Was kann ein großes Unternehmen wie Lamoda mit einem optimierten Prozess und Dutzenden miteinander verbundener Dienste dazu bringen, den Ansatz erheblich zu ändern? Die Motivation kann völlig anders sein: von der Gesetzgebung bis zum Wunsch aller Programmierer, zu experimentieren.
Dies bedeutet jedoch keineswegs, dass man nicht mit zusätzlichen Vorteilen rechnen kann. Was genau gewonnen werden kann, wenn Sie die ereignisgesteuerte API auf Kafka implementieren, wird Sergey Zaika (
Fewald ) sagen. Auch über ausgestopfte Beulen und interessante Entdeckungen wird es sicherlich geben - ein Experiment kann nicht ohne sie auskommen.
 Haftungsausschluss: Dieser Artikel basiert auf den Materialien des Mitaps, den Sergey im November 2018 auf HighLoad ++ gehalten hat. Lamodas Live-Erfahrung mit Kafka zog die Zuhörer nicht weniger an als andere Zeitplanberichte. Es scheint uns, dass dies ein großartiges Beispiel dafür ist, dass es immer möglich und notwendig ist, Gleichgesinnte zu finden, und die Organisatoren von HighLoad ++ werden weiterhin versuchen, eine Atmosphäre zu schaffen, die dies fördert.
Haftungsausschluss: Dieser Artikel basiert auf den Materialien des Mitaps, den Sergey im November 2018 auf HighLoad ++ gehalten hat. Lamodas Live-Erfahrung mit Kafka zog die Zuhörer nicht weniger an als andere Zeitplanberichte. Es scheint uns, dass dies ein großartiges Beispiel dafür ist, dass es immer möglich und notwendig ist, Gleichgesinnte zu finden, und die Organisatoren von HighLoad ++ werden weiterhin versuchen, eine Atmosphäre zu schaffen, die dies fördert.Über den Prozess
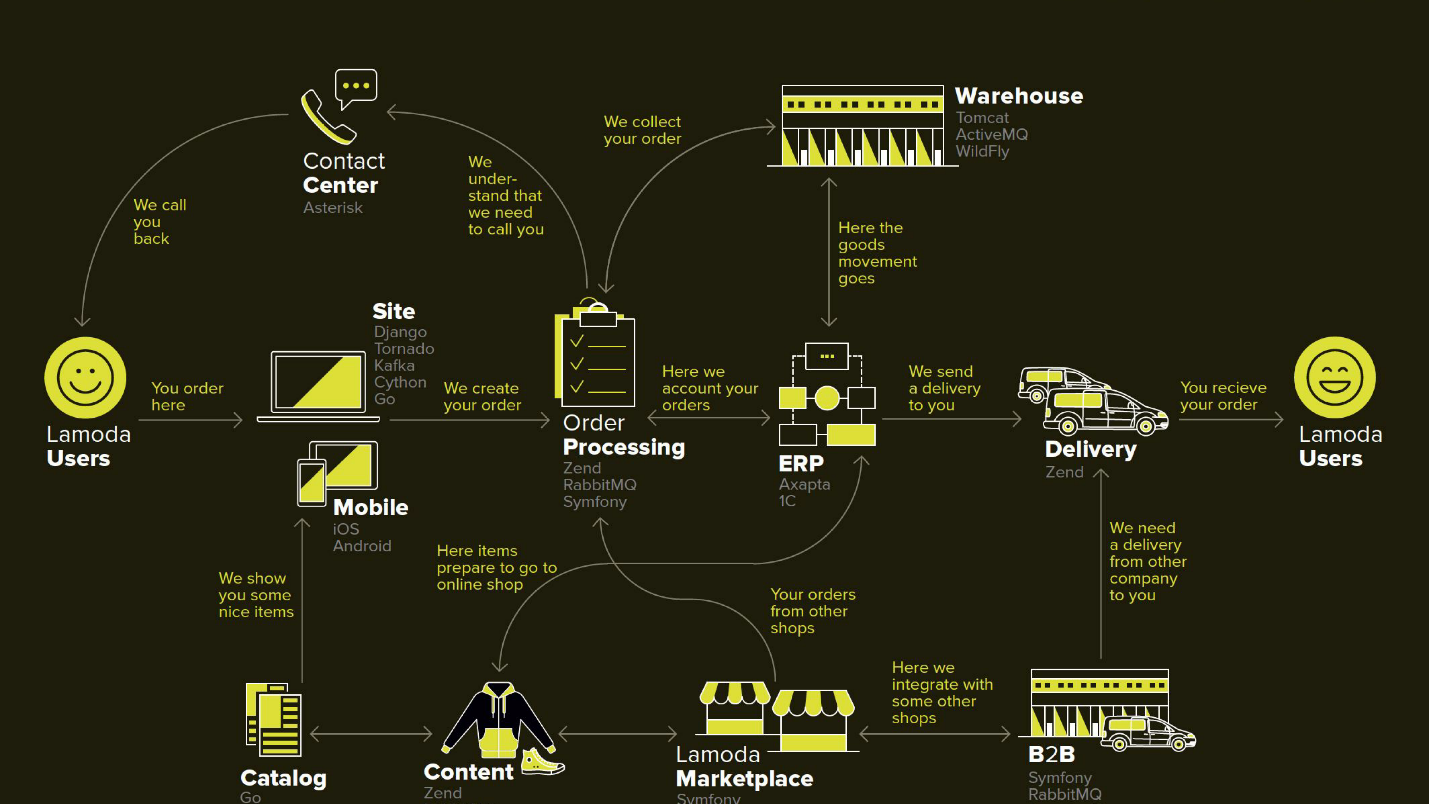
Lamoda ist eine große E-Commerce-Plattform, die über ein eigenes Contact Center, einen Lieferservice (und viele verbundene Unternehmen), ein Fotostudio, ein riesiges Lager und alles verfügt, was mit ihrer Software funktioniert. Es gibt Dutzende von Zahlungsmethoden, B2B-Partner, die einen Teil oder alle dieser Dienste nutzen können und die neuesten Informationen zu ihren Produkten erhalten möchten. Darüber hinaus ist Lamoda neben der Russischen Föderation in drei Ländern tätig, und dort ist alles etwas anders. Insgesamt gibt es wahrscheinlich mehr als hundert Möglichkeiten, eine neue Bestellung zu konfigurieren, die auf ihre eigene Weise verarbeitet werden muss. All dies funktioniert mit Hilfe von Dutzenden von Diensten, die manchmal auf nicht offensichtliche Weise kommunizieren. Es gibt auch ein zentrales System, dessen Hauptverantwortung der Status von Bestellungen ist. Wir nennen sie BOB, ich arbeite mit ihr.
