Wir veröffentlichen weiterhin Videos und Transkripte der besten Berichte der
PGConf.Russia 2019- Konferenz. Ein Bericht von Oleg Bartunov zum Thema „Professional Postgres“ eröffnete den Plenarteil der Konferenz. Es enthüllt die Geschichte von Postgres DBMS, den russischen Beitrag zur Entwicklung, Architekturmerkmale.
Frühere Materialien in dieser Reihe: „Typische Fehler bei der Arbeit mit PostgreSQL“ von Ivan Frolkov, Teil
1 und
2 .

Ich werde über professionelle Postgres sprechen. Bitte verwechseln Sie nicht die Firma, die ich jetzt vertrete - Postgres Professional.

Ich werde wirklich darüber sprechen, wie Postgres, das als akademische Amateurentwicklung begann, professionell wurde - so wie wir es jetzt sehen. Ich werde nur meine persönliche Meinung äußern, sie spiegelt weder die Meinung unseres Unternehmens noch einer Gruppe wider.

Es ist so passiert, dass ich Postgres-Schnipsel benutze und nicht mache, sondern kontinuierlich von 1995 bis heute. Seine ganze Geschichte ging vor meinen Augen vorbei, ich bin Teilnehmer an den Hauptereignissen.
Die Geschichte
Auf dieser Folie habe ich kurz die Projekte skizziert, an denen ich teilgenommen habe. Viele von ihnen sind Ihnen vertraut. Und ich werde die Geschichte von Postgres sofort mit einem Bild beginnen, das ich vor vielen, vielen Jahren gemalt und dann einfach erstellt habe - die Anzahl der Versionen nimmt zu. Es spiegelt die Entwicklung relationaler Datenbanken wider. Auf der linken Seite, wenn jemand es nicht weiß, ist dies
Michael Stonebreaker , der der Vater von Postgres genannt wird. Nachfolgend finden Sie unsere ersten "nuklearen" Entwickler. Die Person, die rechts sitzt, ist Vadim Mikheev aus Krasnojarsk, er war einer der ersten Kernentwickler.
Ich werde die Geschichte des relationalen Modells mit IBM beginnen, das einen großen Beitrag zur Branche geleistet hat. Es war IBM, die für
Edgar Codd arbeitete. Das erste Whitepaper zu
IBM System R erschien aus dem Darm - es war die erste relationale Datenbank. Mike Stonebreaker arbeitete zu dieser Zeit in Burkeley. Er hat diesen Artikel gelesen und mit seinen Jungs Feuer gefangen: Wir müssen eine Datenbank erstellen.

In diesen Jahren - zu Beginn der 70er Jahre - gab es, wie Sie vermuten, nicht viele Computer. Es gab einen PDP-11 für die gesamte Informatikabteilung in Berkeley, und alle Studenten und Fakultäten kämpften um die Maschinenzeit. Diese Maschine wurde hauptsächlich für Berechnungen verwendet. Ich selbst habe in jungen Jahren so gearbeitet: Sie geben dem Bediener eine Aufgabe, er startet sie. Aber Studenten und Entwickler wollten interaktive Arbeit. Es war unser Traum - an der Fernbedienung zu sitzen, Programme einzugeben, sie zu debuggen. Und als Mike Stonebreaker und seine Freunde die erste Basis errichteten, nannten sie sie
Ingres - das INteractive Grafic REtrieval System. Die Leute verstanden nicht: Warum interaktiv? Und das war nur ein Traum seiner Entwickler. Sie hatten einen Konsolen-Client, mit dem sie mit Ingres arbeiten konnten. Er hat viel von unserer Industrie gegeben. Sehen Sie, wie viele Pfeile es von Ingres gibt? Dies sind die Datenbanken, die er beeinflusst hat und die seinen Code durcheinander gebracht haben. Michael Stonebreaker hatte viele Entwicklungsstudenten, die
Sybase und
MS SQL ,
NonStop SQL ,
Illustra und
Informix verließen und dann entwickelten.
Als Ingres so viel entwickelte, dass es kommerziell interessant wurde, wurde
Illustra gegründet (dies war das Jahr 1992), und der
Illustra DBMS-Code wurde von
Informix gekauft , das später von
IBM gegessen wurde, und somit ging der Code an
DB2 . Aber was hat
IBM an
Ingres interessiert? Zuallererst Erweiterbarkeit - diese revolutionären Ideen, die Michael Stonebreaker von Anfang an aufstellte und der Meinung war, dass die Datenbank bereit sein sollte, alle geschäftlichen Probleme zu lösen. Dazu müssen Sie der Datenbank Ihre Datentypen, Zugriffsmethoden und Funktionen hinzufügen. Für uns Postgresisten scheint dies natürlich. In diesen Jahren war es eine Revolution. Seit der Zeit von Ingres und Postgres sind diese Funktionen zum De-facto-Standard für alle relationalen Datenbanken geworden. Jetzt haben alle Datenbanken Benutzerfunktionen, und als Stonebreaker schrieb, dass Benutzerfunktionen benötigt werden, rief
Oracle beispielsweise, dass dies gefährlich sei und dass dies nicht möglich sei, da Benutzer die Daten beschädigen könnten. Jetzt sehen wir, dass in allen Datenbanken benutzerdefinierte Funktionen vorhanden sind, mit denen Sie Ihre eigenen Aggregate und Datentypen erstellen können.

Postgres entwickelte sich als akademische Entwicklung, was bedeutet: Es gibt einen Professor, er hat ein Stipendium für Entwicklung, Studenten und Doktoranden, die mit ihm arbeiten. Eine seriöse Basis, die für die Produktion bereit ist, kann so nicht geschaffen werden. Die neueste Version von Berkeley -
Postgres95 - hat jedoch bereits
SQL hinzugefügt. Zu dieser Zeit begannen studentische Entwickler bereits bei Illustra zu arbeiten, machten Informix und verloren das Interesse an dem Projekt. Sie sagten: Wir haben Postgres95, nimm es, wer es braucht! Ich erinnere mich sehr gut an all das, weil ich selbst einer derjenigen war, die diesen Brief erhalten haben: Es gab eine Mailingliste und weniger als 400 Abonnenten. Die
Postgres95- Community begann mit diesen 400 Personen. Wir haben alle gemeinsam für dieses Projekt gestimmt. Wir haben einen Enthusiasten gefunden, der den CVS-Server abgeholt hat, und wir haben alles nach Panama gezogen, da die Server dort waren.
