Der dritte Artikel in der Reihe und ein kleiner Zweig aus der Hauptserie - dieses Mal werde ich Ihnen zeigen, wie die Spring-Integrationstestbibliothek funktioniert und wie sie funktioniert, was passiert, wenn Sie den Test ausführen und wie Sie die Anwendung und ihre Umgebung für den Test optimieren können.
Ich wurde durch einen Hixon10- Kommentar aufgefordert, diesen Artikel darüber zu schreiben, wie eine echte Basis wie Postgres in einem Integrationstest verwendet wird. Der Autor des Kommentars schlug vor, den praktischen All-Inclusive-Library- Embedded-Database-Spring-Test zu verwenden . Und ich habe bereits einen Absatz und ein Beispiel für die Verwendung im Code hinzugefügt, aber dann habe ich darüber nachgedacht. Natürlich ist es richtig und gut, eine vorgefertigte Bibliothek zu verwenden. Wenn Sie jedoch verstehen möchten, wie Tests für eine Spring-Anwendung geschrieben werden, ist es sinnvoller, zu zeigen, wie Sie dieselbe Funktionalität selbst implementieren. Erstens ist dies ein guter Grund, darüber zu sprechen, was sich unter der Haube des Frühlingstests befindet . Und zweitens glaube ich, dass Sie sich nicht auf Bibliotheken von Drittanbietern verlassen können. Wenn Sie nicht verstehen, wie sie im Inneren angeordnet sind, führt dies nur zur Stärkung des Mythos der "Magie" der Technologie.
Dieses Mal gibt es keine Benutzerfunktion, aber es gibt ein Problem, das gelöst werden muss. Ich möchte die reale Datenbank an einem zufälligen Port starten und die Anwendung automatisch mit dieser temporären Datenbank verbinden. Nach den Tests stoppe ich die Datenbank und lösche sie.
Zunächst, wie schon üblich, eine kleine Theorie. Personen, die mit den Konzepten bin, Kontext und Konfiguration nicht allzu vertraut sind, empfehle ich, das Wissen zu aktualisieren, beispielsweise in meinem Artikel Die Rückseite von Spring / Habr .
Federtest
Spring Test ist eine der im Spring Framework enthaltenen Bibliotheken. Alles, was im Dokumentationsabschnitt über Integrationstests beschrieben wird, ist genau das Richtige. Die vier Hauptaufgaben, die die Bibliothek löst, sind:
- Verwalten von Spring IoC-Containern und deren Zwischenspeicherung zwischen Tests
- Stellen Sie eine Abhängigkeitsinjektion für Testklassen bereit
- Bereitstellung eines für Integrationstests geeigneten Transaktionsmanagements
- Stellen Sie eine Reihe von Basisklassen bereit, damit der Entwickler Integrationstests schreiben kann
Ich empfehle dringend, die offizielle Dokumentation zu lesen, die viele nützliche und interessante Dinge enthält. Hier werde ich einen kurzen Druck geben und ein paar praktische Tipps geben, die nützlich sind, um sie im Auge zu behalten.
