Ankündigung
Kolleginnen und Kollegen, ich plane, mitten im Sommer eine weitere Artikelserie zum Design von Warteschlangensystemen zu veröffentlichen: „VTrade Experiment“ - ein Versuch, ein Framework für Handelssysteme zu schreiben. Der Zyklus analysiert die Theorie und Praxis des Aufbaus einer Börse, einer Auktion und eines Geschäfts. Am Ende des Artikels schlage ich vor, für die Themen zu stimmen, die Sie am meisten interessieren.

Dies ist der letzte Artikel im verteilten reaktiven Anwendungszyklus von Erlang / Elixir. Im ersten Artikel finden Sie die theoretischen Grundlagen der reaktiven Architektur. Der zweite Artikel veranschaulicht die grundlegenden Muster und Mechanismen zum Aufbau solcher Systeme.
Heute werden wir Fragen zur Entwicklung der Codebasis und der Projekte im Allgemeinen aufwerfen.
Serviceorganisation
Im wirklichen Leben müssen Sie bei der Entwicklung eines Dienstes häufig mehrere Interaktionsmuster in einem Controller kombinieren. Beispielsweise muss der Benutzerdienst, der die Aufgaben zum Verwalten von Benutzerprofilen für ein Projekt löst, auf Anforderungsanforderungen antworten und Profilaktualisierungen über pub-sub melden. Dieser Fall ist ganz einfach: Hinter Messaging befindet sich ein Controller, der die Logik des Dienstes implementiert und Aktualisierungen veröffentlicht.
Die Situation ist kompliziert, wenn wir einen fehlertoleranten verteilten Dienst implementieren müssen. Angenommen, die Benutzeranforderungen haben sich geändert:
- Jetzt sollte der Dienst Anforderungen auf 5 Knoten des Clusters verarbeiten.
- in der Lage sein, Hintergrundverarbeitungsaufgaben auszuführen,
- und in der Lage sein, Ihre Profilaktualisierungs-Abonnementlisten dynamisch zu verwalten.
Hinweis: Das Problem der konsistenten Speicherung und Replikation von Daten wird nicht berücksichtigt. Angenommen, diese Probleme wurden früher behoben und das System verfügt bereits über eine zuverlässige und skalierbare Speicherschicht, und die Handler verfügen über Mechanismen zur Interaktion mit ihr.
Die formale Beschreibung des Benutzerdienstes ist komplizierter geworden. Aus Sicht eines Programmierers ist die Verwendung von Messaging-Änderungen minimal. Um die erste Anforderung zu erfüllen, müssen wir den Ausgleich am erforderlichen Austauschpunkt anpassen.
Die Anforderung, Hintergrundaufgaben zu erledigen, entsteht häufig. Bei Benutzern kann dies das Überprüfen von Benutzerdokumenten, das Verarbeiten heruntergeladener Multimedia-Inhalte oder das Synchronisieren von Daten mit sozialen Diensten sein. Netzwerke. Diese Aufgaben müssen irgendwie innerhalb des Clusters verteilt sein und den Fortschritt steuern. Daher haben wir zwei Lösungen: Verwenden Sie entweder die Aufgabenverteilungsvorlage aus dem vorherigen Artikel oder schreiben Sie, falls dies nicht passt, einen benutzerdefinierten Aufgabenplaner, der für die Verwaltung des Pools von Handlern erforderlich ist.
Punkt 3 erfordert eine Erweiterung der Pub-Sub-Vorlage. Und für die Implementierung müssen wir nach dem Erstellen des Pub-Sub-Austauschpunkts zusätzlich den Controller dieses Punkts als Teil unseres Service starten. Daher scheinen wir die Logik der Verarbeitung von Abonnements und der Abmeldung von der Messaging-Schicht in die Benutzerimplementierung zu übernehmen.
Als Ergebnis zeigte die Zerlegung der Aufgabe, dass wir zur Erfüllung der Anforderungen 5 Dienstinstanzen auf verschiedenen Knoten ausführen und eine zusätzliche Entität erstellen müssen - den Pub-Sub-Controller, der für das Abonnieren verantwortlich ist.
Um 5 Handler auszuführen, müssen Sie den Servicecode nicht ändern. Die einzige zusätzliche Aktion besteht darin, am Austauschpunkt Ausgleichsregeln einzurichten, über die wir etwas später sprechen werden.
