Die Anhäufung technischer Schulden kann Ihr Unternehmen in eine Krise führen. Es kann aber auch zu einem starken Treiber für massive Prozessänderungen werden und bei der Einführung von Konstruktionspraktiken helfen. Ich werde es Ihnen anhand meines eigenen Beispiels erzählen.
 Das IT-Team
Das IT-Team von
Dodo Pizza wuchs innerhalb von 7 Jahren von 2 Entwicklern in einem Land auf 60 Mitarbeiter in 12 Ländern. Als Scrum Master und XP Coach half ich Teams dabei, Prozesse einzurichten und technische Praktiken anzuwenden, aber diese Einführung war zu langsam. Es war für mich eine Herausforderung, die Teams dazu zu bringen, eine hohe Codequalität beizubehalten, wenn mehrere Teams an einem einzigen Produkt arbeiten. Wir sind in die Falle geraten, Geschäftsmerkmale der technischen Exzellenz vorzuziehen, und haben zu viele architektonische technische Schulden angehäuft. Als das Marketing 2018 eine massive Werbekampagne startete, konnten wir die Last nicht aushalten und fielen hin. Es war eine Schande. Während der Krise haben wir jedoch festgestellt, dass wir um ein Vielfaches effizienter arbeiten können. Die Krise hat uns zu revolutionären Änderungen in den Prozessen und zur raschen Einführung der bekanntesten technischen Praktiken getrieben.
Hintergrund
Sie können denken, dass Dodo Pizza ein reguläres Pizzeria-Netzwerk ist. Aber eigentlich ist
Dodo Pizza ein IT-Unternehmen, das zufällig Pizza verkauft . Unser Geschäft basiert auf
Dodo IS - einer Cloud-basierten Plattform, die alle Geschäftsprozesse verwaltet, angefangen von der Auftragsannahme über das Kochen und Fertigstellen bis hin zur Bestandsverwaltung, Personalverwaltung und Entscheidungsfindung. In nur 7 Jahren sind wir von 2 Entwicklern, die eine einzelne Pizzeria bedienen, auf über 70 Entwickler gewachsen, die mehr als 470 Pizzerien in 12 Ländern bedienen.
Als ich vor zwei Jahren in das Unternehmen eintrat, hatten wir 6 Teams und ungefähr 30 Entwickler. Die Dodo IS-Codebasis hatte ungefähr 1 Million Codezeilen. Es hatte eine monolithische Architektur und nur eine sehr geringe Abdeckung durch Unit-Tests. Bis dahin hatten wir keine API / UI-Tests. Die Codequalität des Systems war enttäuschend. Wir wussten es und träumten von einer glänzenden Zukunft, als wir den Monolithen in ein Dutzend Dienste aufteilten und die schrecklichsten Teile des Systems neu schrieben. Wir zeichnen sogar das Diagramm „Architektur sein“, haben aber ehrlich gesagt fast nichts für den zukünftigen Zustand getan.
Mein primäres Ziel war es, den Entwicklern technische Praktiken beizubringen und einen Entwicklungsprozess aufzubauen, sodass 6 Teams an einem einzigen Produkt arbeiten .
Als das Team wuchs, litten wir mehr unter dem Mangel an klaren Prozess- und Konstruktionspraktiken. Unsere Releases wurden größer und länger, da immer mehr Entwickler zum System beitrugen. Wir hatten jedoch keine automatisierten Regressionstests und verschwendeten daher mit jedem Release mehr Zeit für die manuelle Regression. Wir haben unter vielen Änderungen gelitten, die von 6 Teams in verschiedenen Niederlassungen vorgenommen wurden. Wenn ein Team seine Änderungen vor der Veröffentlichung zu einem einzigen Zweig zusammenführte, verloren wir manchmal bis zu 4 Stunden, um Zusammenführungskonflikte zu lösen.
Scheiße passiert
2018 startete Marketing unsere erste Bundeswerbekampagne im Fernsehen . Es war eine große Veranstaltung für uns. Wir haben 100 Millionen Rubel (1,5 Millionen US-Dollar) für die Finanzierung der Kampagne ausgegeben - für uns ein beachtlicher Betrag. Das IT-Team bereitete sich ebenfalls auf die Kampagne vor. Wir haben unsere Bereitstellung automatisiert und vereinfacht - jetzt können wir den Monolithen mit einem einzigen Knopf in TeamCity in 12 Ländern bereitstellen. Wir haben Leistungstests untersucht und Schwachstellenanalysen durchgeführt. Wir haben unser Bestes gegeben, sind aber auf unerwartete Probleme gestoßen.
Die Werbekampagne war großartig. Wir gingen von 100 auf 300 Bestellungen / Minute. Das waren gute Nachrichten. Schlechte Nachrichten waren, dass Dodo IS einer solchen Belastung nicht standhalten konnte und starb. Wir haben unsere vertikalen Skalierungsgrenzen erreicht und konnten keine Bestellungen mehr bearbeiten. Das System wurde alle 3 Stunden neu gestartet. Jede Minute Ausfallzeit hat uns Millionen Geld gekostet und den Respekt wütender Kunden verloren.
Als ich vor 2 Jahren als Chief Agile Officer zu Dodo kam, hatte ich den großen Wunsch, aus unserem damals kleinen Team - ungefähr 12 Personen - ein Traumteam zu machen. Ich fing sofort an, technische Praktiken einzuführen. Die meisten Teams haben bald Paarprogrammierung, Unit-Tests und DDD eingeführt. Aber nicht alles war einfach. Ich musste den Widerstand der Entwickler, des Product Owner und des Support-Teams überwinden.
Im Gegensatz zu technischen Praktiken befürworteten nicht alle die Idee von Feature-Teams. Entwickler waren es gewohnt zu glauben, dass ein Team, das sich auf eine Komponente konzentriert, besseren Code schreibt. Es war nicht klar, wie die rasche Entwicklung von Geschäftsfunktionen mit dem längst überfälligen massiven Refactoring eines komplexen Systems kombiniert werden sollte. Ein kontinuierlicher Strom von Fehlern erforderte auch ständige Aufmerksamkeit. Das Support-Team bevorzugte es, ein eigenes Team zu haben, das sich nur auf die Behebung von Fehlern konzentriert. Viele Teams waren es gewohnt, in getrennten Niederlassungen zu arbeiten, und hatten Angst, sich häufig zu integrieren. Wir haben nicht mehr als einmal pro Woche veröffentlicht, und jede Veröffentlichung hat ziemlich lange gedauert, was eine enorme Menge an Unterstützung für manuelle Regression und UI-Tests erforderte. Ich habe versucht, das Problem zu beheben, aber meine Prozessänderungen waren zu langsam und fragmentiert.
Die Geschichte von Fall und Aufstieg
Ausgangszustand: Monolithische Architektur
Um die Geschwindigkeit der Entwicklung von Geschäftsfunktionen zu erreichen, haben wir technische Lösungen nicht immer gut durchdacht. Ein Mangel an Erfahrung hat uns ebenfalls betroffen. Am Anfang konnte es sich das Unternehmen nicht leisten, die besten Entwickler einzustellen. Wir haben mit Enthusiasten zusammengearbeitet, die sich bereit erklärt haben, bei der Entwicklung von Dodo IS zu helfen, an den Gründer des Unternehmens - Fedor - geglaubt und fast für Lebensmittel gearbeitet (natürlich Pizza). Die Entwickler, die sich dem Team anschlossen, folgten später der etablierten Architektur, die veraltet war. Wir hatten also eine monolithische Anwendung mit einer einzigen Datenbank, die alle Daten aller Komponenten an einem Ort enthielt. Tracker, Checkout, Site, API für Zielseiten - alle Komponenten des Systems arbeiteten mit einer einzigen Datenbank, was zu einem Engpass wurde. Unsere monolithische Architektur verursachte monolithische Probleme. Ein einzelner Blog-Beitrag führte zu einem Ausfall der Restaurantkasse.
Wahre Geschichte
Um zu veranschaulichen, wie fragil die monolithische Architektur ist, gebe ich nur ein Beispiel. Einmal haben alle unsere Restaurants in Russland aufgrund eines Blogposts keine Bestellungen mehr angenommen. Wie kann das passieren?
Eines Tages veröffentlichte unser CEO - Fedor einen Beitrag in seinem Blog. Dieser Beitrag gewann schnell an Popularität. Auf der Blog-Website des Fedor gibt es einen Zähler, der eine Reihe von Pizzerien in unserer Kette und den Gesamtumsatz aller Pizzerien anzeigt. Jedes Mal, wenn jemand Fedors Blog las, schickte der Webserver eine Anfrage an die Master-Datenbank, um die Einnahmen zu berechnen. Diese Anfragen überlasteten die Datenbank und es wurden keine Anfragen mehr an der Kasse des Restaurants bearbeitet. Ein beliebter Blogbeitrag störte also die Arbeit der gesamten Restaurantkette. Wir haben das Problem schnell behoben, aber es war (unter anderem) ein klares Zeichen dafür, dass unsere Architektur die geschäftlichen Anforderungen nicht erfüllen kann und neu gestaltet werden muss. Aber wir haben diese Zeichen ignoriert. Wir haben schnelle und einfache Lösungen implementiert (wie das Hinzufügen einer schreibgeschützten Replik der Master-Datenbank), aber wir hatten keine technische Roadmap für die Neugestaltung.
Monolithische Architektur ist gut zu beginnen, weil es einfach ist. Aber es kann der hohen Last nicht standhalten, die ein einzelner Fehlerpunkt ist.
Früh scheitert 2017
Der 14. Februar ist ein Valentinstag . Jeder liebt diesen Urlaub. Damit sich die Liebenden gegenseitig gratulieren können, machen wir am 14. Februar eine spezielle Pizza - Peperoni in Form eines Herzens. Ich werde mich für immer an den 14. Februar 2017 erinnern, denn an diesem Tag, als alle Pizzerien unter Volllast arbeiteten, begann Dodo IS zu fallen. In jeder Pizzeria haben wir 4-5 Tabletten zum Nachverfolgen, für welche Bestellung ein Pizzabäcker Teig macht, Zutaten legt, backt oder zur Lieferung sendet. Die Anzahl der Pizzerien erreichte 300+, jedes Tablet aktualisierte seinen Status mehrmals pro Minute. Alle diese Anforderungen haben die Datenbank so stark belastet, dass der SQL Server nicht mehr standhält und die Datenbank ausfällt. Dodo IS wird im unangemessensten Moment festgelegt - während des Höhepunkts des Umsatzes. Es stand eine arbeitsreiche Ferienzeit bevor: der 23. Februar (Tag der Armee und der Marine), der 8. März (Internationaler Frauentag), der 1. Mai (Tag der internationalen Solidarität der Arbeiter) und der 9. Mai (Tag des Sieges im Zweiten Weltkrieg). In diesen Ferien erwarteten wir ein noch größeres Auftragswachstum.
Der Tag, an dem du sterben wirst . In Kenntnis unserer Wachstumspläne und der Grenze der Belastung, der wir standhalten können, haben wir herausgefunden, wie lange wir am Leben bleiben können, dh wenn die heutige Spitzenlast regelmäßig wird. Das geschätzte Datum von Harmagedon wird in etwa sechs Monaten erwartet - im August oder September. Wie fühlt es sich an zu leben, wenn man das Datum seines Todes kennt?
Stoppen Sie die Feature-Entwicklung für ein Jahr . Zusammen mit CEO Fedor mussten wir eine schwierige Entscheidung treffen. Vielleicht eine der schwierigsten Entscheidungen in der Geschichte des Unternehmens. Wir haben die Entwicklung von Geschäftsfunktionen gestoppt. Wir dachten, wir würden für 3 Monate aufhören, aber bald stellten wir fest, dass das Volumen der technischen Schulden so groß war, dass 3 Monate nicht ausreichen würden, und wir müssen weiter an technischen Problemen arbeiten und den Geschäftsstau verschieben. Tatsächlich haben wir mit 6 Teams im nächsten Jahr nur ein Geschäftsfeature erstellt. Den Rest der Zeit waren die Teams mit der Rückzahlung von technischen Schulden beschäftigt. Diese Schulden haben uns viel gekostet - über 1,5 Mio. USD.
Einige Verbesserungen nach einem Jahr
Im Laufe des Jahres hatten wir folgende bemerkenswerte Erfolge:
- Wir haben unsere Bereitstellungspipeline automatisiert und beschleunigt. Zuvor war die Bereitstellung halbmanuell. Wir haben uns in ca. 2 Stunden in 10 Ländern eingesetzt.
- Begann einen Monolithen zu spalten. Der am stärksten ausgelastete Teil des Systems - der Tracker - wurde auf einen separaten Dienst mit eigener Datenbank aufgeteilt. Jetzt kommuniziert der Tracker über eine Warteschlange mit Ereignissen mit dem Rest des Systems.
- Wir haben begonnen, den Lieferkassierer zu trennen - die zweite Komponente, die eine hohe Last erzeugt.
- Benutzer- und Geräteauthentifizierungssystem neu geschrieben.
Unser Architekt hat den technischen Rückstand bewältigt. Wir haben die architektonischen Änderungen genutzt, um den Rückstand zu steigern. Jedes Team hatte die Freiheit, das Richtige zu tun, um eine nützliche Architektur zu erstellen. Für das Jahr mit den 6. Teams haben wir nur ein wertvolles Feature für das Geschäft gemacht. Den Rest der Zeit arbeiteten die Teams an technischen Schulden. Es scheint, dass wir stolz auf uns sein können. Aber vor uns gab es eine große Enttäuschung.
Scheitern während der Federal Marketing Campaign. Die zweite Vertrauenskrise.
Technische Schulden sind leicht zu akkumulieren, aber sehr schwer zurückzuzahlen. Es ist unwahrscheinlich, dass Sie im Voraus verstehen, wie viel es Sie kosten wird.
Trotz der Tatsache, dass wir ein ganzes Jahr lang gegen technische Schulden gekämpft haben, waren wir nicht bereit für eine massive Marketingkampagne und haben es vor unserem Geschäft vermasselt. Sie gewinnen Vertrauen in Tropfen, Sie verlieren es in Eimern. Und wir mussten es wieder gewinnen.
Wir haben den Moment verpasst, in dem es notwendig war, die Entwicklung von Geschäftsfunktionen zu verlangsamen und technische Schulden in den Griff zu bekommen. Es war zu spät, als wir es bemerkten. Wir legen uns wieder unter Last. Das System stürzte ab und startete alle 3 Stunden neu. Unser Geschäft verlor zig Millionen Rubel.

Dank der Krise haben wir jedoch gesehen, dass wir unter extremen Bedingungen um ein Vielfaches effizienter arbeiten können. Wir haben 20 Mal am Tag veröffentlicht. Alle arbeiteten als ein Team und konzentrierten sich auf ein einziges Ziel. Während der zweiwöchigen Krise haben wir das getan, wovor wir uns vorher gefürchtet hatten, weil wir glaubten, dass es Monate dauern würde. Asynchrone Reihenfolge, Leistungstests und klare Protokolle sind nur ein kleiner Teil unserer Arbeit. Wir waren bestrebt, weiterhin so effektiv zu arbeiten, aber ohne Überstunden und Stress.
