
Hallo allerseits! Mit diesem Artikel eröffnet AERODISK einen Blog über Habré. Hurra, Genossen!
In früheren Artikeln zu Habr wurden Fragen zur Architektur und Grundkonfiguration von Speichersystemen berücksichtigt. In diesem Artikel werden wir eine Frage betrachten, die zuvor nicht behandelt wurde, aber häufig gestellt wurde - über die Fehlertoleranz von AERODISK ENGINE-Speichersystemen. Unser Team wird alles tun, damit das AERODISK-Speichersystem nicht mehr funktioniert, d. H. sie brechen.
So kam es, dass Artikel über die Geschichte unseres Unternehmens, über unsere Produkte sowie ein Beispiel für eine erfolgreiche Implementierung bereits bei Habré hängen, wofür wir uns bei unseren Partnern - TS Solution und Softline - bedanken.
Daher werde ich hier nicht die Verwaltungsfähigkeiten zum Kopieren und Einfügen trainieren, sondern lediglich Links zu den Originalen dieser Artikel geben:
Ich möchte auch die guten Nachrichten teilen. Aber ich werde natürlich mit dem Problem beginnen. Wir als junger Anbieter sehen uns unter anderem immer wieder der Tatsache gegenüber, dass viele Ingenieure und Administratoren nicht wissen, wie sie unsere Speichersysteme richtig betreiben sollen.
Es ist klar, dass die Verwaltung der meisten Speichersysteme aus Sicht des Administrators ungefähr gleich aussieht, aber jeder Hersteller hat seine eigenen Merkmale. Und wir sind keine Ausnahme.
Um die Ausbildung von IT-Fachleuten zu vereinfachen, haben wir uns daher entschlossen, dieses Jahr der freien Bildung zu widmen. Zu diesem Zweck eröffnen wir in vielen großen Städten Russlands ein Netzwerk von AERODISK-Kompetenzzentren, in denen jeder interessierte technische Spezialist einen Kurs absolut kostenlos belegen und ein AERODISK ENGINE-Speicherverwaltungszertifikat erhalten kann.
In jedem Kompetenzzentrum installieren wir einen vollwertigen Demostand aus dem AERODISK-Speichersystem und einen physischen Server, auf dem unser Lehrer eine Vollzeitschulung durchführt. Der Arbeitsplan der Kompetenzzentren wird nach ihrem Erscheinen veröffentlicht, aber jetzt haben wir ein Zentrum in Nischni Nowgorod eröffnet und die Stadt Krasnodar steht an nächster Stelle. Sie können sich über die folgenden Links für das Training anmelden. Ich bringe die aktuell bekannten Informationen über Städte und Daten mit:
- Nischni Nowgorod (BEREITS FUNKTIONIERT - Sie können sich hier registrieren https://aerodisk.promo/nn/ );
Bis zum 16. April 2019 können Sie das Zentrum jederzeit besuchen. Am 16. April 2019 wird ein großer Schulungskurs organisiert. - Krasnodar (BALD KOMMEN - hier anmelden https://aerodisk.promo/krsnd/ );
Vom 9. bis 25. April 2019 können Sie das Zentrum jederzeit besuchen. Am 25. April 2019 wird ein großer Schulungskurs organisiert. - Jekaterinburg (BALD ERÖFFNUNG, folgen Sie den Informationen auf unserer Website oder auf Habré);
Mai-Juni 2019. - Nowosibirsk (folgen Sie den Informationen auf unserer Website oder auf Habré);
Oktober 2019 - Krasnojarsk (folgen Sie den Informationen auf unserer Website oder auf Habré);
November 2019
Und wenn Moskau nicht weit von Ihnen entfernt ist, können Sie jederzeit unser Büro in Moskau besuchen und eine ähnliche Ausbildung absolvieren.
Das ist alles. Mit dem Marketing verbunden, gehen Sie zur Technik!
Auf Habré veröffentlichen wir regelmäßig technische Artikel über unsere Produkte, Stresstests, Vergleiche, Verwendungsmerkmale und interessante Implementierungen.
AERODISK ENGINE N2 Lagerungstest, Festigkeitsprüfung
ACHTUNG! Nachdem Sie den Artikel gelesen haben, können Sie sagen: Nun, natürlich wird sich der Verkäufer selbst überprüfen, damit alles "mit einem Knall", Gewächshausbedingungen usw. funktioniert. Ich werde antworten: nichts dergleichen! Im Gegensatz zu unseren ausländischen Konkurrenten sind wir hier, in Ihrer Nähe, und Sie können jederzeit zu uns (in Moskau oder einem Zentralkomitee) kommen und unser Speichersystem auf irgendeine Weise testen. Daher ist es wenig sinnvoll, die Ergebnisse an das Idealbild der Welt anzupassen, weil Wir sind sehr einfach zu überprüfen. Für diejenigen , die zu faul zum Gehen sind und keine Zeit haben, können wir Ferntests organisieren. Dafür haben wir ein spezielles Labor. Kontakt.
ACHTUNG-2! Dieser Test ist kein Belastungstest, weil hier geht es nur um fehlertoleranz. In ein paar Wochen werden wir einen leistungsstärkeren Stand vorbereiten und Lasttests von Speichersystemen durchführen. Die Ergebnisse werden hier veröffentlicht (Testwünsche werden übrigens akzeptiert).
Also, lass uns Pause machen.
