
Die Zeitreihendatenbank (TSDB) in Prometheus 2 ist ein hervorragendes Beispiel für eine technische Lösung, die hinsichtlich der Geschwindigkeit der Datenspeicherung und der Abfrageausführung sowie der Ressourceneffizienz wesentliche Verbesserungen gegenüber dem v2-Speicher in Prometheus 1 bietet. Wir haben Prometheus 2 in Percona Monitoring and Management (PMM) implementiert, und ich hatte die Gelegenheit, die Leistung von Prometheus 2 TSDB zu verstehen. In diesem Artikel werde ich über die Ergebnisse dieser Beobachtungen sprechen.
Prometheus durchschnittliche Arbeitsbelastung
Für diejenigen, die es gewohnt sind, mit Primärdatenbanken umzugehen, ist die reguläre Arbeitsbelastung von Prometheus ziemlich merkwürdig. Die Geschwindigkeit der Datenakkumulation tendiert zu einem stabilen Wert: Normalerweise senden die von Ihnen überwachten Dienste ungefähr die gleiche Anzahl von Metriken, und die Infrastruktur ändert sich relativ langsam.
Informationsanfragen können aus verschiedenen Quellen stammen. Einige von ihnen, wie z. B. Warnungen, streben auch einen stabilen und vorhersehbaren Wert an. Andere, wie z. B. Benutzerabfragen, können Spitzen verursachen, obwohl dies für den größten Teil der Last nicht typisch ist.
Belastungstest
Während des Testens konzentrierte ich mich auf die Fähigkeit, Daten zu sammeln. Ich habe Prometheus 2.3.2, kompiliert mit Go 1.10.1 (als Teil von PMM 1.14), auf dem Linode-Dienst mithilfe dieses Skripts
bereitgestellt :
StackScript . Für die realistischste
Lastgenerierung habe ich mit diesem
StackScript mehrere MySQL-Knoten mit einer realen Last gestartet (Sysbench TPC-C-Test), von denen jeder 10 Linux / MySQL-Knoten emulierte.
Alle folgenden Tests wurden auf einem Linode-Server mit acht virtuellen Kernen und 32 GB Speicher durchgeführt, auf dem 20 Lastsimulationen zur Überwachung von zweihundert MySQL-Instanzen gestartet wurden. Oder in Prometheus-Begriffen 800 Ziele, 440 Kratzer pro Sekunde, 380.000 Proben pro Sekunde und 1,7 Millionen aktive Zeitreihen.
Design
Der übliche Ansatz herkömmlicher Datenbanken, einschließlich des von Prometheus 1.x verwendeten, ist die
Speicherbeschränkung . Wenn es nicht ausreicht, um der Last standzuhalten, treten große Verzögerungen auf und einige Anforderungen werden nicht erfüllt.
Die Speichernutzung in Prometheus 2 wird mit dem Schlüssel
storage.tsdb.min-block-duration konfiguriert, der bestimmt, wie lange die Datensätze im Speicher gespeichert werden, bevor sie auf die Festplatte geschrieben werden (standardmäßig sind dies 2 Stunden). Die benötigte Speichermenge hängt von der Anzahl der Zeitreihen, Beschriftungen und der Intensität der Datenerfassung (Scrapes) insgesamt mit dem Nettoeingabestream ab. In Bezug auf den Speicherplatz strebt Prometheus die Verwendung von 3 Bytes pro Datensatz (Beispiel) an. Andererseits sind die Speicheranforderungen viel höher.
Trotz der Tatsache, dass es möglich ist, die Blockgröße zu konfigurieren, wird nicht empfohlen, sie manuell zu konfigurieren, sodass Sie Prometheus so viel Speicherplatz zur Verfügung stellen müssen, wie für Ihre Last erforderlich ist.
Wenn nicht genügend Speicher vorhanden ist, um den eingehenden Metrik-Stream zu unterstützen, fällt Prometheus aus dem Speicher aus oder der OOM-Killer erreicht ihn.
Das Hinzufügen von Swap, um den Absturz zu verzögern, wenn Prometheus nicht mehr genügend Speicher hat, hilft nicht wirklich, da die Verwendung dieser Funktion einen explosiven Speicherverbrauch verursacht. Ich denke, das Ding ist Go, sein Müllsammler und wie es mit Swap funktioniert.
Ein weiterer interessanter Ansatz besteht darin, den Kopfblock so einzustellen, dass er zu einem bestimmten Zeitpunkt auf die Festplatte zurückgesetzt wird, anstatt ihn vom Beginn des Prozesses an zu zählen.
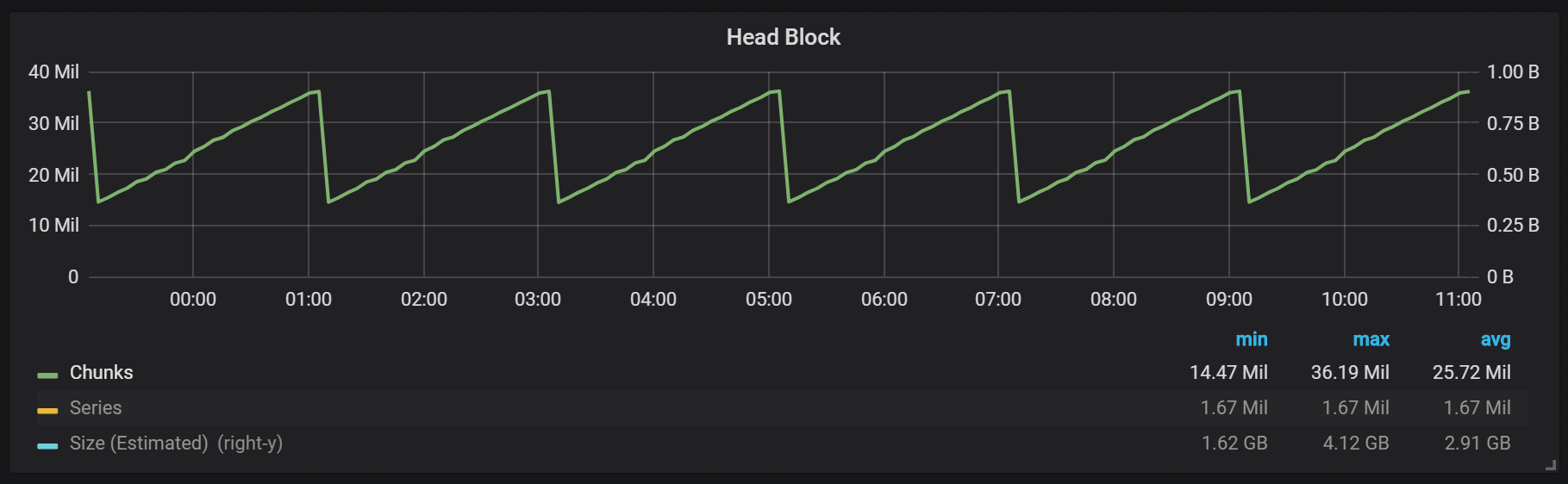
Wie Sie in der Grafik sehen können, werden alle zwei Stunden Festplatten geleert. Wenn Sie den Parameter min-block-duration auf eine Stunde ändern, treten diese Entladungen stündlich ab einer halben Stunde auf.
Wenn Sie diese und andere Grafiken in Ihrer Prometheus-Installation verwenden möchten, können Sie dieses Dashboard verwenden . Es wurde für PMM entwickelt, eignet sich jedoch mit geringfügigen Änderungen für jede Installation von Prometheus.Wir haben einen aktiven Block namens Kopfblock, der im Speicher gespeichert ist. Auf Blöcke mit älteren Daten kann über
mmap() . Dadurch entfällt die Notwendigkeit, den Cache separat zu konfigurieren, aber Sie müssen auch genügend Speicherplatz für den Betriebssystem-Cache lassen, wenn Sie Daten anfordern möchten, die älter als der Headblock sind.
Dies bedeutet auch, dass der Verbrauch des virtuellen Prometheus-Speichers ziemlich hoch sein wird, worüber Sie sich keine Sorgen machen sollten.

Ein weiterer interessanter Entwurfspunkt ist die Verwendung von WAL (Write Ahead Log). Wie Sie der Speicherdokumentation entnehmen können, verwendet Prometheus WAL, um Verluste durch Stürze zu vermeiden. Die spezifischen Mechanismen zur Sicherstellung der Datenüberlebensfähigkeit sind leider nicht gut dokumentiert. Prometheus Version 2.3.2 leert die WAL alle 10 Sekunden auf die Festplatte, und dieser Parameter kann nicht vom Benutzer konfiguriert werden.
Dichtungen (Verdichtungen)
Prometheus TSDB basiert auf dem Image eines LSM-Repositorys (Log Structured Merge - ein logstrukturierter Baum mit Zusammenführung): Der Kopfblock wird regelmäßig auf die Festplatte geleert, während der Komprimierungsmechanismus mehrere Blöcke miteinander kombiniert, um das Scannen zu vieler Blöcke während Anforderungen zu verhindern. Hier sehen Sie die Anzahl der Blöcke, die ich nach einem Arbeitstag auf dem Testsystem beobachtet habe.
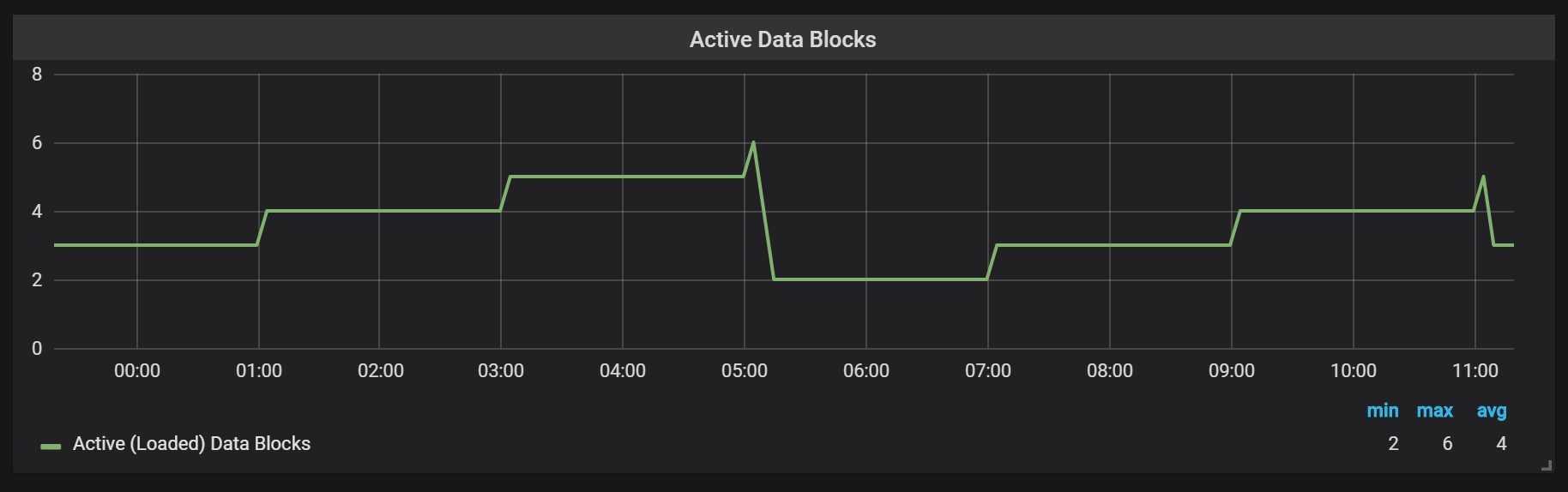
Wenn Sie mehr über das Repository erfahren möchten, können Sie die Datei meta.json lesen, die Informationen zu den verfügbaren Blöcken und deren Darstellung enthält.
{ "ulid": "01CPZDPD1D9R019JS87TPV5MPE", "minTime": 1536472800000, "maxTime": 1536494400000, "stats": { "numSamples": 8292128378, "numSeries": 1673622, "numChunks": 69528220 }, "compaction": { "level": 2, "sources": [ "01CPYRY9MS465Y5ETM3SXFBV7X", "01CPYZT0WRJ1JB1P0DP80VY5KJ", "01CPZ6NR4Q3PDP3E57HEH760XS" ], "parents": [ { "ulid": "01CPYRY9MS465Y5ETM3SXFBV7X", "minTime": 1536472800000, "maxTime": 1536480000000 }, { "ulid": "01CPYZT0WRJ1JB1P0DP80VY5KJ", "minTime": 1536480000000, "maxTime": 1536487200000 }, { "ulid": "01CPZ6NR4Q3PDP3E57HEH760XS", "minTime": 1536487200000, "maxTime": 1536494400000 } ] }, "version": 1 }
Siegel in Prometheus sind an die Zeit gebunden, als ein Kopfblock auf die Scheibe gespült wurde. Zu diesem Zeitpunkt können mehrere solcher Operationen ausgeführt werden.
