 Gepostet von Denis Tsyplakov , Solution Architect, DataArt
Gepostet von Denis Tsyplakov , Solution Architect, DataArtErklärung des Problems
Eines der Probleme beim Erstellen von Microservice-Architekturen und insbesondere beim Migrieren einer monolithischen Architektur zu Microservices sind häufig Transaktionen. Jeder Mikrodienst ist für seine eigene Gruppe von Funktionen verantwortlich, steuert möglicherweise die dieser Gruppe zugeordneten Daten und kann Benutzeranforderungen entweder autonom oder durch Senden von Anforderungen an andere Mikrodienste bedienen. All dies funktioniert einwandfrei, bis wir die Konsistenz der Daten sicherstellen müssen, die von verschiedenen Microservices gesteuert werden.
Zum Beispiel funktioniert unsere Anwendung in einem großen Online-Shop. Unter anderem haben wir drei separate, schwach miteinander verbundene Geschäftsbereiche:
- Lager - was, wo, wie und wie lange es gelagert wurde, wie viele Waren eines bestimmten Typs derzeit auf Lager sind usw.
- Versand von Waren - Verpackung, Versand, Sendungsverfolgung, Analyse von Beschwerden über die Verzögerung usw.
- Durchführung einer Zollberichterstattung über den Warenverkehr, wenn die Waren ins Ausland geschickt werden (tatsächlich weiß ich nicht, ob in diesem Fall etwas Besonderes erstellt werden muss, aber ich werde die staatlichen Dienste dennoch mit dem Prozess verbinden, um Drama hinzuzufügen).
Jeder dieser drei Bereiche enthält viele disjunkte Funktionen und kann als mehrere Mikrodienste dargestellt werden.
Es gibt ein Problem. Angenommen, eine Person hat ein Produkt gekauft, verpackt und per Kurier verschickt. Unter anderem müssen wir darauf hinweisen, dass sich eine Wareneinheit weniger im Lager befindet, um festzustellen, dass der Prozess der Warenlieferung begonnen hat, und wenn die Waren beispielsweise nach China geschickt werden, um die Papiere für den Zoll zu erledigen. Wenn die Anwendung in der zweiten oder dritten Phase des Prozesses abstürzt (z. B. ein Knoten abstürzt), werden unsere Daten in einen inkonsistenten Zustand versetzt, und nur wenige solcher Fehler können zu recht unangenehmen Problemen für das Unternehmen führen (z. B. ein Besuch von Zollbeamten).
In einer klassischen monolithischen Architektur dieser Art wird das Problem einfach und elegant durch Transaktionen in der Datenbank gelöst. Aber was ist, wenn wir Microservices verwenden? Selbst wenn wir von allen Diensten dieselbe Datenbank verwenden (was nicht sehr elegant ist, aber in unserem Fall möglich ist), stammt die Arbeit mit dieser Datenbank aus verschiedenen Prozessen, und wir können die Transaktion zwischen den Prozessen nicht verlängern.
Lösungen
Das Problem hat mehrere Lösungen:
- Seltsamerweise kann das Problem manchmal ignoriert werden. Wenn wir wissen, dass ein Fehler nicht mehr als einmal im Monat auftritt und die manuelle Beseitigung der Folgen für das Unternehmen akzeptables Geld kostet, können Sie das Problem nicht berücksichtigen, egal wie hässlich es aussehen mag. Ich weiß nicht, ob es möglich ist, die Forderungen des Zolldienstes zu ignorieren, aber es kann davon ausgegangen werden, dass dies auch unter bestimmten Umständen möglich ist.
- Die Entschädigung (hier geht es nicht um eine finanzielle Entschädigung des Zolls, zum Beispiel, wenn Sie eine Geldstrafe gezahlt haben) ist eine Gruppe verschiedener Arten von Schritten, die die Verarbeitungssequenz komplizieren, es Ihnen jedoch ermöglichen, einen fehlgeschlagenen Prozess zu erkennen und zu verarbeiten. Zum Beispiel schreiben wir vor Beginn des Vorgangs an einen speziellen Dienst, dass wir den Versandvorgang starten, und am Ende markieren wir, dass alles gut geendet hat. Anschließend überprüfen wir regelmäßig, ob ausstehende Vorgänge vorhanden sind, und versuchen, die Daten in einen konsistenten Zustand zu versetzen, wenn alle drei Datenbanken untersucht werden. Dies ist eine vollständig funktionierende Methode, die jedoch die Verarbeitungslogik erheblich verkompliziert, und dies für jede Operation ist ziemlich schmerzhaft.
- Genau genommen ist die XA + -Spezifikation, mit der Sie Transaktionen erstellen können, die relativ zu Anwendungen verteilt sind, ein sehr schwerer Mechanismus, den nur wenige Benutzer mögen und, was noch wichtiger ist, nur wenige Benutzer konfigurieren können. Darüber hinaus ist es mit leichten Mikrodiensten ideologisch schwach kompatibel.
- Im Prinzip ist eine Transaktion ein Sonderfall des Konsensproblems, und zahlreiche verteilte Konsenssysteme können verwendet werden, um das Problem zu lösen (grob gesagt, alles, was mit den Schlüsselwörtern paxos, raft, zookeeper usw., consul googelt). In der praktischen Anwendung für umfangreiche und verzweigte Daten der Lageraktivität sieht dies jedoch noch komplizierter aus als bei zweiphasigen Transaktionen.
- Warteschlangen und eventuelle Konsistenz (Konsistenz auf lange Sicht) - Wir teilen die Aufgabe in drei asynchrone Aufgaben auf, verarbeiten die Daten nacheinander, übergeben sie zwischen den Diensten von der Warteschlange an die Warteschlange und verwenden den Übermittlungsbestätigungsmechanismus. In diesem Fall ist der Code nicht sehr kompliziert, aber es gibt einige Punkte zu beachten:
- Die Warteschlange garantiert die Zustellung "einmal oder mehrmals", dh bei erneuter Zustellung derselben Nachricht muss der Dienst diese Situation korrekt behandeln und darf die Waren nicht zweimal versenden. Dies kann beispielsweise über die eindeutige UUID der Bestellung erfolgen.
- Die Daten zu einem bestimmten Zeitpunkt sind leicht inkonsistent. Das heißt, die Ware verschwindet zuerst aus dem Lager und erst dann wird mit einer leichten Verzögerung eine Bestellung für den Versand erstellt. Später werden die Zolldaten verarbeitet. In unserem Beispiel ist dies völlig normal und verursacht keine Probleme für das Unternehmen. Es gibt jedoch Fälle, in denen ein solches Datenverhalten sehr unangenehm sein kann.
- Wenn der allererste Dienst infolgedessen einige Daten an den Benutzer zurückgeben muss, kann die Reihenfolge der Aufrufe, die die Daten letztendlich an den Browser des Benutzers liefern, nicht trivial sein. Das Hauptproblem besteht darin, dass der Browser Anforderungen synchron sendet und normalerweise eine synchrone Antwort erwartet. Wenn Sie eine asynchrone Anforderungsverarbeitung durchführen, müssen Sie eine asynchrone Übermittlung der Antwort an den Browser erstellen. Klassischerweise erfolgt dies entweder über Web-Sockets oder durch regelmäßige Anfragen nach neuen Ereignissen vom Browser an den Server. Es gibt Mechanismen wie beispielsweise SocksJS, die einige Aspekte des Aufbaus dieser Verbindung vereinfachen, aber es wird immer noch zusätzliche Komplexität geben.
In den meisten Fällen ist die letztere Option am akzeptabelsten. Die Verarbeitungsanforderung wird zwar nicht sehr kompliziert, obwohl sie mehrmals länger funktioniert. In der Regel ist dies für diese Art von Vorgang jedoch akzeptabel. Es erfordert auch eine etwas komplexere Datenorganisation, um wiederholte Anforderungen auszuschließen, aber auch daran ist nichts besonders Kompliziertes.
Schematisch kann eine der Optionen für die Verarbeitung von Transaktionen mithilfe von Warteschlangen und eventueller Konsistenz folgendermaßen aussehen:
- Der Benutzer hat einen Kauf getätigt, eine Nachricht darüber wird an die Warteschlange gesendet (z. B. ein RabbitMQ-Cluster oder, wenn wir in der Google Cloud Platform arbeiten - Pub / Sub). Die Warteschlange ist persistent, garantiert die Zustellung ein- oder mehrmals und ist transaktional. Wenn der Dienst, der die Nachricht verarbeitet, plötzlich unterbrochen wird, geht die Nachricht nicht verloren, sondern wird erneut an eine neue Instanz des Dienstes übermittelt.
- Die Nachricht kommt beim Service an, der die Waren im Lager als versandbereit kennzeichnet und die Nachricht „Die Waren sind versandbereit“ an die Warteschlange sendet.
- Im nächsten Schritt erhält der für den Versand zuständige Dienst eine Nachricht über die Versandbereitschaft, erstellt eine Versandaufgabe und sendet dann die Nachricht „Der Versand der Ware ist geplant“.
- Der nächste Dienst, der eine Nachricht erhalten hat, dass der Versand geplant ist, startet den Papierkram für den Zoll.
Darüber hinaus wird jede vom Dienst empfangene Nachricht auf Eindeutigkeit überprüft, und wenn eine Nachricht mit einer solchen UUID bereits verarbeitet wurde, wird sie ignoriert.
Hier befinden sich die Datenbankbasis (en) zu jedem Zeitpunkt in einem leicht inkonsistenten Zustand, dh die Waren im Lager sind bereits als im Lieferprozess befindlich markiert, aber die Lieferaufgabe selbst ist noch nicht vorhanden. Sie wird in ein oder zwei Sekunden angezeigt. Gleichzeitig haben wir 99,999% (tatsächlich entspricht diese Zahl dem Zuverlässigkeitsgrad des Warteschlangendienstes), dass die sendende Aufgabe angezeigt wird. Für die meisten Unternehmen ist dies akzeptabel.
Worum geht es dann in dem Artikel?
In dem Artikel möchte ich über einen anderen Weg sprechen, um das Transaktionsproblem in Microservice-Anwendungen zu lösen. Trotz der Tatsache, dass Microservices am besten funktionieren, wenn jeder Dienst über eine eigene Datenbank verfügt, passen alle Daten für kleine und mittlere Systeme in der Regel problemlos in eine moderne relationale Datenbank. Dies gilt für fast jedes interne Unternehmenssystem. Das heißt, wir müssen häufig keine Daten zwischen verschiedenen physischen Maschinen austauschen. Wir können Daten von verschiedenen Mikrodiensten in nicht verwandten Gruppen von Tabellen derselben Datenbank speichern. Dies ist besonders praktisch, wenn Sie eine alte monolithische Anwendung in Dienste aufteilen und den Code bereits aufgeteilt haben, die Daten jedoch weiterhin in derselben Datenbank gespeichert sind. Das Problem der Transaktionsaufteilung bleibt jedoch weiterhin bestehen - die Transaktion ist fest mit der Netzwerkverbindung und dementsprechend mit dem Prozess verbunden, der diese Verbindung geöffnet hat, und wir haben separate Prozesse. Wie man ist
Oben habe ich verschiedene gängige Methoden zur Lösung des Problems beschrieben. Darüber hinaus möchte ich für einen speziellen Fall eine andere Möglichkeit anbieten, wenn sich alle Daten in derselben Datenbank befinden. Ich
empfehle nicht, diese Methode
in diesem Projekt zu implementieren , aber es ist neugierig genug
, sie im Artikel zu präsentieren. Nun, plötzlich wird es in einem besonderen Fall nützlich sein.
Sein Wesen ist sehr einfach. Eine Transaktion ist mit einer Netzwerkverbindung verknüpft, und die Datenbank weiß nicht genau, wer an diesem Ende der offenen Netzwerkverbindung sitzt. Es ist ihr egal, Hauptsache, dass die richtigen Befehle am Socket ankommen. Es ist klar, dass ein Socket normalerweise ausschließlich zu einem Prozess auf der Clientseite gehört, aber ich sehe mindestens drei Möglichkeiten, um dies zu umgehen.
1. Ändern Sie den Datenbankcode
Auf der Ebene des Datenbankcodes für Datenbanken, deren Code wir ändern können, indem wir unsere eigene Datenbankassemblierung erstellen, implementieren wir den Mechanismus zum Übertragen von Transaktionen zwischen Verbindungen. Wie es aus Sicht des Kunden funktionieren kann:
- Wir starten die Transaktion, nehmen einige Änderungen vor, es ist Zeit, die Transaktion zum nächsten Service zu übertragen.
- Wir weisen die DB an, uns die UUID der Transaktion zu geben und N Sekunden zu warten. Wenn während dieser Zeit keine andere Verbindung mit dieser UUID hergestellt wird, setzen Sie die Transaktion zurück. Wenn dies der Fall ist, übertragen Sie alle mit der Transaktion verknüpften Datenstrukturen auf die neue Verbindung und arbeiten Sie weiter damit.
- Wir übergeben die UUID an den nächsten Dienst (d. H. An einen anderen Prozess, möglicherweise an eine andere VM).
- Öffnen Sie darin eine Verbindung und geben Sie den DB-Befehl ein - setzen Sie die Transaktion mit der angegebenen UUID fort.
- Wir arbeiten weiterhin mit der Datenbank als Teil einer Transaktion, die von einem anderen Prozess gestartet wurde.
Diese Methode ist am leichtesten zu verwenden, erfordert jedoch eine Änderung des Datenbankcodes. Anwendungsprogrammierer tun dies normalerweise nicht. Sie erfordern viele spezielle Fähigkeiten. Höchstwahrscheinlich wird es notwendig sein, Daten zwischen den Datenbankprozessen und Datenbanken zu übertragen, deren Code wir im Großen und Ganzen sicher ändern können - One - PostgreSQL. Darüber hinaus funktioniert dies nur für nicht verwaltete Server. In RDS oder Cloud SQL ist dies nicht der Fall.
Schematisch sieht es so aus:

2. Manipulation von Steckdosen
Das zweite, was mir in den Sinn kommt, ist die subtile Manipulation von Datenbankverbindungen durch Sockets. Wir können einen "Reverse-Socket-Proxy" erstellen, der die von mehreren Clients kommenden Befehle an einen bestimmten Port in einem Befehlsstrom an die Datenbank weiterleitet.
Tatsächlich ist diese Anwendung pgBouncer sehr ähnlich, nur dass sie zusätzlich zu ihrer Standardfunktionalität einige Manipulationen mit dem Bytestream von Clients vornimmt und auf Befehl einen Client anstelle eines anderen ersetzen kann.
Ich mag diese Methode überhaupt nicht, für ihre Implementierung ist es notwendig, die zwischen dem Server und den Clients zirkulierenden Binärpakete zu bereinigen. Und es erfordert immer noch viel Systemprogrammierung. Ich habe es nur der Vollständigkeit halber mitgebracht.
3. Gateway JDBC
Wir können einen Gateway-JDBC-Treiber erstellen - wir verwenden den Standard-JDBC-Treiber für eine bestimmte Datenbank, sei es PostgreSQL. Wir verpacken die Klasse und erstellen HTTP-Schnittstellen zu allen externen Methoden (nicht HTTP, aber der Unterschied ist gering). Als nächstes erstellen wir einen weiteren JDBC-Treiber - eine Fassade, die alle Methodenaufrufe an das JDBC-Gateway umleitet. Das heißt, wir teilen den vorhandenen Treiber in zwei Hälften und verbinden diese Hälften über das Netzwerk. Wir erhalten folgendes Komponentendiagramm:
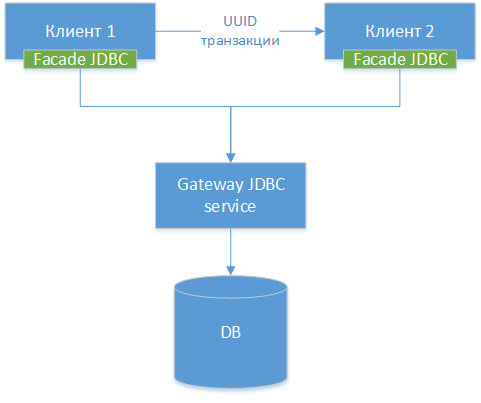 NB!: Wie wir sehen können, sind alle drei Optionen ähnlich. Der einzige Unterschied besteht darin, auf welcher Ebene wir die Verbindung übertragen und welche Tools wir dafür verwenden.
NB!: Wie wir sehen können, sind alle drei Optionen ähnlich. Der einzige Unterschied besteht darin, auf welcher Ebene wir die Verbindung übertragen und welche Tools wir dafür verwenden.
Danach bringen wir unserem Treiber bei, im Wesentlichen denselben Trick mit der in Methode 1 beschriebenen UUID-Transaktion auszuführen.
Im Java-Anwendungscode könnte die Verwendung dieser Methode folgendermaßen aussehen.
Service A - Beginn der Transaktion
Unten finden Sie den Code für einen Dienst, der eine Transaktion startet, Änderungen an der Datenbank vornimmt und diese an einen anderen Dienst weiterleitet, um sie abzuschließen. Im Code verwenden wir die direkte Arbeit mit JDBC-Klassen. Natürlich tut dies 2019 niemand, aber der Einfachheit halber wird der Code vereinfacht.
Service B - Transaktionsabschluss
Interaktion mit anderen Komponenten und Frameworks
Berücksichtigen Sie die möglichen Nebenwirkungen einer solchen architektonischen Lösung.
Verbindungspool
Da wir in Wirklichkeit einen echten Verbindungspool innerhalb des JDBC-Gateways haben, ist es besser, die Verbindungspools in Diensten zu deaktivieren, da sie eine Verbindung innerhalb des Dienstes erfassen und halten, die von einem anderen Dienst verwendet werden könnte.
Nachdem die UUID empfangen und auf die Übertragung zu einem anderen Prozess gewartet wurde, wird die Verbindung im Wesentlichen funktionsunfähig. Aus Sicht des Frontend-JDBC wird sie automatisch geschlossen. Aus Sicht des Gateway-JDBC muss sie gehalten werden, ohne dass jemand anderem als wem etwas gegeben wird wird mit der gewünschten UUID geliefert.
Mit anderen Worten, die doppelte Verwaltung des Verbindungspools im Gateway-JDBC und in jedem der Dienste kann zu subtilen, unangenehmen Fehlern führen.
Jpa
Bei JPA sehe ich zwei mögliche Probleme:
- Transaktionsmanagement. Beim Festschreiben eines JPA glaubt die Engine möglicherweise, dass alle Daten gespeichert wurden, obwohl sie nicht gespeichert wurden. Die manuelle Transaktionsverwaltung und flush () vor der Übertragung der Transaktion sollten das Problem höchstwahrscheinlich lösen.
- Der Cache der zweiten Ebene funktioniert wahrscheinlich nicht richtig, aber in verteilten Systemen ist seine Verwendung in jedem Fall eingeschränkt.
Frühlingstransaktionen
Der Transaktionsverwaltungsmechanismus von Spring kann möglicherweise nicht aktiviert werden, und Sie müssen sie manuell verwalten. Ich bin mir fast sicher, dass es erweitert werden kann - zum Beispiel um einen benutzerdefinierten Bereich zu schreiben -, aber um sicher zu sein, müssen wir untersuchen, wie die Spring Transactions-Erweiterung dort angeordnet ist, aber ich habe dort noch nicht nachgesehen.
Vorteile und Nachteile
Vorteile
- Praktisch erfordert keine Änderung des vorhandenen monolithischen Codes beim Sägen.
- Sie können komplexe serverübergreifende Transaktionen praktisch ohne Codekomplexität schreiben.
- Ermöglicht die dienstübergreifende Ablaufverfolgung der Transaktionsausführung.
- Die Lösung ist sehr flexibel. Sie können klassische Transaktionen verwenden, bei denen keine Verteilung erforderlich ist, und die Transaktion nur für Vorgänge freigeben, bei denen eine dienstübergreifende Interaktion erforderlich ist.
- Das Projektteam muss neue Technologien nicht zwangsweise beherrschen. Neue Technologien sind natürlich gut, aber die Aufgabe - es ist zwingend und dringend (bis gestern!), 20 Entwicklern das Konzept des Aufbaus reaktiver Systeme beizubringen - kann sehr trivial sein. Es gibt jedoch keine Garantie dafür, dass alle 20 Personen die Schulung pünktlich abschließen.
Nachteile
- Nicht skalierbar und im Gegensatz zu einer Lösung in der Warteschlange auf Datenbankebene nicht modular. Sie haben noch eine Datenbank, in der alle Abfragen und die gesamte Last zusammenlaufen. In diesem Sinne ist die Lösung eine Sackgasse: Wenn Sie später die Last erhöhen oder die Lösung gemäß den Daten modular gestalten möchten, müssen Sie alles wiederholen.
- Sie müssen beim Übertragen einer Transaktion zwischen Prozessen, insbesondere in in Frameworks geschriebenen Prozessen, sehr vorsichtig sein. Sitzungen haben ihre eigenen Einstellungen, und bei verschiedenen Frameworks kann eine plötzliche Änderung der Verbindung mit der Datenbank zu Fehlfunktionen führen. Siehe beispielsweise Sitzungseinstellungen und Transaktionen für PostgreSQL.
- Als ich die Idee im Chat unseres lokalen Architekten über DataArt erzählte, fragten mich meine Kollegen als erstes, ob ich trinke (nein, nicht trinken!). Aber ich gebe zu, dass die Idee, sagen wir, nicht die am weitesten verbreitete ist, und wenn Sie sie in Ihrem Projekt implementieren, wird sie für die anderen Teilnehmer sehr ungewöhnlich aussehen.
- Benötigt einen benutzerdefinierten JDBC-Treiber. Das Schreiben braucht Zeit, Sie müssen es debuggen, nach Fehlern suchen, einschließlich solcher, die durch Netzwerkkommunikationsfehler usw. verursacht wurden.
Warnung
Ich warne Sie noch einmal:
Versuchen Sie
nicht, diesen Trick zu Hause in diesem Projekt
zu wiederholen , es sei denn, Sie haben eine sehr klare Erklärung, warum Sie ihn brauchen, und überzeugende Beweise dafür, dass es überhaupt keinen anderen Weg gibt.
Alles ab dem 1. April!