
Im letzten Artikel haben wir die theoretischen Grundlagen der reaktiven Architektur untersucht. Es ist Zeit, über Datenströme, Möglichkeiten zur Implementierung reaktiver Erlang / Elixir-Systeme und Messaging-Muster zu sprechen:
- Antwort anfordern
- Request-Chunked-Antwort
- Antwort mit Anfrage
- Veröffentlichen-Abonnieren
- Inverted Publish-Subscribe
- Aufgabenverteilung
SOA, MSA und Messaging
SOA, MSA - Systemarchitekturen, die die Regeln für das Erstellen von Systemen definieren, während Messaging Grundelemente für deren Implementierung bereitstellt.
Ich möchte diese oder jene Architektur von Gebäudesystemen nicht fördern. Ich bin für die Anwendung der effektivsten und nützlichsten Praktiken für ein bestimmtes Projekt und Geschäft. Welches Paradigma wir auch wählen, es ist besser, Systemblöcke mit Blick auf den Unix-Weg zu erstellen: Komponenten mit minimaler Konnektivität, die für einzelne Entitäten verantwortlich sind. API-Methoden führen die einfachsten Aktionen mit Entitäten aus.
Messaging - wie der Name schon sagt, ist ein Nachrichtenbroker. Sein Hauptzweck ist es, Nachrichten zu empfangen und zu geben. Er ist verantwortlich für die Schnittstellen zum Senden von Informationen, die Bildung logischer Kanäle für die Übertragung von Informationen innerhalb des Systems, das Routing und den Ausgleich sowie die Verarbeitung von Fehlern auf Systemebene.
Das zu entwickelnde Messaging versucht nicht, mit rabbitmq zu konkurrieren oder es zu ersetzen. Seine Hauptmerkmale:
- Verteilung
Austauschpunkte können auf allen Knoten des Clusters so nahe wie möglich an dem Code erstellt werden, der sie verwendet. - Einfachheit.
Konzentrieren Sie sich auf die Minimierung des Boilerplate-Codes und der Benutzerfreundlichkeit. - Die beste Leistung.
Wir versuchen nicht, die Funktionalität von rabbitmq zu wiederholen, sondern heben nur die Architektur- und Transportschicht hervor, die in OTP so einfach wie möglich ist, um die Kosten zu minimieren. - Flexibilität.
Jeder Dienst kann viele Austauschvorlagen kombinieren. - Fehlertoleranz im Design.
- Skalierbarkeit.
Messaging wächst mit der Anwendung. Mit zunehmender Last können Sie die Austauschpunkte auf einzelne Maschinen verschieben.
Bemerkung. Aus Sicht der Code-Organisation eignen sich Metaprojekte gut für komplexe Systeme mit Erlang / Elixir. Der gesamte Projektcode befindet sich in einem Repository - einem Dachprojekt. Gleichzeitig sind Microservices so isoliert wie möglich und führen einfache Vorgänge aus, die für eine separate Einheit verantwortlich sind. Mit diesem Ansatz ist es einfach, die API des gesamten Systems zu unterstützen. Nehmen Sie einfach Änderungen vor. Es ist bequem, Einheiten und Integrationstests zu schreiben.
Systemkomponenten interagieren direkt oder über einen Broker. Aus Messaging-Sicht hat jeder Dienst mehrere Lebensphasen:
- Service-Initialisierung.
In dieser Phase erfolgt die Konfiguration und der Start des Dienstes, der den Prozess und die Abhängigkeiten ausführt. - Einen Austauschpunkt erstellen.
Der Dienst kann den in der Konfiguration des Knotens angegebenen statischen Austauschpunkt verwenden oder Austauschpunkte dynamisch erstellen. - Serviceregistrierung.
Damit der Dienst Anfragen bearbeiten kann, muss er an der Vermittlungsstelle registriert sein. - Normale Funktion.
Service produziert nützliche Arbeit. - Herunterfahren.
Es gibt zwei Arten des Herunterfahrens: reguläres und Notfall. Bei einem regulären Service wird die Verbindung zum Wechselpunkt getrennt und angehalten. In Notfällen führt Messaging eines der Failover-Szenarien aus.
