Im Bereich der Entwicklung hoch geladener Multithread- oder verteilter Anwendungen kommt es häufig zu Diskussionen über asynchrone Programmierung. Heute werden wir uns eingehend mit Asynchronität befassen und untersuchen, was es ist, wenn es auftritt, wie es sich auf den Code und die Programmiersprache auswirkt, die wir verwenden. Wir werden herausfinden, warum Futures und Versprechen benötigt werden, und Coroutinen und Betriebssysteme ansprechen. Dadurch werden die Kompromisse, die sich während der Softwareentwicklung ergeben, deutlicher.
Das Material basiert auf einer Abschrift eines Berichts von Ivan Puzyrevsky, einem Lehrer an der Yandex Data Analysis School.

Videoaufnahme
1. Inhalt
2. Einführung
Hallo allerseits, mein Name ist Ivan Puzyrevsky, ich arbeite für Yandex. In den letzten sechs Jahren beschäftigte ich mich mit der Infrastruktur der Datenspeicherung und -verarbeitung, jetzt wechselte ich zum Produkt - auf der Suche nach Reisen, Hotels und Tickets. Da ich lange in der Infrastruktur gearbeitet habe, habe ich viel Erfahrung mit dem Schreiben verschiedener geladener Anwendungen gesammelt. Unsere Infrastruktur arbeitet täglich rund um die Uhr und ohne Unterbrechung auf Tausenden von Maschinen. Natürlich müssen Sie Code schreiben, damit er zuverlässig und effizient funktioniert und die Aufgaben des Unternehmens löst.
Heute werden wir über Asynchronität sprechen. Was ist Asynchronität? Es ist ein Missverhältnis von etwas mit etwas in der Zeit. Aus dieser Beschreibung geht im Allgemeinen nicht hervor, worüber ich heute sprechen werde. Um das Problem irgendwie zu klären, brauche ich ein Beispiel a la "Hallo Welt!". Asynchronität tritt normalerweise beim Schreiben von Netzwerkanwendungen auf, daher habe ich ein Netzwerkanalogon von „Hallo Welt!“. Dies ist eine Ping-Pong-App. Der Code sieht folgendermaßen aus:
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Ich erstelle einen Socket, lese eine Zeile von dort und überprüfe, ob es Ping ist, dann schreibe ich Pong als Antwort. Sehr einfach und klar. Was passiert, wenn Sie solchen Code auf Ihrem Computerbildschirm sehen? Wir betrachten diesen Code als eine Folge dieser Schritte:
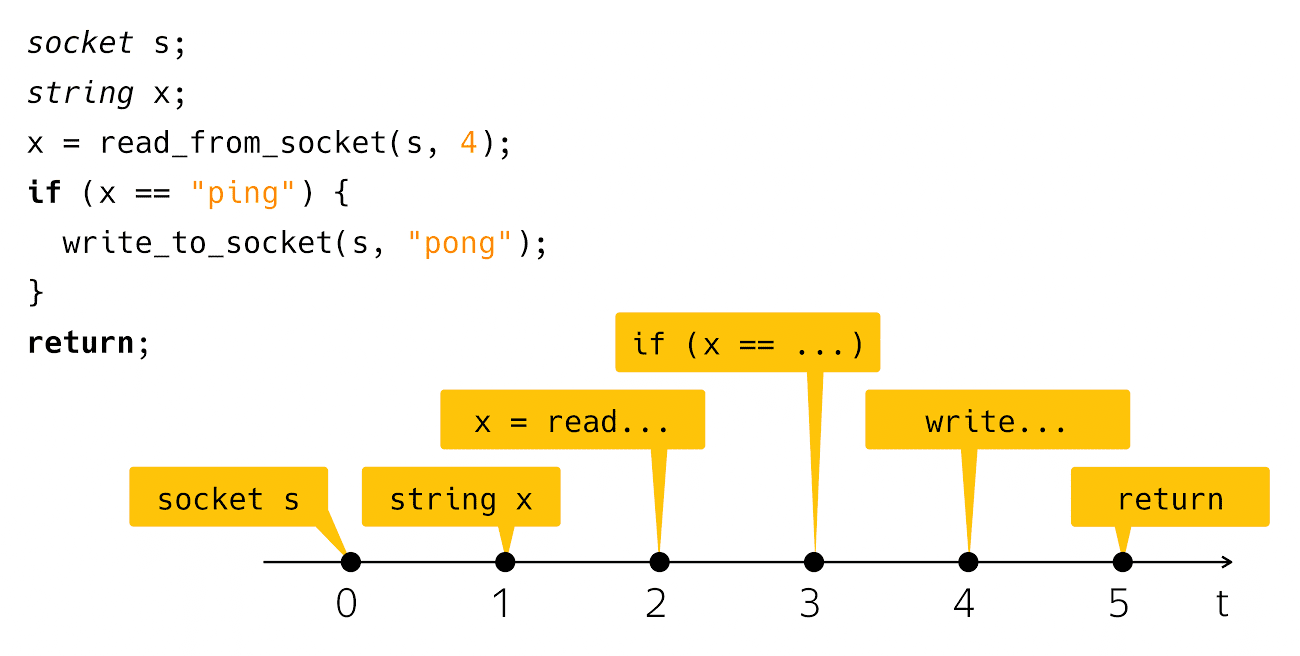
Aus Sicht der realen physischen Zeit ist alles etwas voreingenommen.

