Anhand eines Beispiels für eine Beschreibung der Implementierung des Verschlüsselungsalgorithmus gemäß GOST 28147–89, der auf dem Feistel-Netzwerk basiert, zeigt der Artikel die Funktionen des Dual-Core-Prozessors BE-T1000 (auch bekannt als Baikal-T1) und führt Vergleichstests der Implementierung des Algorithmus mithilfe von Vektorberechnungen mit und ohne SIMD-Coprozessor durch. Hier zeigen wir die Verwendung des SIMD-Blocks für die Verschlüsselungsaufgabe gemäß GOST 28147-89, EZB-Modus.
Dieser Artikel wurde letztes Jahr für die Zeitschrift Electronic Components von Alexei Kolotnikov , einem führenden Programmierer bei Baikal Electronics, geschrieben. Und da es nicht sehr viele Leser dieser Zeitschrift gibt und der Artikel für diejenigen nützlich ist, die sich beruflich mit Kryptographie beschäftigen, veröffentliche ich ihn mit Erlaubnis des Autors und seiner kleinen Ergänzungen hier.
Der Baikal-T1-Prozessor und der darin enthaltene SIMD-Block
Der Baikal-T1-Prozessor umfasst ein Multiprozessor-Dual-Core-System der MIPS32 P5600-Familie sowie eine Reihe von Hochgeschwindigkeitsschnittstellen für den Datenaustausch und eine niedrige Geschwindigkeit für die Steuerung von Peripheriegeräten. Hier ist das Strukturdiagramm dieses Prozessors:
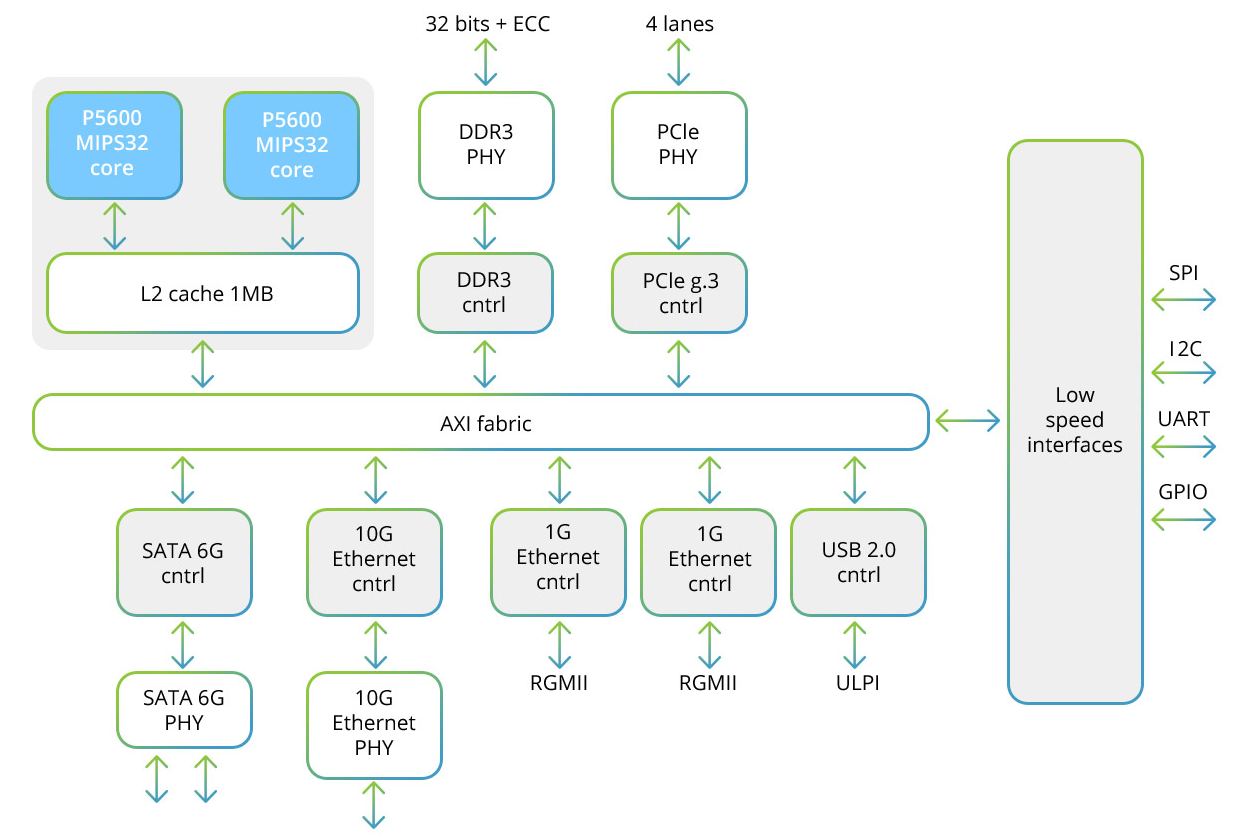
Jeder der beiden Kerne enthält einen SIMD-Block, mit dem Sie mit 128-Bit-Vektoren arbeiten können. Bei Verwendung der SIMD-Methode wird mehr als eine Probe verarbeitet.