Es sieht ziemlich kompliziert aus, aber nicht alles ist im Code so beängstigend. Beispiele für Code mit Kommentaren werden etwas später in der Analyse von Vorlagen angegeben.
Börsen
Ein Austauschpunkt ist ein Messaging-Prozess, der die Logik der Interaktion mit Komponenten in einer Messaging-Vorlage implementiert. In allen folgenden Beispielen interagieren die Komponenten über Austauschpunkte, deren Kombination Messaging bildet.
Nachrichtenaustauschmuster (MEPs)
Das Teilen von Mustern kann global in zwei Richtungen und eine Richtung unterteilt werden. Ersteres impliziert eine Antwort auf die empfangene Nachricht, letzteres nicht. Ein klassisches Beispiel für ein Zwei-Wege-Muster in einer Client-Server-Architektur ist das Request-Response-Muster. Betrachten Sie die Vorlage und ihre Änderungen.
Anfrage - Antwort oder RPC
RPC wird verwendet, wenn wir eine Antwort von einem anderen Prozess erhalten müssen. Dieser Prozess kann am selben Standort oder auf einem anderen Kontinent gestartet werden. Unten sehen Sie ein Diagramm der Interaktion von Client und Server durch Messaging.
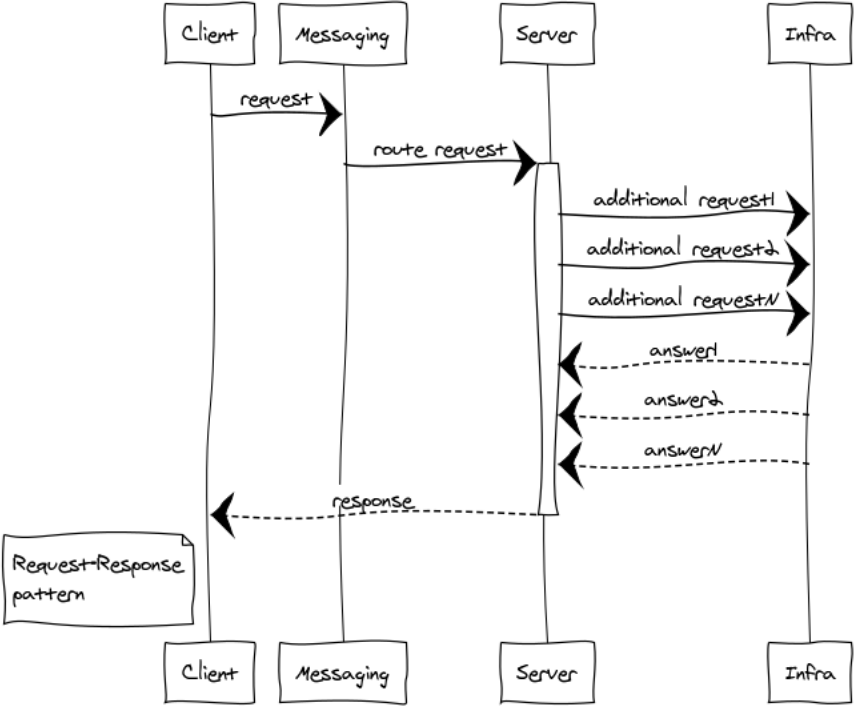
Da das Messaging vollständig asynchron ist, ist der Austausch für den Client in zwei Phasen unterteilt:
Einreichung anfordern
messaging:request(Exchange, ResponseMatchingTag, RequestDefinition, HandlerProcess).
Austausch - ein eindeutiger Name für den Austauschpunkt
ResponseMatchingTag - Die lokale Bezeichnung für die Antwort. Zum Beispiel beim Senden mehrerer identischer Anfragen, die verschiedenen Benutzern gehören.
RequestDefinition - Anfragetext
HandlerProcess - PID-Handler. Dieser Prozess erhält eine Antwort vom Server.
Antwortverarbeitung
handle_info(#'$msg'{exchange = EXCHANGE, tag = ResponseMatchingTag,message = ResponsePayload}, State)
ResponsePayload - Serverantwort.
