Wenn Sie mit mehreren Kunden gleichzeitig arbeiten, müssen Sie schnell viele Informationen in verschiedenen Konten und Berichten analysieren. Bei mehr als 10 Kunden hat der Vermarkter keine Zeit mehr, die Statistiken ständig zu überwachen. Aber es gibt einen Weg.
In diesem Artikel werde ich darüber sprechen, wie Werbekonten mithilfe der API und Python überwacht werden.
Am Ausgang erhalten wir eine Anfrage an die Yandex.Direct-API, mit der wir Statistiken über Werbekampagnen erhalten und diese Daten verarbeiten können.
Dafür brauchen wir:
- Holen Sie sich das Yandex Direct API-Token
- Schreiben Sie eine Serveranfrage
- Daten in DataFrame importieren
Bibliotheken importieren
Sie müssen die in der Abfrage verwendeten Bibliotheken sowie Pandas und DataFrame importieren.
Alle Importe sehen folgendermaßen aus:
import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame
Token empfangen
Im Moment kann ich nichts Besseres sagen als die Dokumentation der Yandex.Direct-API, daher hinterlasse ich einen Link.
(
Anweisungen zum Erhalt eines Tokens )
Wir schreiben eine Anfrage an den Yandex.Direct API-Server
Kopieren Sie die Anforderung aus der API-DokumentationÄndern Sie die Anfrage.- Verschreiben Sie Ihr Token und melden Sie sich an
Token.
token = 'blaBlaBLAblaBLABLABLAblabla'
Login
clientLogin = 'e-66666666'
- Wir passen den Anfragetext für uns an.
Daraus
body = { "params": { "SelectionCriteria": { "DateFrom": "_", "DateTo": "_" }, "FieldNames": [ "Date", "CampaignName", "LocationOfPresenceName", "Impressions", "Clicks", "Cost" ], "ReportName": u("_"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "CUSTOM_DATE", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO"
Mach es
body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": « ", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } }
In
SelectionCriteria schreiben wir, wie wir Daten auswählen. Standardmäßig werden dort 2 Daten geschrieben, aber um diese nicht ständig ändern zu müssen, ersetzen wir den Zeitraum durch "Letzte 5 Tage".
Wir setzen den Filter für Daten . Dies ist vor allem erforderlich, um keine leeren Werte zu erhalten. Das Problem ist, dass Direct die fehlenden Daten als zwei Minuspunkte anzeigt, aufgrund derer sich der Datentyp der gesamten Spalte ändert. Danach können Sie keine mathematischen Operationen ohne unnötige Gesten ausführen.
Feldnamen Wir schreiben hier die Daten, die Sie benötigen. Ich habe die Felder registriert, die ich für die Analyse verwende. Ihre Liste kann abweichen.
ReportType Der Berichtstyp wird in dieses Feld geschrieben. Für Kampagnen wird dieser Bericht benötigt.
Sie sollten so etwas bekommen.
