Die Verarbeitung natürlicher Sprache wird nur noch in sehr konservativen Bereichen verwendet. In den meisten technologischen Lösungen ist die Erkennung und Verarbeitung von „menschlichen“ Sprachen seit langem eingeführt: Aus diesem Grund gehört die übliche IVR mit fest codierten Antwortoptionen allmählich der Vergangenheit an, Chatbots beginnen ohne die Teilnahme eines Live-Betreibers angemessener zu kommunizieren, Mail-Filter arbeiten mit einem Knall usw. Wie ist die Erkennung von aufgezeichneter Sprache, dh Text? Oder vielmehr, auf welcher Grundlage werden moderne Erkennungs- und Verarbeitungstechniken eingesetzt? Unsere heutige angepasste Übersetzung reagiert gut darauf - unter dem Schnitt finden Sie einen Longride, der die Lücken in den Grundlagen von NLP schließt. Viel Spaß beim Lesen!
Was ist die Verarbeitung natürlicher Sprache?
Verarbeitung natürlicher Sprache (im Folgenden: NLP) - Die Verarbeitung natürlicher Sprache ist ein Unterabschnitt der Informatik und KI, der sich mit der Analyse natürlicher (menschlicher) Sprachen durch Computer befasst. NLP ermöglicht die Verwendung von Algorithmen für maschinelles Lernen für Text und Sprache.
Zum Beispiel können wir NLP verwenden, um Systeme wie Spracherkennung, Verallgemeinerung von Dokumenten, maschinelle Übersetzung, Spam-Erkennung, Erkennung benannter Entitäten, Antworten auf Fragen, automatische Vervollständigung, vorausschauende Texteingabe usw. zu erstellen.
Heutzutage haben viele von uns Spracherkennungs-Smartphones - sie verwenden NLP, um unsere Sprache zu verstehen. Außerdem verwenden viele Benutzer Laptops mit integrierter Spracherkennung im Betriebssystem.
Beispiele
Cortana
Windows verfügt über einen virtuellen Cortana-Assistenten, der Sprache erkennt. Mit Cortana können Sie Erinnerungen erstellen, Anwendungen öffnen, Briefe senden, Spiele spielen, das Wetter herausfinden usw.
Siri
Siri ist Assistent für Apples Betriebssystem: iOS, watchOS, macOS, HomePod und tvOS. Viele Funktionen funktionieren auch über die Sprachsteuerung: jemanden anrufen / schreiben, eine E-Mail senden, einen Timer einstellen, ein Foto aufnehmen usw.
Google Mail
Ein bekannter E-Mail-Dienst erkennt Spam, damit er nicht in den Posteingang Ihres Posteingangs gelangt.
Dialogfluss
Eine Plattform von Google, mit der Sie NLP-Bots erstellen können. Sie können beispielsweise einen Pizza-Bestellbot erstellen
, für dessen Annahme keine altmodische IVR erforderlich ist .
NLTK Python Library
NLTK (Natural Language Toolkit) ist eine führende Plattform zum Erstellen von NLP-Programmen in Python. Es verfügt über benutzerfreundliche Schnittstellen für viele
Sprachfälle sowie Bibliotheken für die Textverarbeitung zur Klassifizierung, Tokenisierung,
Stemming ,
Markup , Filterung und zum
semantischen Denken . Nun, und dies ist ein kostenloses Open Source-Projekt, das mit Hilfe der Community entwickelt wird.
Wir werden dieses Tool verwenden, um die Grundlagen von NLP zu zeigen. Für alle nachfolgenden Beispiele gehe ich davon aus, dass NLTK bereits importiert wurde. Dies kann mit dem
import nltkNLP-Grundlagen für Text
In diesem Artikel werden wir folgende Themen behandeln:
- Tokenisierung durch Angebote.
- Tokenisierung durch Worte.
- Lemmatisierung und Stempelung des Textes.
- Hör auf mit Worten.
- Reguläre Ausdrücke.
- Tasche voller Wörter .
- TF-IDF .