Für den Server besteht der Prozess auch aus 2 Phasen:
- Exchange Point-Initialisierung
- Eingehende Anfragen bearbeiten
Lassen Sie uns diese Vorlage mit Code veranschaulichen. Angenommen, wir müssen einen einfachen Dienst implementieren, der die einzig genaue Zeitmethode bietet.
Servercode
Nehmen Sie die Definition der Service-API in api.hrl heraus:
Definieren Sie einen Service Controller in time_controller.erl
Kundencode
Um eine Anforderung an einen Dienst zu senden, können Sie die Messaging-Anforderungs-API an einer beliebigen Stelle im Client aufrufen:
case messaging:request(?EXCHANGE, tag, #time_req{opts = #{}}, self()) of ok -> ok; _ ->
In einem verteilten System kann die Konfiguration der Komponenten sehr unterschiedlich sein und zum Zeitpunkt der Anforderung wird das Messaging möglicherweise noch nicht gestartet, oder der Service-Controller ist nicht bereit, die Anforderung zu bearbeiten. Daher müssen wir die Messaging-Antwort überprüfen und den Fehlerfall behandeln.
Nach erfolgreichem Senden erhält der Client eine Antwort oder einen Fehler vom Dienst.
Behandeln Sie beide Fälle in handle_info:
handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time{unixtime = Utime}}}, State) -> ?debugVal(Utime), {noreply, State}; handle_info(#'$msg'{exchange = ?EXCHANGE, tag = tag, message = #time_resp{result = #time_error{code = ErrorCode}}}, State) -> ?debugVal({error, ErrorCode}), {noreply, State};
Request-Chunked-Antwort
Besser nicht die Übertragung großer Nachrichten zulassen. Davon hängt die Reaktionsfähigkeit und der stabile Betrieb des gesamten Systems ab. Wenn die Antwort auf die Anforderung viel Speicherplatz beansprucht, ist eine Aufteilung in Teile obligatorisch.
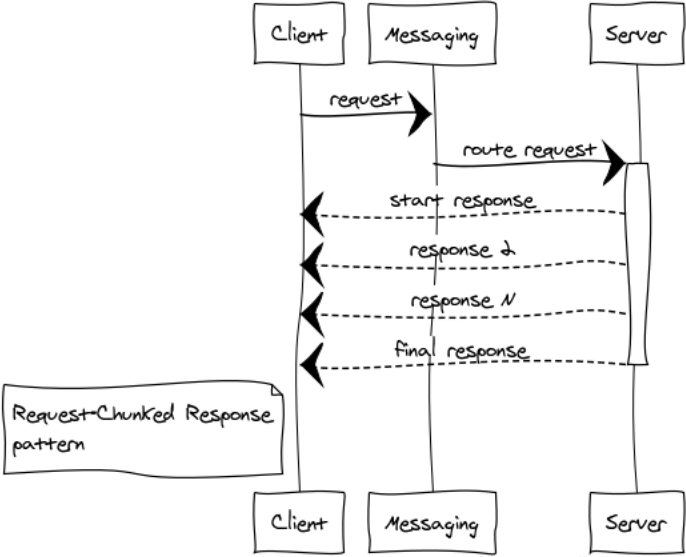
Ich werde einige Beispiele für solche Fälle geben:
- Komponenten tauschen Binärdaten aus, z. B. Dateien. Wenn Sie die Antwort in kleine Teile unterteilen, können Sie effizient mit Dateien jeder Größe arbeiten und keine Speicherüberläufe feststellen.
- Auflistungen. Zum Beispiel müssen wir alle Datensätze aus einer riesigen Tabelle in der Datenbank auswählen und auf eine andere Komponente übertragen.
Ich nenne diese Antworten eine Lokomotive. In jedem Fall sind 1024 1-MB-Nachrichten besser als eine einzelne 1-GB-Nachricht.
Im Erlang-Cluster erhalten wir einen zusätzlichen Gewinn, der die Belastung des Vermittlungspunkts und des Netzwerks verringert, da die Antworten sofort an den Empfänger gesendet werden und der Vermittlungspunkt umgangen wird.
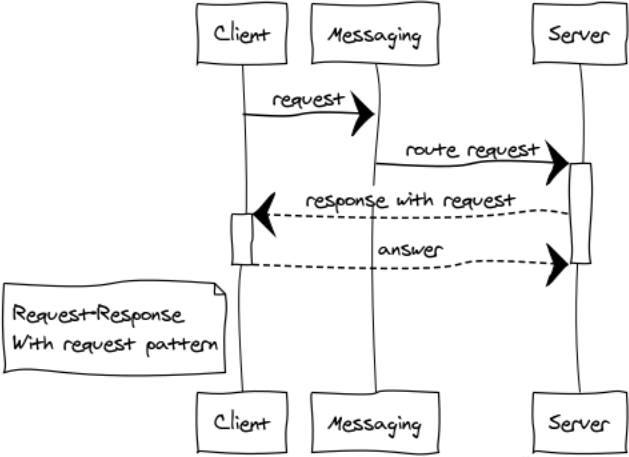
Antwort mit Anfrage
Dies ist eine ziemlich seltene Modifikation des RPC-Musters zum Erstellen interaktiver Systeme.
Publish-Subscribe (Datenverteilungsbaum)
Ereignisorientierte Systeme liefern Daten an Verbraucher, sobald Daten verfügbar sind. Daher sind Systeme anfälliger für Push-Modelle als für Pull oder Poll. Mit dieser Funktion können Sie keine Ressourcen verschwenden, indem Sie ständig Daten abfragen und darauf warten.
Die Abbildung zeigt den Prozess der Verteilung einer Nachricht an Verbraucher, die ein bestimmtes Thema abonniert haben.
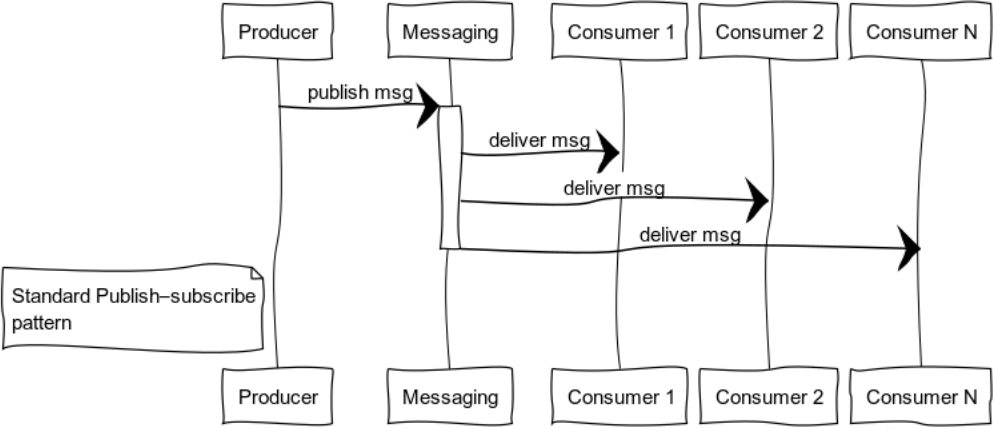
Klassische Beispiele für die Verwendung dieser Vorlage sind die Verteilung des Staates: die Spielewelt in Computerspielen, Marktdaten über Börsen, nützliche Informationen in Datenfeeds.
Betrachten Sie den Teilnehmercode:
init(_Args) ->
Die Quelle kann die Funktion nach der Veröffentlichung an einem beliebigen Ort aufrufen:
messaging:publish_message(Exchange, Key, Message).
