Seit letztem Jahr werden in unserem Unternehmen Hackathons organisiert. Der erste derartige Wettbewerb war sehr erfolgreich, darüber haben wir im
Artikel geschrieben . Der zweite Hackathon fand im Februar 2019 statt und war nicht weniger erfolgreich. Der Veranstalter hat kürzlich über die Ziele des letzteren geschrieben.
Die Teilnehmer erhielten eine ziemlich interessante Aufgabe mit völliger Freiheit bei der Auswahl eines Technologie-Stacks für dessen Implementierung. Es war erforderlich, eine Entscheidungsplattform für die bequeme Bereitstellung von Kundenbewertungsfunktionen zu implementieren, die für einen schnellen Anwendungsfluss geeignet sind, hohen Belastungen standhalten, und das System selbst konnte problemlos skaliert werden.
Die Aufgabe ist nicht trivial und kann auf viele Arten gelöst werden, wie wir in der Demonstration der Abschlusspräsentationen der Projekte der Teilnehmer gesehen haben. Es waren 6 Teams mit 5 Personen beim Hackathon, alle Teilnehmer hatten gute Projekte, aber unsere Plattform erwies sich als die wettbewerbsfähigste. Wir haben ein sehr interessantes Projekt, über das ich in diesem Artikel sprechen möchte.
Unsere Lösung ist eine Plattform, die auf einer serverlosen Architektur in Kubernetes basiert und die Zeit reduziert, die erforderlich ist, um neue Funktionen in die Produktion zu bringen. Analysten können Code in einer für sie geeigneten Umgebung schreiben und ohne Beteiligung von Ingenieuren und Entwicklern im Produkt bereitstellen.
Was ist Punktzahl?
Tinkoff.ru hat, wie viele moderne Unternehmen, Kundenbewertungen. Scoring ist ein Kundenbewertungssystem, das auf statistischen Methoden der Datenanalyse basiert.
Ein Kunde bittet uns beispielsweise, ihm einen Kredit zu gewähren oder ein IP-Konto bei uns zu eröffnen. Wenn wir ihm einen Kredit gewähren möchten, müssen Sie seine Zahlungsfähigkeit bewerten. Wenn es sich bei dem Konto um Private Equity handelt, müssen Sie sicherstellen, dass der Kunde keine betrügerischen Transaktionen durchführt.
Diese Entscheidungen basieren auf mathematischen Modellen, die sowohl die Daten der Anwendung selbst als auch die Daten unseres Speichers analysieren. Neben der Bewertung können ähnliche statistische Methoden auch in der Arbeit des Dienstes verwendet werden, um individuelle Empfehlungen für neue Produkte für unsere Kunden zu generieren.
Die Methode einer solchen Bewertung kann eine Vielzahl von Eingabedaten erhalten. Und irgendwann können wir der Eingabe einen neuen Parameter hinzufügen, der laut der Analyse historischer Daten die Konvertierung der Nutzung des Dienstes erhöht.
Wir speichern viele Daten zu Kundenbeziehungen, und das Volumen dieser Informationen wächst ständig. Damit die Bewertung funktioniert, sind für die Datenverarbeitung auch Regeln (oder mathematische Modelle) erforderlich, mit denen Sie schnell entscheiden können, wer den Antrag genehmigt, wen er ablehnt und wer noch einige Produkte anbietet, um sein potenzielles Interesse zu bewerten.
Für diese Aufgabe verwenden wir bereits das spezialisierte
IBM WebSphere ILOG JRules BRMS- Entscheidungsfindungssystem, das auf der Grundlage der von Analysten, Technologen und Entwicklern festgelegten Regeln entscheidet, ob ein bestimmtes Bankprodukt einem Kunden genehmigt oder abgelehnt wird.
Es gibt viele vorgefertigte Lösungen auf dem Markt, sowohl Bewertungsmodelle als auch Entscheidungssysteme. Wir verwenden eines dieser Systeme in unserem Unternehmen. Aber das Geschäft wächst und diversifiziert sich, sowohl die Anzahl der Kunden als auch die Anzahl der angebotenen Produkte nehmen zu, und gleichzeitig entstehen Ideen, wie der bestehende Entscheidungsprozess verbessert werden kann. Sicherlich haben Leute, die mit dem vorhandenen System arbeiten, viele Ideen, wie sie es einfacher, besser und bequemer machen können, aber manchmal sind Ideen von außen nützlich. Um fundierte Ideen zu sammeln, wurde ein neuer Hackathon organisiert.