1. Tokenisierung durch Angebote
Bei der Tokenisierung (manchmal Segmentierung) von Sätzen wird eine geschriebene Sprache in Komponentensätze unterteilt. Die Idee sieht ziemlich einfach aus. In Englisch und einigen anderen Sprachen können wir einen Satz jedes Mal isolieren, wenn wir ein bestimmtes Interpunktionszeichen finden - einen Punkt.
Aber auch auf Englisch ist diese Aufgabe nicht trivial, da der Punkt auch in Abkürzungen verwendet wird. Die Abkürzungstabelle kann bei der Textverarbeitung sehr hilfreich sein, um zu vermeiden, dass Satzgrenzen falsch platziert werden. In den meisten Fällen werden dafür Bibliotheken verwendet, sodass Sie sich nicht wirklich um Implementierungsdetails kümmern müssen.
Ein Beispiel:Nehmen Sie einen kurzen Text über das Backgammon-Brettspiel:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
Um die Tokenisierung von Angeboten mithilfe von NLTK
nltk.sent_tokenize , können Sie die Methode
nltk.sent_tokenize verwenden
| text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice." |
| sentences = nltk.sent_tokenize(text) |
| for sentence in sentences: |
| print(sentence) |
| print() |
Am Ausgang erhalten wir 3 separate Sätze:
Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice.
2. Tokenisierung nach Worten
Tokenisierung (manchmal Segmentierung) nach Wörtern ist der Prozess des Teilens von Sätzen in einzelne Wörter. In Englisch und vielen anderen Sprachen, die die eine oder andere Version des lateinischen Alphabets verwenden, ist ein Leerzeichen ein gutes Worttrennzeichen.
Probleme können jedoch auftreten, wenn wir nur ein Leerzeichen verwenden. Im Englischen werden zusammengesetzte Substantive unterschiedlich geschrieben und manchmal durch Leerzeichen getrennt. Und hier helfen uns wieder Bibliotheken.
Ein Beispiel:Nehmen wir die Sätze aus dem vorherigen Beispiel und wenden die Methode
nltk.word_tokenize auf sie an
| for sentence in sentences: |
| words = nltk.word_tokenize(sentence) |
| print(words) |
| print() |
Fazit:
['Backgammon', 'is', 'one', 'of', 'the', 'oldest', 'known', 'board', 'games', '.'] ['Its', 'history', 'can', 'be', 'traced', 'back', 'nearly', '5,000', 'years', 'to', 'archeological', 'discoveries', 'in', 'the', 'Middle', 'East', '.'] ['It', 'is', 'a', 'two', 'player', 'game', 'where', 'each', 'player', 'has', 'fifteen', 'checkers', 'which', 'move', 'between', 'twenty-four', 'points', 'according', 'to', 'the', 'roll', 'of', 'two', 'dice', '.']
3. Lemmatisierung und Stempelung des Textes
Normalerweise enthalten Texte unterschiedliche grammatikalische Formen desselben Wortes, und es können auch Wörter mit einer Wurzel vorkommen. Lemmatisierung und Stemming zielen darauf ab, alle vorkommenden Wortformen zu einer einzigen, normalen Vokabularform zusammenzuführen.
Beispiele:Verschiedene Wortformen zu einer bringen:
dog, dogs, dog's, dogs' => dog
Das gleiche, aber mit Bezug auf den ganzen Satz:
the boy's dogs are different sizes => the boy dog be differ size
Lemmatisierung und Stemming sind Sonderfälle der Normalisierung und unterscheiden sich.
Stemming ist ein grober heuristischer Prozess, der „Überschüsse“ von der Wortwurzel abschneidet. Dies führt häufig zum Verlust von Suffixen zur Wortbildung.
Die Lemmatisierung ist ein subtilerer Prozess, bei dem Vokabeln und morphologische Analysen verwendet werden, um das Wort letztendlich in seine kanonische Form zu bringen - das Lemma.