Austausch - der Name des Austauschpunkts,
Schlüssel - Routing-Schlüssel
Nachricht - Nutzlast
Inverted Publish-Subscribe
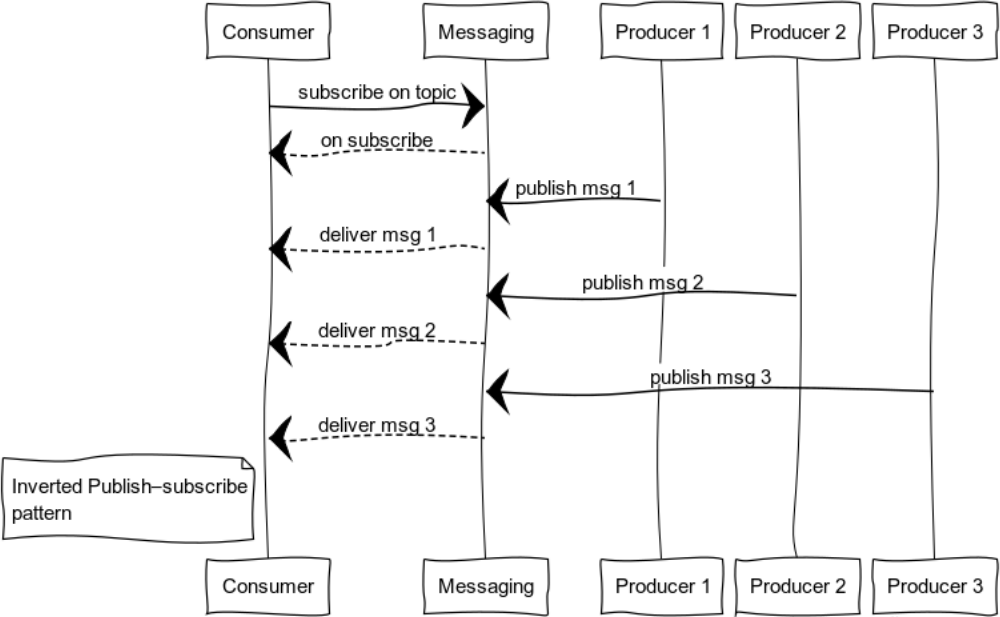
Durch Erweitern von pub-sub erhalten Sie ein Muster, das für die Protokollierung geeignet ist. Die Quellen und Verbraucher können völlig unterschiedlich sein. Die Abbildung zeigt einen Fall mit einem Verbraucher und mehreren Quellen.
Aufgabenverteilungsmuster
In fast jedem Projekt treten Aufgaben der verzögerten Verarbeitung auf, z. B. das Generieren von Berichten, das Übermitteln von Benachrichtigungen und das Empfangen von Daten von Systemen von Drittanbietern. Der Durchsatz eines Systems, das diese Aufgaben ausführt, kann durch Hinzufügen von Handlern leicht skaliert werden. Wir müssen nur noch eine Gruppe von Handlern bilden und die Aufgaben gleichmäßig auf sie verteilen.
Betrachten Sie die Situationen, die am Beispiel von 3 Handlern auftreten. Bereits in der Phase der Aufgabenverteilung stellt sich die Frage nach der Fairness der Verteilung und dem Überlauf der Prozessoren. Die Round-Robin-Verteilung ist für die Gerechtigkeit verantwortlich. Um ein Überlaufen der Handler zu vermeiden, führen wir die Einschränkung prefetch_limit ein . In Übergangsmodi verhindert prefetch_limit , dass ein Handler alle Aufgaben empfängt.
Messaging verwaltet Warteschlangen und Verarbeitungsprioritäten. Handler erhalten Aufgaben, sobald sie verfügbar sind. Die Aufgabe kann erfolgreich sein oder fehlschlagen:
messaging:ack(Tack) - messaging:ack(Tack) bei erfolgreicher Nachrichtenverarbeitung aufgerufenmessaging:nack(Tack) - wird in allen Notfallsituationen aufgerufen. Nachdem die Aufgabe zurückgekehrt ist, wird sie durch Messaging an einen anderen Handler übertragen.
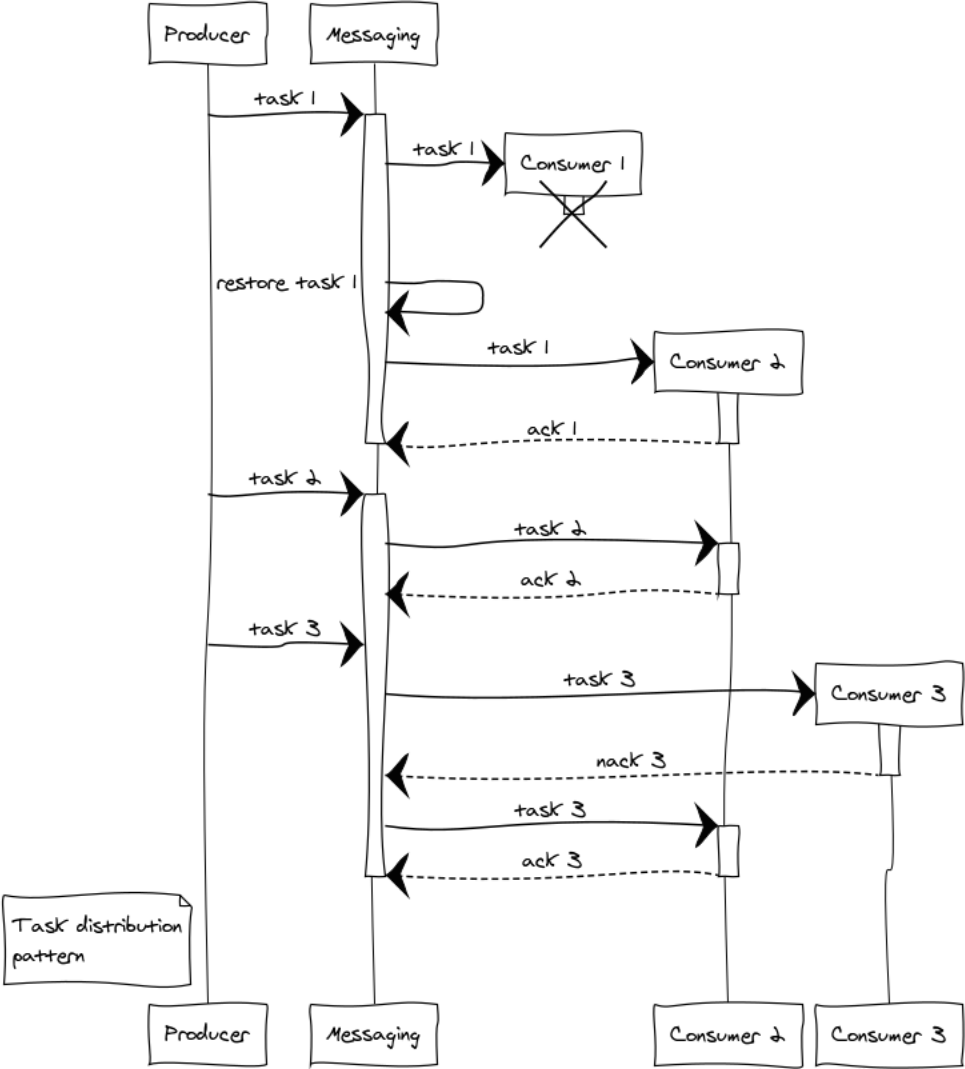
Angenommen, während der Verarbeitung von drei Aufgaben ist ein komplexer Fehler aufgetreten: Handler 1 stürzte nach dem Empfang der Aufgabe ab, bevor er mit dem Austauschpunkt kommunizieren konnte. In diesem Fall überträgt der Austauschpunkt nach Ablauf des Bestätigungszeitlimits den Job an einen anderen Handler. Handler 3 lehnte die Aufgabe aus irgendeinem Grund ab und sendete nack. Infolgedessen wurde die Aufgabe auch an einen anderen Handler übergeben, der sie erfolgreich abgeschlossen hat.
Vorläufiges Ergebnis
Wir haben die Grundbausteine verteilter Systeme auseinander genommen und ein grundlegendes Verständnis ihrer Anwendung in Erlang / Elixir erhalten.
Durch die Kombination grundlegender Muster können Sie komplexe Paradigmen zur Lösung neu auftretender Probleme erstellen.
Im letzten Teil des Zyklus werden wir die allgemeinen Fragen der Organisation von Diensten, des Routings und des Ausgleichs betrachten und auch über die praktische Seite der Skalierbarkeit und Fehlertoleranz von Systemen sprechen.
Das Ende des zweiten Teils.
Foto Marius Christensen
Illustrationen erstellt von websequencediagrams.com