Prüfstand
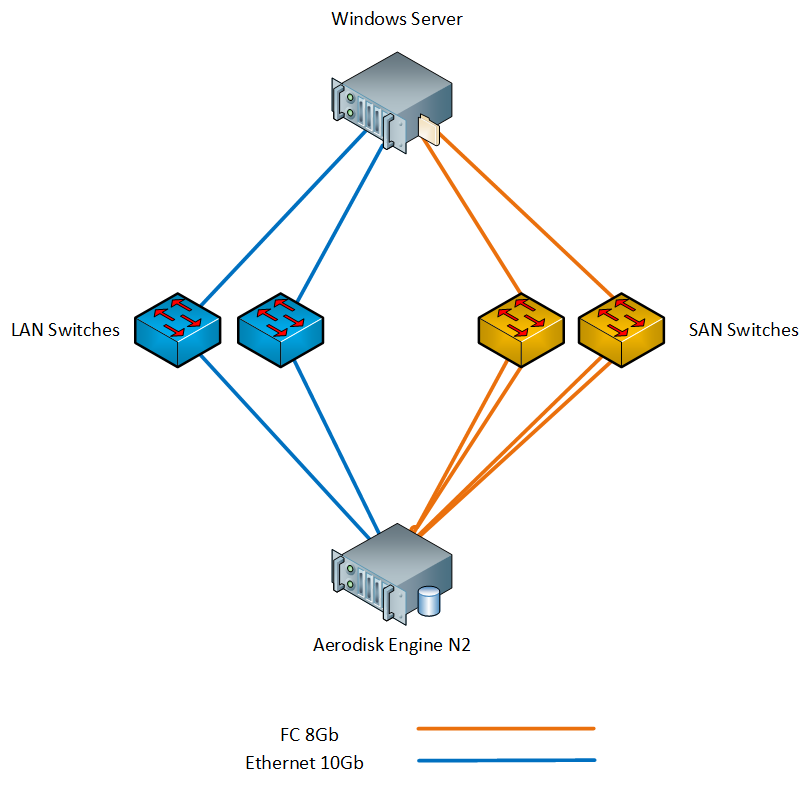
Unser Stand besteht aus folgendem Eisen:
- 1 x Aerodisk Engine N2-Speicher (2 Controller, 64 GB Cache, 8 x FC-Ports 8 Gbit / s, 4 x Ethernet-Ports 10 Gbit / s SFP +, 4 x Ethernet-Ports 1 Gbit / s); Die folgenden Festplatten sind im Speichersystem installiert:
- 4 x SAS SSD Disc 900 GB;
- 12 x SAS 10k-Laufwerke 1,2 TB;
- 1 x physischer Server mit Windows Server 2016 (2xXeon E5 2667 v3, 96 GB RAM, 2xFC-Ports 8 Gbit / s, 2x Ethernet-Ports 10 Gbit / s SFP +);
- 2 x SAN 8G-Schalter;
- 2 x LAN 10G-Switch;
Wir haben den Server über Switches über FC und Ethernet 10G mit dem Speicher verbunden. Schema des Standes unten.
Die erforderlichen Komponenten wie MPIO und iSCSI-Initiator werden unter Windows Server installiert.
Zonen werden auf FC-Switches konfiguriert, entsprechende VLANs werden auf LAN-Switches konfiguriert und MTU 9000 wird auf Speicherports, Switches und Host installiert (wie dies alles funktioniert, wird in unserer Dokumentation beschrieben, daher werden wir diesen Prozess hier nicht beschreiben).
Testmethode
Der Crashtest-Plan lautet wie folgt:
- Überprüfung des FC- und Ethernet-Portfehlers.
- Stromausfallprüfung.
- Überprüfen des Controller-Fehlers.
- Überprüfen Sie den Festplattenfehler in einer Gruppe / einem Pool.
Alle Tests werden unter synthetischen Lastbedingungen durchgeführt, die wir mit IOMETER erzeugen. Parallel dazu werden wir dieselben Tests durchführen, jedoch unter den Bedingungen, dass große Dateien auf das Speichersystem kopiert werden.
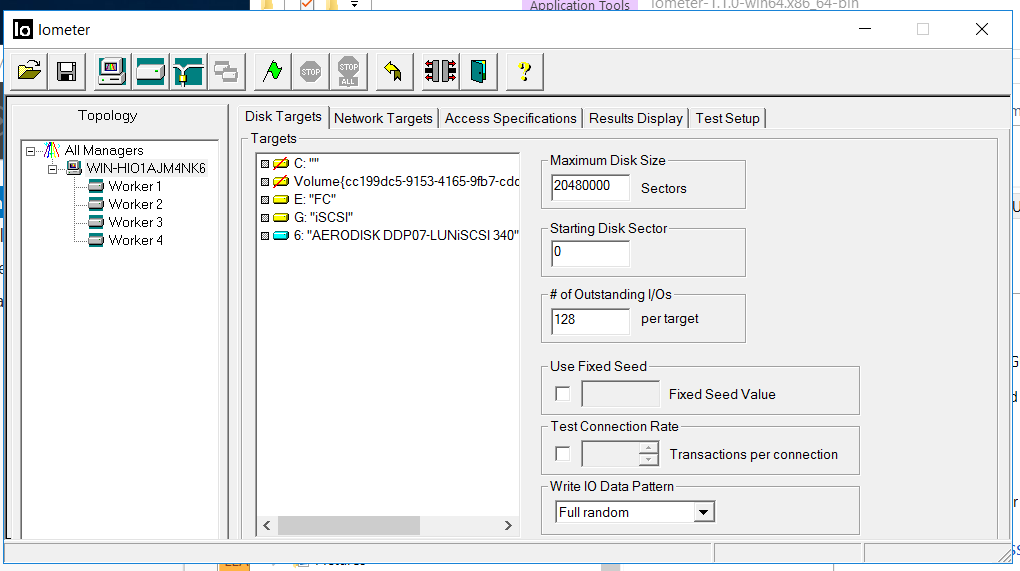
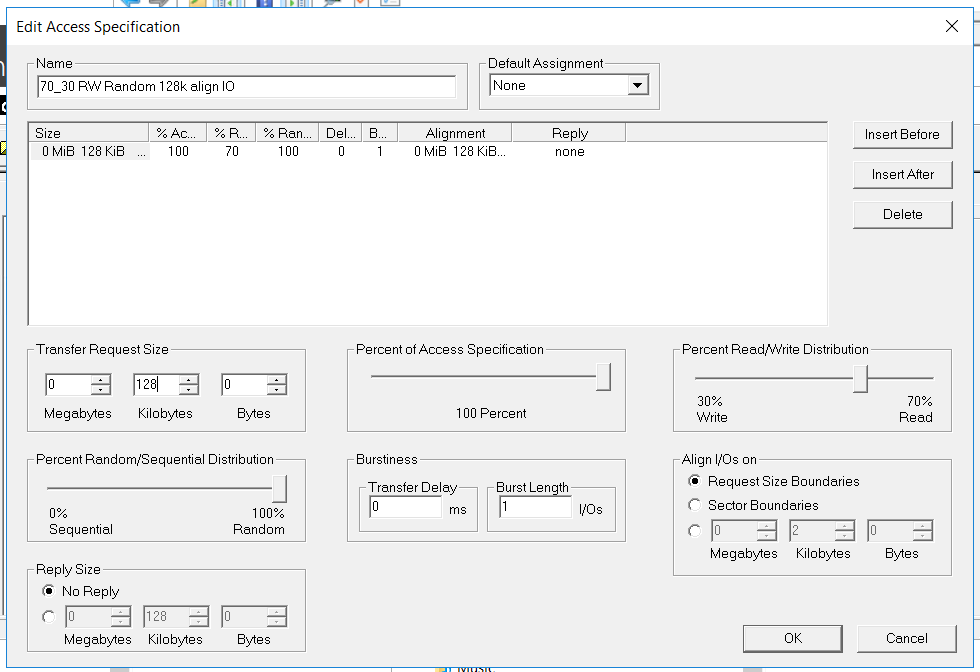
Die IOmeter-Konfiguration lautet wie folgt:
- Lesen / Schreiben - 70/30
- Block - 128k (wir haben beschlossen, das Speichersystem mit großen Blöcken zu benetzen)
- Die Anzahl der Threads beträgt 128 (was der Arbeitslast sehr ähnlich ist).