Es gab auch zusätzliche Komplexität: Der Pub-Sub-Controller und der benutzerdefinierte Taskplaner sollten in einer einzigen Kopie arbeiten. Auch hier sollte der Nachrichtendienst als grundlegender Mechanismus einen Mechanismus zur Auswahl eines Leiters bereitstellen.
Wahl des Führers
In verteilten Systemen ist die Wahl eines Leiters der Prozess der Ernennung des einzigen Prozesses, der für die Planung der verteilten Verarbeitung einer Last verantwortlich ist.
In Systemen, die nicht zur Zentralisierung neigen, werden universelle Konsensalgorithmen wie Paxos oder Floß verwendet.
Da Messaging ein Makler und ein zentrales Element ist, kennt er alle Service-Controller - Kandidaten für die Führung. Messaging kann einen Leiter ohne Abstimmung ernennen.
Nach dem Starten und #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers} Verbindung zum Austauschpunkt erhalten alle Dienste die Systemmeldung #'$leader'{exchange = ?EXCHANGE, pid = LeaderPid, servers = Servers} . Wenn LeaderPid mit der pid aktuellen Prozesses LeaderPid , wird sie als Leader zugewiesen, und die Servers enthält alle Knoten und ihre Parameter.
Wenn ein neuer Clusterknoten angezeigt wird und die Verbindung getrennt wird, erhalten alle Service-Controller die #'$slave_up'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} und #'$slave_down'{exchange = ?EXCHANGE, pid = SlavePid, options = SlaveOpts} .
Somit sind alle Komponenten über alle Änderungen informiert, und im Cluster ist zu jedem Zeitpunkt ein Leiter garantiert.
Vermittler
Für die Implementierung komplexer verteilter Verarbeitungsprozesse sowie für die Optimierung einer vorhandenen Architektur ist es zweckmäßig, Vermittler einzusetzen.
Um den Code der Dienste nicht zu ändern und beispielsweise die Aufgaben der zusätzlichen Verarbeitung, Weiterleitung oder Protokollierung von Nachrichten zu lösen, können Sie vor dem Dienst einen Proxy-Prozessor aktivieren, der alle zusätzlichen Arbeiten ausführt.
Ein klassisches Beispiel für die Pub-Sub-Optimierung ist eine verteilte Anwendung mit einem Business-Kernel, der Aktualisierungsereignisse generiert, z. B. eine Änderung des Marktpreises, und einer Zugriffsebene - N-Server, die Websocket-APIs für Webclients bereitstellen.
Wenn Sie sich für "Stirn" entscheiden, ist der Kundenservice wie folgt:
- Der Client stellt Verbindungen zur Plattform her. Auf der Serverseite wird der Prozess, der diese Verbindung bedient, gestartet, indem der Datenverkehr beendet wird.
- Im Rahmen des Serviceprozesses erfolgt die Autorisierung und das Abonnement von Updates. Der Prozess ruft die Abonnementmethode für Themen auf.
- Nachdem das Ereignis im Kernel generiert wurde, wird es an die Prozesse übermittelt, die die Verbindungen bedienen.
Stellen Sie sich vor, wir haben 50.000 Abonnenten für das Thema "Nachrichten". Abonnenten sind gleichmäßig auf 5 Server verteilt. Infolgedessen wird jedes Update, das am Austauschpunkt eintrifft, 50.000 Mal repliziert: 10.000 Mal auf jeden Server, je nach Anzahl der Abonnenten. Nicht ganz ein effektives Schema, oder?
Um die Situation zu verbessern, führen wir einen gleichnamigen Proxy mit dem Austauschpunkt ein. Der globale Namensregistrator sollte in der Lage sein, den nächstgelegenen Prozess namentlich zurückzugeben. Dies ist wichtig.
Führen Sie diesen Proxy auf den Servern der Zugriffsschicht aus, und alle unsere Prozesse, die die Websocket-API bedienen, abonnieren ihn und nicht den ursprünglichen Pub-Sub-Austauschpunkt im Kernel. Der Proxy abonniert den Kernel nur im Fall eines eindeutigen Abonnements und repliziert die eingehende Nachricht an alle seine Abonnenten.
Infolgedessen werden 5 Nachrichten anstelle von 50.000 Nachrichten zwischen dem Kernel und den Zugriffsservern gesendet.