Refund Tool mit ereignisgesteuerter API
Das Wort ereignisgesteuert ist ziemlich abgedroschen, ein wenig weiter werden wir genauer definieren, was damit gemeint ist. Ich beginne mit dem Kontext, in dem wir beschlossen haben, den ereignisgesteuerten Kafka-API-Ansatz auszuprobieren.

In jedem Geschäft gibt es zusätzlich zu Bestellungen, für die Kunden bezahlen, Zeiten, in denen das Geschäft Geld zurückgeben muss, weil das Produkt nicht zum Kunden passt. Dieser relativ kurze Prozess: Wir klären die Informationen, wenn ein solcher Bedarf besteht, und überweisen das Geld.
Die Rückgabe war jedoch aufgrund von Gesetzesänderungen kompliziert, und wir mussten einen separaten Mikroservice dafür implementieren.

Unsere Motivation:
- Gesetz FZ-54 - Kurz gesagt, das Gesetz schreibt vor, dass Sie dem Finanzamt in wenigen Minuten jede Geldtransaktion, sei es eine Rückgabe oder eine Quittung, in einem relativ kurzen SLA melden müssen. Wir als E-Commerce führen einige Operationen durch. Technisch bedeutet dies eine neue Verantwortung (und damit einen neuen Service) und Verbesserungen in allen beteiligten Systemen.
- BOB-Split - das unternehmensinterne Projekt, um BOB von einer Vielzahl von nicht zum Kerngeschäft gehörenden Aufgaben zu befreien und die Gesamtkomplexität zu verringern.

Dieses Diagramm zeigt die wichtigsten Lamoda-Systeme. Jetzt ähneln die meisten eher einer
Konstellation von 5-10 Mikrodiensten um einen abnehmenden Monolithen . Sie wachsen langsam, aber wir versuchen, sie kleiner zu machen, weil es beängstigend ist, das in der Mitte hervorgehobene Fragment einzusetzen - es darf nicht fallen. Alle Börsen (Pfeile) sind wir gezwungen zu reservieren und darauf zu setzen, dass einer von ihnen möglicherweise nicht verfügbar ist.
Es gibt auch ziemlich viele Börsen in BOB: Zahlung, Lieferung, Benachrichtigungssysteme usw.
Technisch gesehen ist BOB:
- ~ 150.000 Codezeilen + ~ 100.000 Testzeilen;
- php7.2 + Zend 1 & Symfony Components 3;
- > 100 API & ~ 50 ausgehende Integrationen;
- 4 Länder mit eigener Geschäftslogik.
Die Bereitstellung von BOB ist teuer und schmerzhaft. Die Menge an Code und die damit verbundenen Aufgaben sind so, dass niemand sie in den Kopf bekommen kann. Im Allgemeinen gibt es viele Gründe, dies zu vereinfachen.
Rückgabeprozess
Zunächst sind zwei Systeme in den Prozess involviert: BOB und Payment. Nun erscheinen zwei weitere:
- Fiscalization Service, der sich um Probleme bei der Fiskalisierung und der Kommunikation mit externen Diensten kümmert.
- Rückerstattungstool, in das neue Börsen einfach herausgenommen werden, um das BOB nicht aufzublasen.
Jetzt sieht der Prozess so aus:
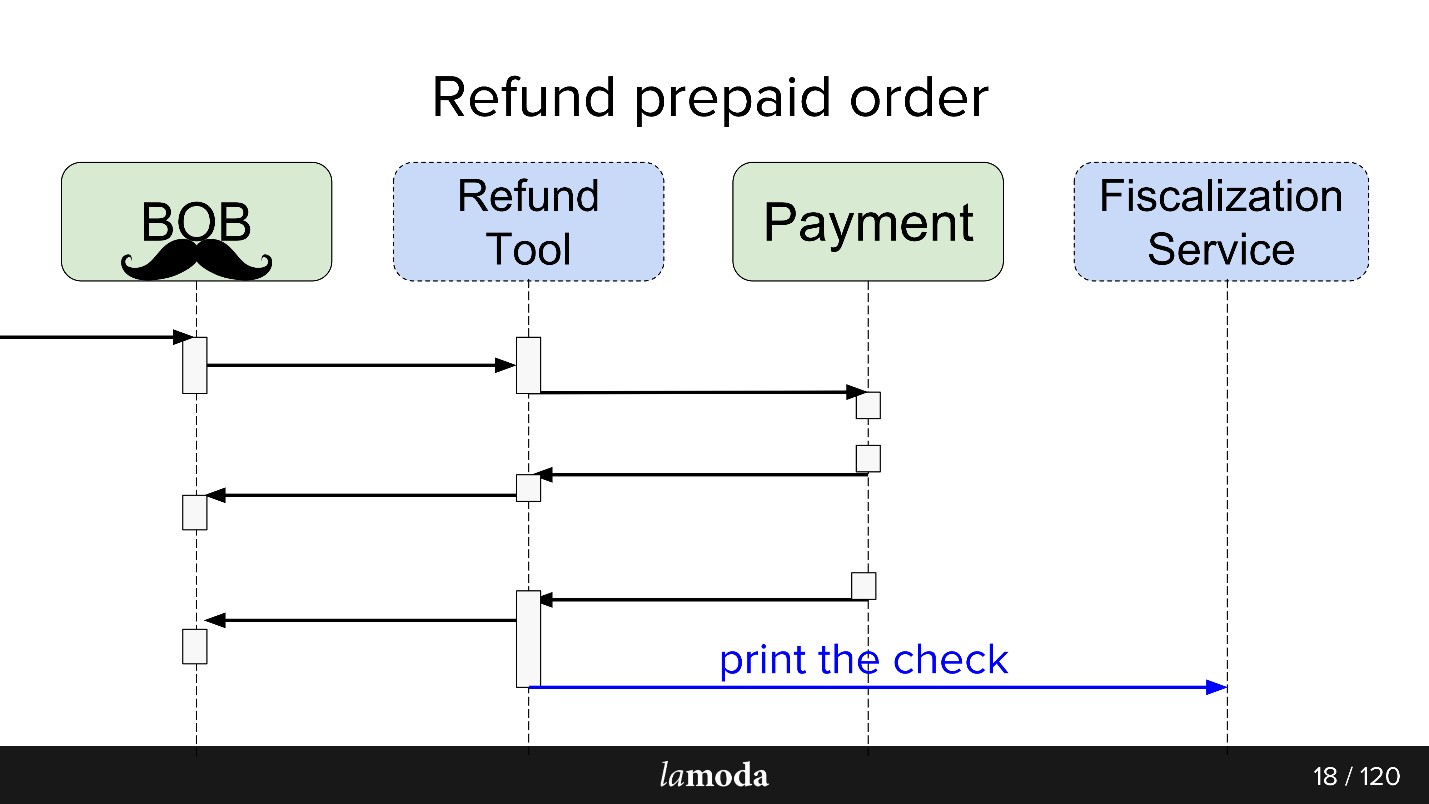
- BOB erhält eine Rückerstattungsanfrage.
