Hallo Freunde. Ende April starten wir einen neuen Kurs
„Sicherheit von Informationssystemen“ . Und jetzt möchten wir Ihnen eine Übersetzung des Artikels mitteilen, die für den Kurs sicherlich sehr nützlich sein wird. Den Originalartikel finden
Sie hier .
Der Artikel beschreibt die wichtigsten Grundlagen, die allen JavaScript-Engines gemeinsam sind und nicht nur
V8 , an dem die Autoren der Engine (
Benedict und
Matias ) arbeiten. Als JavaScript-Entwickler kann ich sagen, dass ein tieferes Verständnis der Funktionsweise der JavaScript-Engine Ihnen dabei hilft, effizienten Code zu schreiben.

Hinweis : Wenn Sie lieber Präsentationen als Artikel lesen möchten, sehen Sie sich dieses Video an . Wenn nicht, überspringen Sie es und lesen Sie weiter.
Pipeline (Pipeline) JavaScript-EngineAlles beginnt damit, dass Sie JavaScript-Code schreiben. Danach verarbeitet die JavaScript-Engine den Quellcode und präsentiert ihn als abstrakten Syntaxbaum (AST). Basierend auf dem konstruierten AST kann der Interpreter endlich an die Arbeit gehen und mit der Generierung von Bytecode beginnen. Großartig! Dies ist der Moment, in dem die Engine JavaScript-Code ausführt.

Um die Ausführung zu beschleunigen, können Sie Bytecode zusammen mit Profildaten an den optimierenden Compiler senden. Der optimierende Compiler trifft bestimmte Annahmen basierend auf Profildaten und generiert dann hochoptimierten Maschinencode.
Wenn sich die Annahmen irgendwann als falsch herausstellen, optimiert der Optimierungs-Compiler den Code und kehrt zur Interpreter-Phase zurück.
Interpreter-Pipelines / Compiler in JavaScript-EnginesSchauen wir uns nun die Teile der Pipeline genauer an, die Ihren JavaScript-Code ausführen, nämlich wo der Code interpretiert und optimiert wird, und einige Unterschiede zwischen den wichtigsten JavaScript-Engines.
Das Herzstück von allem ist eine Pipeline, die einen Interpreter und einen optimierenden Compiler enthält. Der Interpreter generiert schnell nicht optimierten Bytecode, der optimierende Compiler arbeitet wiederum länger, aber die Ausgabe verfügt über einen stark optimierten Maschinencode.
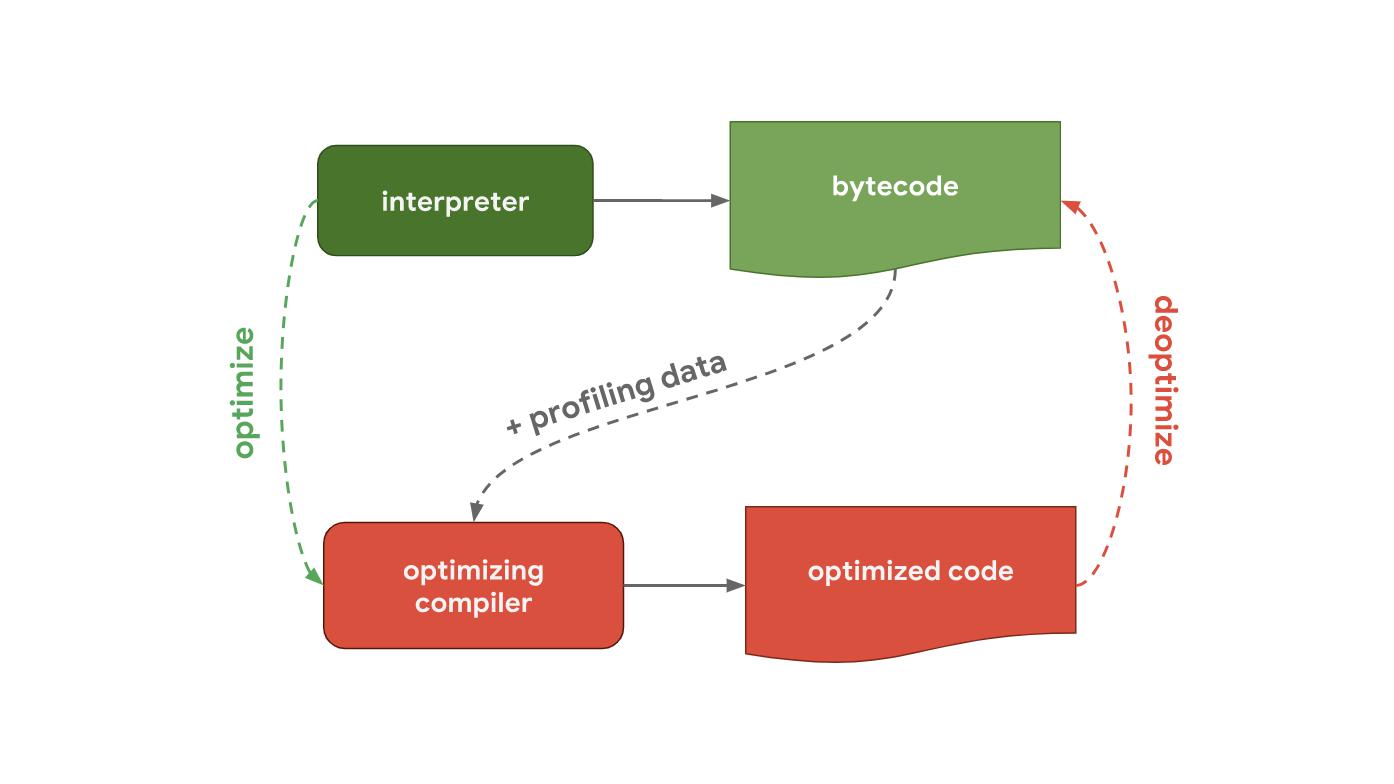
Als nächstes folgt eine Pipeline, die zeigt, wie V8 funktioniert, die von Chrome und Node.js verwendete JavaScript-Engine.

Der Interpreter in V8 heißt Ignition und ist für die Generierung und Ausführung des Bytecodes verantwortlich. Es sammelt Profildaten, mit denen die Ausführung im nächsten Schritt beschleunigt werden kann, während der Bytecode verarbeitet wird. Wenn eine Funktion
heiß wird , beispielsweise wenn sie häufig gestartet wird, werden der generierte Bytecode und die Profildaten an den TurboFan übertragen, dh an den optimierenden Compiler, um auf der Grundlage der Profildaten hochoptimierten Maschinencode zu generieren.

