
In unseren Projekten verwenden wir Microservice-Architektur. Wenn Leistungsengpässe auftreten, wird viel Zeit für die Überwachung und Analyse von Protokollen aufgewendet. Wenn die Zeitabläufe einzelner Vorgänge in einer Protokolldatei protokolliert werden, ist es normalerweise schwierig zu verstehen, was zum Aufruf dieser Vorgänge geführt hat, um die Abfolge von Aktionen oder den Zeitversatz eines Vorgangs relativ zu einem anderen in verschiedenen Diensten zu verfolgen.
Um die manuelle Arbeit zu minimieren, haben wir uns für eines der Tracing-Tools entschieden. Wie und wofür es möglich ist, Tracing zu verwenden und wie wir es gemacht haben, und wir werden diesen Artikel diskutieren.
Welche Probleme können mit trace gelöst werden
- Finden Sie Leistungsengpässe sowohl innerhalb eines einzelnen Dienstes als auch im gesamten Ausführungsbaum zwischen allen teilnehmenden Diensten. Zum Beispiel:
- Viele kurze aufeinanderfolgende Aufrufe zwischen Diensten, z. B. zur Geokodierung oder zu einer Datenbank.
- Langes Warten auf Eingaben, z. B. Übertragen von Daten über ein Netzwerk oder Lesen von der Festplatte.
- Lange Datenanalyse.
- Lange Operationen, die CPU erfordern.
- Codeteile, die nicht benötigt werden, um das Endergebnis zu erhalten, und die gelöscht oder verzögert ausgeführt werden können.
- Verstehen Sie klar, in welcher Reihenfolge, was aufgerufen wird und was passiert, wenn die Operation ausgeführt wird.
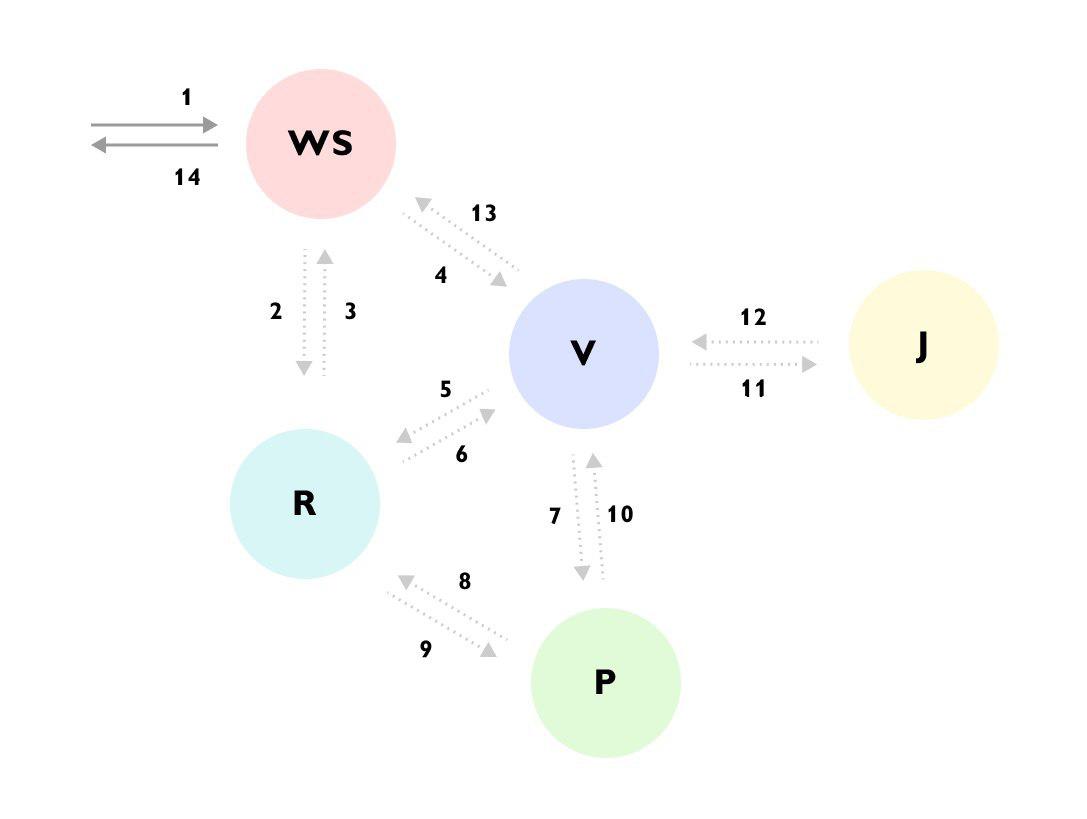
Es ist ersichtlich, dass beispielsweise die Anforderung an den WS-Dienst eingegangen ist -> der WS-Dienst die Daten über den R-Dienst ergänzt hat -> dann die Anforderung an den V-Dienst gesendet hat -> der V-Dienst viele Daten vom R-Dienst geladen hat -> zum P-Dienst gegangen ist -> der P-Dienst wieder ausgeschaltet wurde an den Dienst R -> Dienst V ignorierte das Ergebnis und ging zum Dienst J -> und gab erst dann die Antwort an den WS-Dienst zurück, während im Hintergrund etwas anderes berechnet wurde.
