Maschinelles Lernen wird während des gesamten Bestellzyklus von Yandex.Taxi eingesetzt, und die Anzahl der dank ML arbeitenden Servicekomponenten wächst stetig. Um sie einheitlich zu bauen, brauchten wir einen separaten Prozess. Roman Khalkachev, Leiter des Dienstes für maschinelles Lernen und Datenanalyse, sprach über die Datenvorverarbeitung, die Verwendung von Modellen in der Produktion, den Prototyping-Service und verwandte Tools.
- Meiner Meinung nach sind einige neue Dinge viel leichter wahrzunehmen, wenn sie anhand eines einfachen Beispiels erzählt werden. Damit der Bericht nicht trocken war, habe ich mich entschlossen, über eine der Aufgaben zu sprechen, die wir lösen. An ihrem Beispiel werde ich zeigen, warum wir so handeln.
Formulieren wir das Problem. Es gibt Taxifahrer, die von Punkt A nach Punkt B gelangen müssen, und es gibt Fahrer, die für einen bestimmten Betrag bereit sind, um diese Benutzer von Punkt A nach Punkt B zu befördern. Der Benutzer hat mehrere Bedingungen, unter denen er sich befindet. Er ruft ein Taxi, wählt Punkt A, Punkt B, Fahrpreis usw. aus, landet mit dem Taxi, fährt und landet schließlich. Heute möchte ich über das Einsteigen in ein Auto und mögliche Probleme sprechen.

Diese Probleme hängen in der Regel damit zusammen, dass eine Person einen Ort auswählen muss, an dem ein Taxi kommen soll. Und hier gibt es eine Reihe von Schwierigkeiten. Diese Schwierigkeiten hängen mit vier Dingen zusammen, die ich auf der Folie aufgelistet habe.
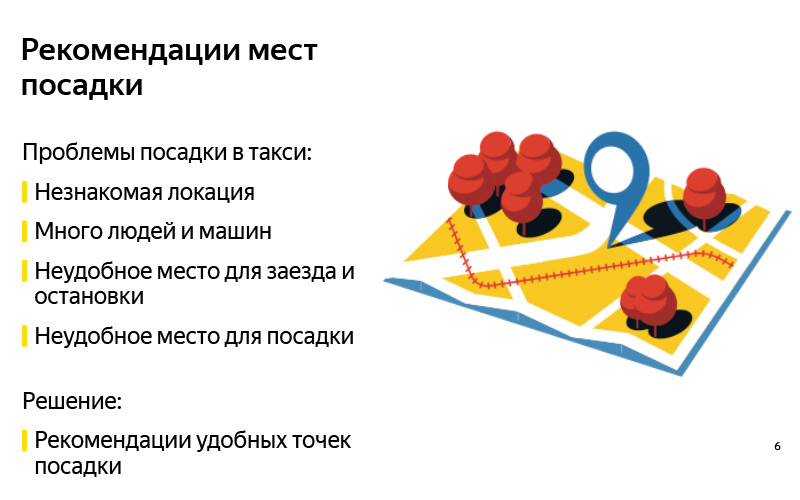
Erstens ist der Standort dem Benutzer möglicherweise nicht bekannt. Als Beispiel können Sie sich vorstellen, wer zu einem großen Einkaufszentrum gekommen ist, das Sie nicht oft besuchen. Sie möchten abreisen und wissen nicht wirklich, wo Sie hier ein Taxi rufen können, wo das Auto anrufen kann, aber wo es zum Beispiel aufgrund der Barriere nicht kann. Es gibt Probleme mit der Tatsache, dass an einigen Orten viele Menschen, viele Autos sind und es für Sie schwierig ist, Ihr Auto zu finden. Es gibt Orte, an denen normalerweise Leute ins Auto steigen. Es ist einfacher, dorthin zu gelangen. Und Sie wissen vielleicht nicht, wo Sie genau landen müssen, wenn Sie sich an einem neuen Ort befinden, nicht unbedingt im Einkaufszentrum. Schwierigkeiten können damit verbunden sein, dass der Fahrer nicht zu dem Ort fahren kann, an dem Sie das Taxi gerufen haben: Es ist ihm verboten zu reisen, es gibt einen großen Ausgang vom Einkaufszentrum, gegenüber dem Sie nicht anhalten können usw.
Andererseits können Sie als Benutzer Probleme haben. Der Fahrer ist angekommen, alles ist in Ordnung, aber es ist unangenehm, sich zu setzen, weil alle ausgegraben haben. Sie bitten den Fahrer, woanders zu fahren. Es gibt andere Gründe.
Das anschaulichste Beispiel, die Quintessenz all dieser Dinge, ist der Flughafen, auf dem fast alles getan wird. Selbst wenn Sie sehr oft von Sheremetyevo aus fliegen, ist es für Sie immer noch ein unbekannter Ort, da sich dort oft viele Dinge ändern. Es gibt viele Menschen, viele Autos, es gibt bequeme Landeplätze, es gibt unbequeme, aber in der Regel erinnert sich keiner von uns daran.
Die Lösung wird aus dem Titel der Folie gelesen. Lassen Sie uns dem Benutzer einige Orte empfehlen, an denen es unserer Meinung nach bequem ist, zu landen. Der Gedanke scheint offensichtlich, aber hier gibt es viele Nuancen.
