Hallo Habr!
Heute werden wir die Fähigkeit entwickeln, Gruppierungs- und Datenvisualisierungstools in Python zu verwenden. In dem bereitgestellten
Datensatz zu Github werden wir verschiedene Merkmale analysieren und eine Reihe von Visualisierungen erstellen.
Nach der Tradition definieren wir am Anfang die Ziele:
- Gruppieren Sie Daten nach Geschlecht und Jahr und visualisieren Sie die allgemeine Fruchtbarkeitsdynamik beider Geschlechter.
- Finden Sie die beliebtesten Namen in der Geschichte;
- Teilen Sie den gesamten Zeitraum in den Daten in 10 Teile auf und finden Sie für jeden den beliebtesten Namen für jedes Geschlecht. Visualisieren Sie für jeden gefundenen Namen seine Dynamik für die gesamte Zeit.
- Berechnen Sie für jedes Jahr, wie viele Namen 50% der Personen abdecken und visualisieren (für jedes Jahr werden verschiedene Namen angezeigt).
- Wählen Sie 4 Jahre aus dem gesamten Zeitraum aus und zeigen Sie für jedes Jahr die Verteilung nach dem ersten Buchstaben im Namen und nach dem letzten Buchstaben im Namen an.
- Erstellen Sie eine Liste mehrerer berühmter Personen (Präsidenten, Sänger, Schauspieler, Filmhelden) und bewerten Sie deren Auswirkungen auf die Dynamik von Namen. Visualisierung erstellen.
Weniger Wörter, mehr Code!
Und lass uns gehen.
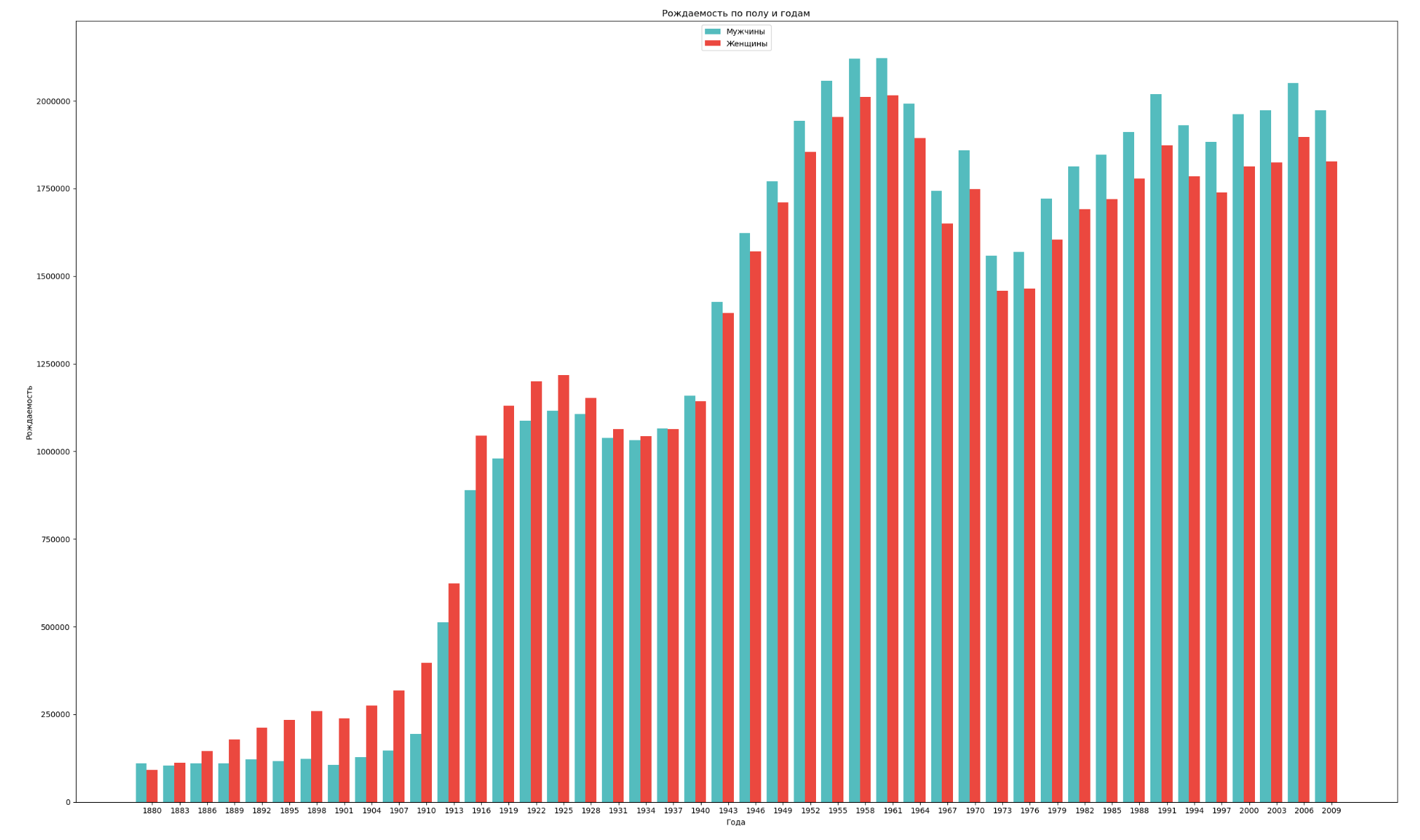
Gruppieren Sie die Daten nach Geschlecht und Jahr und visualisieren Sie die allgemeine Dynamik der Geburtenrate beider Geschlechter:
import numpy as np import pandas as pd import matplotlib.pyplot as plt years = np.arange(1880, 2011, 3) datalist = 'https://raw.githubusercontent.com/wesm/pydata-book/2nd-edition/datasets/babynames/yob{year}.txt' dataframes = [] for year in years: dataset = datalist.format(year=year) dataframe = pd.read_csv(dataset, names=['name', 'sex', 'count']) dataframes.append(dataframe.assign(year=year)) result = pd.concat(dataframes) sex = result.groupby('sex') births_men = sex.get_group('M').groupby('year', as_index=False) births_women = sex.get_group('F').groupby('year', as_index=False) births_men_list = births_men.aggregate(np.sum)['count'].tolist() births_women_list = births_women.aggregate(np.sum)['count'].tolist() fig, ax = plt.subplots() fig.set_size_inches(25,15) index = np.arange(len(years)) stolb1 = ax.bar(index, births_men_list, 0.4, color='c', label='') stolb2 = ax.bar(index + 0.4, births_women_list, 0.4, alpha=0.8, color='r', label='') ax.set_title(' ') ax.set_xlabel('') ax.set_ylabel('') ax.set_xticklabels(years) ax.set_xticks(index + 0.4) ax.legend(loc=9) fig.tight_layout() plt.show()
Finden Sie die beliebtesten Namen in der Geschichte:
years = np.arange(1880, 2011) dataframes = [] for year in years: dataset = datalist.format(year=year) dataframe = pd.read_csv(dataset, names=['name', 'sex', 'count']) dataframes.append(dataframe) result = pd.concat(dataframes) names = result.groupby('name', as_index=False).sum().sort_values('count', ascending=False) names.head(10)

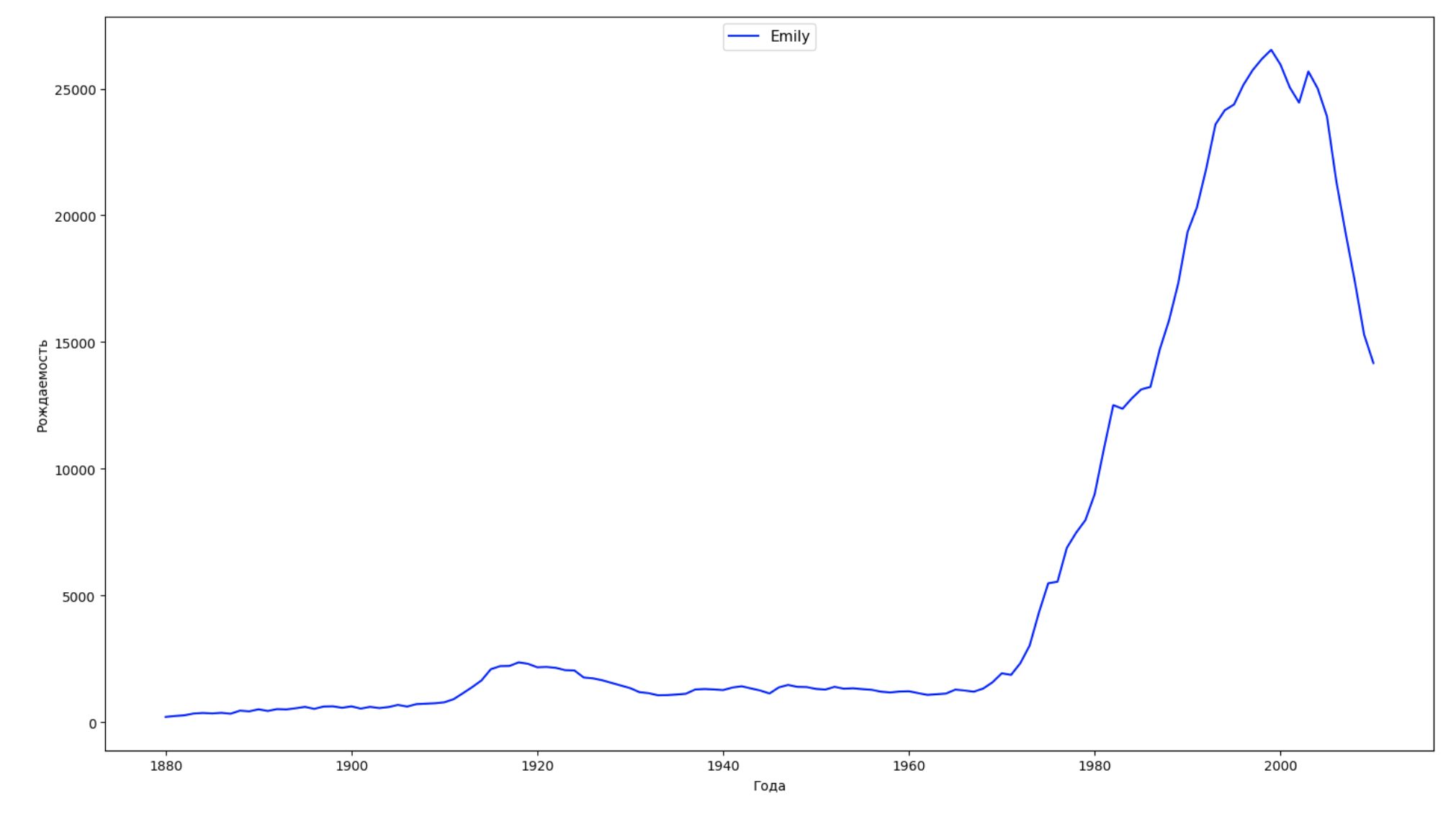
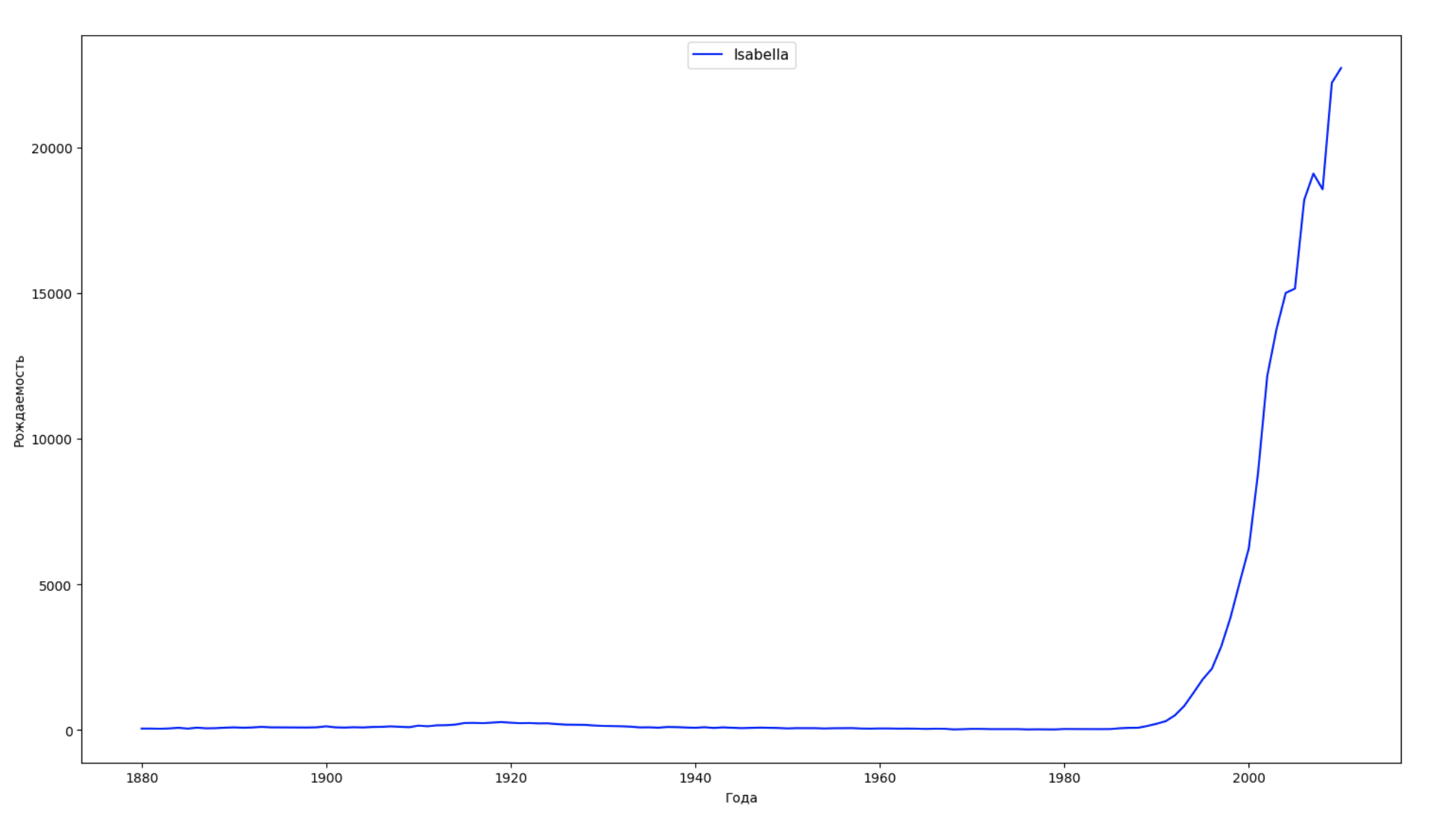
Wir teilen den gesamten Zeitraum in den Daten in 10 Teile auf und finden für jeden den beliebtesten Namen jedes Geschlechts. Visualisieren Sie für jeden gefundenen Namen seine Dynamik für die gesamte Zeit:
years = np.arange(1880, 2011) part_size = int((years[years.size - 1] - years[0]) / 10) + 1 parts = {} def GetPart(year): return int((year - years[0]) / part_size) for year in years: index = GetPart(year) r = years[0] + part_size * index, min(years[years.size - 1], years[0] + part_size * (index + 1)) parts[index] = str(r[0]) + '-' + str(r[1]) dataframe_parts = [] dataframes = [] for year in years: dataset = datalist.format(year=year) dataframe = pd.read_csv(dataset, names=['name', 'sex', 'count']) dataframe_parts.append(dataframe.assign(years=parts[GetPart(year)])) dataframes.append(dataframe.assign(year=year)) result_parts = pd.concat(dataframe_parts) result = pd.concat(dataframes) result_parts_sums = result_parts.groupby(['years', 'sex', 'name'], as_index=False).sum() result_parts_names = result_parts_sums.iloc[result_parts_sums.groupby(['years', 'sex'], as_index=False).apply(lambda x: x['count'].idxmax())] result_sums = result.groupby(['year', 'sex', 'name'], as_index=False).sum() for groupName, groupLabels in result_parts_names.groupby(['name', 'sex']).groups.items(): group = result_sums.groupby(['name', 'sex']).get_group(groupName) fig, ax = plt.subplots(1, 1, figsize=(18,10)) ax.set_xlabel('') ax.set_ylabel('') label = group['name'] ax.plot(group['year'], group['count'], label=label.aggregate(np.max), color='b', ls='-') ax.legend(loc=9, fontsize=11) plt.show()
