Habr, hallo!
Viele Menschen wissen nicht, wie sie mit Trends im Internet arbeiten sollen, wo sie suchen sollen. Bevor sie ein Unternehmen gründen, wissen sie nicht, wo sie sehen können, ob dieses Unternehmen überhaupt beliebt ist und ob es benötigt wird. Daher werde ich ein vollständiges Tutorial schreiben, um alle Fragen zu diesem Thema zu schließen.
Wir werden mit einem speziellen Service zusammenarbeiten, um Suchanfragen von Yandex-Benutzern von
Wordstat zu sammeln , dessen Oberfläche recht einfach und verständlich ist:
Am Anfang werde ich der Tradition nach Ziele setzen:
- Verstehen Sie alle Funktionen und lernen Sie, wie Sie mit Wordstat arbeiten.
- Wie man Semantik mit maximaler Relevanz und Klickrate> 50% sammelt;
- Da wir auf Habré sind, werden wir direkt mit der Wordstat-API arbeiten.
Die Schlüsselrolle des Dienstes liegt in der Tatsache, dass er dazu beiträgt, das Interesse der Benutzer an Trends und verschiedenen Themen zu bewerten und Schlüsselwörter für kontextbezogene Werbung auszuwählen.
Bekanntschaft mit dem Service
Um
Wordstat verwenden zu können , müssen wir uns bei Ihrem Yandex-Konto anmelden:

Nach der Autorisierung können wir den Service nutzen. Das Anzeigen von Daten aus Suchanfragen steht uns auf der Registerkarte "Nach" zur Verfügung:
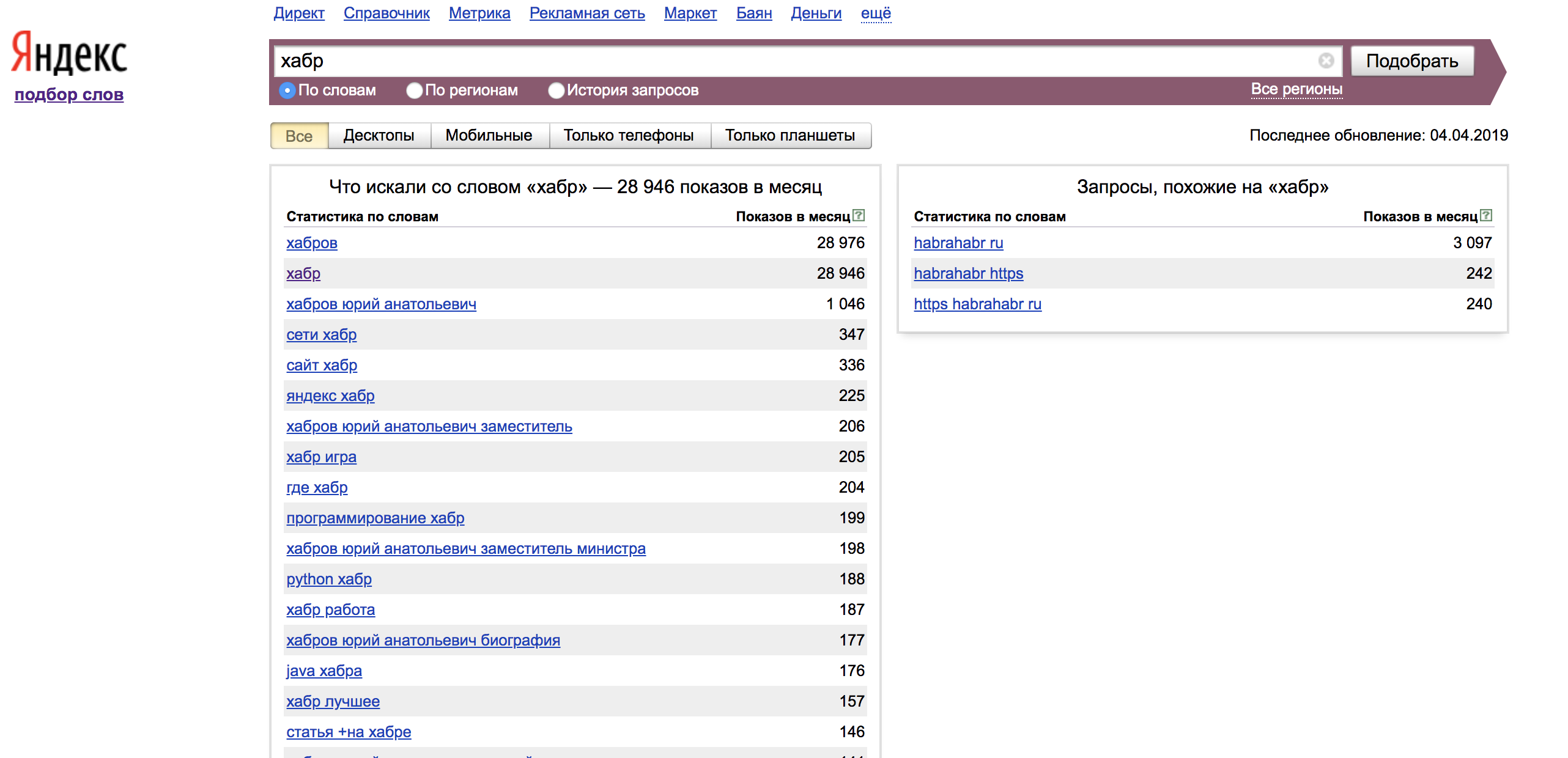
In der linken Spalte sehen wir Statistiken für die Wörter
, die zusammen mit Ihrer Suchanfrage und Impressionen pro Monat für sie waren. Damit wir unser Wort genau finden können, müssen wir
Operatoren verwenden . In der rechten Spalte werden Abfragen mit ähnlicher Bedeutung für den von uns festgelegten Ausdruck angezeigt.