Diejenigen, die solchen Code tatsächlich geschrieben und ausgeführt haben, wissen das nach dem Leseschritt und nach dem Schritt
Schreiben ist ein ziemlich auffälliges Zeitintervall, in dem unser Programm aus Sicht unseres Codes nichts zu tun scheint, aber unter der Haube die Maschine arbeitet, die wir "Eingabe-Ausgabe" nennen.

Während der E / A werden Pakete über das Netzwerk und die gesamte damit verbundene schwere Arbeit auf niedriger Ebene ausgetauscht. Lassen Sie uns ein Gedankenexperiment durchführen: Nehmen Sie ein solches Programm, führen Sie es auf einem physischen Prozessor aus und tun Sie so, als hätten wir kein Betriebssystem. Was wird passieren? Der Prozessor kann nicht anhalten, er führt weiterhin Maßnahmen durch, ohne Anweisungen zu befolgen, und verschwendet nur vergeblich Energie.
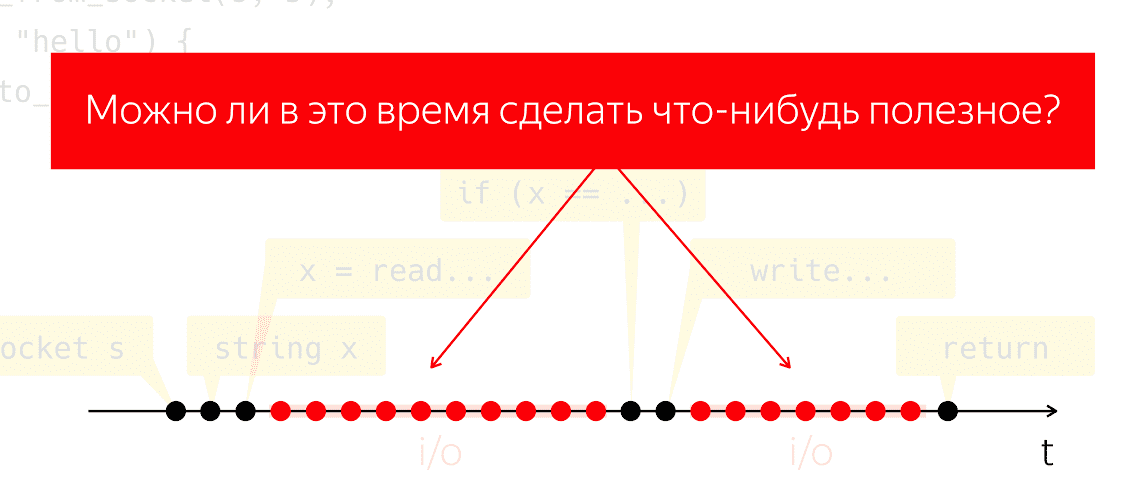
Es stellt sich die Frage, ob wir in dieser Zeit etwas Nützliches tun können. Dies ist eine sehr natürliche Frage, deren Antwort es uns ermöglichen würde, Prozessorleistung zu sparen und sie für etwas Nützliches zu verwenden, während unsere Anwendung nichts zu tun scheint.
3. Grundlegende Konzepte
3.1. Thread der Ausführung
Wie können wir uns dieser Aufgabe nähern? Lassen Sie uns die Konzepte in Einklang bringen. Ich werde "Ausführungsfluss" sagen und mich auf eine sinnvolle Abfolge elementarer Operationen oder Schritte beziehen. Die Aussagekraft wird durch den Kontext bestimmt, in dem ich vom Ablauf der Ausführung spreche. Das heißt, wenn es sich um einen Single-Thread-Algorithmus handelt (Aho-Korasik, Graphensuche), dann ist dieser Algorithmus selbst bereits ein Thread der Ausführung. Er unternimmt einige Schritte, um das Problem zu lösen.
Wenn es sich um eine Datenbank handelt, kann ein Ausführungsthread Teil der von der Datenbank ausgeführten Aktionen sein, um eine eingehende Anforderung zu bedienen. Gleiches gilt für Webserver. Wenn ich eine Art Mobil- oder Webanwendung schreibe, um den Betrieb eines Benutzers zu bedienen, z. B. Klicken auf eine Schaltfläche, Netzwerkinteraktionen, Interaktion mit lokalem Speicher usw. Die Abfolge dieser Aktionen aus Sicht meiner mobilen Anwendung ist auch ein separater aussagekräftiger Ausführungsfluss. Aus Sicht des Betriebssystems ist ein Prozess oder ein Prozessthread auch ein aussagekräftiger Ausführungsthread.
3.2. Multitasking und Parallelität
Der Eckpfeiler der Produktivität ist die Fähigkeit, einen solchen Trick auszuführen: Wenn ich einen Ausführungsthread habe, der Lücken in seinem physischen Zeitscan enthält, dann fülle diese Lücken mit etwas Nützlichem - folge den Schritten anderer Ausführungsthreads.
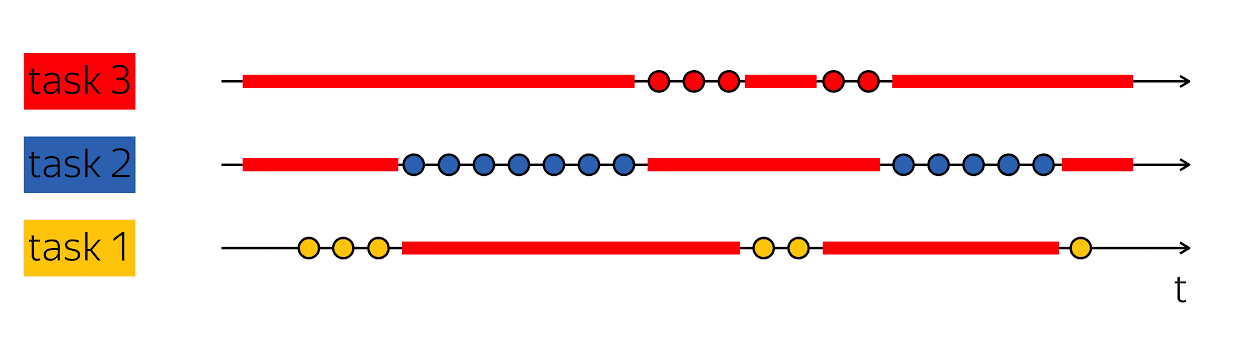
Datenbanken bedienen normalerweise viele Clients gleichzeitig. Wenn wir die Arbeit an mehreren Ausführungsthreads im Rahmen eines Ausführungsthreads einer höheren Ebene kombinieren können, spricht man von Multitasking. Das heißt, Multitasking ist, wenn ich Aktionen im Rahmen eines größeren Ausführungsflusses ausführe, die der Lösung kleinerer Aufgaben untergeordnet sind.
Es ist wichtig, das Konzept des Multitasking nicht mit Parallelität zu verwechseln. Parallelität -
Dies sind Eigenschaften der Laufzeitumgebung, die es ermöglichen, in einem Schritt in einem Schritt Fortschritte in verschiedenen Ausführungsthreads zu erzielen. Wenn ich zwei physische Prozessoren habe, können sie in einem Taktzyklus zwei Anweisungen ausführen. Wenn das Programm auf einem Prozessor ausgeführt wird, dauert es zwei Taktzyklen, um dieselben zwei Anweisungen auszuführen.