Beispielsweise funktioniert Mozillas SpiderMonkey-JavaScript-Engine, die in Firefox und
SpiderNode verwendet wird , etwas anders. Es gibt nicht einen, sondern zwei optimierende Compiler. Der Interpreter ist in einen Basis-Compiler (Baseline-Compiler) optimiert, der optimierten Code erzeugt. Zusammen mit den während der Codeausführung gesammelten Profildaten kann der IonMonkey-Compiler stark optimierten Code generieren. Wenn die spekulative Optimierung fehlschlägt, kehrt IonMonkey zum Baseline-Code zurück.

Chakra - Microsofts JavaScript-Engine, die in Edge und
Node-ChakraCore verwendet wird , hat eine sehr ähnliche Struktur und verwendet zwei optimierende Compiler. Der Interpreter ist in SimpleJIT optimiert (wobei JIT für „Just-In-Time-Compiler“ steht, der etwas optimierten Code erzeugt. Zusammen mit den Profildaten kann FullJIT noch stärker optimierten Code erstellen.
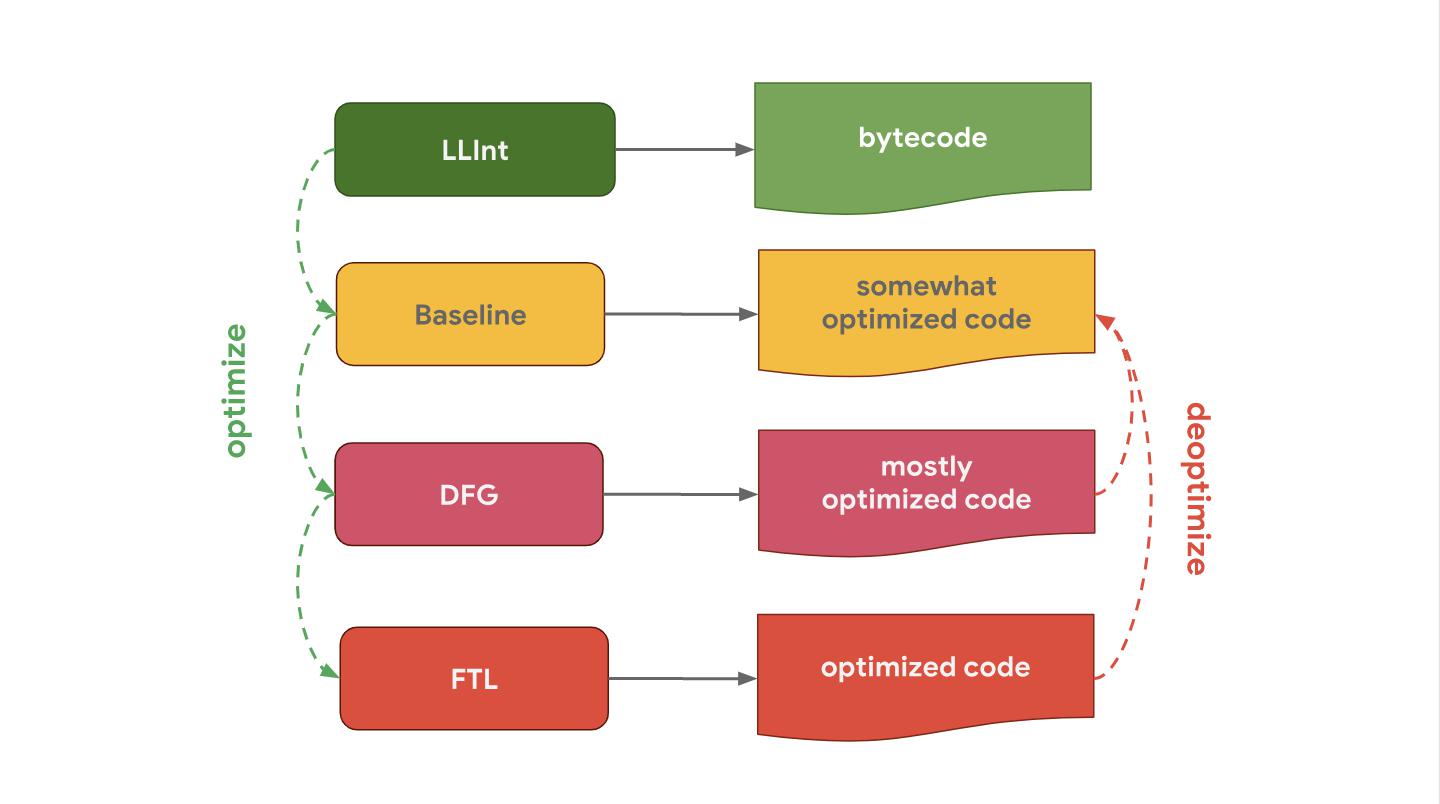
JavaScriptCore (abgekürzt als JSC), Apples JavaScript-Engine, die von Safari und React Native verwendet wird, verfügt im Allgemeinen über drei verschiedene Optimierungscompiler. LLInt ist ein Low-Level-Interpreter, der für den Basis-Compiler optimiert ist, der wiederum für den DFG-Compiler (Data Flow Graph) optimiert ist und bereits für den FTL-Compiler (Faster Than Light) optimiert ist.
Warum haben einige Engines mehr optimierende Compiler als andere? Es geht um Kompromisse. Der Interpreter kann Bytecode schnell verarbeiten, aber Bytecode allein ist nicht besonders effizient. Der optimierende Compiler arbeitet dagegen etwas länger, erzeugt aber effizienteren Maschinencode. Dies ist ein Kompromiss zwischen dem schnellen Abrufen des Codes (Interpreter) oder dem Warten und Ausführen des Codes mit maximaler Leistung (Optimierung des Compilers). Einige Engines fügen mehrere optimierende Compiler mit unterschiedlichen Zeit- und Effizienzmerkmalen hinzu, sodass Sie diese Kompromisslösung optimal steuern und die Kosten für zusätzliche Komplikationen des internen Geräts verstehen können. Ein weiterer Nachteil ist die Speichernutzung. Weitere
Informationen finden Sie in diesem
Artikel .
Wir haben gerade die Hauptunterschiede zwischen Interpreter- und Optimizer-Compiler-Pipelines für verschiedene JavaScript-Engines untersucht. Trotz dieser großen Unterschiede haben alle JavaScript-Engines dieselbe Architektur: Sie haben alle einen Parser und eine Art Interpreter / Compiler-Pipeline.