Die Geschichte von
PostgreSQL [im Folgenden einfach Postgres] beginnt mit Version 6.0, da die Versionen 1, 4, 5 noch Postgres95 waren. Am 3. April 1997 erschien unser Logo - ein Elefant. Vorher hatten wir verschiedene Tiere. Auf meiner Seite gab es zum Beispiel
lange Zeit einen Geparden , was darauf hindeutet, dass Postgres sehr schnell ist. Dann wurde in der Mailingliste eine Frage aufgeworfen: Unsere große Datenbank braucht ein ernstes Tier. Und jemand schrieb: Lass es ein Elefant sein. Alle haben zusammen abgestimmt, dann haben unsere Jungs aus St. Petersburg dieses Logo gezeichnet. Anfangs war es ein Elefant in einem Diamanten - wenn Sie tiefer in eine Zeitmaschine eintauchen, werden Sie es sehen. Der Elefant wurde ausgewählt, weil Elefanten ein sehr gutes Gedächtnis haben. Sogar Agatha Christie hat eine Geschichte „Elefanten können sich erinnern“: Der Elefant ist dort sehr rachsüchtig, er erinnerte sich etwa fünfzig Jahre lang an das Vergehen und hat dann den Täter niedergeschlagen. Der Diamant wurde dann abgespalten, das vektorisierte Muster, und das Ergebnis war dieser Elefant. Dies ist also einer der ersten russischen Beiträge zu Postgres.

Cheetah ersetzte Elephant im Diamanten:

Postgres Entwicklungsstadien
Die erste Aufgabe bestand darin, seine Arbeit zu stabilisieren. Die Community hat den Quellcode für akademische Entwickler übernommen. Was war nicht da! Sie fingen an, all dies zu schaufeln, um anständig zu kompilieren. Auf dieser Folie habe ich das Jahr 1997 hervorgehoben, Version 6.1 - Internationalisierung erschien darin. Ich habe es nicht hervorgehoben, weil ich es selbst gemacht habe (es war wirklich mein erster Patch), sondern weil es eine wichtige Phase war. Sie sind bereits daran gewöhnt, dass Postgres mit jeder Sprache und an jedem Ort arbeitet - auf der ganzen Welt. Und dann verstand er nur ASCII, also keine 8 Bits, keine europäischen Sprachen, kein Russisch. Nachdem ich dies nach den Prinzipien von Open Source entdeckt hatte, nahm ich einfach die Gebietsschemas und unterstützte sie. Und dank dieser Arbeit ging Postgres in die Welt. Nach mir unterstützte der Japaner
Tatsuo Ishii Multibyte-Codierungen, und Postgres wurde wirklich weltweit.
Im Jahr 2005 wurde die
Windows- Unterstützung eingeführt. Ich erinnere mich an diese hitzigen Debatten, als sie dies in der Mailingliste diskutierten. Alle Entwickler waren normale Leute, sie arbeiteten unter
Unix . Sie klatschen gerade und auf die gleiche Weise haben die Leute damals reagiert. Und dagegen gestimmt. Es dauerte Jahre. Darüber hinaus haben
SRA Computers einige Jahre zuvor ihren nativen Windows-Port
Powergres veröffentlicht. Aber es war ein rein japanisches Produkt. Als wir 2005 in der 8. Version Unterstützung für Windows erhielten, stellte sich heraus, dass dies ein starker Schritt war: Die Community war geschwollen. Es gab viele Leute und viele dumme Fragen, aber die Community wurde groß, wir haben vinduzovye Benutzer gepackt.
Im Jahr 2010 hatten wir eine integrierte Replikation. Das ist ein Schmerz. Ich erinnere mich, wie viele Jahre Menschen in Postgres um die Replikation gekämpft haben. Zuerst sagten alle: Wir brauchen keine Replikation, dies ist keine Datenbankangelegenheit, dies ist eine Angelegenheit externer Dienstprogramme. Wenn sich jemand erinnert, hat
Slony Jan Wieck gemacht. „Elefanten“ kamen übrigens auch aus der russischen Sprache: Jan fragte mich, wie viele Elefanten auf Russisch sein würden, und ich antwortete: „Elefanten“. Also machte er Slony. Diese Elefanten arbeiteten wie eine logische Replikation an Triggern. Ihre Konfiguration war ein Albtraum - Veteranen erinnern sich. Außerdem hörten alle lange auf
Tom Lane , der, wie ich mich erinnere, verzweifelt rief: Warum sollten wir den Code durch Replikation komplizieren, wenn dies außerhalb der Basis möglich ist? Infolgedessen wurde die Inline-Replikation weiterhin angezeigt. Dies führte sofort zu einer großen Anzahl von Unternehmensbenutzern, da diese Benutzer zuvor sagten: Wie können wir überhaupt ohne Replikation leben? Es ist unmöglich!
Im Jahr 2014 erschien jsonb. Dies ist meine Arbeit,
Fedor Sigaev und
Alexander Korotkov . Und auch die Leute riefen: Warum brauchen wir das? Im Allgemeinen hatten wir bereits den Laden, den wir 2003 gemacht haben, und 2006 trat er in Postgres ein. Die Leute haben es auf der ganzen Welt wunderbar benutzt, es geliebt, und wenn Sie
hstore auf Google
eingeben , erschien eine große Menge von Dokumenten. Sehr beliebte Erweiterung. Und wir haben die Idee unstrukturierter Daten in Postgres nachdrücklich gefördert. Von Anfang an war ich nur daran interessiert, und als wir
jsonb machten , erhielt ich viele Dankesbriefe und Fragen. Und die Community hat
NoSQL- Benutzer! Vor jsonb gingen die durch Hype zombifizierten Personen zum Schlüsselwert der Datenbank. Gleichzeitig waren sie gezwungen, Integrität und
ACID- Identität zu opfern. Und wir gaben ihnen die Gelegenheit, ohne etwas zu opfern, mit ihrem schönen Sohn zu arbeiten. Die Community ist wieder stark gewachsen.