- Voll zufällig
- Anzahl der Arbeitnehmer - 4 (2 für FC, 2 für iSCSI)
 Der Test hat folgende Aufgaben:
Der Test hat folgende Aufgaben:- Stellen Sie sicher, dass das synthetische Laden und der Kopiervorgang nicht unterbrochen werden und bei verschiedenen Fehlermodi keine Fehler verursachen.
- Stellen Sie sicher, dass der Prozess des Wechsels von Ports, Controllern usw. ausreichend automatisiert ist und keine Administratoraktionen im Falle von Fehlern erforderlich sind (dh bei einem Failover wird natürlich nicht über Failbacks gesprochen).
- Stellen Sie sicher, dass die Informationen in den Protokollen korrekt angezeigt werden.
Host- und Speichervorbereitung
Wir haben den Blockzugriff auf den Speicher über FC- und Ethernet-Ports (FC bzw. iSCSI) konfiguriert. Wie das geht, haben die Jungs von TS Solution in einem früheren Artikel ( https://habr.com/en/company/tssolution/blog/432876/ ) ausführlich beschrieben. Nun, und natürlich hat niemand Handbücher und Kurse abgesagt.
Wir haben eine Hybridgruppe mit allen vorhandenen Laufwerken eingerichtet. 2 SSD-Festplatten werden dem Cache hinzugefügt, 2 SSD-Festplatten werden als zusätzliche Speicherebene hinzugefügt (Online-Schicht). Wir haben 12 SAS10k-Festplatten in RAID-60P (Triple Parity) gruppiert, um den Ausfall von drei Festplatten in einer Gruppe gleichzeitig zu überprüfen. Eine Festplatte wurde für die automatische Korrektur übrig gelassen.
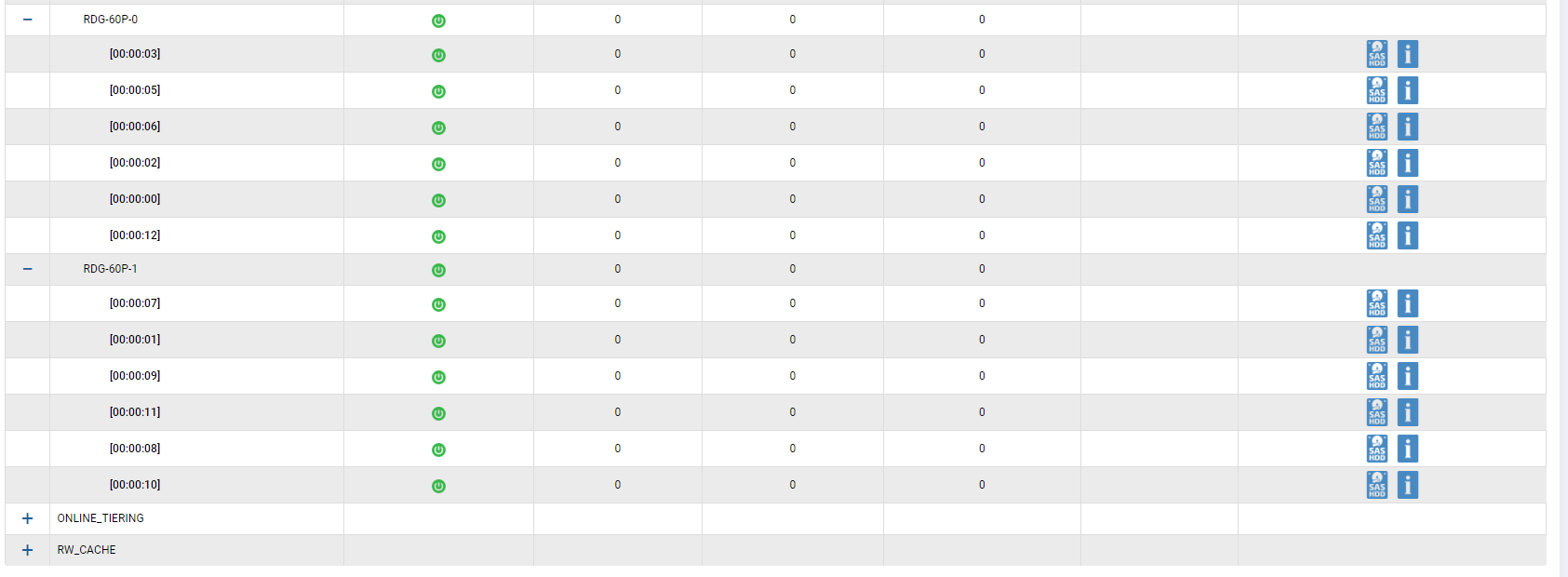
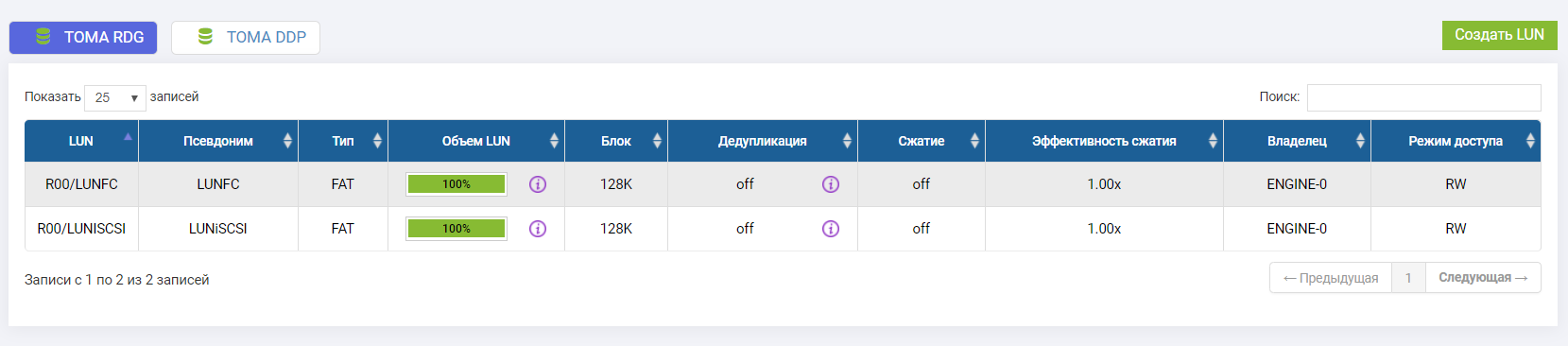
Wir haben zwei LUNs verbunden (eine auf FC, eine auf iSCSI).