Ein gutes Beispiel für die Verwendung von Schlüsselwörtern mit Operatoren:
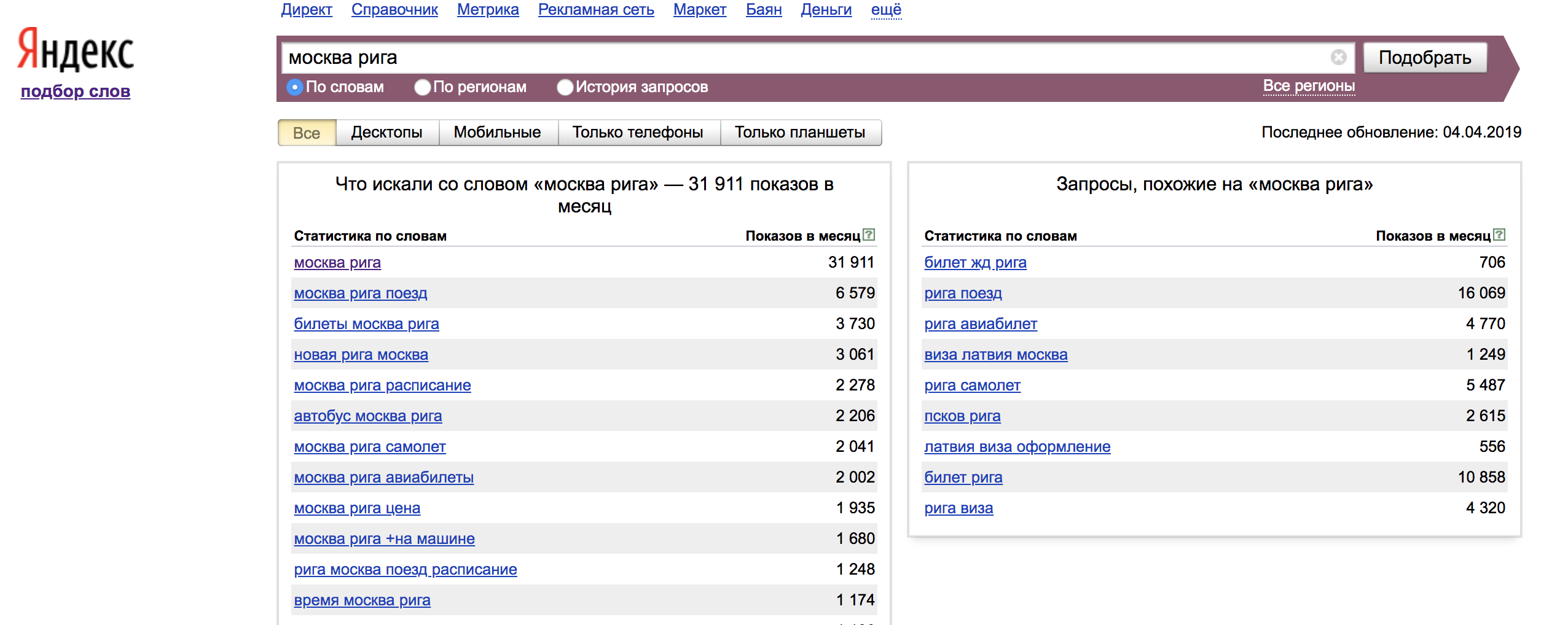
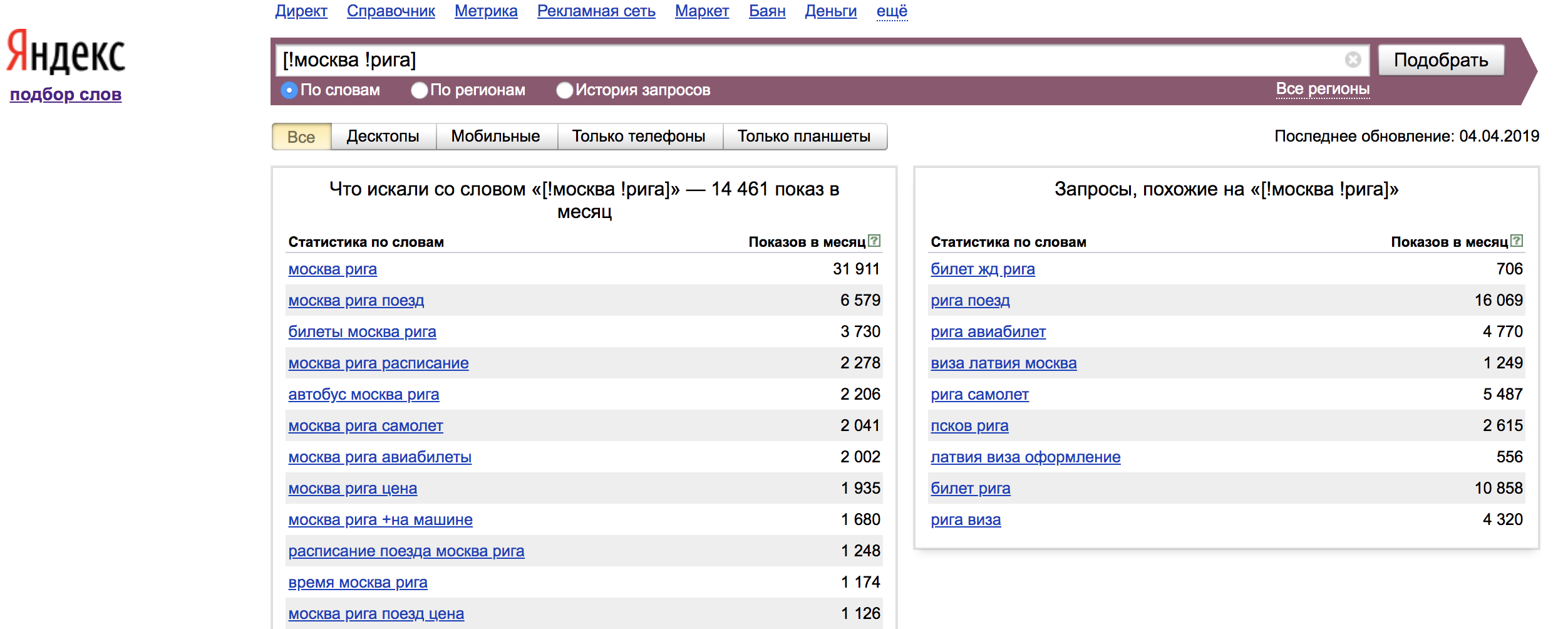
Der Operator "!" - legt die Form des Wortes fest (Nummer, Fall, Zeit);

Operator "[]" - Korrigiert die Wortreihenfolge. In diesem Fall werden alle Wortformen und Stoppwörter berücksichtigt.