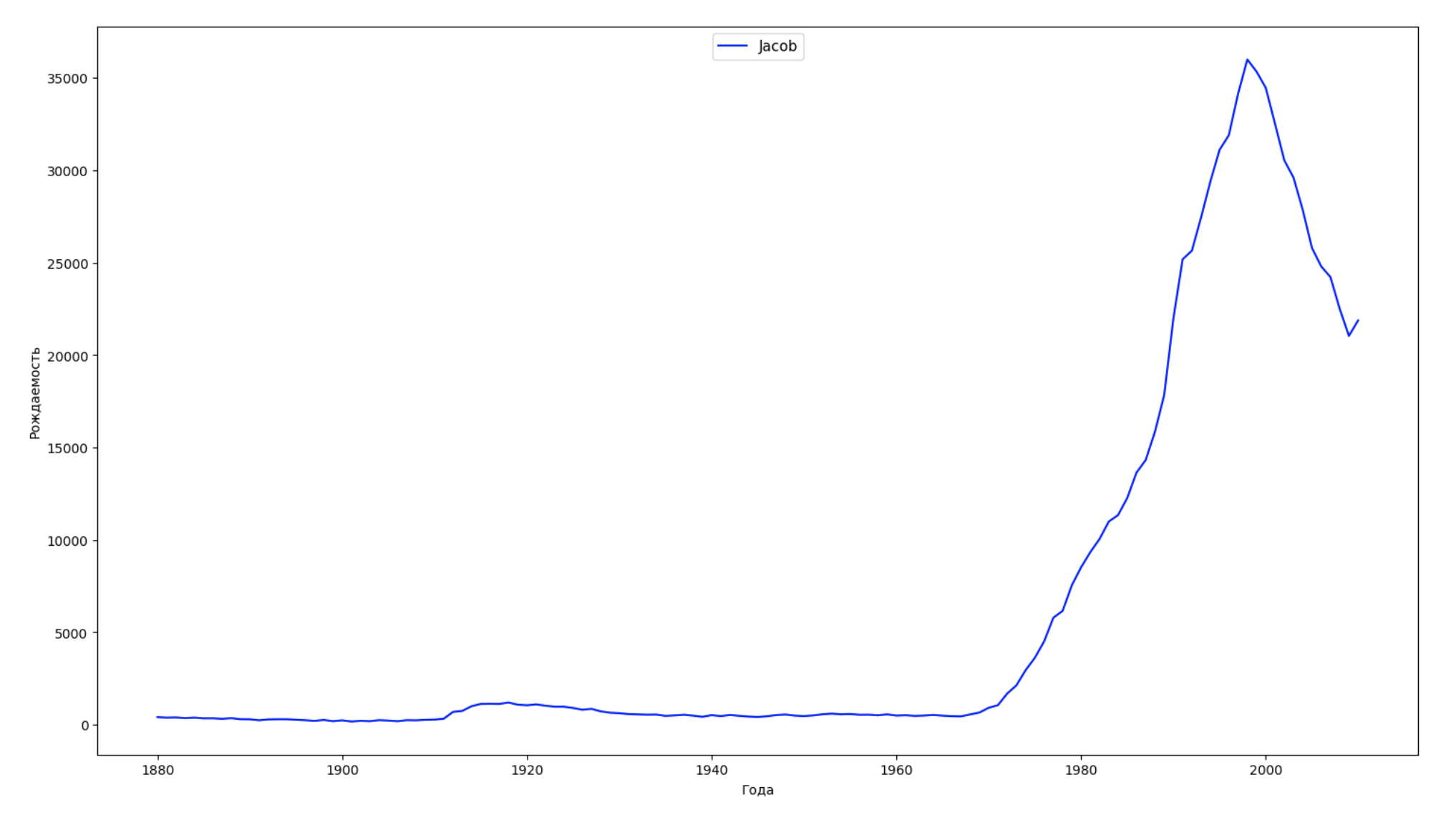

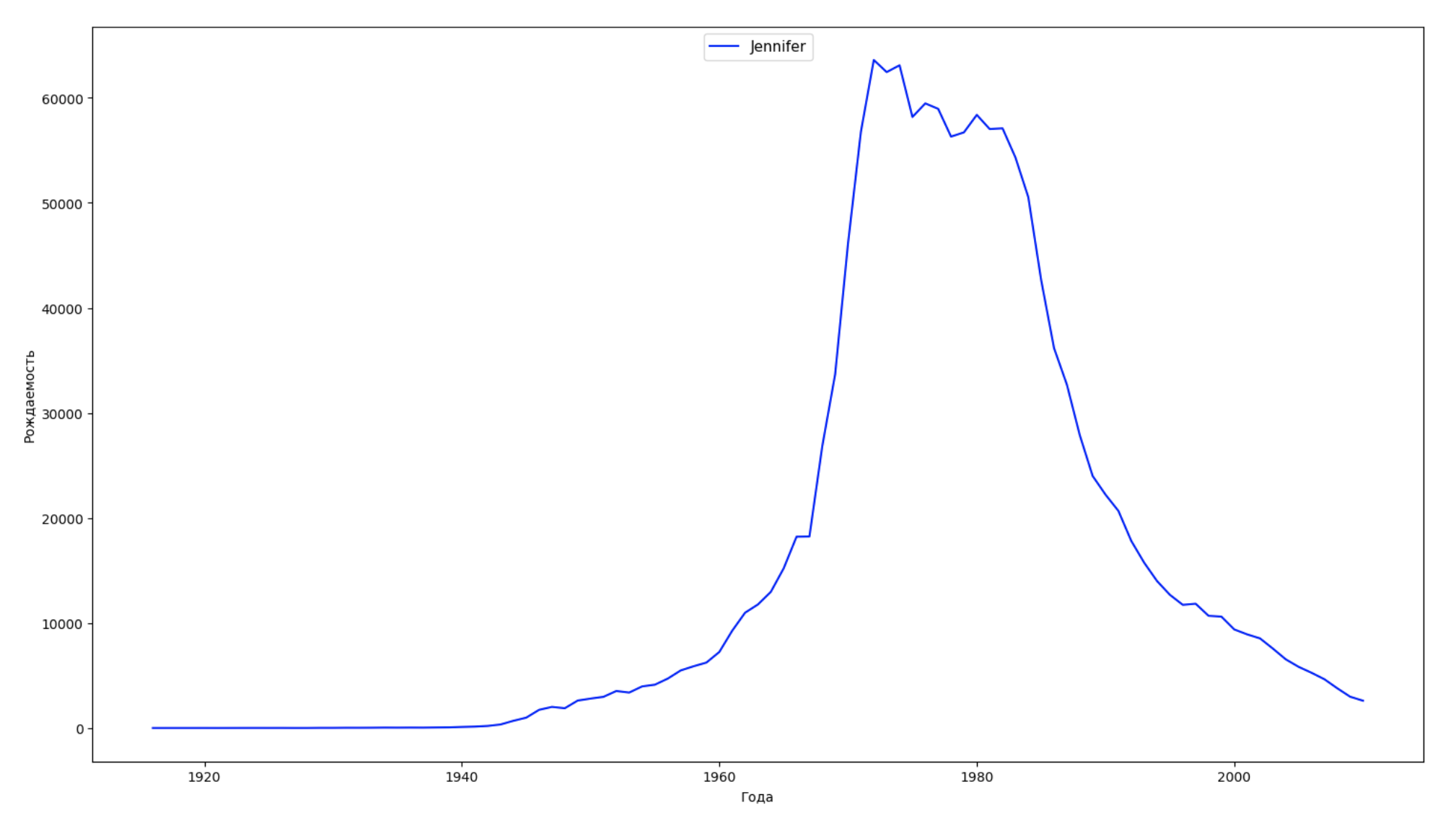
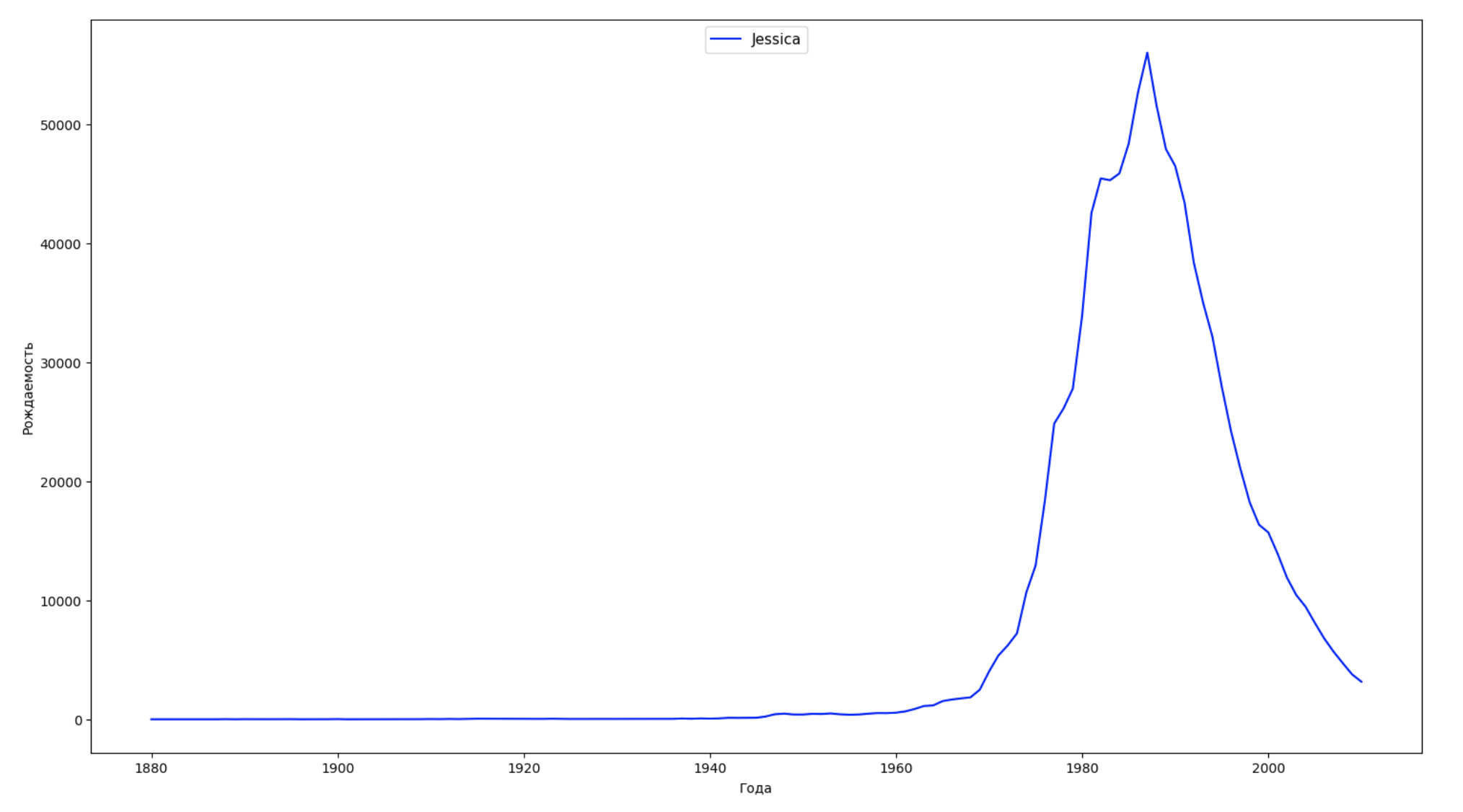
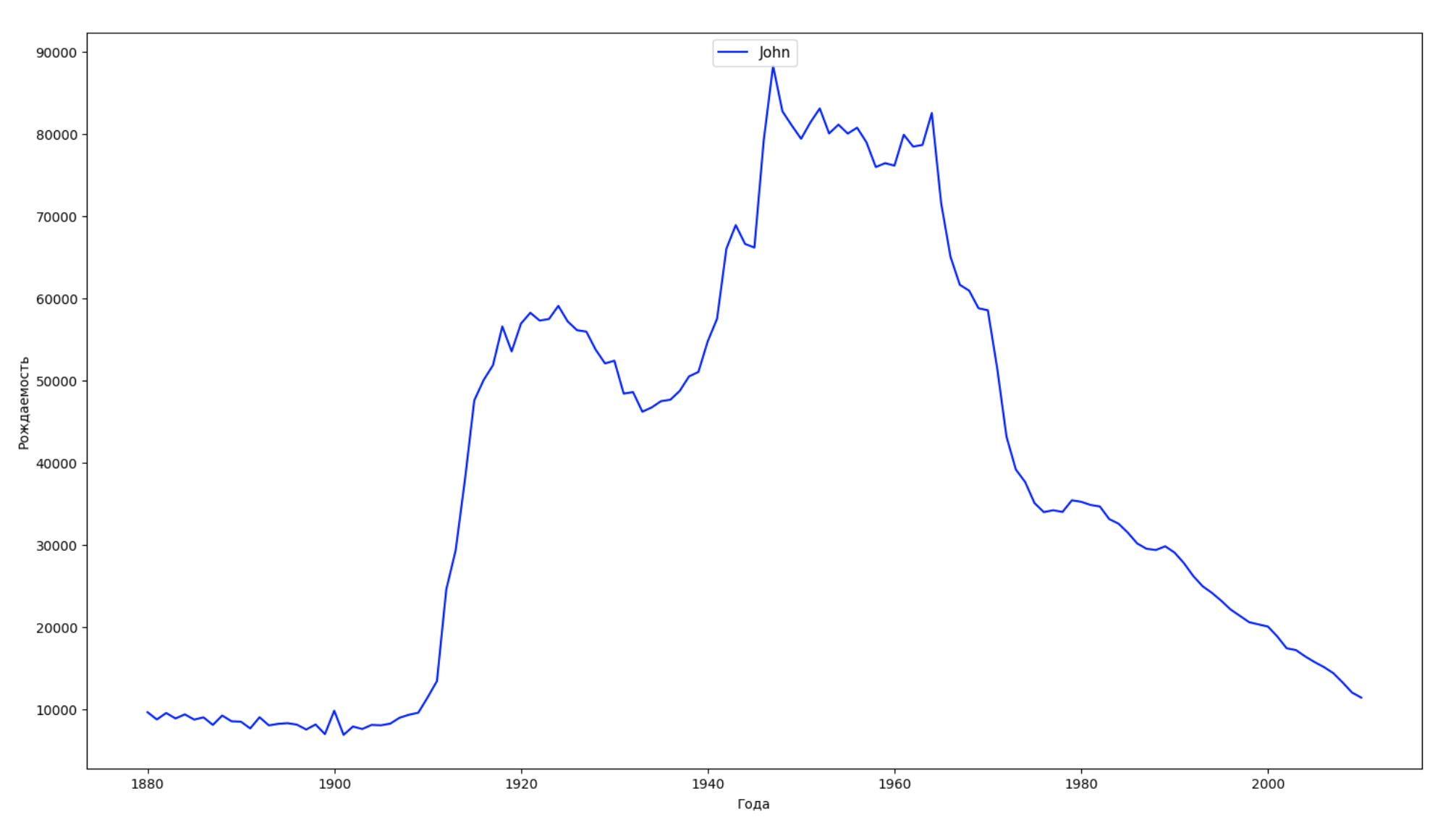


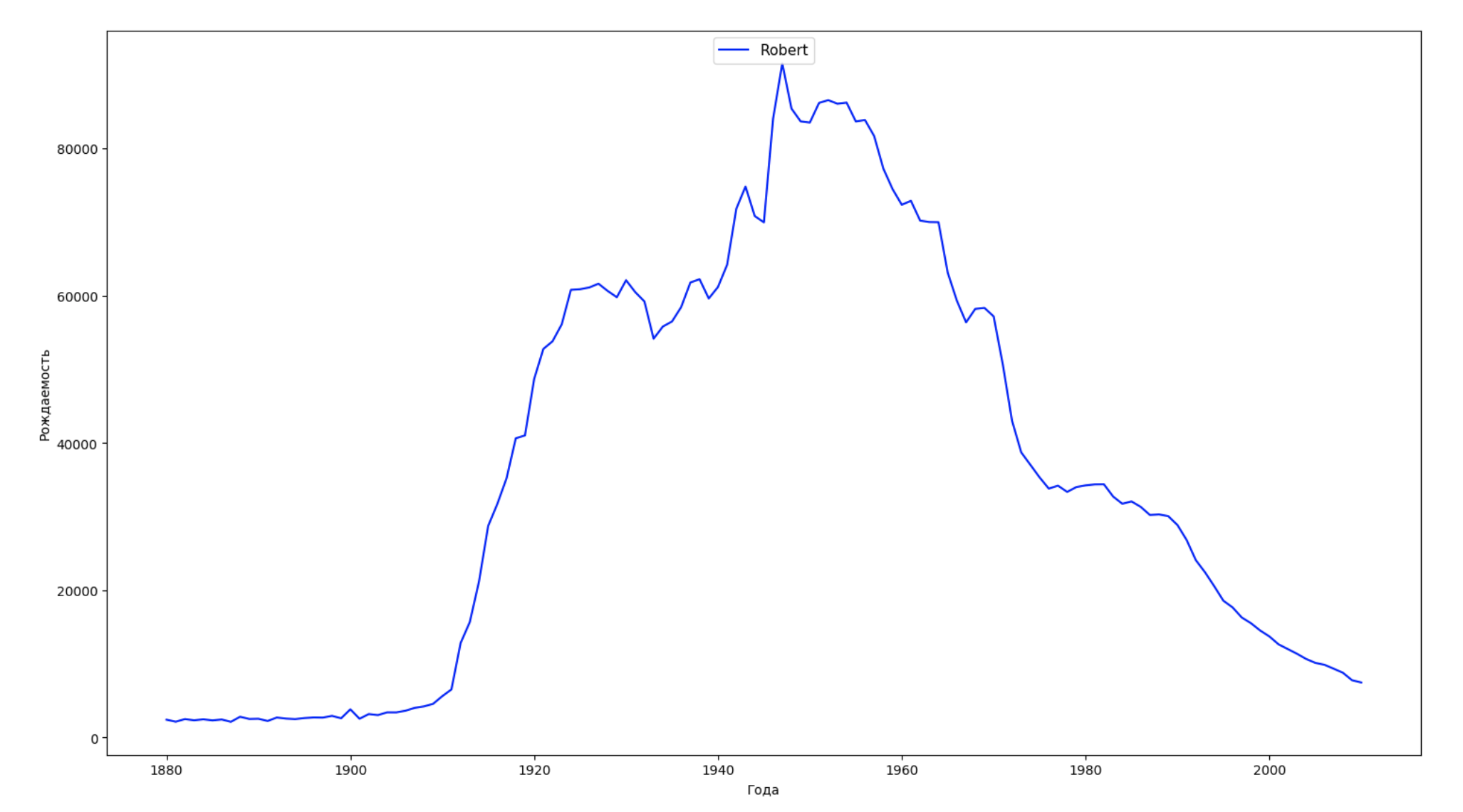
Für jedes Jahr berechnen wir, wie viele Namen 50% der Personen diese Daten abdecken und visualisieren:
dataframe = pd.DataFrame({'year': [], 'count': []}) years = np.arange(1880, 2011) for year in years: dataset = datalist.format(year=year) csv = pd.read_csv(dataset, names=['name', 'sex', 'count']) names = csv.groupby('name', as_index=False).aggregate(np.sum) names['sum'] = names.sum()['count'] names['percent'] = names['count'] / names['sum'] * 100 names = names.sort_values(['percent'], ascending=False) names['cum_perc'] = names['percent'].cumsum() names_filtered = names[names['cum_perc'] <= 50] dataframe = dataframe.append(pd.DataFrame({'year': [year], 'count': [names_filtered.shape[0]]})) fig, ax1 = plt.subplots(1, 1, figsize=(22,13)) ax1.set_xlabel('', fontsize = 12) ax1.set_ylabel(' ', fontsize = 12) ax1.plot(dataframe['year'], dataframe['count'], color='r', ls='-') ax1.legend(loc=9, fontsize=12) plt.show()

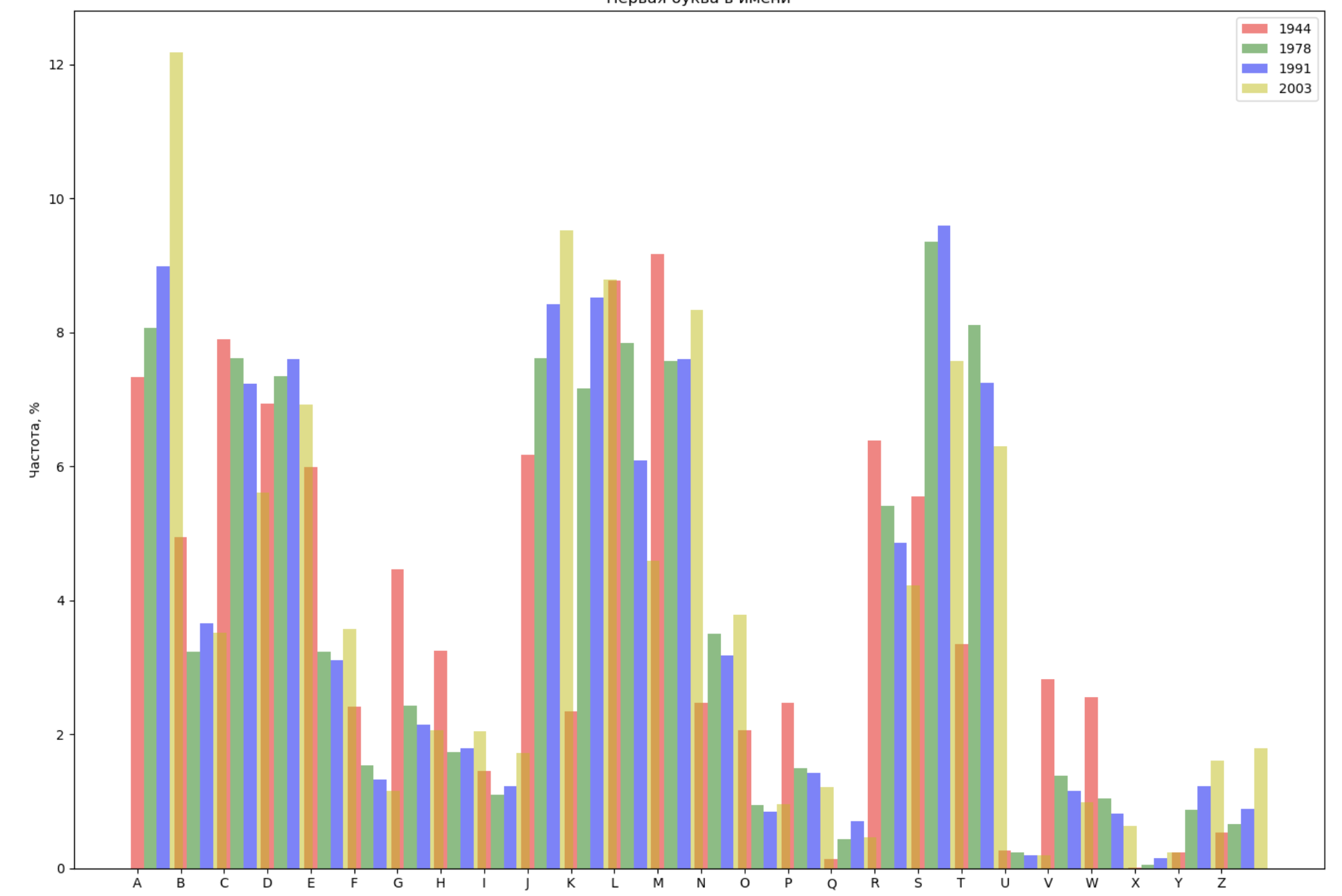
Wählen Sie 4 Jahre aus dem gesamten Zeitraum und zeigen Sie für jedes Jahr die Verteilung nach dem ersten Buchstaben im Namen und nach dem letzten Buchstaben im Namen an:
from string import ascii_lowercase, ascii_uppercase fig_first, ax_first = plt.subplots(1, 1, figsize=(14,10)) fig_last, ax_last = plt.subplots(1, 1, figsize=(14,10)) index = np.arange(len(ascii_uppercase)) years = [1944, 1978, 1991, 2003] colors = ['r', 'g', 'b', 'y'] n = 0 for year in years: dataset = datalist.format(year=year) csv = pd.read_csv(dataset, names=['name', 'sex', 'count']) names = csv.groupby('name', as_index=False).aggregate(np.sum) count = names.shape[0] dataframe = pd.DataFrame({'letter': [], 'frequency_first': [], 'frequency_last': []}) for letter in ascii_uppercase: countFirst = (names[names.name.str.startswith(letter)].count()['count']) countLast = (names[names.name.str.endswith(letter.lower())].count()['count']) dataframe = dataframe.append(pd.DataFrame({ 'letter': [letter], 'frequency_first': [countFirst / count * 100], 'frequency_last': [countLast / count * 100]})) ax_first.bar(index + 0.3 * n, dataframe['frequency_first'], 0.3, alpha=0.5, color=colors[n], label=year) ax_last.bar(index + bar_width * n, dataframe['frequency_last'], 0.3, alpha=0.5, color=colors[n], label=year) n += 1 ax_first.set_xlabel(' ') ax_first.set_ylabel(', %') ax_first.set_title(' ') ax_first.set_xticks(index) ax_first.set_xticklabels(ascii_uppercase) ax_first.legend() ax_last.set_xlabel(' ') ax_last.set_ylabel(', %') ax_last.set_title(' ') ax_last.set_xticks(index) ax_last.set_xticklabels(ascii_uppercase) ax_last.legend() fig_first.tight_layout() fig_last.tight_layout() plt.show()
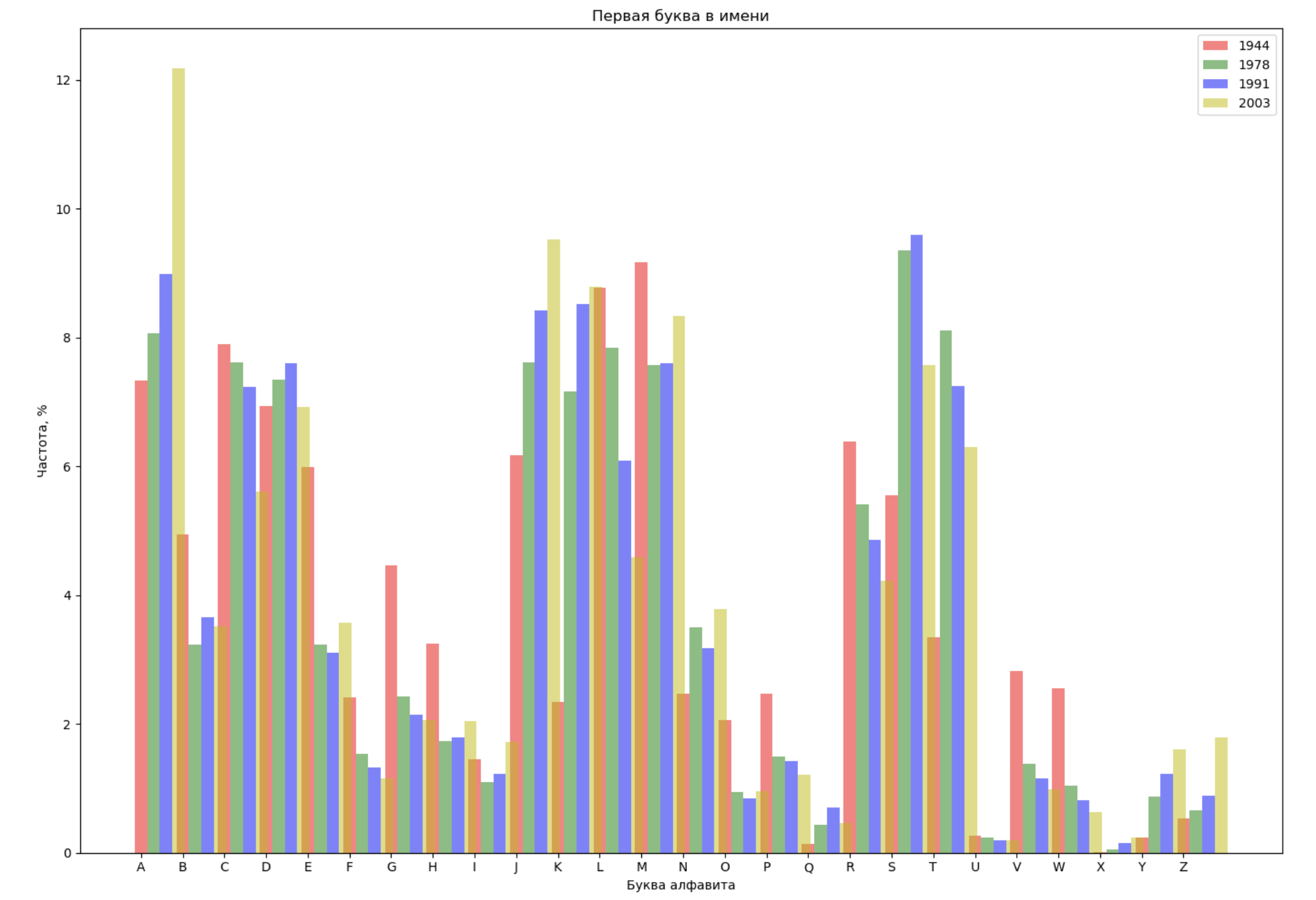

Lassen Sie uns eine Liste mehrerer berühmter Personen (Präsidenten, Sänger, Schauspieler, Filmhelden) erstellen und deren Auswirkungen auf die Dynamik von Namen bewerten:
celebrities = {'Frank': 'M', 'Britney': 'F', 'Madonna': 'F', 'Bob': 'M'} dataframes = [] for year in years: dataset = datalist.format(year=year) dataframe = pd.read_csv(dataset, names=['name', 