Ohne eine solche Ablaufverfolgung oder detaillierte Dokumentation für den gesamten Prozess ist es sehr schwierig zu verstehen, was passiert, wenn Sie den Code zum ersten Mal betrachten. Der Code ist auf verschiedene Dienste verteilt und hinter einer Reihe von Bins und Schnittstellen versteckt.
- Sammlung von Informationen zum Ausführungsbaum für die nachfolgende ausstehende Analyse. In jeder Ausführungsphase können Sie dem in dieser Phase verfügbaren Trace Informationen hinzufügen und dann herausfinden, welche Eingaben zu einem ähnlichen Szenario geführt haben. Zum Beispiel:
- Benutzer-ID
- Rechte
- Art der ausgewählten Methode
- Protokoll- oder Ausführungsfehler
- Verwandeln Sie Traces in eine Teilmenge von Metriken und analysieren Sie sie weiter als Metriken.
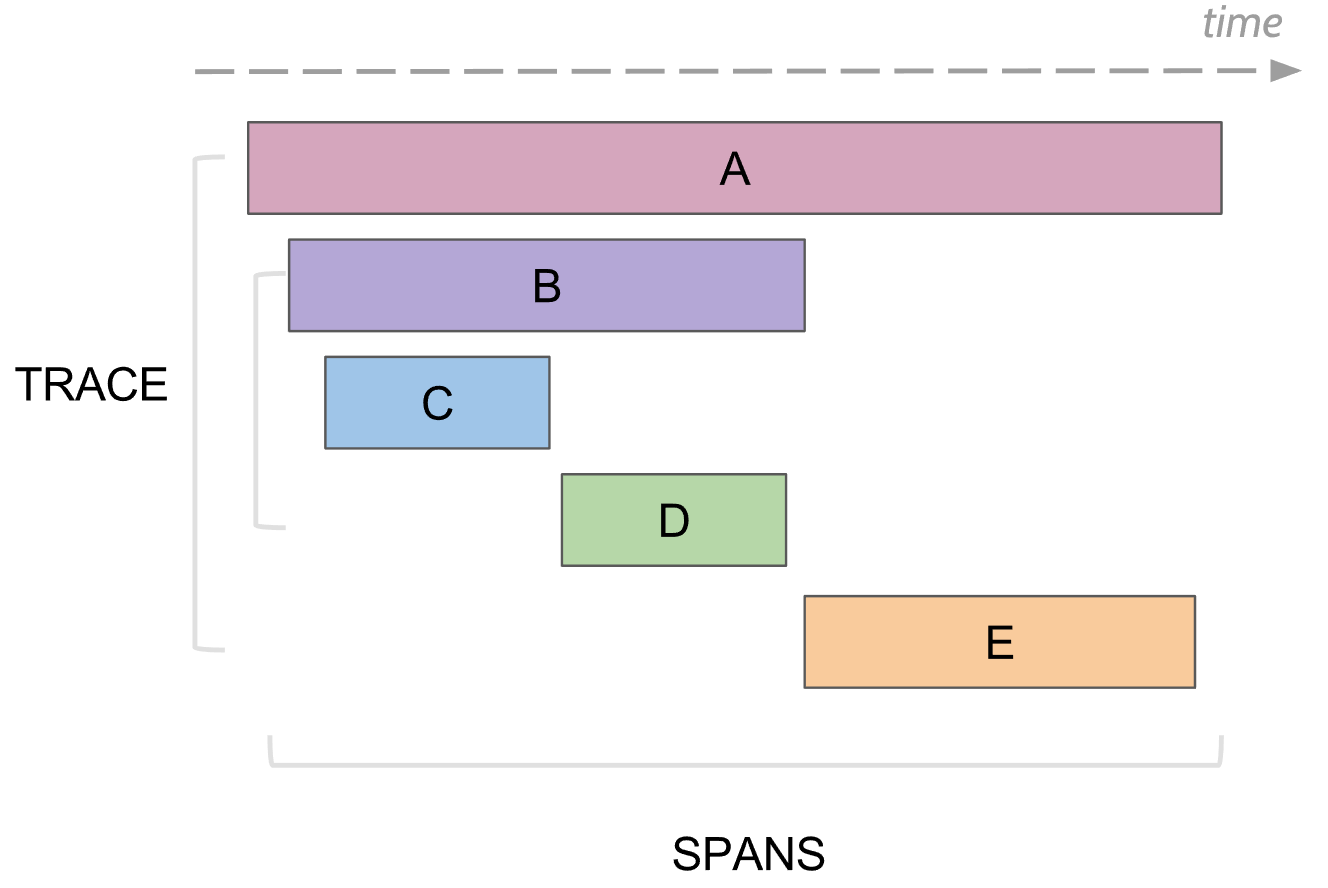
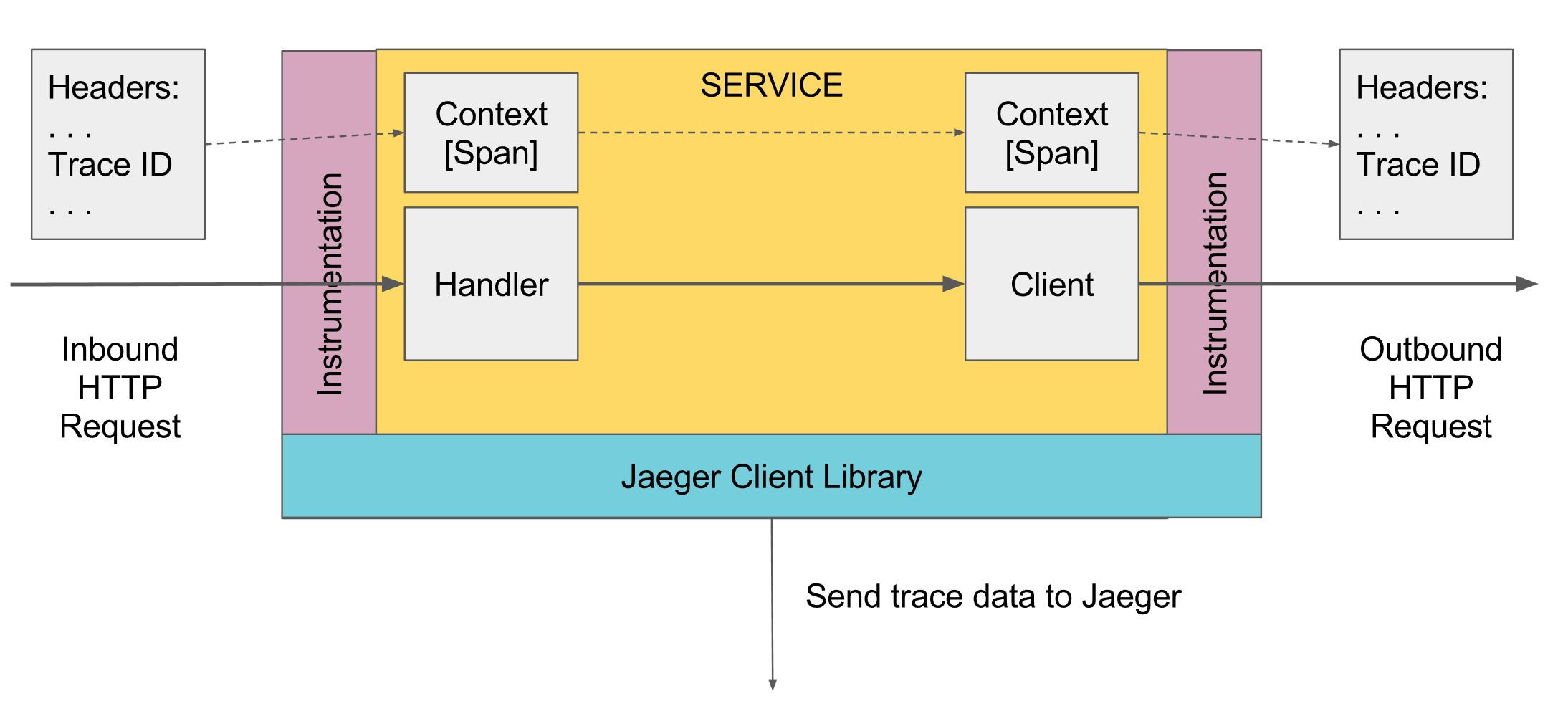
Was kann die Protokollierung verfolgen? Span
Bei der Ablaufverfolgung gibt es das Konzept der Spanne, es ist ein Analogon eines Protokolls zur Konsole. Die Spanne hat:
- Der Name, normalerweise der Name der ausgeführten Methode
- Der Name des Dienstes, in dem der Bereich generiert wurde
- Eigene eindeutige ID