und der gesamte Vektor, der mehrere Abtastwerte enthalten kann, dh ein Befehl wird sofort auf den gesamten Vektor (Array) von Daten angewendet. Somit werden in einem Befehlszyklus mehrere Abtastwerte verarbeitet. Der Prozessor verwendet den MIPS32-SIMD-Block, mit dem Sie mit 32 128-Bit-Registern arbeiten können.
Jedes Register kann Vektoren der folgenden Dimensionen enthalten: 8 × 16; 16 × 8; 4 × 32 oder
2 × 64 Bit. Es ist möglich, mehr als 150 Datenverarbeitungsanweisungen zu verwenden: Ganzzahl-, Gleitkomma- und Festkommaanweisungen, einschließlich bitweiser Operationen, Vergleichsoperationen und Konvertierungsoperationen.
Die sehr detaillierte MIPS SIMD-Technologie wurde von SparF im Artikel "MIPS SIMD-Technologie und der Baikal-T1-Prozessor" beschrieben .
Bewertung der Wirksamkeit des Vektor-Computing
Der arithmetische Coprozessor des Baikal-T1-Prozessorkerns kombiniert einen herkömmlichen Gleitkommaprozessor und einen parallelen SIMD-Prozessor, der sich auf die effiziente Verarbeitung von Vektoren und digitalisierten Signalen konzentriert. Eine unabhängige Leistungsbewertung des Vektor-SIMD-Coprozessors wurde 2017 von SparF beim Schreiben des Artikels „MIPS SIMD-Technologie und der Baikal-T1-Prozessor“ durchgeführt . Falls gewünscht, können solche Messungen wiederholt werden, indem sie unabhängig voneinander durch Anschließen an einen entfernten Ständer mit einem Prozessor durchgeführt werden .
Anschließend bestand die Testaufgabe darin, das mit den kostenlosen x264-Bibliotheken (H.264-Democlip) und x265 (HEVC-Videodatei) codierte Video zu dekodieren, wobei in regelmäßigen Abständen Screenshots erstellt wurden. Wie erwartet wurde eine spürbare Steigerung der Prozessorkernleistung bei FFmpeg-Aufgaben unter Verwendung von SIMD-Hardwarefunktionen festgestellt:

Kurze Beschreibung des Algorithmus GOST 28147-89
Hier werden nur die Hauptmerkmale für das Verständnis des Codes und die Optimierung aufgeführt:
- Der Algorithmus basiert auf dem Feistel-Netzwerk.

- Der Algorithmus besteht aus 32 Runden.
- Eine Runde besteht aus dem Mischen eines Schlüssels und dem Ersetzen von 8 Teilen von 4 Bits in einer Tabelle durch eine Verschiebung von 11 Bits.
Eine detaillierte Beschreibung des Informationskonvertierungsalgorithmus gemäß GOST 28147-89 ist im State Standard der UdSSR enthalten .
Implementierung des GOST 28147-89-Algorithmus ohne Verwendung eines SIMD-Blocks
Zu Vergleichszwecken wurden die Algorithmen zunächst mit Standardbefehlen „nicht vektorisiert“ implementiert.
Mit dem hier vorgeschlagenen MIPS-Assembler-Code können Sie einen 64-Bit-Block in 450 ns (oder ~ 150 Mbit / s) bei einer nominalen Prozessorfrequenz von 1200 MHz verschlüsseln. An den Berechnungen ist nur ein Kern beteiligt.
