
Die moderne Welt ist ohne den Einsatz verteilter Systeme einfach nicht denkbar. Selbst die einfachste mobile Anwendung verfügt über eine API, über die eine Verbindung zum Cloud-Speicher hergestellt wird. Der Entwurf verteilter Systeme ist jedoch immer noch eine Kunst, keine exakte Wissenschaft. Die Notwendigkeit, eine ernsthafte Grundlage zu schaffen, ist längst überfällig. Wenn Sie Vertrauen in die Erstellung, Unterstützung und den Betrieb verteilter Systeme gewinnen möchten, beginnen Sie mit diesem Buch!
Brendan Burns, ein renommierter Spezialist für Cloud-Technologien und Kubernetes, legt in dieser kleinen Arbeit das absolute Minimum fest, das für das ordnungsgemäße Design verteilter Systeme erforderlich ist. Dieses Buch beschreibt die zeitlosen Muster beim Entwerfen verteilter Systeme. Es wird Ihnen helfen, solche Systeme nicht nur von Grund auf neu zu erstellen, sondern auch vorhandene Systeme effektiv zu konvertieren.
Auszug. Dekorateur Muster. Konvertieren Sie eine Anfrage oder Antwort
FaaS ist ideal, wenn Sie einfache Funktionen benötigen, die Eingabedaten verarbeiten und dann an andere Dienste übertragen. Diese Art von Muster kann verwendet werden, um HTTP-Anforderungen zu erweitern oder zu dekorieren, die von einem anderen Dienst gesendet oder empfangen werden. Dieses Muster ist schematisch in Fig. 1 gezeigt. 8.1.
In Programmiersprachen gibt es übrigens mehrere Analogien zu diesem Muster. Insbesondere verfügt Python über Funktionsdekoratoren, die den Anforderungs- oder Antwortdekoratoren funktional ähnlich sind. Da Dekorationstransformationen keinen Status speichern und bei der Entwicklung des Dienstes häufig ex-facto hinzugefügt werden, eignen sie sich ideal für die Implementierung als FaaS. Darüber hinaus bedeutet die FaaS-Leichtigkeit, dass Sie mit verschiedenen Dekorateuren experimentieren können, bis Sie einen finden, der sich besser in den Service einfügt.
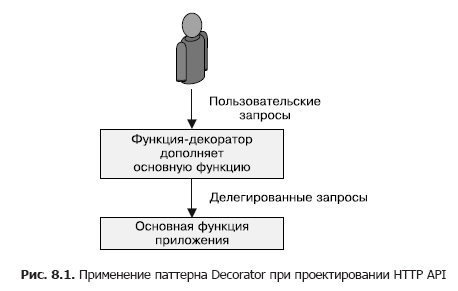
Das Hinzufügen von Standardwerten zu den Eingabeparametern von HTTP-RESTful-API-Anforderungen zeigt die Vorteile des Decorator-Musters. Viele API-Anforderungen enthalten Felder, die mit angemessenen Werten ausgefüllt werden müssen, wenn sie nicht vom Aufrufer angegeben wurden. Sie möchten beispielsweise, dass das Feld standardmäßig auf true gesetzt ist. Dies ist mit klassischem JSON schwierig zu erreichen, da das standardmäßige leere Feld null ist, was normalerweise als falsch interpretiert wird. Um dieses Problem zu lösen, können Sie die Logik des Ersetzens von Standardwerten entweder vor dem API-Server oder im Anwendungscode hinzufügen (z. B. if (field == null) field = true). Beide Ansätze sind jedoch nicht optimal, da der Standardsubstitutionsmechanismus konzeptionell unabhängig von der Anforderungsverarbeitung ist. Stattdessen können wir das FaaS Decorator-Muster verwenden, das die Anforderung auf dem Weg zwischen dem Benutzer und der Service-Implementierung transformiert.
In Anbetracht dessen, was weiter oben im Abschnitt über Einzelknotenmuster gesagt wurde, fragen Sie sich möglicherweise, warum wir den Standardsubstitutionsdienst nicht in Form eines Adaptercontainers entworfen haben. Dieser Ansatz ist sinnvoll, bedeutet aber auch, dass die Skalierung des Standard-Suchdienstes und die Skalierung des API-Dienstes selbst voneinander abhängig werden. Das Ersetzen von Standardwerten ist eine rechnerisch einfache Operation, für die Sie höchstwahrscheinlich nicht viele Instanzen des Dienstes benötigen.
In den Beispielen in diesem Kapitel verwenden wir das kubeless FaaS-Framework (https://github.com/kubeless/kubeless). Kubeless wird zusätzlich zum Kubernetes Container Orchestrator-Dienst bereitgestellt. Wenn Sie den Kubernetes-Cluster bereits vorbereitet haben, fahren Sie mit der Installation von Kubeless fort, die von der entsprechenden Site (https://github.com/kubeless/kubeless/releases) heruntergeladen werden kann. Sobald Sie die ausführbare Datei kubeless haben, können Sie sie mit dem Befehl kubeless install im Cluster installieren.
Kubeless wird als Kubernetes API-Add-On eines Drittanbieters installiert. Dies bedeutet, dass es nach der Installation als Teil des Befehlszeilentools kubectl verwendet werden kann. Beispielsweise können die im Cluster bereitgestellten Funktionen durch Ausführen des Befehls kubectl get functions angezeigt werden. Derzeit sind in Ihrem Cluster keine Funktionen bereitgestellt.
Werkstatt Ersetzen von Standardwerten vor der Anforderungsverarbeitung
Sie können die Nützlichkeit des Decorator-Musters in FaaS am Beispiel des Ersetzens von Standardwerten in einem RESTful-Aufruf durch Parameter demonstrieren, deren Werte nicht vom Benutzer festgelegt wurden. Mit FaaS ist das ganz einfach. Die Standard-Suchfunktion ist in Python geschrieben:
# -, # def handler(context): # obj = context.json # "name" , # if obj.get("name", None) is None: obj["name"] = random_name() # 'color', # 'blue' if obj.get("color", None) is None: obj["color"] = "blue" # API- # # return call_my_api(obj)
Speichern Sie diese Funktion in einer Datei namens defaults.py. Denken Sie daran, den Aufruf call_my_api durch die gewünschte API zu ersetzen. Diese Standardsubstitutionsfunktion kann mit dem folgenden Befehl als kubeless-Funktion registriert werden:
kubeless function deploy add-defaults \ --runtime python27 \ --handler defaults.handler \ --from-file defaults.py \ --trigger-http
Zum Testen können Sie das kubeless-Tool verwenden:
kubeless function call add-defaults --data '{"name": "foo"}'
Das Decorator-Muster zeigt, wie einfach es ist, vorhandene APIs anzupassen und um zusätzliche Funktionen wie das Überprüfen oder Ersetzen von Standardwerten zu erweitern.
Ereignisbehandlung
Die meisten Systeme sind abfrageorientiert - sie verarbeiten kontinuierliche Flüsse von Benutzer- und API-Anforderungen. Trotzdem gibt es einige ereignisorientierte Systeme. Der Unterschied zwischen der Anfrage und dem Ereignis scheint mir im Konzept der Sitzung zu liegen. Anfragen sind Teil eines größeren Interaktionsprozesses (Sitzung). Im allgemeinen Fall ist jede Benutzeranforderung Teil des Interaktionsprozesses mit einer Webanwendung oder der API als Ganzes. Ich sehe Ereignisse als "einmaliger", asynchroner Natur. Ereignisse sind wichtig und sollten entsprechend behandelt werden, aber sie werden aus dem Hauptkontext der Interaktion herausgerissen und die Antwort darauf kommt erst nach einiger Zeit. Ein Beispiel für ein Ereignis ist das Abonnement eines Benutzers für einen bestimmten Dienst, wodurch ein Begrüßungsschreiben gesendet wird. Hochladen einer Datei in einen freigegebenen Ordner, wodurch Benachrichtigungen an alle Benutzer dieses Ordners gesendet werden; oder sogar den Computer auf einen Neustart vorzubereiten, der den Bediener oder das automatisierte System darüber informiert, dass geeignete Maßnahmen erforderlich sind.
Da diese Ereignisse weitgehend unabhängig sind und keinen internen Zustand haben und ihre Häufigkeit sehr variabel ist, eignen sie sich ideal für die Arbeit in ereignisorientierten FaaS-Architekturen. Sie werden häufig neben dem "Battle" -Anwendungsserver bereitgestellt, um zusätzliche Funktionen bereitzustellen oder um Daten im Hintergrund als Reaktion auf neu auftretende Ereignisse zu verarbeiten. Da dem Service ständig neue Arten von verarbeiteten Ereignissen hinzugefügt werden, sind sie aufgrund der Einfachheit der Funktionsbereitstellung für die Implementierung von Ereignishandlern geeignet. Und da jedes Ereignis konzeptionell unabhängig von den anderen ist, können wir durch die erzwungene Schwächung der Beziehungen innerhalb eines auf Funktionen basierenden Systems seine konzeptionelle Komplexität reduzieren, sodass sich der Entwickler auf die Schritte konzentrieren kann, die zur Verarbeitung nur eines bestimmten Ereignistyps erforderlich sind.