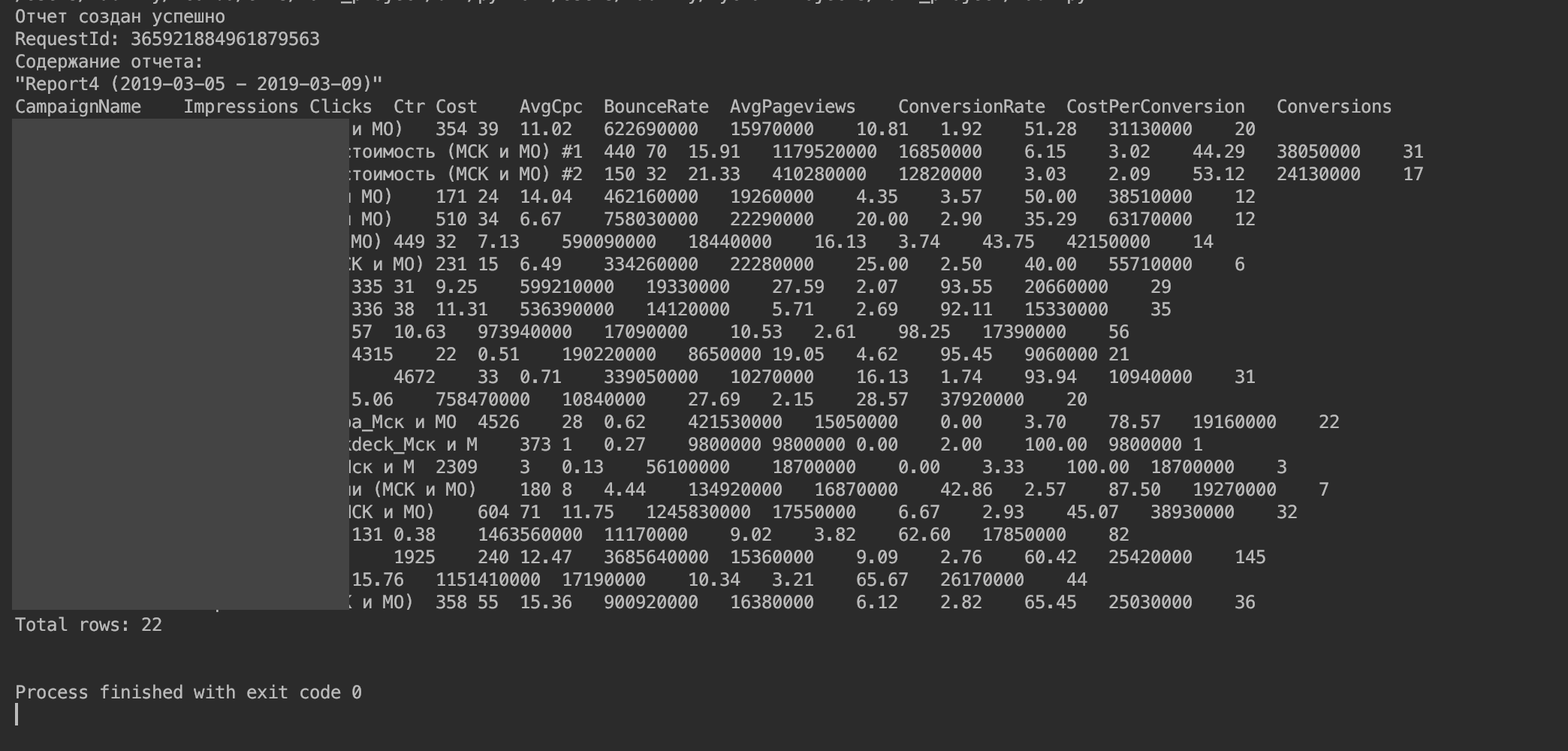
5. Importieren Sie die Daten in einen DataFrame.
(Ein DataFrame ist wahrscheinlich die am besten geeignete Methode, um mit diesen Daten zu arbeiten.)
Ich konnte diese Funktion implementieren, indem ich eine CSV-Datei schrieb und las.
Wir finden in der Abfrage das Stück, das für die Statistikausgabe verantwortlich ist - dies ist "req.text".
Wir löschen die Standardausgabe des Programms zum Schreiben in die Datei. Ändern Sie dazu alle Schlussfolgerungen in Code 200.
print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print(" : \n{}».format(u(req.text)))
Am:
format(u(req.text))
Importieren Sie nun die Serverantwort in den DataFrame.
file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,)
Schritt für Schritt:
- Öffnen Sie die Datei cashe.csv zum Schreiben (und erstellen Sie sie automatisch)
- Wir schreiben die Serverantwort hinein
- Schließen Sie die Datei
- Öffnen Sie die Datei als DataFrame (geben Sie den Dateinamen an, in welcher Zeile sich die Tabellenüberschriften befinden, in welcher Spalte sich die Daten befinden und in welcher Spalte sich der Index befindet).
Es stellte sich Folgendes heraus:
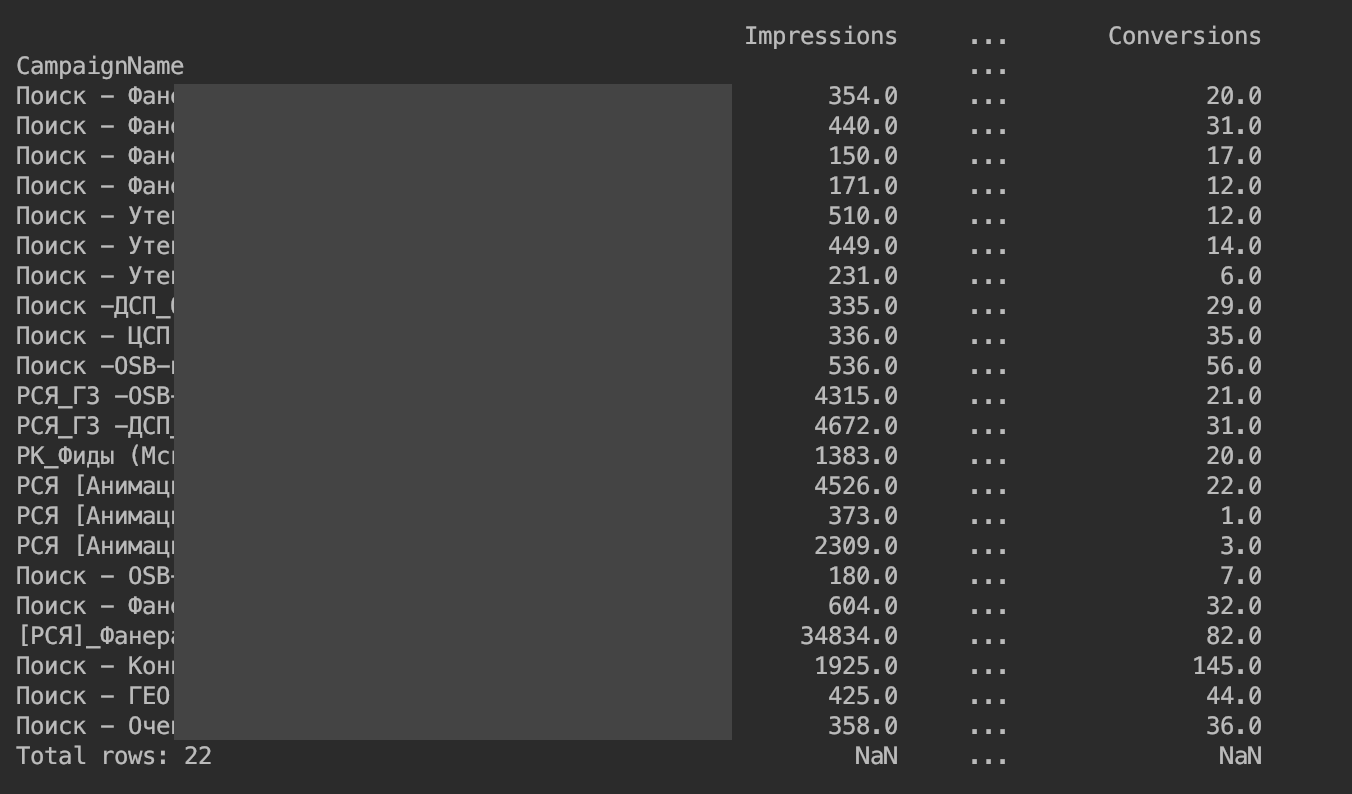
Wir entfernen die Einschränkung für die Ausgabe von Spalten:
pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1)
Jetzt wird alles gezeigt:
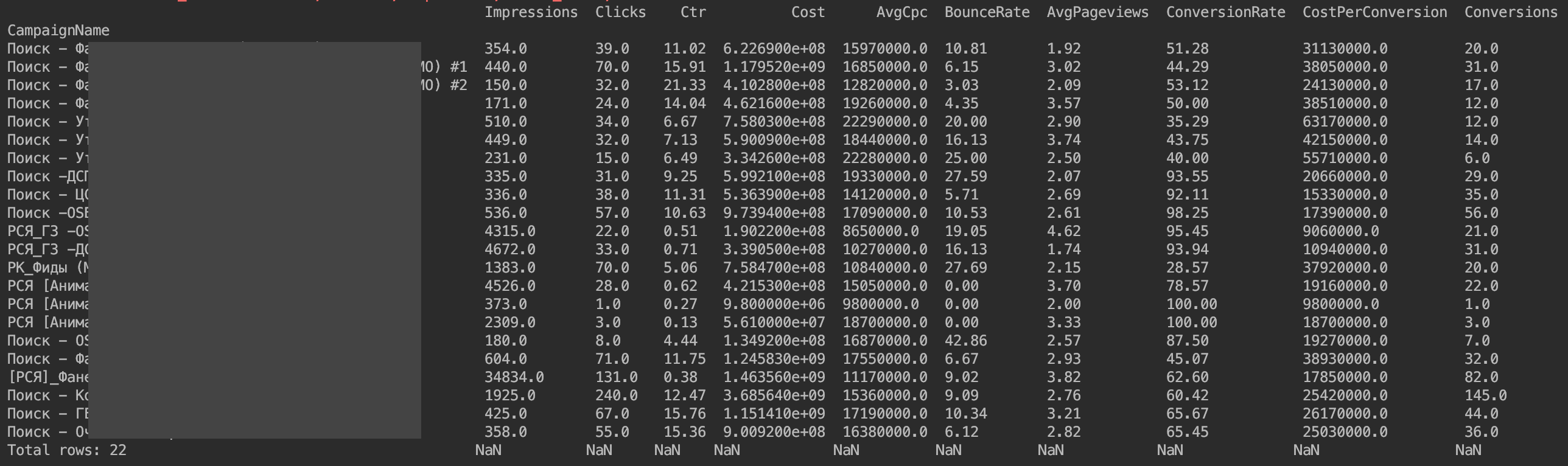
Das einzige Problem ist, dass die Geldwerte nicht so angezeigt werden, wie sie möchten. Dies sind die Funktionen der Yandex.Direct-API-Implementierung. Wir müssen nur die Geldwerte durch 1.000.000 teilen.