- BOB spricht über dieses Rückerstattungstool.
- Das Rückerstattungstool sagt Zahlung: "Holen Sie sich das Geld zurück."
- Die Zahlung gibt das Geld zurück.
- Das Refund Tool und BOB synchronisieren die Status miteinander, da beide sie vorerst benötigen. Wir sind noch nicht bereit, vollständig auf das Rückerstattungstool umzusteigen, da BOB über eine Benutzeroberfläche, Berichte für die Buchhaltung und im Allgemeinen viele Daten verfügt, die Sie nicht einfach übertragen können. Wir müssen auf zwei Stühlen sitzen.
- Der Fiskalisierungsantrag geht.
Als Ergebnis haben wir auf Kafka eine Art Eventbus gebaut - einen Eventbus, mit dem alles begann. Hurra, jetzt haben wir einen einzigen Fehlerpunkt (Sarkasmus).

Die Vor- und Nachteile liegen auf der Hand. Wir haben einen Bus gebaut, daher hängen jetzt alle Dienste davon ab. Dies vereinfacht das Design, führt jedoch einen einzelnen Fehlerpunkt in das System ein. Kafka wird fallen, der Prozess wird steigen.
Was ist eine ereignisgesteuerte API?
Eine gute Antwort auf diese Frage findet sich in dem Bericht von Martin Fowler (GOTO 2017)
"Die vielen Bedeutungen ereignisgesteuerter Architektur" .
Kurz gesagt, was wir getan haben:
- Alle asynchronen Austausche wurden über den Ereignisspeicher abgeschlossen . Anstatt jeden interessierten Verbraucher über das Netzwerk über die Statusänderung zu informieren, schreiben wir ein Statusänderungsereignis in das zentrale Repository, und Verbraucher, die an dem Thema interessiert sind, lesen alles, was von dort aus angezeigt wird.
- Ein Ereignis in diesem Fall ist eine Benachrichtigung ( Benachrichtigungen ), dass sich irgendwo etwas geändert hat. Beispielsweise hat sich der Bestellstatus geändert. Ein Verbraucher, der an Daten interessiert ist, die mit der Statusänderung einhergehen, und die nicht in der Benachrichtigung enthalten sind, kann seinen Status selbst herausfinden.
- Die maximale Option ist eine vollständige Ereignisbeschaffung, Statusübertragung, bei der das Ereignis alle für die Verarbeitung erforderlichen Informationen enthält: von wo und zu welchem Status haben Sie gewechselt, wie genau haben sich die Daten geändert usw. Die einzige Frage ist, ob es sich lohnt und wie viele Informationen Sie sich leisten können, um sie zu speichern.
Im Rahmen des Starts des Refund-Tools haben wir die dritte Option verwendet. Dies vereinfachte die Verarbeitung von Ereignissen, da keine detaillierten Informationen eingeholt werden mussten, und schloss das Szenario aus, in dem jedes neue Ereignis eine Flut von Klärungsanfragen von Verbrauchern erzeugt.
Der Refund Tool Service ist
nicht geladen , daher ist Kafka dort eher ein Pen-Test als eine Notwendigkeit. Ich glaube nicht, dass das Unternehmen glücklich wäre, wenn der Rückerstattungsservice zu einem Hochlastprojekt würde.
Asynchroner Austausch wie besehen
Für den asynchronen Austausch verwendet die PHP-Abteilung normalerweise RabbitMQ. Wir haben die Daten für die Anfrage gesammelt, in die Warteschlange gestellt, und der Verbraucher desselben Dienstes hat sie gelesen und gesendet (oder nicht gesendet). Für die API selbst verwendet Lamoda aktiv Swagger. Wir entwerfen die API, beschreiben sie in Swagger, generieren Client- und Servercode. Wir verwenden auch einen leicht fortgeschrittenen JSON RPC 2.0.
Hier und da werden esb-Busse verwendet, jemand lebt von activeMQ, aber im Allgemeinen ist
RabbitMQ der Standard .
Async Austausch zu sein
Beim Entwerfen eines Austauschs über den Ereignisbus wird eine Analogie verfolgt. In ähnlicher Weise beschreiben wir den zukünftigen Datenaustausch durch Ereignisstrukturbeschreibungen. Das Yaml-Format, die Codegenerierung musste von uns selbst durchgeführt werden, der Generator erstellt das DTO gemäß der Spezifikation und bringt Clients und Servern bei, wie man mit ihnen arbeitet. Die Generation geht in zwei Sprachen -
Golang und PHP . Dies hält die Bibliotheken konsistent. Der Generator ist in Golang geschrieben, für den er den Namen Gogi erhielt.
Event-Sourcing bei Kafka ist eine typische Sache. Es gibt eine Lösung aus der Hauptunternehmensversion von Kafka Confluent, es gibt
Nakadi , eine Lösung aus unseren "Brüdern" im Bereich der Zalando-Domain. Unsere
Motivation, mit Vanilla Kafka zu beginnen, besteht darin, die Lösung frei zu lassen, bis wir schließlich entscheiden, ob wir sie überall verwenden möchten, und auch Raum für Manöver und Verbesserungen zu lassen: Wir möchten Unterstützung für unseren
JSON RPC 2.0 , Generatoren für zwei Sprachen, und sehen, was noch alles.
Es ist ironisch, dass wir selbst in einem so glücklichen Fall, wenn es ein ähnliches Geschäft wie Zalando gibt, das eine ähnliche Entscheidung getroffen hat, es nicht effektiv nutzen können.
