Vorwort
Dieser Artikel ist nicht sehr ähnlich zu denen, die zuvor über das Scannen des Internets bestimmter Länder veröffentlicht wurden, da ich nicht die Ziele verfolgt habe, ein bestimmtes Segment des Internets nach offenen Ports und dem Vorhandensein der beliebtesten Sicherheitslücken zu durchsuchen, da dies gegen das Gesetz verstößt.
Ich hatte eher ein etwas anderes Interesse - zu versuchen, alle relevanten Sites in der BY-Domänenzone mit verschiedenen Methoden zu identifizieren, den Stapel der verwendeten Technologien durch Dienste wie Shodan, VirusTotal usw. zu bestimmen, eine passive Aufklärung über IP und offene Ports durchzuführen und im Anhang ein wenig anderes Nützliches zu sammeln Informationen zur Erstellung einiger allgemeiner Statistiken zum Sicherheitsniveau in Bezug auf Websites und Benutzer.
Einführung und unser Toolkit
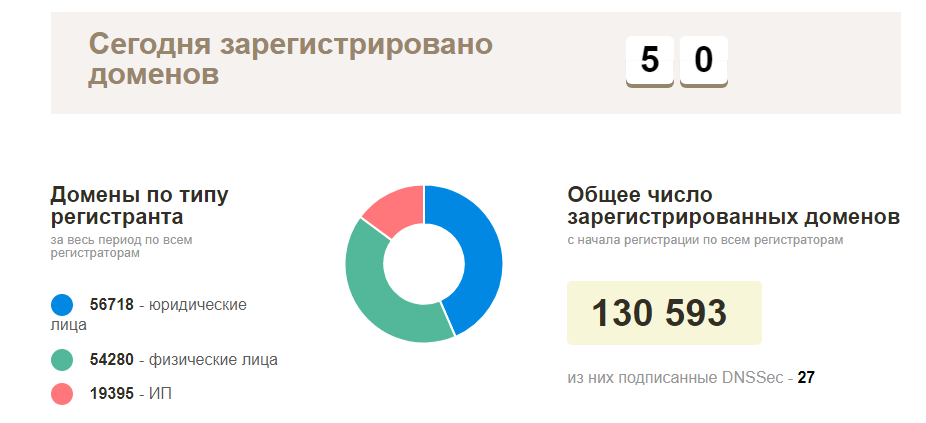
Der Plan am Anfang war einfach: Wenden Sie sich an Ihren lokalen Registrar, um eine Liste der aktuell registrierten Domains zu erhalten. Überprüfen Sie dann alles auf Verfügbarkeit und erkunden Sie funktionierende Websites. In Wirklichkeit stellte sich heraus, dass alles viel komplizierter war - diese Art von Informationen war natürlich, niemand wollte sie bereitstellen, mit Ausnahme der offiziellen Statistikseite der tatsächlich registrierten Domainnamen in der BY-Zone (ungefähr 130.000 Domains). Wenn es keine solchen Informationen gibt, müssen Sie sie selbst sammeln.
In Bezug auf Werkzeuge ist in der Tat alles ganz einfach - wir schauen auf Open Source, Sie können immer etwas hinzufügen, einige minimale Krücken fertigstellen. Von den beliebtesten wurden die folgenden Tools verwendet:
Beginn der Aktivitäten: Ausgangspunkt
Als Einführung waren, wie ich bereits sagte, idealerweise Domain-Namen geeignet, aber wo kann ich sie bekommen? Wir müssen von etwas Einfacherem ausgehen, in diesem Fall sind IP-Adressen für uns geeignet, aber auch hier ist es bei umgekehrten Suchvorgängen nicht immer möglich, alle Domänen abzufangen, und beim Sammeln von Hostnamen ist dies nicht immer die richtige Domäne. Zu diesem Zeitpunkt begann ich erneut über mögliche Szenarien für das Sammeln dieser Art von Informationen nachzudenken - die Tatsache, dass unser Budget für die VPS-Vermietung 5 USD betrug, wurde berücksichtigt, alles andere sollte kostenlos sein.
Unsere potenziellen Informationsquellen:
- IP-Adressen ( ip2location site)
- Suchen Sie nach Domains im zweiten Teil der E-Mail-Adresse (aber wo erhalten Sie sie?
- Einige Registrare / Hosting-Anbieter stellen uns solche Informationen möglicherweise in Form von Subdomains zur Verfügung
- Subdomains und ihre anschließende Umkehrung (Sublist3r und Aquatone können hier helfen)
- Bruteforce und manuelle Eingabe (lang, trostlos, aber möglich, obwohl ich diese Option nicht verwendet habe)
Ich werde ein wenig vorausgehen und sagen, dass ich mit diesem Ansatz ungefähr 50.000 eindeutige Domains bzw. Sites gesammelt habe (ich habe es nicht geschafft, alles zu verarbeiten). Wenn er weiterhin aktiv Informationen gesammelt hätte, hätte mein Förderer mit Sicherheit in weniger als einem Monat Arbeit die gesamte Datenbank oder den größten Teil davon gemeistert.
Kommen wir zur Sache
In früheren Artikeln wurden Informationen zu IP-Adressen von der IP2LOCATION-Site übernommen. Aus offensichtlichen Gründen bin ich nicht auf diese Artikel gestoßen (da alle Aktionen viel früher ausgeführt wurden), sondern auch auf diese Ressource. In meinem Fall war der Ansatz zwar anders - ich habe mich entschieden, die Datenbank nicht lokal für mich zu nutzen und keine Informationen aus der CSV zu extrahieren, sondern die Änderungen direkt auf der Website zu überwachen, fortlaufend und als Hauptgrundlage, von der aus alle nachfolgenden Skripte Ziele verfolgen - eine Tabelle mit erstellt IP-Adressen in verschiedenen Formaten: CIDR, Liste „von“ und „bis“, Ländermarke (nur für den Fall), AS-Nummer, AS-Beschreibung.
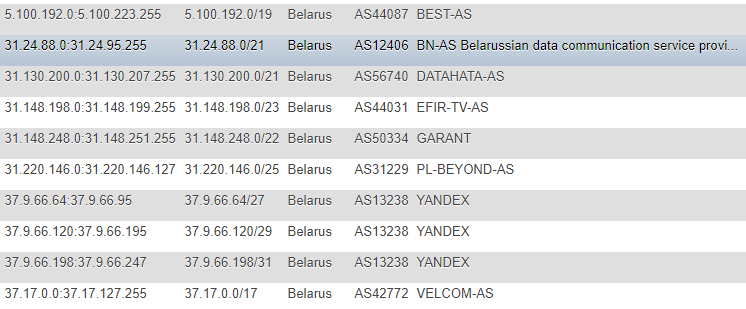
Das Format ist nicht das optimalste, aber ich war sehr zufrieden mit der Demo und der einmaligen Werbung. Um nicht ständig nach zusätzlichen Informationen wie ASN zu suchen, habe ich beschlossen, diese zusätzlich selbst zu protokollieren. Um diese Informationen zu erhalten, habe ich mich an den
IpToASN- Dienst
gewandt. Er verfügt über eine praktische API (mit Einschränkungen), die Sie nur in sich selbst integrieren müssen.
IP-Parsing-Codefunction ipList() { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://lite.ip2location.com/belarus-ip-address-ranges"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $ipList = curl_exec($ch); curl_close ($ch); preg_match_all("/(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}\<\/td\>\s+\<td\>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})/", $ipList, $matches); return $matches[0]; } function iprange2cidr($ipStart, $ipEnd){ if (is_string($ipStart) || is_string($ipEnd)){ $start = ip2long($ipStart); $end = ip2long($ipEnd); } else{ $start = $ipStart; $end = $ipEnd; } $result = array(); while($end >= $start){ $maxSize = 32; while ($maxSize > 0){ $mask = hexdec(iMask($maxSize - 1)); $maskBase = $start & $mask; if($maskBase != $start) break; $maxSize--; } $x = log($end - $start + 1)/log(2); $maxDiff = floor(32 - floor($x)); if($maxSize < $maxDiff){ $maxSize = $maxDiff; } $ip = long2ip($start); array_push($result, "$ip/$maxSize"); $start += pow(2, (32-$maxSize)); } return $result; } $getIpList = ipList(); foreach($getIpList as $item) { $cidr = iprange2cidr($ip[0], $ip[1]); }
Nachdem wir IP herausgefunden haben, müssen wir unsere gesamte Datenbank leider ohne Einschränkungen über die Reverse-Lookup-Dienste ausführen - dies ist mit Ausnahme des Geldes unmöglich.
Von den Diensten, die dafür großartig und bequem zu verwenden sind, möchte ich zwei erwähnen:
- VirusTotal - Begrenzung der Häufigkeit von Aufrufen von einem API-Schlüssel
- Hackertarget.com (ihre API) - Begrenzung der Anzahl der Treffer von einer IP
Unter Umgehung der Grenzwerte wurden folgende Optionen erhalten:
- Im ersten Fall besteht eines der Szenarien darin, Zeitüberschreitungen von 15 Sekunden zu überstehen. Insgesamt werden 4 Anrufe pro Minute ausgeführt, was sich stark auf unsere Geschwindigkeit auswirken kann. In dieser Situation ist es nützlich, 2-3 solcher Tasten zu verwenden, und ich würde empfehlen, auf dieselben zurückzugreifen zum Proxy und zum Ändern des Benutzeragenten.
- Im zweiten Fall habe ich ein Skript zum automatischen Parsen der Proxy-Datenbank basierend auf öffentlich verfügbaren Informationen, deren Validierung und anschließender Verwendung geschrieben (aber später habe ich diese Option verlassen, da VirusTotal im Wesentlichen auch ausreichte).
Wir gehen weiter und gehen reibungslos zu den E-Mail-Adressen. Sie können auch eine Quelle nützlicher Informationen sein, aber wo können sie gesammelt werden? Es dauerte nicht lange, eine Lösung zu finden. Benutzer halten wenig in unserem Segment persönlicher Websites, und die meisten von ihnen sind Organisationen - Profilwebsites wie Online-Shop-Verzeichnisse, Foren und bedingte Marktplätze werden zu uns passen.
Eine schnelle Überprüfung einer dieser Websites ergab beispielsweise, dass viele Benutzer ihre E-Mails direkt zu ihrem öffentlichen Profil hinzufügen. Dementsprechend kann dieses Unternehmen für die zukünftige Verwendung sorgfältig analysiert werden.
Ich werde nicht näher auf das Parsen der einzelnen Websites eingehen. An einem Ort ist es bequemer, die Benutzer-ID mit brutaler Gewalt zu erraten. An einem Ort ist es einfacher, eine Sitemap zu analysieren, Informationen zu Unternehmensseiten abzurufen und dann Adressen von diesen zu sammeln. Nach dem Sammeln der Adressen müssen wir noch einige einfache Vorgänge ausführen, um sie sofort nach der Domänenzone zu sortieren, die „Schwänze“ beizubehalten und sie auszuführen, um Duplikate aus der vorhandenen Datenbank auszuschließen.
In diesem Stadium glaube ich, dass wir mit der Bildung des Anwendungsbereichs enden und zur Intelligenz übergehen können. Wie wir bereits wissen, kann es zwei Arten von Intelligenz geben - in unserem Fall aktiv und passiv -, wobei der passive Ansatz am relevantesten ist. Andererseits ist es durchaus legitim, auf die Site über Port 80 oder 443 ohne böswillige Belastung zuzugreifen und Schwachstellen auszunutzen. Unser Interesse gilt Serverantworten auf eine einzelne Anfrage. In einigen Fällen kann es zwei Anfragen geben (Umleitung von http zu https), in selteneren Fällen sogar drei (wenn www verwendet wird).
Intelligenz
Mit solchen Informationen als Domain können wir die folgenden Daten sammeln:
- DNS-Einträge (NS, MX, TXT)
- Beantworten Sie Header
- Identifizieren Sie den verwendeten Technologie-Stack
- Verstehen Sie, nach welchem Protokoll die Site funktioniert.
- Versuchen Sie, offene Ports (basierend auf der Shodan / Censys-Datenbank) ohne direktes Scannen zu identifizieren
- Versuchen Sie, Schwachstellen anhand der Korrelation von Informationen aus Shodan / Censys mit der Vulners-Datenbank zu identifizieren
- Befindet es sich in der Malware-Datenbank von Google Safe Browsing?
- Sammeln Sie E-Mail-Adressen nach Domain sowie die bereits gefundenen Übereinstimmungen und überprüfen Sie sie zusätzlich durch Verweisen auf soziale Netzwerke
- Eine Domain ist in einigen Fällen nicht nur das Gesicht des Unternehmens, sondern auch das Produkt seiner Aktivitäten, E-Mail-Adressen für die Registrierung von Diensten usw. Sie können auf Ressourcen wie GitHub, Pastebin, Google Dorks (Google CSE) nach Informationen suchen, die mit ihnen verknüpft sind )
Sie können jederzeit Masscan oder nmap, zmap als Option verwenden und diese zuerst über Tor einrichten, indem Sie sie zu einem zufälligen Zeitpunkt oder sogar aus mehreren Instanzen heraus starten. Wir haben jedoch andere Ziele und der Name impliziert, dass ich keine direkten Scans durchgeführt habe.
Wir sammeln DNS-Einträge, prüfen die Möglichkeit der Verstärkung von Anfragen und Konfigurationsfehlern wie AXFR:
Ein Beispiel für das Sammeln von NS-Serverdatensätzen dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'
Beispiel für die Sammlung von MX-Datensätzen (siehe NS, ersetzen Sie einfach 'ns' durch 'mx'
Suchen Sie nach AXFR (hier gibt es viele Lösungen, hier ist eine andere Krücke, aber keine Sicherheit, die zum Anzeigen der Ausgaben verwendet wird). $digNs = trim(shell_exec("dig ns +short $domain | sed 's/\.$//g' | awk '{print $1}'")); $ns = explode("\n", $digNs); foreach($ns as $target) { $axfr = trim(shell_exec("dig -t axfr $domain @$target | awk '{print $1}' | sed 's/\.$//g'")); $axfr = preg_replace("/\;/", "", $axfr); if(!empty(trim($axfr))) { $axfr = preg_replace("/\;/", "", $axfr); $res = json_encode(explode("\n", trim($axfr)));
Überprüfen Sie die DNS-Verstärkung dig +short test.openresolver.com TXT @$dns
In meinem Fall wurden die NS-Server aus der Datenbank entnommen, sodass Sie am Ende der Variablen tatsächlich nur jeden Server ersetzen können. In Bezug auf die Richtigkeit der Ergebnisse dieses Dienstes kann ich nicht sicher sein, dass dort alles reibungslos funktioniert und die Ergebnisse immer gültig sind, aber ich hoffe, dass die meisten Ergebnisse echt sind.
Wenn wir für irgendeinen Zweck eine vollständige endgültige URL zur Site behalten müssen, habe ich dafür cURL verwendet:
curl -I -L $target | awk '/Location/{print $2}'
Er selbst wird die gesamte Weiterleitung durchlaufen und die letzte anzeigen, d. H. aktuelle Site-URL. In meinem Fall war es äußerst nützlich für die spätere Verwendung von Tools wie WhatWeb.
Warum sollten wir es benutzen? Um das Betriebssystem, den Webserver, die verwendete CMS-Site, einige Header, zusätzliche Module wie JS / HTML-Bibliotheken / Frameworks sowie den Site-Titel zu bestimmen, nach dem Sie später versuchen können, nach demselben Aktivitätsfeld zu filtern.
In diesem Fall besteht eine sehr bequeme Option darin, die Ergebnisse des Betriebs des Tools im XML-Format für die nachfolgende Analyse zu exportieren und in die Datenbank zu importieren, wenn das Ziel besteht, alles später zu verarbeiten.
whatweb --no-errors https://www.mywebsite.com --log-xml=results.xml
Für mich selbst habe ich JSON als Ergebnis der Ausgabe erstellt und es bereits in die Datenbank gestellt.
Apropos Header: Mit einer normalen cURL können Sie fast dasselbe tun, indem Sie eine Abfrage des Formulars ausführen:
curl -I https://www.mywebsite.com
Abrufen von Informationen zu CMS und Webservern in den Headern beispielsweise mithilfe regulärer Ausdrücke.
Zusätzlich zu dem nützlichen können wir auch die Möglichkeit hervorheben, Informationen über offene Ports mit Shodan zu sammeln und dann anhand der bereits erhaltenen Daten die Vulners-Datenbank mithilfe ihrer API zu überprüfen (Links zu Diensten finden Sie im Header). Natürlich kann es in diesem Szenario zu Problemen mit der Genauigkeit kommen, aber dies ist kein direkter Scan mit manueller Validierung, sondern ein banales „Jonglieren“ von Daten aus Quellen von Drittanbietern, aber zumindest ist es besser als gar nichts.
PHP-Funktion für Shodan function shodanHost($host) { $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, "https://api.shodan.io/shodan/host/".$host."?key=<YOUR_API_KEY>"); curl_setopt($ch, CURLOPT_HEADER, 0); curl_setopt($ch, CURLOPT_USERAGENT,'Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.13) Gecko/20080311 Firefox/2.0.0.13'); curl_setopt($ch, CURLOPT_RETURNTRANSFER, true); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); $shodanResponse = curl_exec($ch); curl_close ($ch); return json_decode($shodanResponse); }
Ein Beispiel für eine solche vergleichende Analyse # 1 Ja, da sie angefangen haben, über die API zu sprechen, haben Vulner Einschränkungen und die optimalste Lösung wäre die Verwendung ihres Python-Skripts. Alles wird ohne Torsions-Twists gut funktionieren. Im Fall von PHP bin ich auf einige kleine Schwierigkeiten gestoßen (wieder hinzufügen). Timeouts haben die Situation gerettet).
Einer der neuesten Tests - Wir werden die Informationen zur Firewall untersuchen, die mit einem Skript wie "wafw00f" verwendet wird. Beim Testen dieses wunderbaren Tools fiel mir eine interessante Sache auf: Es war nicht immer das erste Mal, dass der verwendete Firewall-Typ bestimmt werden konnte.
Um zu sehen, welche Arten von Firewalls wafw00f möglicherweise erkennen kann, können Sie den folgenden Befehl eingeben:
wafw00f -l
Um den Firewall-Typ zu bestimmen, analysiert wafw00f die Server-Antwortheader nach dem Senden einer Standardanforderung an die Site. Wenn dieser Versuch nicht ausreicht, wird eine zusätzliche einfache Testanforderung generiert. Wenn dies nicht erneut ausreicht, verarbeitet die dritte Methode die Daten nach den ersten beiden Versuchen .
Weil Für Statistiken benötigen wir nicht die gesamte Antwort. Wir schneiden den gesamten Überschuss mit einem regulären Ausdruck ab und belassen nur den Namen Firewall:
/is\sbehind\sa\s(.+?)\n/
Nun, wie ich bereits geschrieben habe - zusätzlich zu Informationen über die Domain und die Site wurden die Informationen über E-Mail-Adressen und soziale Netzwerke auch im passiven Modus aktualisiert:
Statistiken per E-Mail basierend auf der Domain definiert Ein Beispiel für die Bestimmung der Bindung sozialer Netzwerke an die E-Mail-Adresse Der einfachste Weg war die Adressvalidierung auf Twitter (2 Wege), bei Facebook (1 Weg) stellte sich diesbezüglich aufgrund eines etwas komplizierteren Systems zum Generieren einer echten Benutzersitzung als etwas komplizierter heraus.
Fahren wir mit der Trockenstatistik fort.
DNS-Statistiken
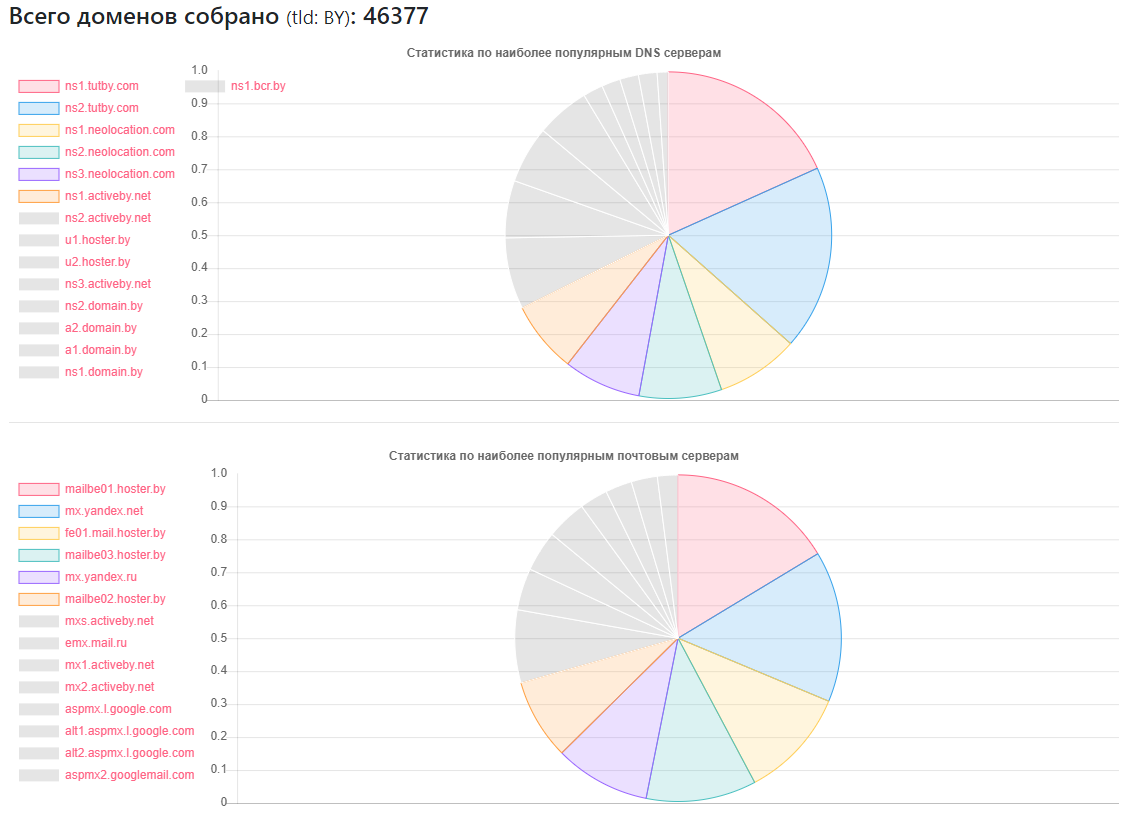 Anbieter - wie viele Websites
Anbieter - wie viele Websitesns1.tutby.com: 10899
ns2.tutby.com: 10899
ns1.neolocation.com: 4877
ns2.neolocation.com: 4873
ns3.neolocation.com: 4572
ns1.activeby.net: 4231
ns2.activeby.net: 4229
u1.hoster.by: 3382
u2.hoster.by: 3378
Eindeutiger DNS gefunden: 2462
Einzigartige MX (Mail) -Server: 9175 (zusätzlich zu den beliebten Diensten gibt es eine ausreichende Anzahl von Administratoren, die ihre eigenen Mail-Dienste verwenden.)
Betroffen von der DNS-Zonenübertragung: 1011
Betroffen von der DNS-Verstärkung: 531
Nur wenige CloudFlare-Fans: 375 (basierend auf verwendeten NS-Datensätzen)
CMS-Statistiken
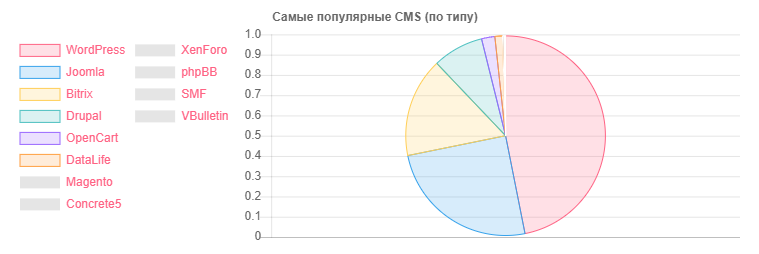 CMS - Menge
CMS - MengeWordPress: 5118
Joomla: 2722
Bitrix: 1757
Drupal: 898
OpenCart: 235
DataLife: 133
Magento: 32
- Potenziell anfällige WordPress-Installationen: 2977
- Potenziell gefährdete Installationen von Joomla: 212
- Mit dem Google SafeBrowsing-Dienst konnten potenziell gefährliche oder infizierte Websites identifiziert werden: etwa 10.000 (zu unterschiedlichen Zeiten wurde jemand repariert, jemand ist anscheinend pleite, Statistiken sind nicht ganz objektiv).
- Über HTTP und HTTPS - weniger als die Hälfte der Sites des gefundenen Volumes verwenden letzteres, aber unter Berücksichtigung der Tatsache, dass meine Datenbank nicht vollständig ist, sondern nur 40% der Gesamtzahl, ist es durchaus möglich, dass die meisten Sites aus der zweiten Hälfte über HTTPS kommunizieren können .