Aufgabe
Der Hackathon fand am 23. Februar statt. Den Teilnehmern wurde eine Kampfmission angeboten: ein Entscheidungsfindungssystem zu entwickeln, das eine Reihe von Bedingungen erfüllen sollte.
Uns wurde gesagt, wie das bestehende System funktioniert und welche Schwierigkeiten während seines Betriebs auftreten und welche Geschäftsziele die in der Entwicklung befindliche Plattform verfolgen sollte. Das System sollte eine schnelle Markteinführungszeit für die Entwicklung von Regeln haben, damit der Arbeitscode der Analysten so schnell wie möglich in Produktion geht. Und für den eingehenden Antragsfluss sollte die Entscheidungszeit auf ein Minimum beschränkt sein. Das entwickelte System sollte auch in der Lage sein, Cross-Selling zu betreiben, um dem Kunden die Möglichkeit zu geben, andere Unternehmensprodukte zu kaufen, wenn diese von uns genehmigt wurden und potenzielle Interessen seitens des Kunden bestehen.
Es ist klar, dass es in einer Nacht unmöglich ist, ein Ready-to-Release-Projekt zu schreiben, das mit Sicherheit in Produktion gehen wird, und das gesamte System ist ziemlich schwer abzudecken, daher wurden wir gebeten, zumindest einen Teil davon zu implementieren. Es wurde eine Reihe von Anforderungen festgelegt, die der Prototyp erfüllen muss. Man könnte versuchen, alle Anforderungen als Ganzes abzudecken und einzelne Abschnitte der entwickelten Plattform detailliert auszuarbeiten.
In Bezug auf die Technologie hatten alle Teilnehmer die völlige Wahlfreiheit. Es konnten alle Konzepte und Technologien verwendet werden: Daten-Streaming, maschinelles Lernen, Event-Sourcing, Big Data und andere.
Unsere Entscheidung
Nach einer kleinen Brainstorming-Sitzung entschieden wir, dass die FaaS-Lösung ideal für diese Aufgabe ist.
Für diese Lösung war es notwendig, ein geeignetes serverloses Framework zur Implementierung der Regeln des entwickelten Entscheidungssystems zu finden. Da Kubernetes in Tinkoff aktiv im Infrastrukturmanagement eingesetzt wird, haben wir mehrere darauf basierende Lösungen untersucht, auf die ich später noch eingehen werde.
Um die effektivste Lösung zu finden, haben wir das entwickelte Produkt mit den Augen seiner Benutzer betrachtet. Die Hauptnutzer unseres Systems sind Analysten, die an der Entwicklung von Regeln beteiligt sind. Regeln müssen auf dem Server bereitgestellt oder, wie in unserem Fall, für spätere Entscheidungen in der Cloud bereitgestellt werden. Aus Sicht des Analysten sieht der Workflow wie folgt aus:
- Der Analyst schreibt ein Skript, eine Regel oder ein ML-Modell basierend auf Daten aus dem Repository. Im Rahmen des Hackathons haben wir uns für Mongodb entschieden, aber die Wahl des Speichersystems ist hier nicht wichtig.
- Nach dem Testen der entwickelten Regeln für historische Daten schüttet der Analyst seinen Code in das Admin-Panel.
- Um die Versionierung sicherzustellen, wird der gesamte Code in Git-Repositorys gespeichert.
- Über das Admin-Panel kann der Code in der Cloud als separates funktionales Serverless-Modul bereitgestellt werden.
Quelldaten von Kunden sollten einen speziellen Enrichment-Service durchlaufen, um die ursprüngliche Anforderung mit Daten aus dem Repository anzureichern. Es war wichtig, diesen Service so zu implementieren, dass er mit einem einzigen Repository funktioniert (aus dem der Analyst bei der Entwicklung der Regeln Daten entnimmt), um eine einheitliche Datenstruktur aufrechtzuerhalten.
Noch vor dem Hackathon haben wir uns für das Serverless Framework entschieden, das wir verwenden werden. Es gibt einige Technologien auf dem Markt, die diesen Ansatz implementieren. Die beliebtesten Kubernetes-Architekturlösungen sind Fission, Open FaaS und Kubeless. Es gibt sogar einen
guten Artikel mit ihrer Beschreibung und vergleichenden Analyse .