Routing und Balancing
Req-resp
In der aktuellen Messaging-Implementierung gibt es 7 Strategien zur Verteilung von Abfragen:
default . Die Anfrage wird an alle Controller weitergeleitet.round-robin . Durchläuft und verteilt Anforderungen zyklisch zwischen Controllern.consensus . Die Controller, die den Dienst bedienen, sind in Leiter und Anhänger unterteilt. Anfragen werden nur an den Leiter weitergeleitet.consensus & round-robin . Es gibt einen Leiter in der Gruppe, aber Anfragen werden unter allen Mitgliedern verteilt.sticky . Die Hash-Funktion wird berechnet und einem bestimmten Handler zugewiesen. Nachfolgende Anforderungen mit dieser Signatur gehen an denselben Handler.sticky-fun . Bei der Initialisierung des Austauschpunktes wird zusätzlich die Hash-Berechnungsfunktion für den sticky Balancing übertragen.fun . Es ist ähnlich wie Sticky-Fun, nur können Sie es zusätzlich umleiten, ablehnen oder vorverarbeiten.
Die Verteilungsstrategie wird festgelegt, wenn der Austauschpunkt initialisiert wird.
Zusätzlich zum Ausgleich von Messaging können Sie Entitäten mit Tags versehen. Betrachten Sie die Arten von Tags im System:
- Verbindungs-Tag. Ermöglicht es Ihnen zu verstehen, durch welche Verbindung die Ereignisse kamen. Wird verwendet, wenn der Controller-Prozess eine Verbindung zum gleichen Vermittlungspunkt herstellt, jedoch mit unterschiedlichen Routing-Schlüsseln.
- Service-Tag. Ermöglicht einem einzelnen Dienst das Gruppieren von Prozessoren und das Erweitern der Routing- und Ausgleichsfunktionen. Für das Anforderungsmuster ist das Routing linear. Wir senden eine Anfrage an die Vermittlungsstelle und leiten sie dann an den Service weiter. Wenn wir die Handler jedoch in logische Gruppen aufteilen müssen, erfolgt die Aufteilung mithilfe von Tags. Wenn Sie ein Tag angeben, wird die Anforderung an eine bestimmte Gruppe von Controllern weitergeleitet.
- Tag anfordern. Ermöglicht die Unterscheidung von Antworten. Da unser System asynchron ist, müssen Sie beim Verarbeiten einer Anfrage einen RequestTag angeben können, um Serviceantworten verarbeiten zu können. Daraus können wir die Antwort verstehen, auf die die Anfrage zu uns kam.
Pub sub
Für Pub-Sub sind die Dinge etwas einfacher. Wir haben einen Austauschpunkt, für den Nachrichten veröffentlicht werden. Der Austauschpunkt verteilt Nachrichten zwischen Teilnehmern, die die benötigten Routing-Schlüssel abonnieren (wir können sagen, dass dies analog zu diesen ist).
Skalierbarkeit und Ausfallsicherheit
Die Skalierbarkeit des Gesamtsystems hängt vom Grad der Skalierbarkeit der Schichten und Komponenten des Systems ab:
- Services werden skaliert, indem dem Cluster zusätzliche Knoten mit Handlern für diesen Service hinzugefügt werden. Während des Testbetriebs können Sie die optimale Ausgleichsrichtlinie auswählen.
- Der Messaging-Dienst selbst innerhalb eines einzelnen Clusters wird im Allgemeinen entweder durch Verschieben speziell geladener Austauschpunkte auf einzelne Clusterknoten oder durch Hinzufügen von Proxy-Prozessen zu speziell geladenen Zonen des Clusters vergrößert.
- Die Skalierbarkeit des gesamten Systems als Merkmal hängt von der Flexibilität der Architektur und der Möglichkeit ab, einzelne Cluster zu einer gemeinsamen logischen Einheit zu kombinieren.
Die Einfachheit und Geschwindigkeit der Skalierung bestimmt häufig den Erfolg eines Projekts. Das Messaging in seiner aktuellen Leistung wächst mit der Anwendung. Selbst wenn uns eine Gruppe von 50-60 Autos fehlt, können wir auf den Verband zurückgreifen. Leider geht das Thema Föderation über den Rahmen dieses Artikels hinaus.