Im Jahr 2016 haben wir parallele Abfrageausführung erhalten. Wenn jemand nicht weiß, ist dies natürlich nicht für
OLTP. Wenn Sie einen geladenen Computer haben, sind alle Kernel bereits ausgelastet. Die gleichzeitige Ausführung von Abfragen ist für
OLAP- Benutzer
hilfreich . Und sie schätzten es, dass eine bestimmte Anzahl von
OLAP- Benutzern in die Community kam.
Als nächstes kamen die kumulativen Prozesse. Im Jahr 2017 erhielten wir eine logische Replikation und eine deklarative Partitionierung - dies war auch ein großer und schwerwiegender Schritt, da durch die logische Replikation sehr, sehr interessante Systeme erstellt werden konnten, die Menschen unbegrenzte Freiheit für ihre Vorstellungskraft hatten und anfingen, Cluster zu erstellen. Durch deklarative Partitionierung wurde es möglich, Partitionen nicht manuell zu erstellen, sondern mit SQL.
Im Jahr 2018, in der 11. Version, haben wir
JIT . Wer weiß nicht, dies ist der Just In Time-Compiler: Sie kompilieren Anforderungen und können die Ausführung erheblich beschleunigen. Dies ist wichtig, um langsame Abfragen zu beschleunigen, da schnelle Abfragen bereits schnell sind und der Aufwand für die Kompilierung immer noch erheblich ist.
Das grundlegendste, was wir im Jahr 2019 erwarten, ist
steckbarer Speicher, eine API , mit der Entwickler ihre eigenen Repositorys erstellen können. Ein Beispiel hierfür ist
zheap - das Repository, das
EnterpriseDB entwickelt.
Und hier ist unsere Entwicklung: SQL / JSON. Ich hatte wirklich gehofft, dass
Sasha Korotkov ihn vor der Konferenz verpflichten würde, aber es gab einige Probleme, und jetzt hoffen wir, dass wir trotzdem
SQL / JSON in diesem Jahr bekommen. Die Leute haben zwei Jahre darauf gewartet [ein wesentlicher Teil des SQL / JSON: jsonpath-Patches wurde jetzt festgeschrieben, dies wird
hier ausführlich beschrieben].

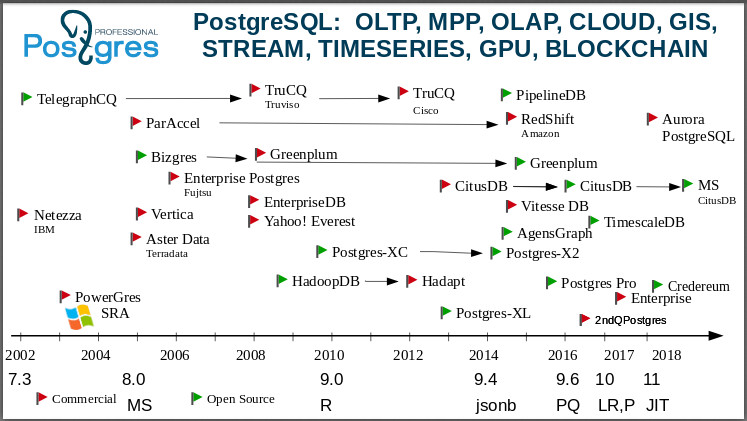
Als nächstes gehe ich zu einer Folie über, die zeigt: Postgres ist eine universelle Datenbank. Sie können dieses Bild stundenlang studieren und eine Reihe von Geschichten über die Entstehung von Unternehmen, die Übernahme und den Tod von Unternehmen erzählen. Ich werde im Jahr 2000 beginnen. Eine der ersten Gabeln von Postgres ist die IBM
Netezza . Stellen Sie sich vor: Der „Blaue Riese“ hat den Postgres-Code verwendet und eine Basis für OLAP zur Unterstützung seines BI erstellt!
Hier ist eine Abzweigung von
TelegraphCQ : Bereits im Jahr 2000 haben die Leute eine Streaming-Datenbank basierend auf Postgres in Berkeley erstellt. Wenn jemand es nicht weiß, ist dies eine Datenbank, die nicht an den Daten selbst interessiert ist, sondern an ihren Aggregaten. Jetzt gibt es viele Aufgaben, bei denen Sie nicht jeden Wert kennen müssen, z. B. die Temperatur zu einem bestimmten Zeitpunkt, sondern einen Durchschnittswert in dieser Region. Und in TelegraphCQ nahmen sie diese Idee (ebenfalls in Berkeley), eine der fortschrittlichsten Ideen dieser Zeit, und entwickelten eine Basis, die auf Postgres basiert. Es wurde weiterentwickelt und 2008 wurde auf seiner Basis ein kommerzielles Produkt veröffentlicht - die
TruCQ- Basis, deren Eigentümer jetzt
Cisco ist .
Ich habe vergessen zu sagen, dass nicht alle Gabeln auf dieser Seite sind, es gibt doppelt so viele. Ich habe das Wichtigste und Interessanteste ausgewählt, um das Bild nicht zu überladen. Die
postgresql Wiki Seite listet alle Gabeln auf. Wer kennt eine Open-Source-Datenbank mit so vielen Gabeln? Es gibt keine solchen Grundlagen.
Postgres unterscheidet sich von anderen Datenbanken nicht nur durch seine Funktionalität, sondern auch dadurch
Eine sehr interessante Community, die normalerweise Gabeln akzeptiert. In der Welt von Open Source ist es allgemein anerkannt: Ich habe eine Gabelung gemacht, weil ich beleidigt war - Sie haben mich nicht unterstützt, also habe ich beschlossen, meine eigene Entwicklung durchzuführen. In der postgriechischen Welt bedeutet das Erscheinen einer Gabel: Einige Leute oder Unternehmen haben beschlossen, einen Prototyp herzustellen und die von ihnen erfundene Funktionalität zu überprüfen, um zu experimentieren. Und wenn Sie Glück haben, schaffen Sie eine kommerzielle Basis, die an Kunden verkauft werden kann, bieten Sie ihnen Service und so weiter. Gleichzeitig geben die Entwickler all dieser Gabeln in der Regel ihre Erfolge und Patches an die Community zurück. Das Produkt unseres Unternehmens ist ebenfalls eine Gabel, und es ist klar, dass wir eine Reihe von Patches an die Community zurückgegeben haben. In der neuesten 11. Version haben wir mehr als 100 Patches an die Community zurückgegeben. Wenn Sie sich ihre Versionshinweise ansehen, gibt es 25 Namen unserer Mitarbeiter. Dies ist normales Community-Verhalten. Wir verwenden die Community-Version und stellen unsere Gabel her, um unsere Ideen zu testen oder den Kunden Funktionen zu bieten, bevor die Community für ihre Annahme reift. Gabeln in der Postgres-Community sind herzlich willkommen.