Ein spezielles Beispiel für die Integration einer ereignisorientierten Komponente in einen vorhandenen Service ist die Implementierung der Zwei-Faktor-Authentifizierung. In diesem Fall ist das Ereignis die Anmeldung des Benutzers. Ein Dienst kann ein Ereignis für diese Aktion generieren und an eine Handlerfunktion übergeben. Der Prozessor sendet ihm auf der Grundlage des übertragenen Codes und der Kontaktdaten des Benutzers einen Authentifizierungscode in Form einer Textnachricht.
Werkstatt Implementierung der Zwei-Faktor-Authentifizierung
Die Zwei-Faktor-Authentifizierung zeigt an, dass der Benutzer zum Betreten des Systems etwas benötigt, das er kennt (z. B. ein Kennwort), und etwas, das er hat (z. B. eine Telefonnummer). Die Zwei-Faktor-Authentifizierung ist viel besser als nur ein Passwort, da ein Angreifer sowohl Ihr Passwort als auch Ihre Telefonnummer stehlen muss, um Zugriff zu erhalten.
Wenn Sie die Implementierung der Zwei-Faktor-Authentifizierung planen, müssen Sie eine Anforderung zum Generieren eines Zufallscodes verarbeiten, beim Anmeldedienst registrieren und eine Nachricht an den Benutzer senden. Sie können Code, der diese Funktionalität implementiert, direkt in den Anmeldedienst selbst einfügen. Dies kompliziert das System und macht es monolithischer. Das Senden einer Nachricht sollte gleichzeitig mit dem Code erfolgen, der die Anmeldewebseite generiert, was zu einer gewissen Verzögerung führen kann. Diese Verzögerung verschlechtert die Qualität der Benutzerinteraktion mit dem System.
Es ist besser, einen FaaS-Dienst zu erstellen, der asynchron eine Zufallszahl generiert, diese beim Anmeldedienst registriert und an das Telefon des Benutzers sendet. Somit kann der Anmeldeserver einfach eine asynchrone Anforderung an den FaaS-Dienst ausführen, die parallel die relativ langsame Aufgabe des Registrierens und Sendens des Codes ausführt.
Beachten Sie den folgenden Code, um zu sehen, wie dies funktioniert:
def two_factor(context): # code = random.randint(1 00000, 9 99999) # user = context.json["user"] register_code_with_login_service(user, code) # Twillio account = "my-account-sid" token = "my-token" client = twilio.rest.Client(account, token) user_number = context.json["phoneNumber"] msg = ", {}, : {}.".format(user, code) message = client.api.account.messages.create(to=user_number, from_="+1 20652 51212", body=msg) return {"status": "ok"}
Dann registrieren Sie FaaS in kubeless:
kubeless function deploy add-two-factor \ --runtime python27 \ --handler two_factor.two_factor \ --from-file two_factor.py \ --trigger-http
Eine Instanz dieser Funktion kann asynchron aus clientseitigem JavaScript-Code generiert werden, nachdem der Benutzer das richtige Kennwort eingegeben hat. Die Weboberfläche kann sofort die Seite zur Eingabe des Codes anzeigen, und der Benutzer kann ihn, sobald er den Code erhält, über den Anmeldedienst informieren, bei dem dieser Code bereits registriert ist.
Der FaaS-Ansatz hat die Entwicklung eines einfachen, asynchronen, ereignisorientierten Dienstes, der initiiert wird, wenn sich ein Benutzer am System anmeldet, erheblich erleichtert.
Eventförderer
Es gibt eine Reihe von Anwendungen, die in der Tat leichter als Pipeline lose gekoppelter Ereignisse zu betrachten sind. Ereignis-Pipelines ähneln oft den guten alten Flussdiagrammen. Sie können als gerichteter Graph der Synchronisation verwandter Ereignisse dargestellt werden. Im Rahmen des Ereignis-Pipeline-Musters entsprechen Knoten Funktionen, und die sie verbindenden Bögen entsprechen HTTP-Anforderungen oder anderen Arten von Netzwerkaufrufen.
Zwischen den Elementen des Containers gibt es in der Regel keinen gemeinsamen Zustand, es kann jedoch einen gemeinsamen Kontext oder einen anderen Bezugspunkt geben, auf dessen Grundlage die Suche im Speicher durchgeführt wird.