Lektionen gelernt
Nach der Retrospektive haben wir unsere Prozesse komplett umstrukturiert. Wir haben das LeSS-Framework übernommen und durch technische Verfahren ergänzt. In den nächsten Monaten haben wir einen Durchbruch bei der Einführung von Konstruktionspraktiken erzielt. Basierend auf dem LeSS-Framework haben wir Folgendes implementiert und verwenden es weiterhin:
- einzelner Rückstand;
- voll funktions- und komponentenübergreifende Feature-Teams;
- Paarprogrammierung;
- Mob-Programmierung versuchen.
- Echte kontinuierliche Integration, dh mehrere Code-Integrationen von 9 Teams in einem Zweig;
- vereinfachtes Konfigurationsmanagement mit trunkbasierter Entwicklung;
- häufige Releases: Continuous Deployment für Microservices, mehrere Releases pro Tag für Monolithen;
- Kein separates QA-Team, QA-Experten sind Teil der Entwicklungsteams.
6 Praktiken, die wir nach der Krise gewählt haben
1. Die Kraft des Fokus . Vor der Krise arbeitete jedes Team an seinem eigenen Rückstand und spezialisierte sich auf seine Domäne. Im Rückstand gab es fein zerlegte Aufgaben, das Team wählte mehrere Aufgaben für einen Sprint aus. Aber während der Krise haben wir ganz anders gearbeitet. Die Teams hatten keine spezifischen Aufgaben, sondern ein großes herausforderndes Ziel. Beispielsweise müssen eine mobile App und eine API 300 Bestellungen pro Minute verarbeiten, egal was passiert. Es ist Sache des Teams, wie das Ziel erreicht wird. Die Teams selbst formulieren Hypothesen, überprüfen sie schnell in der Produktion und werfen sie weg. Und genau das wollten wir auch weiterhin tun. Teams wollen keine dummen Programmierer sein, sie wollen Probleme lösen.
Die Kraft des Fokus manifestierte sich in der Lösung komplexer Probleme. Während der Krise haben wir beispielsweise eine Reihe von Leistungstests erstellt, obwohl wir kein Fachwissen hatten. Wir haben auch die Logik des Empfangs einer Bestellung asynchron gemacht. Wir haben lange darüber nachgedacht und gesprochen, und es schien uns, dass dies eine sehr schwierige und lange Aufgabe ist. Es stellte sich jedoch heraus, dass das Team in zwei Wochen durchaus in der Lage ist, dies zu tun, wenn es nicht abgelenkt ist und sich vollständig auf das Problem konzentriert.
2. Regelmäßige Hackathons . Wir haben gerne im Modus gearbeitet, in dem alle Teams auf ein Ziel ausgerichtet sind, und wir haben beschlossen, manchmal solche „Hackathons“ zu organisieren. Es kann nicht gesagt werden, dass wir sie regelmäßig durchführen, aber es gab einige Male. Zum Beispiel gab es einen Hackathon mit 500 Fehlern, bei dem alle Teams die Protokolle bereinigten und die Ursachen für 500 Fehler auf der Site und in der API beseitigten. Ziel war es, die Protokolle sauber zu halten. Wenn die Protokolle sauber sind und die neuen Fehler deutlich sichtbar sind, können Sie die Schwellenwerte für die Warnungen einfach konfigurieren. Es ist ähnlich wie bei Unit-Tests - sie können nicht ein wenig rot sein.
Ein weiteres Beispiel für einen Hackathon sind Bugs. Früher hatten wir einen riesigen Fehlerrückstand, einige der Fehler waren seit Jahren im Rückstand. Es schien, dass sie niemals enden würden. Und jeden Tag gab es neue. Sie müssen die Arbeit an Fehlern und an regulären Backlog-Elementen irgendwie kombinieren.
Wir haben die Richtlinie #zerobugspolicy in 4 Schritten eingeführt.- Erste Fehlerbehebung basierend auf dem Datum. Wenn der Fehler länger als 3 Monate im Backlog ist, löschen Sie ihn einfach. Höchstwahrscheinlich war es ewig dort.
- Sortieren Sie nun die verbleibenden Fehler danach, wie sie sich auf Kunden auswirken. Wir haben die verbleibenden Fehler sorgfältig aussortiert. Wir haben nur Fehler aufbewahrt, die einer großen Gruppe von Benutzern das Leben schwer machen. Wenn dies nur etwas ist, das Unannehmlichkeiten verursacht, Sie aber damit umgehen können - löschen Sie es rücksichtslos. Deshalb haben wir die Anzahl der Fehler auf 25 reduziert, was akzeptabel ist.
- Hackathon. Alle Teams schwärmen und beheben alle Fehler. Wir haben das in ein paar Sprints gemacht. Bei jedem Sprint nahm jedes Team mehrere Fehler und behebte sie. Nach 2-3 Sprints hatten wir einen deutlichen Bugs Backlog. Jetzt können Sie #zerobugspolicy eingeben.
