Der Artikel wird im Auftrag von John Akhaltsev , Jiga , veröffentlicht
Tinkoff.ru ist heute nicht nur eine Bank, sondern ein IT-Unternehmen. Es bietet nicht nur Bankdienstleistungen an, sondern baut auch ein Ökosystem um sie herum auf.
Wir bei Tinkoff.ru gehen eine Partnerschaft mit verschiedenen Diensten ein, um die Qualität des Kundendienstes zu verbessern und zu besseren Diensten zu werden. Zum Beispiel haben wir Lasttests und Leistungsanalysen für einen dieser Dienste durchgeführt, die dazu beigetragen haben, Engpässe im System zu finden - einschließlich transparenter großer Seiten in der Betriebssystemkonfiguration.
Wenn Sie wissen möchten, wie eine Analyse der Systemleistung durchgeführt wird und was daraus bei uns geworden ist, dann sind Sie bei cat willkommen.
Problembeschreibung
Im Moment lautet die Servicearchitektur:
- Nginx-Webserver für die Verarbeitung von http-Verbindungen
- PHP-fpm für die PHP-Prozesssteuerung
- Redis zum Zwischenspeichern
- PostgreSQL zur Datenspeicherung
- One-Stop-Shopping-Lösung
Das Hauptproblem, das wir beim nächsten Verkauf unter hoher Last fanden, war die hohe Auslastung der CPU, während die Prozessorzeit im Kernelmodus (Systemzeit) zunahm und länger war als die Zeit im Benutzermodus (Benutzerzeit).
- Benutzerzeit - Die Zeit, die der Prozessor für die Aufgaben des Benutzers benötigt. Dies ist die Hauptsache, für die Sie beim Kauf eines Prozessors bezahlen.
- Systemzeit - Die Zeit, die das System für Paging, das Ändern von Kontexten, das Starten geplanter Aufgaben und andere Systemaufgaben benötigt.
Bestimmen der primären Eigenschaften des Systems
Zunächst haben wir einen Lastkreis mit nahezu produktiven Ressourcen gesammelt und ein Lastprofil erstellt, das einer normalen Last an einem typischen Tag entspricht.
Gatling Version 3 wurde als Schälwerkzeug ausgewählt, und das Schälen selbst wurde innerhalb des lokalen Netzwerks über Gitlab-Runner durchgeführt. Der Standort von Agenten und Zielen im selben lokalen Netzwerk ist auf geringere Netzwerkkosten zurückzuführen. Daher konzentrieren wir uns auf die Überprüfung der Ausführung des Codes selbst und nicht auf die Leistung der Infrastruktur, in der das System bereitgestellt wird.
Bei der Bestimmung der primären Eigenschaften des Systems ist ein Szenario mit einer linear ansteigenden Last mit einer http-Konfiguration geeignet:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
Zu diesem Zeitpunkt haben wir ein Skript implementiert, um die Hauptseite zu öffnen und alle Ressourcen herunterzuladen

Die Ergebnisse dieses Tests zeigten eine maximale Leistung von 1500 U / min. Eine weitere Erhöhung der Lastintensität führte zu einer Verschlechterung des Systems, die mit einer Erhöhung der Softirq-Zeit verbunden war.


Softirq ist ein verzögerter Interrupt-Mechanismus und wird in der Datei kernel / softirq.s beschrieben. Gleichzeitig hämmern sie die Warteschlange mit Anweisungen an den Prozessor und verhindern so, dass sie im Benutzermodus nützliche Berechnungen durchführen können. Interrupt-Handler können auch die zusätzliche Arbeit mit Netzwerkpaketen in Betriebssystem-Threads verzögern (Systemzeit). Kurz über die Arbeit des Netzwerkstapels und Optimierungen finden Sie in einem separaten Artikel .
Der Verdacht auf das Hauptproblem wurde nicht bestätigt, da das Produkt eine viel längere Systemzeit mit weniger Netzwerkaktivität aufwies.
Benutzerskripte
Der nächste Schritt bestand darin, benutzerdefinierte Skripte zu entwickeln und mehr hinzuzufügen, als nur eine Seite mit Bildern zu öffnen. Das Profil enthält umfangreiche Vorgänge, bei denen der Site-Code und die Datenbank vollständig einbezogen wurden, und keinen Webserver, der statische Ressourcen bereitstellt.