Architektonisch ist das Muster beim Start wie folgt: Lesen Sie direkt von Kafka, aber schreiben Sie nur über den Ereignisbus. In Kafka gibt es viel zu lesen: Broker, Balancer und es ist mehr oder weniger bereit für horizontale Skalierung, ich wollte es behalten. Die Aufzeichnung wollten wir durch einen Gateway alias Events-Bus wickeln, und deshalb.
Veranstaltungsbus
Oder ein Eventbus. Dies ist nur ein zustandsloses http-Gateway, das mehrere wichtige Rollen übernimmt:
- Validierung der Produktion - Wir überprüfen, ob die Ereignisse unserer Spezifikation entsprechen.
- Ein Event-Master-System , dh es ist das wichtigste und einzige System im Unternehmen, das die Frage beantwortet, welche Events mit welchen Strukturen als gültig angesehen werden. Die Validierung umfasst lediglich Datentypen und Aufzählungen für eine strikte Spezifikation des Inhalts.
- Die Hash- Funktion für das Sharding - die Nachrichtenstruktur von Kafka ist der Schlüsselwert, und hier wird sie durch den Hash vom Schlüssel berechnet, wo er abgelegt werden soll.
Warum
Wir arbeiten in einem großen Unternehmen mit einem optimierten Prozess. Warum etwas ändern?
Dies ist ein Experiment , und wir erwarten mehrere Vorteile.
1: n + 1 Austausch (eins zu viele)
Mit Kafka ist es sehr einfach, neue Verbraucher mit der API zu verbinden.
Angenommen, Sie haben ein Verzeichnis, das in mehreren Systemen gleichzeitig (und in einigen neuen) auf dem neuesten Stand gehalten werden muss. Zuvor haben wir ein Bundle erfunden, das eine Set-API implementiert hat, und Verbraucheradressen wurden an das Mastersystem gemeldet. Jetzt sendet das Mastersystem Aktualisierungen zum Thema und zu allen, die am Lesen interessiert sind. Ein neues System ist erschienen - sie haben es zu diesem Thema unterschrieben. Ja, auch bündeln, aber einfacher.
Im Fall des Rückerstattungs-Tools, bei dem es sich um ein Stück BOB handelt, ist es für uns praktisch, sie über Kafka synchron zu halten. Die Zahlung besagt, dass sie das Geld zurückgegeben haben: BOB, RT hat davon erfahren, ihren Status geändert, Fiscalization Service hat davon erfahren und einen Scheck ausgeknockt.

Wir haben vor, einen einzigen Benachrichtigungsservice einzurichten, der den Kunden über die Neuigkeiten zu seiner Bestellung / Rücksendung informiert. Jetzt ist diese Verantwortung auf die Systeme verteilt. Es reicht aus, wenn wir dem Benachrichtigungsdienst beibringen, relevante Informationen von Kafka abzufangen und darauf zu reagieren (und diese Benachrichtigungen in anderen Systemen zu deaktivieren). Es ist kein neuer direkter Austausch erforderlich.
Datengesteuert
Informationen zwischen Systemen werden transparent - egal wie blutig Ihr Unternehmen ist und wie geschwollen Ihr Rückstand ist. Lamoda verfügt über eine Data Analytics-Abteilung, die Daten zu Systemen sammelt und in eine wiederverwendbare Form bringt, sowohl für Unternehmen als auch für intelligente Systeme. Mit Kafka können Sie ihnen schnell viele Daten geben und diesen Informationsfluss auf dem neuesten Stand halten.
Replikationsprotokoll
Nachrichten verschwinden nach dem Lesen nicht wie in RabbitMQ. Wenn das Ereignis genügend Informationen für die Verarbeitung enthält, haben wir einen Verlauf der letzten Änderungen am Objekt und, falls gewünscht, die Möglichkeit, diese Änderungen anzuwenden.
Die Speicherdauer des Replikationsprotokolls hängt von der Intensität des Schreibens in dieses Thema ab. Mit Kafka können Sie die Speicherzeit und das Datenvolumen flexibel begrenzen. Bei intensiven Themen ist es wichtig, dass alle Verbraucher Zeit haben, Informationen zu lesen, bevor sie verschwinden, auch bei kurzfristiger Inoperabilität. Normalerweise werden Daten für Tageseinheiten gespeichert, was für den Support völlig ausreicht.