- #zerobugspolicy. Jeder neue Fehler hat jetzt nur zwei Möglichkeiten. Äther, es fällt in den Rückstand oder nicht. Wenn es zu einem Rückstand kommt, beheben wir ihn zuerst. Jeder Fehler im Backlog hat eine höhere Priorität als jedes andere Backlog-Element. Aber um in den Rückstand zu geraten, muss der Fehler schwerwiegend sein. Entweder verursacht es irreparablen Schaden oder es betrifft eine große Anzahl von Benutzern.
3. Temporäre Projektteams zu stabilen Feature-Teams . Es gab eine lustige Geschichte mit Projektteams. Während der Krise haben wir Tigerteams gebildet, die für diese Aufgabe am besten geeignet waren. Nachdem die Krise vorbei war, beschlossen die Teams, diese Praxis fortzusetzen und die Teams aufzulösen. Trotz der Tatsache, dass mir diese Idee überhaupt nicht gefallen hat, ließ ich sie es versuchen. In nur 2 Wochen (ein Sprint), bei der nächsten Retrospektive, gaben die Teams dieses Training auf (diese Entscheidung machte mich äußerst glücklich). Sie haben versucht und verstanden, warum es viel komfortabler ist, in einem stabilen Feature-Team zu arbeiten. Auch wenn dem Team einige Fähigkeiten fehlen, können sie nach und nach lernen. Aber der Teamgeist, die Unterstützung und die gegenseitige Unterstützung werden für eine lange Zeit gebildet, es dauert Monate. Kurzfristige Projektteams befinden sich ständig in der Formungs- und Sturmphase. Sie können es ein paar Wochen aushalten, aber Sie können nicht die ganze Zeit so arbeiten. Es ist gut, dass die Teams die Vorteile stabiler Feature-Teams ausprobiert und verstanden haben.
4. Befreien Sie sich von der manuellen Regression . Vor der Krise haben wir einmal pro Woche und während der Krise Dutzende Male am Tag veröffentlicht. Wir haben unsere Fähigkeit geliebt, oft zu veröffentlichen. Wir haben geschätzt, wie bequem es war, eine kleine Änderung vorzunehmen, sie schnell bereitzustellen und sofort Feedback von der Produktion zu erhalten. Aus diesem Grund haben wir unseren Ansatz für Releases geändert, was sich auf den Ansatz für Programmierung und Design auswirkte. Jetzt veröffentlichen wir kontinuierlich alle 1-2 Tage. Alles in der Entwicklungsbranche geht in Produktion. Auch wenn einige Funktionen nicht bereit sind, ist dies kein Grund, den Code nicht freizugeben. Wenn wir Benutzern noch keine noch nicht bereitgestellten Funktionen anzeigen möchten, blenden wir sie mit Funktionsumschaltungen aus. Dieser Ansatz hat uns geholfen, uns in kleinen Schritten zu entwickeln.
Wir haben uns zum Ziel gesetzt, manuelle Regressionen loszuwerden. Wir haben 1,5 Jahre gebraucht, um es zu erreichen. Wenn Sie jedoch ein langfristig ehrgeiziges Ziel haben, denken Sie über Schritte nach, die zum Ziel führen.
Wir haben es in 3 Schritten gemacht.- Kritischen Pfad automatisieren. Im Juni 2017 haben wir das QA-Team gebildet. Die Aufgabe des Teams bestand darin, die Regression der kritischsten Funktion von Dodo IS zu automatisieren - Auftragsannahme und Produktion. Während der nächsten 6 Monate deckte ein neues QS-Team von 4 Personen den gesamten kritischen Pfad ab. Entwickler von Feature-Teams haben ihnen aktiv geholfen. Gemeinsam haben wir eine schöne und verständliche domänenspezifische Sprache (DSL) geschrieben, die auch von Kunden gelesen werden konnte. Parallel zu den End-to-End-Tests deckten die Entwickler den Code mit Unit-Tests ab. Einige neue Komponenten wurden mit TDD neu gestaltet. Danach haben wir das QA-Team aufgelöst. Die ehemaligen QA-Teammitglieder schlossen sich Feature-Teams an, um Fachwissen über die Unterstützung und Wartung von Autotests auszutauschen.
- Schattenmodus. Mit Autotests haben wir in 5 Releases manuelle Regressionen im Schattenmodus durchgeführt. Die Teams verließen sich nur auf eine automatisierte Testsuite. Als das Team jedoch entschied, dass wir zur Veröffentlichung bereit sind, führen wir eine manuelle Regression durch, um zu überprüfen, ob unsere Autotests Fehler übersehen. Wir haben verfolgt, wie viele Fehler manuell und nicht von Autotests abgefangen wurden. Nach 5 Releases haben wir die Daten überprüft und festgestellt, dass wir unseren Autotests vertrauen können. Es wurden keine größeren Fehler übersehen.
- Entfernen Sie manuelle Regressionen. Als wir genug Tests hatten, denen wir vertrauten, gaben wir die manuellen Tests vollständig auf. Je mehr wir unsere Tests durchführen, desto mehr vertrauen wir ihnen. Dies geschah jedoch nur 1,5 Jahre, nachdem wir begonnen hatten, die Regressionstests zu automatisieren.
5. Der Leistungstest ist Teil des Regressionstests . Während der Krise haben wir eine Reihe von Leistungstests erstellt. Es war ein völlig neues Gebiet für uns. Trotzdem konnten wir in nur zwei Wochen einige Leistungstests mit Visual Studio-Tools erstellen. Diese Tests haben uns nicht nur dabei geholfen, Leistungseinbußen festzustellen. Wir haben sie verwendet, um dem Produktionsserver eine synthetische Last hinzuzufügen, um die Leistungsgrenzen zu ermitteln. Wenn beispielsweise die organische Produktionslast 100 Bestellungen / min beträgt und wir mithilfe unserer Leistungstests 50 weitere Bestellungen / min hinzufügen, können wir feststellen, ob die Produktionsserver die erhöhte Last bewältigen können. Sobald wir Ausnahmen oder eine erhöhte Latenz bemerken, beenden wir den Test. Bei diesen Experimenten haben wir herausgefunden, wie viel Last unsere Produktionsserver maximal bewältigen können und wie der Hotspot aussehen wird.
Nächstes Jahr haben wir die Leistungstests an ein erfahrenes PerformanceLab-Team übertragen. Sie saßen mit unseren Entwicklern und Infrastrukturmitarbeitern zusammen und halfen uns, eine Reihe robuster Leistungstests zu erstellen. Jetzt führen wir diese Tests wöchentlich durch und geben den Entwicklungsteams schnelles Feedback, wenn die Leistung beeinträchtigt wird.
Einige der Konstruktionspraktiken wurden iterativ verfeinert. Zum Beispiel häufige Veröffentlichungen. Wir begannen mit wöchentlichen Release-Zyklen, die durch langsame und fragile manuelle Tests unterstützt wurden. Wir haben Funktionen für eine Woche entwickelt und für eine weitere Woche getestet. Es war jedoch schwierig, Änderungen, die von mehreren während einer Woche vorgenommen wurden, beizubehalten. Dann haben wir einzelne Team-Releases ausprobiert, bei denen nur Änderungen veröffentlicht wurden, die von einem einzelnen Team vorgenommen wurden. Dieser Prozess schlug jedoch fehl, da jedes Team mehrere Wochen in der Warteschlange warten musste. Dann lernten die Teams die Vorteile einer häufigen Integration und wir begannen, gemeinsame Releases mehrerer Teamänderungen zu üben. Die Entwickler begannen, mit Feature Toggle zu experimentieren und unfertige Features für die Produktion bereitzustellen. Schließlich kamen wir zu Continuous Integration und mehreren Releases pro Tag für Monolith und Continuous Deployment für Microservices.
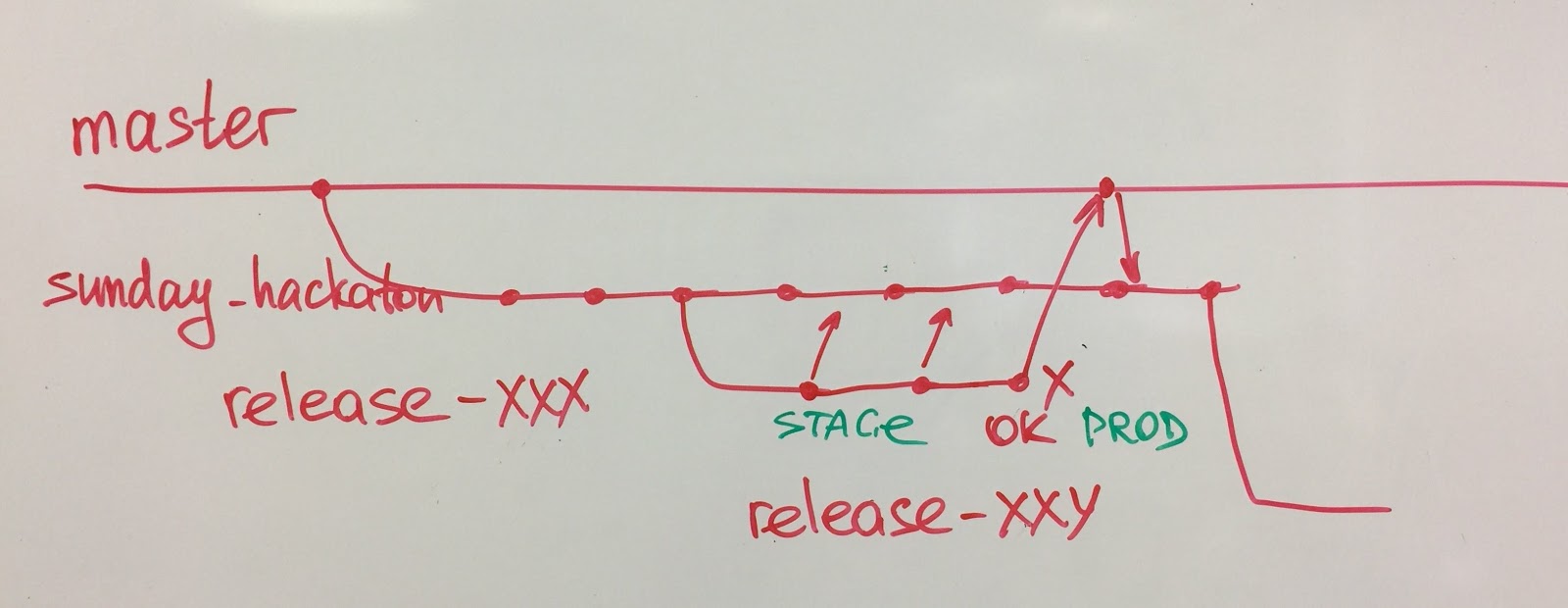
Ein weiterer interessanter Fall ist unsere QS-Abteilung. Früher hatten wir kein QS-Team, stattdessen hatten wir manuelle Tester. Als wir die Notwendigkeit einer Testautomatisierung erkannten, bildeten wir ein QS-Team, aber vom ersten Tag an wusste dieses Team, dass es eines Tages aufgelöst werden würde. Nach 6 Monaten automatisierte das Team unsere wichtigsten Geschäftsszenarien und schrieb mit Hilfe von Entwicklern eine praktische domänenspezifische Sprache (DSL) zum Schreiben von Tests. Das Team löste sich auf und Qualitätsingenieure schlossen sich den Feature-Teams an. Jetzt entwickeln und pflegen die Teams selbst Autotests.