Nachdem wir alle Vor- und Nachteile abgewogen hatten, entschieden wir uns für
Fission . Dieses serverlose Framework ist recht einfach zu verwalten und erfüllt die Anforderungen der Aufgabe.
Um mit Fission arbeiten zu können, müssen Sie zwei grundlegende Konzepte verstehen: Funktion und Umgebung. Funktion (Funktion) ist ein Code, der in einer der Sprachen geschrieben ist, für die es eine Fission-Umgebung (Umgebung) gibt.
Die Liste der im Rahmen dieses Frameworks implementierten Umgebungen umfasst Python, JS, Go, JVM und viele andere beliebte Sprachen und Technologien.
Fission kann auch Funktionen ausführen, die in mehrere Dateien unterteilt sind und im Archiv vorinstalliert sind. Die Fission-Operation im Kubernetes-Cluster wird von speziellen Pods bereitgestellt, die vom Framework selbst verwaltet werden. Für die Interaktion mit Cluster-Pods muss jeder Funktion eine Route zugewiesen werden, an die Sie im Falle einer POST-Anforderung GET-Parameter oder Anforderungshauptteile übergeben können.
Aus diesem Grund planten wir eine Lösung, mit der Analysten entwickelte Regelskripte ohne Beteiligung von Ingenieuren und Entwicklern bereitstellen können. Durch den beschriebenen Ansatz müssen Entwickler den Code von Analysten nicht mehr in einer anderen Sprache umschreiben. Für das derzeitige Entscheidungssystem, das wir verwenden, müssen wir beispielsweise Regeln in engmaschigen Technologien und Sprachen schreiben, deren Umfang äußerst begrenzt ist, und es besteht auch eine starke Abhängigkeit vom Anwendungsserver, da alle Entwürfe von Bankregeln in einer einzigen Umgebung bereitgestellt werden. Daher ist es für die Bereitstellung neuer Regeln erforderlich, das gesamte System freizugeben.
In der von uns vorgeschlagenen Lösung müssen die Regeln nicht freigegeben werden. Der Code kann einfach per Knopfdruck bereitgestellt werden. Durch das Infrastrukturmanagement in Kubernetes können Sie auch nicht an die Last und Skalierung denken. Solche Probleme werden sofort gelöst. Durch die Verwendung eines einzelnen Data Warehouse müssen Echtzeitdaten nicht mehr mit historischen Daten verglichen werden, was die Arbeit des Analysten vereinfacht.
Was haben wir bekommen?
Da wir (in unseren Fantasien) mit einer vorgefertigten Lösung zum Hackathon gekommen sind, müssen wir nur alle unsere Gedanken in Codezeilen umwandeln.
Der Schlüssel zum Erfolg bei jedem Hackathon ist die Vorbereitung und ein gut gemachter Plan. Daher haben wir zunächst entschieden, aus welchen Modulen unsere Systemarchitektur bestehen und welche Technologien wir verwenden werden.
Die Architektur unseres Projekts war wie folgt:
Dieses Diagramm zeigt zwei Einstiegspunkte, einen Analysten (den Hauptbenutzer unseres Systems) und einen Kunden.
Der Arbeitsprozess ist so aufgebaut. Der Analyst entwickelt die Regelfunktion und die Datenanreicherungsfunktion für sein Modell, speichert seinen Code im Git-Repository und stellt sein Modell über die Anwendung des Administrators in der Cloud bereit. Überlegen Sie, wie die erweiterte Funktion aufgerufen wird, und treffen Sie Entscheidungen über eingehende Anforderungen von Clients:
- Der Kunde, der auf der Site ein Formular ausfüllt, sendet seine Anfrage an den Controller. Eine Anwendung kommt am Eingang des Systems an, gemäß dem eine Entscheidung getroffen werden muss, und wird in ihrer ursprünglichen Form in der Datenbank aufgezeichnet.
- Als nächstes wird bei Bedarf eine Rohanforderung zur Anreicherung gesendet. Sie können die ursprüngliche Anforderung mit Daten sowohl von externen Diensten als auch vom Repository ergänzen. Die empfangene Rich-Abfrage wird ebenfalls in der Datenbank gespeichert.
- Die Analysefunktion wird gestartet, die an der Eingabe eine erweiterte Anforderung empfängt und eine Entscheidung trifft, die ebenfalls im Repository aufgezeichnet wird.