Der Unterschied besteht darin, dass der Stemmer (eine spezifische Implementierung des Stemming-Algorithmus - Übersetzerkommentar) ohne Kenntnis des Kontexts arbeitet und dementsprechend den Unterschied zwischen Wörtern, die je nach Wortart unterschiedliche Bedeutungen haben, nicht versteht. Die Stemmers haben jedoch ihre eigenen Vorteile: Sie sind einfacher zu implementieren und arbeiten schneller. Außerdem spielt eine geringere „Genauigkeit“ in einigen Fällen möglicherweise keine Rolle.
Beispiele:- Das Wort gut ist ein Lemma für das Wort besser. Stemmer wird diese Verbindung nicht sehen, da Sie hier das Wörterbuch konsultieren müssen.
- Das Wortspiel ist die Grundform des Wortspiels. Hier werden sowohl Stemming als auch Lemmatisierung bewältigt.
- Das Wort Treffen kann je nach Kontext entweder eine normale Form eines Substantivs oder eine Form des zu treffenden Verbs sein. Im Gegensatz zum Stemming wird bei der Lemmatisierung versucht, das richtige Lemma basierend auf dem Kontext auszuwählen.
Nachdem wir nun wissen, was der Unterschied ist, schauen wir uns ein Beispiel an:
| from nltk.stem import PorterStemmer, WordNetLemmatizer |
| from nltk.corpus import wordnet |
| |
| def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos): |
| """ |
| Print the results of stemmind and lemmitization using the passed stemmer, lemmatizer, word and pos (part of speech) |
| """ |
| print("Stemmer:", stemmer.stem(word)) |
| print("Lemmatizer:", lemmatizer.lemmatize(word, pos)) |
| print() |
| |
| lemmatizer = WordNetLemmatizer() |
| stemmer = PorterStemmer() |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "seen", pos = wordnet.VERB) |
| compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "drove", pos = wordnet.VERB) |
Fazit:
Stemmer: seen Lemmatizer: see Stemmer: drove Lemmatizer: drive
4. Stoppen Sie Wörter
Stoppwörter sind Wörter, die vor / nach der Textverarbeitung aus dem Text geworfen werden. Wenn wir maschinelles Lernen auf Texte anwenden, können solche Wörter viel Lärm verursachen, sodass Sie irrelevante Wörter entfernen müssen.
Stoppwörter werden normalerweise von Artikeln, Interjektionen, Gewerkschaften usw. verstanden, die keine semantische Last tragen. Es versteht sich, dass es keine universelle Liste von Stoppwörtern gibt, alles hängt vom jeweiligen Fall ab.
NLTK verfügt über eine vordefinierte Liste von Stoppwörtern. Vor der ersten Verwendung müssen Sie es herunterladen:
nltk.download(“stopwords”) . Nach dem Herunterladen können Sie das
stopwords importieren und die Wörter selbst
stopwords :
| from nltk.corpus import stopwords |
| print(stopwords.words("english")) |
Fazit:
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
Überlegen Sie, wie Sie Stoppwörter aus einem Satz entfernen können:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [word for word in words if not word in stop_words] |
| print(without_stop_words) |
Fazit:
['Backgammon', 'one', 'oldest', 'known', 'board', 'games', '.']
Wenn Sie mit Listenverständnissen nicht vertraut sind, erfahren Sie hier mehr. Hier ist ein anderer Weg, um das gleiche Ergebnis zu erzielen:
| stop_words = set(stopwords.words("english")) |
| sentence = "Backgammon is one of the oldest known board games." |
| |
| words = nltk.word_tokenize(sentence) |
| without_stop_words = [] |
| for word in words: |
| if word not in stop_words: |
| without_stop_words.append(word) |
| |
| print(without_stop_words) |
Denken Sie jedoch daran, dass das Listenverständnis schneller ist, weil es optimiert ist. Der Interpreter zeigt während der Schleife ein Vorhersagemuster an.
