Differenz werden sich herausstellen, wenn einige kleine Details auf der nächsten Skalenebene nicht mehr sichtbar sind oder umgekehrt die nächste Skalenebene beginnt, einen Teil zu erfassen, der auf der vorherigen nicht sichtbar war. Diese Technik heißt DoG, Difference of Gaussian. Wir können davon ausgehen, dass die große Bedeutung dieses Unterschieds bereits ein Signal dafür ist, dass an dieser Stelle auf dem Bild etwas Interessantes ist. Wir sind jedoch an der Skala interessiert, für die dieser Schlüsselpunkt am aussagekräftigsten sein wird. Zu diesem Zweck betrachten wir einen Schlüsselpunkt nicht nur als einen Punkt, der sich von seiner Umgebung unterscheidet, sondern sich auch am stärksten zwischen verschiedenen Bildskalen unterscheidet. Mit anderen Worten, wir werden einen Schlüsselpunkt nicht nur im Raum X und Y, sondern auch im Raum auswählen . In SIFT erfolgt dies durch Auffinden von Punkten im DoG (Differenz der Gaußschen), bei denen es sich um lokale Hochs oder Tiefs handelt Raumwürfel um sie herum:
Algorithmen zum Auffinden von Schlüsselpunkten und zum Erstellen von SIFT- und SURF-Deskriptoren sind patentiert. Das heißt, für ihre kommerzielle Nutzung ist es erforderlich, eine Lizenz zu erhalten. Aus diesem Grund sind sie nicht im Hauptpaket opencv verfügbar, sondern nur in einem separaten Paket opencv_contrib. Bisher ist unsere Forschung jedoch rein akademischer Natur, daher hindert uns nichts daran, im Vergleich zum SIFT teilzunehmen.
Deskriptoren
Versuchen wir, eine Art Detektor (z. B. Harris) auf die Vorlage und das Bild anzuwenden.


Nachdem Sie die wichtigsten Punkte im Bild und in der Vorlage gefunden haben, müssen Sie sie irgendwie miteinander vergleichen. Ich möchte Sie daran erinnern, dass wir bisher nur die Positionen der wichtigsten Punkte extrahiert haben. Was dieser Punkt bedeutet (zum Beispiel, in welche Richtung der gefundene Winkel gerichtet ist), haben wir noch nicht bestimmt. Eine solche Beschreibung kann beim Vergleich von Bildpunkten und Mustern hilfreich sein. Einige der Punkte der Vorlage im Bild können durch Verzerrungen verschoben werden, die von anderen Objekten abgedeckt werden. Daher scheint es unzuverlässig, sich nur auf die Position der Punkte relativ zueinander zu verlassen. Nehmen wir daher für jeden Schlüsselpunkt eine Nachbarschaft, um eine bestimmte Beschreibung (Deskriptor) zu erstellen, die es uns dann ermöglicht, einige Punkte (einen Punkt aus der Vorlage, einen aus dem Bild) zu nehmen und ihre Ähnlichkeit zu vergleichen.
KURZ
(.. 0 1), , XOR , . ? , N . , i- , , — i- 1. N. - (, — ), : , “”. , ( ). BRIEF .

. . , GII .
, , (.. , , ). OpenCV .
SIFT
SIFT , . SIFT 1616 , 44 . ( , ). 8 (, -, , ..). — 8 , , . . , 8- . 128 ( 4*4 = 16 , 8 ). .
Vergleich
( — , ), - :

— . ?
, . , , . , , , , . ? BRIEF, , , . , BRIEF 1/16 . SIFT — - 1/4 .
SIFT.
Jetzt wenden wir das gesamte erworbene Wissen an, um unser Problem zu lösen. In unserem Fall reichen die Anforderungen an den Schlüsselpunktdetektor aus: Wir benötigen keine Invarianz zum Ändern der Größe sowie eine extrem hohe Leistung. Vergleichen Sie alle drei Detektoren.
| Harris Eckendetektor | Schnell | SIFT |
|---|
 |  |  |
 |  |  |
 |  |  |
SIFT hat extrem wenige wichtige Punkte auf der Schaltfläche gefunden. Dies ist verständlich - die Schaltfläche ist ein ziemlich kleines und flaches Objekt, und das Zoomen hilft nicht, wichtige Punkte zu finden.