- Einige Metainformationen in Form von Schlüssel / Wert, die ihm zugesagt wurden. Beispielsweise endeten Methodenparameter oder die Methode mit einem Fehler oder nicht
- Die Start- und Endzeiten dieser Spanne
- ID der übergeordneten Spanne
Jeder Bereich wird an den Bereichssammler gesendet, um ihn zur späteren Anzeige in der Datenbank zu speichern, sobald er ausgeführt wurde. In Zukunft können Sie einen Baum aller Bereiche erstellen, indem Sie eine Verbindung über die ID des übergeordneten Elements herstellen. In der Analyse finden Sie beispielsweise alle Bereiche in einem Dienst, die länger als einige Zeit gedauert haben. Wenn Sie zu einer bestimmten Spanne gehen, sehen Sie den gesamten Baum über und unter dieser Spanne.
Opentracing, Jagger und wie wir es für unsere Projekte umgesetzt haben
Es gibt einen allgemeinen
Opentracing- Standard, der beschreibt, wie und was zusammengestellt werden soll, ohne an eine bestimmte Implementierung in einer beliebigen Sprache gebunden zu sein. In Java wird beispielsweise die gesamte Arbeit mit Traces über die allgemeine Opentracing-API ausgeführt, und darunter kann beispielsweise Jaeger oder eine leere Standardimplementierung, die nichts tut, ausgeblendet werden.
Wir verwenden
Jaeger als Implementierung von Opentracing. Es besteht aus mehreren Komponenten:
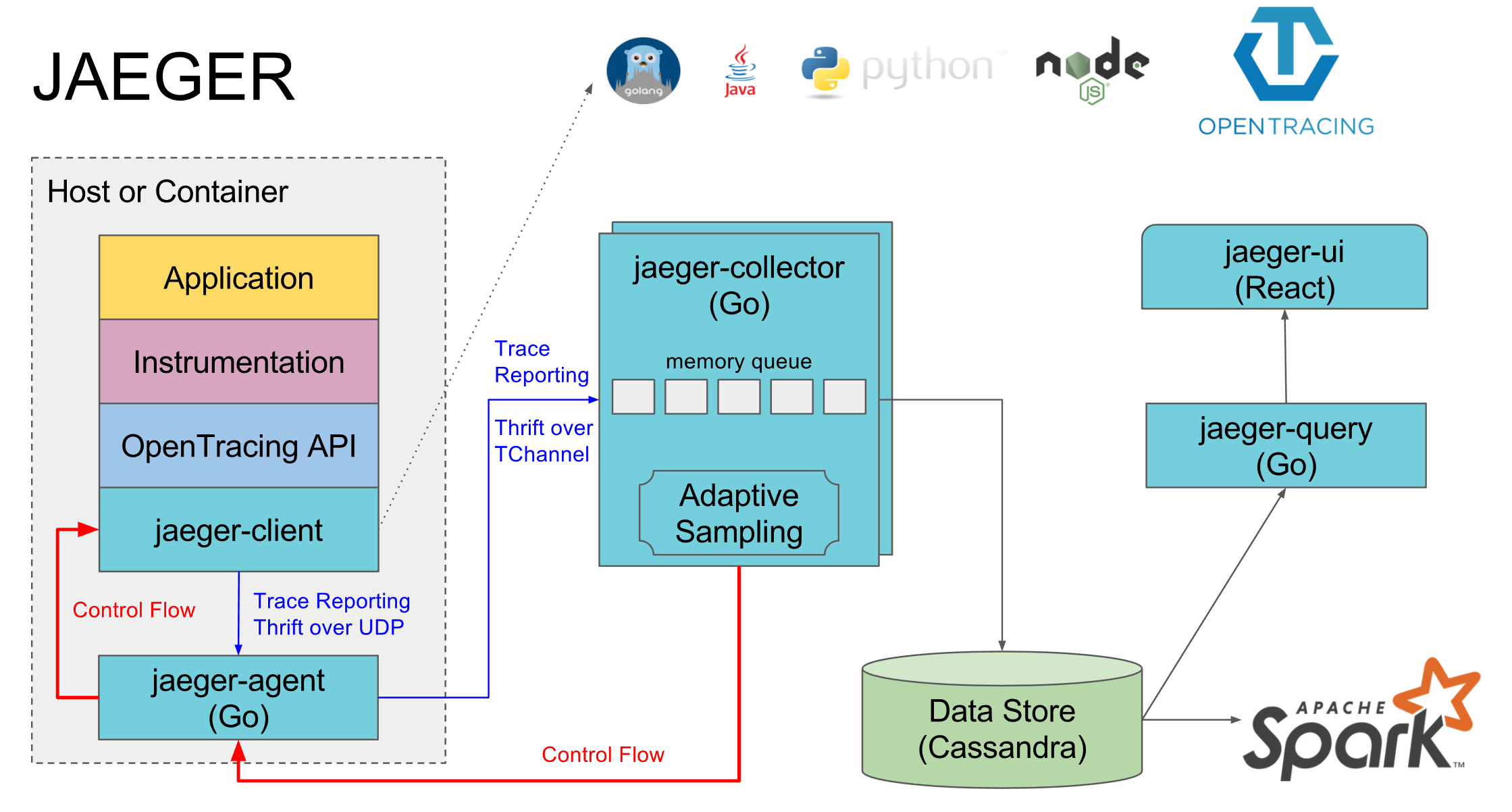
- Jaeger-Agent ist ein lokaler Agent, der normalerweise auf jedem Computer steht und dessen Dienste am lokalen Standardport angemeldet sind. Wenn kein Agent vorhanden ist, werden normalerweise die Ablaufverfolgungen aller Dienste auf diesem Computer deaktiviert
- Jaeger-Sammler - alle Agenten senden gesammelte Spuren an ihn und er legt sie in der ausgewählten Datenbank ab
- Die Datenbank ist ihre bevorzugte Kassandra, aber wir verwenden Elasticsearch. Es gibt Implementierungen für einige andere Datenbanken und im Speicher eine Implementierung, die nichts auf der Festplatte speichert
- Jaeger-query ist ein Dienst, der in die Datenbank geht und bereits gesammelte Spuren zur Analyse liefert
- Jaeger-ui ist eine Webschnittstelle zum Suchen und Anzeigen von Spuren, die zur Jaeger-Abfrage geht
Eine separate Komponente ist die Implementierung von Opentracing Jaeger für bestimmte Sprachen, über die Spannen an Jaeger-Agent gesendet werden.
Beim Verbinden von Jagger in Java muss die io.opentracing.Tracer-Schnittstelle simuliert werden. Danach werden alle durchlaufenden Traces an den Real Agent weitergeleitet.
Sie können auch den
Opentracing-Spring-Cloud-Starter und eine Implementierung von Jaeger