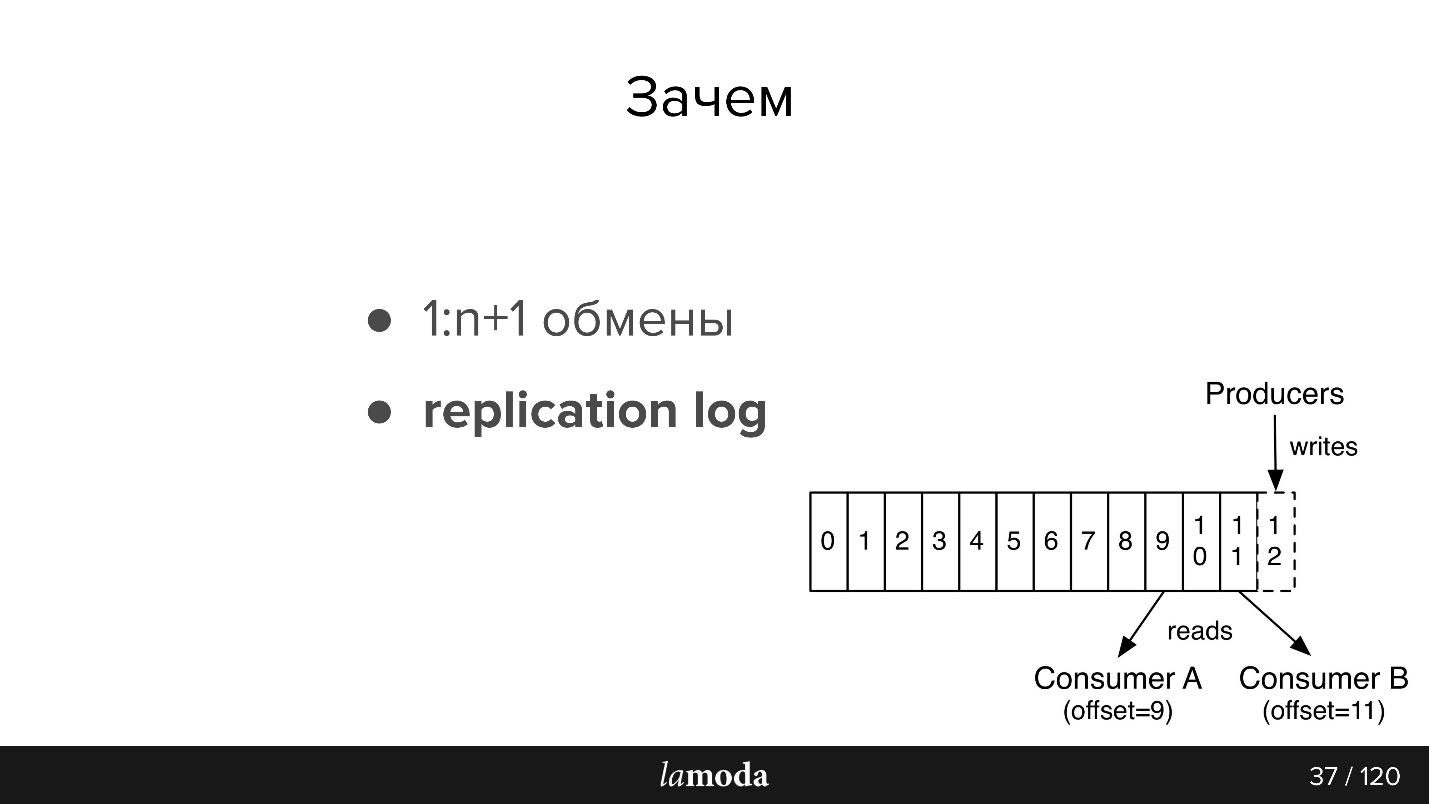
Dann eine kleine Nacherzählung der Dokumentation für diejenigen, die mit Kafka nicht vertraut sind (das Bild stammt auch aus der Dokumentation)
In AMQP gibt es Warteschlangen: Wir schreiben Nachrichten für den Verbraucher in die Warteschlange. In der Regel wird eine Warteschlange von einem System mit derselben Geschäftslogik verarbeitet. Wenn Sie mehrere Systeme benachrichtigen müssen, können Sie der Anwendung das Schreiben in mehrere Warteschlangen beibringen oder den Austausch mit dem Fanout-Mechanismus konfigurieren, der sie selbst klont.
Kafka hat eine ähnliche
Themenabstraktion, in der Sie Nachrichten schreiben, die jedoch nach dem Lesen nicht verschwinden. Wenn Sie eine Verbindung zu Kafka herstellen, erhalten Sie standardmäßig alle Nachrichten, und gleichzeitig besteht die Möglichkeit, den Ort zu speichern, an dem Sie aufgehört haben. Das heißt, Sie lesen nacheinander, Sie können die Nachricht nicht als gelesen markieren, sondern die ID speichern, von der aus Sie dann weiterlesen. Die ID, bei der Sie anhalten, heißt Offset, und der Mechanismus ist Commit-Offset.
Dementsprechend kann eine andere Logik implementiert werden. Zum Beispiel haben wir BOB in 4 Fällen für verschiedene Länder - Lamoda ist in Russland, Kasachstan, der Ukraine, Weißrussland. Da sie separat bereitgestellt werden, haben sie ein wenig ihre eigenen Konfigurationen und ihre eigene Geschäftslogik. In der Nachricht geben wir an, auf welches Land es sich bezieht. Jeder BOB-Verbraucher in jedem Land liest mit einer anderen Gruppen-ID. Wenn die Nachricht nicht auf ihn zutrifft, überspringen Sie sie, d. H. Sofort Offset +1 festschreiben. Wenn dasselbe Thema von unserem Zahlungsservice gelesen wird, erfolgt dies mit einer separaten Gruppe, und daher überschneiden sich die Offsets nicht.
Veranstaltungsvoraussetzungen:- Vollständigkeit der Daten. Ich wünschte, es wären genügend Daten in der Veranstaltung vorhanden, damit sie verarbeitet werden könnten.
- Integrität Wir delegieren den Events-Bus, um zu überprüfen, ob das Event konsistent ist und es verarbeiten kann.
- Ordnung ist wichtig. Im Falle einer Rückkehr sind wir gezwungen, mit der Geschichte zu arbeiten. Bei Benachrichtigungen ist die Bestellung nicht wichtig. Wenn es sich um homogene Benachrichtigungen handelt, ist die E-Mail dieselbe, unabhängig davon, welche Bestellung zuerst eingegangen ist. Im Falle einer Rücksendung gibt es einen klaren Prozess. Wenn Sie die Bestellung ändern, gibt es Ausnahmen, die Rückerstattung wird nicht erstellt oder verarbeitet - wir werden in einem anderen Status enden.
- Kohärenz. Wir haben ein Repository und jetzt erstellen wir anstelle der API Ereignisse. Wir brauchen eine Möglichkeit, Informationen über neue Ereignisse und Änderungen an bestehenden Ereignissen schnell und kostengünstig an unsere Dienste zu übertragen. Dies wird mithilfe einer gemeinsamen Spezifikation in einem separaten Git-Repository und Codegeneratoren erreicht. Daher werden Clients und Server in verschiedenen Diensten mit uns koordiniert.
Kafka in Lamoda
Wir haben drei Kafka-Installationen:
- Protokolle
- F & E;
- Veranstaltungsbus.
Heute sprechen wir nur über den letzten Punkt. Im Events-Bus haben wir keine sehr großen Installationen - 3 Broker (Server) und insgesamt 27 Themen. Ein Thema ist in der Regel ein Prozess. Aber dies ist ein heikler Moment, und jetzt werden wir darauf eingehen.