Lebenszyklus testen
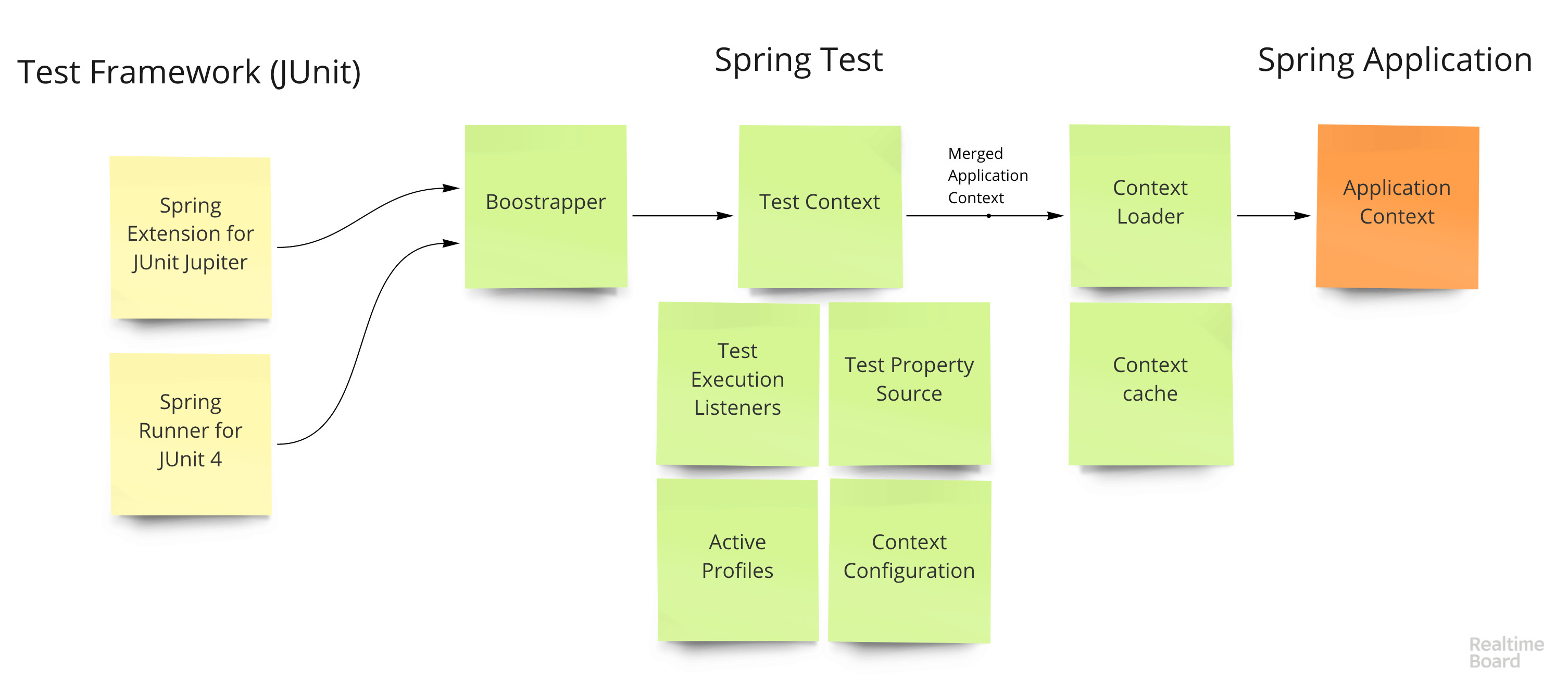
Der Lebenszyklus eines Tests sieht folgendermaßen aus:
- Die Erweiterung für das
SpringRunner ( SpringRunner für JUnit 4 und SpringExtension für JUnit 5) ruft Test Context Bootstrapper auf - Boostrapper erstellt
TestContext - die Hauptklasse, in der der aktuelle Status des Tests und der Anwendung gespeichert wird TestContext richtet verschiedene Hooks ein (z. B. das Starten von Transaktionen vor dem Test und das Rollback nach dem Test), fügt Abhängigkeiten in @Autowired (alle @Autowired Felder in @Autowired ) und erstellt Kontexte- Mit dem Context Loader wird ein Kontext erstellt. Er übernimmt die Grundkonfiguration der Anwendung und führt sie mit der Testkonfiguration zusammen (überlappende Eigenschaften, Profile, Bins, Initialisierer usw.).
- Der Kontext wird mithilfe eines zusammengesetzten Schlüssels zwischengespeichert, der die Anwendung vollständig beschreibt - eine Reihe von Bins, Eigenschaften usw.
- Testläufe
Die gesamte Drecksarbeit beim Verwalten der Tests wird in der Tat durch den spring-test erledigt, und der Spring Boot Test fügt wiederum mehrere @DataJpaTest hinzu, wie die bekannten nützlichen Dienstprogramme @DataJpaTest und @SpringBootTest , wie TestPropertyValues , um die Kontexteigenschaften dynamisch zu ändern. Sie können die Anwendung auch als echten Webserver oder als @MockBean (ohne Zugriff über HTTP) @MockBean können Systemkomponenten bequem mit @MockBean usw. @MockBean .