Um eine Ersetzungstabelle vorzubereiten, müssen Sie sie in eine 32-Bit-Darstellung erweitern, um die Arbeit der Runde zu beschleunigen: Anstatt vier Bits durch Maskieren und Verschieben im Voraus zu ersetzen
Die vorbereitete Tabelle ersetzt jeweils acht Bits.
uint8_t sbox_test[8][16] = { {0x9, 0x6, 0x3, 0x2, 0x8, 0xb, 0x1, 0x7, 0xa, 0x4, 0xe, 0xf, 0xc, 0x0, 0xd, 0x5}, {0x3, 0x7, 0xe, 0x9, 0x8, 0xa, 0xf, 0x0, 0x5, 0x2, 0x6, 0xc, 0xb, 0x4, 0xd, 0x1}, {0xe, 0x4, 0x6, 0x2, 0xb, 0x3, 0xd, 0x8, 0xc, 0xf, 0x5, 0xa, 0x0, 0x7, 0x1, 0x9}, {0xe, 0x7, 0xa, 0xc, 0xd, 0x1, 0x3, 0x9, 0x0, 0x2, 0xb, 0x4, 0xf, 0x8, 0x5, 0x6}, {0xb, 0x5, 0x1, 0x9, 0x8, 0xd, 0xf, 0x0, 0xe, 0x4, 0x2, 0x3, 0xc, 0x7, 0xa, 0x6}, {0x3, 0xa, 0xd, 0xc, 0x1, 0x2, 0x0, 0xb, 0x7, 0x5, 0x9, 0x4, 0x8, 0xf, 0xe, 0x6}, {0x1, 0xd, 0x2, 0x9, 0x7, 0xa, 0x6, 0x0, 0x8, 0xc, 0x4, 0x5, 0xf, 0x3, 0xb, 0xe}, {0xb, 0xa, 0xf, 0x5, 0x0, 0xc, 0xe, 0x8, 0x6, 0x2, 0x3, 0x9, 0x1, 0x7, 0xd, 0x4} }; uint32_t sbox_cvt[4*256]; for (i = 0; i < 256; ++i) { uint32_t p; p = sbox[7][i >> 4] << 4 | sbox[6][i & 15]; p = p << 24; p = p << 11 | p >> 21; sbox_cvt[i] = p; // S87 p = sbox[5][i >> 4] << 4 | sbox[4][i & 15]; p = p << 16; p = p << 11 | p >> 21; sbox_cvt[256 + i] = p; // S65 p = sbox[3][i >> 4] << 4 | sbox[2][i & 15]; p = p << 8; p = p << 11 | p >> 21; sbox_cvt[256 * 2 + i] = p; // S43 p = sbox[1][i >> 4] << 4 | sbox[0][i & 15]; p = p << 11 | p >> 21; sbox_cvt[256 * 3 + i] = p; // S21 }
Die Blockverschlüsselung ist eine 32-fache Wiederholung der Runde mit dem Schlüssel.
// input: a0 - &in, a1 - &out, a2 - &key, a3 - &sbox_cvt LEAF(gost_encrypt_block_asm) .set reorder lw n1, (a0) // n1, IN lw n2, 4(a0) // n2, IN + 4 lw t0, (a2) // key[0] -> t0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 0 gostround n1, n2, 1 gostround n2, n1, 2 gostround n1, n2, 3 gostround n2, n1, 4 gostround n1, n2, 5 gostround n2, n1, 6 gostround n1, n2, 7 gostround n2, n1, 7 gostround n1, n2, 6 gostround n2, n1, 5 gostround n1, n2, 4 gostround n2, n1, 3 gostround n1, n2, 2 gostround n2, n1, 1 gostround n1, n2, 0 gostround n2, n1, 0 1: sw n2, (a1) sw n1, 4(a1) jr ra nop END(gost_encrypt_block_asm)
Eine ausgebreitete Tischrunde ist nur ein Tischtausch.