Heute haben wir einen einzigen Rückstand, an dem 9 Feature-Teams arbeiten. Feature-Teams sind stabile, funktionsübergreifende und komponentenübergreifende Teams. Die meisten unserer Teams sind Feature-Teams.
6. Konzentrieren Sie sich auf technische Praktiken . Alle unsere Teams verwenden Paarprogrammierung. Ich betrachte die Paarprogrammierung als eine der einfachsten, aber leistungsfähigsten Methoden, mit deren Hilfe andere technische Methoden implementiert werden können. Wenn Sie nicht wissen, welche technische Praxis Sie starten sollen, empfehle ich die Paarprogrammierung.
Ergebnisse
Das Hauptergebnis, das uns die Krise gebracht hat, ist eine Erschütterung. Wir wachten auf und begannen zu handeln. Die Krise hat uns geholfen, das Maximum unserer Chancen zu erkennen. Wir haben gesehen, dass wir um ein Vielfaches effizienter arbeiten und unsere Ziele schnell erreichen können. Dies erfordert jedoch eine Änderung der normalen Arbeitsweise. Wir haben aufgehört, Angst vor mutigen Experimenten zu haben. Als Ergebnis dieser Experimente haben wir im vergangenen Jahr die Qualität und Stabilität von Dodo IS erheblich verbessert. Wenn unsere Pizzerien während der Frühlingsferien 2018 aufgrund von Dodo IS nicht funktionieren konnten, dann funktionierte Dodo IS 2019 mit einem Wachstum von 300 auf 450 Pizzerien einwandfrei. Während der zweiten Marketingkampagne und der Frühlingsferien erlebten wir leise den Höhepunkt der Verkäufe im neuen Jahr. Zum ersten Mal seit langer Zeit sind wir von der Qualität des Systems überzeugt und schlafen nachts gut. Dies ist das Ergebnis des ständigen Einsatzes technischer Praktiken und des Fokus auf technische Exzellenz.
Ergebnisse für das Geschäft
Engineering-Praktiken sind für sich genommen nicht erforderlich, wenn sie Ihrem Unternehmen nicht zugute kommen. Durch den Fokus auf technische Exzellenz verbessern wir die Codequalität und entwickeln Geschäftsfunktionen mit vorhersehbarer Geschwindigkeit. Veröffentlichungen sind für uns zu einem regelmäßigen Ereignis geworden. Wir veröffentlichen den Monolithen alle 2 Tage und kleinere Dienste alle paar Minuten. Dies bedeutet, dass wir unseren Benutzern schnell Geschäftswert liefern und schneller Feedback sammeln können. Dank der Flexibilität der Feature-Teams erreichen wir eine hohe Entwicklungsgeschwindigkeit.
Heute sind 480 Pizzerien online, 400 davon in Russland. In den Maiferien dieses Jahres gab es wieder Probleme mit der Auftragsabwicklung in unseren Pizzerien. Diesmal war der Engpass jedoch der Kundenservice in Pizzerien. Dodo IS lief trotz der wachsenden Anzahl von Pizzerien und Bestellungen wie am Schnürchen.
Ergebnisse für die Teams
Heute wenden wir eine breite Palette von Konstruktionspraktiken an:
- Voll funktions- und komponentenübergreifende Feature-Teams.
- Paarprogrammierung / Mob-Programmierung.
- Echte kontinuierliche Integration, dh mehrere Code-Integrationen von 9 Teams in einem Zweig.
- Vereinfachtes Konfigurationsmanagement mit Trunk-basierter Entwicklung.
- Gemeinsames Ziel für mehrere Teams.
- Fachexperte ist im Team.
- Kein separates QA-Team, QA-Experten sind Teil der Entwicklungsteams.
- Eventueller manueller Regressionswechsel durch Autotests.
- Null-Fehler-Richtlinie.
- Technischer Schuldenbestand.
- Stoppen Sie die Leitung als Treiber für die Beschleunigung der Bereitstellungspipeline.