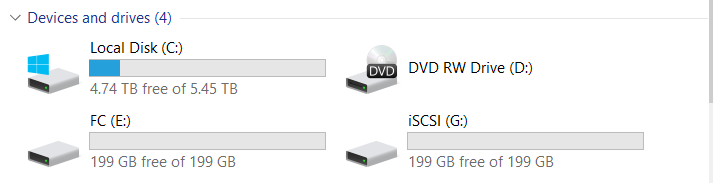
Beide LUNs gehören dem Engine-0-Controller.
Starten Sie den Test
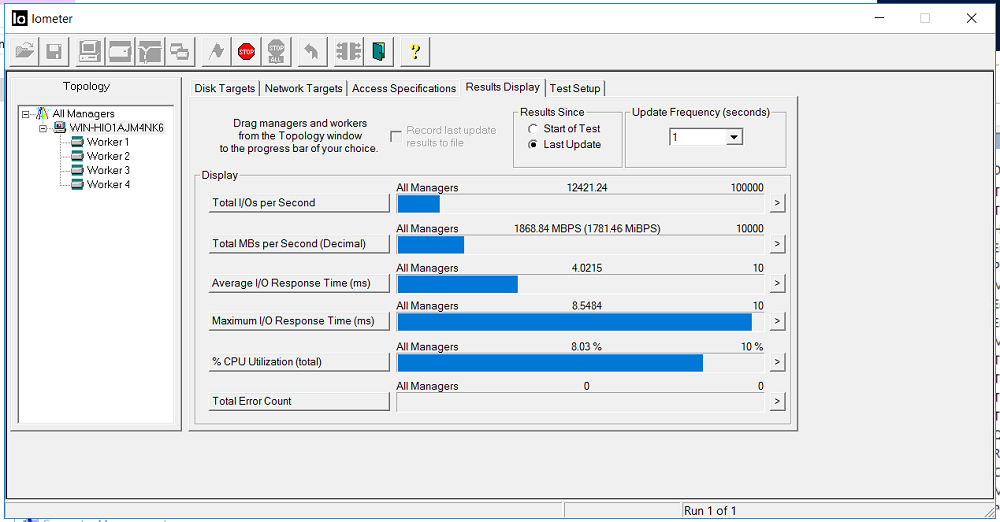
Schalten Sie IOMETER mit der obigen Konfiguration ein.
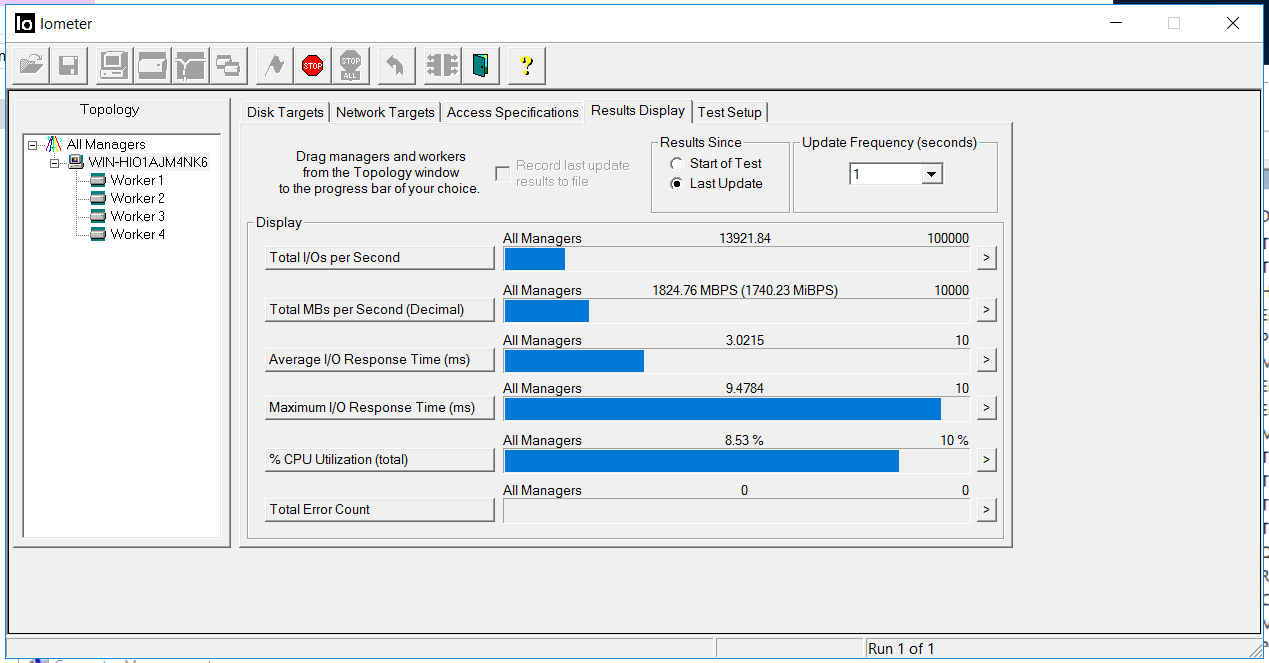
Wir korrigieren die Bandbreite von 1,8 GB / s und eine Verzögerung von 3 Millisekunden. Es liegen keine Fehler vor (Total Error Count).