Was ist der Unterschied zwischen einer solchen Pipeline- und einer Microservice-Architektur? Es gibt zwei wichtige Unterschiede. Der erste und wichtigste Unterschied zwischen Servicefunktionen und ständig laufenden Services besteht darin, dass Ereignis-Pipelines im Wesentlichen ereignisgesteuert sind. Im Gegensatz dazu impliziert die Microservice-Architektur eine Reihe von ständig funktionierenden Services. Darüber hinaus können Ereignis-Pipelines asynchron sein und eine Vielzahl von Ereignissen binden. Es ist schwer vorstellbar, wie die Antragsgenehmigung von Jira in eine Microservice-Anwendung integriert werden kann. Gleichzeitig ist es leicht vorstellbar, wie es in die Ereignis-Pipeline integriert wird.
Betrachten Sie als Beispiel eine Pipeline, in der das Quellereignis das Laden von Code in ein Versionskontrollsystem ist. Dieses Ereignis führt zu einer Neuerstellung des Codes. Die Montage kann einige Minuten dauern. Danach wird ein Ereignis generiert, das die Testfunktion der zusammengesetzten Anwendung auslöst. Abhängig vom Erfolg der Montage führt die Testfunktion unterschiedliche Aktionen aus. Wenn die Montage erfolgreich war, wird eine Anwendung erstellt, die von der Person genehmigt werden muss, damit die neue Version der Anwendung in Betrieb genommen werden kann. Das Schließen der Anwendung dient als Signal für die Inbetriebnahme der neuen Version. Wenn die Assembly fehlgeschlagen ist, fordert Jira den erkannten Fehler an und die Pipeline wird beendet.
Werkstatt Implementieren einer Pipeline zum Registrieren eines neuen Benutzers
Betrachten Sie die Aufgabe, eine Folge von Aktionen zum Registrieren eines neuen Benutzers zu implementieren. Beim Erstellen eines neuen Kontos werden immer eine ganze Reihe von Aktionen ausgeführt, z. B. das Senden einer Begrüßungs-E-Mail. Es gibt auch eine Reihe von Aktionen, die möglicherweise nicht jedes Mal ausgeführt werden, z. B. das Abonnieren eines E-Mail-Newsletters über neue Versionen eines Produkts (auch als Spam bezeichnet).
Ein Ansatz besteht darin, einen monolithischen Dienst zum Erstellen neuer Konten zu erstellen. Bei diesem Ansatz ist ein Entwicklungsteam für den gesamten Service verantwortlich, der auch als Ganzes bereitgestellt wird. Dies macht es schwierig, Experimente durchzuführen und Änderungen am Prozess der Benutzerinteraktion mit der Anwendung vorzunehmen.
Betrachten Sie die Implementierung der Benutzeranmeldung als Ereignis-Pipeline mehrerer FaaS-Dienste. Bei dieser Trennung hat die Benutzererstellungsfunktion keine Ahnung, was während der Benutzeranmeldung geschieht. Sie hat zwei Listen:
- eine Liste der erforderlichen Aktionen (z. B. Senden einer Begrüßungs-E-Mail);
- eine Liste optionaler Aktionen (z. B. Abonnieren eines Newsletters).
Jede dieser Aktionen wird auch als FaaS implementiert, und die Liste der Aktionen ist nichts weiter als eine Liste der HTTP-Rückruffunktionen. Daher hat die Benutzererstellungsfunktion die folgende Form:
def create_user(context): # for key, value in required.items(): call_function(value.webhook, context.json) # # for key, value in optional.items(): if context.json.get(key, None) is not None: call_function(value.webhook, context.json)
Jeder der Handler kann nun auch nach dem FaaS-Prinzip implementiert werden:
def email_user(context): # user = context.json['username'] msg = ', {}, , !".format(user) send_email(msg, contex.json['email]) def subscribe_user(context): # email = context.json['email'] subscribe_user(email)
Auf diese Weise zerlegt, wird der FaaS-Dienst viel einfacher, enthält weniger Codezeilen und konzentriert sich auf die Implementierung einer bestimmten Funktion. Der Microservice-Ansatz vereinfacht das Schreiben von Code, kann jedoch zu Schwierigkeiten bei der Bereitstellung und Verwaltung von drei verschiedenen Microservices führen. Hier erweist sich der FaaS-Ansatz in seiner ganzen Pracht, da es aufgrund seiner Verwendung sehr einfach wird, kleine Codeteile zu verwalten. Durch die Visualisierung des Prozesses zum Erstellen eines Benutzers in Form einer Ereignispipeline können wir auch allgemein verstehen, was genau passiert, wenn sich ein Benutzer anmeldet, indem wir einfach die Änderung des Kontexts von Funktion zu Funktion innerhalb der Pipeline verfolgen.
»Weitere Informationen zum Buch finden Sie auf
der Website des Herausgebers»
Inhalt»
Auszug20% Rabatt auf Gutscheine für Designer -
DesignmusterNach Zahlung der Papierversion des Buches wird eine elektronische Version des Buches per E-Mail verschickt.