
Die Logik der Maschinen ist einwandfrei, sie machen keine Fehler, wenn ihr Algorithmus korrekt funktioniert und die eingestellten Parameter den erforderlichen Standards entsprechen. Bitten Sie das Auto, eine Route von Punkt A nach Punkt B zu wählen, und es wird die optimalste Route unter Berücksichtigung der Entfernung, des Kraftstoffverbrauchs, des Vorhandenseins von Tankstellen usw. erstellen. Dies ist eine reine Berechnung. Das Auto wird nicht sagen: "Lass uns diese Straße entlang gehen, ich fühle diese Route besser." Vielleicht sind Autos in der Geschwindigkeit der Berechnungen besser als wir, aber die Intuition ist immer noch einer unserer Trümpfe. Die Menschheit hat Jahrzehnte damit verbracht, eine Maschine zu entwickeln, die dem menschlichen Gehirn ähnlich ist. Aber haben sie so viel gemeinsam? Heute werden wir eine Studie betrachten, in der Wissenschaftler, die an der unübertroffenen "Vision" der Maschine auf der Grundlage von Faltungs-Neuronalen Netzen zweifelten, ein Experiment durchführten, um ein Objekterkennungssystem mit einem Algorithmus zu täuschen, dessen Aufgabe es war, "gefälschte" Bilder zu erstellen. Wie erfolgreich war die Sabotageaktivität des Algorithmus, haben die Menschen die Erkennung besser bewältigt als Autos, und was wird diese Studie für die Zukunft dieser Technologie bringen? Antworten finden wir im Bericht der Wissenschaftler. Lass uns gehen.
Studienbasis
Objekterkennungstechnologien, die Faltungs-Neuronale Netze (SNS) verwenden, ermöglichen es der Maschine grob gesagt, einen Schwan von der Nummer 9 oder eine Katze von einem Fahrrad zu unterscheiden. Diese Technologie entwickelt sich recht schnell und wird derzeit in verschiedenen Bereichen eingesetzt, von denen der offensichtlichste die Herstellung unbemannter Fahrzeuge ist. Viele sind der Meinung, dass die SNA des Systems zur Erkennung von Objekten als Modell des menschlichen Sehens angesehen werden kann. Diese Aussage ist jedoch aufgrund des menschlichen Faktors zu laut. Die Sache ist, dass es sich als einfacher herausstellte, ein Auto zu täuschen, als eine Person zu täuschen (zumindest in Bezug auf die Objekterkennung). SNA-Systeme sind sehr anfällig für die Auswirkungen böswilliger Algorithmen (wenn Sie dies wünschen, feindlich), die sie in jeder Hinsicht daran hindern, ihre Aufgabe korrekt auszuführen, und Bilder erstellen, die vom SNA-System falsch klassifiziert werden.
Die Forscher teilen solche Bilder in zwei Kategorien ein: "Narren" (das Ziel vollständig ändern) und "peinlich" (das Ziel teilweise ändern). Die ersten sind bedeutungslose Bilder, die vom System als etwas Vertrautes erkannt werden. Beispielsweise kann eine Reihe von Linien als "Baseball" und mehrfarbiges digitales Rauschen als "Gürteltier" klassifiziert werden. Die zweite Kategorie von Bildern („peinlich“) sind Bilder, die unter normalen Bedingungen korrekt klassifiziert würden, aber der böswillige Algorithmus verzerrt sie in den Augen des SNA-Systems leicht, übertrieben übertrieben. Beispielsweise wird die handschriftliche Nummer 6 aufgrund eines kleinen Komplements von mehreren Pixeln als Nummer 5 klassifiziert.
Stellen Sie sich vor, welchen Schaden solche Algorithmen anrichten können. Es lohnt sich, die Klassifizierung der Verkehrszeichen gegen autonomen Verkehr auszutauschen, und Unfälle sind unvermeidlich.
Nachfolgend finden Sie die „gefälschten“ Bilder, die das SNA-System täuschen, das darauf trainiert ist, Objekte zu erkennen, und wie ein ähnliches System sie klassifiziert.
 Bild Nr. 1
Bild Nr. 1Serienerklärung:
- und - indirekt verschlüsselte "betrügerische" Bilder;
- b - direkt codierte "betrügerische" Bilder;
- c - „peinliche“ Bilder, die das System zwingen, eine Ziffer als eine andere zu klassifizieren;
- d - LaVAN-Angriffe (lokalisiertes und sichtbares gegnerisches / böswilliges Rauschen) können zu einer falschen Klassifizierung führen, selbst wenn sich das „Rauschen“ nur an einem Punkt befindet (in der unteren rechten Ecke).