Auch kein einziger Detektor schaffte den dritten Fall. Dies ist erklärbar und wird erwartet. In der Regel werden die oben genannten Methoden verwendet, um ein Objekt aus einer Vorlage in einem Bild zu finden, in dem es teilweise ausgeblendet, gedreht oder leicht verzerrt sein kann. In unserem Fall möchten wir nicht genau dasselbe Objekt finden , sondern ein Objekt, das der Vorlage (Schaltfläche) sehr ähnlich ist . Dies ist eine etwas andere Aufgabe. Wenn Sie also die Form der Schaltfläche selbst ändern (z. B. den Radius der Eckenrundung oder die Dicke des Punktrahmens), werden die wichtigsten Punkte in ihnen und ihre Deskriptoren geändert. Darüber hinaus befinden sich wichtige Punkte an der Ecke der Schaltfläche. Aufgrund der Position am Rand sind die Punkte instabil: Ihre genaue Position und ihre Deskriptoren werden durch das beeinflusst, was neben der Schaltfläche gezeichnet wird.
Schlussfolgerung - Die Methode ist gut und erfüllt Situationen korrekt, in denen das gewünschte Objekt gedreht, seine Größe geändert oder das Objekt teilweise ausgeblendet wird (was beispielsweise zum Auffinden komplexer Objekte oder eines Preisschilds geeignet ist). Wenn sich jedoch nur wenige Punkte auf dem Objekt befinden, die „eingefangen“ werden können, oder wenn sich die Form des Objekts zu stark ändert, stimmen die wichtigsten Punkte und diese auf der Vorlage und dem Bild möglicherweise nicht überein. Ein Hintergrund mit vielen kleinen Details kann auch die "Schlüsselpunkte" verschieben oder ihre Deskriptoren ändern.
Wir können eine Übereinstimmung finden, die die Koordinaten der Schlüsselpunkte verwendet. Anstatt nach Punktpaaren auf der Vorlage und dem Bild zu suchen, deren Nachbarschaft ähnlich ist, können Sie nach solchen Punktmengen suchen. Die Interposition der wichtigsten Punkte auf der Vorlage und dem Bild ist ähnlich. Im allgemeinen Fall ist dies eine ziemlich komplizierte Aufgabe (sowohl rechnerisch als auch programmtechnisch), insbesondere in einer Situation, in der einige Punkte verschoben sein können oder fehlen. Da wir jedoch Schlüsselpunkte - Winkel - haben, reicht es für uns, Gruppen zu finden, die ungefähr ein Rechteck mit den gewünschten Proportionen bilden und in denen es keine Schlüsselpunkte gibt. Allmählich kommen wir zu folgender Methode:
Konturerkennung
Normalerweise ist eine Schaltfläche eine Art rechteckiges Objekt (manchmal mit abgerundeten Ecken), dessen Seiten parallel zu den Koordinatenachsen sind. Versuchen wir dann, die Kontrastdifferenzzonen (Kanten) zu unterscheiden, und unter ihnen finden wir Gesichter, deren Umrisse dem Umriss des benötigten Objekts ähnlich sind. Diese Methode wird als Konturerkennung bezeichnet.
Kantenerkennung
Im Gegensatz zur Schlüsselpunkterkennung interessieren uns nicht nur wichtige Punktwinkel, sondern auch Kanten. Die Grundideen können wir jedoch von dort übernehmen. Glätten Sie das Bild mit einem Gaußschen Filter und wie im Harris-Eckendetektor. Dann berechnen wir die Ableitungen der Intensität und . Da wir keine Winkel von Kanten unterscheiden müssen, müssen wir den strukturellen Tensor nicht berücksichtigen - es reicht aus, die Stärke des Gradienten zu berechnen: (Übrigens ist dies die Wurzel von oder aus der Summe der Diagonale des Strukturtensors). Danach belassen wir nur Pixel, die in Bezug auf lokale Maxima sind (unter Verwendung der bereits berücksichtigten nicht maximalen Unterdrückung), aber als Gebietsschema werden wir nicht 8 benachbarte Pixel auswählen, sondern die Pixel aus diesen 8, auf die ich gerichtet bin, und von der gegenüberliegenden Seite:
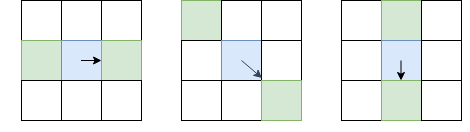
Das betreffende Pixel ist blau, der Pfeil ist Richtung I. Die grünen Pixel sind diejenigen, die bei nicht maximaler Unterdrückung berücksichtigt werden.