Opentracing-Spring-Jaeger-Cloud-Starter verbinden, die die Ablaufverfolgung automatisch für alles konfiguriert, was diese Komponenten durchläuft, z. B. http-Anforderungen an Controller, Datenbankanforderungen über jdbc usw.
Ablaufverfolgung der Protokollierung in Java
Irgendwo auf der höchsten Ebene sollte die erste Spanne erstellt werden. Dies kann automatisch erfolgen, z. B. durch den Federregler, wenn eine Anforderung empfangen wird, oder manuell, wenn keine vorhanden ist. Weiter wird es durch Scope unten übertragen. Wenn eine der folgenden Methoden Span hinzufügen möchte, nimmt sie den aktuellen activeSpan aus Scope, erstellt einen neuen Span und gibt an, dass das übergeordnete Element activeSpan empfangen hat, und aktiviert den neuen Span. Wenn externe Dienste aufgerufen werden, wird der aktuell aktive Bereich an sie übertragen, und diese Dienste erstellen neue Bereiche mit Bezug auf diesen Bereich.
Alle Arbeiten werden über die Tracer-Instanz ausgeführt. Sie können sie über den DI-Mechanismus oder GlobalTracer.get () als globale Variable abrufen, wenn der DI-Mechanismus nicht funktioniert. Wenn der Tracer nicht initialisiert wurde, gibt NoopTracer standardmäßig zurück, was nichts bewirkt.