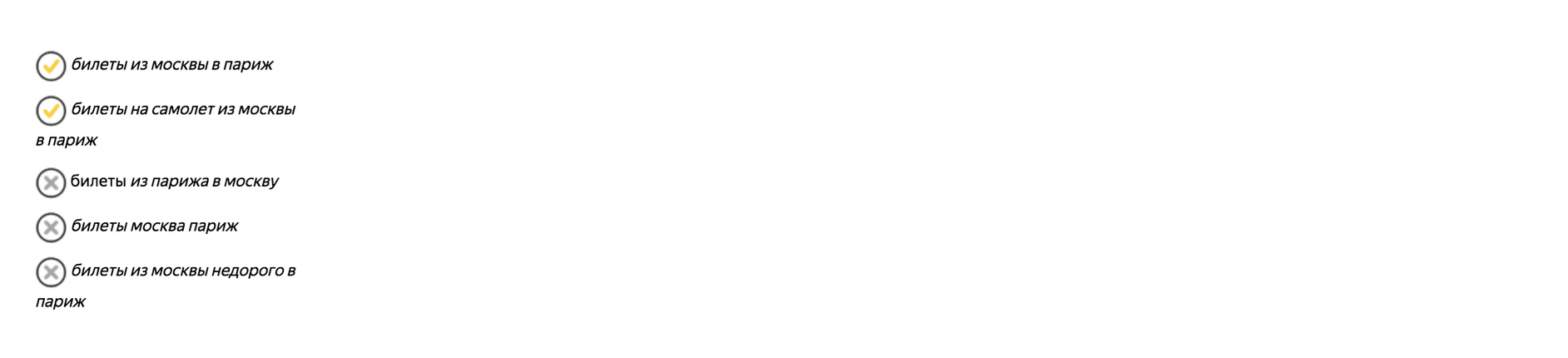
Lesen Sie hier mehr über Betreiber.
Standardmäßig zeigt Wordstat Anforderungen für alle Gerätetypen an. Einstellungen können geändert werden: nur Desktop / Handy / Telefon / Tablet. In unserem Fall filtern wir nur Desktops.