Als Speicher in unserem System haben wir uns entschieden, MongoDB im Hinblick auf die dokumentierte Speicherung von Daten in Form von JSON-Dokumenten zu verwenden, da Anreicherungsdienste, einschließlich der ersten Anforderung, alle Daten über REST-Controller aggregierten.
Wir hatten also einen Tag Zeit, um die Plattform zu implementieren. Wir haben die Rollen recht erfolgreich verteilt, jedes Teammitglied hatte seinen eigenen Verantwortungsbereich in unserem Projekt:
- Das Frontend-Admin-Panel für die Arbeit des Analysten, über das er die Regeln aus dem Versionskontrollsystem der geschriebenen Skripte herunterladen, die Optionen zum Anreichern der Eingabedaten auswählen und die Regelskripte online bearbeiten kann.
- Ein Backend-Admin-Panel, das eine REST-API für die Front- und VCS-Integration enthält.
- Einrichten der Infrastruktur in Google Cloud und Entwickeln eines Dienstes zur Anreicherung von Quelldaten.
- Das Modul zur Integration der Administratoranwendung in das Serverless Framework für die nachfolgende Bereitstellung der Regeln.
- Skripte mit Regeln zum Testen des Zustands des gesamten Systems und zum Zusammenfassen von Analysen für eingehende Anwendungen (getroffene Entscheidungen) für die endgültige Demonstration.
Beginnen wir in der richtigen Reihenfolge.
Unser Frontend wurde in Angular 7 mit dem Banking UI Kit geschrieben. Die endgültige Version des Admin-Panels war wie folgt:
Da nicht viel Zeit blieb, haben wir versucht, nur die Schlüsselfunktionalität zu implementieren. Um eine Funktion im Kubernetes-Cluster bereitzustellen, musste ein Ereignis ausgewählt werden (ein Dienst, für den Sie eine Regel in der Cloud bereitstellen müssen) und der Code der Funktion codiert werden, die die Entscheidungslogik implementiert. Für jede Bereitstellung der Regel für den ausgewählten Dienst haben wir ein Protokoll dieses Ereignisses geschrieben. Im Admin-Bereich konnten Sie die Protokolle aller Ereignisse anzeigen.