JavaScript-ObjektmodellMal sehen, was JavaScript-Engines sonst noch gemeinsam haben und welche Tricks sie verwenden, um den Zugriff auf die Eigenschaften von JavaScript-Objekten zu beschleunigen. Es stellt sich heraus, dass alle Hauptmotoren dies auf ähnliche Weise tun.
Die ECMAScript-Spezifikation definiert alle Objekte als Wörterbücher mit Zeichenfolgenschlüsseln, die den
Eigenschaftsattributen entsprechen .

Zusätzlich zu
[[Value]] definiert die Spezifikation die folgenden Eigenschaften:
[[Writable]] bestimmt, ob eine Eigenschaft neu zugewiesen werden kann.[[Enumerable]] bestimmt, ob die Eigenschaft in For-In-Schleifen angezeigt wird.[[Configurable]] bestimmt, ob eine Eigenschaft gelöscht werden kann.
Die Notation
[[ ]] sieht seltsam aus, aber so beschreibt die Spezifikation Eigenschaften in JavaScript. Sie können diese Eigenschaftsattribute für jedes Objekt und jede Eigenschaft in JavaScript mithilfe der
Object.getOwnPropertyDescriptor API weiterhin
Object.getOwnPropertyDescriptor :
const object = { foo: 42 }; Object.getOwnPropertyDescriptor(object, 'foo');
Ok, also JavaScript definiert Objekte. Was ist mit Arrays?
Sie können sich Arrays als spezielle Objekte vorstellen. Der einzige Unterschied besteht darin, dass Arrays über eine spezielle Indexverarbeitung verfügen. Hier ist ein Array-Index ein spezieller Begriff in der ECMAScript-Spezifikation. In JavaScript ist die Anzahl der Elemente in einem Array begrenzt - bis zu 2³² - 1. Ein Array-Index ist ein beliebiger verfügbarer Index aus diesem Bereich, dh ein ganzzahliger Wert von 0 bis 2³² - 2.
Ein weiterer Unterschied besteht darin, dass Arrays die magische Eigenschaft der
length .
const array = ['a', 'b']; array.length;
In diesem Beispiel hat das Array zum Zeitpunkt der Erstellung eine Länge von 2. Dann weisen wir Index 2 ein weiteres Element zu und die Länge erhöht sich automatisch.
JavaScript definiert sowohl Arrays als auch Objekte. Beispielsweise werden alle Schlüssel, einschließlich Array-Indizes, explizit als Zeichenfolgen dargestellt. Das erste Element des Arrays wird unter dem Schlüssel '0' gespeichert.

Die
length Eigenschaft ist nur eine weitere Eigenschaft, die sich als nicht aufzählbar und nicht konfigurierbar herausstellt.
Sobald ein Element zum Array hinzugefügt wird, aktualisiert JavaScript automatisch das Attribut der Eigenschaft
[[Value]] Eigenschaft
length .

Im Allgemeinen können wir sagen, dass sich Arrays ähnlich wie Objekte verhalten.
Optimierung des Zugriffs auf ImmobilienNachdem wir nun wissen, wie Objekte in JavaScript definiert sind, werfen wir einen Blick darauf, wie Sie mit JavaScript-Engines effizient mit Objekten arbeiten können.
Im Alltag ist der Zugang zu Immobilien die häufigste Operation. Es ist äußerst wichtig, dass der Motor dies schnell erledigt.
const object = { foo: 'bar', baz: 'qux', };
FormulareIn JavaScript-Programmen ist es durchaus üblich, vielen Objekten dieselben Eigenschaftsschlüssel zuzuweisen. Sie sagen, dass solche Objekte die gleiche
Form haben .
const object1 = { x: 1, y: 2 }; const object2 = { x: 3, y: 4 };
Eine übliche Mechanik ist auch der Zugriff auf die Eigenschaft von Objekten derselben Form:
function logX(object) { console.log(object.x);
In diesem Wissen können JavaScript-Engines den Zugriff auf die Eigenschaft eines Objekts basierend auf seiner Form optimieren. Sehen Sie, wie es funktioniert.
Angenommen, wir haben ein Objekt mit den Eigenschaften x und y, es verwendet die Wörterbuchdatenstruktur, über die wir zuvor gesprochen haben. Es enthält Schlüsselzeichenfolgen, die auf ihre jeweiligen Attribute verweisen.
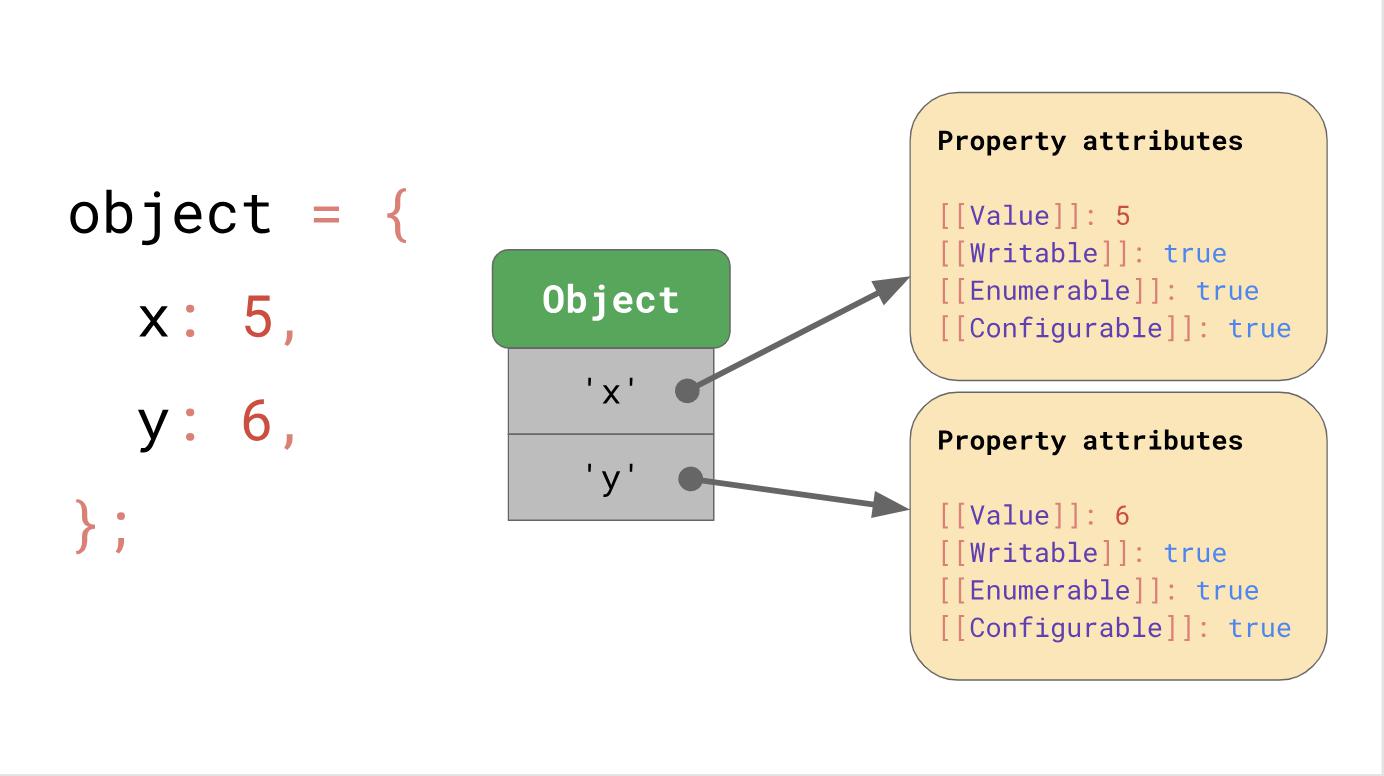
Wenn Sie auf eine Eigenschaft wie
object.y, sucht die JavaScript-Engine nach einem JSObject mit dem Schlüssel
'y' , lädt dann die Eigenschaftsattribute, die dieser Abfrage entsprechen, und gibt schließlich
[[Value]] .