Sie fragen sich vielleicht, warum wir die Liste in
viele konvertiert haben. Ein Satz ist ein abstrakter Datentyp, der eindeutige Werte in einer undefinierten Reihenfolge speichern kann. Die Suche nach Set ist viel schneller als das Durchsuchen einer Liste. Für eine kleine Anzahl von Wörtern spielt dies keine Rolle, aber wenn wir über eine große Anzahl von Wörtern sprechen, wird die Verwendung von Mengen dringend empfohlen. Wenn Sie mehr über die Zeit erfahren möchten, die für die Durchführung verschiedener Operationen erforderlich ist, sehen Sie sich
diesen wunderbaren Spickzettel an .
5. Reguläre Ausdrücke.
Ein regulärer Ausdruck (Regex, Regexp, Regex) ist eine Folge von Zeichen, die ein Suchmuster definiert. Zum Beispiel:
- . - jedes Zeichen außer Zeilenvorschub;
- \ w ist ein Wort;
- \ d - eine Ziffer;
- \ s - ein Leerzeichen;
- \ W ist ein NICHT-Wort;
- \ D - eine nichtstellige Zahl;
- \ S - ein Nicht-Leerzeichen;
- [abc] - stellt fest, dass eines der angegebenen Zeichen mit a, b oder c übereinstimmt;
- [^ abc] - findet ein beliebiges Zeichen außer den angegebenen;
- [ag] - Findet ein Zeichen im Bereich von a bis g.
Auszug aus der
Python-Dokumentation :
Reguläre Ausdrücke verwenden den Backslash (\) , um Sonderformen anzugeben oder die Verwendung von Sonderzeichen zu ermöglichen. Dies widerspricht der Verwendung des Backslash in Python: '\\\\' beispielsweise den Backslash wörtlich zu bezeichnen, müssen Sie '\\\\' als Suchmuster schreiben, da der reguläre Ausdruck wie \\ aussehen sollte, wobei jeder Backslash maskiert werden muss.
Die Lösung besteht darin, die rohe Zeichenfolgennotation für Suchmuster zu verwenden. Backslashes werden nicht speziell verarbeitet, wenn sie mit dem Präfix 'r' . Somit ist r”\n” eine Zeichenfolge mit zwei Zeichen ('\' 'n') , und “\n” ist eine Zeichenfolge mit einem Zeichen (Zeilenvorschub).
Wir können Stammgäste verwenden, um unseren Text weiter zu filtern. Sie können beispielsweise alle Zeichen entfernen, die keine Wörter sind. In vielen Fällen ist keine Interpunktion erforderlich und kann mithilfe von Stammgästen leicht entfernt werden.
Das Modul
re in Python repräsentiert Operationen mit regulären Ausdrücken. Wir können die Funktion
re.sub verwenden, um alles, was zum Suchmuster passt, durch die angegebene Zeichenfolge zu ersetzen. So können Sie alle Nichtwörter durch Leerzeichen ersetzen:
| import re |
| sentence = "The development of snowboarding was inspired by skateboarding, sledding, surfing and skiing." |
| pattern = r"[^\w]" |
| print(re.sub(pattern, " ", sentence)) |
Fazit:
'The development of snowboarding was inspired by skateboarding sledding surfing and skiing '
Stammgäste sind ein leistungsstarkes Werkzeug, mit dem viel komplexere Muster erstellt werden können. Wenn Sie mehr über reguläre Ausdrücke erfahren möchten, kann ich diese beiden Webanwendungen empfehlen:
Regex ,
Regex101 .
6. Tasche voller Wörter
Algorithmen für maschinelles Lernen können nicht direkt mit Rohtext arbeiten, daher müssen Sie den Text in Zahlenmengen (Vektoren) konvertieren. Dies wird als
Merkmalsextraktion bezeichnet .
Eine Worttasche ist eine beliebte und einfache Funktion zum Extrahieren von Funktionen, die beim Arbeiten mit Text verwendet wird. Es beschreibt das Vorkommen jedes Wortes im Text.
Um das Modell verwenden zu können, benötigen wir:
- Definieren Sie ein Wörterbuch bekannter Wörter (Token).
- Wählen Sie den Grad der Präsenz berühmter Wörter.