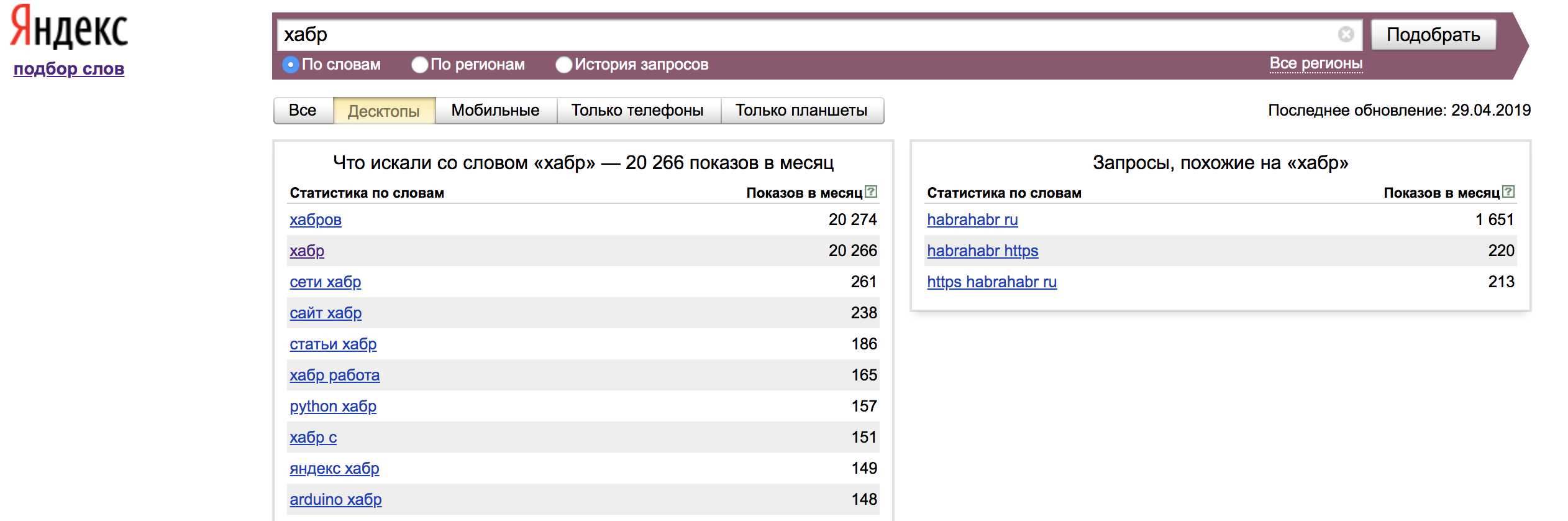
Standardmäßig werden Statistiken für alle Regionen angezeigt. Auf der Registerkarte "Alle Regionen" können Sie Statistiken für die für uns interessante Region anzeigen:
Auf der Registerkarte „Nach Region“ werden Daten aus allen Regionen sowie die regionale Beliebtheit angezeigt - der Anteil, den die Region an den Impressionen nach Wort einnimmt, geteilt durch den Anteil aller Impressionen der Suchergebnisse, die dieser Region zugeordnet werden können.
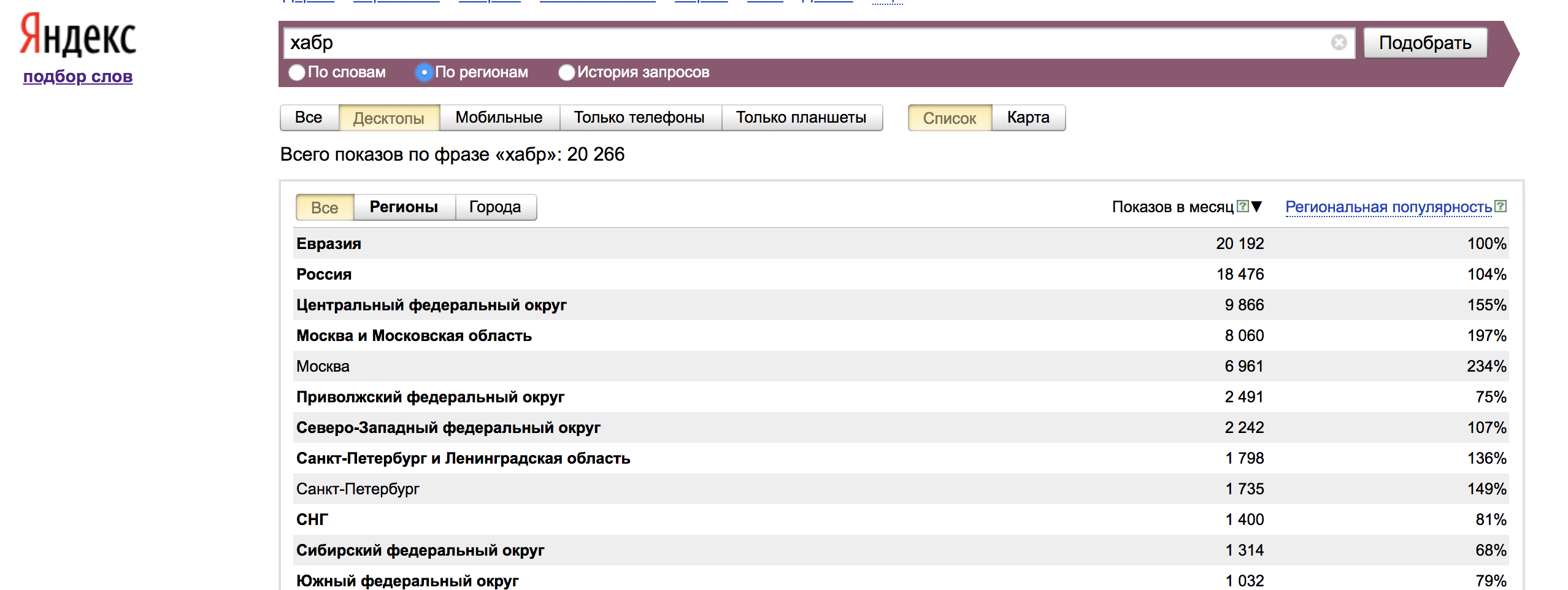