Aber wo werden diese Eigenschaftsattribute gespeichert? Sollten wir sie als Teil eines JSObject speichern? Wenn wir dies tun, werden wir später weitere Objekte dieses Formulars sehen. In diesem Fall ist es eine Verschwendung von Speicherplatz, ein vollständiges Wörterbuch mit den Namen von Eigenschaften und Attributen in JSObject selbst zu speichern, da Eigenschaftsnamen für alle Objekte desselben Formulars wiederholt werden. Dies führt zu vielen Überschneidungen und zu einer Fehlallokation des Speichers. Zur Optimierung speichern die Engines die Form des Objekts separat.

Diese
Shape enthält alle Eigenschaftsnamen und Attribute außer
[[Value]] . Stattdessen enthält das Formular die Versatzwerte im JSObject, sodass die JavaScript-Engine weiß, wo nach den Werten gesucht werden muss. Jedes JSObject mit einem gemeinsamen Formular gibt eine bestimmte Instanz des Formulars an. Jetzt muss jedes JSObject nur Werte speichern, die für das Objekt eindeutig sind.
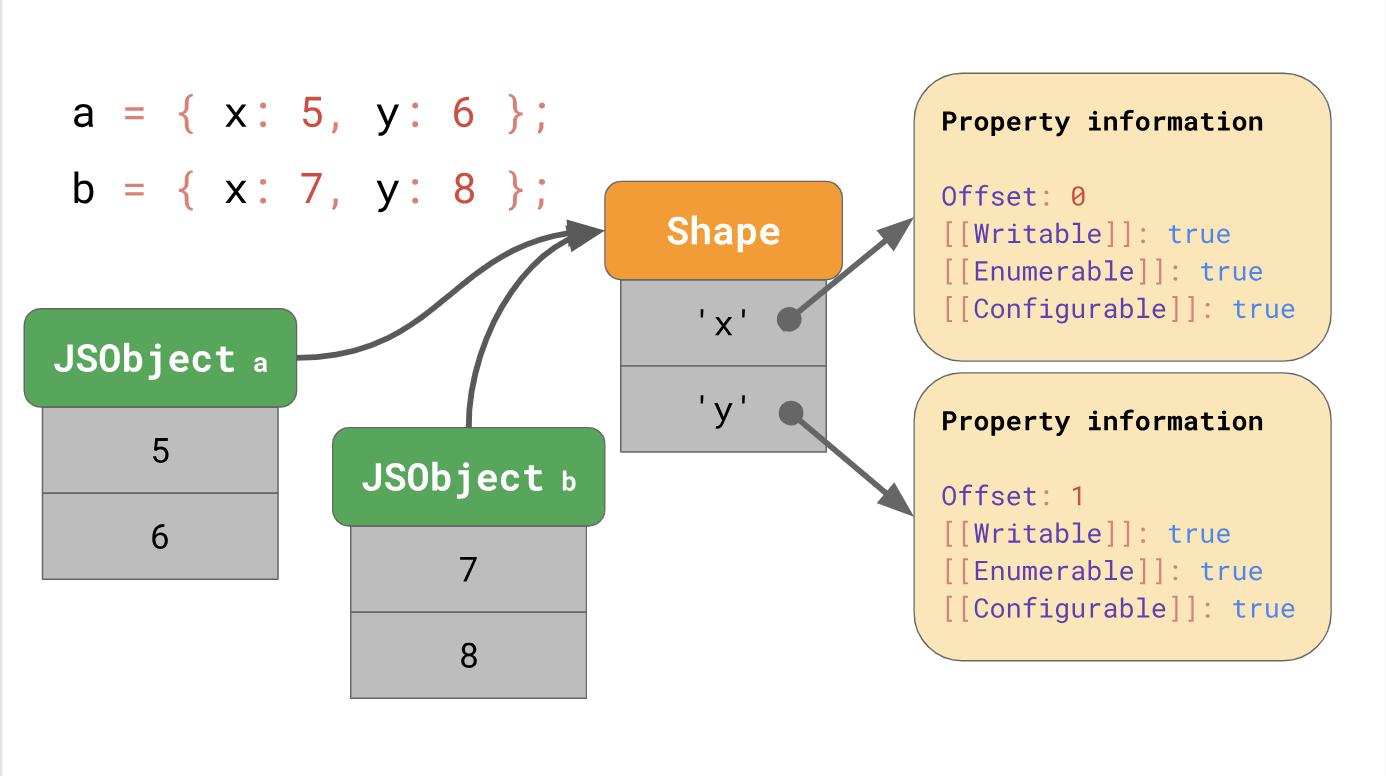
Der Vorteil wird offensichtlich, sobald wir viele Objekte haben. Ihre Anzahl spielt keine Rolle, denn wenn sie ein Formular haben, speichern wir Informationen über das Formular und die Eigenschaft nur einmal.