Die berühmte
Vertica stammt aus dem
C-Store - ebenfalls von Postgres gewachsen. Einige Leute behaupten, Vertica habe überhaupt keinen Postgres-Quellcode gehabt, sondern nur das Postgres-Protokoll unterstützt. Trotzdem ist es üblich, es als postgriechische Gabeln zu klassifizieren.
Greenplum . Jetzt können Sie es herunterladen und als Cluster verwenden. Es stammt von
Bizgres , einer massiv parallelen Datenbank. Dann wurde es von Greenplum gekauft, wurde und blieb lange Zeit kommerziell. Aber Sie sehen, dass sie um 2015 herum erkannt haben, dass sich die Welt verändert hat: Die Welt bewegt sich in Richtung offener Protokolle, offener Gemeinschaften, offener Datenbanken. Und sie öffneten die Greenplum-Codes. Jetzt holen sie Postgres aktiv ein, weil sie natürlich sehr zurückgeblieben sind. Sie haben sich bei 8,2 bewegt und jetzt sagen sie, dass sie 9,6 eingeholt haben.
Wir alle lieben und mögen
Amazon nicht . Sie wissen, wie es dazu kam. Es passierte vor meinen Augen. Es gab eine Firma, es gab
ParAccel mit Vektorverarbeitung, ebenfalls auf Postgres - einem offenen Community-Produkt. Im Jahr 2012 kaufte der listige Amazon den Quellcode und gab buchstäblich sechs Monate später bekannt, dass wir jetzt
RDS in Amazon haben. Wir fragten sie dann, sie zögerten lange, aber dann stellte sich heraus, dass es Postgres war. RDS lebt immer noch und dies ist einer der beliebtesten Dienste von Amazon. Dort drehen sich etwa 7.000 Basen. Aber sie haben sich nicht beruhigt, und 2010 erschien Amazon Aurora - Postgres 10 mit einer umgeschriebenen Geschichte, die direkt in die Infrastruktur von Amazon in ihrem verteilten Speicher eingenäht ist.
Schauen Sie sich jetzt
Teradata an . Ein großes, gutes altes Analyseunternehmen,
OLAP . Nach dem G8 [PostgreSQL 8.0] entstanden
Aster Data .
Hadoop : Wir haben Postgres auf Hadoop -
HadoopDB . Nach einer Weile wurde es eine geschlossene
Hadapt- Basis im Besitz von
Teradata . Wenn Sie Hadapt sehen, wissen Sie, was Postgres darin ist.
Ein sehr interessantes Schicksal mit
Citus . Jeder weiß, dass dies Postgres ist, das für Online-Analysen verteilt wird. Transaktionen werden nicht unterstützt.
Citus Data war ein Startup und Citus war Closed Source, eine separate Datenbank. Nach einiger Zeit wurde den Menschen klar, dass es besser ist, mit der Gemeinschaft zu leben und sich zu öffnen. Und sie haben viel getan, um nur eine Erweiterung von Postgres zu werden. Außerdem begannen sie bereits mit der Bereitstellung ihrer Cloud-Dienste. Sie alle wissen bereits:
MS Citus wurde hier geschrieben, weil
Microsoft sie buchstäblich vor zwei Wochen gekauft hat. Wahrscheinlich spielt Microsoft diese Spiele auch, um Postgres auf
Azure zu unterstützen. Auf Azure wird Postgres ausgeführt, und das Citus-Entwicklungsteam hat sich den MS-Entwicklern angeschlossen.
Im Allgemeinen sind in letzter Zeit die Prozesse zum Kauf von Post-Gres-Unternehmen intensiv verlaufen. Kurz nachdem Microsoft Citus gekauft hatte, kaufte ein anderes Postgres-Unternehmen,
glaubwürdig ,
OmniTI , um seine
Marktpräsenz zu stärken. Dies sind zwei bekannte, solide Unternehmen. Und Amazon hat
OpenSCG gekauft. Die Welt der Postgres verändert sich jetzt und ich werde Ihnen zeigen, warum das Interesse an Postgres so groß ist.
Die
gefeierte TimescaleDB war ebenfalls eine separate Datenbank, ist aber jetzt eine Erweiterung: Sie nehmen Postgres und installieren timescaledb als Erweiterung und erhalten eine Datenbank, die alle Arten von spezialisierten Datenbanken zerstört.
Es gibt auch Postgres XL, es gibt Cluster, die sich entwickeln.
Hier habe ich 2015 unsere Gabel gesetzt:
Postgres Pro . Wir haben
Postgres Pro Enterprise , es gibt eine zertifizierte Version, wir unterstützen
1C sofort und wir werden von
1C anerkannt. Wenn jemand Postgres Pro Enterprise ausprobieren möchte, können Sie das Distributionskit kostenlos mitnehmen. Wenn Sie es für die Arbeit benötigen, können Sie es kaufen.
Wir haben
Credereum erstellt , eine Prototypdatenbank mit Blockchain-Unterstützung. Jetzt warten wir darauf, dass die Leute reifen, um es zu benutzen.
Sehen Sie, wie groß und interessant das Bild ist. Ich spreche nicht einmal über
Yahoo! Everest mit Spaltenspeicher, mit Petabyte an Daten in Yahoo! - Es war das 2008. Jahr. Sie haben sogar unsere Konferenz in Kanada gesponsert, sind dorthin gekommen, irgendwo habe ich sogar ein Hemd von dort :)
Es gibt auch
PipelineDB . Es begann auch als Closed-Source-Datenbank, aber jetzt ist es auch nur eine Erweiterung. Wir sehen, dass Citus, TimescaleDB und PipelineDB wie separate Datenbanken sind, aber gleichzeitig als Erweiterungen existieren, dh Sie nehmen die Standard-Postgres und kompilieren die Erweiterung. PipelineDB ist eine Fortsetzung der Idee von Stream-Datenbanken. Möchten Sie mit Streams arbeiten?