- e - dreidimensionale Objekte, die aus verschiedenen Winkeln falsch klassifiziert wurden.
Das Merkwürdigste daran ist, dass eine Person möglicherweise nicht dem Erliegen eines böswilligen Algorithmus erliegt und Bilder basierend auf ihrer Intuition korrekt klassifiziert. Bisher hat, wie Wissenschaftler sagen, niemand einen praktischen Vergleich der Fähigkeiten einer Maschine und einer Person in einem Experiment durchgeführt, um böswilligen Algorithmen gefälschter Bilder entgegenzuwirken. Dafür haben sich die Forscher entschieden.
Zu diesem Zweck wurden mehrere Bilder erstellt, die mit böswilligen Algorithmen erstellt wurden. Den Probanden wurde gesagt, dass die Maschine diese (vorderen) Bilder als vertraute Objekte klassifizierte, d.h. Die Maschine hat sie nicht richtig erkannt. Die Aufgabe der Probanden bestand darin, genau zu bestimmen, wie die Maschine diese Bilder klassifizierte, d.h. Was sie denken, dass die Maschine in den Bildern gesehen hat, ist diese Klassifizierung wahr usw.
Insgesamt wurden 8 Experimente durchgeführt, bei denen 5 Arten von böswilligen Bildern verwendet wurden, die ohne Berücksichtigung des menschlichen Sehens erstellt wurden. Mit anderen Worten, sie werden von Maschine zu Maschine erstellt. Die Ergebnisse dieser Experimente erwiesen sich als sehr unterhaltsam, aber wir werden sie nicht verderben und alles in Ordnung bringen.
Versuchsergebnisse
Experiment Nr. 1: Bilder mit ungültigen Tags täuschen
Im ersten Experiment wurden 48 getäuschte Bilder verwendet, die vom Algorithmus erstellt wurden, um dem auf dem SNA namens AlexNet basierenden Erkennungssystem entgegenzuwirken. Dieses System klassifizierte diese Bilder als "Zahnrad" und "Donut" (
2a ).
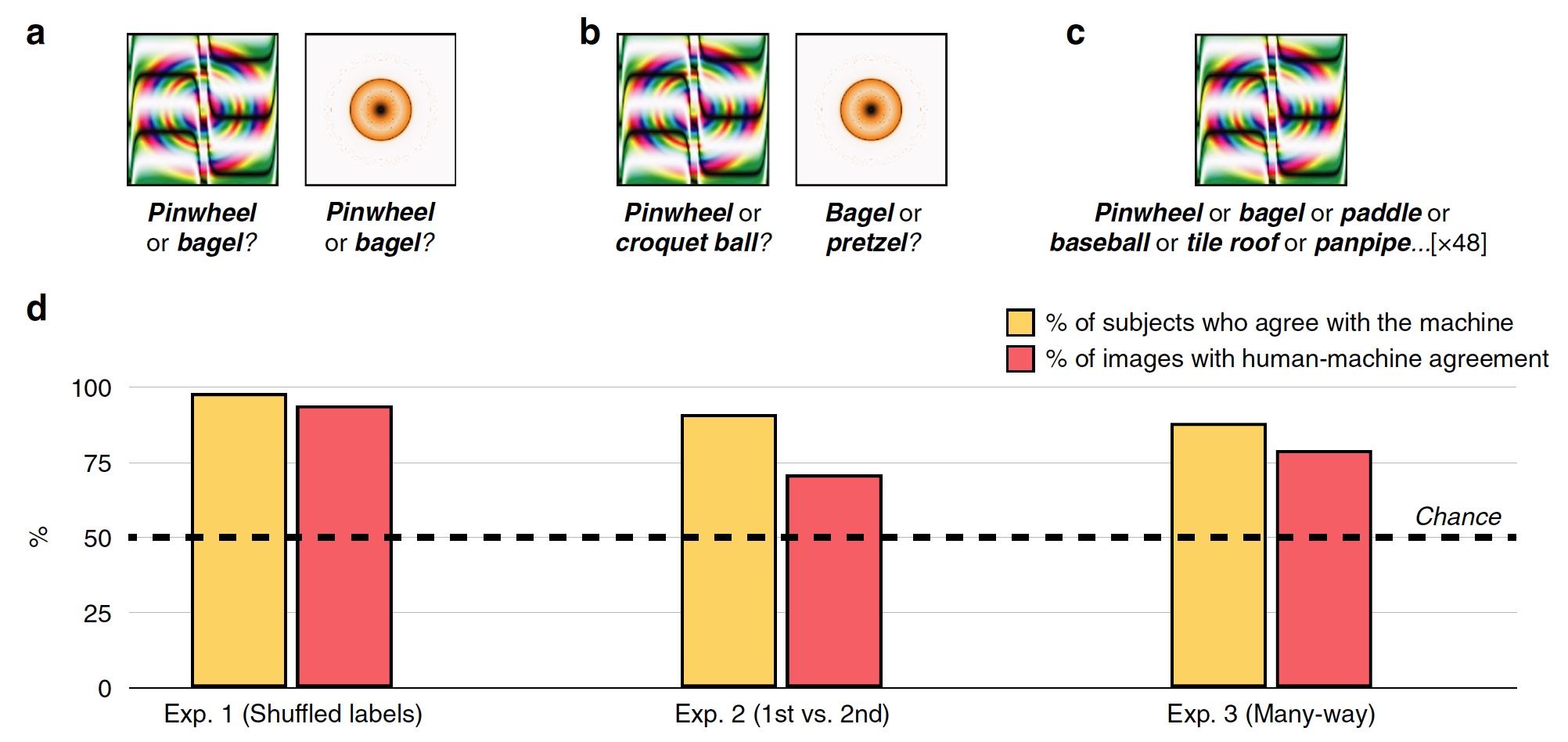 Bild Nr. 2
Bild Nr. 2Während jedes Versuchs sah die Testperson, von der es 200 gab, ein betrügerisches Bild und zwei Markierungen, d.h. Klassifizierungsetiketten: System-SNS-Etikett und zufällig aus den anderen 47 Bildern. Die Probanden mussten das Etikett auswählen, das von der Maschine erstellt wurde.