Alle Informationen über die Reihenfolge oder Struktur von Wörtern werden ignoriert. Deshalb wird es eine TASCHE mit Wörtern genannt. Dieses Modell versucht zu verstehen, ob ein bekanntes Wort in einem Dokument vorkommt, weiß jedoch nicht, wo genau es vorkommt.
Die Intuition legt nahe, dass
ähnliche Dokumente einen
ähnlichen Inhalt haben . Dank des Inhalts können wir auch etwas über die Bedeutung des Dokuments lernen.
Ein Beispiel:Beachten Sie die Schritte zum Erstellen dieses Modells. Wir verwenden nur 4 Sätze, um zu verstehen, wie das Modell funktioniert. Im wirklichen Leben werden Sie auf mehr Daten stoßen.
1. Daten herunterladen
Stellen Sie sich vor, dies sind unsere Daten und wir möchten sie als Array laden:
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
Lesen Sie dazu einfach die Datei und teilen Sie sie durch die Zeile:
| with open("simple movie reviews.txt", "r") as file: |
| documents = file.read().splitlines() |
| |
| print(documents) |
Fazit:
["I like this movie, it's funny.", 'I hate this movie.', 'This was awesome! I like it.', 'Nice one. I love it.']
2. Definieren Sie ein Wörterbuch
Wir werden alle eindeutigen Wörter aus 4 geladenen Sätzen sammeln, wobei Groß- und Kleinschreibung, Interpunktion und Token mit einem Zeichen ignoriert werden. Dies wird unser Wörterbuch sein (berühmte Wörter).
Um ein Wörterbuch zu erstellen, können Sie die
CountVectorizer- Klasse aus der sklearn-Bibliothek verwenden. Fahren Sie mit dem nächsten Schritt fort.
3. Erstellen Sie Dokumentvektoren
Als nächstes müssen wir die Wörter im Dokument bewerten. In diesem Schritt ist es unser Ziel, Rohtext in eine Reihe von Zahlen umzuwandeln. Danach verwenden wir diese Mengen als Eingabe für das Modell des maschinellen Lernens. Die einfachste Bewertungsmethode besteht darin, das Vorhandensein von Wörtern zu notieren, dh 1, wenn ein Wort vorhanden ist, und 0, wenn es nicht vorhanden ist.
Jetzt können wir mit der oben genannten CountVectorizer-Klasse eine Wortsammlung erstellen.
| # Import the libraries we need |
| from sklearn.feature_extraction.text import CountVectorizer |
| import pandas as pd |
| |
| # Step 2. Design the Vocabulary |
| # The default token pattern removes tokens of a single character. That's why we don't have the "I" and "s" tokens in the output |
| count_vectorizer = CountVectorizer() |
| |
| # Step 3. Create the Bag-of-Words Model |
| bag_of_words = count_vectorizer.fit_transform(documents) |
| |
| # Show the Bag-of-Words Model as a pandas DataFrame |
| feature_names = count_vectorizer.get_feature_names() |
| pd.DataFrame(bag_of_words.toarray(), columns = feature_names) |
Fazit:
Dies sind unsere Vorschläge. Jetzt sehen wir, wie das Modell „Bag of Words“ funktioniert.
Ein paar Worte über die Wortsammlung
Die Komplexität dieses Modells besteht darin, wie das Wörterbuch bestimmt und das Auftreten von Wörtern gezählt wird.
Wenn die Wörterbuchgröße zunimmt, wächst auch der Dokumentvektor. Im obigen Beispiel ist die Länge des Vektors gleich der Anzahl bekannter Wörter.
In einigen Fällen können wir eine unglaublich große Datenmenge haben, und dann kann der Vektor aus Tausenden oder Millionen von Elementen bestehen. Darüber hinaus kann jedes Dokument nur einen kleinen Teil der Wörter aus dem Wörterbuch enthalten.
Infolgedessen enthält die Vektordarstellung viele Nullen. Vektoren mit vielen Nullen werden als spärliche Vektoren bezeichnet. Sie erfordern mehr Speicher und Rechenressourcen.