Eine solch ungewöhnliche Auswahl von Pixeln zum Vergleich ist darauf zurückzuführen, dass wir keine Lücken im Rand machen wollen. Im linken Bild geht das Gesicht von oben nach unten, und da die nicht maximale Unterdrückung die Intensitäten nicht mit Pixeln über und unter Blau vergleicht, erhalten wir ein kontinuierliches Gesicht.
Offensichtlich reicht eine nicht maximale Unterdrückung nicht aus, und Sie müssen eine Art Filterung anwenden, um Kanten mit zu niedrigem Il zu entfernen. Dazu wenden wir die Technik des „doppelten Schwellenwerts“ an: Wir entfernen alle Pixel mit Il mit einer Gradientenstärke unterhalb des unteren Schwellenwerts und weisen alle Pixel oberhalb des hohen Schwellenwerts „starken Kanten“ zu. Pixel, bei denen die Gradientenstärke zwischen niedrig und hoch liegt, werden als "schwache Kanten" bezeichnet. Wir belassen sie nur, wenn sie mit "starken Kanten" verbunden sind:
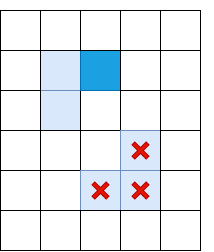
Hellblau zeigt "schwache Rippen" an, dunkelblau - stark. Die Rippen im unteren Teil werden herausgesiebt, da sie mit keiner starken Rippe verbunden sind.
Wir haben gerade Canny Edge Detector beschrieben. Es wird bis heute sehr häufig als einfaches und schnelles Verfahren verwendet, mit dem Sie die Konturen von Objekten finden können.
Grenzverfolgung
Die nächste Aktion besteht darin, die Konturen auf der Karte mit den gefundenen Flächen auszuwählen. Suchen Sie die zugehörigen Komponenten (Inseln benachbarter Pixel, die alle Prüfungen bestanden haben) und überprüfen Sie jeweils, wie sehr sie wie eine Schaltfläche aussehen. Nachdem wir in Canny eine nicht maximale Unterdrückung angewendet haben, haben wir Garantien, dass die Kanten ein Pixel dick sind, aber verlassen wir uns darauf. Für jedes Pixel, das einem Gesicht zugewiesen wurde und neben dem sich ein Nicht-Gesichtspixel befindet, weisen wir es einem „Rand“ zu. Wenn wir uns von einem Pixel des Randes zum anderen bewegen, kehren wir entweder zum selben Pixel zurück (und dann haben wir den Pfad gefunden) oder zu einer Sackgasse (dann können Sie versuchen, zurückzukehren, wenn sich irgendwo auf dem Weg eine Gabelung befand):

Hier wird der vollständige Randverfolgungsalgorithmus beschrieben, der verschiedene Kantenfälle berücksichtigt (z. B. wenn ein Objekt mit einer dicken Fläche zwei interne und externe Konturen erzeugt). Nach der Anwendung dieses Algorithmus haben wir eine Reihe von Konturen, die möglicherweise Schaltflächen sein können.