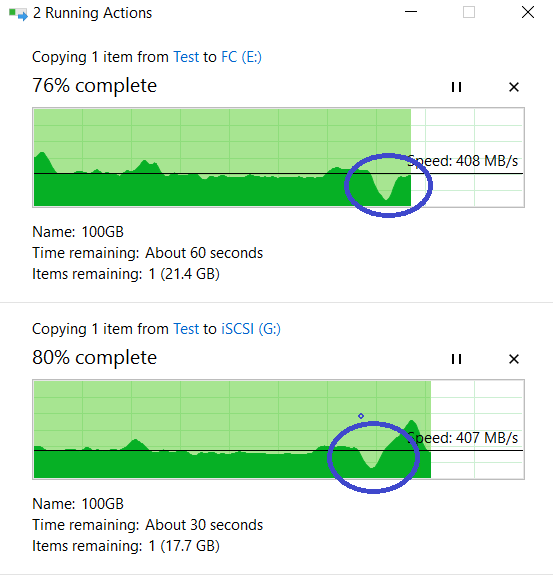
Gleichzeitig beginnen wir vom lokalen Laufwerk "C" unseres Hosts gleichzeitig, zwei große 100-GB-Dateien über andere Schnittstellen auf die FC- und iSCSI-LUNs des Speichersystems (E- und G-Festplatten in Windows) zu kopieren.
Oben ist der Vorgang des Kopierens auf LUN FC, unten iSCSI.

Test Nr. 1. Deaktivieren der E / A-Ports
Wir nähern uns der Rückseite des Speichersystems))) und ziehen mit einem Handgriff alle FC- und Ethernet 10G-Kabel aus dem Engine-0-Controller heraus. Als ob eine Putzfrau mit einem Mopp vorbeigegangen wäre und beschlossen hätte, den Boden genau dort zu waschen, wo Rotz lügt Kabel lagen (d. h. der Controller funktioniert weiterhin, aber die E / A-Ports sind tot).

Wir betrachten IOMETER und das Kopieren von Dateien. Die Bandbreite sank auf 0,5 GB / s, kehrte aber ziemlich schnell auf den vorherigen Stand zurück (in ca. 4-5 Sekunden). Es gibt keine Fehler.
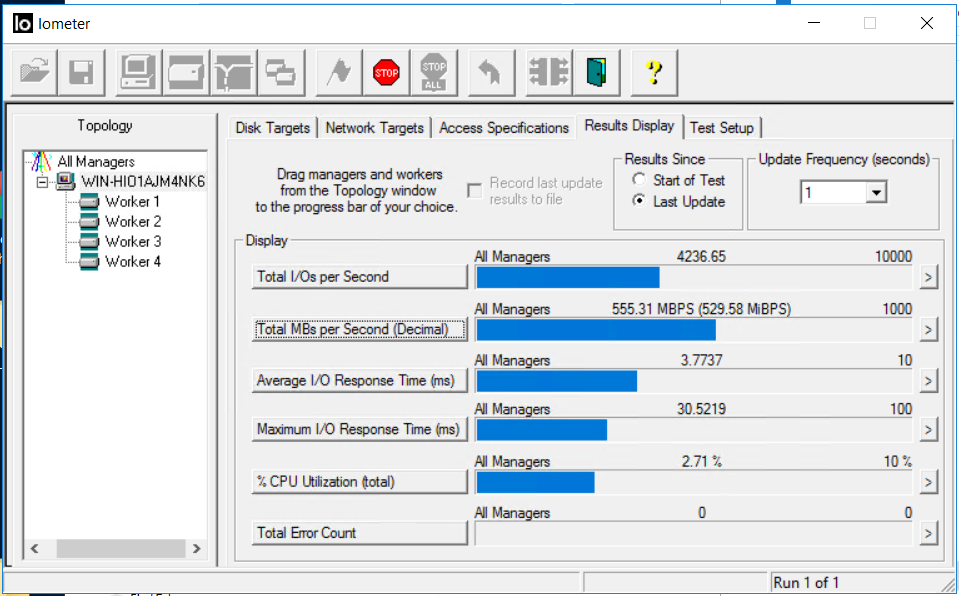
Das Kopieren von Dateien wurde nicht gestoppt, die Geschwindigkeit nimmt ab, ist jedoch völlig unkritisch (von 840 MB / s auf 720 MB / s gesunken). Das Kopieren hörte nicht auf.
Wir schauen in die Protokolle des Speichersystems und sehen eine Meldung über die Nichtverfügbarkeit von Ports und das automatische Verschieben der Gruppe.

Das Dashboard zeigt uns auch, dass mit FC-Ports nicht alles sehr gut ist.
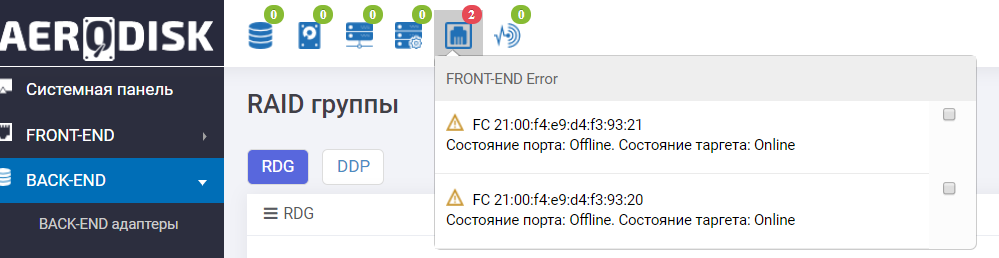
Die Speicher-E / A-Ports sind erfolgreich fehlgeschlagen .