Es ist wichtig, diese Konzepte nicht zu verwechseln, da sie in verschiedene Kategorien fallen. Multitasking ist eine Funktion Ihres Programms, die intern als variable Arbeit für verschiedene Aufgaben strukturiert ist. Parallelität ist eine Eigenschaft der Laufzeitumgebung, mit der Sie mehrere Aufgaben in einem Taktzyklus bearbeiten können.
In vielerlei Hinsicht schreiben asynchroner Code und das Schreiben von asynchronem Code Multitasking-Code. Die Hauptschwierigkeit besteht darin, wie ich Aufgaben codiere und wie ich sie verwalte. Deshalb werden wir heute darüber sprechen - Multitasking-Code schreiben.
4. Blockieren und warten

Beginnen wir mit einem einfachen Beispiel. Zurück zum Tischtennis:
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Wie wir bereits besprochen haben, wird der Ausführungsthread nach dem Einschlafen und den weißen Linien blockiert und blockiert. Normalerweise sagen wir: "Der Fluss ist blockiert."
socket s; string x; x = read_from_socket(s, 4); if (x == "ping") { write_to_socket(s, "pong"); } return;
Dies bedeutet, dass der Ausführungsfluss einen Punkt erreicht hat, an dem ein Ereignis erforderlich ist, um ihn fortzusetzen. Insbesondere bei unserer Netzwerkanwendung ist es erforderlich, dass Daten über das Netzwerk eintreffen, oder umgekehrt haben wir einen freien Puffer zum Schreiben von Daten in das Netzwerk. Ereignisse können unterschiedlich sein. Wenn wir über Zeitaspekte sprechen, können wir warten, bis der Timer ausgelöst wird oder ein anderer Prozess abgeschlossen ist. Die Ereignisse hier sind eine Art abstrakte Sache, über sie ist es wichtig zu verstehen, dass sie erwartet werden können.