Wir können jedoch die Anzahl der bekannten Wörter reduzieren, wenn wir dieses Modell verwenden, um die Anforderungen an die Rechenressourcen zu verringern. Dazu können Sie dieselben Techniken verwenden, die wir bereits vor dem Erstellen einer Worttasche in Betracht gezogen haben:
- den Fall von Wörtern ignorieren;
- Interpunktion ignorieren;
- Stoppwörter auswerfen;
- Reduktion von Wörtern auf ihre Grundformen (Lemmatisierung und Stemming);
- Korrektur falsch geschriebener Wörter.
Eine andere, kompliziertere Möglichkeit, ein Wörterbuch zu erstellen, besteht darin, gruppierte Wörter zu verwenden. Dadurch wird die Größe des Wörterbuchs geändert und der Worttasche mehr Details zum Dokument hinzugefügt. Dieser Ansatz wird als "
N-Gramm " bezeichnet.
N-Gramm ist eine Folge beliebiger Entitäten (Wörter, Buchstaben, Zahlen, Zahlen usw.). Im Kontext von Sprachkörpern wird das N-Gramm normalerweise als eine Folge von Wörtern verstanden. Ein Unigramm ist ein Wort, ein Bigram ist eine Folge von zwei Wörtern, ein Trigramm ist drei Wörter und so weiter. Die Zahl N gibt an, wie viele gruppierte Wörter im N-Gramm enthalten sind. Nicht alle möglichen N-Gramm fallen in das Modell, sondern nur die, die im Fall erscheinen.
Ein Beispiel:Betrachten Sie den folgenden Satz:
The office building is open today
Hier sind seine Bigramme:
- das Büro
- Bürogebäude
- Gebäude ist
- ist offen
- heute geöffnet
Wie Sie sehen können, ist eine Tüte Bigrams ein effektiverer Ansatz als eine Tüte Wörter.
Bewertung (Bewertung) von WörternWenn ein Wörterbuch erstellt wird, sollte das Vorhandensein von Wörtern bewertet werden. Wir haben bereits einen einfachen binären Ansatz in Betracht gezogen (1 - es gibt ein Wort, 0 - es gibt kein Wort).
Es gibt andere Methoden:
- Menge. Es wird berechnet, wie oft jedes Wort im Dokument erscheint.
- Frequenz Es wird berechnet, wie oft jedes Wort im Text vorkommt (bezogen auf die Gesamtzahl der Wörter).
7. TF-IDF
Die Frequenzbewertung hat ein Problem: Wörter mit der höchsten Frequenz haben jeweils die höchste Bewertung. In diesen Worten gibt es möglicherweise nicht so viel
Informationsgewinn für das Modell wie in weniger häufigen Worten. Eine Möglichkeit, die Situation zu korrigieren, besteht darin, die Wortbewertung zu senken, die häufig
in allen ähnlichen Dokumenten zu finden ist . Dies wird als
TF-IDF bezeichnet .
TF-IDF (kurz für Term Frequency - Inverse Document Frequency) ist ein statistisches Maß zur Bewertung der Wichtigkeit eines Wortes in einem Dokument, das Teil einer Sammlung oder eines Korpus ist.
Die Bewertung durch TF-IDF wächst proportional zur Häufigkeit des Auftretens eines Wortes in einem Dokument. Dies wird jedoch durch die Anzahl der Dokumente ausgeglichen, die dieses Wort enthalten.