Infolgedessen entschieden sich die meisten Probanden für eine von der Maschine erstellte Beschriftung anstelle einer Beschriftung eines böswilligen Algorithmus. Klassifizierungsgenauigkeit, d.h. Der Grad der Zustimmung des Probanden zur Maschine betrug 74%. Statistisch gesehen wählten 98% der Probanden Maschinen-Tags auf einer höheren Ebene als die statistische Zufälligkeit (
2d , „% der Probanden stimmen mit der Maschine überein“). 94% der Bilder zeigten eine sehr hohe Mensch-Maschine-Ausrichtung, dh von 48 wurden nur 3 Bilder von Personen anders als eine Maschine klassifiziert.
So zeigten die Probanden, dass eine Person in der Lage ist, ein reales Bild und einen Narren zu teilen, dh gemäß einem auf der SNA basierenden Programm zu handeln.
Experiment Nr. 2: erste Wahl gegen zweite
Die Forscher stellten die Frage - aufgrund dessen, welche Probanden Bilder so gut erkennen und von fehlerhaften Markierungen und betrügerischen Bildern trennen konnten? Vielleicht haben die Probanden den orange-gelben Ring als „Donut“ bezeichnet, weil der Donut in Wirklichkeit genau diese Form hat und ungefähr dieselbe Farbe hat. In Anerkennung könnten Assoziationen und intuitive Entscheidungen, die auf Erfahrung und Wissen basieren, einer Person helfen.
Um dies zu überprüfen, wurde das zufällige Etikett durch das Etikett ersetzt, das von der Maschine als zweite mögliche Klassifizierungsoption ausgewählt wurde. Zum Beispiel klassifizierte AlexNet den orange-gelben Ring als „Donut“, und die zweite Option für dieses Programm war „Brezel“.
Die Probanden standen vor der Aufgabe, die erste Markierung der Maschine oder diejenige zu wählen, die für alle 48 Bilder (
2s ) den zweiten Platz
einnahm .
Die Grafik in der Mitte von Bild
2d zeigt die Ergebnisse dieses Tests: 91% der Probanden wählten die erste Version des Etiketts, und der Grad der Mensch-Maschine-Übereinstimmung betrug 71%.