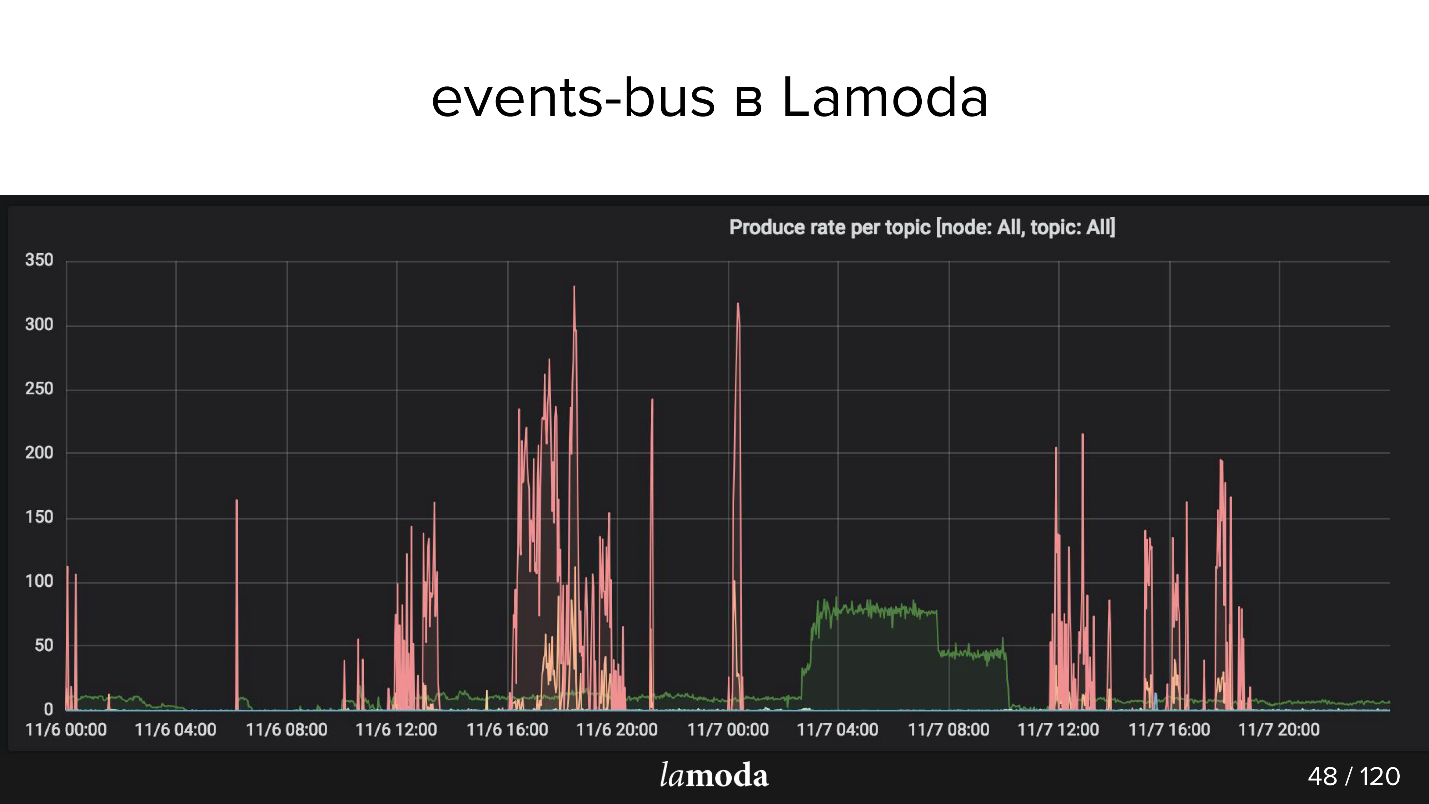
Oben ist das RPS-Diagramm. Der Rückerstattungsprozess ist mit einer türkisfarbenen Linie markiert (ja, die auf der X-Achse liegende), und Pink ist der Prozess zur Inhaltsaktualisierung.
Lamodas Katalog enthält Millionen von Produkten, wobei die Daten ständig aktualisiert werden. Einige Kollektionen sind aus der Mode gekommen, stattdessen erscheinen neue, neue Modelle erscheinen ständig im Katalog. Wir versuchen vorherzusagen, was für unsere Kunden morgen interessant sein wird, also kaufen wir ständig neue Dinge, fotografieren sie und aktualisieren das Fenster.
Pink Peaks sind ein Produktupdate, dh Änderungen an Produkten. Es ist zu sehen, dass die Jungs Fotos gemacht haben, Fotos gemacht haben und dann wieder! - ein Ereignispaket heruntergeladen.
Anwendungsfälle von Lamoda Events
Wir verwenden die konstruierte Architektur für solche Operationen:
- Verfolgung von Rückgabestatus : Handlungsaufforderung und Verfolgung von Status aller beteiligten Systeme. Zahlung, Status, Fiskalisierung, Benachrichtigungen. Hier haben wir den Ansatz ausprobiert, die Tools erstellt, alle Fehler gesammelt, die Dokumentation geschrieben und den Kollegen erklärt, wie sie verwendet werden sollen.
- Aktualisieren von Produktkarten: Konfiguration, Metadaten, Eigenschaften. Ein System liest (was angezeigt wird) und mehrere schreiben.
- E-Mail, Push und SMS : Die Bestellung wird abgeholt, die Bestellung ist eingetroffen, die Rücksendung wurde angenommen usw., viele von ihnen.
- Lagerbestand, Lageraktualisierung - eine quantitative Aktualisierung der Artikel, nur Zahlen: Eingang im Lager, Rückgabe. Es ist erforderlich, dass alle Systeme im Zusammenhang mit der Warenreservierung mit den relevantesten Daten arbeiten. Jetzt ist das Abfluss-Upgrade-System ziemlich kompliziert, Kafka wird es vereinfachen.
- Datenanalyse (F & E-Abteilung), ML-Tools, Analytik, Statistik. Wir möchten, dass die Informationen transparent sind - dafür ist Kafka gut geeignet.
Der interessantere Teil handelt von ausgestopften Zapfen und interessanten Entdeckungen, die über sechs Monate stattfanden.
Designprobleme
Angenommen, wir möchten etwas Neues machen - zum Beispiel den gesamten Lieferprozess an Kafka übertragen. Ein Teil des Prozesses wird jetzt in der Auftragsabwicklung in BOB implementiert. Hinter der Übergabe der Bestellung an den Lieferservice, der Übergabe an ein Zwischenlager usw. steht ein Statusmodell. Es gibt einen ganzen Monolithen, sogar zwei, sowie eine Reihe von Bereitstellungs-APIs. Sie wissen viel mehr über Lieferung.
Dies scheinen ähnliche Bereiche zu sein, aber für die Auftragsabwicklung im BOB und für das Liefersystem sind die Status unterschiedlich. Beispielsweise senden einige Kurierdienste keine Zwischenstatus, sondern nur endgültige: "geliefert" oder "verloren". Andere hingegen berichten ausführlich über den Warenverkehr. Jeder hat seine eigenen Validierungsregeln: Für jemanden ist E-Mail gültig, daher wird sie verarbeitet. Für andere ist es nicht gültig, aber die Bestellung wird weiterhin bearbeitet, da ein Telefon für die Kommunikation vorhanden ist und jemand sagt, dass eine solche Bestellung überhaupt nicht bearbeitet wird.
Datenstrom
Bei Kafka stellt sich die Frage nach der Organisation des Datenflusses. Diese Aufgabe ist mit der Wahl der Strategie für mehrere Punkte verbunden, wir werden sie alle durchgehen.
In einem Thema oder in einem anderen?
Wir haben eine Veranstaltungsspezifikation. In BOB schreiben wir, dass eine solche Bestellung geliefert werden muss, und geben an: die Bestellnummer, ihre Zusammensetzung, einige SKUs und Barcodes usw. Wenn die Waren im Lager ankommen, kann die Lieferung Status, Zeitstempel und alles, was benötigt wird, erhalten. Aber weiter wollen wir Updates zu diesen Daten in BOB erhalten. Wir stehen vor dem umgekehrten Prozess, Daten aus der Lieferung zu erhalten. Ist das das gleiche Ereignis? Oder ist es ein separater Austausch, der ein separates Thema verdient?
Höchstwahrscheinlich werden sie sich sehr ähnlich sein, und die Versuchung, ein Thema zu erstellen, ist nicht unangemessen, da ein separates Thema separate Verbraucher, separate Konfigurationen und eine separate Generation all dessen sind. Aber keine Tatsache.
Neues Feld oder neues Ereignis?
Wenn Sie jedoch dieselben Ereignisse verwenden, tritt ein anderes Problem auf. Beispielsweise können nicht alle Liefersysteme ein DTO generieren, das BOBs generieren kann. Wir senden ihnen eine ID, aber sie speichern sie nicht, weil sie sie nicht benötigen. Aus Sicht des Starts des Event-Bus-Prozesses ist dieses Feld erforderlich.
Wenn wir eine Regel für den Ereignisbus einführen, dass dieses Feld erforderlich ist, müssen wir zusätzliche Validierungsregeln im BOB oder im Startereignishandler festlegen. Die Validierung schleicht sich in den Service ein - dies ist nicht sehr praktisch.
— . , - , , , , . — . — , . JSON .
refunds . -, refund update, type, , update . «» , , type.
Kafka
Avro , Confluent. . replication log, «». , , : , . , , , .
partitions
Kafka partitions. , , , .
Kafka . partition, . . , , , . , , , Kafka partition, Kafka — , .
Kafka ? ( JSON) key. -, , partition .
refunds , partition, , . - , partition.
Events vs commands
, . Event — : , - - (something_happened), , item refund. - , «item » refund , « refund» - .
, , — , - . something_happened (item_canceled, refund_refunded), something_should_be_done. , item .
, , . , . , do_something. , - ; , ; , -, - . , do_something, , .

RabbitMQ, , http, response — , . Kafka, , Kafka, , , .
, - , - . , , - . , «item_ready_to_refund», , refund , , «money_refunded». , .
Nuancen
: , - , , .
, offset , .
, , . , events-bus, , PostgreSQL, MySQL UNSIGNED INT, PostgreSQL INT. , Id . Symfony . , , , , offset, , . , Symfony , offset.
- — , Kafka , . . .
Kafka tooling offset. , — , , redeployments. Kafka tooling offset, .
—
replication log vs rdkafka.so — . PHP, PHP, , , Kafka rdkafka.so, - . , , , - . , .
partitions,
consumers >= topic partitions . , . , partitions. , partition, 20 , , . , , partitions.
Überwachung
, , , , .
, , , , , , . Kafka , . , .

, , , events-bus , . , Refund Tool , BOB - ( ).

consumer-group lag. , . , 0, . Kafka , .
Burrow , Kafka. API consumer-group , . Failed warning, , — , . , .
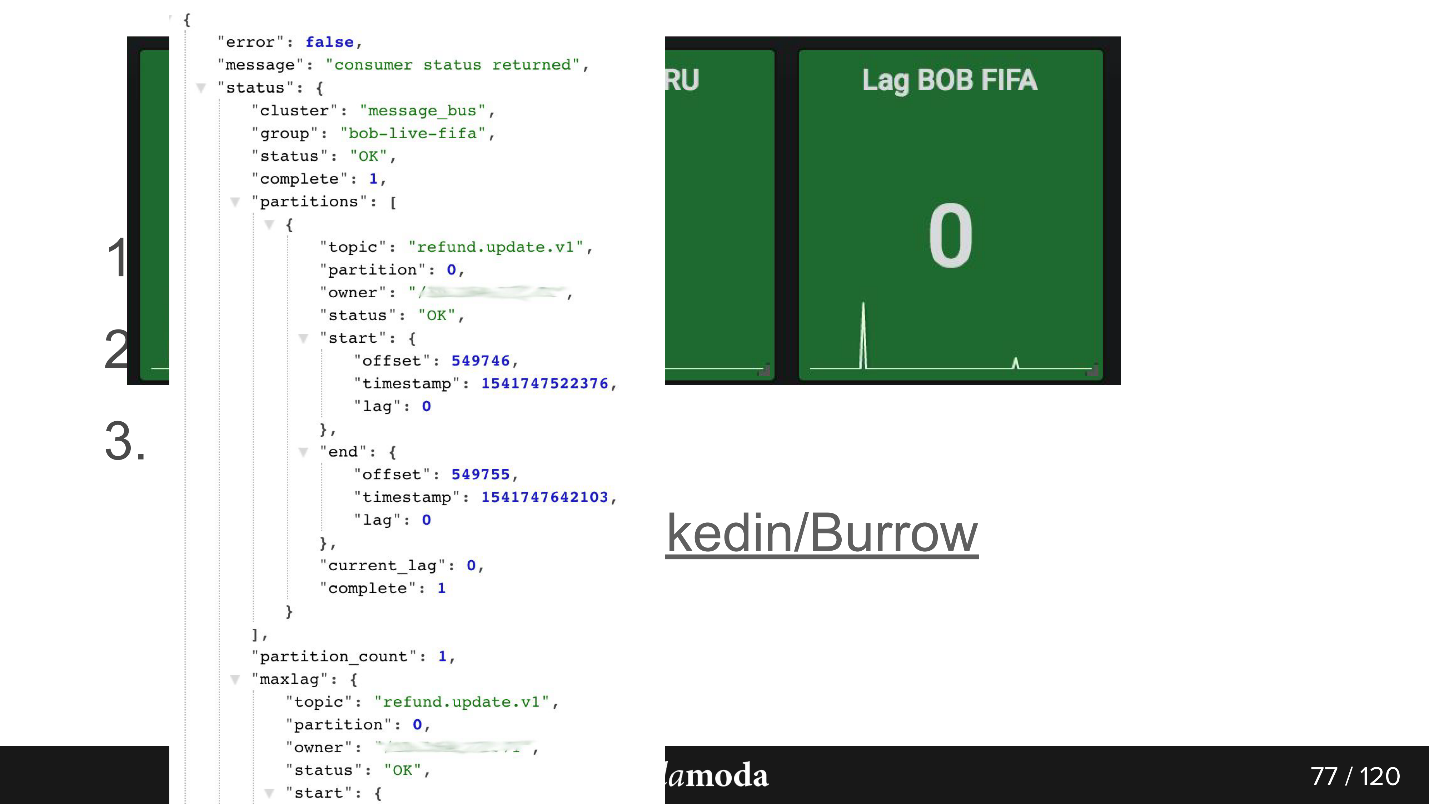
API. bob-live-fifa, partition refund.update.v1, , lag 0 — offset -.