Alle JavaScript-Engines verwenden Formulare als Optimierungsmittel, benennen sie jedoch nicht direkt als
shapes :
- In der akademischen Dokumentation werden sie als versteckte Klassen bezeichnet (ähnlich wie bei JavaScript-Klassen).
- V8 nennt sie Karten;
- Chakra nennt sie Typen;
- JavaScriptCore nennt sie Strukturen;
- SpiderMonkey nennt sie Shapes.
In diesem Artikel nennen wir sie weiterhin
shapes .
Übergangsketten und BäumeWas passiert, wenn Sie ein Objekt mit einer bestimmten Form haben, aber eine neue Eigenschaft hinzufügen? Wie definiert die JavaScript-Engine ein neues Formular?
const object = {}; object.x = 5; object.y = 6;
Formulare erstellen sogenannte Übergangsketten in der JavaScript-Engine. Hier ist ein Beispiel:
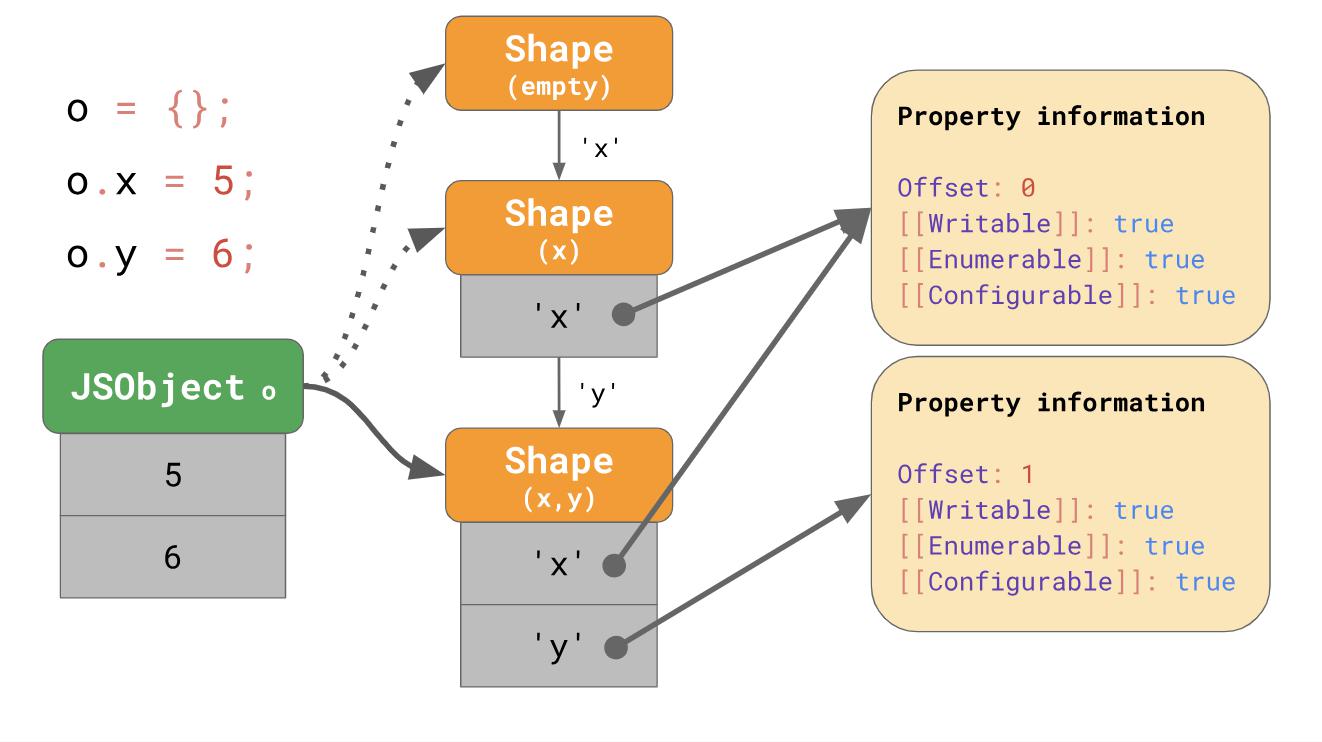
Ein Objekt hat zunächst keine Eigenschaften, es entspricht einem leeren Formular. Der folgende Ausdruck fügt diesem Objekt die Eigenschaft
'x' mit dem Wert 5 hinzu. Anschließend wechselt die Engine zu dem Formular, das die Eigenschaft
'x' enthält
'x' und der Wert 5 wird beim ersten Versatz 0 zu JSObject hinzugefügt. In der nächsten Zeile wird die Eigenschaft
'y' hinzugefügt, und die Engine wechselt zum nächsten Ein Formular, das bereits
'x' und
'y' und JSObject bei Offset 1 den Wert 6 hinzufügt.
Hinweis : Die Reihenfolge, in der Eigenschaften hinzugefügt werden, wirkt sich auf das Formular aus. Zum Beispiel führt {x: 4, y: 5} zu einer anderen Form als {y: 5, x: 4}.
Wir müssen nicht einmal die gesamte Eigenschaftentabelle für jedes Formular speichern. Stattdessen muss jedes Formular nur eine neue Eigenschaft kennen, die es aufnehmen möchte. In diesem Fall müssen wir beispielsweise keine Informationen über 'x' in der letzteren Form speichern, da diese früher in der Kette gefunden werden können. Damit dies funktioniert, wird das Formular mit dem vorherigen Formular zusammengeführt.
