Hallo Habr!
Ich arbeite für eine Spielefirma, die Online-Spiele entwickelt. Gegenwärtig sind alle unsere Spiele in viele "Märkte" unterteilt (ein "Markt" pro Land) und in jedem "Markt" gibt es ein Dutzend Welten, zwischen denen die Spieler während der Registrierung verteilt werden (oder manchmal können sie es selbst auswählen). Jede Welt hat eine Datenbank und einen oder mehrere Web- / App-Server. Auf diese Weise wird die Last nahezu gleichmäßig auf die Welten / Server verteilt und verteilt. Dadurch erhalten wir das Maximum von 6K-8K-Spielern online (dies ist das Maximum, meistens um ein Vielfaches weniger) und 200-300 Anfragen pro Hauptsendezeit pro Welt.
Eine solche Struktur mit der Aufteilung der Akteure in Märkte und Welten wird obsolet, die Spieler wollen etwas Globales. In den letzten Spielen haben wir aufgehört, die Menschen nach Ländern aufzuteilen, und nur ein oder zwei Märkte (Amerika und Europa) verlassen, aber immer noch viele Welten in jeder. Der nächste Schritt wird die Entwicklung von Spielen mit einer neuen Architektur und die Vereinigung aller Spieler in einer einzigen Welt mit
einer Datenbank sein .
Heute wollte ich ein wenig darüber sprechen, wie ich damit beauftragt wurde zu überprüfen, ob das gesamte Online-Spiel (und das sind jeweils 50 bis 200.000 Benutzer) eines unserer beliebten Spiele "sendet", um das nächste Spiel zu spielen, das auf der neuen Architektur basiert, und ob Das gesamte System, insbesondere die Datenbank (
PostgreSQL 11 ), kann einer solchen Belastung praktisch standhalten und, falls dies nicht möglich ist, herausfinden, wo unser Maximum liegt. Ich werde Ihnen ein wenig über die aufgetretenen Probleme und die Entscheidungen zur Vorbereitung auf das Testen so vieler Benutzer, den Prozess selbst und ein wenig über die Ergebnisse erzählen.
Intro
In der Vergangenheit hat jedes
Innenteam bei der
InnoGames GmbH ein Spielprojekt nach seinem Geschmack und seiner Farbe erstellt, wobei häufig unterschiedliche Technologien, Programmiersprachen und Datenbanken verwendet wurden. Darüber hinaus verfügen wir über viele externe Systeme, die für Zahlungen, das Versenden von Push-Benachrichtigungen, Marketing und mehr verantwortlich sind. Um mit diesen Systemen arbeiten zu können, haben Entwickler auch ihre einzigartigen Schnittstellen so gut wie möglich erstellt.
Derzeit im Mobile-Gaming-Geschäft viel
Geld und dementsprechend viel Wettbewerb. Es ist hier sehr wichtig, es von jedem Dollar zurückzugeben, der für Marketing ausgegeben wird, und ein bisschen mehr von oben. Daher schließen alle Spielefirmen Spiele sehr oft sogar im Stadium geschlossener Tests, wenn sie die analytischen Erwartungen nicht erfüllen. Dementsprechend ist es unrentabel, Zeit für die Erfindung des nächsten Rads zu verlieren. Daher wurde beschlossen, eine einheitliche Plattform zu schaffen, die Entwicklern eine vorgefertigte Lösung für die Integration in alle externen Systeme, eine Datenbank mit Replikation und alle Best Practices bietet. Alles, was Entwickler brauchen, ist, ein gutes Spiel zu entwickeln und darauf zu setzen und keine Zeit mit der Entwicklung zu verschwenden, die nicht mit dem Spiel selbst zusammenhängt.
Diese Plattform heißt
GameStarter :

Also auf den Punkt. Alle zukünftigen InnoGames-Spiele werden auf dieser Plattform erstellt, die über zwei Datenbanken verfügt - Master und Game (PostgreSQL 11). Der Master speichert grundlegende Informationen über die Spieler (Login, Passwort usw.) und nimmt hauptsächlich nur am Anmelde- / Registrierungsprozess im Spiel selbst teil. Spiel - die Datenbank des Spiels selbst, in der dementsprechend alle Spieldaten und -entitäten gespeichert sind. Dies ist der Kern des Spiels, in den die gesamte Last gehen wird.
Daher stellte sich die Frage, ob diese gesamte Struktur einer solchen potenziellen Anzahl von Benutzern standhalten kann, die dem Maximum online eines unserer beliebtesten Spiele entspricht.
Herausforderung
Die Aufgabe selbst bestand darin, zu überprüfen, ob die Datenbank (PostgreSQL 11) mit aktivierter Replikation der Last standhält, die wir derzeit im am meisten geladenen Spiel haben, und über den gesamten PowerEdge M630-Hypervisor (HV) verfügt.
Ich werde klarstellen, dass die Aufgabe im Moment
nur darin bestand , anhand der vorhandenen Datenbankkonfigurationen zu überprüfen, die wir unter Berücksichtigung von Best Practices und unserer eigenen Erfahrung erstellt haben.
Ich sage gleich die Datenbank, und das gesamte System hat sich mit Ausnahme einiger Punkte gut gezeigt. Dieses spezielle Spielprojekt befand sich jedoch im Prototypenstadium und in Zukunft werden mit der Komplikation der Spielmechanik die Anforderungen an die Datenbank komplizierter und die Last selbst kann erheblich zunehmen und ihre Art kann sich ändern. Um dies zu verhindern, muss das Projekt iterativ mit jedem mehr oder weniger wichtigen Meilenstein getestet werden. Die Automatisierung der Fähigkeit, diese Art von Tests mit ein paar Hunderttausenden von Benutzern durchzuführen, ist in dieser Phase zur Hauptaufgabe geworden.