Der Einfachheit halber werden dieselben Daten auf der Karte angezeigt:
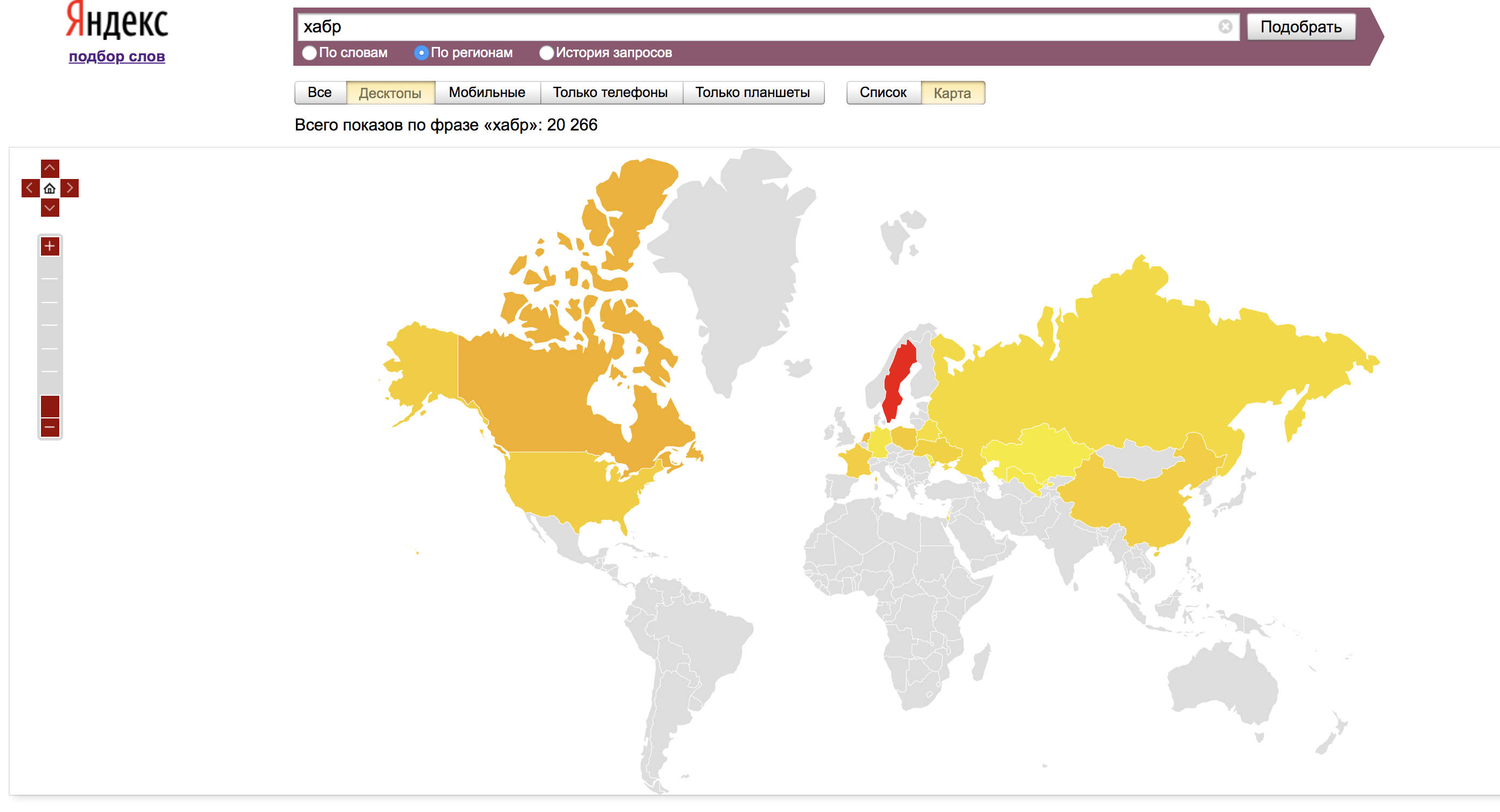
Auf der Registerkarte "Abfrageverlauf" werden Daten zur Anforderung angezeigt, normalerweise für 1,5 Jahre. Hier können wir die Trends und deren Einfluss auf bestimmte Anfragen klar bewerten.
Statistiken können sowohl in absoluten als auch in relativen Werten angezeigt werden. Um einen relativen Wert zu erhalten, wird die absolute Zahl auf die Anzahl der Impressionen der Yandex-Suchergebnisse für den entsprechenden Monat normiert.