'sex', 'count']) dataframes.append(dataframe.assign(year=year)) result = pd.concat(dataframes) for celebrity, sex in celebrities.items(): names = result[result.name == celebrity] dataframe = names[names.sex == sex] fig, ax = plt.subplots(1, 1, figsize=(16,8)) ax.set_xlabel('', fontsize = 10) ax.set_ylabel('', fontsize = 10) ax.plot(dataframe['year'], dataframe['count'], label=celebrity, color='r', ls='-') ax.legend(loc=9, fontsize=12) plt.show()
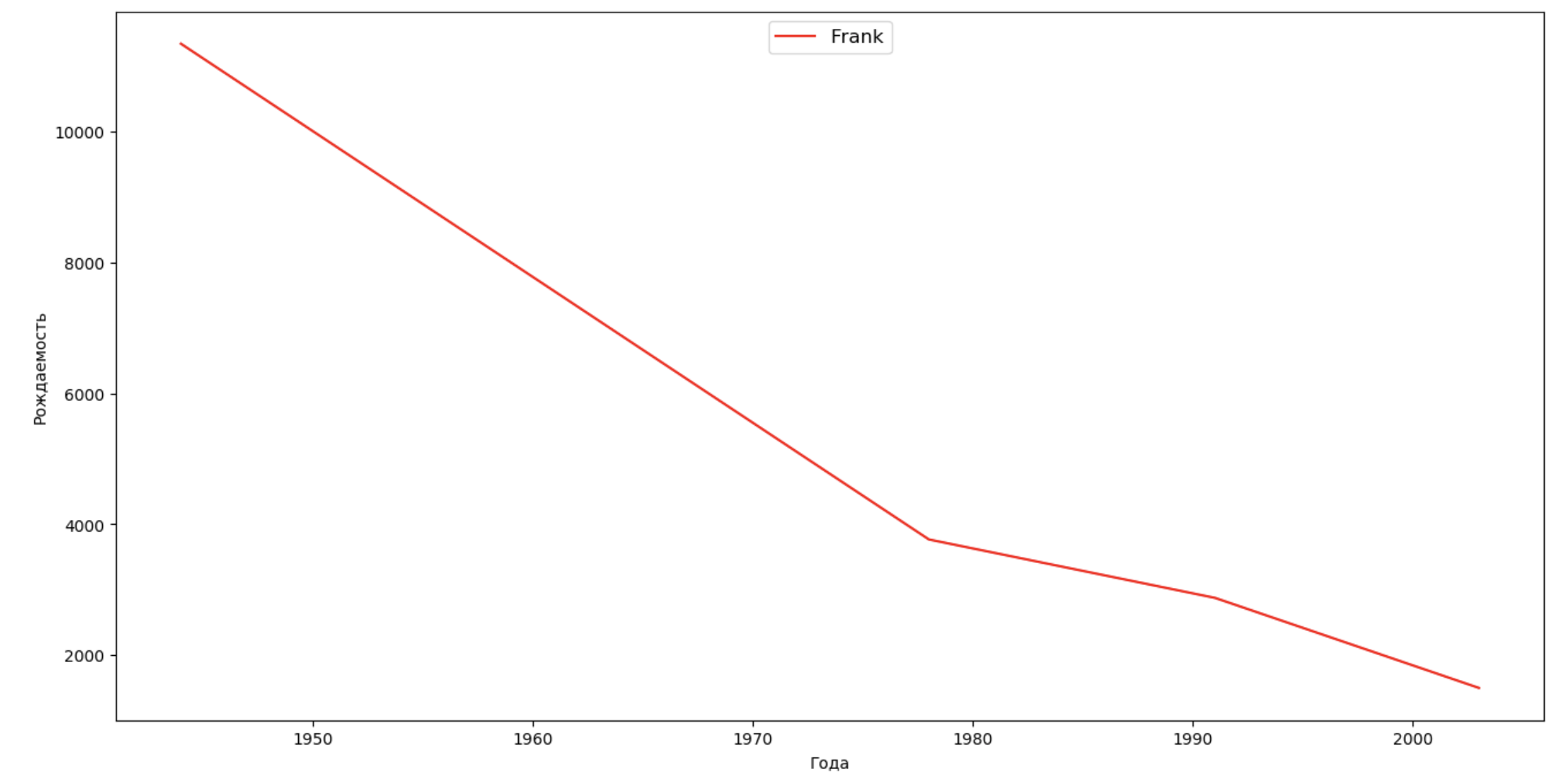
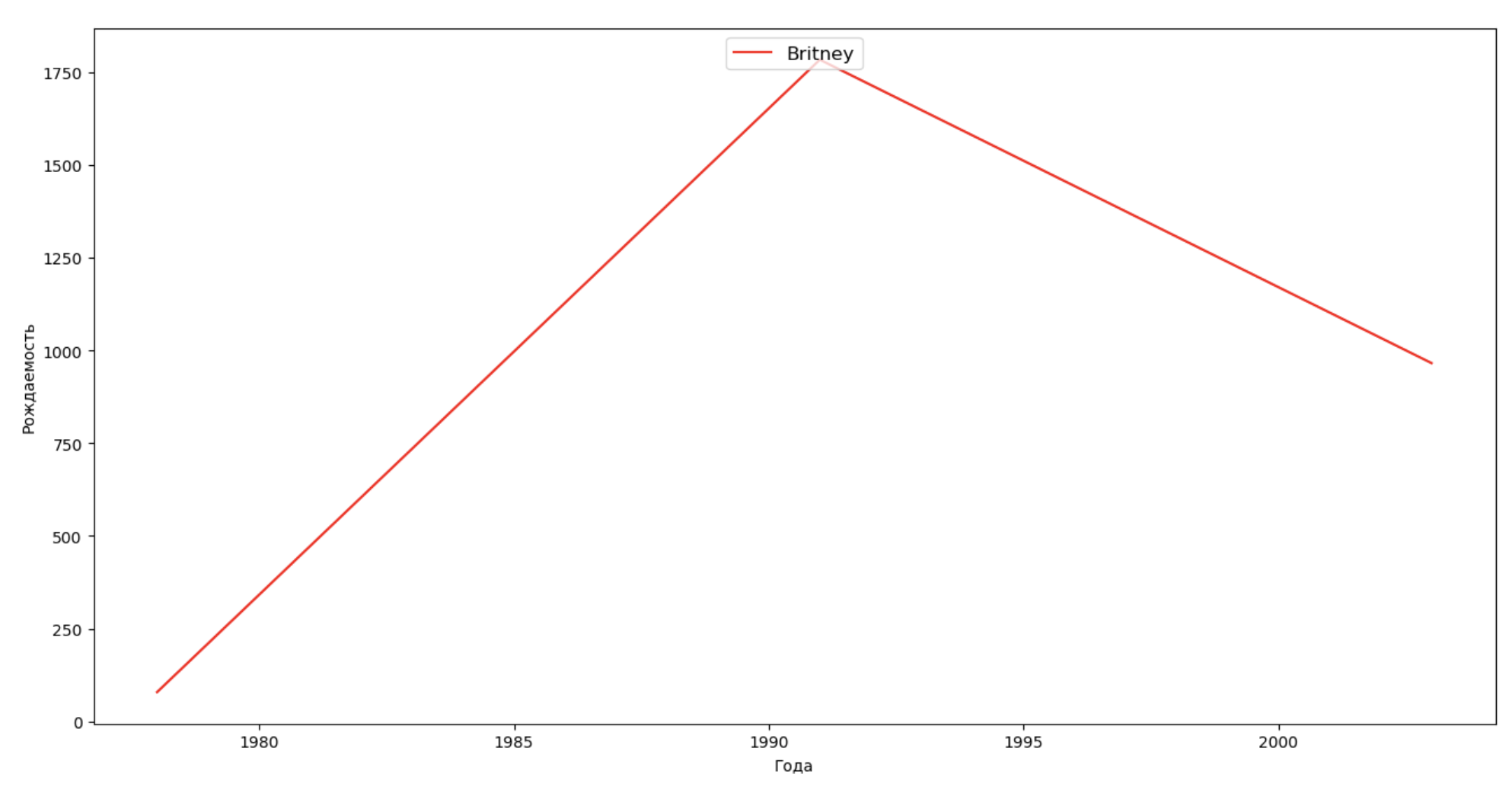
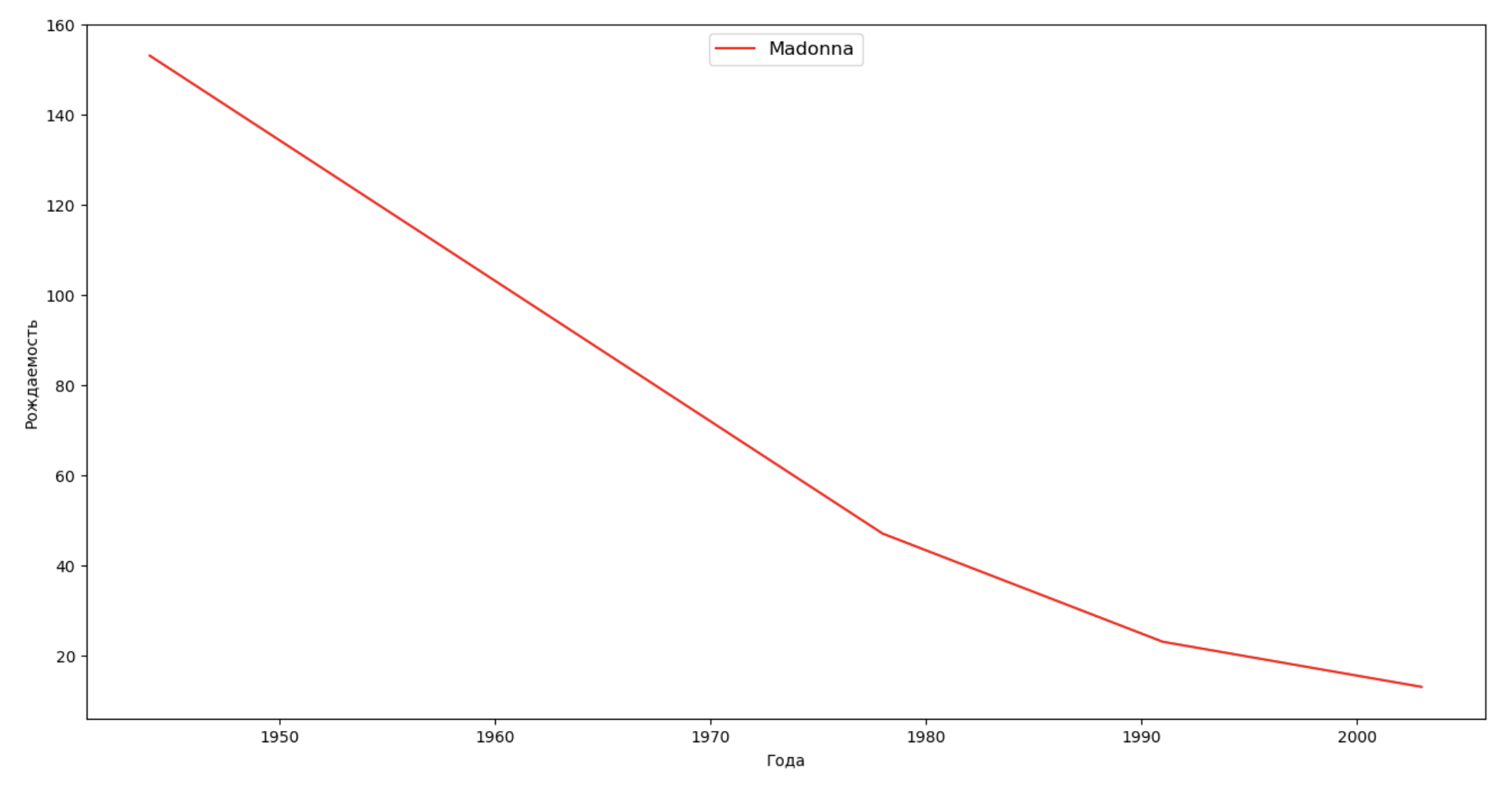
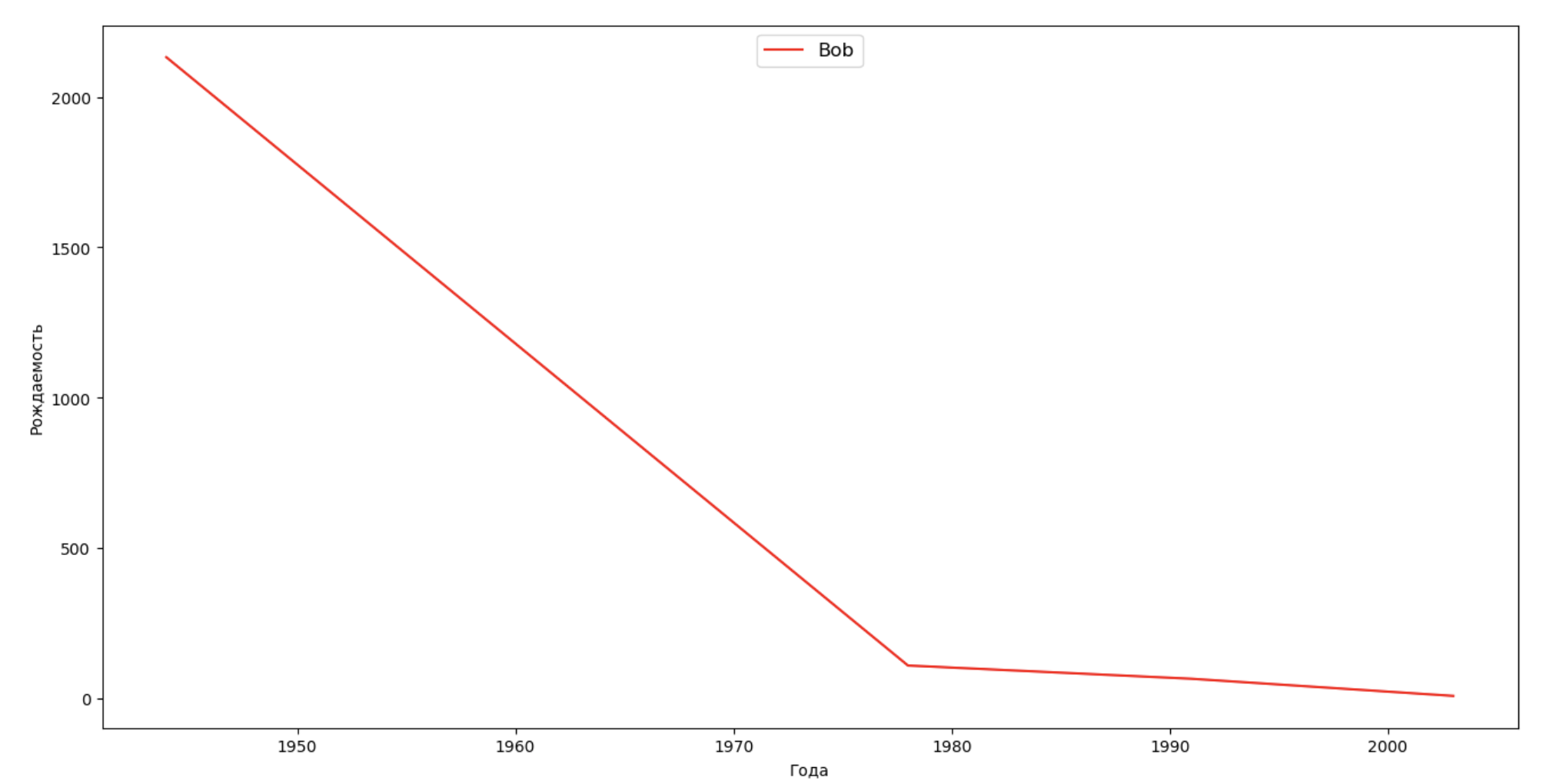
Für das Training können Sie die Lebensdauer des Prominenten zur Visualisierung aus dem letzten Beispiel hinzufügen, um deren Einfluss auf die Dynamik von Namen visuell zu bewerten.
Damit wurden alle unsere Ziele erreicht und erfüllt. Wir haben die Fähigkeit entwickelt, Datengruppierungs- und Visualisierungstools in Python zu verwenden, und wir werden weiterhin mit Daten arbeiten. Jeder kann für sich selbst Schlussfolgerungen zu vorgefertigten, visualisierten Daten ziehen.
Alles Wissen!