Einige Unternehmen, einschließlich unserer Kunden, entwickeln das Produkt über ein Affiliate-Netzwerk. Beispielsweise sind große Online-Shops in einen Lieferservice integriert - Sie bestellen Waren und erhalten bald eine Sendungsverfolgungsnummer für das Paket. Ein weiteres Beispiel: Zusammen mit einem Flugticket kaufen Sie eine Versicherung oder ein Aeroexpress-Ticket.
Hierzu wird eine API verwendet, die über die Gateway-API an Partner ausgegeben werden muss. Wir haben dieses Problem gelöst. Dieser Artikel enthält Details.
Gegeben: Ökosystem- und API-Portal mit einer Schnittstelle, über die Benutzer registriert werden, Informationen erhalten usw. Wir müssen eine bequeme und zuverlässige Gateway-API erstellen. Dabei mussten wir bereitstellen
- Registrierung
- API-Verbindungssteuerung
- Überwachen, wie Benutzer das Endsystem verwenden
- Bilanzierung von Geschäftsindikatoren.
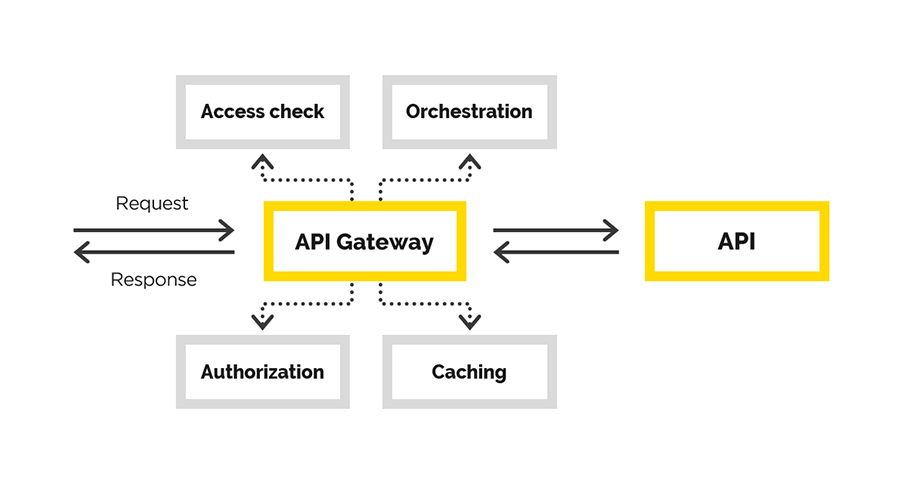
In diesem Artikel werden wir über unsere Erfahrungen beim Erstellen der Gateway-API sprechen, bei der wir die folgenden Aufgaben gelöst haben:
- Benutzerauthentifizierung
- Benutzerberechtigung
- Änderung der ursprünglichen Anfrage,
- Proxy anfordern
- Nachbearbeitung der Antwort.