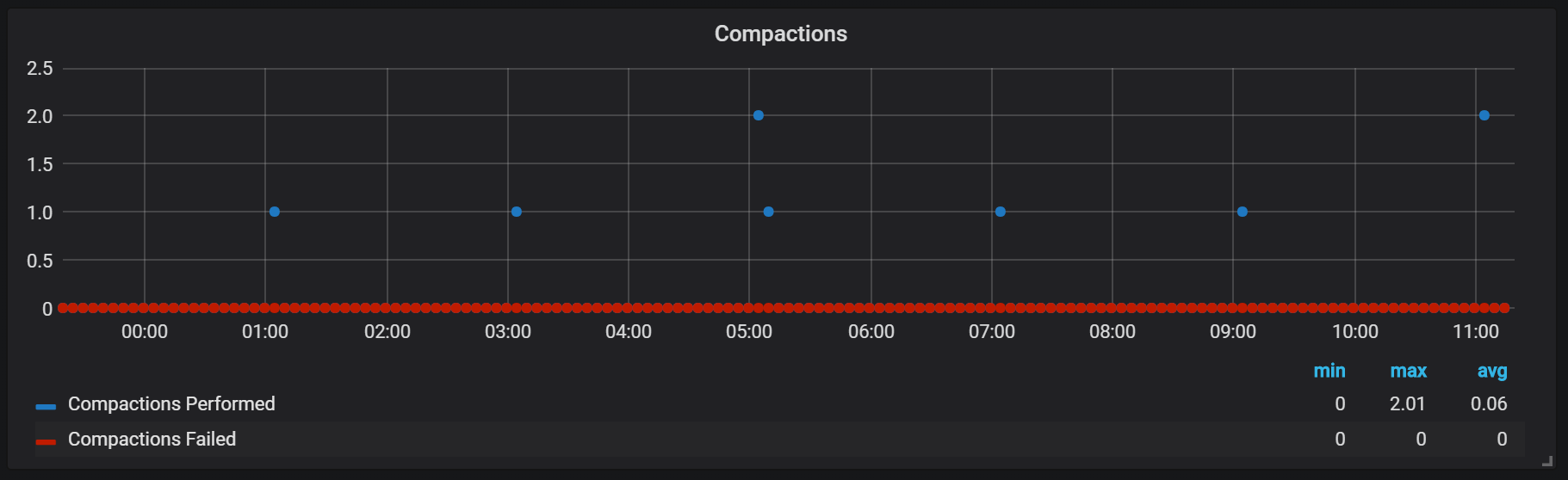
Anscheinend sind Siegel in keiner Weise unbegrenzt und können zur Laufzeit große Festplatten-E / A-Sprünge verursachen.

CPU-Download-Spitzen

Dies wirkt sich natürlich negativ auf die Geschwindigkeit des Systems aus und ist auch eine ernsthafte Herausforderung für den LSM-Speicher: Wie werden Siegel hergestellt, um hohe Abfragegeschwindigkeiten zu unterstützen und nicht zu viel Overhead zu verursachen?
Interessant ist auch die Verwendung von Speicher bei der Verdichtung.

Wir können sehen, wie nach der Komprimierung der größte Teil des Speichers den Status von zwischengespeichert in frei ändert: Dies bedeutet, dass potenziell wertvolle Informationen von dort entfernt wurden. Es ist merkwürdig, ob hier
fadvice() oder eine andere Minimierungstechnik verwendet wird, oder liegt dies daran, dass der Cache von Blöcken befreit wurde, die während der Komprimierung zerstört wurden?