Experiment Nr. 3: Multithread-Klassifizierung
Die oben beschriebenen Experimente sind recht einfach, da die Probanden zwischen zwei möglichen Antworten wählen können (Maschinen-Tag und Zufalls-Tag). Tatsächlich durchläuft die Maschine bei der Bilderkennung Hunderte und sogar Tausende von Optionen für Etiketten, bevor sie die am besten geeignete auswählt.
Bei diesem Test befanden sich alle Markierungen für 48 Bilder unmittelbar vor den Probanden. Sie mussten aus diesem Set das für jedes Bild am besten geeignete auswählen.
Infolgedessen wählten 88% der Probanden genau die gleichen Etiketten wie die Maschine, und der Koordinationsgrad betrug 79%. Eine interessante Tatsache ist, dass selbst bei der Auswahl des falschen Etiketts, das von der Maschine ausgewählt wurde, die Probanden in 63% dieser Fälle eines der Top-5-Etiketten auswählten. Das heißt, alle Markierungen auf dem Auto sind in einer Liste von den am besten geeigneten bis zu den unangemessensten geordnet (übertriebenes Beispiel: „Bagel“, „Brezel“, „Gummiring“, „Reifen“ usw. bis hin zu „Falke am Nachthimmel“). )
Versuch Nr. 3b: "Was ist das?"
In diesem Test haben Wissenschaftler die Regeln leicht geändert. Anstatt sie zu fragen, welches Etikett die Maschine für ein bestimmtes Bild wählen soll, wurden die Probanden einfach gefragt, was sie vor sich sehen.
Erkennungssysteme, die auf Faltungs-Neuronalen Netzen basieren, wählen die geeignete Bezeichnung für ein bestimmtes Bild aus. Dies ist ein ziemlich klarer und logischer Prozess. In diesem Test zeigen die Probanden intuitives Denken.
Infolgedessen wählten 90% der Probanden ein Etikett, das auch von der Maschine ausgewählt wurde. Die Mensch-Maschine-Ausrichtung zwischen den Bildern betrug 81%.
Experiment 4: Statisches Fernsehrauschen
Wissenschaftler stellen fest, dass Bilder in früheren Experimenten ungewöhnlich sind, aber unterscheidbare Merkmale aufweisen, die die Probanden dazu veranlassen können, die richtige (oder falsche) Wahl des Etiketts zu treffen. Zum Beispiel ist das Bild „Baseball“ kein Ball, aber es gibt Linien und Farben, die auf einem echten Baseballball vorhanden sind. Dies ist ein auffälliges Unterscheidungsmerkmal. Aber wenn das Bild keine solchen Merkmale aufweist, sondern im Wesentlichen statisches Rauschen ist, kann eine Person dann zumindest etwas darauf erkennen? Das wurde beschlossen zu überprüfen.
 Bild Nr. 3a
Bild Nr. 3aIn diesem Test befanden sich 8 Bilder mit Statik vor den Probanden, die das SNS-System als spezifisches Objekt erkennt (z. B. eine Vogel-Zaryanka). Außerdem befanden sich vor den Probanden ein Etikett und damit verbundene normale Bilder (8 statische Bilder, 1 Etikett „Zaryanka“ und 5 Fotos dieses Vogels). Die Testperson musste 1 von 8 statischen Bildern auswählen, die am besten zu dem einen oder anderen Etikett passen.
Sie können sich selbst testen. Oben sehen Sie ein Beispiel für einen solchen Test. Welches der drei Bilder passt am besten zum Tag „Zaryanka“ und warum?
81% der Probanden wählten das Etikett, das die Maschine wählte. Gleichzeitig wurden 75% der Bilder von den Probanden mit der nach Ansicht der Maschine am besten geeigneten Beschriftung beschriftet (aus einer Reihe von Optionen, wie bereits erwähnt).
Für diesen speziellen Test haben Sie möglicherweise Fragen, genau wie meine. Tatsache ist, dass ich in der vorgeschlagenen Statik (oben) persönlich drei ausgeprägte Merkmale sehe, die sie voneinander unterscheiden. Und nur in einem Bild ähnelt dieses Merkmal stark der gleichen Zaryanka (ich denke, Sie verstehen, welches Bild der drei). Daher ist meine persönliche und sehr subjektive Meinung, dass ein solcher Test nicht besonders aussagekräftig ist. Obwohl vielleicht unter anderem Optionen für statische Bilder wirklich nicht zu unterscheiden und nicht wiederzuerkennen waren.
Experiment Nr. 5: "zweifelhafte" Zahlen
Die oben beschriebenen Tests basierten auf Bildern, die nicht sofort vollständig und ohne Zweifel als das eine oder andere Objekt klassifiziert werden können. Es gibt immer einen Bruchteil der Zweifel. Die täuschenden Bilder sind in ihrer Arbeit ziemlich einfach - um das Bild bis zur Unkenntlichkeit zu verderben. Es gibt jedoch eine zweite Art von böswilligen Algorithmen, die nur ein kleines Detail im Bild hinzufügen (oder entfernen), wodurch das Erkennungssystem des SNA-Systems vollständig verletzt werden kann. Fügen Sie ein paar Pixel hinzu, und die Zahl 6 wird auf magische Weise zur Zahl 5 (
1s ).
Wissenschaftler halten solche Algorithmen für einen der gefährlichsten. Sie können das Bild-Tag leicht ändern, und das unbemannte Fahrzeug berücksichtigt das Tempolimit-Zeichen (z. B. 75 statt 45) falsch, was zu traurigen Konsequenzen führen kann.
 Bild # 3b
Bild # 3bIn diesem Test schlugen die Wissenschaftler vor, dass die Probanden die falsche Antwort wählen, aber eher die falsche. Im Test wurden 100 digitale Bilder verwendet, die durch einen böswilligen Algorithmus geändert wurden (der LeNet SNA hat seine Klassifizierung geändert, dh der böswillige Algorithmus hat erfolgreich funktioniert). Die Probanden mussten sagen, welche Zahl ihrer Meinung nach die Maschine sah. Wie erwartet haben 89% der Probanden diesen Test erfolgreich abgeschlossen.
Experiment 6: Fotos und lokalisierte "Verzerrung"
Wissenschaftler stellen fest, dass sich nicht nur Objekterkennungssysteme entwickeln, sondern auch böswillige Algorithmen, die sie daran hindern. Bisher war es für eine falsche Klassifizierung des Bildes erforderlich, 14% aller Pixel im Zielbild zu verzerren (ändern, löschen, beschädigen usw.). Jetzt ist diese Zahl viel kleiner geworden. Es reicht aus, ein kleines Bild in das Ziel einzufügen, und die Klassifizierung wird verletzt.
 Bild Nr. 4
Bild Nr. 4In diesem Test wurde ein ziemlich neuer böswilliger LaVAN-Algorithmus verwendet, der ein kleines Bild platziert, das an einer Stelle auf dem Zielfoto lokalisiert ist. Infolgedessen kann das Objekterkennungssystem den U-Bahn-Zug als eine Dose Milch erkennen (
4a ). Die wichtigsten Merkmale dieses Algorithmus sind genau der geringe Anteil beschädigter Pixel (nur 2%) des Zielbilds und das Fehlen der Notwendigkeit, es in seiner Gesamtheit oder im Hauptteil (höchstwertigen Teil) zu verzerren.
Im Test wurden 22 durch LaVAN beschädigte Bilder verwendet (das SNA-Erkennungssystem Inception V3 wurde von diesem Algorithmus erfolgreich gehackt). Die Probanden sollten die böswillige Beilage auf dem Foto klassifizieren. 87% der Probanden konnten dies erfolgreich tun.
Experiment 7: dreidimensionale Objekte
Die Bilder, die wir zuvor gesehen haben, sind zweidimensional, wie jedes Foto, Bild oder Zeitungsausschnitt. Die meisten böswilligen Algorithmen bearbeiten genau solche Bilder erfolgreich. Diese Schädlinge können jedoch nur unter bestimmten Bedingungen wirken, dh sie weisen eine Reihe von Einschränkungen auf:
- Komplexität: nur zweidimensionale Bilder;
- Praktische Anwendung: Böswillige Änderungen sind nur auf Systemen möglich, die die empfangenen digitalen Bilder lesen, und nicht auf Bildern von Sensoren und Sensoren.
- Stabilität: Ein böswilliger Angriff verliert seine Stärke, wenn Sie ein zweidimensionales Bild drehen (Größe ändern, zuschneiden, schärfen usw.).
- Menschen: Wir sehen die Welt und die Objekte um uns herum in 3D unter verschiedenen Winkeln, bei Beleuchtung und nicht in Form von zweidimensionalen digitalen Bildern, die aus einem Winkel aufgenommen wurden.
Wie wir jedoch wissen, hat der Fortschritt böswillige Algorithmen nicht verschont. Unter ihnen erschien einer, der nicht nur zweidimensionale, sondern auch dreidimensionale Bilder verzerren kann, was zu einer falschen Klassifizierung durch das Objekterkennungssystem führt. Bei Verwendung von Software für dreidimensionale Grafiken führt ein solcher Algorithmus Klassifizierer, die auf dem SNA (in diesem Fall dem Inception V3-Programm) basieren, aus unterschiedlichen Entfernungen und Betrachtungswinkeln in die Irre. Das Überraschendste ist, dass solche täuschenden 3D-Bilder auf einem geeigneten Drucker gedruckt werden können, d.h. Erstellen Sie ein reales physisches Objekt, und das Objekterkennungssystem klassifiziert es immer noch falsch (z. B. eine Orange als Bohrmaschine). Und das alles dank geringfügiger Änderungen in der Textur auf dem Zielbild (
4b ).
Für ein Objekterkennungssystem ist ein solcher böswilliger Algorithmus ein schwerwiegender Gegner. Aber der Mensch ist keine Maschine, er sieht und denkt anders. In diesem Test gab es vor den Probanden Bilder von dreidimensionalen Objekten, in denen es die oben beschriebenen Texturänderungen aus drei Winkeln gab. Die Probanden erhielten auch die richtige und fehlerhafte Note. Sie mussten feststellen, welche Etiketten korrekt sind, welche nicht und warum, d.h. ob Testpersonen Texturänderungen in Bildern sehen.
Infolgedessen haben 83% der Probanden die Aufgabe erfolgreich abgeschlossen.
Für eine detailliertere Einarbeitung in die Nuancen der Studie empfehle ich dringend, dass Sie sich den
Bericht von Wissenschaftlern ansehen.
Unter
diesem Link finden Sie die Bild-, Daten- und Codedateien, die in der Studie verwendet wurden.
Nachwort
Die durchgeführten Arbeiten gaben Wissenschaftlern die Möglichkeit, eine einfache und ziemlich offensichtliche Schlussfolgerung zu ziehen - die menschliche Intuition kann eine Quelle sehr wichtiger Daten und ein Werkzeug sein, um die richtige Entscheidung und / oder Wahrnehmung von Informationen zu treffen. Eine Person kann intuitiv verstehen, wie sich das Objekterkennungssystem verhält, welche Beschriftungen es wählt und warum.
Die Gründe, warum es für eine Person einfacher ist, ein reales Bild zu sehen und es richtig zu erkennen, sind mehrere. Am offensichtlichsten ist die Methode, Informationen zu erhalten: Die Maschine empfängt ein Bild in digitaler Form, und eine Person sieht es mit eigenen Augen. Für eine Maschine ist ein Bild ein Datensatz, an dem Änderungen vorgenommen werden, deren Klassifizierung Sie verzerren können. Für uns wird das Bild eines U-Bahn-Zuges immer ein U-Bahn-Zug sein, keine Dose Milch, weil wir es sehen.
Wissenschaftler betonen auch, dass solche Tests schwer zu bewerten sind, weil eine Person keine Maschine ist und eine Maschine keine Person. Zum Beispiel sprechen Forscher über den Test mit einem „Donut“ und einem „Rad“. Diese Bilder ähneln dem „Donut“ und dem „Rad“, da das Erkennungssystem sie so klassifiziert. Eine Person sieht, dass sie wie ein "Donut" und "Rad" aussieht, aber sie sind es nicht. Dies ist der grundlegende Unterschied in der Wahrnehmung visueller Informationen zwischen einer Person und einem Programm.
Vielen Dank für Ihre Aufmerksamkeit, bleiben Sie neugierig und haben Sie eine gute Arbeitswoche, Jungs.
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden empfehlen, einen
Rabatt von 30% für Habr-Benutzer auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s von $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s bis zum Sommer kostenlos, wenn Sie für einen Zeitraum von sechs Monaten bezahlen, können Sie
hier bestellen.
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel Dodeca-Core Xeon E5-2650v4 128 GB DDR4 6 x 480 GB SSD 1 Gbit / s 100 TV von 249 US-Dollar in den Niederlanden und den USA! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?