Reservierung
In der Analyse des Lastausgleichs haben wir bereits die Reservierung von Service-Controllern erörtert. Nachrichten sollten jedoch auch reserviert werden. Im Falle eines Knoten- oder Maschinenabsturzes sollte das Messaging automatisch und so bald wie möglich wiederhergestellt werden.
In meinen Projekten verwende ich zusätzliche Knoten, die im Falle eines Sturzes die Last aufnehmen. Erlang verfügt über eine Standardimplementierung im verteilten Modus für OTP-Anwendungen. Der verteilte Modus führt tatsächlich eine Wiederherstellung im Falle eines Fehlers durch, indem die abgestürzte Anwendung auf einem anderen zuvor gestarteten Knoten gestartet wird. Der Prozess ist transparent. Nach einem Fehler wird die Anwendung automatisch auf den Failover-Knoten verschoben. Weitere Informationen zu dieser Funktionalität finden Sie hier .
Leistung
Versuchen wir, die Leistung von rabbitmq und unseren benutzerdefinierten Nachrichten zumindest annähernd zu vergleichen.
Ich habe offizielle Rabbitmq-Testergebnisse vom Openstack-Team gefunden.
In Abschnitt 6.14.1.2.1.2.2. Das Originaldokument enthält das Ergebnis von RPC CAST:
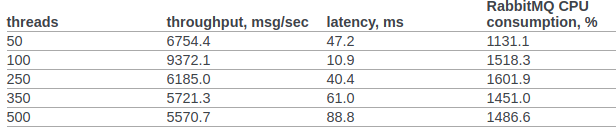
Bisher werden keine zusätzlichen Einstellungen für den Betriebssystemkernel oder die erlang-VM vorgenommen. Testbedingungen:
- erl wählt: + A1 + sbtu.
- Der Test innerhalb eines einzelnen erlang-Knotens läuft auf einem Laptop mit einem alten i7 in mobiler Leistung.
- Clustertests finden auf Servern mit einem 10G-Netzwerk statt.
- Der Code funktioniert in Docker-Containern. Netzwerk im NAT-Modus.
Testcode:
req_resp_bench(_) -> W = perftest:comprehensive(10000, fun() -> messaging:request(?EXCHANGE, default, ping, self()), receive #'$msg'{message = pong} -> ok after 5000 -> throw(timeout) end end ), true = lists:any(fun(E) -> E >= 30000 end, W), ok.
Szenario 1: Der Test wird auf einem Laptop mit einer alten mobilen i7-Ausführung ausgeführt. Test, Messaging und Service werden auf einem Knoten in einem Docker-Container ausgeführt:
Sequential 10000 cycles in ~0 seconds (26987 cycles/s) Sequential 20000 cycles in ~1 seconds (26915 cycles/s) Sequential 100000 cycles in ~4 seconds (26957 cycles/s) Parallel 2 100000 cycles in ~2 seconds (44240 cycles/s) Parallel 4 100000 cycles in ~2 seconds (53459 cycles/s) Parallel 10 100000 cycles in ~2 seconds (52283 cycles/s) Parallel 100 100000 cycles in ~3 seconds (49317 cycles/s)
Szenario 2 : 3 Knoten, die auf verschiedenen Computern unter Docker (NAT) ausgeführt werden.
Sequential 10000 cycles in ~1 seconds (8684 cycles/s) Sequential 20000 cycles in ~2 seconds (8424 cycles/s) Sequential 100000 cycles in ~12 seconds (8655 cycles/s) Parallel 2 100000 cycles in ~7 seconds (15160 cycles/s) Parallel 4 100000 cycles in ~5 seconds (19133 cycles/s) Parallel 10 100000 cycles in ~4 seconds (24399 cycles/s) Parallel 100 100000 cycles in ~3 seconds (34517 cycles/s)
In allen Fällen überschritt die CPU-Auslastung 250% nicht
Zusammenfassung
Ich hoffe, dieser Zyklus sieht nicht wie eine Bewusstseinsdeponie aus, und meine Erfahrung wird sowohl Forschern verteilter Systeme als auch Praktikern, die am Anfang des Aufbaus verteilter Architekturen für ihre Geschäftssysteme stehen und Erlang / Elixir mit Interesse betrachten, aber Zweifel haben, echte Vorteile bringen ist es das wert ...
Foto von @chuttersnap