Wenn wir einfachen Code schreiben, geben wir implizit die Kontrolle über die Ereigniserwartung auf eine höhere Ebene. In unserem Fall das Betriebssystem. Als eine Einheit einer höheren Ebene ist sie dafür verantwortlich, auszuwählen, welche Aufgabe als nächstes ausgeführt wird, und sie ist auch dafür verantwortlich, das Auftreten von Ereignissen zu verfolgen.
Unser Code, den wir als Entwickler schreiben, ist gleichzeitig in Bezug auf die Arbeit an einer Aufgabe strukturiert. Das Code-Snippet aus dem Beispiel behandelt eine Verbindung: Es liest Ping von einer Verbindung und schreibt Pong in eine Verbindung.
Der Code ist klar. Sie können es lesen und verstehen, was es tut, wie es funktioniert, welches Problem es löst, welche Invarianten es hat und so weiter. Gleichzeitig verwalten wir die Aufgabenplanung in einem solchen Modell sehr schlecht. Im Allgemeinen haben Betriebssysteme Prioritätskonzepte. Wenn Sie jedoch weiche Echtzeitsysteme geschrieben haben, wissen Sie, dass die unter Linux verfügbaren Tools nicht ausreichen, um genügend vernünftige Echtzeitsysteme zu erstellen.
Darüber hinaus ist das Betriebssystem eine komplizierte Sache, und das Umschalten des Kontexts von unserer Anwendung zum Kernel kostet einige Mikrosekunden, was uns mit einigen einfachen Berechnungen eine Schätzung von etwa 20-100.000 Kontextwechseln pro Sekunde ergibt. Das heißt, wenn wir einen Webserver schreiben, können wir in einer Sekunde ungefähr 20.000 Anfragen verarbeiten, vorausgesetzt, die Verarbeitung von Anfragen ist zehnmal teurer als das System.

4.1. Nicht blockierendes Warten
Wenn Sie zu der Situation kommen, dass Sie effizienter mit dem Netzwerk arbeiten müssen, suchen Sie im Internet nach Hilfe und verwenden select / epoll. Im Internet steht geschrieben, dass Sie epoll benötigen, wenn Sie Tausende von Verbindungen gleichzeitig bedienen möchten, da dies ein guter Mechanismus ist und so weiter. Sie öffnen die Dokumentation und sehen ungefähr so:
int select(int nfds, fd_set* readfds, fd_set* writefds, fd_set* exceptfds, struct timeval* timeout); void FD_CLR(int fd, fd_set* set); int FD_ISSET(int fd, fd_set* set); void FD_SET(int fd, fd_set* set); void FD_ZERO(fd_set* set); int epoll_ctl(int epfd, int op, int fd, struct epoll_event* event); int epoll_wait(int epfd, struct epoll_event* events, int maxevents, int timeout);
Funktionen, bei denen die Schnittstelle entweder viele Deskriptoren enthält, mit denen Sie arbeiten (im Fall von select), oder viele Ereignisse, die übergeben werden
über die Grenzen Ihrer Anwendung hinweg den Kernel des Betriebssystems, den Sie verarbeiten müssen (im Fall von epoll).
Es ist auch erwähnenswert, dass Sie nicht zu select / epoll kommen können, sondern zu einer Bibliothek wie libuv, die keine Ereignisse in der API enthält, aber viele Rückrufe enthält. Die Bibliotheksoberfläche sagt: "Lieber Freund, geben Sie einen Rückruf zum Lesen des Sockets, den ich aufrufen werde, wenn die Daten angezeigt werden."
int uv_timer_start(uv_timer_t* handle, uv_timer_cb cb, uint64_t timeout, uint64_t repeat); typedef void (*uv_timer_cb)(uv_timer_t* handle); int uv_read_start(uv_stream_t* stream, uv_alloc_cb alloc_cb, uv_read_cb read_cb); int uv_read_stop(uv_stream_t*); typedef void (*uv_read_cb)(uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf); int uv_write(uv_write_t* req, uv_stream_t* handle, const uv_buf_t bufs[], unsigned int nbufs, uv_write_cb cb); typedef void (*uv_write_cb)(uv_write_t* req, int status);
Was hat sich gegenüber unserem Synchroncode im vorherigen Kapitel geändert? Der Code ist asynchron geworden. Dies bedeutet, dass wir die Logik in die Anwendung übernommen haben, um den Zeitpunkt zu bestimmen, zu dem Ereignisse überwacht werden. Explizite Select / Epoll-Aufrufe sind die Punkte, an denen wir das Betriebssystem um Informationen zu den aufgetretenen Ereignissen bitten. Wir haben auch die Auswahl der Aufgabe, an der wir als nächstes arbeiten möchten, in unseren Anwendungscode aufgenommen.