Pfadfilterung
Woher wissen wir, dass unsere Schaltung ein Knopf ist? Für Rechtecke und Polygone gibt es eine hervorragende Methode, die auf der Vereinfachung des Umrisses basiert. Es reicht aus, die Rippen allmählich zu „kollabieren“, wenn sie sich fast auf einer geraden Linie befinden, und dann die Anzahl der verbleibenden Rippen zu berechnen und die Winkel zwischen ihnen zu überprüfen. Leider sind diese Methoden für unseren Fall nicht geeignet - unser Rechteck hat abgerundete Ecken. Es gibt auch eine Konturanpassung für Figuren mit komplexer Geometrie - aber es geht auch nicht um uns, da wir nur ein Rechteck haben (Beispiele mit einem menschlichen Umriss finden Sie im Artikel). Daher ist es besser, einen Filter basierend auf den Eigenschaften der Figur selbst zu erstellen. Wir wissen das:
- Die Schaltfläche ist groß genug (Bereich über 100 Pixel)
- Die Seiten sind parallel zu den Koordinatenachsen
- Das Verhältnis der Fläche der Figur zur Fläche des Begrenzungsrechtecks sollte ziemlich nahe an der Einheit liegen. Wir setzen den Schwellenwert auf 0,8, da die Schaltfläche ein Rechteck mit Seiten parallel zu den Koordinatenachsen ist und die fehlenden 20% die abgerundeten Ecken sind.
Aufgrund der Erfahrung mit Schlüsselpunktdetektoren erinnern wir uns außerdem daran, dass es Probleme mit Situationen geben kann, in denen sich ein Kontrastobjekt unter der Schaltfläche befindet. Daher verwischen wir nach dem Auftragen von Canny die Kanten, um kleine Löcher zu schließen, die aus solchen Objekten entstehen können.
Wir wenden den resultierenden Ansatz an:

Die Canny-Filteranwendung (Bild 2) fand die erforderliche Form, aber aufgrund der komplexen Form der Schaltfläche und des Verlaufs wurden viele Konturen gleichzeitig gefunden, und aufgrund der nicht maximalen Unterdrückung wurden einige von ihnen nicht geschlossen. Durch Anwenden von Unschärfe (3 Bilder) wurde das Problem behoben.
Testansatz
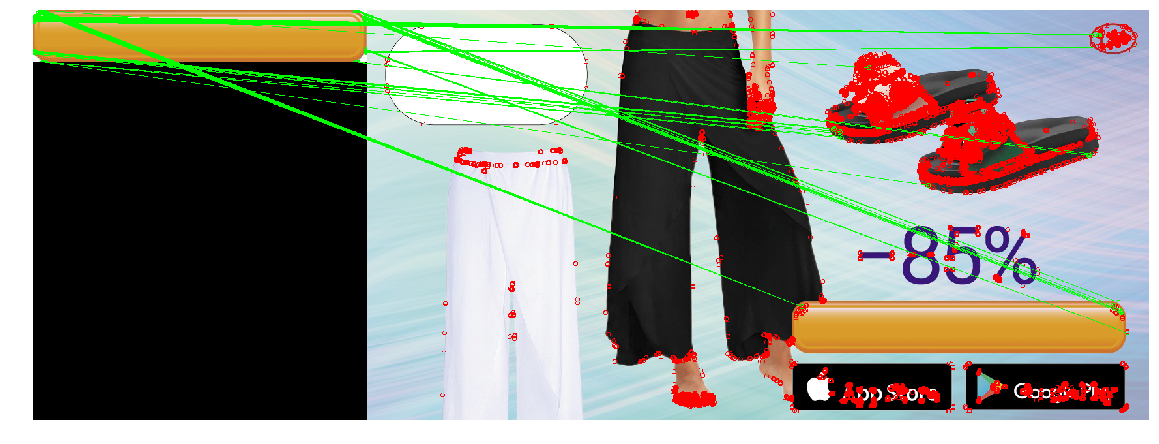
Führen Sie die Suche nach Konturen im resultierenden Bild aus. Färben Sie die Konturen, die den Test bestanden haben, rot. Wenn es mehrere davon gibt, müssen wir die erfolgreichste Option unter ihnen auswählen. Wir wählen den Umriss des größten Bereichs aus und malen ihn grün.
|  |
|  |
|  |
|
Das resultierende Design fand Schaltflächen auf Testbildern. Ein Lauf auf allen Bannern zeigte, dass gelegentlich (1 Fall von ~ 20) anstelle einer Schaltfläche rechteckige Kacheln von iOS Appstore und Google Apps oder andere rechteckige Objekte (Telefonhüllen) ausgewählt werden. Aus diesem Grund haben wir diese Option im Lokalisierungstool implementiert, indem wir die Möglichkeit hinzugefügt haben, die Position in diesem seltenen Fall einer falschen Bestimmung manuell anzugeben.