Nehmen Sie Postgres, nehmen Sie PipelineDB und Sie können arbeiten.Darüber hinaus gibt es Erweiterungen, mit denen Sie mit der GPU arbeiten können . Sehen Sie die Überschrift? Ich habe gezeigt, dass es ein Ökosystem gibt, das eine große Anzahl verschiedener Arten von Daten und Lasten abdeckt. Daher sagen wir, dass Postgres eine universelle Datenbank ist.Lieblingsbasis
 Die nächste Folie hat große Namen. Alle berühmtesten Wolken der Welt unterstützen Postgres. In Russland wird Postgres von großen staatlichen Unternehmen unterstützt. Sie nutzen es und wir dienen ihnen als unsere Kunden.
Die nächste Folie hat große Namen. Alle berühmtesten Wolken der Welt unterstützen Postgres. In Russland wird Postgres von großen staatlichen Unternehmen unterstützt. Sie nutzen es und wir dienen ihnen als unsere Kunden. Es gibt bereits viele Erweiterungen und viele Anwendungen, sodass Postgres die Datenbank ist, von der aus das Projekt startet. Ich sage immer zu Startups: Leute, ihr müsst keine NoSQL- Datenbank nehmen. Ich verstehe, dass Sie wirklich wollen, aber beginnen Sie mit Postgres. Wenn Sie nicht genug haben, können Sie einen Dienst jederzeit aushängen und an eine spezialisierte Datenbank weitergeben. Neben der Universalität hat Postgres noch einen weiteren Vorteil: eine sehr liberale BSD-Lizenz, mit der Sie alles mit Ihrer Datenbank tun können.Auf alles, was Sie auf dieser Folie sehen, kann zugegriffen werden, da Postgres eine erweiterbare Datenbank ist und diese Erweiterbarkeit sofort in die Datenbankarchitektur eingebettet ist. Als Michael Stonebreaker in seinem ersten Artikel über ihn über Postgres schrieb (er wurde 1984 von ihm geschrieben, hier zitiere ich einen Artikel aus dem Jahr 1987), sprach er bereits über Erweiterbarkeit als wichtigste Komponente der Datenbankfunktionalität. Und dies wurde, wie sie sagen, bereits mit der Zeit getestet. Sie können Ihre eigenen Funktionen, Datentypen, Operatoren und Indexzugriffe (dh optimierte Zugriffsmethoden) hinzufügen und Ihre Prozeduren in einer sehr großen Anzahl von Sprachen schreiben. Wir haben einen Foreign Data Wrapper ( FDW ), dh Schnittstellen für die Arbeit mit verschiedenen Repositorys, Dateien, die Sie mit Oracle , MySQL verbinden könnenund andere Basen.Ich möchte ein Beispiel aus meiner persönlichen Erfahrung geben. Ich habe mit Postgres gearbeitet und als in Postgres etwas fehlte, haben meine Kollegen und ich diese Funktionalität einfach hinzugefügt. Wir mussten zum Beispiel mit der russischen Sprache arbeiten und haben ein 8-Bit-Gebietsschema erstellt. Es war ein Rambler- Projekt . Übrigens war er dann in den Top 5. Wandererwar das erste große globale Projekt, das auf Postgres gestartet wurde. Arrays in Postgres waren von Anfang an, aber sie waren so, dass nichts mit ihnen gemacht werden konnte. Es war nur eine Textzeile, in der die Arrays gespeichert wurden. Wir haben Operatoren hinzugefügt, Indizes erstellt, und jetzt sind Arrays ein wesentlicher Bestandteil der Postgres-Funktionalität, und viele von Ihnen verwenden sie, ohne sich Gedanken darüber zu machen, wie schnell sie funktionieren - und das ist in Ordnung. Sie pflegten zu sagen, dass Arrays kein traditionelles relationales Modell mehr sind, sondern nicht den klassischen Normalformen entsprechen. Jetzt sind die Leute bereits daran gewöhnt, Arrays zu verwenden.
Es gibt bereits viele Erweiterungen und viele Anwendungen, sodass Postgres die Datenbank ist, von der aus das Projekt startet. Ich sage immer zu Startups: Leute, ihr müsst keine NoSQL- Datenbank nehmen. Ich verstehe, dass Sie wirklich wollen, aber beginnen Sie mit Postgres. Wenn Sie nicht genug haben, können Sie einen Dienst jederzeit aushängen und an eine spezialisierte Datenbank weitergeben. Neben der Universalität hat Postgres noch einen weiteren Vorteil: eine sehr liberale BSD-Lizenz, mit der Sie alles mit Ihrer Datenbank tun können.Auf alles, was Sie auf dieser Folie sehen, kann zugegriffen werden, da Postgres eine erweiterbare Datenbank ist und diese Erweiterbarkeit sofort in die Datenbankarchitektur eingebettet ist. Als Michael Stonebreaker in seinem ersten Artikel über ihn über Postgres schrieb (er wurde 1984 von ihm geschrieben, hier zitiere ich einen Artikel aus dem Jahr 1987), sprach er bereits über Erweiterbarkeit als wichtigste Komponente der Datenbankfunktionalität. Und dies wurde, wie sie sagen, bereits mit der Zeit getestet. Sie können Ihre eigenen Funktionen, Datentypen, Operatoren und Indexzugriffe (dh optimierte Zugriffsmethoden) hinzufügen und Ihre Prozeduren in einer sehr großen Anzahl von Sprachen schreiben. Wir haben einen Foreign Data Wrapper ( FDW ), dh Schnittstellen für die Arbeit mit verschiedenen Repositorys, Dateien, die Sie mit Oracle , MySQL verbinden könnenund andere Basen.Ich möchte ein Beispiel aus meiner persönlichen Erfahrung geben. Ich habe mit Postgres gearbeitet und als in Postgres etwas fehlte, haben meine Kollegen und ich diese Funktionalität einfach hinzugefügt. Wir mussten zum Beispiel mit der russischen Sprache arbeiten und haben ein 8-Bit-Gebietsschema erstellt. Es war ein Rambler- Projekt . Übrigens war er dann in den Top 5. Wandererwar das erste große globale Projekt, das auf Postgres gestartet wurde. Arrays in Postgres waren von Anfang an, aber sie waren so, dass nichts mit ihnen gemacht werden konnte. Es war nur eine Textzeile, in der die Arrays gespeichert wurden. Wir haben Operatoren hinzugefügt, Indizes erstellt, und jetzt sind Arrays ein wesentlicher Bestandteil der Postgres-Funktionalität, und viele von Ihnen verwenden sie, ohne sich Gedanken darüber zu machen, wie schnell sie funktionieren - und das ist in Ordnung. Sie pflegten zu sagen, dass Arrays kein traditionelles relationales Modell mehr sind, sondern nicht den klassischen Normalformen entsprechen. Jetzt sind die Leute bereits daran gewöhnt, Arrays zu verwenden. Wenn wir eine Volltextsuche brauchten, haben wir es getan. Wenn wir Daten unterschiedlicher Art speichern mussten, haben wir die hstore-Erweiterung erstellt, und viele Leute haben damit begonnen: Sie ermöglichte die Erstellung flexibler Datenbankschemata, damit diese immer schneller werden konnten. Wir haben einen GIN- Index erstellt, damit die Volltextsuche schnell funktioniert. Wir haben Trigramme erstellt ( pg_trgm ). NoSQL gemacht. Und das alles ist in meiner Erinnerung, all meine eigenen Bedürfnisse.