An den Beispielen für Schnittstellen können Sie erkennen, dass es grundsätzlich zwei Mechanismen zur Einführung von Multitasking gibt. Eine Art "ziehen", wenn wir
Wir zeichnen viele der Ereignisse heraus, auf die wir warten, und reagieren dann irgendwie darauf. Bei diesem Ansatz ist es einfach, den Overhead um eins zu amortisieren
ein Ereignis und erzielen daher einen hohen Durchsatz in der Kommunikation über die Menge der aufgetretenen Ereignisse. Normalerweise basieren alle Netzwerkelemente wie die Interaktion des Kernels mit der Netzwerkkarte oder die Interaktion von Ihnen und dem Betriebssystem auf Abfragemechanismen.
Der zweite Weg ist ein "Push" -Mechanismus, bei dem eine bestimmte externe Entität eindeutig hereinkommt, den Ausführungsfluss unterbricht und sagt: "Behandeln Sie jetzt bitte das Ereignis, das gerade eingetroffen ist." Dies ist ein Ansatz mit Rückrufen, mit Unix-Signalen und mit Unterbrechungen auf Prozessorebene, wenn eine externe Entität eindeutig in Ihren Ausführungsthread eindringt und sagt: "Nun, bitte, wir arbeiten an diesem Ereignis." Dieser Ansatz wurde entwickelt, um die Verzögerung zwischen dem Auftreten eines Ereignisses und der Reaktion darauf zu verringern.
Warum möchten wir C ++ - Entwickler, die bestimmte Anwendungsprobleme schreiben und lösen, möglicherweise ein Ereignismodell in unseren Code ziehen? Wenn wir die Arbeit an vielen Aufgaben per Drag & Drop in unseren Code ziehen und verwalten, können wir aufgrund des fehlenden Übergangs zum Kernel und umgekehrt etwas schneller arbeiten und pro Zeiteinheit nützlichere Aktionen ausführen.
Was führt dies in Bezug auf den Code, den wir schreiben? Nehmen wir zum Beispiel nginx, einen sehr verbreiteten Hochleistungs-HTTP-Server. Wenn Sie den Code lesen, basiert er auf einem asynchronen Modell. Der Code ist ziemlich schwer zu lesen. Wenn Sie sich fragen, was genau bei der Verarbeitung einer einzelnen HTTP-Anforderung passiert, stellt sich heraus, dass der Code viele Fragmente enthält, die in verschiedenen Dateien und in verschiedenen Winkeln der Codebasis angeordnet sind. Jedes Fragment erledigt einen kleinen Arbeitsaufwand als Teil der Bearbeitung der gesamten HTTP-Anforderung. Z.B:
static void ngx_http_request_handler(ngx_event_t *ev) { … if (c->close) { ngx_http_terminate_request(r, 0); return; } if (ev->write) { r->write_event_handler(r); } else { r->read_event_handler(r); } ... } typedef void (*ngx_http_event_handler_pt)(ngx_http_request_t *r); struct ngx_http_request_s { ngx_http_event_handler_pt read_event_handler; }; r->read_event_handler = ngx_http_request_empty_handler; r->read_event_handler = ngx_http_block_reading; r->read_event_handler = ngx_http_test_reading; r->read_event_handler = ngx_http_discarded_request_body_handler; r->read_event_handler = ngx_http_read_client_request_body_handler; r->read_event_handler = ngx_http_upstream_rd_check_broken_connection; r->read_event_handler = ngx_http_upstream_read_request_handler;
Es gibt eine Anforderungsstruktur, die an den Ereignishandler weitergeleitet wird, wenn der Socket Lese- oder Schreibzugriff signalisiert. Ferner wechselt dieser Handler im Verlauf des Programms abhängig vom Zustand der Anforderungsverarbeitung ständig. Entweder lesen wir die Header oder wir lesen den Hauptteil der Anfrage oder wir fragen vorgelagert nach Daten - im Allgemeinen gibt es viele verschiedene Zustände.
Ein solcher Code ist schwer zu lesen, da er im Wesentlichen als Reaktion auf Ereignisse beschrieben wird. Wir sind in so und so einem Zustand und reagieren auf bestimmte Weise auf die Ereignisse, die gekommen sind. Es fehlt ein ganzheitliches Bild des gesamten Prozesses der Verarbeitung einer HTTP-Anfrage.
Eine andere Option, die häufig in JavaScript verwendet wird, besteht darin, auf Rückrufen basierenden Code zu erstellen, wenn wir unseren Rückruf an den Schnittstellenaufruf weiterleiten, in dem normalerweise ein anderer verschachtelter Rückruf für das Ereignis vorhanden ist, und so weiter.
int LibuvStreamWrap::ReadStart() { return uv_read_start(stream(), [](uv_handle_t* handle, size_t suggested_size, uv_buf_t* buf) { static_cast<LibuvStreamWrap*>(handle->data)->OnUvAlloc(suggested_size, buf); }, [](uv_stream_t* stream, ssize_t nread, const uv_buf_t* buf) { static_cast<LibuvStreamWrap*>(stream->data)->OnUvRead(nread, buf); }); } for (p=data; p != data + len; p++) { ch = *p; reexecute: switch (CURRENT_STATE()) { case s_start_req_or_res: case s_res_or_resp_H: case s_res_HT: case s_res_HTT: case s_res_HTTP: case s_res_http_major: case s_res_http_dot:
Der Code ist wieder sehr fragmentiert, es gibt kein Verständnis für den aktuellen Stand, wie wir an der Anfrage arbeiten. Viele Informationen werden durch Schließungen übertragen, und Sie müssen mentale Anstrengungen unternehmen, um die Logik der Verarbeitung einer einzelnen Anforderung zu rekonstruieren.
Durch die Einführung von Multitasking in unseren Code (die Logik, Arbeitsaufgaben auszuwählen und zu multiplexen) erhalten wir effektiven Code und Kontrolle über die Priorisierung von Aufgaben, verlieren jedoch viele davon an Lesbarkeit. Dieser Code ist schwer zu lesen und schwer zu pflegen.