Firewall-Statistiken:
 Firewall - Nummer
Firewall - NummerModSecurity: 4354
IBM Web App Security: 126
Bessere WP-Sicherheit: 110
CloudFlare: 104
Imperva SecureSphere: 45
Juniper WebApp Secure: 45
Webserver-Statistiken
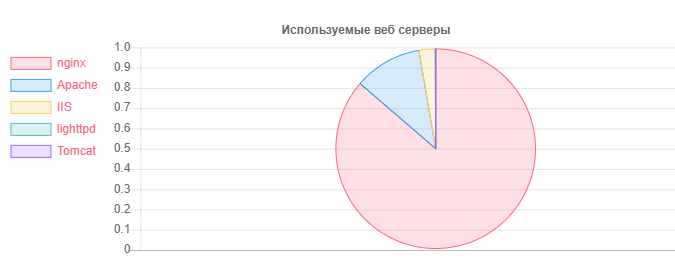 Webserver - Nummer
Webserver - NummerNginx: 31752
Apache: 4042
IIS: 959
Veraltete und potenziell anfällige Installationen von Nginx: 20966
Veraltete und möglicherweise anfällige Installationen von Apache: 995
Trotz der Tatsache, dass hoster.by beispielsweise bei Domains und Hosting im Allgemeinen führend ist, wurde auch Open Contact ausgezeichnet, aber die Wahrheit liegt in der Anzahl der Websites auf einer IP:
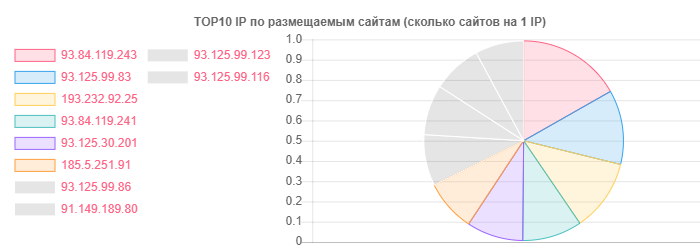 IP - Sites
IP - Sites93.84.119.243: 556
93.125.99.83: 399
193.232.92.25: 386
Per E-Mail entschieden sich die detaillierten Statistiken wirklich dafür, nicht abgerufen und nicht nach der Domain-Zone sortiert zu werden. Vielmehr war es interessant, den Standort der Benutzer bei bestimmten Anbietern zu sehen:
- Auf dem TUT.BY-Dienst: 38282
- Auf dem Yandex-Dienst (von | ru): 28127
- Auf dem Google Mail-Dienst: 33452
- An Facebook gebunden: 866
- An Twitter gebunden: 652
- Gekennzeichnet in Lecks gemäß HIBP: 7844
- Passive Intelligenz half dabei, mehr als 13.000 E-Mail-Adressen zu identifizieren
Wie Sie sehen, ist das Gesamtbild recht positiv, insbesondere die aktive Nutzung von Nginx seitens der Hosting-Anbieter. Möglicherweise liegt dies hauptsächlich an dem bei normalen Benutzern beliebten Shared-Hosting-Typ.
Aufgrund der Tatsache, dass es mir nicht wirklich gefallen hat, gibt es eine ausreichende Anzahl von Hosting-Anbietern der mittleren Hand, die Fehler wie AXFR bemerkt, veraltete Versionen von SSH und Apache und einige andere kleinere Probleme verwendet haben. Hier könnte natürlich durch die aktive Phase mehr Licht auf die Situation geworfen werden, aber im Moment scheint es mir aufgrund unserer Gesetzgebung unmöglich zu sein, und ich möchte mich nicht wirklich in die Reihen der Schädlinge für solche Angelegenheiten eintragen.
Das E-Mail-Bild ist im Allgemeinen ziemlich rosig, wenn man es so nennen kann. Oh ja, wo der TUT.BY-Anbieter angegeben ist - das bedeutete, die Domain zu benutzen, weil Dieser Service basiert auf Yandex.
Fazit
Abschließend kann ich eines sagen: Selbst mit den verfügbaren Ergebnissen können Sie schnell verstehen, dass Spezialisten, die Websites von Viren reinigen, WAF einrichten und verschiedene CMS konfigurieren / hinzufügen, viel Arbeit benötigen.
Nun, im Ernst, wie in den beiden vorhergehenden Artikeln, sehen wir, dass die Probleme in absolut allen Segmenten des Internets und in den Ländern auf absolut unterschiedlichen Ebenen bestehen und einige von ihnen auch dann auftauchen, wenn sie das Problem aus der Ferne untersuchen, ohne beleidigende Methoden usw. e. Verwendung öffentlich zugänglicher Informationen, um zu sammeln, welche besonderen Fähigkeiten nicht erforderlich sind.