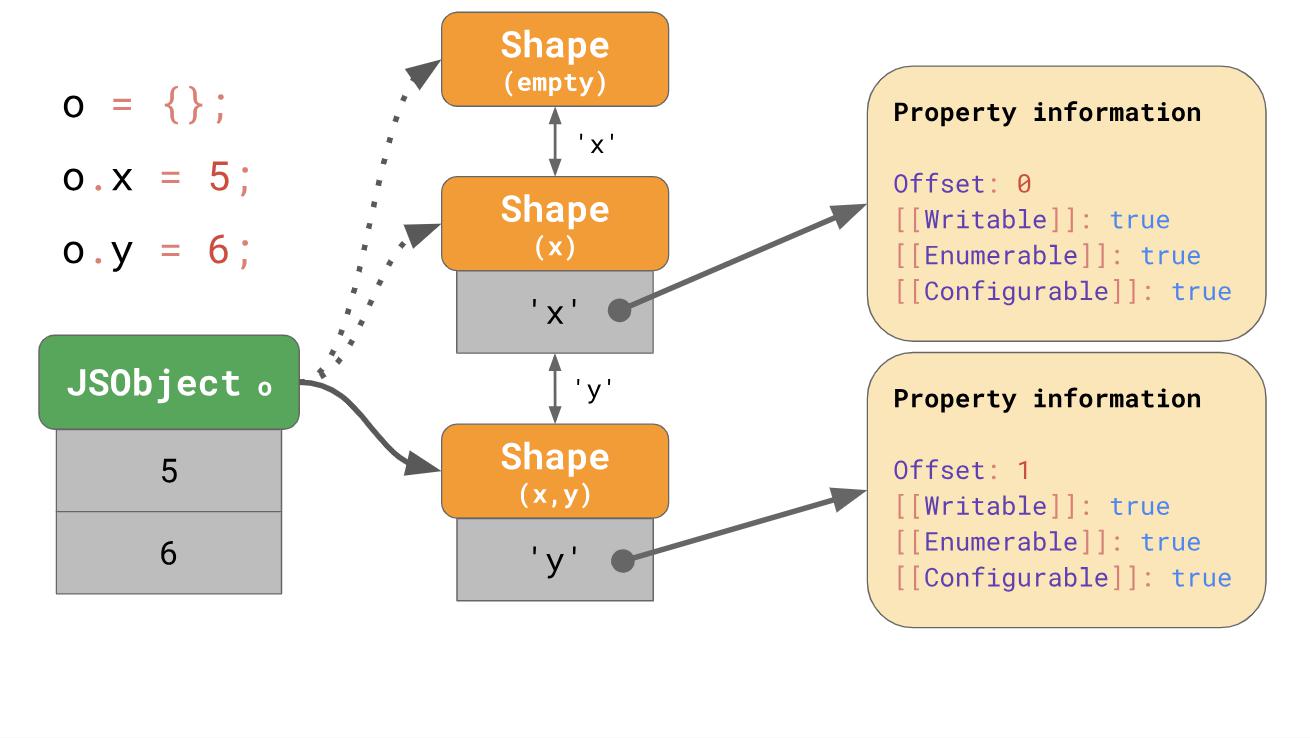
Wenn Sie
ox in Ihren JavaScript-Code schreiben, sucht JavaScript entlang der Übergangskette nach der Eigenschaft
'x' , bis ein Formular erkannt wird, das bereits die Eigenschaft
'x' .
Aber was passiert, wenn es unmöglich ist, eine Übergangskette zu erstellen? Was passiert beispielsweise, wenn Sie zwei leere Objekte haben und ihnen unterschiedliche Eigenschaften hinzufügen?
const object1 = {}; object1.x = 5; const object2 = {}; object2.y = 6;
In diesem Fall wird ein Zweig angezeigt, und anstelle der Übergangskette erhalten wir einen Übergangsbaum:
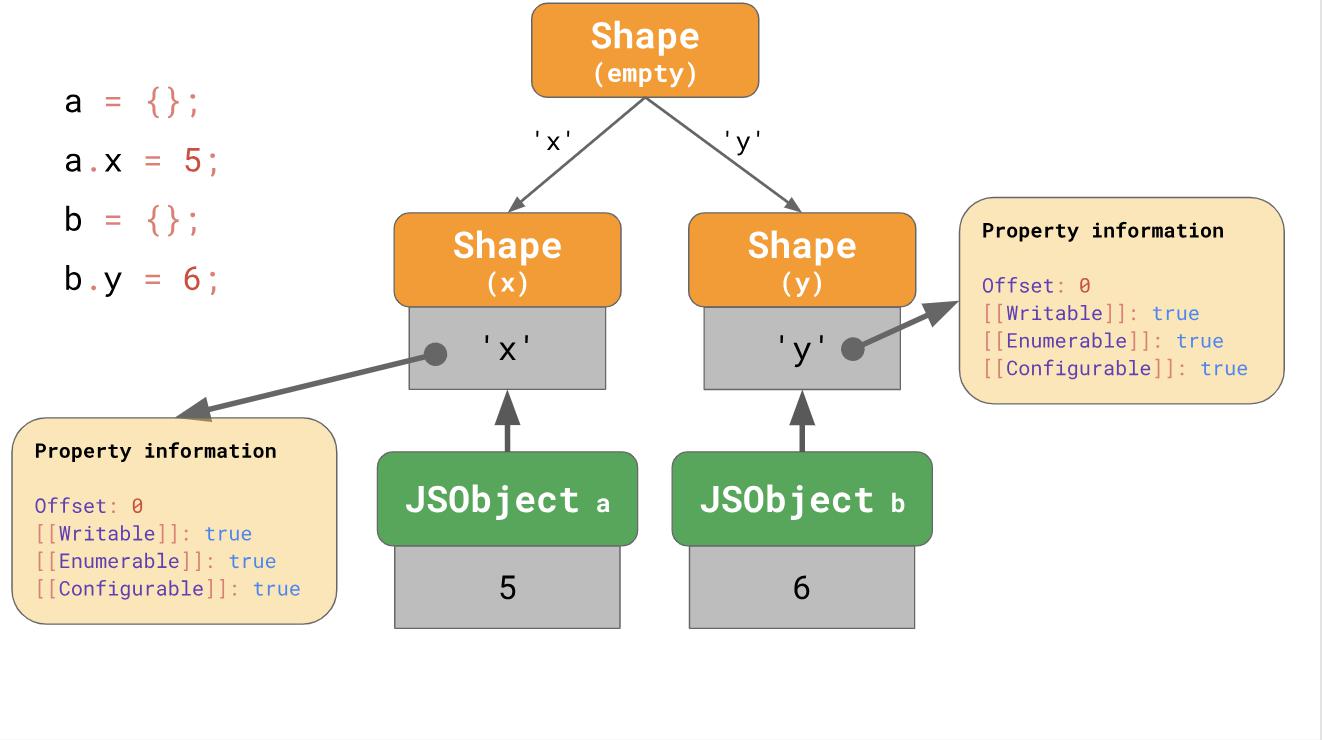
Wir erstellen ein leeres Objekt
a und fügen ihm die Eigenschaft
'x' . Als Ergebnis haben wir ein
JSObject das einen einzelnen Wert und zwei Formulare enthält: leer und ein Formular mit einer einzelnen
'x' JSObject 'x' Eigenschaft.
Das zweite Beispiel beginnt mit der Tatsache, dass wir ein leeres Objekt
b , aber dann fügen wir eine weitere Eigenschaft
'y' . Als Ergebnis erhalten wir hier zwei Ketten von Formen, aber am Ende erhalten wir drei Ketten.