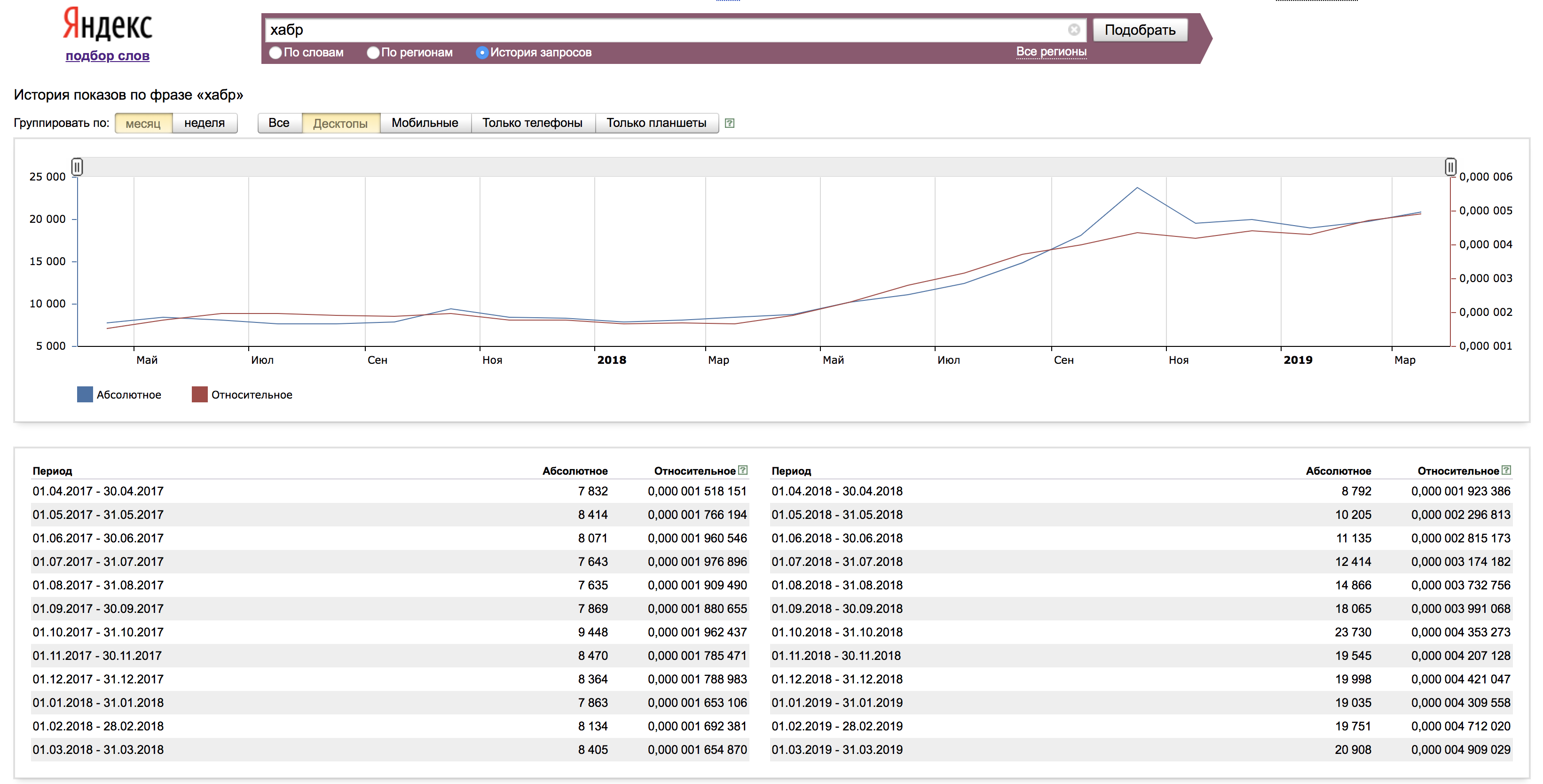
Mit dieser Werkzeugstudie können Sie unser nächstes Ziel erreichen und erreichen - die korrekte Sammlung des semantischen Kerns.
Die korrekte Sammlung des semantischen Kerns
Im Internet viele Dienste und Methoden zum Sammeln des semantischen Kerns sowie seiner künstlichen Erstellung. Wir werden kein Fahrrad bauen und mit einem Tamburin tanzen, aber wir werden die Semantik einfach, einfach und kostenlos sammeln.
Um unsere Semantik zu sammeln, laden wir zunächst die neueste Version von der offiziellen Yandex-Website
Yandex.Direct Commander herunter .
Führen Sie nach dem Herunterladen das Programm aus, melden Sie sich an und erstellen Sie (unabhängig vom Namen) die Kampagne:
Fügen Sie eine Anzeigengruppe hinzu (es macht immer noch keinen Sinn, sich mit ihrem Namen zu beschäftigen):
Gehen Sie zur Registerkarte "Phrasenauswahl" und voila! Dies ist das gleiche Wordstat, nur im Direct Commander-Programm. Die Logik der Arbeit damit ist dieselbe, nur im Gegensatz zur Webversion von Wordstat können wir hier sofort Minuswörter angeben:
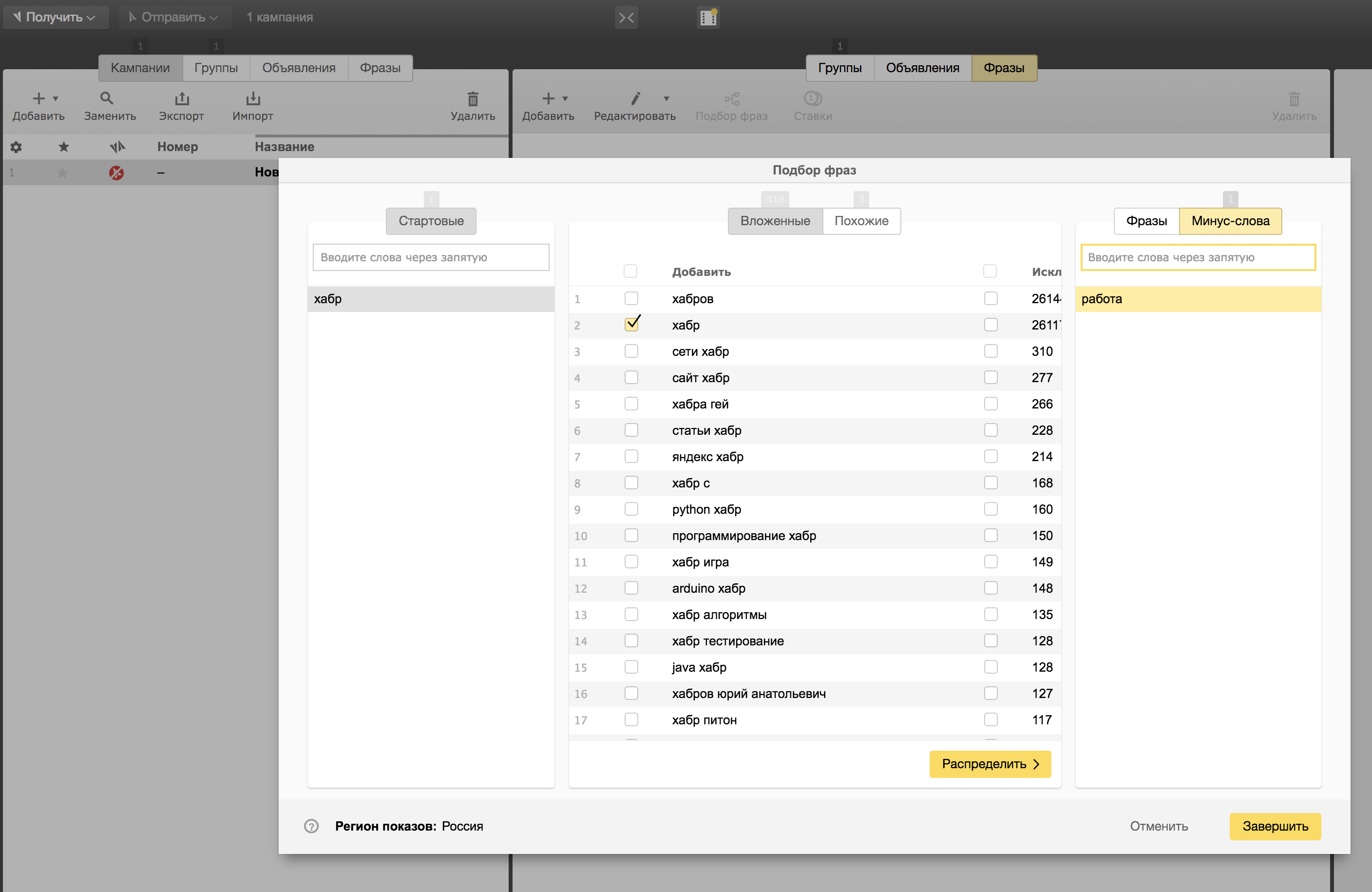
Nachdem wir die
gesamte Liste der Suchanfragen sorgfältig nach unnötigen Abfragen gefiltert haben, können wir unsere Kampagne in eine CSV-Datei exportieren. Wir müssen nur noch die zusätzlichen Spalten entfernen. Unser semantischer Kern befindet sich in der Spalte "Phrase (mit ausschließenden Schlüsselwörtern)":
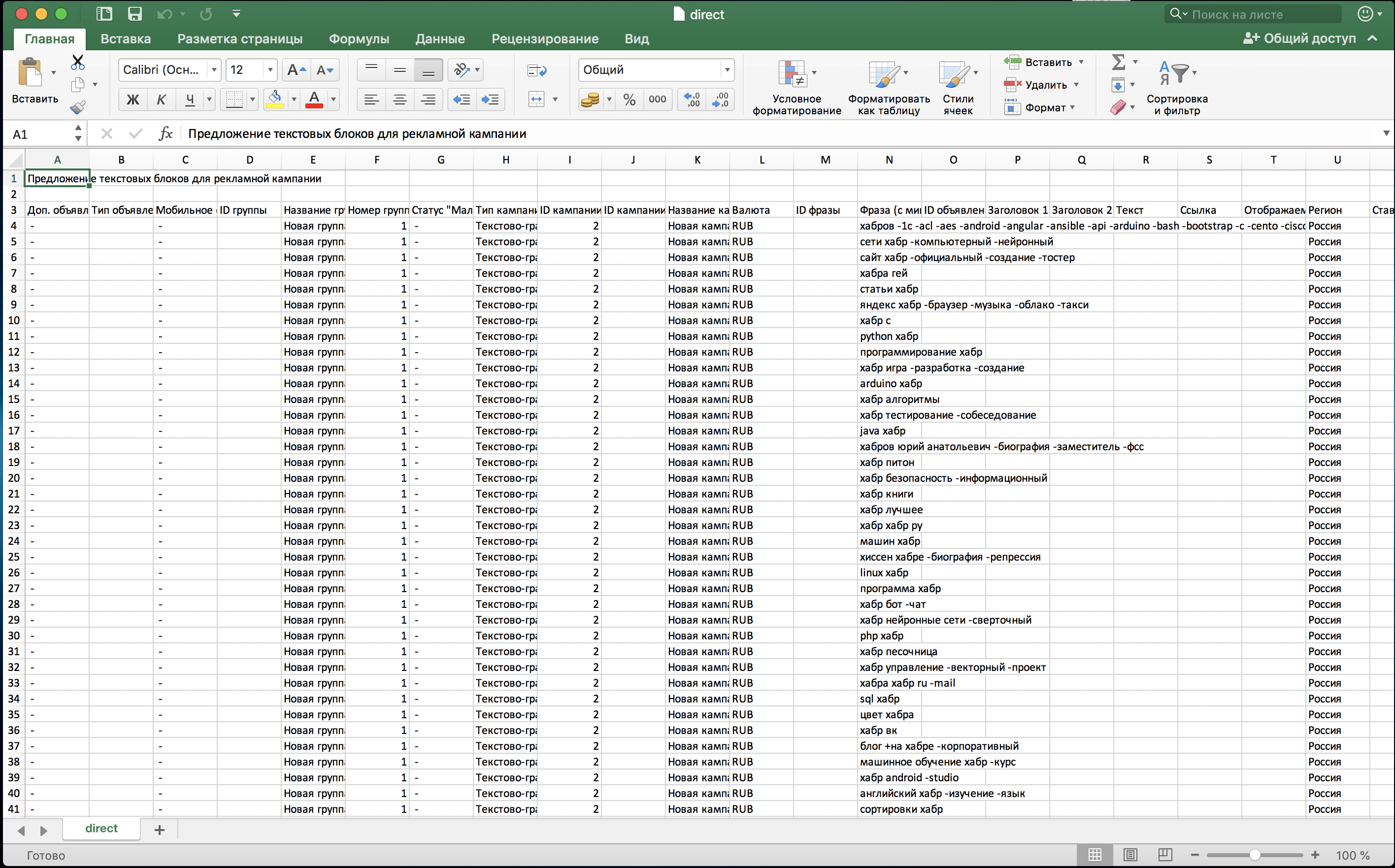
Die Vorteile des Sammelns von Semantik auf diese Weise:
- Abdeckung von Anfragen mit einer Häufigkeit von bis zu 1 pro Monat;
- Wir bauen keine künstliche Semantik auf, in der es höchstwahrscheinlich Abfragen geben wird, die im realen Suchverlauf tatsächlich nicht vorhanden sind.
- Wir erhöhen die Klickrate von Anzeigen so weit wie möglich (natürlich nicht nur aufgrund der Semantik, sondern auch aufgrund der ordnungsgemäßen Aufteilung der Anzeigen in Anforderungscluster und deren Texte. All dies basiert jedoch auf unserer Semantik).
