Das Shenango-System soll in Rechenzentren eingesetzt werden.
 / Foto Marco Verch CC BY
/ Foto Marco Verch CC BYLaut einem der Anbieter
nutzen Rechenzentren nur 20-40% der verfügbaren Rechenleistung. Bei hohen Belastungen kann dieser Wert
60% erreichen . Diese Verteilung der Ressourcen führt zur Entstehung der sogenannten "Zombieserver". Dies sind Maschinen, die die meiste Zeit im Leerlauf stehen und Energie verschwenden. Heute sind 30% der Server weltweit arbeitslos und verbrauchen 30 Milliarden US-Dollar pro Jahr Strom.
Das MIT entschied sich für den ineffizienten Einsatz von Computerressourcen.
Ein Team von Ingenieuren hat ein Lastausgleichssystem für Prozessoren namens Shenango entwickelt. Ziel ist es, den Status des Task-Puffers zu überwachen und festgefahrene Prozesse (die keine Prozessorzeit empfangen können) an freie Maschinen weiterzugeben.
Wie Shenango funktioniert
Shenango ist eine C-basierte Linux-Bibliothek mit Rust- und C ++ - Bindungen. Projektcode und Testanwendungen werden im
Repository auf GitHub veröffentlicht.
Die Basis der Lösung ist der IOKernel-Algorithmus, der auf einem dedizierten Kern eines Multiprozessorsystems ausgeführt wird. Es verwaltet CPU-Anforderungen mithilfe des
DPDK- Frameworks, mit dem Anwendungen direkt mit Netzwerkgeräten interagieren können.
IOKernel entscheidet, welche Kernel eine bestimmte Aufgabe übergeben sollen. Der Algorithmus entscheidet auch, wie viele Kerne benötigt werden. Für jeden Prozess werden die Hauptkerne (garantiert) und die zusätzlichen (Burstable) definiert - die zweiten werden gestartet, wenn die Anzahl der Anforderungen an die CPU stark zunimmt.
Die IOKernel-Anforderungswarteschlange ist als
Ringpuffer organisiert . Alle fünf Mikrosekunden prüft der Algorithmus, ob alle dem Kernel zugewiesenen Aufgaben abgeschlossen wurden. Dazu vergleicht er die aktuelle Position des „Kopfes“ des Puffers mit der vorherigen Position seines „Schwanzes“. Wenn sich herausstellt, dass sich das Tail zum Zeitpunkt der vorherigen Prüfung bereits in der Warteschlange befand, stellt das System die Pufferüberlastung fest und weist dem Prozess einen zusätzlichen Kernel zu.
Bei der Verteilung der Last wird den Kerneln Vorrang eingeräumt, für die derselbe Prozess zuvor ausgeführt wurde und die teilweise im Cache verblieben sind, oder allen inaktiven Kerneln.
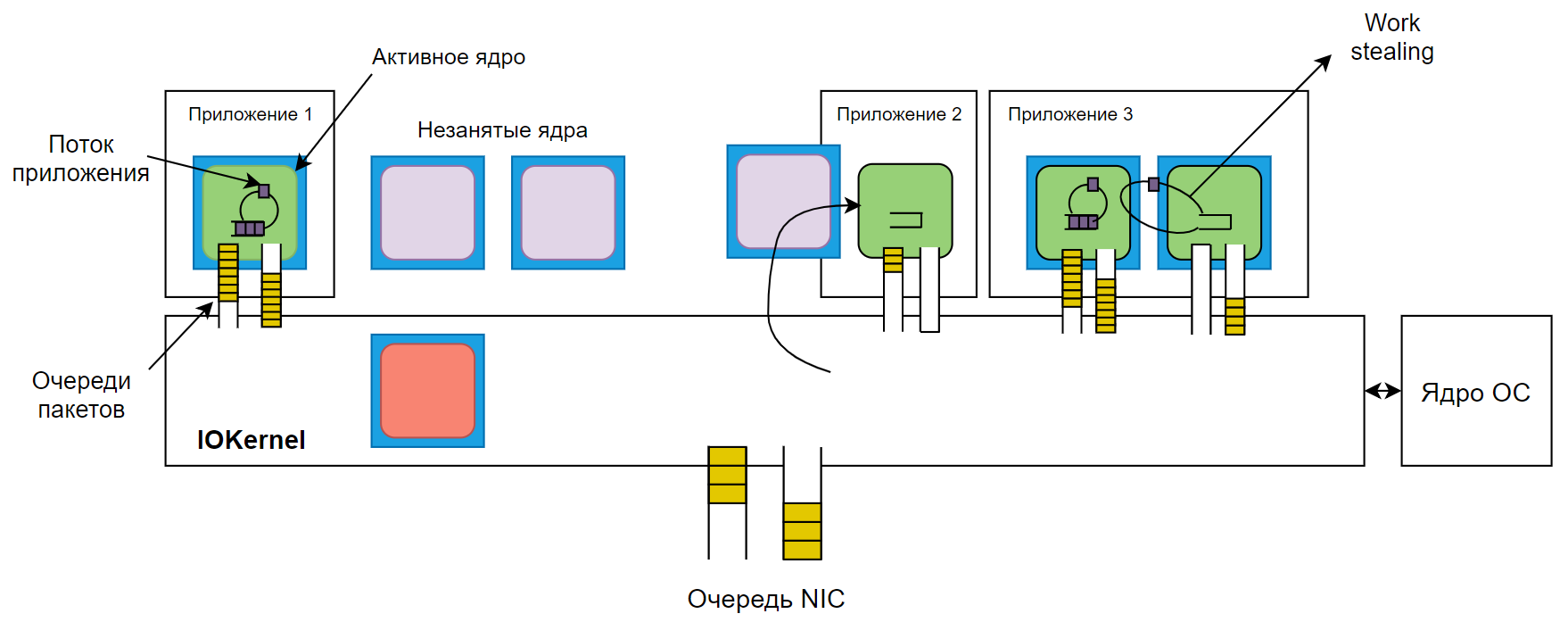
Shenango verfolgt zusätzlich einen Ansatz des
Arbeitsdiebstahls . Die für den Betrieb einer Anwendung zugewiesenen Kernel überwachen die Anzahl der Aufgaben für einander. Wenn ein Kern seine Aufgabenliste früher als die anderen abschließt, „entfernt“ er einen Teil der Last von seinen Nachbarn.