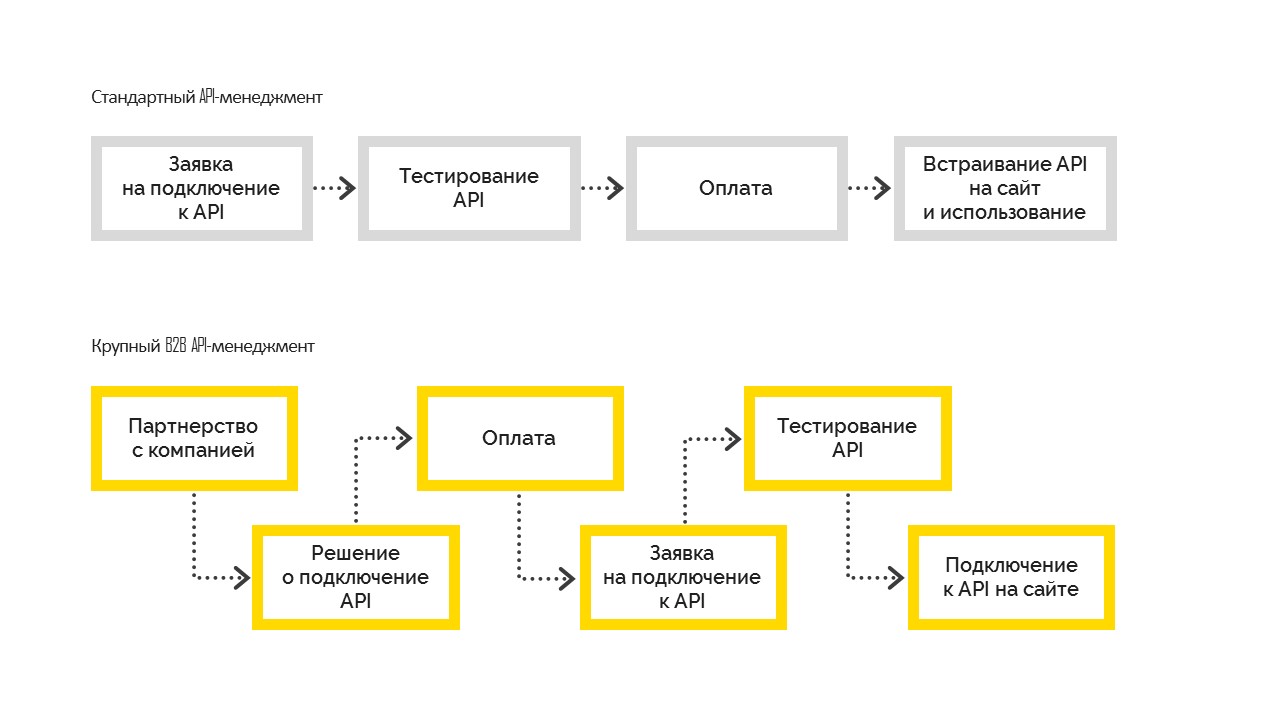
Es gibt zwei Arten der API-Verwaltung:
1. Standard, der wie folgt funktioniert. Vor dem Verbinden testet der Benutzer die Möglichkeiten, bezahlt und bettet dann auf seiner Site ein. Am häufigsten wird es in kleinen und mittleren Unternehmen eingesetzt.
2. Ein großes B2B-API-Management wird, wenn das Unternehmen zum ersten Mal eine Geschäftsentscheidung über die Verbindung trifft, zu einem Partnerunternehmen mit einer vertraglichen Verpflichtung und stellt dann eine Verbindung zur API her. Und nachdem alle Formalitäten erledigt sind, erhält das Unternehmen Testzugriff, besteht die Tests und geht in den Verkauf. Dies ist jedoch nicht möglich, ohne dass das Management die Entscheidung getroffen hat, eine Verbindung herzustellen.
Unsere Entscheidung
In diesem Teil werden wir uns mit dem Erstellen der Gateway-API befassen.
Endbenutzer des erstellten Gateways zur API sind die Partner unserer Kunden. Für jeden von ihnen haben wir bereits die notwendigen Verträge. Wir müssen nur die Funktionalität erweitern und den gewährten Zugriff auf das Gateway beachten. Dementsprechend ist ein gesteuerter Verbindungs- und Steuerungsprozess erforderlich.
Natürlich könnte man eine vorgefertigte Lösung zur Lösung der API-Verwaltungsaufgabe und insbesondere zur Erstellung des API-Gateways verwenden. Dies kann beispielsweise die
Azure-API-Verwaltung sein . Es passte nicht zu uns, weil wir in unserem Fall bereits ein API-Portal und ein riesiges Ökosystem darauf aufgebaut hatten. Alle Benutzer sind bereits registriert, sie haben bereits verstanden, wo und wie sie die notwendigen Informationen erhalten können. Die notwendigen Schnittstellen waren bereits im API-Portal vorhanden, wir brauchten nur das API-Gateway. Eigentlich haben wir angefangen, es zu entwickeln.