Der Test mit stabiler Last wurde mit einer geringeren Intensität als dem Maximum gestartet. Der Konfiguration wurde ein Umleitungsübergang hinzugefügt:
val httpConfig: HttpProtocolBuilder = http .baseUrl("https://test.host.ru") .inferHtmlResources()
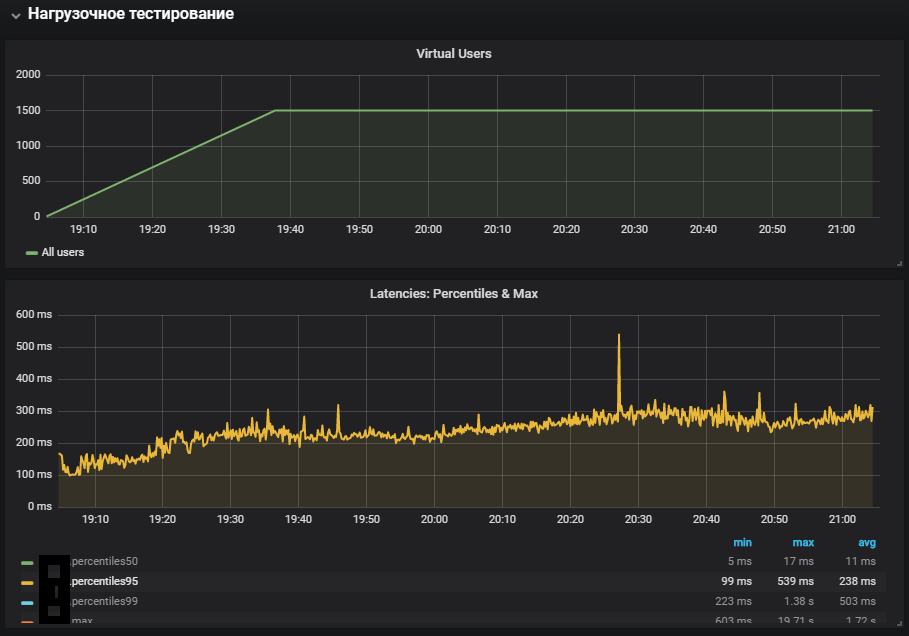

Die vollständigste Verwendung von Systemen zeigte eine Zunahme der Systemzeitmetrik sowie deren Wachstum während des Stabilitätstests. Das Problem mit der Produktionsumgebung wurde reproduziert.
Vernetzung mit Redis
Bei der Analyse von Problemen ist es sehr wichtig, alle Komponenten des Systems zu überwachen, um zu verstehen, wie es funktioniert und welche Auswirkungen die zugeführte Last auf das System hat.
Mit dem Aufkommen der Redis-Überwachung wurde es möglich, nicht die allgemeinen Metriken des Systems, sondern seine spezifischen Komponenten zu betrachten. Das Szenario für Stresstests wurde ebenfalls geändert, was zusammen mit der zusätzlichen Überwachung dazu beitrug, die Lokalisierung des Problems anzugehen.

Bei der Überwachung sah Redis ein ähnliches Bild mit der CPU-Auslastung, oder besser gesagt, die Systemzeit ist erheblich länger als die Benutzerzeit, während die Hauptauslastung der CPU in der SET-Operation lag, dh der Zuweisung von RAM zum Speichern des Werts.

Um den Effekt der Netzwerkinteraktion mit Redis zu eliminieren, wurde beschlossen, die Hypothese zu testen und Redis auf einen UNIX-Socket anstelle eines TCP-Sockets umzustellen. Dies geschah direkt in dem Framework, über das php-fpm eine Verbindung zur Datenbank herstellt. In der Datei /yiisoft/yii/framework/caching/CRedisCache.php haben wir die Zeile von host: port durch den Hardcode redis.sock ersetzt. Weitere Informationen zur Socket-Leistung finden Sie im Artikel .
protected function connect() { $this->_socket=@stream_socket_client(
Dies hatte leider keine großen Auswirkungen. Die CPU-Auslastung hat sich etwas stabilisiert, aber unser Problem nicht gelöst - der größte Teil der CPU-Auslastung erfolgte im Kernel-Modus.