Profil
Wie bei jedem Lasttest beginnt alles mit einem Lastprofil.
Unser potenzieller Wert CCU60 (CCU ist die maximale Anzahl von Benutzern für einen bestimmten Zeitraum, in diesem Fall 60 Minuten) wird mit
250.000 Benutzern angenommen. Die Anzahl der wettbewerbsfähigen virtuellen Benutzer (VUs) ist geringer als die der CCU60, und Analysten haben vorgeschlagen, dass sie sicher in zwei Teile geteilt werden kann. Runden Sie
150.000 wettbewerbsfähige VUs auf und akzeptieren Sie sie.
Die Gesamtzahl der Anfragen pro Sekunde wurde einem ziemlich geladenen Spiel entnommen:
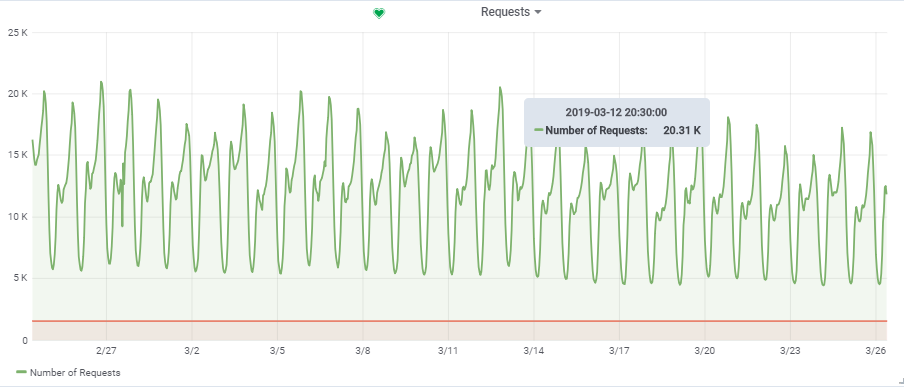
Somit beträgt unsere Ziellast ~
20.000 Anfragen / s bei
150.000 VU.
Struktur
Eigenschaften des „Standes“
In einem früheren
Artikel habe ich bereits über die Automatisierung des gesamten Lasttestprozesses gesprochen. Weiter möchte ich mich ein wenig wiederholen, aber ich werde Ihnen einige Punkte genauer erläutern.

In der Abbildung sind die blauen Quadrate unsere Hypervisoren (HV), eine Cloud, die aus vielen Servern besteht (Dell M620 - M640). Auf jeder HV werden ein Dutzend virtueller Maschinen (VMs) über KVM gestartet (Web / App und Datenbank im Mix). Beim Erstellen einer neuen VM erfolgt das Ausgleichen und Durchsuchen des Parametersatzes einer geeigneten HV, und es ist zunächst nicht bekannt, auf welchem Server sie sich befinden wird.
Datenbank (Spiel-DB):
Für unseren db1-Zweck haben wir jedoch einen separaten HV
targer_hypervisor reserviert, der auf dem M630 basiert.
Kurze Eigenschaften von targer_hypervisor:
Dell M_630
Modellname: Intel® Xeon® CPU E5-2680 v3 bei 2,50 GHz
CPU (s): 48
Gewinde pro Kern: 2
Kern (e) pro Sockel: 12
Steckdose (n): 2
RAM: 128 GB
Debian GNU / Linux 9 (Strecke)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
Detaillierte SpezifikationenDebian GNU / Linux 9 (Strecke)
4.9.0-8-amd64 # 1 SMP Debian 4.9.130-2 (2018-10-27)
lscpu
Architektur: x86_64
CPU-Betriebsmodus: 32-Bit, 64-Bit
Bytereihenfolge: Little Endian
CPU (s): 48
Liste der Online-CPUs: 0-47
Gewinde pro Kern: 2
Kern (e) pro Sockel: 12
Steckdose (n): 2
NUMA-Knoten: 2
Hersteller-ID: GenuineIntel
CPU-Familie: 6
Modell: 63
Modellname: Intel® Xeon® CPU E5-2680 v3 bei 2,50 GHz
Schritt: 2
CPU MHz: 1309,356
CPU max MHz: 3300.0000
CPU min MHz: 1200.0000
BogoMIPS: 4988,42
Virtualisierung: VT-x
L1d-Cache: 32 KB
L1i-Cache: 32 KB
L2-Cache: 256 KB
L3-Cache: 30720 KB
NUMA-Knoten 0 CPU (s): 0,2,4,6,8,10,12,14,16,18,20,22,24,26,28,30,32,34,36,38,40,42 44,46
NUMA-Knoten1 CPU (s): 1,3,5,7,9,11,13,15,17,19,21,23,25,27,29,31,33,35,37,39,41,43 45,47
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse SMX est tm2 SSSE3 SDBG fma CX16 xtpr pdcm PCID DCA sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes XSAVE AVX F16C rdrand lahf_lm abm EPB invpcid_single ssbd IBRS IbpB stibp Kaiser tpr_shadow vnmi Flexpriority ept VPID fsgsbase tsc_adjust Bmi1 AVX2 SMEP BMI2 erms invpcid CQM xsaveopt cqm_llc cqm_occup_llc dtherm ida arat pln pts flush_l1d
/ usr / bin / qemu-system-x86_64 --version
QEMU-Emulator Version 2.8.1 (Debian 1: 2.8 + dfsg-6 + deb9u5)
Copyright © 2003-2016 Fabrice Bellard und die QEMU-Projektentwickler
Kurze Eigenschaften von db1:
Architektur: x86_64
CPU (s): 48
RAM: 64 GB
4.9.0-8-amd64 # 1 SMP Debian 4.9.144-3.1 (2019-02-19) x86_64 GNU / Linux
Debian GNU / Linux 9 (Strecke)
psql (PostgreSQL) 11.2 (Debian 11.2-1.pgdg90 + 1)
PostgreSQL-Konfiguration mit einigen Erklärungenseq_page_cost = 1.0
random_page_cost = 1.1 # Wir haben SSD
include '/etc/postgresql/11/main/extension.conf'
log_line_prefix = '% t [% p-% l]% q% u @% h'
log_checkpoints = on
log_lock_waits = on
log_statement = ddl
log_min_duration_statement = 100
log_temp_files = 0
autovacuum_max_workers = 5
autovacuum_naptime = 10s
autovacuum_vacuum_cost_delay = 20ms
vacac_cost_limit = 2000
wartung_arbeit_mem = 128MB
synchronous_commit = aus
checkpoint_timeout = 30min
listen_addresses = '*'
work_mem = 32 MB
effektive_cache_size = 26214MB # 50% des verfügbaren Speichers
shared_buffers = 16384MB # 25% des verfügbaren Speichers
max_wal_size = 15 GB
min_wal_size = 80 MB
wal_level = hot_standby
max_wal_senders = 10
wal_compression = on
archive_mode = on
archive_command = '/ bin / true'
archive_timeout = 1800
hot_standby = on
wal_log_hints = on
hot_standby_feedback = on
hot_standby_feedback ist standardmäßig
deaktiviert . Wir hatten es
aktiviert , aber später musste es
deaktiviert werden, um einen erfolgreichen Test durchzuführen. Ich werde später erklären, warum.