Wenn wir eine Volltextsuche brauchten, haben wir es getan. Wenn wir Daten unterschiedlicher Art speichern mussten, haben wir die hstore-Erweiterung erstellt, und viele Leute haben damit begonnen: Sie ermöglichte die Erstellung flexibler Datenbankschemata, damit diese immer schneller werden konnten. Wir haben einen GIN- Index erstellt, damit die Volltextsuche schnell funktioniert. Wir haben Trigramme erstellt ( pg_trgm ). NoSQL gemacht. Und das alles ist in meiner Erinnerung, all meine eigenen Bedürfnisse. Die Erweiterbarkeit macht Postgres zu einer einzigartigen Datenbank, einer universellen Datenbank, mit der Sie arbeiten können und keine Angst haben, dass Sie ohne Unterstützung bleiben. Schauen Sie, wie viele Leute wir hier haben - das ist schon ein Markt! Trotz der Tatsache, dass jetzt Hype-Graph-Datenbanken, Dokumentendatenbanken, Zeitreihen usw. aussehen: Die meisten verwenden immer noch relationale Datenbanken. Sie dominieren, dies sind 75% des Datenbankmarktes, und der Rest sind exotische Datenbanken, eine Kleinigkeit im Vergleich zu relationalen.
Die Erweiterbarkeit macht Postgres zu einer einzigartigen Datenbank, einer universellen Datenbank, mit der Sie arbeiten können und keine Angst haben, dass Sie ohne Unterstützung bleiben. Schauen Sie, wie viele Leute wir hier haben - das ist schon ein Markt! Trotz der Tatsache, dass jetzt Hype-Graph-Datenbanken, Dokumentendatenbanken, Zeitreihen usw. aussehen: Die meisten verwenden immer noch relationale Datenbanken. Sie dominieren, dies sind 75% des Datenbankmarktes, und der Rest sind exotische Datenbanken, eine Kleinigkeit im Vergleich zu relationalen. Wenn man sich das Verhältnis von Open - Source - Datenbanken zu kommerziellen suchen, dann,nach DB-EnginesWir werden sehen, dass die Anzahl der Open-Source-Datenbanken fast der Anzahl der kommerziellen Datenbanken entspricht. Und wir sehen, dass Open Source-Datenbanken (blaue Linie) wachsen und kommerzielle (rote) fallen. Dies ist die Richtung der Entwicklung der gesamten IT-Community, die Richtung der Offenheit. Jetzt ist es natürlich unanständig, sich auf Gartner zu beziehen , aber ich sage es trotzdem: Sie sagen voraus, dass bis 2022 70% offene Datenbanken verwenden und bis zu 50% der vorhandenen Systeme auf Open Source migrieren werden.Schauen Sie sich dieses Pomosomer an: Wir sehen, dass Postgres die Datenbank von 2018 heißt. Im vergangenen Jahr war sie auch die erste unabhängige Expertenschätzung von DB-Engines. Das Ranking zeigt, dass Postgres den anderen wirklich voraus ist. Es ist in absoluten Zahlen auf dem 4. Platz, aber schauen Sie, wie es wächst. Klar, gut. Auf der Folie ist dies eine blaue Linie. Der Rest - MySQL, Oracle, MS SQL - gleicht sich entweder auf seiner Ebene aus oder beginnt sich zu verbiegen.
Wenn man sich das Verhältnis von Open - Source - Datenbanken zu kommerziellen suchen, dann,nach DB-EnginesWir werden sehen, dass die Anzahl der Open-Source-Datenbanken fast der Anzahl der kommerziellen Datenbanken entspricht. Und wir sehen, dass Open Source-Datenbanken (blaue Linie) wachsen und kommerzielle (rote) fallen. Dies ist die Richtung der Entwicklung der gesamten IT-Community, die Richtung der Offenheit. Jetzt ist es natürlich unanständig, sich auf Gartner zu beziehen , aber ich sage es trotzdem: Sie sagen voraus, dass bis 2022 70% offene Datenbanken verwenden und bis zu 50% der vorhandenen Systeme auf Open Source migrieren werden.Schauen Sie sich dieses Pomosomer an: Wir sehen, dass Postgres die Datenbank von 2018 heißt. Im vergangenen Jahr war sie auch die erste unabhängige Expertenschätzung von DB-Engines. Das Ranking zeigt, dass Postgres den anderen wirklich voraus ist. Es ist in absoluten Zahlen auf dem 4. Platz, aber schauen Sie, wie es wächst. Klar, gut. Auf der Folie ist dies eine blaue Linie. Der Rest - MySQL, Oracle, MS SQL - gleicht sich entweder auf seiner Ebene aus oder beginnt sich zu verbiegen. Hacker-News - Sie alle haben es wahrscheinlich gelesen oder Y Combinator- Dort werden regelmäßig Umfragen durchgeführt, Unternehmen veröffentlichen dort ihre offenen Stellen und führen seit einiger Zeit Statistiken durch. Sie sehen, dass Postgres ab 2014 allen voraus ist. Es war das erste MySQL, aber Postgres ist langsam gewachsen, und jetzt setzt es sich in der gesamten Hacker-Community (im guten Sinne des Wortes) durch und wächst weiter.