Vor- und Nachteile
Laut Ingenieuren am MIT kann Shenango fünf Millionen Anfragen pro Sekunde verarbeiten und eine durchschnittliche Antwortzeit von 37 Mikrosekunden einhalten. Experten sagen, dass die Technologie in einigen Fällen die Auslastung von Prozessoren in Rechenzentren auf 100% steigern kann. Dadurch können Rechenzentrumsbetreiber beim Kauf und der Wartung von Servern sparen.
Mögliche Lösungen
werden auch
von Spezialisten anderer Universitäten
festgestellt . Laut einem Professor des Koreanischen Instituts wird das System des MIT dazu beitragen, Verzögerungen bei der Arbeit von Webdiensten zu verringern. Zum Beispiel ist es beim Betrieb von Online-Shops nützlich. In den Verkaufstagen führt bereits eine zweite Verzögerung beim Laden der Seite zu einer Verringerung der Anzahl der Site-Aufrufe um 11%. Der Online-Lastausgleich hilft dabei, mehr Kunden zu bedienen.
Die Technologie hat immer noch Nachteile - sie unterstützt keine Multiprozessor-
NUMA- Systeme, bei denen die Chips mit verschiedenen Speichermodulen verbunden sind und nicht miteinander "kommunizieren". In diesem Fall kann IOKernel den Betrieb einer separaten Gruppe von Prozessoren regeln, jedoch nicht aller Serverchips.
 / Foto Tim Reckmann CC BY
/ Foto Tim Reckmann CC BYÄhnliche Technologie
Unter anderen Prozessor-Lastausgleichssystemen kann Arachne unterschieden werden. Es berechnet, wie viele Kerne die Anwendung zum Zeitpunkt ihres Starts benötigt, und verteilt die Prozesse gemäß diesem Indikator. Laut den Autoren beträgt die maximale Anwendungslatenz in Arachne etwa 10 000 Mikrosekunden.
Die Technologie ist als C ++ - Bibliothek für Linux implementiert und der Quellcode befindet sich auf
GitHub .
Ein weiteres Auswuchtwerkzeug ist ZygOS. Wie in Shenango verwendet die Technologie die Methode des Arbeitsdiebstahls, um Prozesse neu zu verteilen. Laut den Autoren von ZygOS beträgt die durchschnittliche Verzögerung in der Anwendung bei Verwendung des Tools etwa 150 Mikrosekunden und das Maximum etwa 450 Mikrosekunden. Der Projektcode ist auch
gemeinfrei .
Schlussfolgerungen
Moderne Rechenzentren expandieren weiter. Insbesondere auf dem Markt der Hyperscale-Rechenzentren macht sich der Aufwärtstrend bemerkbar: Derzeit
gibt es weltweit 430 hyper-skalierbare Rechenzentren, deren Anzahl sich jedoch in den kommenden Jahren um 30% erhöhen könnte. Aus diesem Grund werden CPU-Lastausgleichstechnologien sehr gefragt sein. Systeme wie Shenango werden bereits
von großen Unternehmen
implementiert , und in Zukunft wird die Anzahl solcher Tools nur noch zunehmen.
Beiträge aus dem ersten Corporate IaaS-Blog: