Im
ersten Teil der Geschichte, basierend auf einer
Präsentation von Dmitry Stogov von Zend Technologies auf HighLoad ++, haben wir die interne Struktur von PHP verstanden. Wir haben im Detail und aus erster Hand erfahren, welche Änderungen in den grundlegenden Datenstrukturen es PHP 7 ermöglichten, mehr als zweimal zu beschleunigen. Dies hätte gestoppt werden können, aber bereits in Version 7.1 gingen die Entwickler viel weiter, da sie noch viele Ideen zur Optimierung hatten.
Die gesammelten Erfahrungen mit JIT vor den sieben können nun interpretiert werden, indem die Ergebnisse in 7.0 ohne JIT und die Ergebnisse von HHVM mit JIT betrachtet werden. In PHP 7.1 wurde beschlossen, nicht mit JIT zu arbeiten, sondern sich erneut an den Interpreter zu wenden. Wenn die Optimierung früher den Interpreter betraf, werden wir uns in diesem Artikel mit der Optimierung des Bytecodes befassen, wobei die Typinferenz verwendet wird, die für unsere JIT implementiert wurde.
Unter dem Schnitt wird Dmitry Stogov anhand eines einfachen Beispiels zeigen, wie dies alles funktioniert.
Bytecode-Optimierung
Unten finden Sie den Bytecode, in den der Standard-PHP-Compiler die Funktion kompiliert. Es ist Single-Pass - schnell und dumm, kann aber seine Aufgabe bei jeder HTTP-Anfrage erneut erledigen (wenn OPcache nicht verbunden ist).

OPcache-Optimierungen
Mit dem Aufkommen von OPcache haben wir begonnen, es zu optimieren. Einige Optimierungsmethoden
sind seit langem in OPcache integriert , z. B. Methoden
zur Spaltoptimierung. Wenn wir den Code durch das Guckloch betrachten, suchen Sie nach vertrauten Mustern und ersetzen Sie sie durch Heuristiken. Diese Methoden werden in 7.0 weiterhin verwendet. Zum Beispiel haben wir zwei Operationen: Addition und Zuweisung.

Sie können zu einer zusammengesetzten Zuweisungsoperation kombiniert werden, die eine Addition direkt für das Ergebnis
ASSIGN_ADD $sum, $i :
ASSIGN_ADD $sum, $i . Ein anderes Beispiel ist eine Post-Inkrement-Variable, die theoretisch ein Ergebnis zurückgeben könnte.

Es ist möglicherweise kein Skalarwert und muss entfernt werden. Verwenden Sie dazu die
FREE Anweisung. Wenn Sie es jedoch in ein Vorinkrement ändern, ist die
FREE Anweisung nicht erforderlich.

Am Ende stehen zwei
RETURN Anweisungen: Die erste spiegelt direkt die RETURN-Anweisung im Quelltext wider, und die zweite wird von einem dummen Compiler mit einer schließenden Klammer hinzugefügt. Dieser Code wird niemals erreicht und kann gelöscht werden.
Es sind nur noch vier Anweisungen in der Schleife vorhanden. Es scheint, dass es nichts weiter zu optimieren gibt, aber nicht für uns.
Schauen Sie sich den
$i++ und die entsprechende Anweisung an - das
PRE_INC -
PRE_INC . Jedes Mal, wenn es ausgeführt wird:
- müssen überprüfen, welche Art von Variable kam;
- ob es
is_long ; - Inkrement ausführen;
- auf Überlauf prüfen;
- gehe zum nächsten;
- Vielleicht überprüfen Sie die Ausnahme.
Eine Person, die nur den PHP-Code betrachtet, wird jedoch feststellen, dass die Variable
$i im Bereich von 0 bis 100 liegt und es keinen Überlauf geben kann, dass keine Typprüfungen erforderlich sind und es auch keine Ausnahmen geben kann.
In PHP 7.1 haben wir versucht, dem Compiler beizubringen, dies zu verstehen .
Optimierung des Kontrollflussdiagramms

Dazu müssen Sie Typen ableiten und zur Eingabe von Typen zunächst eine formale Darstellung der Datenströme erstellen, die der Computer versteht. Zunächst erstellen wir jedoch ein Kontrollflussdiagramm, ein Kontrollabhängigkeitsdiagramm. Zunächst teilen wir den Code in Basisblöcke auf - eine Reihe von Anweisungen mit einer Eingabe und einer Ausgabe. Daher schneiden wir den Code an den Stellen, an denen der Übergang stattfindet, dh an den Bezeichnungen L0, L1. Wir schneiden es auch nach den bedingten und unbedingten Verzweigungsoperatoren und verbinden es dann mit Bögen, die die Abhängigkeiten für die Steuerung anzeigen.

Also haben wir CFG.
Optimierung des statischen Einzelzuweisungsformulars
Nun brauchen wir eine Datenabhängigkeit. Zu diesem Zweck verwenden wir das statische Einzelzuweisungsformular - eine beliebte Darstellung in der Welt der Optimierung von Compilern. Dies bedeutet, dass der Wert jeder Variablen nur einmal zugewiesen werden kann.

Für jede Variable fügen wir einen Index oder eine Reinkarnationsnummer hinzu. An jedem Ort, an dem die Zuordnung stattfindet, setzen wir einen neuen Index und verwenden ihn - bis zu den Fragezeichen, da er nicht immer überall bekannt ist. Zum Beispiel kann in der Anweisung
IS_SMALLER $ i sowohl vom Block L0 mit der Nummer 4 als auch vom ersten Block mit der Nummer 2 stammen.
Um dieses Problem zu lösen, führt die SSA
die Phi- Pseudofunktion ein, die bei Bedarf am Anfang von basic-> block eingefügt wird, alle Arten von Indizes einer Variablen verwendet, die von verschiedenen Stellen in den Basisblock gelangt sind, und eine neue Reinkarnation der Variablen erstellt. Es sind solche Variablen, die später verwendet werden, um Mehrdeutigkeiten zu beseitigen.

Wenn Sie alle Fragezeichen auf diese Weise ersetzen, erstellen wir die SSA.
Typoptimierung
Jetzt leiten wir Typen ab - als ob wir versuchen würden, diesen Code direkt im Management auszuführen.

Im ersten Block werden den Variablen konstante Werte zugewiesen - Nullen, und wir wissen mit Sicherheit, dass diese Variablen vom Typ long sind. Als nächstes kommt die Phi-Funktion. Long kommt zur Eingabe und wir kennen die Werte anderer Variablen, die aus anderen Zweigen stammen, nicht.

Wir glauben, dass die Ausgabe phi () wir lange haben werden.

Wir vertreiben weiter. Wir kommen zu bestimmten Funktionen, zum Beispiel
ASSIGN_ADD und
PRE_INC . Addiere zwei lange. Das Ergebnis kann entweder lang oder doppelt sein, wenn ein Überlauf auftritt.

Diese Werte fallen wieder in die Phi-Funktion, die Vereinigung der Mengen möglicher Typen, die auf verschiedenen Zweigen ankommen, erfolgt. Nun und so weiter verbreiten wir uns weiter, bis wir zu einem festen Punkt kommen und sich alles beruhigt.

Wir haben an jedem Punkt im Programm einen möglichen Satz von Typwerten. Das ist schon gut Der Computer weiß bereits, dass
$i nur lang oder doppelt sein kann und einige unnötige Überprüfungen ausschließen kann. Aber wir wissen, dass doppeltes
$i nicht sein kann. Woher wissen wir das? Und wir sehen eine Bedingung, die das Wachstum von
$i im Zyklus auf einen möglichen Überlauf begrenzt. Wir werden dem Computer beibringen, dies zu sehen.
Optimierung der Reichweitenausbreitung
In der
PRE_INC Anweisung
PRE_INC wir nie herausgefunden, dass ich nur eine ganze Zahl sein kann - es kostet lang oder doppelt. Dies geschieht, weil wir nicht versucht haben, mögliche Bereiche abzuleiten. Dann könnten wir die Frage beantworten, ob ein Überlauf auftritt oder nicht.
Diese Ausgabe der Bereiche erfolgt auf ähnliche, aber etwas komplexere Weise. Als Ergebnis erhalten wir einen festen Bereich von Variablen
$i mit den Indizes 2, 4, 6 und 7, und jetzt können wir sicher sagen, dass das Inkrement
$i nicht zu einem Überlauf führt.

Durch die Kombination dieser beiden Ergebnisse können wir mit Sicherheit sagen, dass die Doppelvariable
$i niemals werden kann.