Testnummer 2. Deaktivieren des Speichercontrollers
Fast sofort (nachdem wir die Kabel wieder in das Speichersystem eingesteckt hatten) beschlossen wir, den Speicher zu beenden, indem wir den Controller aus dem Gehäuse zogen.
Wieder nähern wir uns dem Speichersystem von hinten (es hat uns gefallen))) und dieses Mal ziehen wir den Engine-1-Controller heraus, der in diesem Moment der Eigentümer von RDG ist (zu dem die Gruppe umgezogen ist).
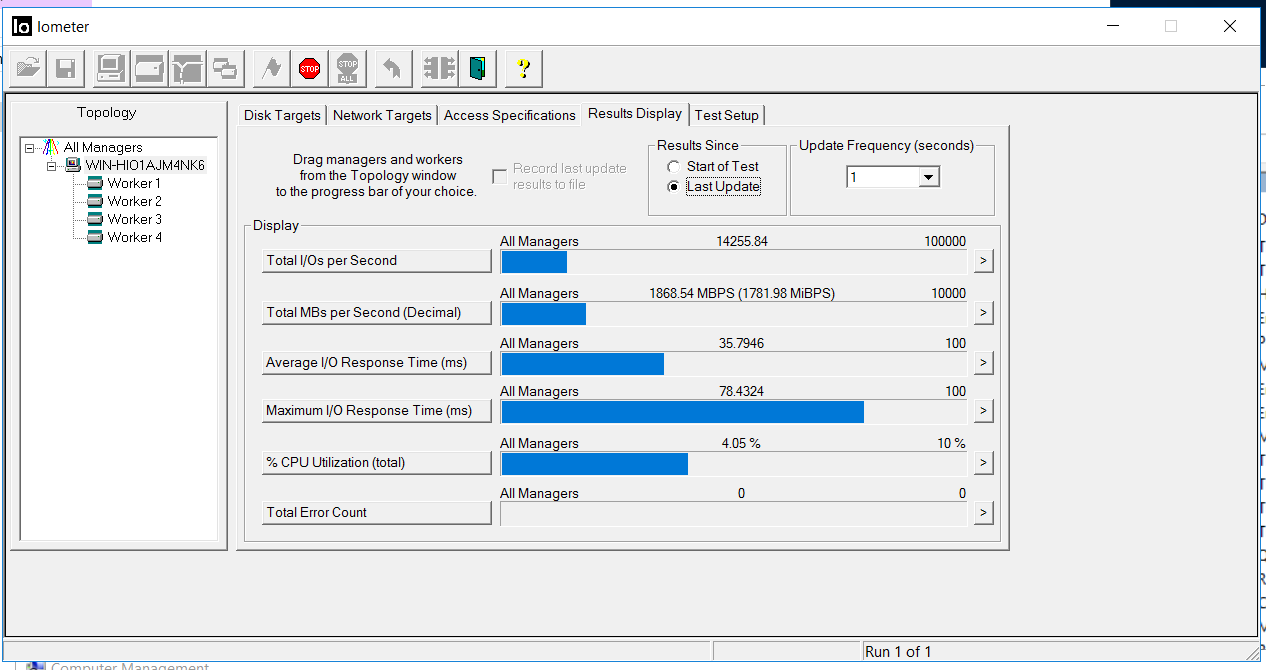
Die Situation im IOmeter ist wie folgt. Der Eingang wurde für ca. 5 Sekunden gestoppt. Fehler häufen sich nicht.
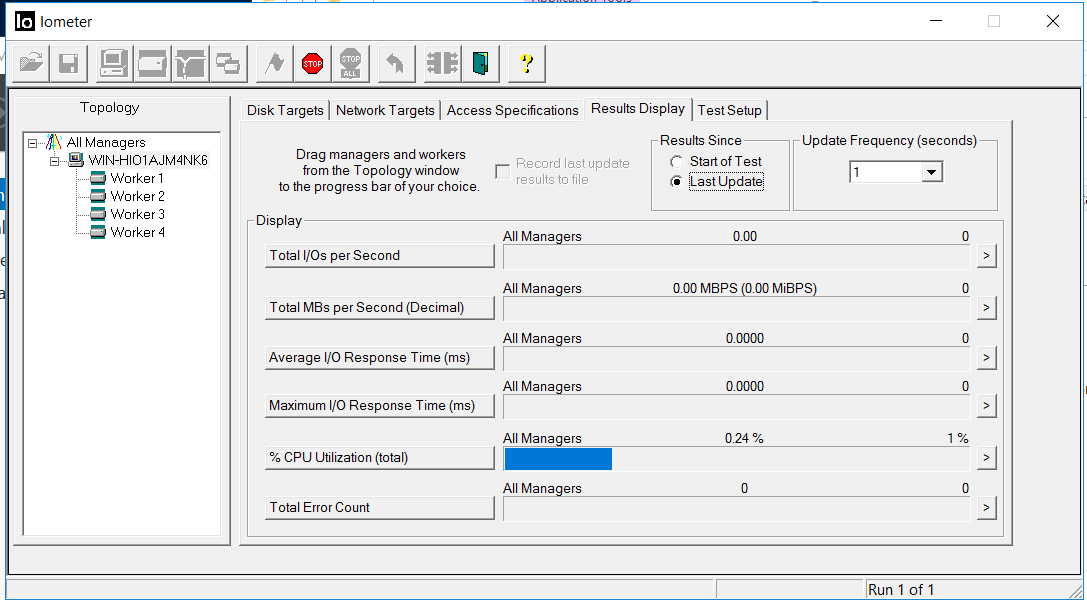
Nach 5 Sekunden wurde die E / A mit ungefähr den gleichen Durchsatzraten, jedoch mit Verzögerungen von 35 Millisekunden wieder aufgenommen (Verzögerungen wurden nach etwa einigen Minuten korrigiert). Wie aus den Screenshots ersichtlich ist, ist der Wert der Gesamtzahl der Fehler 0, dh es gab keine Schreib- oder Lesefehler.
Wir schauen uns das Kopieren unserer Dateien an. Wie Sie sehen können, hat es nicht unterbrochen, es gab einen kleinen Leistungsabfall, aber im Allgemeinen kehrte alles auf die gleichen ~ 800 MB / s zurück.