Warum? Angenommen, ich habe einen einfachen Fall, zum Beispiel, ich lese eine Datei und übertrage sie über das Netzwerk. In einer nicht blockierenden Version entspricht dieser Fall einer solchen linearen Zustandsmaschine:
- Ausgangszustand
- Beginnen Sie mit dem Lesen einer Datei.
- Warten auf eine Antwort vom Dateisystem,
- Schreiben einer Datei in einen Socket,
- Endzustand.
Angenommen, ich möchte dieser Datei Informationen aus der Datenbank hinzufügen. Eine einfache Option:
- Ausgangszustand
- eine Datei lesen
- Lesen Sie die Datei
- Lesen aus der Datenbank
- aus der Datenbank lesen,
- Ich arbeite mit einer Steckdose
- schrieb an die Steckdose.
Es scheint ein linearer Code zu sein, aber die Anzahl der Zustände hat zugenommen.
Dann denken Sie, dass es schön wäre, die beiden Schritte zu parallelisieren - Lesen aus einer Datei und aus einer Datenbank. Die Wunder der Kombinatorik beginnen: Sie befinden sich im Ausgangszustand und fordern das Lesen der Datei und der Daten aus der Datenbank an. Dann können Sie entweder in einen Zustand gelangen, in dem Daten aus der Datenbank vorhanden sind, aber keine Datei vorhanden ist, oder umgekehrt - es gibt Daten aus der Datei, jedoch nicht aus der Datenbank. Als nächstes müssen Sie in einen Zustand gehen, in dem Sie eines von zwei Dingen haben. Auch dies sind zwei Zustände. Dann müssen Sie in einen Zustand gehen, in dem Sie beide Zutaten haben. Dann schreiben Sie sie in die Steckdose und so weiter.
Je komplexer die Anwendung, desto mehr Zustände, desto mehr Codefragmente müssen in Ihrem Kopf kombiniert werden. Unbequem. Oder Sie schreiben Rückrufnudeln, deren Lesen unpraktisch ist. Wenn ein Verzweigungssystem geschrieben wird, kommt eines Tages eine Zeit, in der Sie es nicht länger tolerieren können.
5. Futures / Versprechen
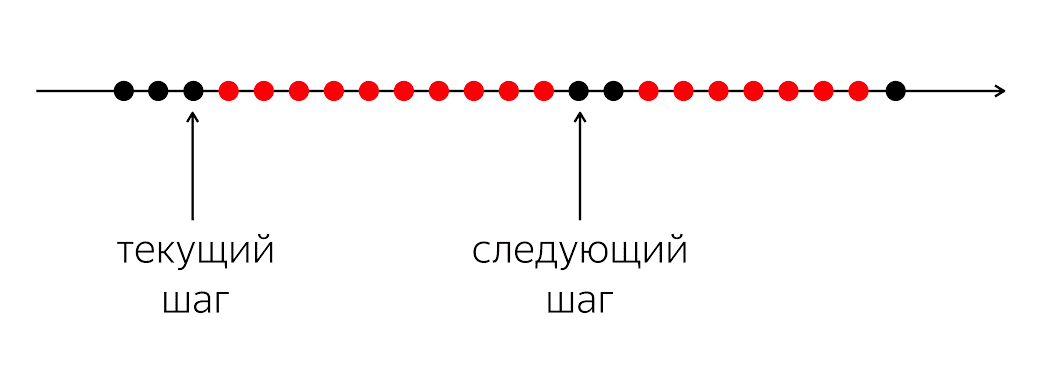
Um das Problem zu lösen, müssen Sie die Situation einfacher betrachten.

