Seit 1999 nutzt unsere Bank das integrierte BISKVIT-Bankensystem auf der Progress OpenEdge-Plattform, um das Backoffice zu bedienen, das weltweit, auch im Finanzsektor, weit verbreitet ist. Mit der Leistung dieses DBMS können Sie bis zu eine Million oder mehr Datensätze pro Sekunde in einer Datenbank (DB) lesen. Unser Progress OpenEdge bedient rund 1,5 Millionen Einlagen von Privatpersonen und rund 22,2 Millionen Verträge für aktive Produkte (Autokredite und Hypotheken) und ist auch für alle Abrechnungen mit der Aufsichtsbehörde (CB) und SWIFT verantwortlich.

Mit Progress OpenEdge sehen wir uns mit der Tatsache konfrontiert, dass wir uns mit Oracle DBMS anfreunden müssen. Ursprünglich war dieses Bundle der „Engpass“ unserer Infrastruktur - bis wir Pro2 CDC installiert und konfiguriert haben - ein Progress-Produkt, mit dem Sie Daten von Progress DBMS direkt online an Oracle DBMS senden können. In diesem Beitrag erklären wir Ihnen ausführlich, wie Sie mit OpenEdge und Oracle effektiv Freunde finden können.
So war es: Hochladen von Daten auf QCD durch Dateifreigabe
Zunächst einige Fakten zu unserer Infrastruktur. Die Anzahl der aktiven Benutzer der Datenbank beträgt ungefähr 15.000. Das Volumen aller produktiven Datenbanken, einschließlich Replikat und Standby, beträgt 600 TB, die größte Datenbank 16,5 TB. Gleichzeitig werden die Datenbanken ständig aufgefüllt: Allein im letzten Jahr wurden rund 120 TB produktive Daten hinzugefügt. Das System bietet 150 Front-End-Server auf der x86-Plattform. Datenbanken werden auf 21 IBM Plattformservern gehostet.
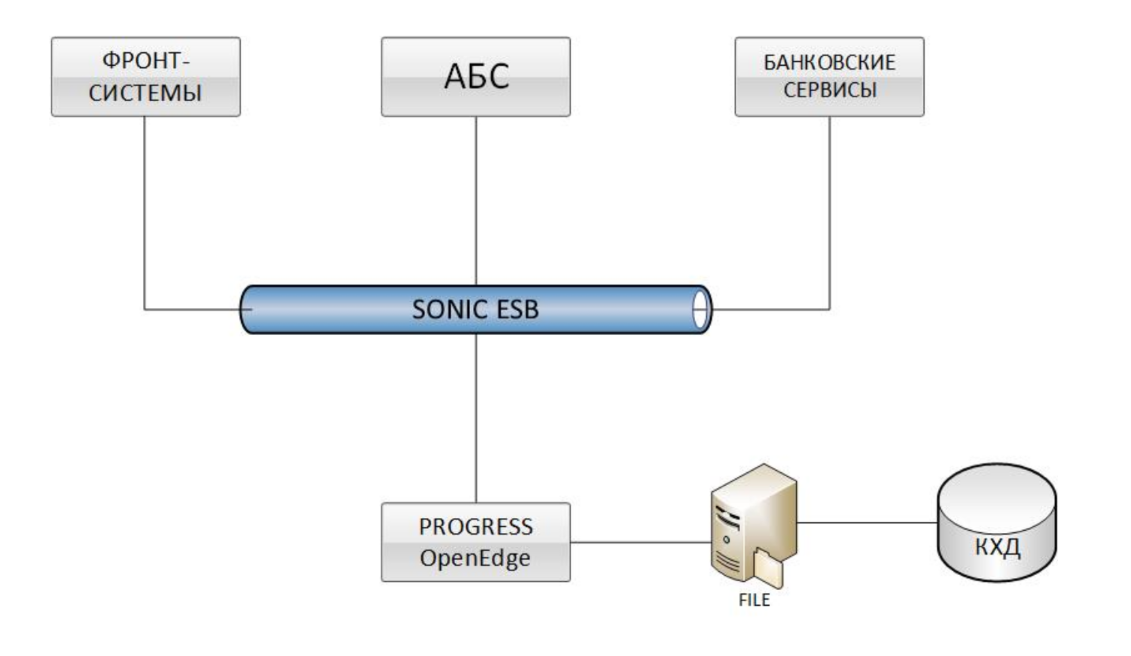
Frontsysteme, verschiedene ABS- und Bankdienstleistungen sind über den Sonic ESB-Bus in OpenEdge Progress (IBS BISQUIT) integriert. Daten werden durch Dateiaustausch auf QCD hochgeladen. Eine solche Lösung hatte bis zu einem bestimmten Zeitpunkt sofort zwei große Probleme: die geringe Leistung beim Hochladen von Informationen in das Corporate Data Warehouse (QCD) und die lange Zeit, die zum Abgleichen von Daten (Abgleich) mit anderen Systemen benötigt wird.
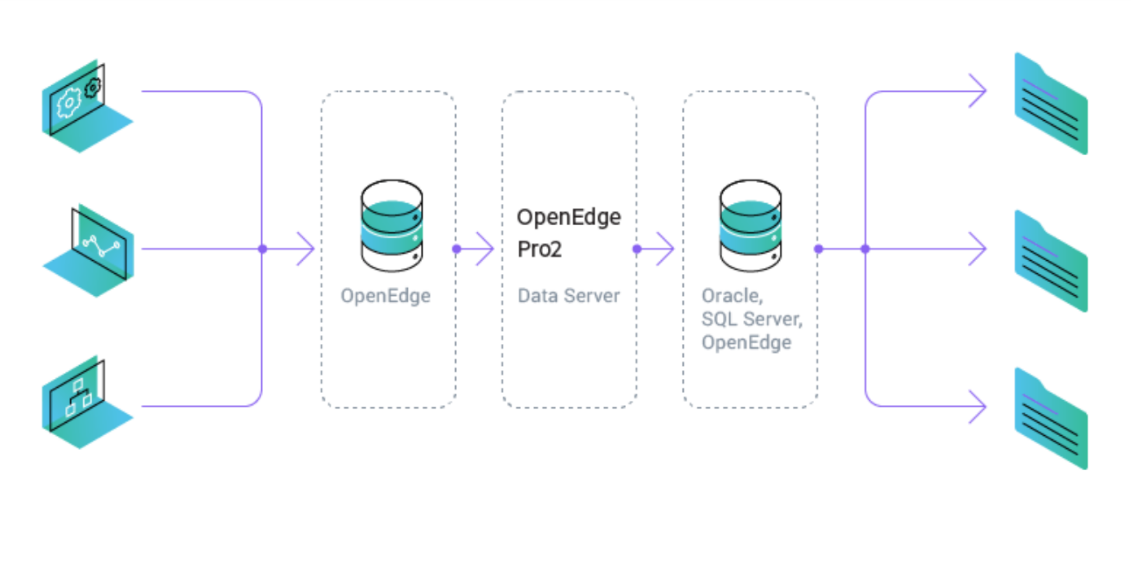
Aus diesem Grund haben wir nach einem Tool gesucht, das diese Prozesse beschleunigen kann. Die Lösung für beide Probleme war genau das neue Progress OpenEdge-Produkt - Pro2 CDC (Change Data Capture). Also fangen wir an.
Installieren Sie Progress OpenEdge und Pro2Oracle
Um Pro2 Oracle auf einem Windows-Computer eines Administrators auszuführen, installieren Sie einfach die Progress OpenEdge Developer Kit Classroom Edition, die kostenlos
heruntergeladen werden kann. OpenEdge-Standardinstallationsverzeichnisse:
DLC: C: \ Progress \ OpenEdge
WRK: C: \ OpenEdge \ WRKETL-Prozesse erfordern Progress OpenEdge-Lizenzen der Version 11.7+, nämlich OE DataServer für Oracle und 4GL Development System. Diese Lizenzen sind in Pro2 enthalten. Für den vollständigen Betrieb von DataServer for Oracle mit einer entfernten Oracle-Datenbank ist Full Oracle Client installiert.
Auf dem Oracle-Server müssen Sie die Version von Oracle Database 12+ installieren, eine leere Datenbank erstellen und den Benutzer hinzufügen (nennen wir es
cdc ).
Laden Sie zum Installieren von Pro2Oracle das neueste Distributionspaket aus dem
Progress Software- Downloadcenter herunter. Entpacken Sie das Archiv in das Verzeichnis
C: \ Pro2 (für die Konfiguration von Pro2 unter Unix wird dasselbe Distributionskit verwendet, und es werden dieselben Konfigurationsprinzipien angewendet).
Erstellen einer cdc-Replikationsdatenbank
Die
cdc (repl) -Replikationsdatenbank wird von Pro2 zum Speichern von Konfigurationsinformationen verwendet, einschließlich der Replikationszuordnung, der Namen der replizierten Datenbanken und ihrer Tabellen. Es enthält auch eine Replikationswarteschlange, die aus Hinweisen besteht, dass sich die Tabellenzeile in der Quellendatenbank geändert hat. Die Daten aus der Replikationswarteschlange werden von ETL-Prozessen verwendet, um die Zeilen zu identifizieren, die aus der Quellendatenbank nach Oracle kopiert werden müssen.
Erstellen Sie eine separate CDC-Datenbank.
Vorgehensweise zum Erstellen einer Datenbank- Erstellen Sie auf dem Datenbankserver ein Verzeichnis für die CDC-Datenbank, z. B. auf der Datenbank / database / cdc / server.
- Erstellen Sie einen Dummy für die cdc-Basis: procopy $ DLC / empty cdc
- Aktivieren Sie die Unterstützung großer Dateien: proutil cdc -C EnableLargeFiles
- Wir bereiten das Skript zum Starten der CDC-Datenbank vor. Die Startparameter sollten den Startparametern der replizierten Datenbank ähnlich sein.
- Wir starten die CDC-Datenbank.
- Wir stellen eine Verbindung zur cdc-Datenbank her und laden das Pro2-Diagramm aus der cdc.df- Datei, die im Pro2-Paket enthalten ist.
- Erstellen Sie in der cdc-Datenbank die folgenden Benutzer:
pro2adm - zum Verbinden über das Pro2-Admin-Panel;
pro2etl - zum Verbinden von ETL-Prozessen (ReplBatch);
pro2cdc - zum Verbinden von CDC-Prozessen (CDCBatch); OpenEdge Change Data Capture aktivieren
Schalten wir nun den CDC-Mechanismus selbst ein, über den Daten in einen zusätzlichen Technologiebereich repliziert werden. In jeder Progress OpenEdge-Quellendatenbank müssen Sie separate Speicherbereiche hinzufügen, in die die Quelldaten dupliziert werden, und den Mechanismus selbst mit dem
Befehl proutil aktivieren.
Beispielverfahren für die Bisquit-Datenbank- Kopieren Sie die Datei cdcadd.st aus dem Verzeichnis C: \ Pro2 \ db in das Verzeichnis der Bisquit- Quellendatenbank.
- Wir beschreiben in cdcadd.st Extents mit festem Umfang für die Bereiche ReplCDCArea und ReplCDCArea_IDX . Sie können online neue Speicherbereiche hinzufügen: prostrct addonline bisquit cdcadd.st
- OpenEdge CDC aktivieren:
proutil bisquit -C enablecdc Bereich "ReplCDCArea" Indexbereich "ReplCDCArea_IDX"
- Die folgenden Benutzer müssen in der Quellendatenbank erstellt werden, um laufende Prozesse zu identifizieren:
a. pro2adm - zum Verbinden über das Pro2-Admin-Panel.
b. pro2etl - zum Verbinden von ETL-Prozessen (ReplBatch).
c. pro2cdc - zum Verbinden von CDC-Prozessen (CDCBatch).
Erstellen eines Schemahalters für DataServer für Oracle
Als Nächstes müssen wir den Datenbankschemahalter auf dem Server erstellen, auf dem die Daten vom Fortschritts-DBMS zum Oracle-DBMS repliziert werden. DataServer Schema Holder ist eine leere Progress OpenEdge-Datenbank ohne Benutzer- oder Anwendungsdaten, die eine Entsprechungskarte zwischen Quelltabellen und externen Oracle-Tabellen enthält.
Die Schema Holder-Datenbank für Progress OpenEdge DataServer für Oracle für Pro2 muss sich auf dem ETL-Prozessserver befinden und wird für jeden Zweig separat erstellt.
So erstellen Sie einen Schemahalter- Entpacken Sie die Pro2-Distribution in das Verzeichnis / pro2
- Erstellen Sie und gehen Sie zum Verzeichnis / pro2 / dbsh
- Erstellen Sie die Schema Holder-Datenbank mit dem Befehl procopy $ DLC / empty bisquitsh
- Wir konvertieren Bisquitsh in die erforderliche Codierung - zum Beispiel in UTF-8, wenn Oracle-Datenbanken in UTF-8 codiert sind: Proutil Bisquitsh -C Convchar konvertiert UTF-8
- Nachdem wir eine leere Bisquitsh- Datenbank erstellt haben, stellen wir im Einzelbenutzermodus eine Verbindung zu ihr her: Pro Bisquitsh
- Gehen Sie zum Datenwörterbuch : Tools -> Datenwörterbuch -> DataServer -> ORACLE-Dienstprogramme -> DataServer-Schema erstellen
- Starten Sie den Schema Holder
- Konfigurieren Sie den Oracle DataServer-Broker:
a. Starten Sie AdminServer.
proadsv -start
b. Start des Oracle DataServer-Brokers
oraman -name orabroker1 -start
Konfigurieren Sie das Admin-Panel und das Replikationsschema
Das Pro2-Administrationsfenster konfiguriert die Pro2-Einstellungen, einschließlich des Einrichtens des Replikationsschemas und des Generierens von ETL-Prozessprogrammen (Prozessorbibliothek), primären Synchronisationsprogrammen (Massenkopierprozessor), Replikationsauslösern und OpenEdge CDC-Richtlinien. Es gibt auch primäre Tools zum Überwachen und Verwalten von ETL- und CDC-Prozessen. Zunächst konfigurieren wir die Parameterdateien.
So richten Sie Parameterdateien ein- Wechseln Sie in das Verzeichnis C: \ Pro2 \ bprepl \ Scripts
- Öffnen Sie die Datei replProc.pf zur Bearbeitung
- Fügen Sie die Parameter für die Verbindung zur cdc-Replikationsdatenbank hinzu:
# Replikationsdatenbank
-db cdc -ld repl -H <Hostname der Hauptdatenbank> -S <Port des cdc-Datenbankbrokers>
-U pro2admin -P <Kennwort>
- Fügen Sie replProc.pf die Parameter für die Verbindung mit den Quelldatenbanken und dem Schema-Halter in Form von Parameterdateien hinzu . Der Name der Parameterdatei muss mit dem Namen der zu verbindenden Quelldatenbank übereinstimmen.
# Stellen Sie eine Verbindung zu allen replizierten Quell-BISQUITs her
-pf bprepl \ scripts \ bisquit.pf
- Fügen Sie die Parameter für die Verbindung zum Schemahalter in replProc.pf hinzu.
#Target Pro DB Schema Holder
-db bisquitsh -ld bisquitsh
-H <Hostname der ETL-Prozesse>
-S <Biskuitsh Broker Port>
-db bisquitsql
-ld bisquitsql
-dt ORACLE
-S 5162 -H <Hostname des Oracle-Brokers>
-DataService orabroker1
- Speichern Sie die Parameterdatei replProc.pf
- Als Nächstes müssen Sie die Parameterdateien für jede verbundene Quellendatenbank im Verzeichnis C: \ Pro2 \ bprepl \ Scripts: bisquit.pf erstellen und zum Bearbeiten öffnen . Jede pf-Datei enthält Parameter für die Verbindung mit der entsprechenden Datenbank, zum Beispiel:
-db bisquit -ld bisquit -H <Hostname> -S <Brokerport>
-U pro2admin -P <Kennwort>
Um Windows-Verknüpfungen zu konfigurieren,
wechseln Sie in das Verzeichnis C: \ Pro2 \ bprepl \ Scripts und bearbeiten Sie die Verknüpfung „Pro2 - Administration“. Öffnen Sie dazu die Eigenschaften der Verknüpfung und geben Sie in der Zeile
Start in das Installationsverzeichnis Pro2 an. Ein ähnlicher Vorgang muss für die Labels "Pro2 - Editor" und "RunBulkLoader" durchgeführt werden.
Konfigurieren der Pro2-Administration: Herunterladen der Primärkonfiguration
Wir starten die Konsole.
Gehen Sie zur "DB Map".

Um die Datenbanken in Pro2 - Administration zu verknüpfen, wechseln Sie zur Registerkarte
DB Map . Wir fügen die Zuordnung von Quelldatenbanken hinzu -
Schema Holder - Oracle .

Wechseln Sie zur Registerkarte
Zuordnung . In der Liste Quelldatenbank ist standardmäßig die erste verbundene Quellendatenbank ausgewählt. Rechts von der Liste sollte
Alle Datenbanken verbunden sein - die ausgewählten Datenbanken sind verbunden. Eine Liste der Fortschrittstabellen von Bisquit sollte unten links sichtbar sein. Auf der rechten Seite finden Sie eine Liste der Tabellen aus der Oracle-Datenbank.
Erstellen von SQL-Schemas und -Datenbanken in Oracle
Um eine Replikationszuordnung zu erstellen, müssen Sie zuerst das
SQL-Schema in Oracle generieren. Führen Sie in Pro2 Administration den Menüpunkt
Extras -> Code generieren -> Zielschema aus ,
wählen Sie dann im Dialogfeld
Datenbank auswählen eine oder mehrere Quelldatenbanken aus und übertragen Sie sie nach rechts.

Klicken Sie auf OK und wählen Sie das Verzeichnis aus, in dem die SQL-Schemas gespeichert werden sollen.
Als nächstes erstellen wir die Basis. Dies kann beispielsweise über
Oracle SQL Developer erfolgen . Stellen Sie dazu eine Verbindung zur Oracle-Datenbank her und laden Sie das Schema, um Tabellen hinzuzufügen. Nachdem Sie die Zusammensetzung der Oracle-Tabellen geändert haben, müssen Sie die SQL-Schemas im Schema-Holder aktualisieren.

Nachdem der Download erfolgreich abgeschlossen wurde, beenden Sie die Bisquitsh-Datenbank und öffnen Sie das Pro2-Administrationsfenster. Die Tabellen aus der Oracle-Datenbank sollten rechts auf der Registerkarte Zuordnung angezeigt werden.
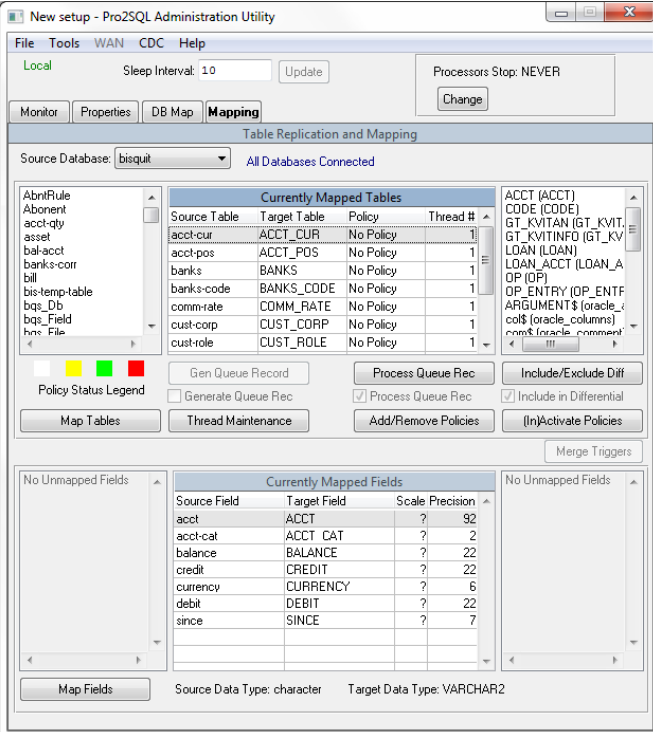
Tabellen zuordnen
Um eine Replikationszuordnung im Pro2-Administrationsbereich zu erstellen, wechseln Sie zur Registerkarte Zuordnung und wählen Sie die Quellendatenbank aus. Wir klicken auf Map Tables, wählen links Select Changes-Tabellen aus, die auf Oracle repliziert werden sollen, übertragen sie nach rechts und bestätigen die Auswahl. Für die ausgewählten Tabellen wird automatisch eine Karte erstellt. Wiederholen Sie den Vorgang, um eine Replikationszuordnung für andere Quelldatenbanken zu erstellen.
Generierung der Programme Pro2 Replication Processor Library und Bulk-Copy Processor
Die Prozessorbibliothek wurde für spezielle Replikationsprozesse (ETLs) entwickelt, die die Pro2-Replikationswarteschlange verarbeiten und die Änderungen in die Oracle-Datenbank übertragen. Nach der Generierung werden die Replikationsprozessor-Bibliotheksprogramme automatisch im
Verzeichnis bprepl / repl_proc (Parameter PROC_DIRECTORY) gespeichert . Um die Replikationsprozessorbibliothek zu generieren, gehen Sie zu
Extras -> Code generieren -> Prozessorbibliothek. Nach Abschluss der Generierung werden die Programme im
Verzeichnis bprepl / repl_proc angezeigt .
Massenprozessorprogramme werden verwendet, um die Quell-Progress-Datenbanken mit der Oracle-Zieldatenbank basierend auf der Programmiersprache Progress ABL (4GL) zu synchronisieren. Um sie zu generieren, gehen Sie zum Menüpunkt
Extras -> Code generieren -> Massenkopierprozessor . Wählen Sie im Dialogfeld Datenbank auswählen die Quelldatenbank aus, übertragen Sie sie auf die rechte Seite des Fensters und klicken Sie auf
OK . Nach Abschluss der Generierung werden die Programme im
Verzeichnis bprepl \ repl_mproc angezeigt .
Konfigurieren von Replikationsprozessen in Pro2
Das Aufteilen der Tabellen in Gruppen, die von einem separaten Replikationsthread bedient werden, kann die Leistung und Effizienz von Oracle Pro2 verbessern. Standardmäßig sind alle in der Replikationszuordnung für neue Replikationstabellen erstellten Verbindungen an Stream Nummer 1 gebunden. Es wird empfohlen, Tabellen in verschiedene Flows zu unterteilen.
Informationen zum Status von Replikationsabläufen werden auf dem Bildschirm Pro2 Administration auf der Registerkarte Monitor im Abschnitt Replikationsstatus angezeigt. Eine ausführliche Beschreibung der Parameterwerte finden Sie in der Pro2-Dokumentation (Verzeichnis C: \ Pro2 \ Docs).
Erstellen und aktivieren Sie CDC-Richtlinien
Richtlinien sind eine Reihe von Regeln für den OpenEdge CDC-Mechanismus, nach denen Änderungen in Tabellen verfolgt werden. Zum Zeitpunkt des Schreibens unterstützt Pro2 nur CDC-Richtlinien mit Stufe 0, dh nur die Tatsache
einer Datensatzänderung wird verfolgt.
Um eine CDC-Richtlinie im Verwaltungsbereich zu erstellen, wechseln Sie zur Registerkarte Zuordnung, wählen Sie die Quellendatenbank aus und klicken Sie auf die Schaltfläche Richtlinien hinzufügen / entfernen. Wählen Sie im daraufhin geöffneten Fenster Änderungen auswählen auf der linken Seite die Option aus und übertragen Sie sie in die rechte Tabelle, für die Sie eine CDC-Richtlinie erstellen oder löschen müssen.
Öffnen Sie zum Aktivieren die Registerkarte Zuordnung erneut, wählen Sie die Quellendatenbank aus und klicken Sie auf die Schaltfläche
(In) Richtlinien aktivieren. Wählen Sie aus und übertragen Sie auf die rechte Seite der Tabelle, deren Richtlinien Sie aktivieren müssen. Klicken Sie auf OK. Danach werden sie grün markiert. Mit
(In) Activate Policies (Richtlinien aktivieren) können Sie auch CDC-Richtlinien deaktivieren. Alle Operationen werden online ausgeführt.

Nach dem Aktivieren der CDC-Richtlinie werden Notizen zu den geänderten Datensätzen gemäß der ursprünglichen Datenbank im Speicherbereich
„ReplCDCArea“ gespeichert. Diese Notizen werden von einem speziellen
CDCBatch- Prozess verarbeitet, der auf ihrer Grundlage Notizen in der Pro2-Replikationswarteschlange in der
cdc (repl) -Datenbank erstellt.
Somit haben wir zwei Warteschlangen für die Replikation. Die erste Stufe ist CDCBatch: Von der ursprünglichen Datenbank gehen die Daten zuerst in die CDC-Zwischendatenbank. In der zweiten Phase werden Daten aus der CDC-Datenbank in Oracle übertragen. Dies ist ein Merkmal der aktuellen Architektur und des Produkts selbst. Bisher konnten Entwickler keine direkte Replikation einrichten.
Primärsynchronisation
Nachdem Sie den CDC-Mechanismus aktiviert und den Pro2-Replikationsserver eingerichtet haben, müssen Sie die primäre Synchronisierung starten. Primärer Startbefehl für die Synchronisation:
/pro2/bprepl/Script/replLoad.sh bisquit TabellennameNach Abschluss der ersten Synchronisierung können Replikationsprozesse gestartet werden.
Starten Sie die Replikationsprozesse
Um Replikationsprozesse zu starten, müssen Sie das Skript
replbatch.sh ausführen . Stellen Sie vor dem Start sicher, dass für alle Threads Replbatch-Skripte vorhanden sind - Replbatch1, Replbatch2 usw. Wenn alles vorhanden ist, öffnen Sie die Befehlszeile (z. B.
proenv) ,
wechseln Sie in das
Verzeichnis / bprepl / scripts und starten Sie das Skript. Im Verwaltungsbereich überprüfen wir, ob der entsprechende Prozess den Status RUNNING erhalten hat.

Ergebnisse
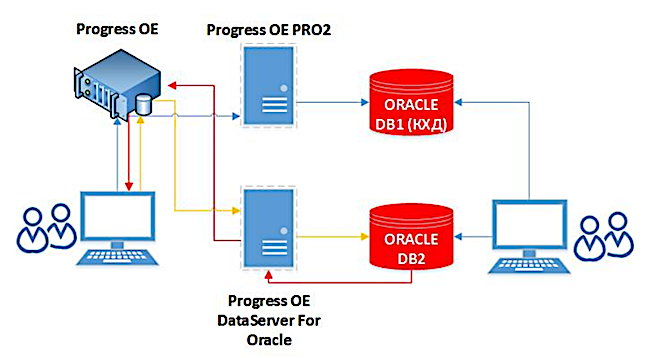
Nach der Implementierung haben wir das Hochladen von Informationen in das Corporate Data Warehouse erheblich beschleunigt. Die Daten selbst gehen online an Oracle. Sie müssen keine Zeit mit lang laufenden Abfragen verbringen, um Daten von verschiedenen Systemen zu erfassen. Darüber hinaus kann der Replikationsprozess in dieser Lösung Daten komprimieren, was sich auch positiv auf die Geschwindigkeit auswirkt. Jetzt begann die tägliche Abstimmung des BISKVIT-Systems mit anderen Systemen 15 bis 20 Minuten statt 2 bis 2,5 Stunden und die vollständige Abstimmung mehrere Stunden statt zwei Tage.