Fazit
Zusammenfassend. Der „klassische“ Lebenslauf ohne tiefes Lernen funktioniert immer noch und basierend darauf können Sie Probleme lösen. Sie sind unprätentiös und erfordern keine große Menge an markierten Daten, leistungsstarke Hardware und sind einfacher zu debuggen. Sie führen jedoch zusätzliche Annahmen ein, und daher kann mit ihrer Hilfe nicht jedes Problem effektiv gelöst werden.
- Der Vorlagenabgleich ist der einfachste Weg, indem Sie eine Stelle im Bild finden, die einer Vorlage am ähnlichsten ist (durch eine einfache Metrik). Wirksam bei pixelweiser Anpassung. Es kann widerstandsfähig gegen Biegungen und kleine Größenänderungen gemacht werden, aber bei großen Änderungen funktioniert es möglicherweise nicht richtig.
- Schlüsselpunkterkennung / -anpassung - Finden Sie die wichtigsten Punkte, passen Sie die Punkte des Bildes und der Vorlage an. Die Detektoren sind resistent gegen Rotationen, Zoomen (abhängig vom ausgewählten Detektor und Deskriptor) und Anpassen - an teilweise Überlappungen. Diese Methode funktioniert jedoch nur dann gut, wenn das Objekt genügend „Schlüsselpunkte“ enthält und die Gebietsschemas der Vorlage und der Bildpunkte recht gut übereinstimmen (dh dasselbe Objekt auf der Vorlage und dem Bild).
- Konturerkennung - Finden der Konturen von Objekten und Finden einer Kontur ähnlich der Kontur des gewünschten Objekts. Diese Lösung berücksichtigt nur die Form des Objekts und ignoriert dessen Inhalt und Farbe (die sowohl ein Plus als auch ein Minus sein können).
Ein sachkundiger Leser kann feststellen, dass unser Problem mit Hilfe moderner geschulter Computer-Vision-Methoden gelöst werden kann. Zum Beispiel gibt das YOLO- Netzwerk den Begrenzungsrahmen des gewünschten Objekts zurück - und das interessiert uns. Ja, wir haben erfolgreich eine Lösung getestet und gestartet, die auf Deep Learning basiert - aber als zweite Iteration (bereits nachdem das Lokalisierungstool gestartet wurde und funktioniert hat). Diese Lösungen sind widerstandsfähiger gegen Änderungen der Schaltflächenparameter und haben viele positive Eigenschaften: Anstatt beispielsweise Schwellenwerte und Parameter mit den Händen zu erfassen, können Sie dem Trainingssatz einfach Beispiele für Banner hinzufügen, auf denen sich das Netzwerk irrt (Active Learning). Deep Learning für unsere Aufgabe zu nutzen, hat seine Probleme und interessanten Punkte. Beispielsweise erfordern viele moderne Computer-Vision-Methoden eine große Anzahl von markierten Bildern, aber wir hatten kein Markup (wie in vielen realen Fällen), und die Gesamtzahl der verschiedenen Banner überschreitet nicht mehrere Tausend. Aus diesem Grund haben wir uns entschlossen, eine kleine Anzahl von Bildern selbst zu erstellen und einen Generator zu schreiben, der auf ihrer Basis andere ähnliche Banner erstellt. In dieser Richtung gibt es viele interessante Tricks . Es gibt viele andere Fallstricke, und die eigentliche Aufgabe, die Position eines Computer-Vision-Objekts zu bestimmen, ist umfangreich und hat viele Lösungen. Daher wurde beschlossen, das Sichtfeld des Artikels einzuschränken, und Entscheidungen, die auf tiefem Lernen beruhten, wurden nicht berücksichtigt.
Code mit Notizblöcken, die die beschriebenen Methoden implementieren und Bilder des Artikels zeichnen, finden Sie im Repository .