Crash Recovery
Die Wiederherstellung nach einem Katastrophenfall braucht Zeit und ist gerechtfertigt. Bei einem eingehenden Datenstrom von einer Million Datensätzen pro Sekunde musste ich etwa 25 Minuten warten, während die Wiederherstellung unter Berücksichtigung des SSD-Laufwerks durchgeführt wurde.
level=info ts=2018-09-13T13:38:14.09650965Z caller=main.go:222 msg="Starting Prometheus" version="(version=2.3.2, branch=v2.3.2, revision=71af5e29e815795e9dd14742ee7725682fa14b7b)" level=info ts=2018-09-13T13:38:14.096599879Z caller=main.go:223 build_context="(go=go1.10.1, user=Jenkins, date=20180725-08:58:13OURCE)" level=info ts=2018-09-13T13:38:14.096624109Z caller=main.go:224 host_details="(Linux 4.15.0-32-generic #35-Ubuntu SMP Fri Aug 10 17:58:07 UTC 2018 x86_64 1bee9e9b78cf (none))" level=info ts=2018-09-13T13:38:14.096641396Z caller=main.go:225 fd_limits="(soft=1048576, hard=1048576)" level=info ts=2018-09-13T13:38:14.097715256Z caller=web.go:415 component=web msg="Start listening for connections" address=:9090 level=info ts=2018-09-13T13:38:14.097400393Z caller=main.go:533 msg="Starting TSDB ..." level=info ts=2018-09-13T13:38:14.098718401Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536530400000 maxt=1536537600000 ulid=01CQ0FW3ME8Q5W2AN5F9CB7R0R level=info ts=2018-09-13T13:38:14.100315658Z caller=web.go:467 component=web msg="router prefix" prefix=/prometheus level=info ts=2018-09-13T13:38:14.101793727Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536732000000 maxt=1536753600000 ulid=01CQ78486TNX5QZTBF049PQHSM level=info ts=2018-09-13T13:38:14.102267346Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536537600000 maxt=1536732000000 ulid=01CQ78DE7HSQK0C0F5AZ46YGF0 level=info ts=2018-09-13T13:38:14.102660295Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536775200000 maxt=1536782400000 ulid=01CQ7SAT4RM21Y0PT5GNSS146Q level=info ts=2018-09-13T13:38:14.103075885Z caller=repair.go:39 component=tsdb msg="found healthy block" mint=1536753600000 maxt=1536775200000 ulid=01CQ7SV8WJ3C2W5S3RTAHC2GHB level=error ts=2018-09-13T14:05:18.208469169Z caller=wal.go:275 component=tsdb msg="WAL corruption detected; truncating" err="unexpected CRC32 checksum d0465484, want 0" file=/opt/prometheus/data/.prom2-data/wal/007357 pos=15504363 level=info ts=2018-09-13T14:05:19.471459777Z caller=main.go:543 msg="TSDB started" level=info ts=2018-09-13T14:05:19.471604598Z caller=main.go:603 msg="Loading configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499156711Z caller=main.go:629 msg="Completed loading of configuration file" filename=/etc/prometheus.yml level=info ts=2018-09-13T14:05:19.499228186Z caller=main.go:502 msg="Server is ready to receive web requests."
Das Hauptproblem des Wiederherstellungsprozesses ist der hohe Speicherverbrauch. Trotz der Tatsache, dass der Server in einer normalen Situation stabil mit der gleichen Speichermenge arbeiten kann, kann es bei einem Absturz aufgrund von OOM nicht zu einem Anstieg kommen. Die einzige Lösung, die ich gefunden habe, war, die Datenerfassung zu deaktivieren, den Server zu erhöhen, ihn wiederherzustellen und mit der bereits aktivierten Erfassung neu zu starten.
Aufwärmen
Ein weiteres Verhalten, an das Sie sich beim Aufwärmen erinnern sollten, ist das Verhältnis von geringer Produktivität und hohem Ressourcenverbrauch direkt nach dem Start. Während einiger, aber nicht aller Starts stellte ich eine ernsthafte Belastung der CPU und des Speichers fest.