Ferner wird der aktuelle Bereich vom Tracer über ScopeManager abgerufen, ein neuer Bereich wird aus dem aktuellen Bereich mit der Bindung des neuen Bereichs erstellt, und dann wird der erstellte Bereich geschlossen, wodurch der erstellte Bereich geschlossen und der vorherige Bereich in den aktiven Zustand zurückgesetzt wird. Der Bereich ist an einen Stream gebunden. Bei der Multithread-Programmierung dürfen Sie also nicht vergessen, den aktiven Bereich auf einen anderen Stream zu übertragen, um den Bereich eines anderen Streams in Bezug auf diesen Bereich weiter zu aktivieren.
io.opentracing.Tracer tracer = ...;
Für die Multithread-Programmierung gibt es auch einen TracedExecutorService und ähnliche Wrapper, die die aktuelle Spanne beim asynchronen Starten von Aufgaben automatisch an den Stream weiterleiten:
private ExecutorService executor = new TracedExecutorService( Executors.newFixedThreadPool(10), GlobalTracer.get() );
Für externe http-Anforderungen gibt es
TracingHttpClient HttpClient httpClient = new TracingHttpClientBuilder().build();
Die Probleme, mit denen wir konfrontiert sind
- Beans und DI funktionieren nicht immer, wenn der Tracer nicht in einem Dienst oder einer Komponente verwendet wird. Dann funktioniert Autowired Tracer möglicherweise nicht und Sie müssen GlobalTracer.get () verwenden.
- Anmerkungen funktionieren nicht, wenn es sich nicht um eine Komponente oder einen Dienst handelt oder wenn ein Methodenaufruf von einer benachbarten Methode derselben Klasse stammt. Sie müssen vorsichtig sein, überprüfen, was funktioniert, und die manuelle Erstellung des Trace verwenden, wenn @Traced nicht funktioniert. Sie können auch einen zusätzlichen Compiler für Java-Annotationen schrauben, dann sollten sie überall funktionieren.
- Im alten Spring- und Spring-Boot funktioniert die automatische Konfiguration der opentraing-Federwolke aufgrund von Fehlern in DI nicht. Wenn Sie möchten, dass die Spuren in den Federkomponenten automatisch funktionieren, können Sie dies analog zu github.com/opentracing-contrib/java-spring-jaeger/blob/ tun. master / opentracing-spring-jaeger-Starter / src / main / java / io / opentracing / Contrib / Java / Frühling / Jaeger / Starter / JaegerAutoConfiguration.java
- Try with Resources funktioniert nicht in groovy, Sie müssen try finally verwenden.
- Jeder Dienst sollte einen eigenen spring.application.name haben, unter dem die Traces protokolliert werden. Was bedeutet ein separater Name für Verkauf und Test, um sie nicht gemeinsam zu stören.
- Wenn Sie GlobalTracer und Tomcat verwenden, haben alle in diesem Tomcat ausgeführten Dienste einen GlobalTracer, sodass alle denselben Dienstnamen haben.
- Wenn Sie einer Methode Traces hinzufügen, müssen Sie sicherstellen, dass sie nicht viele Male in der Schleife aufgerufen wird. Es ist erforderlich, für alle Anrufe eine gemeinsame Ablaufverfolgung hinzuzufügen, die die Gesamtarbeitszeit garantiert. Andernfalls entsteht eine Überlast.
- Einmal in Jaeger-UI haben sie zu große Anfragen für eine große Anzahl von Spuren gestellt und da sie nicht auf eine Antwort gewartet haben, haben sie es erneut getan. Infolgedessen begann die Jaeger-Abfrage viel Gedächtnis zu verbrauchen und das Gummiband zu verlangsamen. Hilft beim Neustart der Jaeger-Abfrage
Spuren abtasten, speichern und anzeigen
Es gibt drei Arten von
Spurenproben :
- Const, die alle Spuren sendet und speichert.
- Probabilistisch, das Spuren mit einer bestimmten Wahrscheinlichkeit filtert.
- Ratelimiting, das die Anzahl der Spuren pro Sekunde begrenzt. Sie können diese Optionen auf dem Client entweder auf dem Jaeger-Agenten oder im Collector konfigurieren. Jetzt haben wir const 1 im Stapel der Bewerter, da es nicht sehr viele Anfragen gibt, aber sie dauern lange. Wenn dies in Zukunft das System übermäßig belastet, können Sie es begrenzen.