Sie helfen 9 Teams bei der Arbeit an einem gemeinsamen Code und einem einzigen Produkt, das Dutzende von Komponenten enthält - eine mobile und Desktop-Site, eine mobile App für iOS und Android sowie ein riesiges Backoffice mit Registrierkasse, Tracking, Restaurantanzeige und persönlichem Konto , Analyse und Prognose.
Was kann besser sein
Es mag den Anschein haben, dass wir in der Ingenieurspraxis bereits gute Fortschritte erzielt haben, aber wir stehen erst am Anfang und haben noch Raum für Wachstum. Zum Beispiel versuchen wir, aber bisher unsystematisch, Mob-Programmierung. Wir untersuchen den BDD-Testschreibansatz. Wir haben immer noch Raum, um in CI zu wachsen. Wir verstehen, dass die Integration auch nur einmal am Tag nicht oft genug ist. Und wenn wir auf 30 Teams angewachsen sind, müssen wir uns häufiger integrieren. Der Übergang von TDD zu ATDD ist noch nicht abgeschlossen. Wir müssen einen nachhaltigen und skalierbaren architektonischen Entscheidungsprozess schaffen.
Das Wichtigste ist, dass wir uns auf den Weg zur Stärkung der technischen Exzellenz gemacht haben.
Aufgrund der Tatsache, dass alle 9 Teams an einem gemeinsamen Rückstand und an einem Produkt arbeiten, haben die Teams einen starken Wunsch, miteinander zu kooperieren. Sie haben gelernt, selbst starke Entscheidungen zu treffen.
Beispielsweise wurden die folgenden Praktiken von den Teams selbst vorgeschlagen und implementiert.- Stoppen Sie die Leitung als Treiber für die Beschleunigung der Bereitstellungspipeline (siehe meinen Erfahrungsbericht „Stoppen Sie die Leitung, um Ihre Bereitstellungspipeline zu optimieren“).
- Ersetzen Sie UI-Tests durch API-Tests.
- Automatische Bereitstellung mit einem Klick.
- Host für Kubernetes.
- Das Entwicklungsteam wird in der Produktion eingesetzt.
Einige Teams zeigten den Wunsch, alle 12 XP-Übungen anzuwenden, und baten mich als XP-Coach und Scrum-Master um Hilfe.
Was wir gelernt haben
Ich wünschte, ich würde die Krise nicht zulassen. Als Entwickler fühlte ich mich persönlich dafür verantwortlich, zu große technische Schulden zu akkumulieren und nicht früher eine rote Fahne zu hissen:
- Ingenieurspraktiken schützen Unternehmen vor Krisen.
- Sammeln Sie keine technischen Schulden. Es kann zu spät sein und zu hohe Kosten verursachen.
- Evolutionäre Veränderungen dauern um ein Vielfaches länger als revolutionäre.
- Krise ist nicht immer eine schlechte Sache. Nutzen Sie die Krise, um Prozesse zu revolutionieren.
- Eine lange evolutionäre Vorbereitung ist jedoch im Voraus erforderlich.
- Implementieren Sie nicht blind alle Praktiken, die Sie mögen. Einige Übungen warten in den Startlöchern, und wenn er kommt, werden die Teams sie ohne Widerstand einsetzen. Warten Sie auf den richtigen Moment.
- Verfeinern und passen Sie die Praktiken an Ihren Kontext an.
- Im Laufe der Zeit beginnen die Teams selbst, starke Entscheidungen zu treffen und diese umzusetzen. Geben Sie ihnen eine sichere Umgebung, um Fehler zu versuchen, zu scheitern und zu lernen.
Technische Schulden führen uns in die Krise. Aber aus der Krise haben sowohl Entwickler als auch Geschäftsleute gelernt, wie wichtig der Fokus auf technische Exzellenz und technische Praktiken ist. Wir haben die Krise als Auslöser für massive Organisations- und Prozessänderungen genutzt.
Danksagung
Ich möchte mich ganz herzlich bei allen Menschen bedanken, die mir auf meinem Weg von der Krise zur LeSS-Transformation geholfen haben. Ich fühle ständig Ihre Unterstützung.
Vielen Dank an unseren CEO Fedor Ovchinnikov für das Vertrauen. Sie sind der wahre Leiter des Unternehmens mit einer echten agilen Kultur.
Vielen Dank an Dmitry Pavlov, unseren Product Owner, meinen alten Freund und Co-Trainer.
Vielen Dank an Alex Andronov und Andrey Morevsky, die mich in meiner Rolle unterstützt haben.
Vielen Dank an Dasha Bayanova, unsere erste hauptberufliche Scrum-Meisterin, die mir geglaubt hat und mir bei all unserer Initiative immer hilft und mich unterstützt. Ihre Hilfe ist schwer zu überschätzen.
Ein besonderes großes Dankeschön an Johanna Rothman, die mir beim Schreiben dieses Berichts unter allen Bedingungen geholfen hat: im Urlaub sein, sich nach einer Krankheit erholen. Johanna, es war mir eine große Freude, mit Ihnen zusammenzuarbeiten. Ihre Hilfe, Ihr Rat, Ihre Liebe zum Detail und Ihre Sorgfalt werden sehr geschätzt.