Der gesamte Funktionscode wurde in einem Remote-Git-Repository gespeichert, das ebenfalls im Admin-Bereich festgelegt werden musste. Um den Code zu versionieren, wurden alle Funktionen in verschiedenen Zweigen des Repositorys gespeichert. Das Admin-Panel bietet auch die Möglichkeit, Anpassungen an geschriebenen Skripten vorzunehmen, sodass Sie vor der Bereitstellung einer Funktion für die Produktion nicht nur den geschriebenen Code überprüfen, sondern auch die erforderlichen Änderungen vornehmen können.
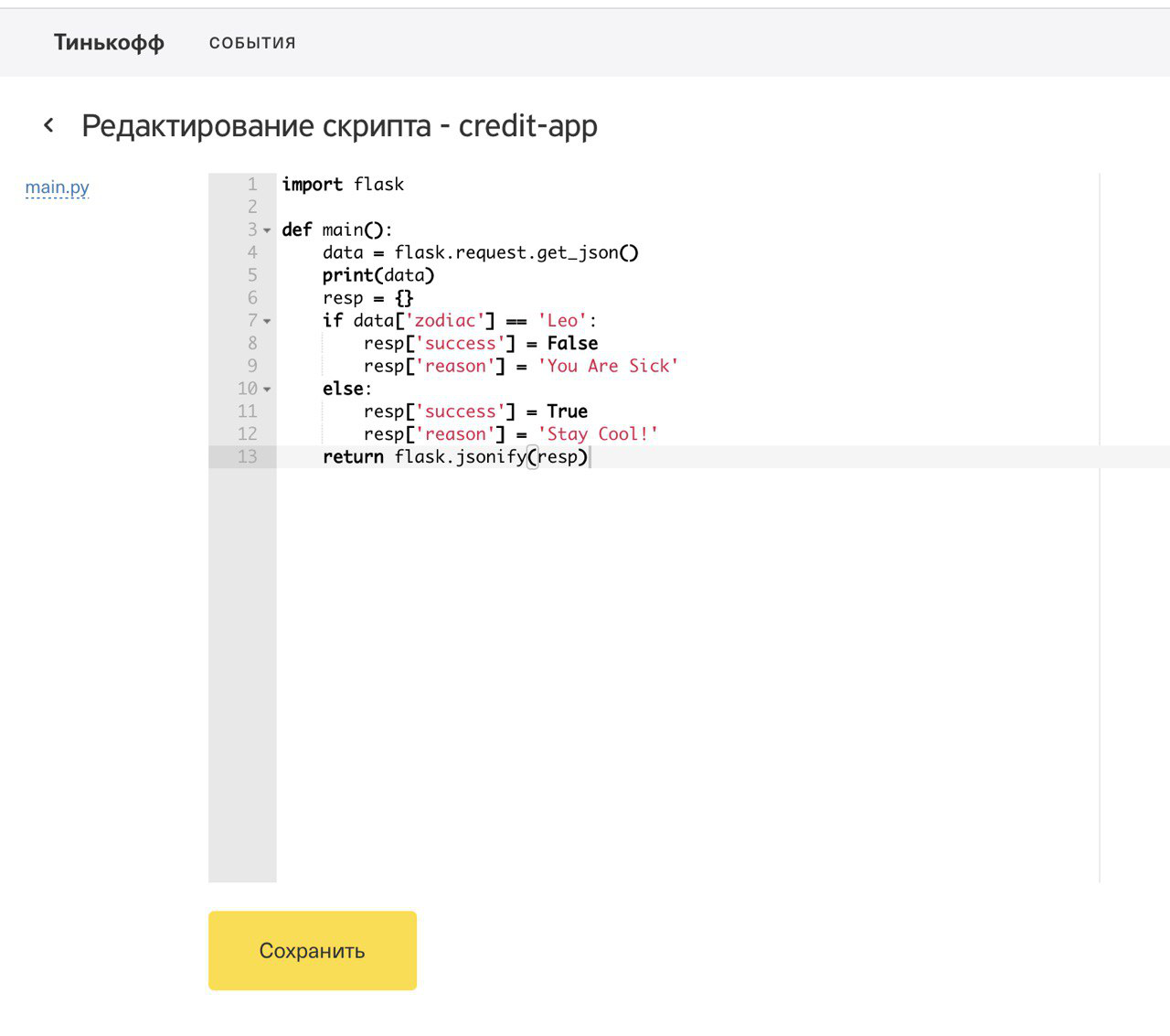
Zusätzlich zu den Funktionen der Regeln haben wir auch die Möglichkeit einer schrittweisen Anreicherung der Quelldaten mithilfe von Anreicherungsfunktionen erkannt, deren Code auch aus Skripten bestand, in denen Sie zum Data Warehouse gehen, Dienste von Drittanbietern aufrufen und vorläufige Berechnungen durchführen konnten. Um unsere Lösung zu demonstrieren, haben wir das Sternzeichen des Kunden berechnet, der die Anwendung verlassen hat, und seinen Mobilfunkbetreiber mithilfe eines REST-Dienstes eines Drittanbieters ermittelt.
Das Plattform-Backend wurde in Java geschrieben und als Spring Boot-Anwendung implementiert. Um die Administratordaten zu speichern, wollten wir ursprünglich Postgres verwenden. Im Rahmen des Hackathons haben wir uns jedoch entschlossen, uns auf einen einfachen H2 zu beschränken, um Zeit zu sparen. Im Backend wurde die Integration mit Bitbucket implementiert, um die Funktionen zur Abfrageanreicherung und Regelskripte zu versionieren. Für die Integration in Remote-Git-Repositorys wurde die
JGit-Bibliothek verwendet , eine Art Wrapper über CLI-Befehle, mit dem Sie alle Git-Anweisungen über eine praktische Programmoberfläche ausführen können. Wir hatten also zwei separate Repositorys für Anreicherungsfunktionen und -regeln, und alle Skripte sind in Verzeichnissen angeordnet. Über die Benutzeroberfläche konnte das letzte Festschreibungsskript eines beliebigen Repository-Zweigs ausgewählt werden. Bei Änderungen am Code über das Admin-Panel wurden Commits des geänderten Codes in den Remote-Repositorys erstellt.