Bedeutet das, dass wir immer mit einem leeren Formular beginnen? Nicht unbedingt. Die Engines verwenden eine Optimierung von Objektliteralen, die bereits Eigenschaften enthalten. Angenommen, wir fügen x hinzu, beginnend mit einem leeren Objektliteral, oder wir haben ein Objektliteral, das bereits
x enthält:
const object1 = {}; object1.x = 5; const object2 = { x: 6 };
Im ersten Beispiel beginnen wir mit einem leeren Formular und gehen zu einer Kette, die auch
x enthält, wie wir zuvor gesehen haben.
Im Fall von
object2 es sinnvoll, Objekte, die bereits von Anfang an x haben, direkt zu erstellen, anstatt mit einem leeren Objekt und einem Übergang zu beginnen.
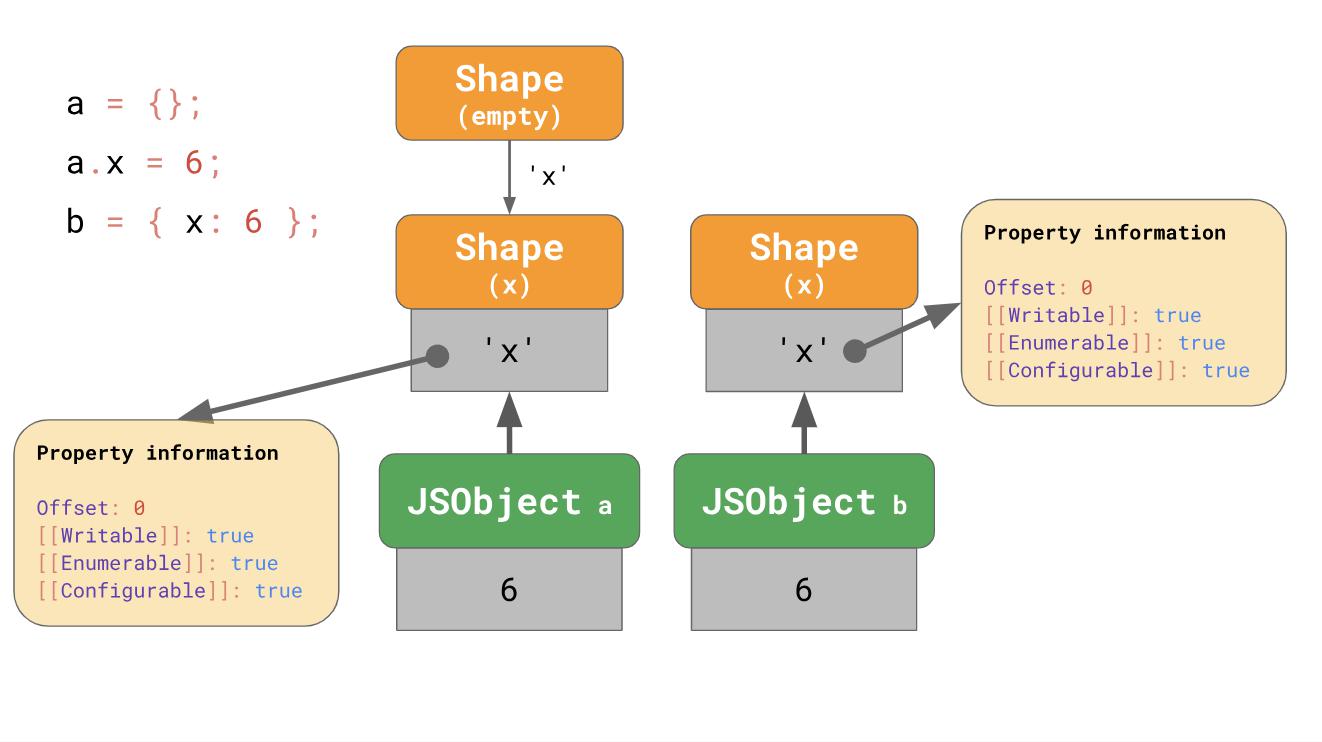
Das Literal eines Objekts, das die Eigenschaft
'x' enthält
'x' beginnt von Anfang an mit einem Formular, das
'x' enthält, und das leere Formular wird effektiv übersprungen. Dies ist (zumindest) das, was V8 und SpiderMonkey tun. Die Optimierung verkürzt die Übergangskette und erleichtert das Zusammensetzen von Objekten aus Literalen.
In Benedikts Blogbeitrag über den erstaunlichen Polymorphismus von Anwendungen auf
React wird erläutert, wie sich solche Feinheiten auf die Leistung auswirken können.
Weiter sehen Sie ein Beispiel für Punkte eines dreidimensionalen Objekts mit den Eigenschaften
'x' ,
'y' ,
'z' .
const point = {}; point.x = 4; point.y = 5; point.z = 6;
Wie Sie zuvor verstanden haben, erstellen wir ein Objekt mit drei Formularen im Speicher (ohne das leere Formular). Wenn Sie beispielsweise auf die Eigenschaft
'x' dieses Objekts
point.x , wenn Sie
point.x in Ihr Programm schreiben, muss die JavaScript-Engine einer verknüpften Liste folgen:
point.x Sie mit dem Formular ganz unten und
point.x Sie dann schrittweise zu dem Formular mit
'x' ganz oben.