f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000
Ich schlage auch vor, sofort nach der Anzahl der Klicks zu sortieren
f=f.sort_values(by=['Clicks'], ascending=False)
Also haben wir DataFrame für die Analyse vorbereitet
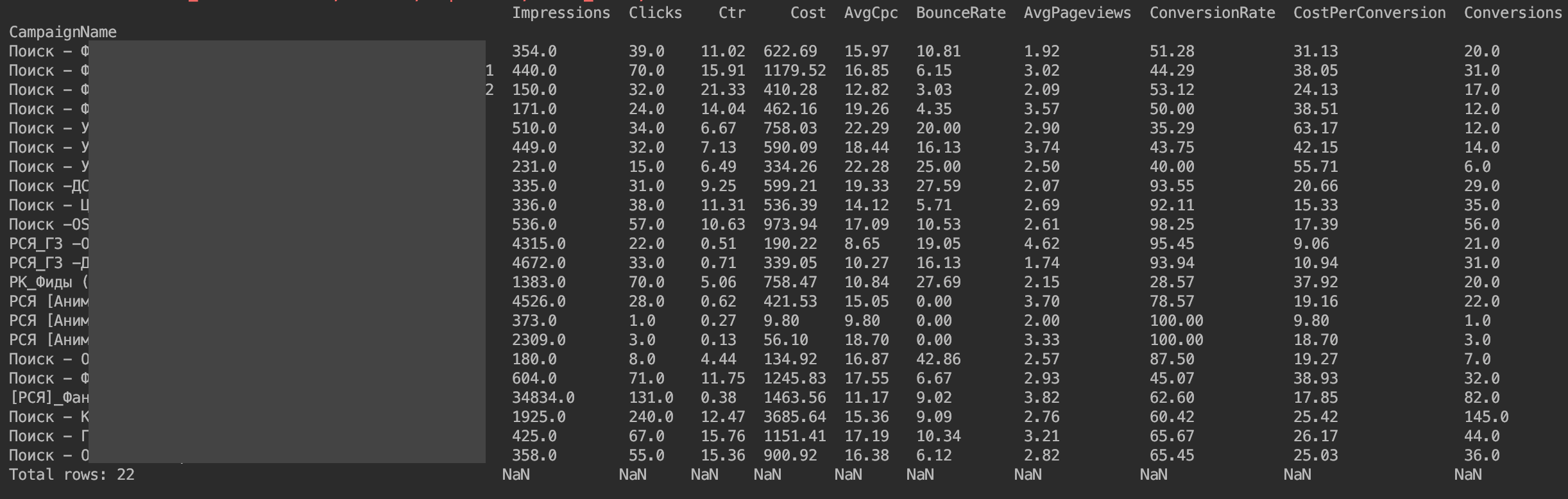
Für mich selbst habe ich ähnliche Anfragen nach Statistiken nach Tag und Kampagne geschrieben, um immer über Verkehrsabweichungen informiert zu sein und zu verstehen, wo die Abweichung ungefähr aufgetreten ist.
Vielen Dank für Ihre Aufmerksamkeit.
Endcode: import requests from requests.exceptions import ConnectionError from time import sleep import json import pandas as pd import numpy as np from pandas import Series,DataFrame pd.set_option('display.max_columns', None) pd.set_option('display.expand_frame_repr', False) pd.set_option('max_colwidth', -1) # UTF-8 Python 3, Python 2 import sys if sys.version_info < (3,): def u(x): try: return x.encode("utf8") except UnicodeDecodeError: return x else: def u(x): if type(x) == type(b''): return x.decode('utf8') else: return x # --- --- # Reports JSON- () ReportsURL = 'https://api.direct.yandex.com/json/v5/reports' # OAuth- , token = ' ' # # , clientLogin = ' ' # --- --- # HTTP- headers = { # OAuth-. Bearer "Authorization": "Bearer " + token, # "Client-Login": clientLogin, # "Accept-Language": "ru", # "processingMode": "auto" # # "returnMoneyInMicros": "false", # # "skipReportHeader": "true", # # "skipColumnHeader": "true", # # "skipReportSummary": "true" } # body = { "params": { "SelectionCriteria": { "Filter": [ { "Field": "Clicks", "Operator": "GREATER_THAN", "Values": [ "0" ] }, ] }, "FieldNames": [ "CampaignName", "Impressions", "Clicks", "Ctr", "Cost", "AvgCpc", "BounceRate", "AvgPageviews", "ConversionRate", "CostPerConversion", "Conversions" ], "ReportName": u("Report4"), "ReportType": "CAMPAIGN_PERFORMANCE_REPORT", "DateRangeType": "LAST_5_DAYS", "Format": "TSV", "IncludeVAT": "NO", "IncludeDiscount": "NO" } } # JSON body = json.dumps(body, indent=4) # --- --- # HTTP- 200, # HTTP- 201 202, while True: try: req = requests.post(ReportsURL, body, headers=headers) req.encoding = 'utf-8' # UTF-8 if req.status_code == 400: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(u(body))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 200: format(u(req.text)) break elif req.status_code == 201: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 202: print(" ") retryIn = int(req.headers.get("retryIn", 60)) print(" {} ".format(retryIn)) print("RequestId: {}".format(req.headers.get("RequestId", False))) sleep(retryIn) elif req.status_code == 500: print(" . , ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break elif req.status_code == 502: print(" .") print(", - .") print("JSON- : {}".format(body)) print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : \n{}".format(u(req.json()))) break else: print(" ") print("RequestId: {}".format(req.headers.get("RequestId", False))) print("JSON- : {}".format(body)) print("JSON- : \n{}".format(u(req.json()))) break # , API except ConnectionError: # print(" API") # break # - except: # print(" ") # break file = open("cashe.csv", "w") file.write(req.text) file.close() f = DataFrame.from_csv("cashe.csv",header=1, sep=' ', index_col=0,) f['Cost'] = f['Cost']/1000000 f['AvgCpc'] = f['AvgCpc']/1000000 f['CostPerConversion'] = f['CostPerConversion']/1000000 f=f.sort_values(by=['Clicks'], ascending=False) print(f)