Um unsere Idee umzusetzen, brauchten wir eine geeignete Infrastruktur. Wir haben uns entschieden, unseren Kubernetes-Cluster in der Cloud bereitzustellen. Unsere Wahl ist Google Cloud Platform. Das Fless-Framework ohne Server wurde auf dem Kubernetes-Cluster installiert, den wir für Gcloud bereitgestellt haben. Anfänglich wurde der Quelldatenanreicherungsdienst von einer separaten Java-Anwendung implementiert, die in einem Pod in einem k8s-Cluster eingeschlossen war. Nach einer vorläufigen Demonstration unseres Projekts mitten im Hackathon wurde uns jedoch empfohlen, den Enrichment-Service flexibler zu gestalten, um die Möglichkeit zu bieten, zu entscheiden, wie die Rohdaten eingehender Anwendungen angereichert werden sollen. Und wir hatten keine andere Wahl, als den Anreicherungsservice auch serverlos zu machen.
Für die Arbeit mit Fission haben wir die Fission-CLI verwendet, die über der Kubernetes-CLI installiert werden muss. Das Bereitstellen von Funktionen im k8s-Cluster ist recht einfach. Sie müssen der Funktion nur eine interne Route und einen internen Eingang zuweisen, um eingehenden Datenverkehr zuzulassen, wenn Zugriff außerhalb des Clusters erforderlich ist. Das Bereitstellen einer Funktion dauert normalerweise nicht länger als 10 Sekunden.
Abschlussshow des Projekts und Zusammenfassung
Um die Funktionsweise unseres Systems zu demonstrieren, haben wir auf einem Remote-Server ein einfaches Formular bereitgestellt, auf dem Sie eines der Produkte der Bank beantragen können. Für die Anfrage mussten Sie Ihre Initialen, Ihr Geburtsdatum und Ihre Telefonnummer eingeben.
Die Daten aus dem Client-Formular gingen an den Controller, der gleichzeitig Anwendungen für alle verfügbaren Regeln sendete, die Daten gemäß den angegebenen Bedingungen voranreicherte und in einem gemeinsamen Speicher speicherte. Insgesamt haben wir drei Entscheidungsfunktionen für eingehende Anwendungen und vier Datenanreicherungsdienste bereitgestellt. Nach dem Absenden der Bewerbung erhielt der Kunde unsere Lösung:
Neben der Ablehnung oder Genehmigung erhielt der Kunde auch eine Liste anderer Produkte, für die wir parallel Anfragen gesendet haben. Daher haben wir die Möglichkeit eines Cross-Sale auf unserer Plattform demonstriert.
Insgesamt standen 3 erfundene Bankprodukte zur Verfügung:
- Gutschrift
- Spielzeug
- Hypothek
Während jeder Demonstration haben wir vorbereitete Funktionen und Anreicherungsskripte für jeden Service bereitgestellt.
Jede Regel benötigte einen eigenen Satz von Eingabedaten. Um die Hypothek zu genehmigen, haben wir das Sternzeichen des Kunden berechnet und dieses mit der Logik des Mondkalenders verknüpft. Um das Spielzeug zu genehmigen, haben wir überprüft, ob der Kunde das Alter der Mehrheit erreicht hat, und um ein Darlehen zu vergeben, haben wir eine Anfrage an einen externen offenen Dienst zur Bestimmung des Mobilfunkbetreibers gesendet und eine Entscheidung darüber getroffen.
Wir haben versucht, unsere Demonstration interessant und interaktiv zu gestalten. Jeder Anwesende konnte in unsere Form gehen und die Verfügbarkeit unserer imaginären Dienste für ihn überprüfen. Ganz am Ende der Präsentation haben wir die Analyse der eingegangenen Anträge demonstriert, wobei gezeigt wurde, wie viele Personen unseren Service genutzt haben, wie viele Genehmigungen und Ablehnungen.
Um Analysen online zu sammeln, haben wir zusätzlich das Open-Source-BI-Tool
Metabase bereitgestellt und in unser Repository geschraubt. Mit Metabase können Sie Bildschirme mit Analysen erstellen, die auf den Daten basieren, an denen wir interessiert sind. Sie müssen lediglich eine Verbindung zur Datenbank registrieren, Tabellen auswählen (in unserem Fall Datensammlungen, da wir MongoDB verwendet haben) und die für uns interessanten Felder angeben.
Als Ergebnis haben wir einen guten Prototyp der Entscheidungsplattform erhalten, und bei der Demonstration konnte jeder Zuhörer seine Leistung persönlich testen. Eine interessante Lösung, ein vorgefertigter Prototyp und eine erfolgreiche Demonstration haben es uns ermöglicht, trotz der starken Konkurrenz gegenüber anderen Teams zu gewinnen. Ich bin sicher, dass Sie über das Projekt jedes Teams auch einen interessanten Artikel schreiben können.