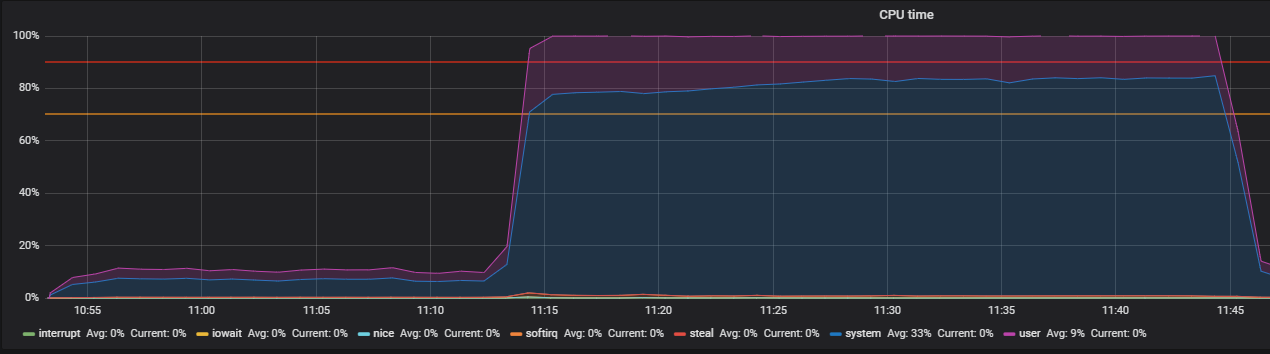
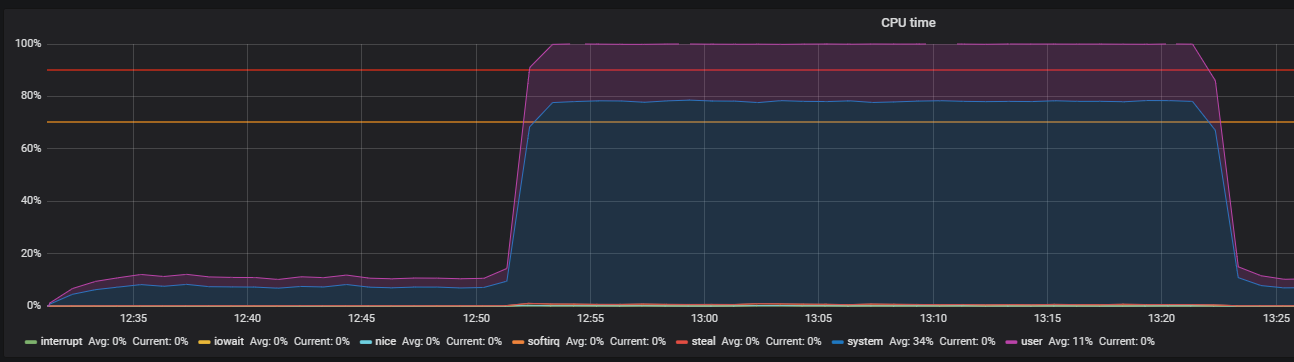
Benchmark mit Stress und Identifizierung von THP-Problemen
Das Stress-Dienstprogramm half bei der Lokalisierung des Problems - ein einfacher Workload-Generator für POSIX-Systeme, mit dem einzelne Systemkomponenten wie CPU, Speicher und E / A geladen werden können.
Das Testen soll auf der Hardware- und Betriebssystemversion erfolgen:
Ubuntu 18.04.1 LTS
12 Intel® Xeon® CPU
Das Dienstprogramm wird mit dem folgenden Befehl installiert:
sudo apt-get install stress
Wir sehen uns an, wie die CPU unter Last ausgelastet ist, und führen einen Test durch, bei dem Mitarbeiter für die Berechnung von Quadratwurzeln mit einer Dauer von 300 Sekunden erstellt werden:
-c, --cpu N spawn N workers spinning on sqrt() > stress --cpu 12 --timeout 300s stress: info: [39881] dispatching hogs: 12 cpu, 0 io, 0 vm, 0 hdd
Die Grafik zeigt die vollständige Auslastung im Benutzermodus. Dies bedeutet, dass alle Prozessorkerne geladen und nützliche Berechnungen durchgeführt werden, keine Systemdienstaufrufe.
Der nächste Schritt besteht darin, Ressourcen zu nutzen, wenn Sie intensiv mit io arbeiten. Führen Sie den Test 300 Sekunden lang aus, und erstellen Sie 12 Worker, die sync () ausführen. Der Synchronisierungsbefehl schreibt im Speicher gepufferte Daten auf die Festplatte. Der Kernel speichert Daten im Speicher, um häufige (normalerweise langsame) Lese- und Schreibvorgänge auf der Festplatte zu vermeiden. Der Befehl sync () stellt sicher, dass alles, was im Speicher gespeichert ist, auf die Festplatte geschrieben wird.