Wir gehen zum Speichersystem und sehen dort im Informationsfeld einen Missbrauch, dass der Engine-1-Controller nicht verfügbar ist (natürlich haben wir ihn geknallt).
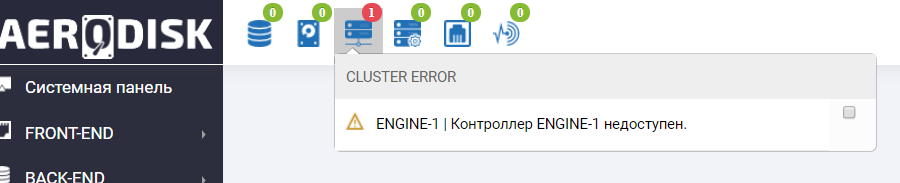
Wir sehen auch einen ähnlichen Eintrag in den Protokollen.

Der Ausfall des Speichercontrollers hat ebenfalls erfolgreich überlebt .
Testnummer 3. Trennen Sie die Stromversorgung.
Nur für den Fall, wir haben wieder angefangen, die Dateien zu kopieren, aber IOMETER hat nicht aufgehört.
Wir ziehen den BP-Schnick.

Eine weitere Warnung wurde dem Speicher im Informationsfenster hinzugefügt.

Wir sehen auch im Sensormenü, dass die Sensoren, die dem herausgezogenen Netzteil zugeordnet sind, rot werden.

SHD arbeitet weiter. Der Ausfall des BP-Schnick hat keinerlei Auswirkungen auf den Betrieb des Speichersystems. Aus Sicht des Hosts blieben die Anzeigen für Kopiergeschwindigkeit und IOMETER unverändert.
Stromausfalltest erfolgreich abgeschlossen.
Vor dem letzten Test haben wir uns entschlossen, den SHD wieder ein wenig zum Leben zu erwecken, den Controller und BP-shnik wieder einzuschalten und die Dinge mit den Kabeln in Ordnung zu bringen, die der SHD uns gerne mit grünen Symbolen in seinem Gesundheitsfenster mitteilte.

Testnummer 4. Ausfall von drei Festplatten in der Gruppe
Vor diesem Test haben wir einen zusätzlichen Vorbereitungsschritt durchgeführt. Tatsache ist, dass der ENGINE-Speicher eine sehr nützliche Funktion bietet - verschiedene Richtlinien zum Wiederherstellen (Wiederherstellen). Zuvor hat TS Solution über diese Funktion geschrieben, erinnert sich jedoch an ihre Essenz. Der Speicheradministrator kann die Priorität der Ressourcenzuweisung während der Wiederherstellung festlegen. Oder in Richtung E / A-Leistung, dh längerer Neuaufbau, aber es gibt keinen Leistungsabfall. Oder in Richtung der Wiederherstellungsgeschwindigkeit, aber die Leistung wird reduziert. Oder eine ausgewogene Option. Da die Leistung des Speichers während einer Neuerstellung einer Datenträgergruppe dem Administrator immer Kopfschmerzen bereitet, testen wir die Richtlinie mit einer Abweichung in Richtung der E / A-Leistung und zum Nachteil der Geschwindigkeit der Neuerstellung.

Überprüfen Sie nun den Ausfall der Laufwerke. Wir aktivieren auch die Aufzeichnung auf LUNs (Dateien und IOMETER). Da wir eine Triple-Parity-Gruppe (RAID-60P) haben, bedeutet dies, dass das System dem Ausfall von drei Festplatten standhalten muss. Nach dem Ausfall muss die automatische Ersetzung funktionieren. Eine Festplatte muss anstelle einer der ausgefallenen in der RDG stehen, und die Neuerstellung sollte darauf beginnen.
Wir fangen an. Markieren Sie zunächst über die Speicherschnittstelle die Datenträger, die Sie herausziehen möchten (um den Datenträger mit automatischem Austausch nicht zu verpassen und nicht zu ziehen).

Überprüfen Sie die Anzeige auf dem Bügeleisen. Alles ist in Ordnung, wir sehen die hervorgehobenen drei Laufwerke.

Und ziehen Sie diese drei Scheiben heraus.

Wir schauen uns den Gastgeber an. Und da ... ist nichts Besonderes passiert.
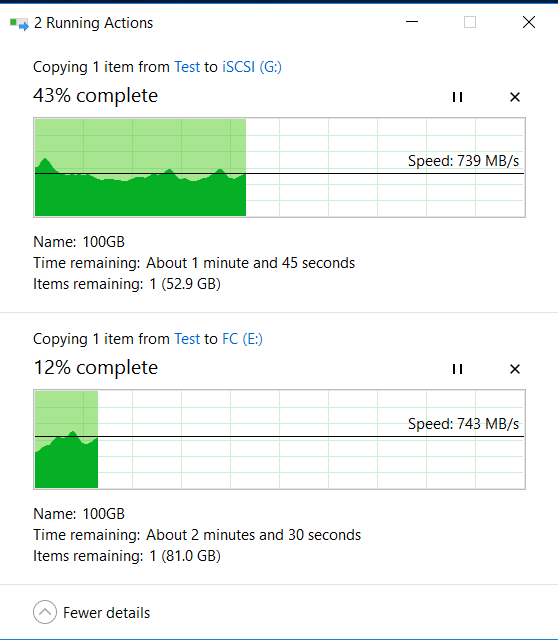
Das Kopieren von Indikatoren (sie sind höher als zu Beginn, da sich der Cache erwärmt hat) und IOMETER ändern sich beim Ziehen von Datenträgern und Starten der Neuerstellung nicht wesentlich (innerhalb von 5-10%).
Wir schauen uns den Speicher an.
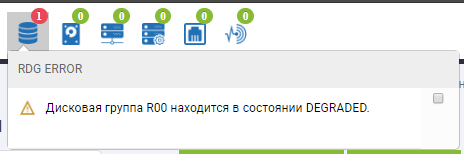
Im Status der Gruppe sehen wir, dass der Wiederaufbauprozess begonnen hat und kurz vor dem Abschluss steht.