- Klicks werden für uns billiger;
- Es ist absolut kostenlos.
Arbeiten Sie mit der Wordstat-API
Bevor Sie beginnen, werden wir uns mit den grundlegenden Informationen aus der Yandex.Direct-Hilfe vertraut machen.
Wordstat-API-Referenz
Beschreibung der ParameterErforderliche GET-Parameter
Anfrage - Daten anfordern
GET-Parameter
lr - Regionscode, wenn 0 - dann alle Regionen
imp - wenn 1 - dann eine wichtige Anfrage
Die Antwort enthältstatus - Statuscode (0 - keine Fehler)
err_msg - Fehlertext
Daten - Impressionen pro Monat
Zur Angabe der Region werden Codes von Yandex verwendet. Laden Sie die Liste der Regionen
über den Link herunter
<?php $array = array(); $array["user"] = '#_'; $array["password"] = '123456'; $array["lr"] = "1"; $array["imp"]=1; $array["request"] = ""; $content = file_get_contents("#url_user_auth".http_build_query($array)); $json = json_decode($content); if( !is_object($json) ){ echo ' '; exit(); } if($json->status!=0){ echo $json->err_msg; exit; } echo $json->data . " . "; ?>
Ergebnis:
{"Status": 0, "err_msg": "OK", "data": "11284", "date_update": "29.04.2019"}
Damit wurden alle Ziele erreicht, die wir uns am Ende des Artikels gesetzt haben.
Alles Wissen!