-i, --io N spawn N workers spinning on sync() > stress --io 12 --timeout 300s stress: info: [39907] dispatching hogs: 0 cpu, 0 io, 0 vm, 12 hdd
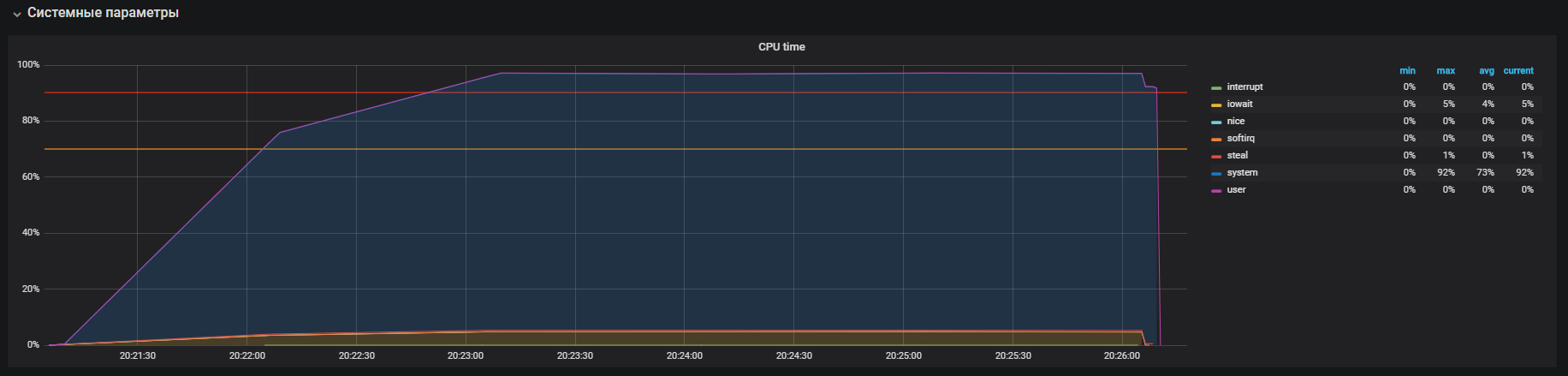

Wir sehen, dass der Prozessor hauptsächlich mit der Verarbeitung von Aufrufen im Kernel-Modus und ein wenig in iowait beschäftigt ist. Sie können auch> 35.000 Ops-Schreibvorgänge auf die Festplatte sehen. Dieses Verhalten ähnelt einem Problem mit hoher Systemzeit, dessen Ursachen wir analysieren. Aber hier gibt es einige Unterschiede: Dies sind iowait und iops sind größer als auf der Produktivschaltung, dies passt nicht zu unserem Fall.
Es ist Zeit, Ihr Gedächtnis zu überprüfen. Wir starten 20 Mitarbeiter, die mit dem folgenden Befehl 300 Sekunden lang Speicher zuweisen und freigeben:
-m, --vm N spawn N workers spinning on malloc()/free() > stress -m 20 --timeout 300s stress: info: [39954] dispatching hogs: 0 cpu, 0 io, 20 vm, 0 hdd
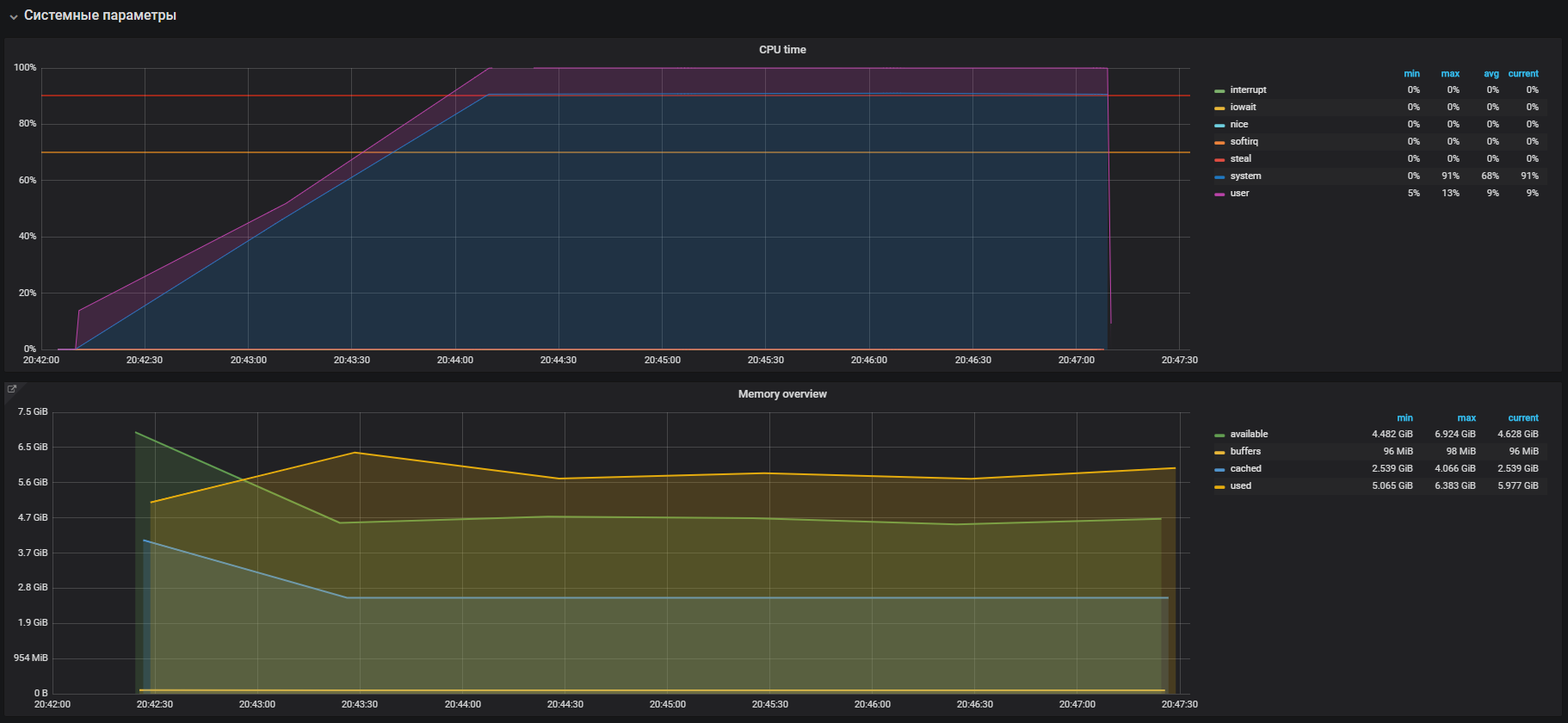
Sofort sehen wir die hohe Auslastung der CPU im Systemmodus und ein wenig im Benutzermodus sowie die Verwendung von RAM von mehr als 2 GB.
Dieser Fall ist dem Problem mit dem Produkt sehr ähnlich, was durch die große Verwendung von Speicher bei Lasttests bestätigt wird. Daher muss das Problem in der Speicheroperation gesucht werden. Die Zuweisung und Freigabe von Speicher erfolgt über Malloc- bzw. Free-Aufrufe, die schließlich von den Kernel-Systemaufrufen verarbeitet werden. Dies bedeutet, dass sie in der CPU-Auslastung als Systemzeit angezeigt werden.
In den meisten modernen Betriebssystemen wird der virtuelle Speicher mithilfe von Paging organisiert. Bei diesem Ansatz wird der gesamte Speicherbereich in Seiten mit fester Länge unterteilt, z. B. 4096 Byte (Standard für viele Plattformen). Wenn beispielsweise 2 GB Speicher zugewiesen werden, muss der Speichermanager ausgeführt werden mehr als 500.000 Seiten. Bei diesem Ansatz entsteht ein hoher Overhead für die Verwaltung und für große Seiten. Es wurden Technologien für transparente große Seiten entwickelt, um diese zu reduzieren. Mit ihrer Hilfe können Sie die Seitengröße beispielsweise auf bis zu 2 MB erhöhen, wodurch die Anzahl der Seiten im Speicherheap erheblich reduziert wird. Der Unterschied in der Technologie besteht nur darin, dass wir für große Seiten die Umgebung explizit konfigurieren und dem Programm die Arbeit mit ihnen beibringen müssen, während transparente große Seiten für Programme „transparent“ funktionieren.
THP und Problemlösung
Wenn Sie Informationen zu transparenten riesigen Seiten googeln, sehen Sie in den Suchergebnissen viele Seiten mit den Fragen "So deaktivieren Sie THP".