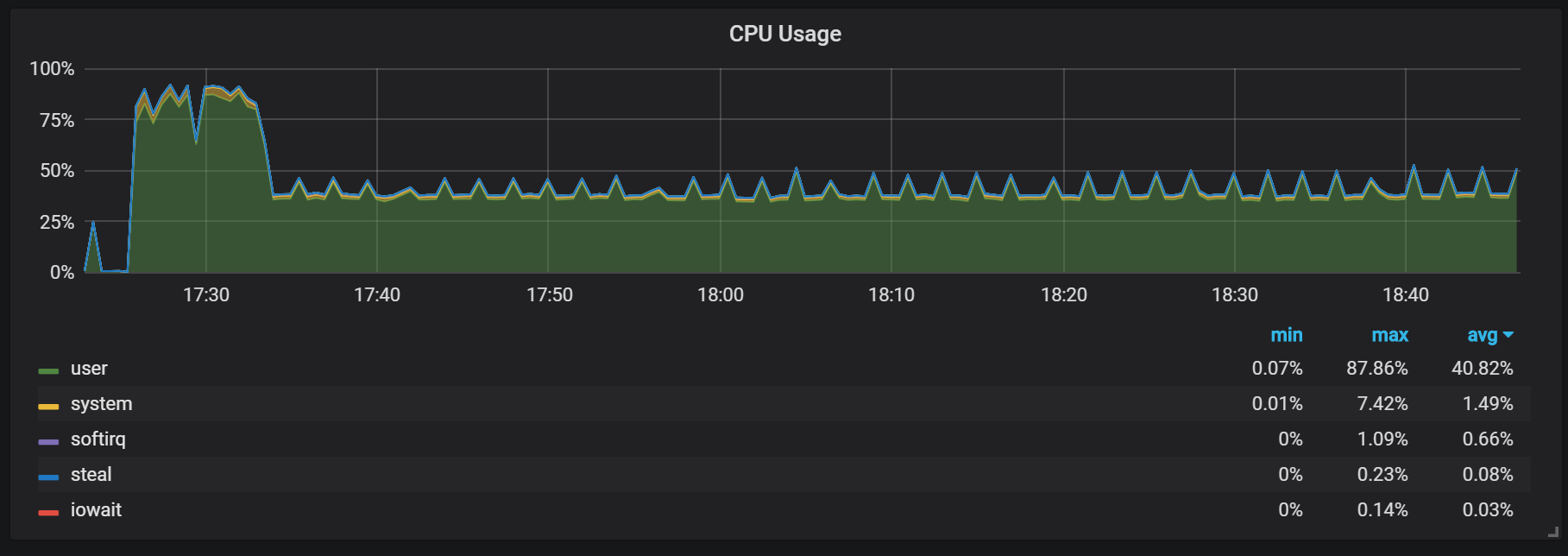

Speicherlücken weisen darauf hin, dass Prometheus nicht von Anfang an alle Gebühren konfigurieren kann und einige Informationen verloren gehen.
Ich habe die genauen Gründe für die hohe Belastung des Prozessors und des Speichers nicht herausgefunden. Ich vermute, dass dies auf die Erstellung neuer Zeitreihen im Kopfblock mit hoher Frequenz zurückzuführen ist.
CPU-Lastspitzen
Zusätzlich zu den Dichtungen, die eine ziemlich hohe E / A-Last erzeugen, bemerkte ich alle zwei Minuten ernsthafte Lastsprünge auf dem Prozessor. Bursts dauern länger mit einem hohen eingehenden Stream und es sieht so aus, als würden sie vom Go-Garbage-Collector verursacht. Zumindest einige Kernel sind vollständig geladen.

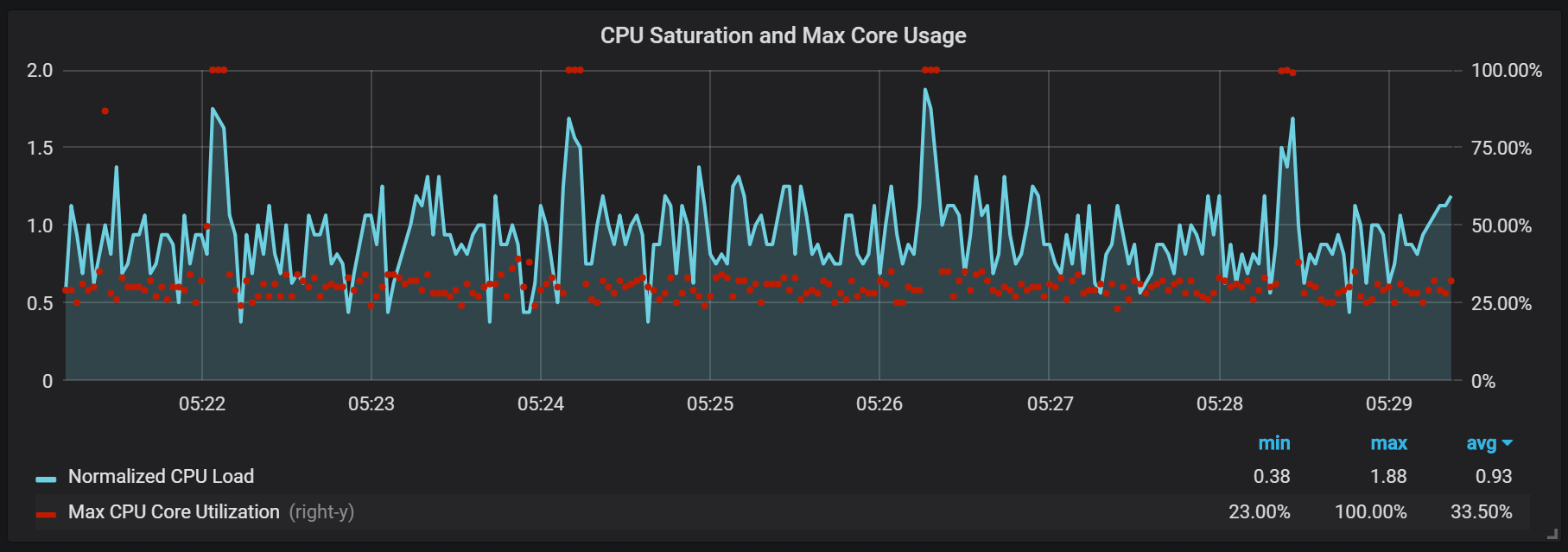
Diese Sprünge sind nicht so unbedeutend. Es scheint, dass der interne Einstiegspunkt und die Prometheus-Metriken nicht mehr zugänglich sind, wenn sie auftreten, was zu Datenlücken in denselben Zeitintervallen führt.
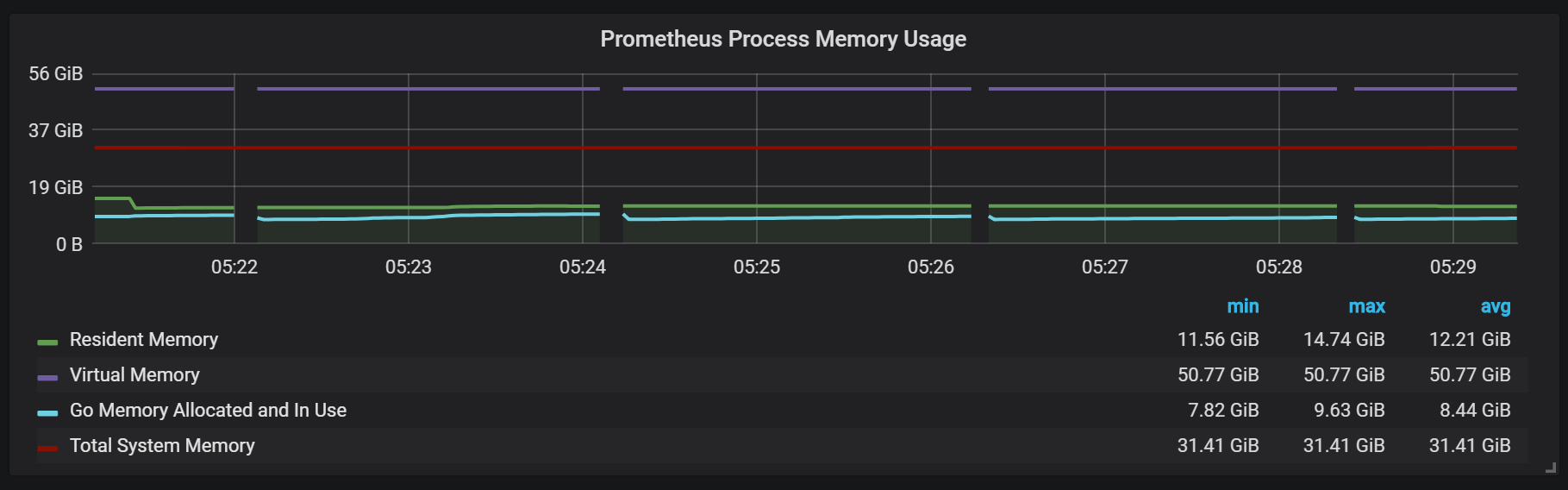
Sie können auch feststellen, dass der Prometheus-Exporteur für eine Sekunde geschlossen bleibt.
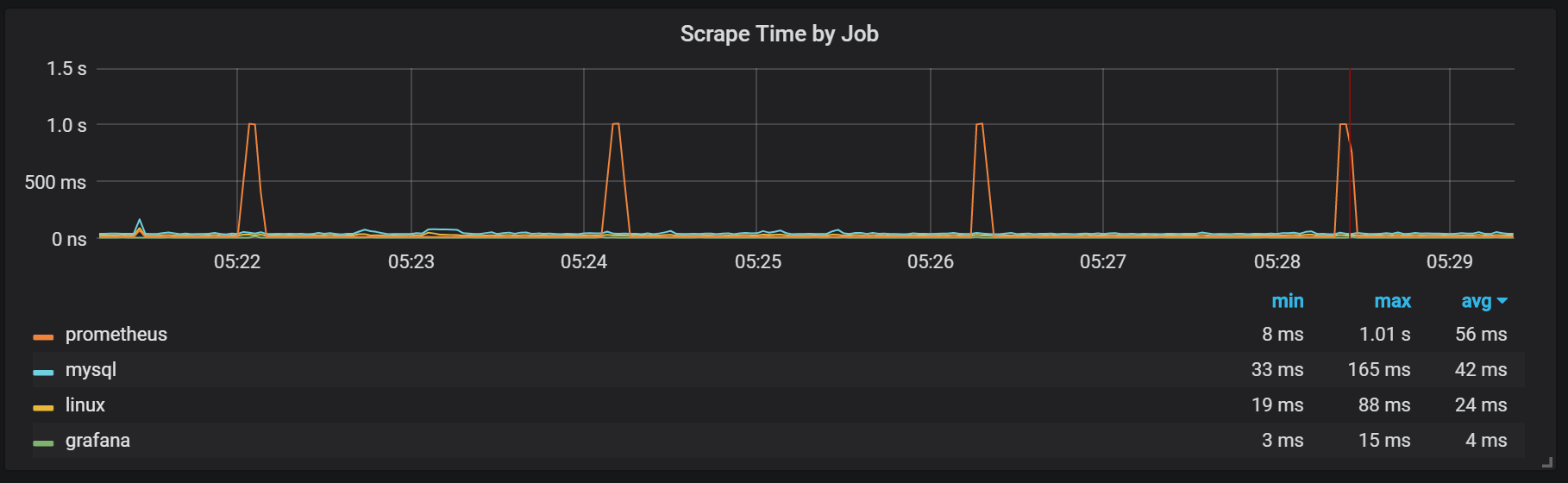
Wir können Korrelationen mit der Garbage Collection (GC) erkennen.

Fazit
TSDB in Prometheus 2 ist schnell, kann Millionen von Zeitreihen verarbeiten und gleichzeitig Tausende von Aufnahmen pro Sekunde mit relativ bescheidener Hardware aufnehmen. Beeindruckend ist auch die Auslastung der CPU- und Festplatten-E / A. In meinem Beispiel wurden bis zu 200.000 Metriken pro Sekunde und verwendetem Kern angezeigt.
Um die Erweiterung zu planen, müssen Sie sich an ausreichende Speichervolumina erinnern. Dies sollte realer Speicher sein. Die Menge des verwendeten Speichers, die ich beobachtete, betrug ungefähr 5 GB pro 100.000 Einträge pro Sekunde des eingehenden Streams, was zusammen mit dem Betriebssystem-Cache ungefähr 8 GB belegten Speicher ergab.
Natürlich gibt es noch viel Arbeit, um die Bursts von CPU- und Festplatten-E / A zu zähmen, und dies ist nicht überraschend, wenn man bedenkt, wie jung die TSDB Prometheus 2 im Vergleich zu InnoDB, TokuDB, RocksDB, WiredTiger ist, aber alle hatten zu Beginn des Lebenszyklus ähnliche Probleme.