Es gibt ein Programm, es hat schwarze und rote Kreise. Unser Hinrichtungsfluss sind schwarze Kreise; manchmal wechseln sie sich mit rot ab, wenn der Stream seine Arbeit nicht fortsetzen kann. Das Problem ist, dass Sie für unseren schwarzen Ausführungsfaden in den nächsten schwarzen Kreis gelangen müssen, der nicht bekannt ist, wann.
Das Problem ist, dass wir dem Computer beim Schreiben von Code in einer Programmiersprache erklären, was jetzt zu tun ist. Ein Computer ist eine relativ einfache Sache, die Anweisungen erwartet, die wir in der Programmiersprache schreiben. Sie wartet auf Anweisungen für den nächsten Kreis, und in unserer Programmiersprache gibt es nicht genug Geld, um zu sagen: "Bitte tun Sie in Zukunft etwas, wenn etwas passiert."

In einer Programmiersprache arbeiten wir mit verständlichen momentanen Aktionen: Aufrufen einer Funktion, arithmetische Operationen usw. Sie beschreiben den spezifischen nächsten nächsten Schritt. Gleichzeitig muss zur Verarbeitung der Anwendungslogik nicht der nächste physische Schritt, sondern der nächste logische Schritt beschrieben werden: Was ist zu tun, wenn beispielsweise Daten aus der Datenbank angezeigt werden?
Daher brauchen wir einen Mechanismus, um diese Fragmente zu kombinieren. In dem Fall, als wir synchronen Code geschrieben haben, haben wir die Frage vollständig unter der Haube versteckt und gesagt, dass das Betriebssystem damit umgehen würde, es erlauben würde, unsere Threads zu unterbrechen und neu zu planen.
In Level 1 haben wir die Büchse dieser Pandora geöffnet und sie hat eine Menge Schalter, Groß- und Kleinschreibung, Bedingungen, Verzweigungen und Zustände in den Code gebracht. Ich möchte einen Kompromiss, damit der Code relativ lesbar ist, aber alle Vorteile von Level 1 beibehält.
Zum Glück haben Barbara Liskov und Luba Shirir, die 1988 an verteilten Systemen beteiligt waren, das Problem erkannt und festgestellt, dass sprachliche Änderungen erforderlich sind. Es ist notwendig, der Programmiersprache Konstrukte hinzuzufügen, die es ermöglichen, zeitliche Beziehungen zwischen Ereignissen auszudrücken - zum aktuellen Zeitpunkt und zu einem ungewissen Zeitpunkt in der Zukunft.
Diese werden Versprechen genannt. Das Konzept ist cool, aber seit zwanzig Jahren verstaubt es in einem Regal. — , Twitter, Ruby on Rails Scala, , , , future . Your Server as a Function. , .
Scala, , ++ ?
, Future. T c : , - .
template <class T> class Future <T>
, , , . , «», , . Future «», Promise — «». ; , JavaScript, Promise — , Java – Future.
, . , , boost::future ( std::future) — , .
5.1. Future & Promise
template <class T> class Future { bool IsSet() const; const T& Get() const; T* TryGet() const; void Subscribe(std::function<void(const T&)> cb); template <class R> Future<R> Then( std::function<R(const T&)> f); template <class R> Future<R> Then( std::function<Future<R>(const T&)> f); }; template <class T> Future<T> MakeFuture(const T& value);
, , - , . , , , . , , — , , . Then, .
template <class T> class Promise { bool IsSet() const; void Set(const T& value); bool TrySet(const T& value); Future<T> ToFuture() const; }; template <class T> Promise<T> NewPromise();
. , . «, , , ».
5.2.
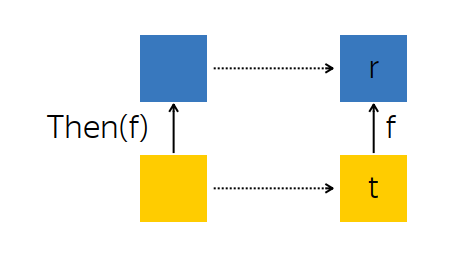
? , . Then — , .
, — future --, - t — . , , , f, - r.
t f. , , r.
: t, , r . :
template <class T> template <class R> Future<R> Future<T>::Then(std::function<R(const T&)> f) { auto promise = NewPromise<R>(); this->Subscribe([promise] (const T& t) { auto r = f(t); promise.Set(r); }); return promise.ToFuture(); }
:
Promise R ,Future<T> t ,- ,
r = f(t) , r Promise ,Promise .
f , R , Future<R> , R . :
template <class T> template <class R> Future<R> Future<T>::Then(std::function<Future<R>(const T&)> f) { auto promise = NewPromise<R>(); this->Subscribe([promise] (const T& t) { auto that = f(t); that.Subscribe([promise] (R r) { promise.Set(r); }); }); return promise.ToFuture(); }
, - t. f, r, . , , .