Was wir als Gateway-API bezeichnen, ist eine Art Proxy. Hier hatten wir wieder die Wahl - Sie können Ihren Proxy schreiben oder etwas Fertiges auswählen. In diesem Fall gingen wir den zweiten Weg und entschieden uns für das Nginx + Lua-Bundle. Warum? Wir brauchten eine zuverlässige, getestete Software, die die Skalierung unterstützt. Nach der Implementierung wollten wir die Richtigkeit der Geschäftslogik und die Richtigkeit des Proxys nicht überprüfen.
Jeder Webserver verfügt über eine Pipeline zur Anforderungsverarbeitung. Im Fall von Nginx sieht es so aus:

(Diagramm von
GitHub Lua Nginx )
Unser Ziel war es, uns in diese Pipeline zu integrieren, wo wir die ursprüngliche Anfrage ändern können.
Wir möchten einen transparenten Proxy erstellen, damit die Anforderung funktionsfähig bleibt. Wir kontrollieren nur den Zugriff auf die endgültige API, wir helfen der Anfrage, darauf zuzugreifen. Falls die Anfrage falsch war, sollte die endgültige API den Fehler anzeigen, aber nicht wir. Der einzige Grund, warum wir die Anfrage ablehnen können, ist der fehlende Zugriff auf den Client.
Für Nginx gibt es bereits eine
Erweiterung für
Lua . Lua ist eine Skriptsprache, sehr leicht und leicht zu erlernen. Daher haben wir die notwendige Logik mit Lua implementiert.
Die Nginx-Konfiguration (Analogie zur Route der Anwendung), in der alle Arbeiten ausgeführt werden, ist verständlich. Bemerkenswert ist hier die letzte Direktive - post_action.
location /middleware { more_clear_input_headers Accept-Encoding; lua_need_request_body on; rewrite_by_lua_file 'middleware/rewrite.lua'; access_by_lua_file 'middleware/access.lua'; proxy_pass https://someurl.com; body_filter_by_lua_file 'middleware/body_filter.lua'; post_action /process_session; }
Überlegen Sie, was in dieser Konfiguration passiert:
more_clear_input_headers - löscht den Wert der nach der Direktive angegebenen Header.
lua_need_request_body - steuert, ob der ursprüngliche Anforderungshauptteil gelesen werden soll, bevor die Anweisungen rewrite / access / access_by_lua ausgeführt werden oder nicht. Standardmäßig liest nginx den Clientanforderungstext nicht. Wenn Sie darauf zugreifen müssen, sollte diese Anweisung aktiviert sein.
rewrite_by_lua_file - Der Pfad zu den Skripten, der die Logik zum Ändern der Anforderung beschreibt
access_by_lua_file - Der Pfad zum Skript, der die Logik beschreibt, die den Zugriff auf die Ressource überprüft.
proxy_pass - URL, an die die Anforderung weitergeleitet wird.
body_filter_by_lua_file - Der Pfad zum Skript, der die Logik zum Filtern der Anforderung vor der Rückkehr zum Client beschreibt.
Und schließlich ist
post_action eine offiziell undokumentierte Direktive, mit der andere Aktionen ausgeführt werden können, nachdem die Antwort an den Client
gesendet wurde .
Als nächstes werden wir beschreiben, wie wir unsere Probleme gelöst haben.
Autorisierung / Authentifizierung und Anforderungsänderung
LoginWir haben die Autorisierung und Authentifizierung mithilfe von Zertifikatzugriffen erstellt. Es gibt ein Stammzertifikat. Jeder neue Kunde des Kunden generiert sein persönliches Zertifikat, mit dem er auf die API zugreifen kann. Dieses Zertifikat wird im Abschnitt Nginx-Einstellungsserver konfiguriert.
ssl on; ssl_certificate /usr/local/openresty/nginx/ssl/cert.pem; ssl_certificate_key /usr/local/openresty/nginx/ssl/cert.pem; ssl_client_certificate /usr/local/openresty/nginx/ssl/ca.crt; ssl_verify_client on;
ÄnderungEs kann sich eine faire Frage stellen: Was tun mit einem zertifizierten Kunden, wenn wir ihn plötzlich vom System trennen möchten? Stellen Sie Zertifikate nicht für alle anderen Kunden erneut aus.
Also haben wir uns reibungslos und der nächsten Aufgabe genähert - der Änderung der ursprünglichen Anfrage. Die ursprüngliche Clientanforderung gilt im Allgemeinen nicht für das endgültige System. Eine der Aufgaben besteht darin, die fehlenden Teile zur Anforderung hinzuzufügen, um sie gültig zu machen. Der Punkt ist, dass die fehlenden Daten für jeden Client unterschiedlich sind. Wir wissen, dass der Kunde mit einem Zertifikat zu uns kommt, von dem wir einen Fingerabdruck nehmen und die erforderlichen Kundendaten aus der Datenbank extrahieren können.
Wenn Sie den Client irgendwann von unserem Service trennen müssen, verschwinden seine Daten aus der Datenbank und er kann nichts mehr tun.
Arbeiten Sie mit Kundendaten
Wir mussten eine hohe Verfügbarkeit der Lösung sicherstellen, insbesondere wie wir Kundendaten erhalten. Die Schwierigkeit besteht darin, dass die Quelle dieser Daten ein Dienst eines Drittanbieters ist, der keine ununterbrochene und relativ hohe Geschwindigkeit garantiert.
Daher mussten wir eine hohe Verfügbarkeit der Kundendaten sicherstellen. Als Werkzeug haben wir uns für
Hazelcast entschieden, das uns
Folgendes bietet:
- schneller Zugriff auf Daten
- die Fähigkeit, einen Cluster aus mehreren Knoten mit Daten zu organisieren, die auf verschiedenen Knoten repliziert wurden.
Wir haben uns für die einfachste Cache-Bereitstellungsstrategie entschieden:
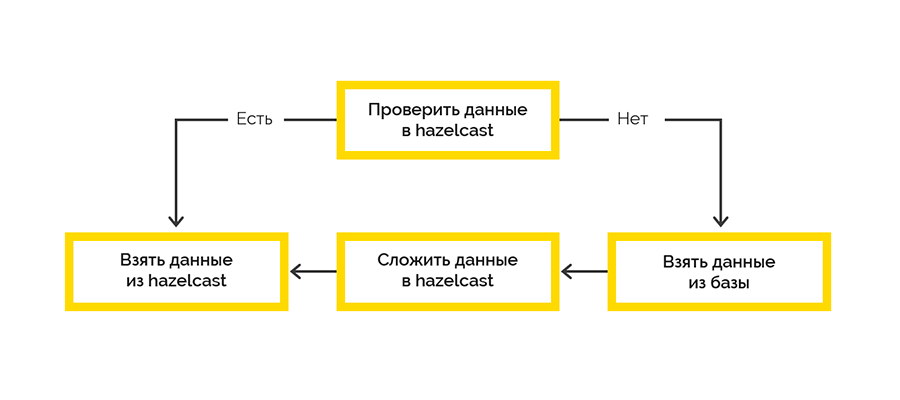
Die Arbeit mit dem endgültigen System erfolgt im Rahmen der Sitzungen, und die maximale Anzahl ist begrenzt. Wenn der Client die Sitzung nicht geschlossen hat, müssen wir dies tun.
Offene Sitzungsdaten stammen vom Zielsystem und werden zunächst auf der Lua-Seite verarbeitet. Wir haben uns für Hazelcast entschieden, um diese Daten mit einem .NET-Writer zu speichern. Dann überprüfen wir in einigen Abständen das Recht auf offene Sitzungen und schließen das Foul.
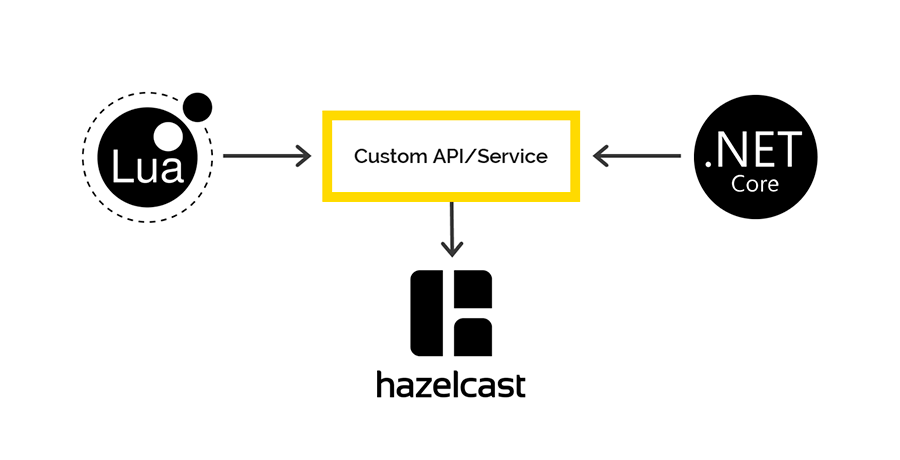
Zugriff auf Hazelcast von Lua und .NET
Auf Lua gibt es keine Clients, die mit Hazelcast arbeiten könnten, aber Hazelcast verfügt über eine REST-API, für die wir uns entschieden haben. Für .NET gibt es einen
Client, über den wir auf der .NET-Seite auf Hazelcast-Daten zugreifen möchten. Aber da war es.

Beim Speichern von Daten über REST und Abrufen über den .NET-Client werden verschiedene Serializer / Deserializer verwendet. Daher ist es unmöglich, Daten über REST zu übertragen, sondern über den .NET-Client und umgekehrt.
Wenn Sie interessiert sind, werden wir in einem separaten Artikel mehr über dieses Problem sprechen. Spoiler - auf der Shemka.
Protokollierung und Überwachung
Unser Unternehmensstandard für die Protokollierung über .NET ist Serilog. Alle Protokolle landen in Elasticsearch und wir analysieren sie über Kibana. Ich wollte in diesem Fall etwas Ähnliches machen. Der einzige
Kunde , der mit Elastic an Lua gearbeitet hat, der bei der ersten Anforderung als pleite befunden wurde. Und wir haben Fluentd verwendet.
Fluentd ist eine Open Source-Lösung zur Bereitstellung einer einzelnen Anwendungsprotokollierungsschicht. Ermöglicht das Sammeln von Protokollen aus verschiedenen Ebenen der Anwendung und deren anschließende Übersetzung in eine einzige Quelle.
Die Gateway-API funktioniert in K8S. Daher haben wir beschlossen, den Container mit fluentd demselben Subtyp hinzuzufügen, um Protokolle in den vorhandenen offenen TCP-Port fluentd zu schreiben.
Wir haben auch untersucht, wie flüssig sich verhalten würde, wenn er keine Verbindung zu Elasticsearch hätte. Zwei Tage lang wurden kontinuierlich Anfragen an das Gateway gesendet, Protokolle an fluentd gesendet, aber IP Elastic wurde von fluentd ausgeschlossen. Nach dem erneuten Verbinden hat fluentd absolut alle Protokolle in Elastic perfekt übertroffen.
Fazit
Der gewählte Implementierungsansatz ermöglichte es uns, in nur 2,5 Monaten ein wirklich funktionierendes Produkt für die Kampfumgebung bereitzustellen.
Wenn Sie jemals solche Dinge tun, empfehlen wir Ihnen, zunächst klar zu verstehen, welches Problem Sie lösen und welche der Ressourcen Sie bereits haben. Beachten Sie die Komplexität der Integration in vorhandene API-Managementsysteme.
Verstehen Sie selbst, was genau Sie entwickeln werden - nur die Geschäftslogik der Anforderungsverarbeitung oder, wie in unserem Fall, der gesamte Proxy. Vergessen Sie nicht, dass alles, was Sie selbst tun, anschließend gründlich getestet werden sollte.