Einführung in Betriebssysteme
Hallo Habr! Ich möchte Sie auf eine Reihe von Artikelübersetzungen einer meiner Meinung nach interessanten Literatur aufmerksam machen - OSTEP. Dieser Artikel beschreibt ziemlich ausführlich die Arbeit von Unix-ähnlichen Betriebssystemen, nämlich die Arbeit mit Prozessen, verschiedenen Schedulern, Speicher und anderen ähnlichen Komponenten, aus denen das moderne Betriebssystem besteht. Das Original aller Materialien können Sie
hier sehen . Bitte beachten Sie, dass die Übersetzung unprofessionell (ziemlich frei) durchgeführt wurde, aber ich hoffe, dass ich die allgemeine Bedeutung beibehalten habe.
Laborarbeiten zu diesem Thema finden Sie hier:
Andere Teile:
Und du kannst meinen Kanal im
Telegramm ansehen =)
Alarm! Für diese Vorlesung gibt es ein Labor! schau
dir github anProzess-API
Betrachten Sie ein Beispiel für das Erstellen eines Prozesses auf einem UNIX-System. Dies geschieht durch zwei Systemaufrufe
fork () und
exec () .
Fork () -Aufruf

Stellen Sie sich ein Programm vor, das einen fork () -Aufruf ausführt. Das Ergebnis seiner Implementierung wird wie folgt sein.
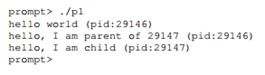
Zunächst geben wir die Funktion main () ein und führen die Ausgabe der Zeichenfolge auf dem Bildschirm aus. Die Zeichenfolge enthält die Prozesskennung, die im Original als
PID oder Prozesskennung bezeichnet wird. Diese Kennung wird unter UNIX verwendet, um auf einen Prozess zu verweisen. Der nächste Befehl ruft fork () auf. Zu diesem Zeitpunkt wird eine fast exakte Kopie des Prozesses erstellt. Für das Betriebssystem sieht es so aus, als würde das System so ausgeführt, als ob zwei Kopien desselben Programms die Funktion fork () beenden würden. Der neu erstellte untergeordnete Prozess (relativ zu dem übergeordneten Prozess, der ihn erstellt hat) wird nicht mehr ausgeführt, beginnend mit der Funktion main (). Es ist zu beachten, dass der untergeordnete Prozess keine exakte Kopie des übergeordneten Prozesses ist, insbesondere hat er einen eigenen Adressraum, eigene Register, einen eigenen Zeiger auf ausführbare Anweisungen und dergleichen. Daher ist der an den Aufrufer der Funktion fork () zurückgegebene Wert unterschiedlich. Insbesondere erhält der übergeordnete Prozess den PID-Wert des Prozesses des Kindes als Rückgabe, und das Kind erhält einen Wert gleich 0. Basierend auf diesen Rückgabecodes ist es bereits möglich, die Prozesse zu trennen und jeden von ihnen zu zwingen, seine Arbeit zu erledigen. Darüber hinaus ist die Ausführung dieses Programms nicht genau definiert. Nach der Aufteilung in zwei Prozesse beginnt das Betriebssystem, diesen ebenfalls zu folgen und ihre Arbeit zu planen. Bei der Ausführung auf einem Single-Core-Prozessor funktioniert einer der Prozesse weiter, in diesem Fall der übergeordnete und dann der untergeordnete Prozess. Beim Neustart kann die Situation anders sein.
Rufen Sie wait () an
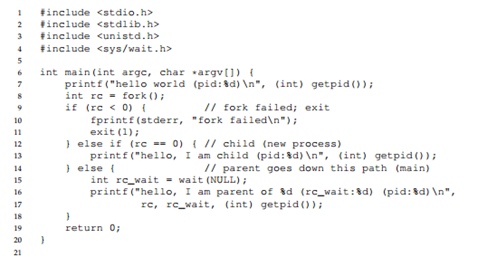
Betrachten Sie das folgende Programm. In diesem Programm
wartet der übergeordnete Prozess aufgrund des Vorhandenseins des Aufrufs
wait () immer darauf, dass der untergeordnete Prozess seine Arbeit beendet. In diesem Fall erhalten wir eine streng definierte Textausgabe auf dem Bildschirm.

Rufen Sie exec () auf

Betrachten Sie den Aufruf von
exec () . Dieser Systemaufruf ist nützlich, wenn wir ein völlig anderes Programm ausführen möchten. Hier rufen wir
execvp () auf, um das Programm wc auszuführen, bei dem es sich um ein
Wortzählprogramm handelt. Was passiert, wenn exec () aufgerufen wird? Der Name der ausführbaren Datei und einige Parameter werden als Argumente an diesen Aufruf übergeben. Danach werden der Code und die statischen Daten aus dieser ausführbaren Datei heruntergeladen und ein eigenes Segment mit Code überschrieben. Die verbleibenden Speicherbereiche wie Stapel und Heap werden neu initialisiert. Danach führt das Betriebssystem das Programm einfach aus und übergibt ihm eine Reihe von Argumenten. Wir haben also keinen neuen Prozess erstellt, sondern einfach das aktuell laufende Programm in ein anderes laufendes Programm umgewandelt. Nach der Ausführung von exec () erweckt der Nachkomme den Eindruck, dass das ursprüngliche Programm im Prinzip nicht gestartet zu sein schien.
Diese Komplikation beim Starten ist für die Unix-Shell absolut normal und ermöglicht es dieser Shell, Code nach dem Aufruf von
fork () , jedoch vor dem Aufruf von
exec () auszuführen. Ein Beispiel für einen solchen Code kann darin bestehen, die Umgebung der Shell an die Anforderungen des zu startenden Programms anzupassen, bevor es direkt gestartet wird.
Shell ist nur ein Anwenderprogramm. Sie zeigt Ihnen die Eingabeaufforderung und wartet darauf, dass Sie etwas darauf schreiben. Wenn Sie dort den Namen des Programms schreiben, findet die Shell in den meisten Fällen ihren Speicherort, ruft die fork () -Methode auf. Um einen neuen Prozess zu erstellen, ruft sie einige der exec () -Typen auf und wartet, bis sie mit dem wait () -Aufruf ausgeführt wird. Wenn der untergeordnete Prozess beendet ist, kehrt die Shell vom Aufruf wait () zurück, zeigt die Eingabeaufforderung erneut an und wartet auf die Eingabe des nächsten Befehls.
Durch die Trennung von fork () und exec () kann die Shell beispielsweise Folgendes ausführen:
wc file> new_file.In diesem Beispiel wird die Ausgabe von wc in eine Datei umgeleitet. Die Art und Weise, wie die Shell dies erreicht, ist recht einfach: Wenn Sie einen
untergeordneten Prozess erstellen, bevor Sie
exec () aufrufen, schließt die Shell den Standardausgabestream und öffnet die Datei
new_file , sodass die gesamte Ausgabe des gestarteten
wc- Programms in die Datei anstatt auf den Bildschirm umgeleitet wird.
Unix-Pipes werden auf ähnliche Weise implementiert, mit dem Unterschied, dass sie den Befehl pipe () verwenden. In diesem Fall wird der Ausgabestream des Prozesses mit der Pipe-Warteschlange im Kernel verbunden, an die der Eingabestream eines anderen Prozesses angehängt wird.