Kontext-Caching
Möglicherweise ist eines der sehr dunklen Themen beim Integrationstest, das viele Fragen und Missverständnisse aufwirft, das Kontext-Caching (siehe Absatz 5 oben) zwischen Tests und dessen Auswirkung auf die Geschwindigkeit von Tests. Ein häufiger Kommentar, den ich höre, ist, dass Integrationstests "langsam" sind und "die Anwendung für jeden Test ausführen". Sie laufen also - aber nicht für jeden Test. Jeder Kontext (d. H. Die Anwendungsinstanz) wird maximal wiederverwendet, d. H. Wenn 10 Tests dieselbe Anwendungskonfiguration verwenden, wird die Anwendung für alle 10 Tests einmal gestartet. Was bedeutet die "gleiche Konfiguration" der Anwendung? Für den Frühlingstest bedeutet dies, dass sich der Satz von Beans, Konfigurationsklassen, Profilen, Eigenschaften usw. nicht geändert hat. In der Praxis bedeutet dies, dass diese beiden Tests beispielsweise denselben Kontext verwenden:
@SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class FirstTest { } @SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class SecondTest { }
Die Anzahl der Kontexte im Cache ist auf 32 begrenzt. Gemäß dem LRSU-Prinzip wird einer von ihnen aus dem Cache gelöscht.
Was kann verhindern, dass der Frühlingstest den Kontext aus dem Cache wiederverwendet und einen neuen erstellt?
@DirtiesContext
Die einfachste Option ist, wenn der Test mit Anmerkungen markiert ist, der Kontext nicht zwischengespeichert wird. Dies kann nützlich sein, wenn der Test den Status der Anwendung ändert und Sie sie "zurücksetzen" möchten.
@ MockBean
Eine sehr nicht offensichtliche Option, ich habe sie sogar separat gerendert - @MockBean ersetzt die echte Bean im Kontext durch ein Modell, das über Mockito getestet werden kann (in den folgenden Artikeln werde ich zeigen, wie man es verwendet). Der entscheidende Punkt ist, dass diese Annotation den Satz von Beans in der Anwendung ändert und Spring Test zwingt, einen neuen Kontext zu erstellen. Wenn wir zum Beispiel das vorherige Beispiel nehmen, werden hier bereits zwei Kontexte erstellt:
@SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class FirstTest { } @SpringBootTest @ActiveProfiles("test") @TestPropertySource("foo=bar") class SecondTest { @MockBean CakeFinder cakeFinderMock; }
@ TestPropertySource
Jede Eigenschaftsänderung ändert automatisch den Cache-Schlüssel und ein neuer Kontext wird erstellt.
@ActiveProfiles
Das Ändern aktiver Profile wirkt sich auch auf den Cache aus.
@ContextConfiguration
Und natürlich schafft jede Konfigurationsänderung auch einen neuen Kontext.
Wir starten die Basis
Mit all diesem Wissen werden wir es jetzt versuchen abheben Verstehen, wie und wo Sie die Datenbank ausführen können. Hier gibt es keine richtige Antwort, es hängt von den Anforderungen ab, aber Sie können sich zwei Optionen vorstellen:
- Führen Sie vor allen Tests in der Klasse einmal aus.
- Führen Sie eine zufällige Instanz und eine separate Datenbank für jeden zwischengespeicherten Kontext aus (möglicherweise mehr als eine Klasse).
Abhängig von den Anforderungen können Sie eine beliebige Option auswählen. Wenn in meinem Fall Postgres relativ schnell startet und die zweite Option geeignet erscheint, ist die erste möglicherweise für etwas Schwierigeres geeignet.
Die erste Option ist nicht an Spring gebunden, sondern an ein Testframework. Sie können beispielsweise Ihre Erweiterung für JUnit 5 erstellen .
Wenn Sie das gesamte Wissen über die Testbibliothek, die Kontexte und das Caching zusammenstellen, läuft die Aufgabe auf Folgendes hinaus: Wenn Sie einen neuen Anwendungskontext erstellen, müssen Sie die Datenbank auf einem zufälligen Port ausführen und die Verbindungsdaten in den Kontext übertragen .
ApplicationContextInitializer Schnittstelle ist für die Ausführung von Aktionen mit dem Kontext verantwortlich, bevor sie im Frühjahr gestartet wird.