Die wichtigsten aktiven Tabellen in der Datenbank (Konstruktion, Produktion, game_entity, building, core_inventory_player_resource, Survivor) werden mithilfe eines Bash-Skripts mit Daten (ca. 80 GB) vorgefüllt.
Replikation:
SELECT * FROM pg_stat_replication; pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_lsn | write_lsn | flush_lsn | replay_lsn | write_lag | flush_lag | replay_lag | sync_priority | sync_state -----+----------+---------+---------------------+--------------+---------------------+-------------+-------------------------------+--------------+-----------+------------+------------+------------+------------+-----------------+-----------------+-----------------+---------------+------------ 759 | 17035 | repmgr | xl1db2 | xxxx | xl1db2 | 51142 | 2019-01-27 08:56:44.581758+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000393 | 00:00:00.001159 | 00:00:00.001313 | 0 | async 977 | 17035 | repmgr | xl1db3 |xxxxx | xl1db3 | 42888 | 2019-01-27 08:57:03.232969+00 | | streaming | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 18/424A9F0 | 00:00:00.000373 | 00:00:00.000798 | 00:00:00.000919 | 0 | async
Anwendungsserver
Anschließend wurden auf einer produktiven HV (prod_hypervisors) mit verschiedenen Konfigurationen und Kapazitäten 15 App-Server gestartet: 8 Kerne, 4 GB. Die Hauptsache, die gesagt werden kann: openjdk 11.0.1 2018-10-16, Frühling, Interaktion mit der Datenbank über
hikari (hikari.maximum-pool-size: 50)
Stresstest-Umgebung
Die gesamte Lasttestumgebung besteht aus einem Hauptserver
admin.loadtest und mehreren
GeneratorN.loadtest- Servern (in diesem Fall waren es 14).
generatorN.loadtest - "nackte" VM Debian Linux 9 mit installiertem Java 8. 32 Kernel / 32 Gigabyte. Sie befinden sich auf nicht produktiven HVs, um die Leistung wichtiger VMs nicht versehentlich zu beeinträchtigen.
admin.loadtest - Debian Linux 9
virtuelle Maschine , 16 Kerne / 16 Gigs, auf der Jenkins, JLTC und andere zusätzliche unwichtige Software ausgeführt werden.
JLTC -
Jmeter Lasttestzentrum . Ein System in Py / Django, das den Start von Tests sowie die Analyse von Ergebnissen steuert und automatisiert.
Teststartschema

Der Prozess zum Ausführen des Tests sieht folgendermaßen aus:
- Der Test wird von Jenkins aus gestartet. Wählen Sie den gewünschten Job aus, und geben Sie die gewünschten Testparameter ein:
- DAUER - Testdauer
- RAMPUP - Aufwärmzeit
- THREAD_COUNT_TOTAL - Die gewünschte Anzahl virtueller Benutzer (VU) oder Threads
- TARGET_RESPONSE_TIME ist ein wichtiger Parameter. Um das gesamte System nicht zu überlasten, stellen wir die gewünschte Antwortzeit ein. Dementsprechend hält der Test die Last auf einem Niveau, bei dem die Antwortzeit des gesamten Systems nicht mehr als die angegebene beträgt.
- Starten
- Jenkins klont den Testplan von Gitlab und sendet ihn an JLTC.
- JLTC arbeitet ein wenig mit einem Testplan (fügt beispielsweise einen einfachen CSV-Writer ein).
- JLTC berechnet die erforderliche Anzahl von Jmeter-Servern, um die gewünschte Anzahl von VUs auszuführen (THREAD_COUNT_TOTAL).
- JLTC stellt eine Verbindung zu jedem LoadgeneratorN-Generator her und startet den jmeter-Server.
Während des Tests generiert der
JMeter-Client eine CSV-Datei mit den Ergebnissen. Während des Tests wächst die Datenmenge und die Größe dieser Datei in einem
wahnsinnigen Tempo und kann nach dem Test nicht mehr für die Analyse verwendet werden.
Daemon wurde erfunden (als Experiment) und analysiert es
„on the fly“ .
Testplan
Den Testplan können Sie hier herunterladen.