Wenn Sie Cassandra verwenden, werden Spuren standardmäßig in nur zwei Tagen gespeichert. Wir verwenden
elasticsearch und Spuren werden für die gesamte Zeit gespeichert und nicht gelöscht. Für jeden Tag wird ein separater Index erstellt, z. B. jaeger-service-2019-03-04. In Zukunft müssen Sie die automatische Reinigung alter Spuren konfigurieren.
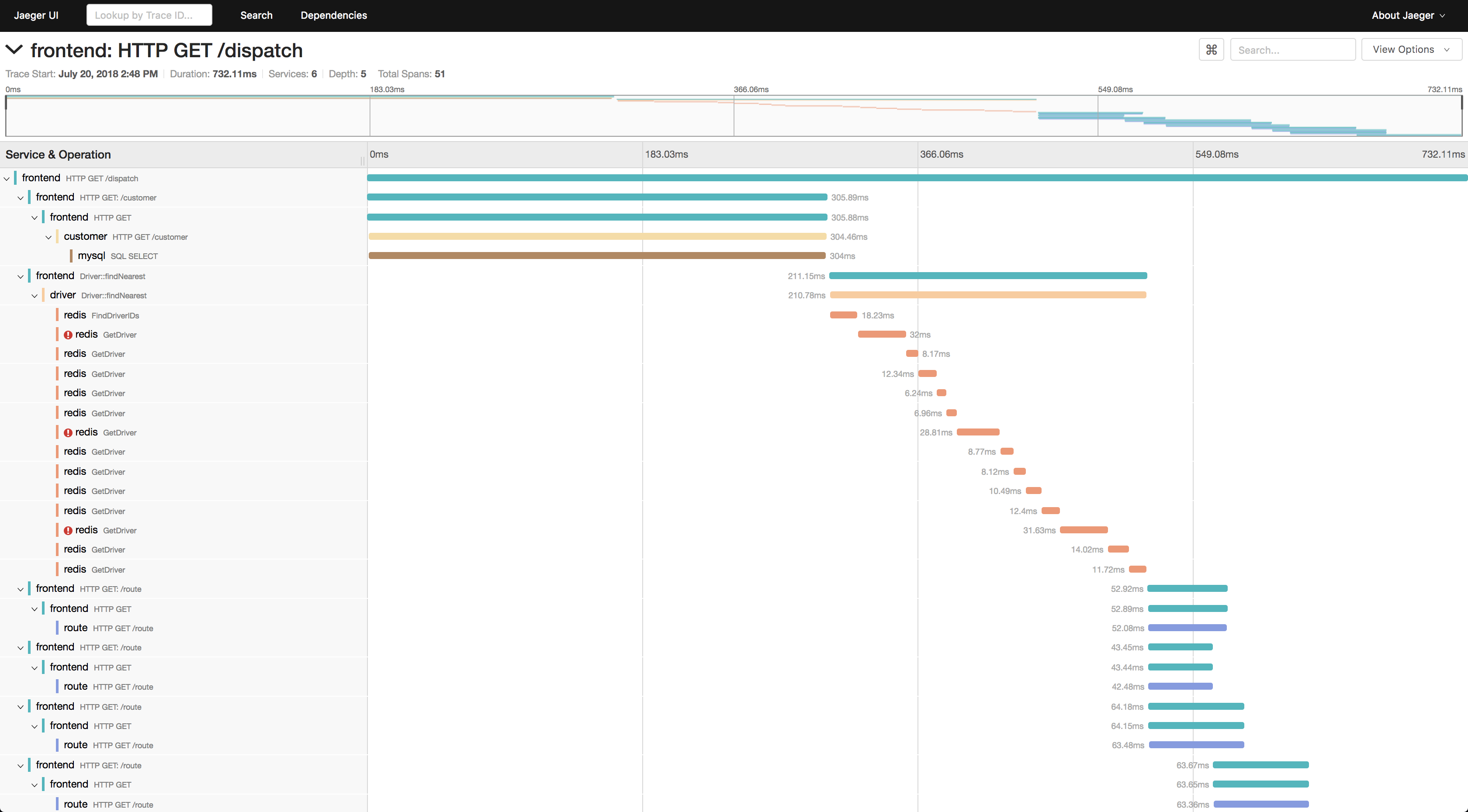
Um die Kurse zu sehen, benötigen Sie:
- Wählen Sie einen Dienst aus, nach dem Sie die Traces filtern möchten, z. B. tomcat7-default für einen Dienst, der auf einer Tomate ausgeführt wird und keinen Namen haben kann.