ApplicationContextInitializer
Die Schnittstelle verfügt nur über eine initialize , die ausgeführt wird, bevor der Kontext "gestartet" wird ( refresh bevor die refresh aufgerufen wird), und mit der Sie Änderungen am Kontext vornehmen können - Bins und Eigenschaften hinzufügen.
In meinem Fall sieht die Klasse folgendermaßen aus:
public class EmbeddedPostgresInitializer implements ApplicationContextInitializer<GenericApplicationContext> { @Override public void initialize(GenericApplicationContext applicationContext) { EmbeddedPostgres postgres = new EmbeddedPostgres(); try { String url = postgres.start(); TestPropertyValues values = TestPropertyValues.of( "spring.test.database.replace=none", "spring.datasource.url=" + url, "spring.datasource.driver-class-name=org.postgresql.Driver", "spring.jpa.hibernate.ddl-auto=create"); values.applyTo(applicationContext); applicationContext.registerBean(EmbeddedPostgres.class, () -> postgres, beanDefinition -> beanDefinition.setDestroyMethodName("stop")); } catch (IOException e) { throw new RuntimeException(e); } } }
Das erste, was hier passiert, ist, dass eingebettetes Postgres über die eingebettete Bibliothek yandex-qatools / postgresql gestartet wird. Anschließend wird eine Reihe von Eigenschaften erstellt - die JDBC-URL für die neu gestartete Basis, der Treibertyp und das Ruhezustandsverhalten für das Schema (automatisch erstellt). Eine nicht offensichtliche Sache ist nur spring.test.database.replace=none - dies ist es, was wir DataJpaTest mitteilen, dass wir nicht versuchen müssen, eine Verbindung zur eingebetteten Datenbank wie H2 herzustellen, und dass wir den DataSource-Bin nicht ersetzen müssen (dies funktioniert).
Ein weiterer wichtiger Punkt ist application.registerBean(…) . Im Allgemeinen kann diese Bohne natürlich nicht registriert werden - wenn niemand sie in der Anwendung verwendet, wird sie nicht besonders benötigt. Die Registrierung ist nur erforderlich, um die Zerstörungsmethode anzugeben, die Spring postgres.stop() wenn der Kontext zerstört wird. In meinem Fall ruft diese Methode postgres.stop() und stoppt die Datenbank.
Im Allgemeinen ist das alles, die Magie endete, wenn überhaupt. Jetzt werde ich diesen Initialisierer in einem Testkontext registrieren:
@DataJpaTest @ContextConfiguration(initializers = EmbeddedPostgresInitializer.class) ...
Oder Sie können sogar der Einfachheit halber Ihre eigenen Anmerkungen erstellen, da wir alle Anmerkungen lieben!
@Target(ElementType.TYPE) @Retention(RetentionPolicy.RUNTIME) @DataJpaTest @ContextConfiguration(initializers = EmbeddedPostgresInitializer.class) public @interface EmbeddedPostgresTest { }
Jetzt @EmbeddedPostgrestTest jeder von @EmbeddedPostgrestTest kommentierte Test die Datenbank an einem zufälligen Port und konfiguriert Spring mit einem zufälligen Namen so, dass eine Verbindung zu dieser Datenbank hergestellt und am Ende des Tests gestoppt wird.
@EmbeddedPostgresTest class JpaCakeFinderTestWithEmbeddedPostgres { ... }
Fazit
Ich wollte zeigen, dass es im Frühling keine mysteriöse Magie gibt, es gibt nur viele „intelligente“ und flexible interne Mechanismen, aber wenn man sie kennt, kann man die Tests und die Anwendung selbst vollständig kontrollieren. Im Allgemeinen motiviere ich in Kampfprojekten nicht jeden, seine eigenen Methoden und Klassen zum Einrichten der Integrationsumgebung für Tests zu schreiben. Wenn es eine vorgefertigte Lösung gibt, können Sie diese verwenden. Wenn die gesamte Methode aus 5 Codezeilen besteht, ist es wahrscheinlich überflüssig, die Abhängigkeit in das Projekt zu ziehen, insbesondere wenn die Implementierung nicht verstanden wird.
Links zu anderen Artikeln der Reihe