Das RDG-Skelett zeigt an, dass sich 2 Festplatten im roten Status befinden und eine bereits ersetzt wurde. Die AutoCorrect-Festplatte ist nicht mehr vorhanden, sondern ersetzt die dritte ausgefallene Festplatte. Rebild wurde einige Minuten lang ausgeführt, die Dateiaufzeichnung wurde nicht unterbrochen, als 3 Festplatten ausfielen, und die E / A-Leistung änderte sich nicht wesentlich.
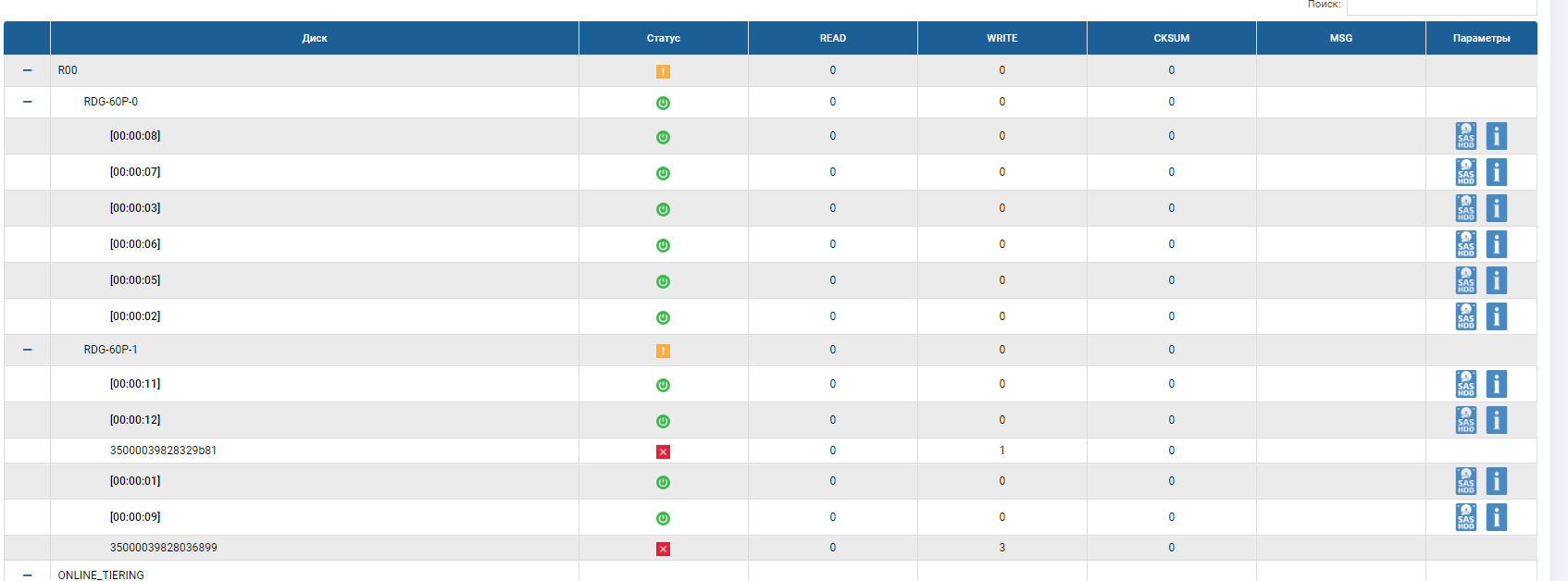
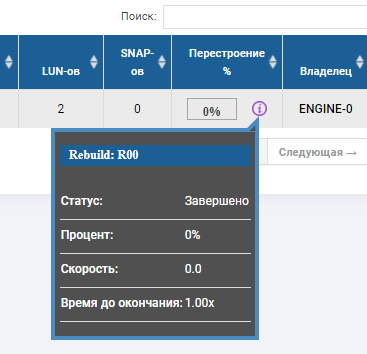
Der Laufwerksausfalltest war definitiv erfolgreich.
Fazit
Aus diesem Grund haben wir beschlossen, den Missbrauch von Speichersystemen zu stoppen. Zusammenfassend:
- FC Port Failure Check - Erfolgreich
- Ethernet Port Failure Check - Erfolgreich
- Controller-Fehlerprüfung - erfolgreich
- Stromausfallprüfung - erfolgreich
- Überprüfen Sie den Festplattenfehler in Gruppe \ Pool - erfolgreich
Keiner der Fehler stoppte die Aufzeichnung und verursachte keine synthetischen Ladefehler. Der Leistungsabfall war natürlich (und wir wissen, wie man dies besiegt, was wir bald tun werden), aber angesichts der Tatsache, dass dies Sekunden sind, ist dies durchaus akzeptabel. Schlussfolgerung: Bei der Fehlertoleranz aller AERODISK-Speicherkomponenten, die auf der Ebene gearbeitet wurden, gibt es keine Fehlerquellen.
Natürlich können wir im Rahmen eines Artikels nicht alle Fehlerszenarien testen, aber wir haben versucht, die beliebtesten abzudecken. Bitte senden Sie daher Ihre Kommentare, Wünsche für die folgenden Veröffentlichungen und natürlich angemessene Kritik. Wir werden gerne diskutieren (und besser zum Training kommen, nur für den Fall, den Zeitplan duplizieren)! Bis zu neuen Tests!
- Nischni Nowgorod (BEREITS FUNKTIONIERT - Sie können sich hier registrieren https://aerodisk.promo/nn/ );
Bis zum 16. April 2019 können Sie das Zentrum jederzeit besuchen. Am 16. April 2019 wird ein großer Schulungskurs organisiert. - Krasnodar (BALD KOMMEN - hier anmelden https://aerodisk.promo/krsnd/ );
Vom 9. bis 25. April 2019 können Sie das Zentrum jederzeit besuchen. Am 25. April 2019 wird ein großer Schulungskurs organisiert. - Jekaterinburg (BALD ERÖFFNUNG, folgen Sie den Informationen auf unserer Website oder auf Habré);
Mai-Juni 2019. - Nowosibirsk (folgen Sie den Informationen auf unserer Website oder auf Habré);
Oktober 2019 - Krasnojarsk (folgen Sie den Informationen auf unserer Website oder auf Habré);
November 2019