Wie sich herausstellte, wurde diese „coole“ Funktion von der Red Hat Corporation in den Linux-Kernel eingeführt. Das Wesentliche an dieser Funktion ist, dass Anwendungen transparent mit dem Speicher arbeiten können, als ob sie mit echten Huge Page arbeiten würden. Laut den Benchmarks beschleunigt THP die abstrakte Anwendung um 10%. Sie können mehr Details in der Präsentation sehen, aber in Wirklichkeit ist alles anders. In einigen Fällen führt THP zu einem unangemessenen Anstieg des CPU-Verbrauchs in Systemen. Weitere Informationen finden Sie in den Empfehlungen von Oracle.
Wir gehen und überprüfen unseren Parameter. Wie sich herausstellte, ist THP standardmäßig aktiviert. Wir deaktivieren es mit dem folgenden Befehl:
echo never > /sys/kernel/mm/transparent_hugepage/enabled
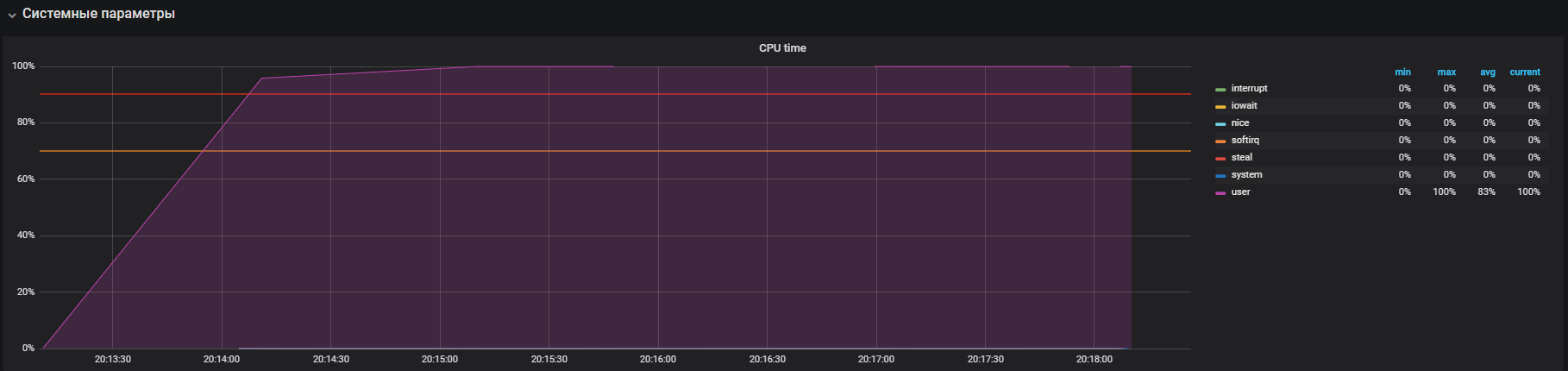
Wir bestätigen mit dem Test vor dem Ausschalten von THP und danach auf dem Lastprofil:
setUp( MainScenario.inject( rampUsers(150) during (200 seconds)), Peak.inject( nothingFor(20 minutes), rampUsers(5000) during (30 minutes)) ).protocols(httpConfig)

Wir haben dieses Bild gesehen, bevor wir THP ausgeschaltet haben

Nach dem Ausschalten von THP können wir eine bereits verringerte Ressourcennutzung beobachten.
Das Hauptproblem wurde lokalisiert. Der Grund war im Betriebssystem standardmäßig aktiviert
Mechanismus der transparenten großen Seiten. Nach dem Deaktivieren der THP-Option verringerte sich die CPU-Auslastung im Systemmodus um mindestens das Zweifache, wodurch Ressourcen für den Benutzermodus freigesetzt wurden. Bei der Analyse des Hauptproblems wurden auch „Engpässe“ bei der Interaktion mit dem Netzwerkstapel von OS und Redis festgestellt, was der Grund für eine eingehendere Untersuchung ist. Aber das ist eine ganz andere Geschichte.
Fazit
Abschließend möchte ich einige Tipps für die erfolgreiche Suche nach Leistungsproblemen geben:
- Bevor Sie die Systemleistung untersuchen, sollten Sie deren Architektur und Komponenteninteraktionen sorgfältig verstehen.
- Konfigurieren Sie die Überwachung für alle Systemkomponenten und verfolgen Sie sie. Wenn nicht genügend Standardmetriken vorhanden sind, gehen Sie tiefer und erweitern Sie sie.
- Lesen Sie die Handbücher zu den verwendeten Systemen.
- Überprüfen Sie die Standardeinstellungen in den Konfigurationsdateien des Betriebssystems und der Systemkomponenten.