.macro gostround x_in, x_out, rkey addu t8, t0, \x_in /* key[0] + n1 = x */ lw t0, \rkey * 4 (a2) /* next key to t0 */ ext t2, t8, 24, 8 /* get bits [24,31] */ ext t3, t8, 16, 8 /* get bits [16,23] */ ext t4, t8, 8, 8 /* get bits [8,15] */ ext t5, t8, 0, 8 /* get bits [0, 7] */ sll t2, t2, 2 /* convert to dw offset */ sll t3, t3, 2 /* convert to dw offset */ sll t4, t4, 2 /* convert to dw offset */ sll t5, t5, 2 /* convert to dw offset */ addu t2, t2, a3 /* add sbox_cvt */ addu t3, t3, a3 /* add sbox_cvt */ addu t4, t4, a3 /* add sbox_cvt */ addu t5, t5, a3 /* add sbox_cvt */ lw t6, (t2) /* sbox[x[3]] -> t2 */ lw t7, 256*4(t3) /* sbox[256 + x[2]] -> t3 */ lw t9, 256*2*4(t4) /* sbox[256 *2 + x[1]] -> t4 */ lw t1, 256*3*4(t5) /* sbox[256 *3 + x[0]] -> t5 */ or t2, t7, t6 /* | */ or t3, t1, t9 /* | */ or t2, t2, t3 /* | */ xor \x_out, \x_out, t2 /* n2 ^= f(...) */ .endm
Implementierung des GOST 28147-89-Algorithmus unter Verwendung eines SIMD-Blocks
Mit dem unten vorgeschlagenen Code können Sie vier Blöcke mit 64 Bit pro 720 ns (oder ~ 350 Mbit / s) unter denselben Bedingungen gleichzeitig verschlüsseln: Prozessorfrequenz 1200 MHz, ein Kern.
Der Austausch erfolgt in zwei Vierfachen und sofort in vier Blöcken mit der shuffle Anweisung und der anschließenden Maskierung der signifikanten Vierer.
Ersetzen einer Substitutionstabelle
for(i = 0; i < 16; ++i) { sbox_cvt_simd[i] = (sbox[7][i] << 4) | sbox[0][i]; // $w8 [7 0] sbox_cvt_simd[16 + i] = (sbox[1][i] << 4) | sbox[6][i]; // $w9 [6 1] sbox_cvt_simd[32 + i] = (sbox[5][i] << 4) | sbox[2][i]; // $w10[5 2] sbox_cvt_simd[48 + i] = (sbox[3][i] << 4) | sbox[4][i]; // $w11[3 4] }
Masken initialisieren.
l0123: .int 0x0f0f0f0f .int 0xf000000f /* substitute from $w8 [7 0] mask in w12*/ .int 0x0f0000f0 /* substitute from $w9 [6 1] mask in w13*/ .int 0x00f00f00 /* substitute from $w10 [5 2] mask in w14*/ .int 0x000ff000 /* substitute from $w11 [4 3] mask in w15*/ .int 0x000f000f /* mask $w16 x N x N */ .int 0x0f000f00 /* mask $w17 N x N x */ LEAF(gost_prepare_asm) .set reorder .set msa la t1, l0123 /* masks */ lw t2, (t1) lw t3, 4(t1) lw t4, 8(t1) lw t5, 12(t1) lw t6, 16(t1) lw t7, 20(t1) lw t8, 24(t1) fill.w $w2, t2 /* 0f0f0f0f -> w2 */ fill.w $w12, t3 /* f000000f -> w12*/ fill.w $w13, t4 /* 0f0000f0 -> w13*/ fill.w $w14, t5 /* 00f00f00 -> w14*/ fill.w $w15, t6 /* 000ff000 -> w15*/ fill.w $w16, t7 /* 000f000f -> w16*/ fill.w $w17, t8 /* 0f000f00 -> w17*/ ld.b $w8, (a0) /* load sbox */ ld.b $w9, 16(a0) ld.b $w10, 32(a0) ld.b $w11, 48(a0) jr ra nop END(gost_prepare_asm)
4-Block-Verschlüsselung