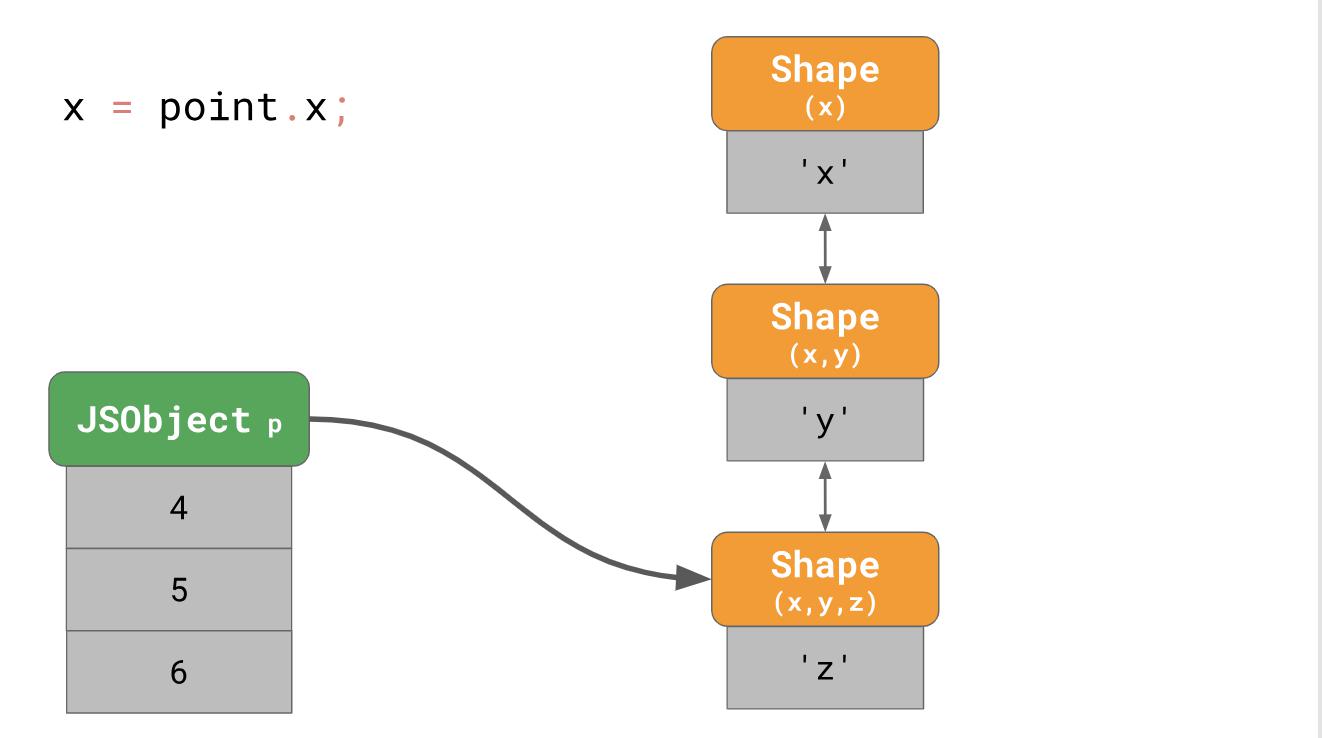
Es stellt sich sehr langsam heraus, besonders wenn Sie es oft und mit vielen Eigenschaften des Objekts tun. Die Verweilzeit einer Eigenschaft ist
O(n) , d. H. Es ist eine lineare Funktion, die mit der Anzahl der Eigenschaften des Objekts korreliert. Um die Suche nach Eigenschaften zu beschleunigen, fügen JavaScript-Engines eine ShapeTable-Datenstruktur hinzu. ShapeTable ist ein Wörterbuch, in dem die Schlüssel auf bestimmte Weise den Formularen zugeordnet werden und die gewünschte Eigenschaft erzeugen.
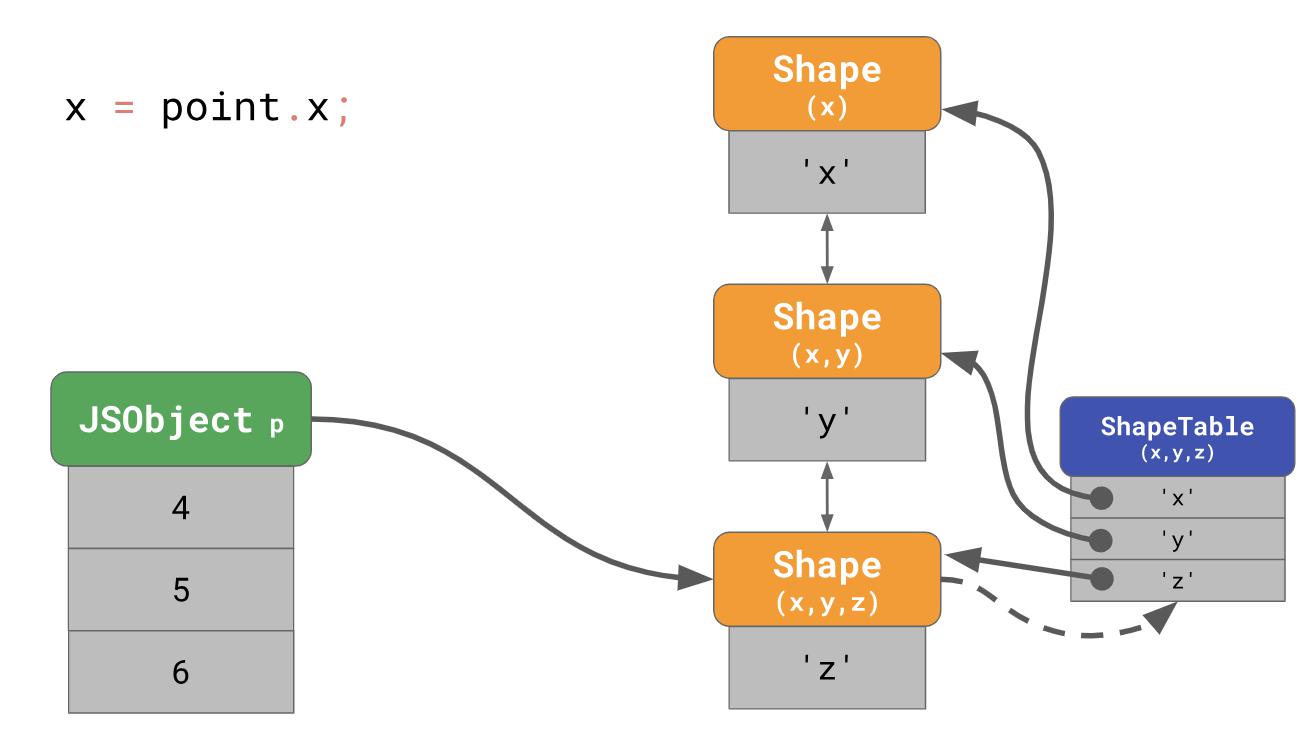
Warten Sie eine Sekunde, jetzt kehren wir zur Wörterbuchsuche zurück ... Genau damit haben wir begonnen, als wir überhaupt Formulare eingefügt haben! Warum interessieren wir uns überhaupt für Formulare?
Tatsache ist, dass Formulare zu einer weiteren Optimierung beitragen, die als
Inline-Caches bezeichnet wird.Wir werden im
zweiten Teil des Artikels über das Konzept von Inline-Caches oder ICs sprechen und möchten Sie nun zu einem
kostenlosen offenen Webinar einladen, das am 9. April vom berühmten Virenanalytiker und Teilzeitlehrer
Alexander Kolesnikov abgehalten wird.