Wir haben nur noch keine Optimierung, dies sind Informationen zur Optimierung! Betrachten Sie die
ASSIGN_ADD . Im Allgemeinen könnte der alte Wert der Summe, die zu dieser Anweisung kam, beispielsweise ein Objekt sein. Nach dem Hinzufügen sollte der alte Wert entfernt worden sein. In unserem Fall wissen wir jedoch mit Sicherheit, dass es einen Long- oder Double-Wert gibt, dh einen Skalarwert. Es ist keine Zerstörung erforderlich, wir können
ASSIGN_ADD durch
ADD ersetzen - eine einfachere Anweisung.
ADD verwendet die
sum sowohl als Argument als auch als Wert.

Bei Vorinkrementierungsoperationen wissen wir mit Sicherheit, dass der Operand immer lang ist und keine Überläufe auftreten können. Für diese Anweisung verwenden wir einen hochspezialisierten Handler, der nur die erforderlichen Aktionen ohne Überprüfung ausführt.

Vergleichen Sie nun die Variable am Ende der Schleife. Wir wissen, dass der Wert der Variablen nur lang sein wird - Sie können diesen Wert sofort überprüfen, indem Sie ihn mit hundert vergleichen. Wenn wir früher das Ergebnis der Überprüfung in einer temporären Variablen aufgezeichnet und dann die temporäre Variable erneut auf wahr / falsch überprüft haben, kann dies jetzt mit einer Anweisung erfolgen, dh vereinfacht.

Bytecode-Ergebnis im Vergleich zum Original.

Der Zyklus enthält nur noch drei Anweisungen, von denen zwei hochspezialisiert sind. Infolgedessen ist der Code auf der rechten Seite
dreimal schneller als das Original.
Hochspezialisierte Handler
Jeder
PHP-Crawler ist nur eine C-Funktion . Links befindet sich ein Standardhandler und oben rechts ein hochspezialisierter. Der linke prüft: den Typ des Operanden, wenn ein Überlauf aufgetreten ist, wenn eine Ausnahme aufgetreten ist. Der Richtige fügt nur einen hinzu und das wars. Es übersetzt in 4 Maschinenanweisungen. Wenn wir weiter gehen und JIT machen würden, würden wir nur eine einmalige Anweisung
incl .

Was weiter?
Wir erhöhen weiterhin die Geschwindigkeit von PHP Branch 7 ohne JIT.
PHP 7.1 wird bei typischen synthetischen Tests
wieder 60% schneller sein, aber bei realen Anwendungen bringt dies fast keinen Gewinn - nur 1-2% bei WordPress. Das ist nicht besonders interessant. Seit August 2016, als der 7.1-Zweig wegen größerer Änderungen eingefroren wurde, haben wir wieder begonnen, an JIT für PHP 7.2 bzw. PHP 8 zu arbeiten.
In einem neuen Versuch verwenden wir
DynAsm , um den Code zu generieren, der von Mike Paul
für LuaJIT-2 entwickelt wurde . Es ist gut, weil es
sehr schnell Code generiert : Die Tatsache, dass Minuten in der JIT-Version auf LLVM kompiliert wurden, geschieht jetzt in 0,1-0,2 s. Bereits heute ist die
Beschleunigung auf bank.php auf JIT 75-mal schneller als auf PHP 5.
Bei realen Anwendungen gibt es keine Beschleunigung, und dies ist die nächste Herausforderung für uns. Zum Teil haben wir den optimalen Code erhalten, aber nachdem wir zu viele PHP-Skripte kompiliert hatten, haben wir den Prozessor-Cache verstopft, sodass er nicht schneller funktionierte. Und nicht die Codegeschwindigkeit war ein Engpass in realen Anwendungen ...
Vielleicht kann DynAsm verwendet werden, um nur bestimmte Funktionen zu kompilieren, die entweder von einem Programmierer oder durch zählerbasierte Heuristiken ausgewählt werden - wie oft eine Funktion aufgerufen wurde, wie oft Zyklen darin wiederholt werden usw.
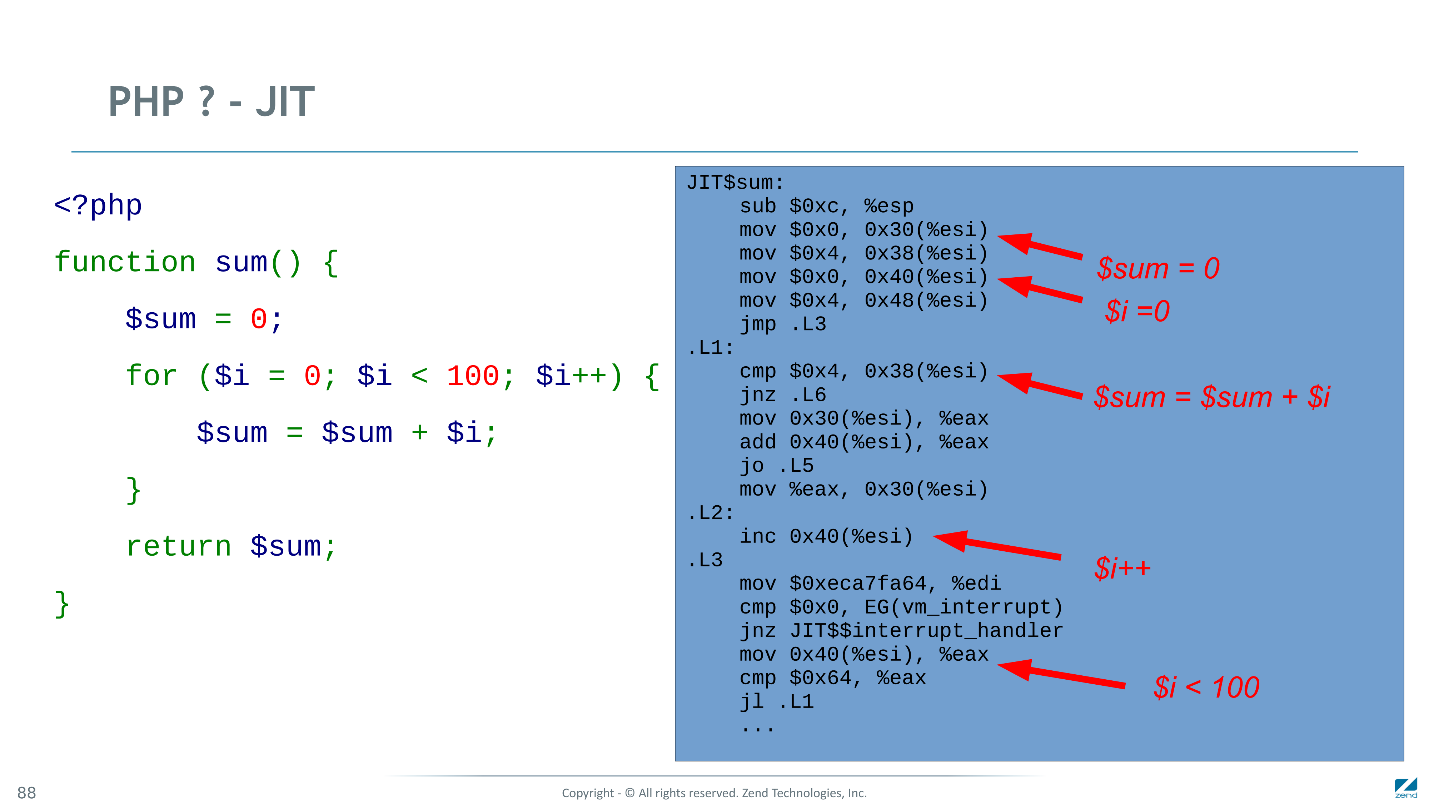
Unten finden Sie den Maschinencode, den unsere JIT für dasselbe Beispiel generiert. Viele Befehle sind optimal kompiliert: Inkrementieren in einen CPU-Befehl, Variableninitialisierung auf Konstanten in zwei. Wo die Typen nicht geschlüpft sind, muss man sich etwas mehr kümmern.
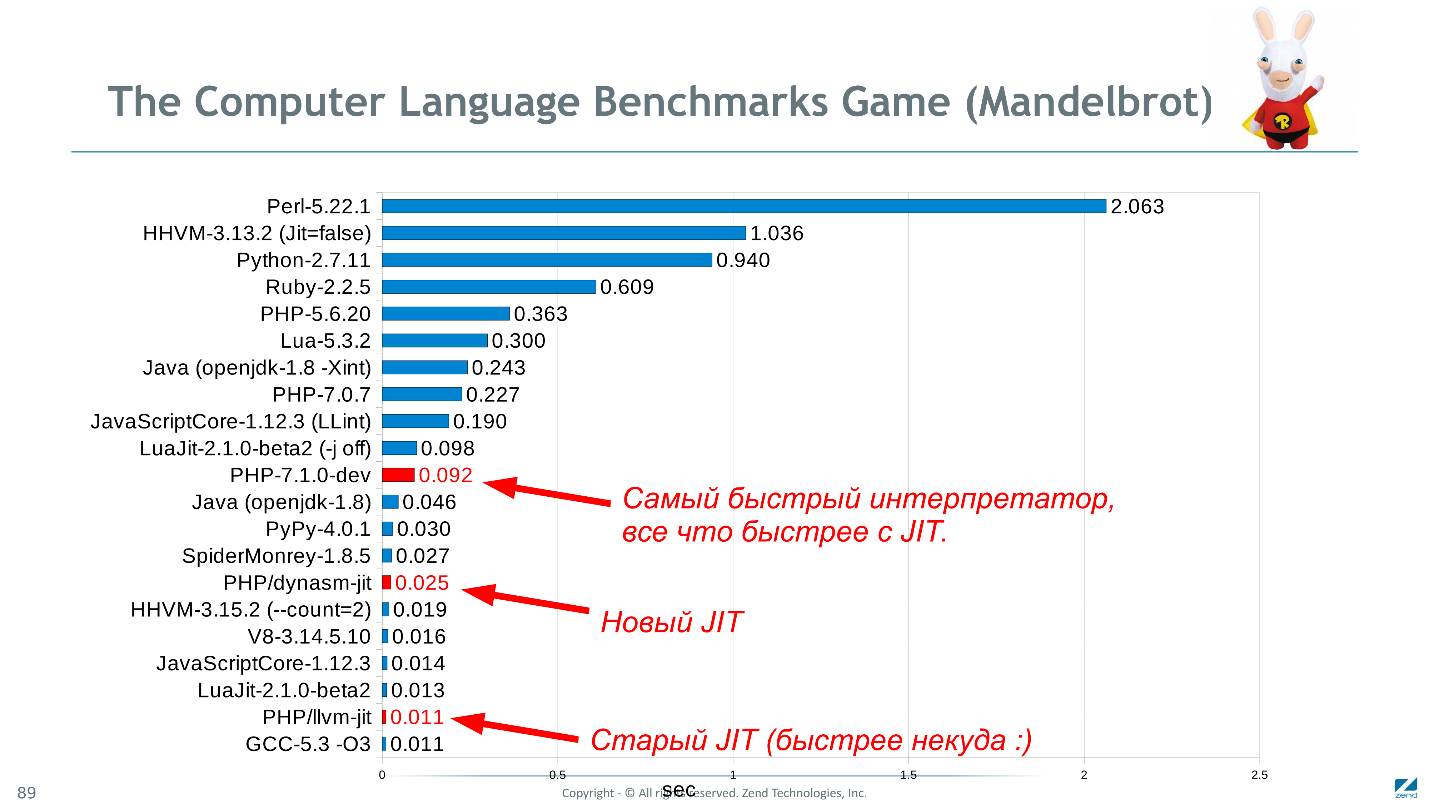
Zurück zum Titelbild zeigt PHP im Vergleich zu ähnlichen Sprachen im Mandelbrot-Test sehr gute Ergebnisse (obwohl die Daten Ende 2016 relevant sind).
Das Diagramm zeigt die Ausführungszeit in Sekunden, weniger ist besser.Vielleicht ist
Mandelbrot nicht der beste Test. Es ist rechnerisch, aber einfach und in allen Sprachen gleichermaßen implementiert. Es wäre schön zu wissen, wie schnell Wordpress in C ++ funktionieren würde, aber es gibt kaum eine Kuriosität, die bereit ist, es neu zu schreiben, nur um alle Perversionen des PHP-Codes zu überprüfen und sogar zu wiederholen. Wenn Sie Ideen für einen angemesseneren Satz von Benchmarks haben, schlagen Sie vor.
Wir werden uns am 17. Mai auf der PHP in Russland treffen und die Perspektiven und die Entwicklung des Ökosystems sowie die Erfahrungen mit der Verwendung von PHP für wirklich komplexe und coole Projekte diskutieren. Schon bei uns:
Das ist natürlich alles andere als gut. Und Call for Papers ist noch geschlossen. Bis zum 1. April warten wir auf Anwendungen von denen, die moderne Ansätze und Best Practices anwenden können, um coole PHP-Dienste zu implementieren. Haben Sie keine Angst vor dem Wettbewerb mit herausragenden Rednern - wir suchen nach Erfahrung in der Verwendung ihrer Aufgaben in realen Projekten und helfen Ihnen dabei, die Vorteile Ihrer Fälle aufzuzeigen.