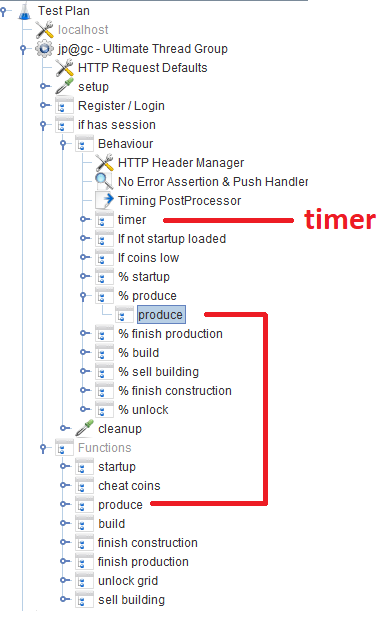
Nach der Registrierung / Anmeldung arbeiten Benutzer im
Verhaltensmodul , das aus mehreren
Durchsatz-Controllern besteht , die die Wahrscheinlichkeit einer bestimmten Spielfunktion angeben. In jedem Durchsatz-Controller gibt es einen
Modul-Controller , der sich auf das entsprechende Modul bezieht, das die Funktion implementiert.
Off-Topic
Während der Entwicklung des Skripts haben wir versucht, Groovy in vollem Umfang zu nutzen, und dank unseres Java-Programmierers habe ich ein paar Tricks für mich entdeckt (vielleicht ist es für jemanden nützlich):
VU / Threads
Wenn ein Benutzer bei der Konfiguration des Jobs in Jenkins die gewünschte Anzahl von VUs mit dem Parameter THREAD_COUNT_TOTAL eingibt, muss die erforderliche Anzahl von Jmeter-Servern irgendwie gestartet und die endgültige Anzahl von VUs zwischen ihnen verteilt werden. Dieser Teil liegt beim JLTC im Teil
Controller / Provision .
Im Wesentlichen lautet der Algorithmus wie folgt:
- Wir teilen die gewünschte Anzahl von VU threads_num in 200-300 Threads auf und basierend auf der mehr oder weniger angemessenen Größe -Xmsm -Xmxm bestimmen wir den erforderlichen Speicherwert für einen jmeter-Server required_memory_for_jri (JRI - Ich nenne Jmeter-Remote-Instanz anstelle von Jmeter-Server).
- Aus threads_num und required_memory_for_jri ermitteln wir die Gesamtzahl der jmeter-Server: target_amount_jri und den Gesamtwert des erforderlichen Speichers: required_memory_total .
- Wir sortieren alle LoadgeneratorN-Generatoren nacheinander und starten die maximale Anzahl von Jmeter-Servern basierend auf dem verfügbaren Speicher. Solange die Anzahl der laufenden current_amount_jri-Instanzen nicht gleich target_amount_jri ist.
- (Wenn die Anzahl der Generatoren und der Gesamtspeicher nicht ausreichen, fügen Sie dem Pool einen neuen hinzu.)
- Wir stellen mit netstat eine Verbindung zu jedem Generator her, wobei wir uns an alle ausgelasteten Ports erinnern, und führen auf zufälligen Ports (die nicht belegt sind) die erforderliche Anzahl von jmeter-Servern aus:
netstat_cmd= 'netstat -tulpn | grep LISTEN' stdin, stdout, stderr = ssh.exec_command(cmd1) used_ports = [] netstat_output = str(stdout.readlines()) ports = re.findall('\d+\.\d+\.\d+\.\d+\:(\d+)', netstat_output) ports_ipv6 = re.findall('\:\:\:(\d+)', netstat_output) p.wait() for port in ports: used_ports.append(int(port)) for port in ports_ipv6: used_ports.append(int(port)) ssh.close() for i in range(1, possible_jris_on_host + 1): port = int(random.randint(10000, 20000)) while port in used_ports: port = int(random.randint(10000, 20000))
- Wir sammeln alle laufenden jmeter-Server auf einmal in der Formatadresse: port, zum Beispiel generator13: 15576, generator9: 14015, generator11: 19152, generator14: 12125, generator2: 17602
- Die resultierende Liste und threads_per_host werden zu Beginn des Tests an den JMeter-Client gesendet:
REMOTE_TESTING_FLAG=" -R $REMOTE_HOSTS_STRING" java -jar -Xms7g -Xmx7g -Xss228k $JMETER_DIR/bin/ApacheJMeter.jar -Jserver.rmi.ssl.disable=true -n -t $TEST_PLAN -j $WORKSPACE/loadtest.log -GTHREAD_COUNT=$THREADS_PER_HOST $OTHER_VARS $REMOTE_TESTING_FLAG -Jjmeter.save.saveservice.default_delimiter=,
In unserem Fall wurde der Test gleichzeitig von 300 Jmeter-Servern mit jeweils 500 Threads durchgeführt. Das Startformat eines Jmeter-Servers mit Java-Parametern sah folgendermaßen aus:
nohup java -server -Xms1200m -Xmx1200m -Xss228k -XX:+DisableExplicitGC -XX:+CMSClassUnloadingEnabled -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -XX:+ScavengeBeforeFullGC -XX:+CMSScavengeBeforeRemark -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -Djava.net.preferIPv6Addresses=true -Djava.net.preferIPv4Stack=false -jar "/tmp/jmeter-JwKse5nY/bin/ApacheJMeter.jar" -Jserver.rmi.ssl.disable=true "-Djava.rmi.server.hostname=generator12.loadtest.ig.local" -Duser.dir=/tmp/jmeter-JwKse5nY/bin/ -Dserver_port=13114 -s -Jpoll=49 > /dev/null 2>&1
50ms
Die Aufgabe besteht darin, zu bestimmen, wie viel unsere Datenbank aushalten kann, anstatt sie und das gesamte System als Ganzes in einen kritischen Zustand zu versetzen. Bei so vielen Jmeter-Servern müssen Sie die Last auf einem bestimmten Niveau halten und nicht das gesamte System töten. Der beim Starten des Tests angegebene Parameter
TARGET_RESPONSE_TIME ist dafür verantwortlich. Wir waren uns einig, dass
50 ms die optimale Reaktionszeit ist, für die das System verantwortlich sein sollte.
In JMeter gibt es standardmäßig viele verschiedene Timer, mit denen Sie den Durchsatz steuern können. In unserem Fall ist jedoch nicht bekannt, wo Sie ihn erhalten können. Es gibt jedoch einen
JSR223-Timer, mit dem Sie anhand der
aktuellen Systemantwortzeit etwas finden
können . Der Timer selbst befindet sich im Hauptblock
Verhalten :

Analyse der Ergebnisse (Daemon)
Zusätzlich zu den Diagrammen in Grafana müssen auch aggregierte Testergebnisse vorliegen, damit die Tests anschließend in JLTC verglichen werden können.
Ein solcher Test generiert 16.000 bis 20.000 Anfragen pro Sekunde. Es ist einfach zu berechnen, dass in 4 Stunden eine CSV-Datei mit einer Größe von einigen hundert GB generiert wird. Daher musste ein Job erstellt werden, der die Daten jede Minute analysiert, an die Datenbank sendet und die Hauptdatei bereinigt.
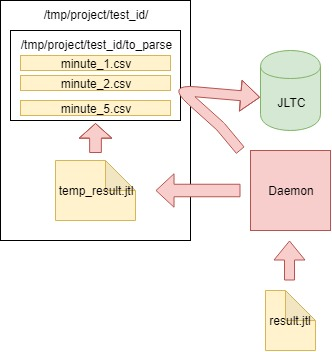
Der Algorithmus ist wie folgt:
- Wir lesen die Daten aus der vom jmeter-client generierten CSV-Datei result.jtl , speichern und bereinigen die Datei (Sie müssen sie korrekt bereinigen, sonst sieht die leere Datei wie die alte FD mit derselben Größe aus):
with open(jmeter_results_file, 'r+') as f: rows = f.readlines() f.seek(0) f.truncate(0) f.writelines(rows[-1])
- Wir schreiben die gelesenen Daten in die temporäre Datei temp_result.jtl :
rows_num = len(rows) open(temp_result_filename, 'w').writelines(rows[0:rows_num])
- Wir lesen die Datei temp_result.jtl . Wir verteilen die gelesenen Daten "in Minuten":
for r in f.readlines(): row = r.split(',') if len(row[0]) == 13: ts_c = int(row[0]) dt_c = datetime.datetime.fromtimestamp(ts_c/1000) minutes_data.setdefault(dt_c.strftime('%Y_%m_%d_%H_%M'), []).append(r)
- Die Daten für jede Minute von minutendaten werden in die entsprechende Datei im Ordner to_parse / geschrieben . (Daher hat im Moment jede Minute des Tests eine eigene Datendatei. Während der Aggregation spielt es keine Rolle, in welcher Reihenfolge die Daten in jede Datei gelangen.)
for key, value in minutes_data.iteritems():
- Unterwegs analysieren wir die Dateien im Ordner to_parse. Wenn sich eine dieser Dateien nicht innerhalb einer Minute geändert hat, ist diese Datei ein Kandidat für die Datenanalyse, Aggregation und das Senden an die JLTC-Datenbank:
for filename in os.listdir(temp_to_parse_path): data_file = os.path.join(temp_to_parse_path, filename) file_mod_time = os.stat(data_file).st_mtime last_time = (time.time() - file_mod_time) if last_time > 60: logger.info('[DAEMON] File {} was not modified since 1min, adding to parse list.'.format(data_file)) files_to_parse.append(data_file)
- Wenn es solche Dateien gibt (eine oder mehrere), senden wir sie analysiert an die Funktion parse_csv_data (jede Datei parallel):
for f in files_to_parse: logger.info('[DAEMON THREAD] Parse {}.'.format(f)) t = threading.Thread( target=parse_csv_data, args=( f, jmeter_results_file_fields, test, data_resolution)) t.start() threads.append(t) for t in threads: t.join()
Daemon selbst in cron.d startet jede Minute:
Daemon startet jede Minute mit cron.d:
* * * * * root sleep 21 && /usr/bin/python /var/lib/jltc/manage.py daemon
Somit schwillt die Datei mit den Ergebnissen nicht auf unvorstellbare Größen an, sondern wird im laufenden Betrieb analysiert und gelöscht.
Ergebnisse
Die App
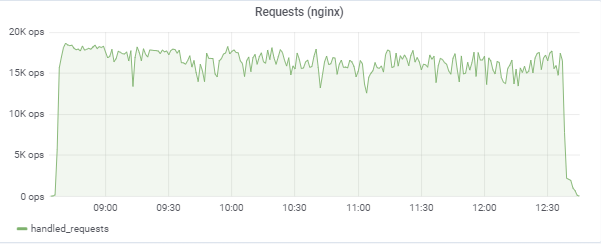
Unsere 150.000 virtuellen Spieler:

Der Test versucht, die Antwortzeit von 50 ms anzupassen, sodass die Last selbst ständig im Bereich zwischen 16.000 und 18.000 Anforderungen / c springt:
Anwendungsserverlast (15 App). Zwei Server haben "Pech", auf dem langsameren M620 zu sein:
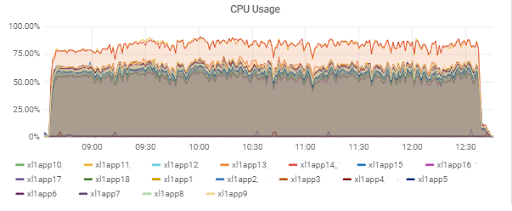
Datenbankantwortzeit (für App-Server):

Datenbank
CPU-Auslastung auf db1 (VM):
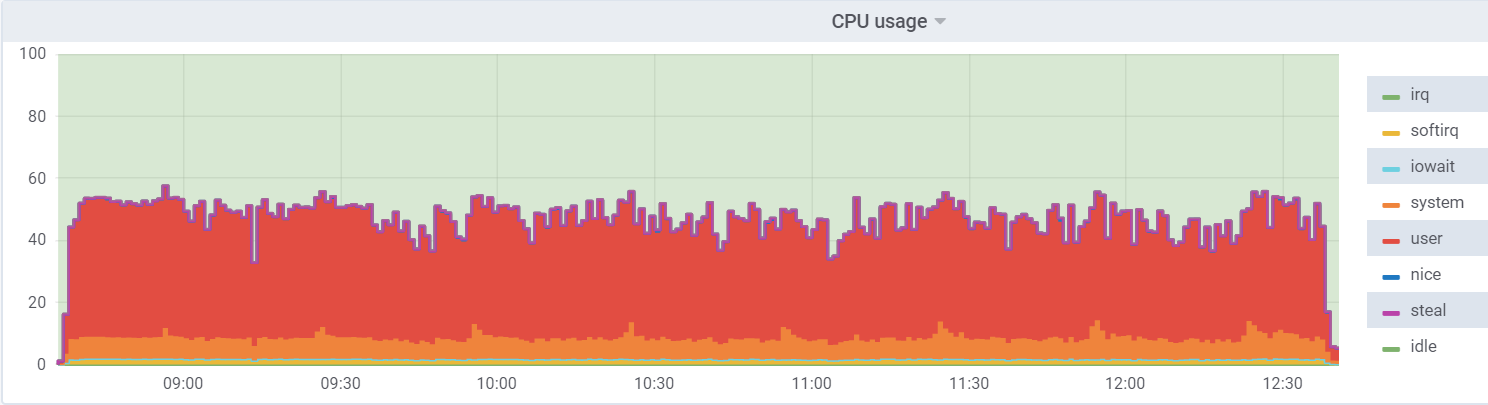
CPU-Auslastung auf dem Hypervisor:
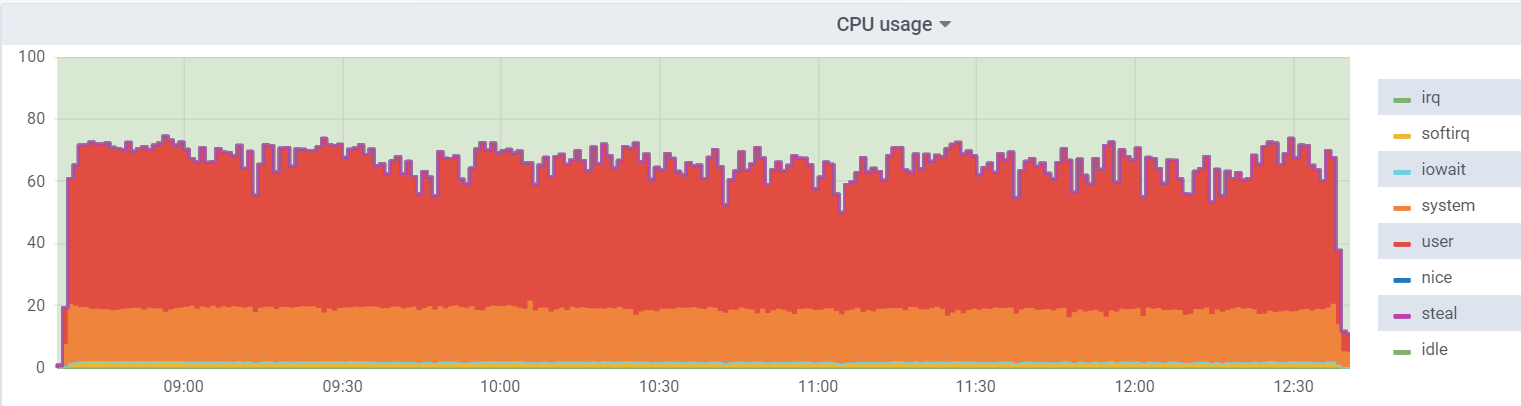
Die Belastung der virtuellen Maschine ist geringer, da davon ausgegangen wird, dass 48 reale Kerne zur Verfügung stehen. Auf dem Hypervisor befinden sich tatsächlich 24
Hyperthreading- Kerne.
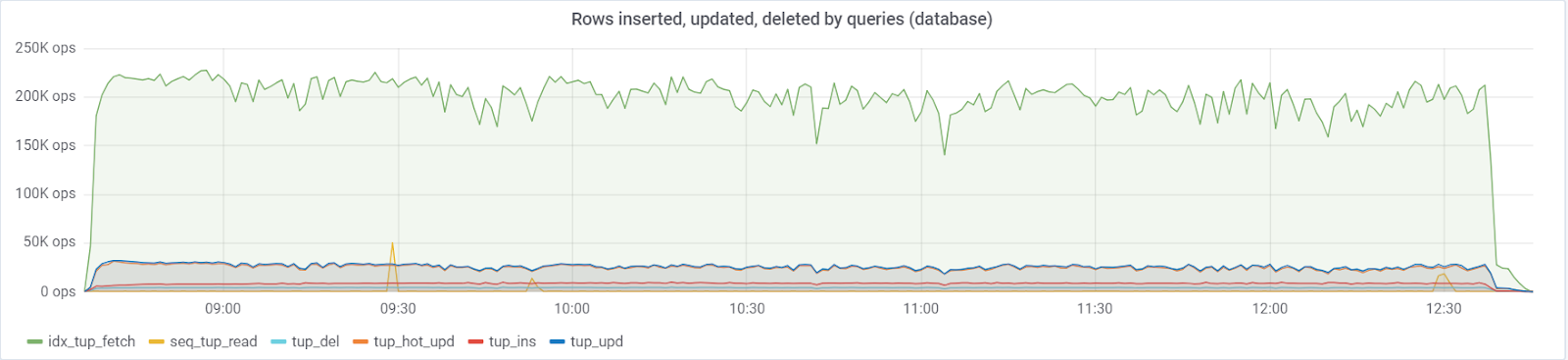
Es werden
maximal ~ 250.000 Abfragen / s an die Datenbank
gesendet , bestehend aus (83% Auswahlen, 3% Einfügungen, 11,6% Aktualisierungen (90% HEISS), 1,6% Löschungen):

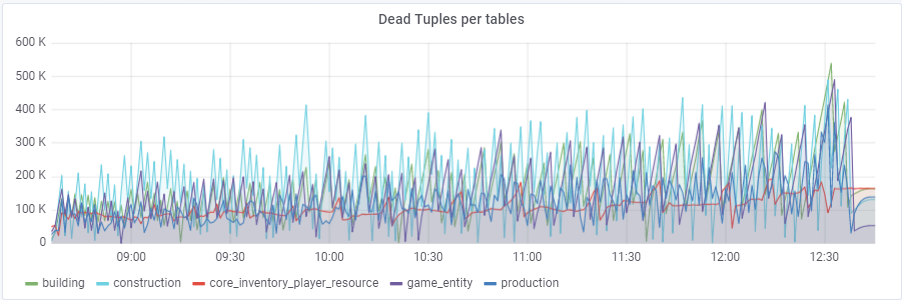
Mit einem Standardwert von
autovacuum_vacuum_scale_factor = 0,2 wuchs die Anzahl der toten Tupel mit dem Test (mit zunehmender Tabellengröße) sehr schnell, was mehrmals zu kurzen Datenbankleistungsproblemen führte, die den gesamten Test mehrmals ruinierten. Ich musste dieses Wachstum für einige Tabellen „zähmen“, indem ich diesem Parameter autovacuum_vacuum_scale_factor persönliche Werte zuwies:
ALTER TABLE ... SET (autovacuum_vacuum_scale_factor = ...)ALTER TABLE Konstruktion SET (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE Produktion SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE game_entity SET (autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE building SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE building SET (autovacuum_analyze_scale_factor = 0.01);
ALTER TABLE core_inventory_player_resource SET (autovacuum_vacuum_scale_factor = 0.10);
ALTER TABLE Survivor SET (autovacuum_vacuum_scale_factor = 0.01);
ALTER TABLE Survivor SET (autovacuum_analyze_scale_factor = 0.01);
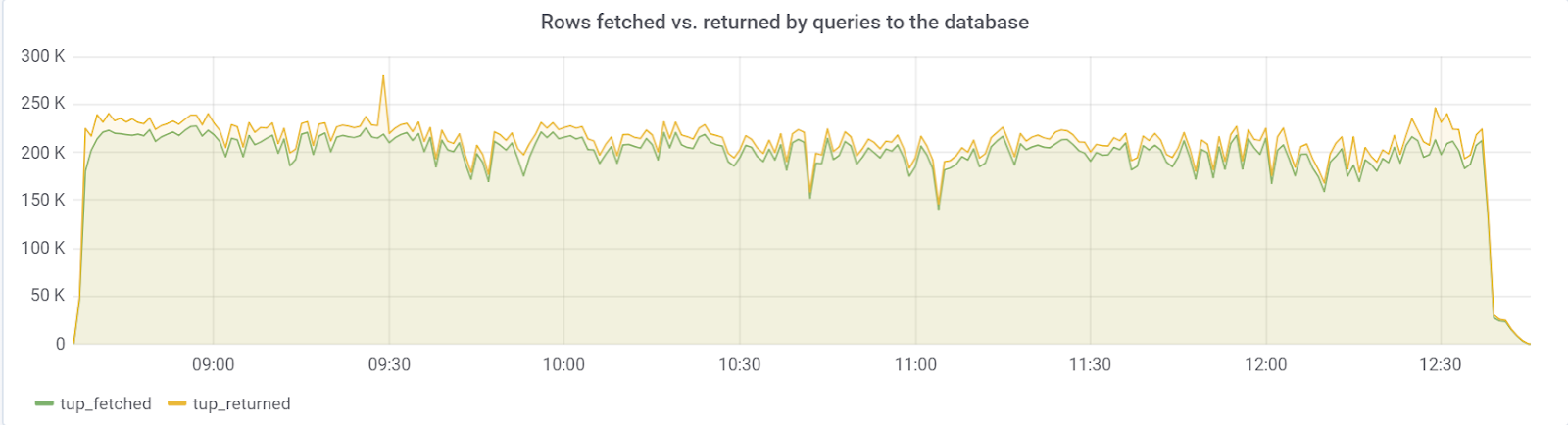
Im Idealfall sollte rows_fetched in der Nähe von rows_returned liegen, was wir glücklicherweise beobachten:
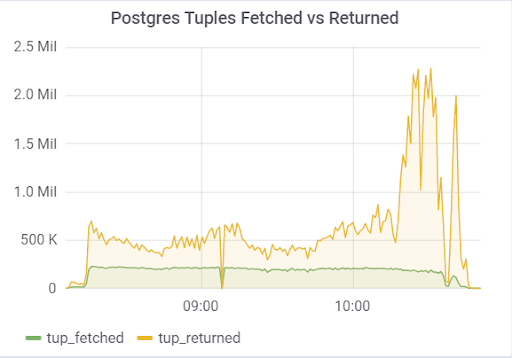
hot_standby_feedback
Das Problem war der Parameter
hot_standby_feedback , der die Leistung des
Hauptservers erheblich beeinträchtigen kann, wenn seine
Standby- Server keine Zeit haben, Änderungen an WAL-Dateien anzuwenden. In der Dokumentation (https://postgrespro.ru/docs/postgrespro/11/runtime-config-replication) heißt es, dass "bestimmt wird, ob der Hot-Standby-Server den Master oder den übergeordneten Slave über die Anforderungen benachrichtigt, die er gerade ausführt". Standardmäßig ist es deaktiviert, aber es wurde in unserer Konfiguration aktiviert. Was zu traurigen Konsequenzen führte, wenn 2 Standby-Server vorhanden sind und die Replikationsverzögerung während des Ladens (aus verschiedenen Gründen) von Null abweicht, können Sie ein solches Bild beobachten, das zum Zusammenbruch des gesamten Tests führen kann:

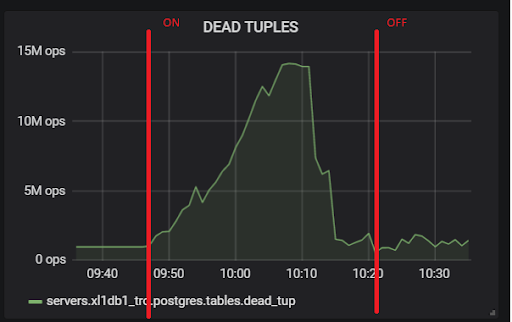
Dies liegt an der Tatsache, dass VACUUM bei aktiviertem hot_standby_feedback keine toten Tupel löschen möchte, wenn Standby-Server in ihrer Transaktions-ID zurückliegen, um Replikationskonflikte zu vermeiden. Ausführlicher Artikel
Was hot_standby_feedback in PostgreSQL wirklich tut :
xl1_game=# VACUUM VERBOSE core_inventory_player_resource; INFO: vacuuming "public.core_inventory_player_resource" INFO: scanned index "core_inventory_player_resource_pkey" to remove 62869 row versions DETAIL: CPU: user: 1.37 s, system: 0.58 s, elapsed: 4.20 s ………... INFO: "core_inventory_player_resource": found 13682 removable, 7257082 nonremovable row versions in 71842 out of 650753 pages <b>DETAIL: 3427824 dead row versions cannot be removed yet, oldest xmin: 3810193429</b> There were 1920498 unused item pointers. Skipped 8 pages due to buffer pins, 520953 frozen pages. 0 pages are entirely empty. CPU: user: 4.55 s, system: 1.46 s, elapsed: 11.74 s.
Eine so große Anzahl toter Tupel führt zu dem oben gezeigten Bild. Hier sind zwei Tests, bei denen hot_standby_feedback ein- und ausgeschaltet ist:
Und dies ist unsere Replikationsverzögerung während des Tests, mit der in Zukunft etwas unternommen werden muss:
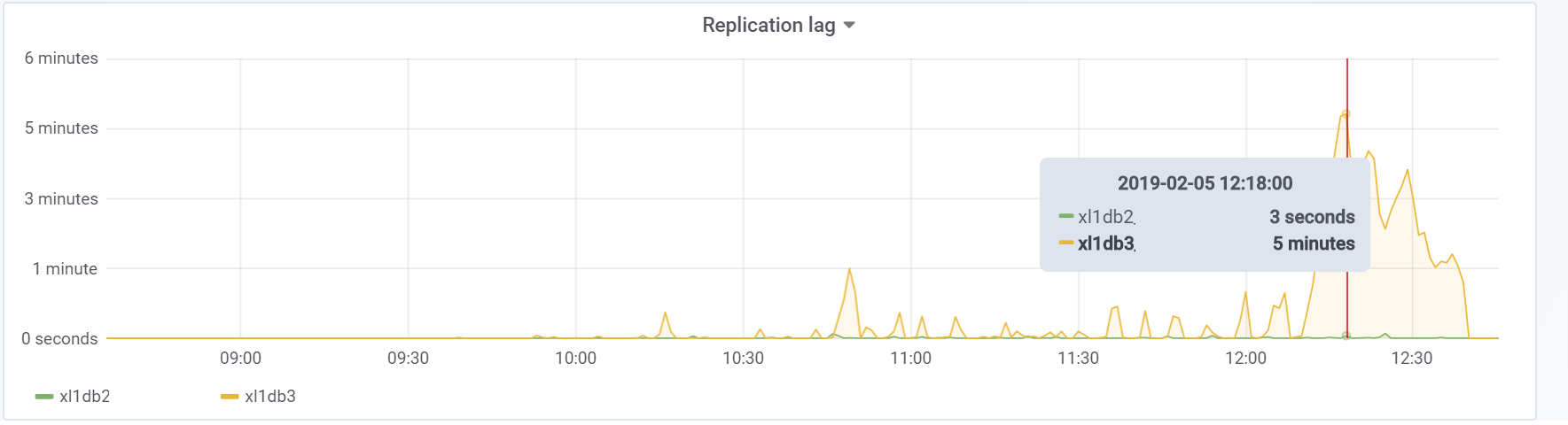
Fazit
Dieser Test hat glücklicherweise (oder leider für den Inhalt des Artikels) gezeigt, dass es in dieser Phase des Prototyps des Spiels durchaus möglich ist, die gewünschte Last seitens der Benutzer zu absorbieren, was ausreicht, um grünes Licht für weitere Prototypen und Entwicklungen zu geben. In den nachfolgenden Entwicklungsphasen müssen die Grundregeln befolgt werden (um die Einfachheit der ausgeführten Abfragen zu gewährleisten, eine Überfülle an Indizes sowie nicht indizierte Messwerte usw. zu verhindern) und vor allem das Projekt in jeder wichtigen Entwicklungsphase testen, um Probleme zu finden und zu beheben kann früher sein. Vielleicht schreibe ich bald einen Artikel, da wir bereits bestimmte Probleme gelöst haben.
Viel Glück an alle!
Unser
GitHub nur für den Fall;)