Hacker-News - Sie alle haben es wahrscheinlich gelesen oder Y Combinator- Dort werden regelmäßig Umfragen durchgeführt, Unternehmen veröffentlichen dort ihre offenen Stellen und führen seit einiger Zeit Statistiken durch. Sie sehen, dass Postgres ab 2014 allen voraus ist. Es war das erste MySQL, aber Postgres ist langsam gewachsen, und jetzt setzt es sich in der gesamten Hacker-Community (im guten Sinne des Wortes) durch und wächst weiter. Der Stack - Überlauf auch jedes Jahr Umfragen durchzuführen. Bei den meisten Nutzern liegt unser Postgres an einem guten dritten Platz. Von den meisten geliebt - am zweiten. Dies ist eine Lieblingsdatenbank. Redis ist keine relationale Datenbank, aber relationale Postgres ist ein Favorit. Ich habe hier nicht das am meisten gefürchtete Bild gegeben- die schrecklichste Datenbank, aber Sie raten wahrscheinlich, wer zuerst kommt. "Base X", wie sie es in Russland gerne nennen.
Der Stack - Überlauf auch jedes Jahr Umfragen durchzuführen. Bei den meisten Nutzern liegt unser Postgres an einem guten dritten Platz. Von den meisten geliebt - am zweiten. Dies ist eine Lieblingsdatenbank. Redis ist keine relationale Datenbank, aber relationale Postgres ist ein Favorit. Ich habe hier nicht das am meisten gefürchtete Bild gegeben- die schrecklichste Datenbank, aber Sie raten wahrscheinlich, wer zuerst kommt. "Base X", wie sie es in Russland gerne nennen. In Russland gibt es eine Überprüfung, eine Umfrage bei uns allen auf der angesehenen HighLoad ++ - Konferenz . Es wurde nicht von uns durchgeführt, es wurde von Oleg Bunin gemacht . Es stellte sich heraus: in Russland Postgres-Datenbank Nr. 1.
In Russland gibt es eine Überprüfung, eine Umfrage bei uns allen auf der angesehenen HighLoad ++ - Konferenz . Es wurde nicht von uns durchgeführt, es wurde von Oleg Bunin gemacht . Es stellte sich heraus: in Russland Postgres-Datenbank Nr. 1. Wir bitten HH.ru zum zweiten Mal , Postgres-Stellenstatistiken mit uns zu teilen. Vor 9 Jahren war Postgres 10 Mal hinter Oracle, alle riefen: Gib uns Orakelisten. Und wir sehen, dass wir letztes Jahr aufgeholt haben, und dann gab es 2018 Wachstum. Und wenn Sie sich Sorgen machen, wo Sie einen Job finden können, sehen Sie: 2.000 Stellen bei HH.ru sind Postgres. Mach dir keine Sorgen, genug Arbeit.
Wir bitten HH.ru zum zweiten Mal , Postgres-Stellenstatistiken mit uns zu teilen. Vor 9 Jahren war Postgres 10 Mal hinter Oracle, alle riefen: Gib uns Orakelisten. Und wir sehen, dass wir letztes Jahr aufgeholt haben, und dann gab es 2018 Wachstum. Und wenn Sie sich Sorgen machen, wo Sie einen Job finden können, sehen Sie: 2.000 Stellen bei HH.ru sind Postgres. Mach dir keine Sorgen, genug Arbeit. Um die Anzeige zu vereinfachen, habe ich ein Bild aufgenommen, auf dem Postgres-Stellenangebote in Bezug auf Oracle-Stellenangebote angezeigt wurden. Es gab weniger, ab 2018 sind sie bereits auf Augenhöhe, und jetzt ist Postgres schon ein bisschen mehr geworden. Bisher ist es ein wenig bedrückend, dass auch die absolute Zahl der Oracle-Stellenangebote wächst, was im Prinzip nicht sein sollte. Aber wie sie sagen, sitzen wir in der Nähe des Flussufers und beobachten: Wann wird die Leiche des Feindes vorbeischweben? Wir machen nur unseren Job.
Um die Anzeige zu vereinfachen, habe ich ein Bild aufgenommen, auf dem Postgres-Stellenangebote in Bezug auf Oracle-Stellenangebote angezeigt wurden. Es gab weniger, ab 2018 sind sie bereits auf Augenhöhe, und jetzt ist Postgres schon ein bisschen mehr geworden. Bisher ist es ein wenig bedrückend, dass auch die absolute Zahl der Oracle-Stellenangebote wächst, was im Prinzip nicht sein sollte. Aber wie sie sagen, sitzen wir in der Nähe des Flussufers und beobachten: Wann wird die Leiche des Feindes vorbeischweben? Wir machen nur unseren Job.
Russische Postgres-Gemeinschaft
Dies ist die am besten organisierte Gemeinschaft in Russland. Ich habe solche Leute noch nie getroffen. Viele Ressourcen, Chats, in denen wir alle geschäftlich kommunizieren. Wir halten Konferenzen ab - zwei große Konferenzen: In St. Petersburg und Moskau nehmen wir an allen wichtigen internationalen Konferenzen teil und führen Kurse durch. In der Tat sind dies Gemeinschaftskurse. Sie wurden von unserer Firma erstellt, sind aber für jeden von Ihnen frei verfügbar. Besuchen Sie unseren Kanal auf Youtube oder besuchen Sie unsere Website im Bereich "Bildung". Es gibt DBA1- , DBA2- , DBA3- Kurse und Entwicklungskurse zum kostenlosen Download .Und jetzt starten wir die Zertifizierung - das ist es, was Unternehmen verlangen, sie wollen zertifizierte Spezialisten haben. Und der Arbeitgeber wird wissen: Sie sind zertifizierter Spezialist.
In der Tat sind dies Gemeinschaftskurse. Sie wurden von unserer Firma erstellt, sind aber für jeden von Ihnen frei verfügbar. Besuchen Sie unseren Kanal auf Youtube oder besuchen Sie unsere Website im Bereich "Bildung". Es gibt DBA1- , DBA2- , DBA3- Kurse und Entwicklungskurse zum kostenlosen Download .Und jetzt starten wir die Zertifizierung - das ist es, was Unternehmen verlangen, sie wollen zertifizierte Spezialisten haben. Und der Arbeitgeber wird wissen: Sie sind zertifizierter Spezialist. Sie fragen oft: Wie viel russische Postgres? Die Frage ist etwas falsch: Postgres ist international. Aber ich werde ein wenig über die russische Flagge sagen. Sie sehen auf der Folie, was Vadim Mikheev getan hat . Diejenigen, die Postgres kennen, verstehen, dass MVCC , WAL , VACUUM usw. für diese Basis bedeuten . Das ist der ganze russische Beitrag. Jetzt gibt es drei führende Entwickler von Postgres, von denen zwei Committer sind. Auf der Folie sehen Sie, dass ziemlich viel getan wurde. Wenn Sie sich die wichtigsten Funktionen aus den Versionshinweisen ansehen, werden Sie unseren Beitrag sehen. Der russische Beitrag ist substanziell genug. Wir haben von Anfang an gearbeitet und arbeiten weiterhin mit der Community zusammen - bereits auf Kampagnenebene.
Sie fragen oft: Wie viel russische Postgres? Die Frage ist etwas falsch: Postgres ist international. Aber ich werde ein wenig über die russische Flagge sagen. Sie sehen auf der Folie, was Vadim Mikheev getan hat . Diejenigen, die Postgres kennen, verstehen, dass MVCC , WAL , VACUUM usw. für diese Basis bedeuten . Das ist der ganze russische Beitrag. Jetzt gibt es drei führende Entwickler von Postgres, von denen zwei Committer sind. Auf der Folie sehen Sie, dass ziemlich viel getan wurde. Wenn Sie sich die wichtigsten Funktionen aus den Versionshinweisen ansehen, werden Sie unseren Beitrag sehen. Der russische Beitrag ist substanziell genug. Wir haben von Anfang an gearbeitet und arbeiten weiterhin mit der Community zusammen - bereits auf Kampagnenebene. Und der Beitrag des Unternehmens sind Bücher. Wir haben 2 Postgres Universitätskurse. Sie können in den Laden gehen und diese Bücher kaufen, Sie können in diesen Kursen unterrichten, Prüfungen ablegen und so weiter. Wir haben Bücher für Anfänger, die verteilt werden, auch hier. Sehr nützliches gutes Buch. Wir haben es sogar ins Englische übersetzt.
Und der Beitrag des Unternehmens sind Bücher. Wir haben 2 Postgres Universitätskurse. Sie können in den Laden gehen und diese Bücher kaufen, Sie können in diesen Kursen unterrichten, Prüfungen ablegen und so weiter. Wir haben Bücher für Anfänger, die verteilt werden, auch hier. Sehr nützliches gutes Buch. Wir haben es sogar ins Englische übersetzt.Professionelle Postgres
Gehen wir weiter zum Hauptthema. Academic Postgres wurde zu Beginn für mehrere Dutzend Benutzer entwickelt. Die Postgres95-Community hatte weniger als 400 Menschen. Die Community bestand hauptsächlich aus Entwicklern und wenigen weiteren Benutzern. Gleichzeitig - ein interessantes Detail - waren die Entwickler hauptsächlich Kunden und Auftragnehmer. Als ich es zum Beispiel brauchte, entwickelte ich mich für mich selbst und teilte es gleichzeitig mit allen. Das heißt, die Community entwickelte sich für die Community.
Ab dem Jahr 2000, etwas früher,
tauchten die ersten Post-Grace-Unternehmen auf:
GreatBridge ,
2ndQuadrant ,
EDB . Sie haben bereits Vollzeitentwickler eingestellt, die für die Community gearbeitet haben. Die ersten Unternehmensgabeln und die ersten Unternehmensanpassungsprogramme wurden angezeigt. Dies führte dazu, dass bis 2015 die Hauptnummer - und fast alle führenden Entwickler - bereits in einigen Unternehmen organisiert waren. 2015 wurde unser Unternehmen gegründet: Wir waren die letzten freiberuflichen Entwickler. Jetzt gibt es praktisch keine solchen Leute. Die Postgres-Community hat sich verändert, sie ist zu einem Unternehmen geworden, und jetzt treiben diese Unternehmen die Entwicklung voran. Das ist gut so, weil diese Unternehmen das tun, was das Unternehmen braucht. Die Community ist in guter Weise eine Bremse: Sie testet Funktionen, verurteilt oder akzeptiert neue Funktionen, sie vereint uns alle. Und Postgres ist
unternehmensbereit geworden, große Unternehmen nutzen es gerne, es ist professionell geworden.

Diese Folie handelt von der Zukunft, wie ich sie sehe. Mit dem Aufkommen des
steckbaren Speichers werden neue Speicher angezeigt:
Nur Anhängen, Nur Lesen ,
Spaltenspeicher - was immer Sie wollen (zum Beispiel träume ich von Parkett). Vektoroperationen werden unterstützt. Heute wird es übrigens einen Bericht darüber geben. Blockchain wird unterstützt. Daran führt kein Weg vorbei, da wir uns der digitalen Wirtschaft und den papierlosen Technologien zuwenden. Sie müssen elektronische Signaturen verwenden und in der Lage sein, Ihre Datenbank zu authentifizieren, sicherzustellen, dass niemand etwas geändert hat, und die Blockchain ist dafür sehr gut geeignet.


Weiter:
adaptive Postgres . Dies ist ein wenig trauriges Thema für Sie, aber es ist noch ziemlich weit von Ihnen entfernt. Tatsache ist, dass DBA im Allgemeinen eine teure Ressource ist und Datenbanken sie bald nicht mehr benötigen werden. Die Basen sind intelligent genug und konfigurieren und passen sich selbst an. Aber es wird wahrscheinlich in weiteren zehn Jahren sein. Wir haben noch viel Zeit.

Und es ist klar, dass es in Postgres native Unterstützung für Clouds und Cloud-Speicher geben wird - ohne diese können wir einfach nicht überleben. Und hier ist natürlich die letzte Folie:
ALLES, WAS SIE BRAUCHEN, IST POSTGRES!

Vielen Dank für Ihre Aufmerksamkeit.