Bewertungsformel für das Wort X in Dokument Y:
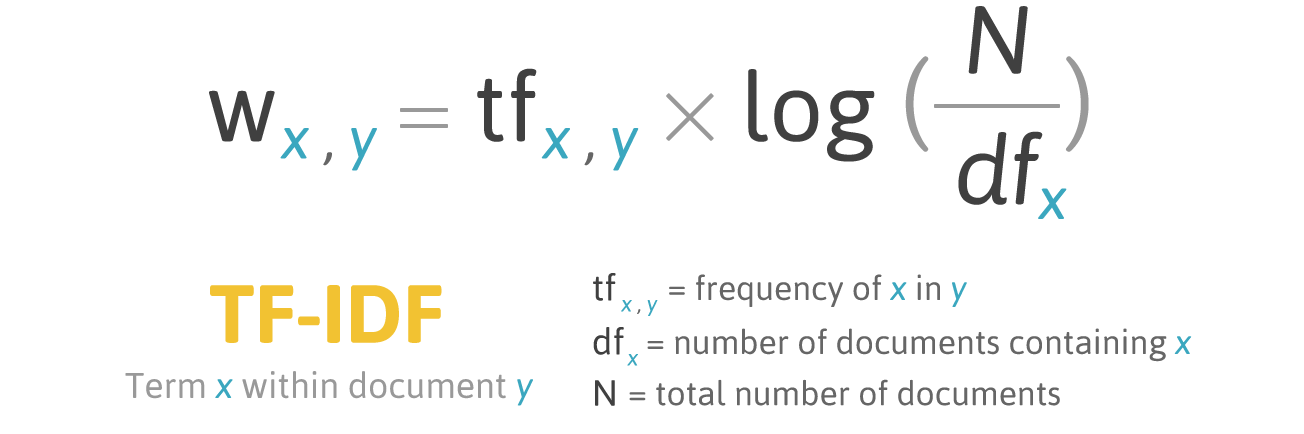 Formel TF-IDF. Quelle: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.html
Formel TF-IDF. Quelle: filotechnologia.blogspot.com/2014/01/a-simple-java-class-for-tfidf-scoring.htmlTF (Termhäufigkeit) ist das Verhältnis der Anzahl der Vorkommen eines Wortes zur Gesamtzahl der Wörter in einem Dokument.
IDF (inverse Dokumenthäufigkeit) ist die Umkehrung der Häufigkeit, mit der ein Wort in Sammlungsdokumenten vorkommt.
Infolgedessen kann TF-IDF für den Wortterm wie folgt berechnet werden:
Ein Beispiel:Sie können die
TfidfVectorizer- Klasse aus der sklearn-Bibliothek verwenden, um TF-IDF zu berechnen. Lassen Sie uns dies mit denselben Nachrichten tun, die wir im Beispiel für die Worttasche verwendet haben.
I like this movie, it's funny. I hate this movie. This was awesome! I like it. Nice one. I love it.
Code:
| from sklearn.feature_extraction.text import TfidfVectorizer |
| import pandas as pd |
| |
| tfidf_vectorizer = TfidfVectorizer() |
| values = tfidf_vectorizer.fit_transform(documents) |
| |
| # Show the Model as a pandas DataFrame |
| feature_names = tfidf_vectorizer.get_feature_names() |
| pd.DataFrame(values.toarray(), columns = feature_names) |
Fazit:
Fazit
Dieser Artikel hat die Grundlagen von NLP für Text behandelt, nämlich:
- NLP ermöglicht die Verwendung von Algorithmen für maschinelles Lernen für Text und Sprache.
- NLTK (Natural Language Toolkit) - eine führende Plattform zum Erstellen von NLP-Programmen in Python;
- Bei der Tokenisierung von Vorschlägen wird eine geschriebene Sprache in einzelne Sätze unterteilt.
- Wort-Tokenisierung ist der Prozess des Teilens von Sätzen in einzelne Wörter;
- Lemmatisierung und Stemming zielen darauf ab, alle Wortformen zu einer einzigen, normalen Vokabularform zusammenzuführen.
- Stoppwörter sind Wörter, die vor / nach der Textverarbeitung aus dem Text geworfen werden.
- Regex (Regex, Regexp, Regex) ist eine Folge von Zeichen, die ein Suchmuster definiert.
- Eine Tüte mit Wörtern ist eine beliebte und einfache Technik zum Extrahieren von Merkmalen, die beim Arbeiten mit Text verwendet wird. Es beschreibt das Vorkommen jedes Wortes im Text.
Großartig! Nachdem Sie die Grundlagen der Merkmalsextraktion kennen, können Sie Merkmale als Eingabe für Algorithmen für maschinelles Lernen verwenden.
Wenn Sie alle beschriebenen Konzepte in einem großen Beispiel sehen möchten, dann
sind Sie hier .