, Then :
Promise ,Subscribe -,Promise , Future .
, . , , , .
, , , -. , , -, Subscribe. , , , - . , .
5.3. Beispiele
AsyncComputeValue, GPU, . Then, , (2v+1) 2 .
Future<int> value = AsyncComputeValue();
. , : (2v+1) 2 . , .
, , . .
. : , ; ; .
Future<int> GetDbKey(); Future<string> LoadDbValue(int key); Future<void> SendToMars(string message); Future<void> ExploreOuterSpace() { return GetDbKey()
— ExploreOuterSpace. Then; — — , . ( ) . .
5.4. Any-
: Future , , . , , :
template <class T> Future<T> Any(Future<T> f1, Future<T> f2) { auto promise = NewPromise<T>(); f1.Subscribe([promise] (const T& t) { promise.TrySet(t); }); f2.Subscribe([promise] (const T& t) { promise.TrySet(t); }); return promise.ToFuture(); }
, Any-, Future : , . , , .
, , , , , . « DB1, DB2, — - ».
5.5. All-
. , , , ( T1 T2), T1 T2 , , .
template <class T1, class T2> Future<std::tuple<T1, T2>> All(Future<T1> f1, Future<T2> f2) { auto promise = NewPromise<std::tuple<T1, T2>>(); auto result = std::make_shared< std::tuple<T1, T2> >(); auto counter = std::make_shared< std::atomic<int> >(2); f1.Subscribe([promise, result, counter] (const T1& t1) { std::get<0>(*result) = t1; if (--(*counter) == 0) { promise.Set(*result)); } }); f2.Subscribe([promise, result, counter] (const T2& t2) { } return promise.ToFuture(); }
nginx. , , . nginx « », « », « » . All- , . .
5.6.
Future Promises — legacy-, . callback- , , : Future, , callback- Future.
: , Future .
6.
, , . .
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp);
. Request, - . , . , , , . , - .
, , . Was zu tun ist? — , request payload, — , .
, Java Netty. , , . , , .
, GetRequest, QueryBackend, HandlePayload Reply , Future.
, , Future T — WaitFor.
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future);
:
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); auto req = WaitFor(GetRequest()); auto pld = WaitFor(QueryBackend(req)); auto rsp = WaitFor(HandlePayload(pld)); WaitFor(Reply(req, rsp));
: Future, . . , . .
. . - 0, , , mutex+cvar future. . , .

6.1.
, . , , , , - , . , - .
— «» , , . . . : boost::asio boost::fiber.
, . Wie kann man das machen?
6.2. WaitFor
, , boost::context, : , ; , . x86/64 , , .
, goto: , , , .
, - . Fiber — . +Future. , , Future, .
class Fiber { MachineContext context_; Future<void> future_; };
class Scheduler { void WaitFor(Future<void> future); void Loop(); MachineContext loop_context_; Fiber* current_fiber_; std::deque<Fiber*> run_queue_; };
Future , , , . : Loop, , , , , .
WaitFor?
thread_local Scheduler* ThisScheduler; template <class T> T WaitFor(Future<T> future) { ThisScheduler->WaitFor(future.As<void>()); return future.Get(); } void Scheduler::WaitFor(Future<void> future) { current_fiber_->future_ = future; SwitchContext(¤t_fiber_->context_, &loop_context_); }
: , - , , Future void, . .
Future<void> , , - .
WaitFor : : « Fiber Future», ( ) .
, :
ThisScheduler->WaitFor return future.Get() , .
? , Future, .
6.3.
- , , , - , . SwitchContext , 2 — .
void Scheduler::Loop() { while (true) {
? , , , Future, Future, , , .
void Scheduler::Loop() { while (true) {
, . :
WaitFor — .

Switch- .

Future ( ), , . - Fiber.

WaitFor Future , - , Future . :
Future<Request> GetRequest(); Future<Payload> QueryBackend(Request req); Future<Response> HandlePayload(Payload pld); Future<void> Reply(Request req, Response rsp); template <class T> T WaitFor(Future<T> future); auto req = WaitFor( GetRequest()); auto pld = WaitFor( QueryBackend(req)); auto rsp = WaitFor( HandlePayload(pld)); WaitFor( Reply(req, rsp));
, , , . , , .
6.4. Coroutine TS
? — . Coroutine TS, , WaitFor CoroutineWait, CoroutineTS — - . , - . , Waiter Co, , .
7. ?
. , , , . , , , .
— . , . . , . , , , , .
- , , . , . , , .

, ? , .
. , , , , . . , , , , .
nginx, , , , , . , , , future promises.
, , , , , , , .
futures, promises actors. . , .
: , , , . , , , , . ? , .
Minute der Werbung. 19-20 C++ Russia 2019. , , Grimm Rainer «Concurrency and parallelism in C++17 and C++20/23» , C++ . , . , , - .