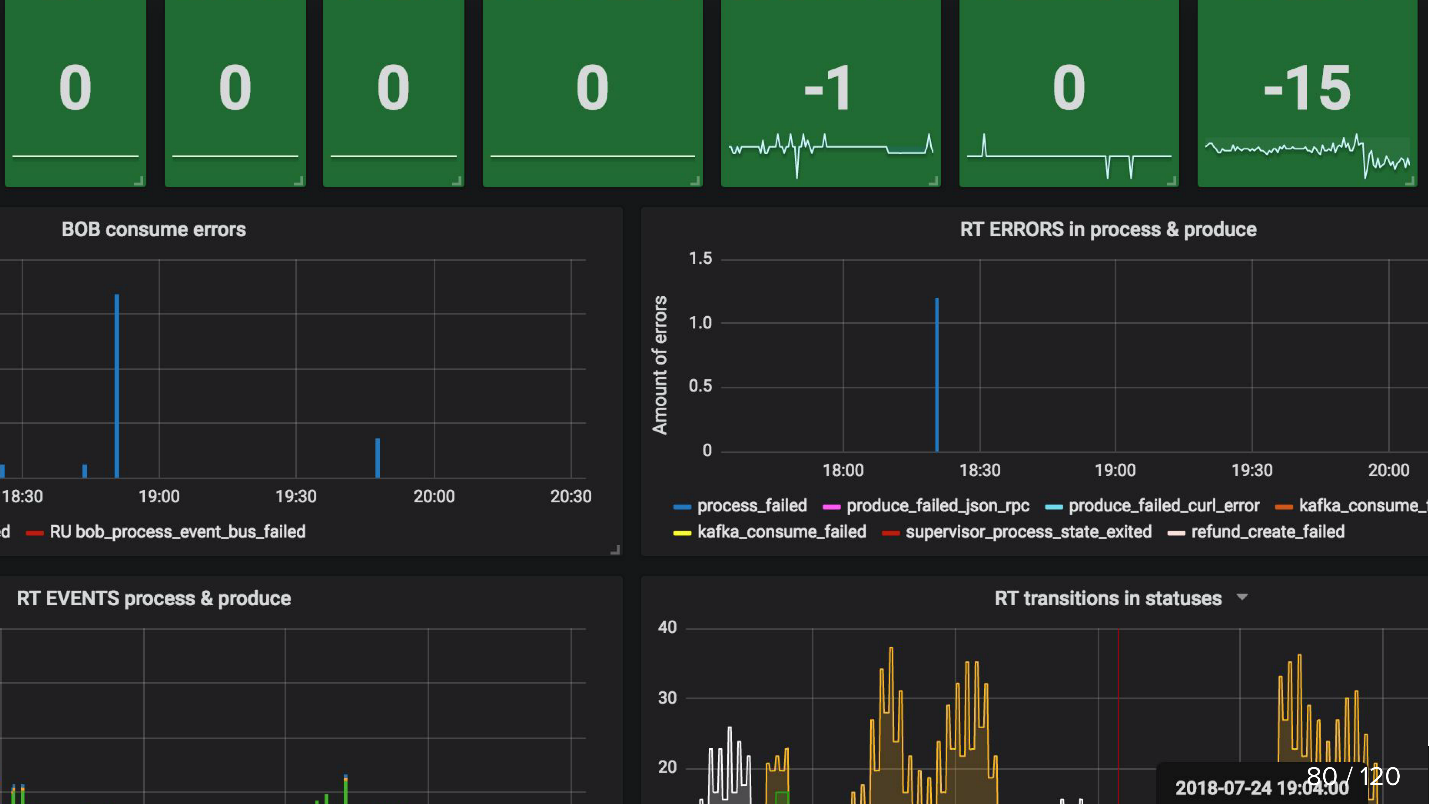 updated_at SLA (stuck)
updated_at SLA (stuck) . , , . Cron, , 5 refund ( ), - , . Cron, , 0, .
, , :
Es scheint, dass der Artikel ein sehr spezifisches Thema hat - die asynchrone API auf Kafka, aber im Zusammenhang damit möchte ich sofort viele Dinge empfehlen.
Erstens sollte das nächste HighLoad ++ erst im November erwartet werden, in St. Petersburg wird es seine Version geben, und im Juni werden wir über hohe Lasten in Nowosibirsk sprechen.
Zweitens ist der Autor des Berichts, Sergey Zaika, Mitglied des Programmausschusses unserer neuen KnowledgeConf- Wissensmanagementkonferenz . Die Konferenz ist eintägig und findet am 26. April statt. Das Programm ist jedoch sehr ereignisreich.
Und im Mai wird es PHP Russia und RIT ++ geben (inklusive DevOpsConf) - Sie können immer noch Ihr eigenes Thema vorschlagen, über Ihre Erfahrungen berichten und sich über Ihre verstopften Unebenheiten beschweren.