- Wählen Sie als Nächstes die Operation, das Zeitintervall und die minimale Operationszeit aus, z. B. 10 Sekunden, um nur lange Läufe durchzuführen.
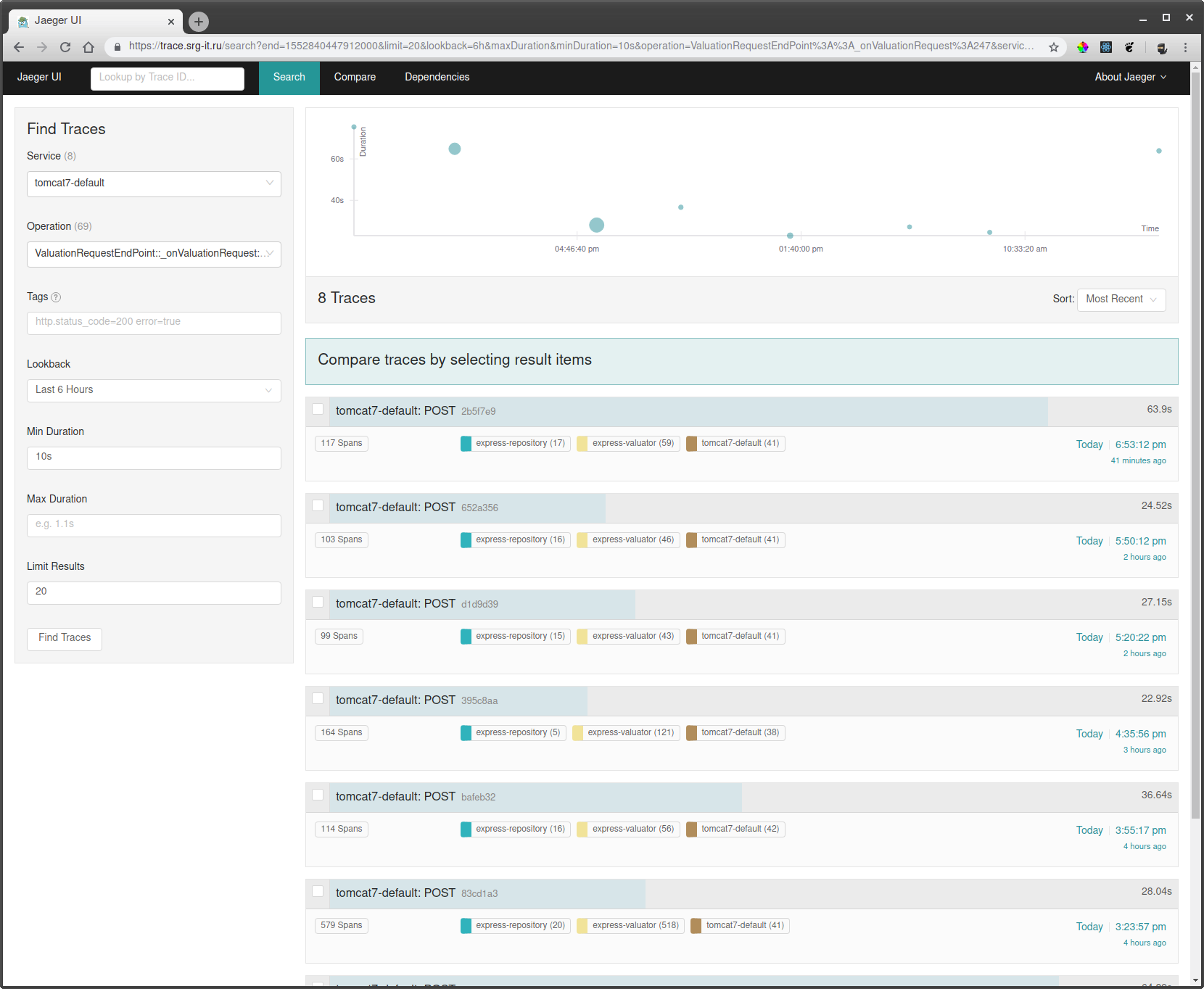
- Gehen Sie zu einem der Tracks und sehen Sie, was dort langsamer wurde.

Wenn eine ID der Anforderung bekannt ist, können Sie anhand einer Tag-Suche eine Ablaufverfolgung anhand dieser ID finden, wenn diese ID im Track-Bereich protokolliert ist.
Die Dokumentation
Artikel
Video