LEAF(gost_encrypt_4block_asm) .set reorder .set msa lw t1, (a0) // n1, IN lw t2, 4(a0) // n2, IN + 4 lw t3, 8(a0) // n1, IN + 8 lw t4, 12(a0) // n2, IN + 12 lw t5, 16(a0) // n1, IN + 16 lw t6, 20(a0) // n2, IN + 20 lw t7, 24(a0) // n1, IN + 24 lw t8, 28(a0) // n2, IN + 28 lw t0, (a2) // key[0] -> t0 insert.w ns1[0],t1 insert.w ns2[0],t2 insert.w ns1[1],t3 insert.w ns2[1],t4 insert.w ns1[2],t5 insert.w ns2[2],t6 insert.w ns1[3],t7 insert.w ns2[3],t8 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 0 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 0 gostround4 ns1, ns2, 1 gostround4 ns2, ns1, 2 gostround4 ns1, ns2, 3 gostround4 ns2, ns1, 4 gostround4 ns1, ns2, 5 gostround4 ns2, ns1, 6 gostround4 ns1, ns2, 7 gostround4 ns2, ns1, 7 gostround4 ns1, ns2, 6 gostround4 ns2, ns1, 5 gostround4 ns1, ns2, 4 gostround4 ns2, ns1, 3 gostround4 ns1, ns2, 2 gostround4 ns2, ns1, 1 gostround4 ns1, ns2, 0 gostround4 ns2, ns1, 0 1: copy_s.w t1,ns2[0] copy_s.w t2,ns1[0] copy_s.w t3,ns2[1] copy_s.w t4,ns1[1] copy_s.w t5,ns2[2] copy_s.w t6,ns1[2] copy_s.w t7,ns2[3] copy_s.w t8,ns1[3] sw t1, (a1) // n2, OUT sw t2, 4(a1) // n1, OUT + 4 sw t3, 8(a1) // n2, OUT + 8 sw t4, 12(a1) // n1, OUT + 12 sw t5, 16(a1) // n2, OUT + 16 sw t6, 20(a1) // n1, OUT + 20 sw t7, 24(a1) // n2, OUT + 24 sw t8, 28(a1) // n1, OUT + 28 jr ra nop END(gost_encrypt_4block_asm)
Runden Sie mit SIMD-Blockbefehlen mit der gleichzeitigen Berechnung von 4 Blöcken
.macro gostround4 x_in, x_out, rkey fill.w $w0, t0 /* key -> Vi */ addv.w $w1, $w0, \x_in /* key[0] + n1 = x */ srli.b $w3, $w1, 4 /* $w1 >> 4 */ and.v $w4, $w1, $w16 /* x 4 x 0*/ and.v $w5, $w1, $w17 /* 6 x 2 x*/ and.v $w6, $w3, $w17 /* 7 x 3 x */ and.v $w7, $w3, $w16 /* x 5 x 1 */ lw t0, \rkey * 4(a2) /* next key -> t0 */ or.v $w4, $w6, $w4 /* 7 4 3 0 */ or.v $w5, $w5, $w7 /* 6 5 2 1 */ move.v $w6, $w5 /* 6 5 2 1 */ move.v $w7, $w4 /* 7 4 3 0 */ /* 7 xx 0 */ /* 6 xx 1 */ /* x 5 2 x */ /* x 4 3 x */ vshf.b $w4, $w8, $w8 /* substitute $w8 [7 0] */ and.v $w4, $w4, $w12 vshf.b $w5, $w9, $w9 /* substitute $w9 [6 1] */ and.v $w5, $w5, $w13 vshf.b $w6, $w10, $w10 /* substitute $w10 [5 2] */ and.v $w6, $w6, $w14 vshf.b $w7, $w11, $w11 /* substitute $w11 [4 3] */ and.v $w7, $w7, $w15 or.v $w4, $w4, $w5 or.v $w6, $w6, $w7 or.v $w4, $w4, $w6 srli.w $w1, $w4, 21 /* $w4 >> 21 */ slli.w $w3, $w4, 11 /* $w4 << 11 */ or.v $w1, $w1, $w3 xor.v \x_out, \x_out, $w1 .endm
Kurze Schlussfolgerungen
Die Verwendung des SIMD-Blocks des Baikal-T1-Prozessors ermöglicht das Erreichen einer Datenkonvertierungsrate von etwa 350 Mbit / s gemäß den GOST 28147-89-Algorithmen, was zweieinhalb (!) Mal höher ist als die Implementierung bei Standardbefehlen. Da dieser Prozessor zwei Kerne hat, ist es theoretisch möglich, einen Stream mit einer Geschwindigkeit von ~ 700 Mbit / s zu verschlüsseln. Zumindest die Testimplementierung von IPsec mit Verschlüsselung gemäß GOST 28147-89 zeigte einen Kanaldurchsatz von ~ 400 Mbit / s auf einem Duplex.