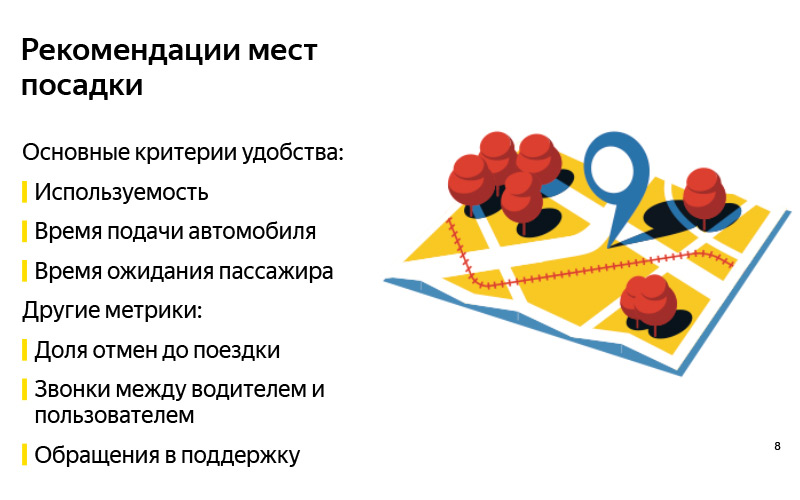
Für den Anfang ist „bequem“ ein subjektives Konzept. Es scheint, dass vor der Lösung des Problems einige Kriterien für die Tatsache formuliert werden müssen, dass das Problem korrekt gelöst wird. Wir haben drei Hauptformulare für uns formuliert. Das erste Kriterium ist wie bei jeder Aufgabe von Empfehlungen: Wahrscheinlich sind Empfehlungen gut, wenn sie verwendet werden. Wenn wir solche Punkte zeigen, von denen der Benutzer wirklich abreist, sind dies wahrscheinlich gute Punkte. Aber das ist natürlich nicht alles, denn Sie können lernen, etwas zu empfehlen, es zu zeigen, den Benutzer zu ermutigen, es zu verwenden, aber Sie können keinen greifbaren Gewinn erzielen (wir werden weder als System noch als Benutzer noch als Fahrer arbeiten). Daher ist es sehr wichtig, andere Metriken zu betrachten. Wir haben zwei ausgewählt.
Wenn wir Ihnen von einem Landeplatz erzählen, zu dem der Fahrer problemlos fahren kann, sollte die Lieferzeit des Fahrzeugs verkürzt werden. Wenn es für den Benutzer hingegen einfacher ist, ein Auto an diesem Ort zu finden, ist es einfacher zu landen, sollte die Wartezeit des Fahrers für den Fahrer verkürzt werden. Dies ist ein Teil unserer Hypothese, die wir für selbstverständlich halten, und dies sind einige Metriken, die wir betrachten, wenn wir diese Empfehlungen aussprechen. Aber dies sind natürlich nicht die einzigen Metriken, die betrachtet werden müssen. Sie können sich ein Dutzend mehr einfallen lassen. Ich denke, jeder von Ihnen kann sich hundert dieser Metriken einfallen lassen.
Hier sind einige weitere Beispiele. Dies kann der Anteil der Stornierungen vor der Reise sein. Theoretisch sollte es abnehmen, wenn der Benutzer leichter landen kann. Herkömmlicherweise sind dies Anrufe, wenn ein Benutzer den Fahrer anruft, um ihn zu finden, oder umgekehrt, wenn der Fahrer den Benutzer anruft, bevor die Reise beginnt. Dieser Aufruf unterstützt und ein Dutzend andere.
Wir haben das Problem formuliert. Wir haben das Kriterium, dass wir dieses Problem lösen können, grob verstanden. Lassen Sie uns nun darüber nachdenken, wie Sie dieses Problem lösen können. Das erste, was mir in den Sinn kommt: Empfehlen wir solche bewährten und verständlichen Landepunkte. Hier auf der Folie ist ein Beispiel für das Europäische Einkaufszentrum. Und wir wissen mit Sicherheit, dass Sie von diesem Einkaufszentrum bis zu den Ausgängen fahren können, und dies ist eine Art Richtlinie, dank derer der Benutzer einen Fahrer finden kann. Es kann jede Organisation sein. In einigen Einkaufszentren gibt es ein Beispiel mit dem ABC of Taste. Meiner Meinung nach ist dies Yerevan Plaza. Dies ist auch eine Art Richtlinie für Benutzer und Fahrer, über die wir wissen, dass Sie dort fahren können.
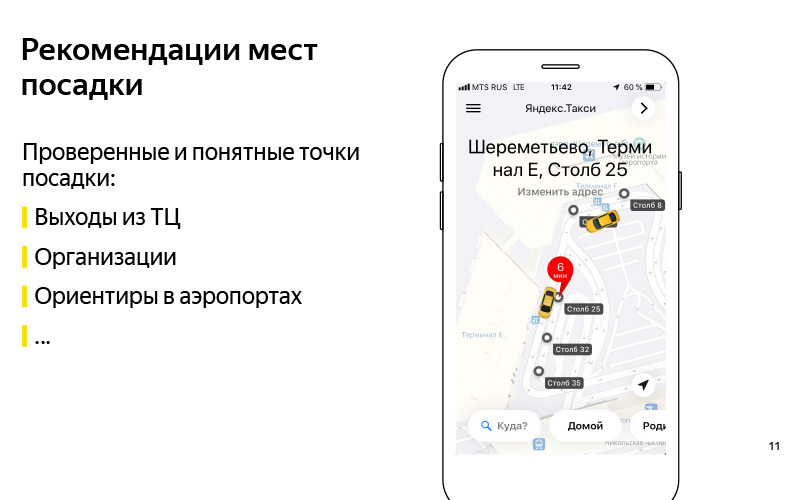
Dies können Wahrzeichen an den Flughäfen sein, von denen ich gesprochen habe. Herkömmlicherweise gibt es in Sheremetyevo solche Pole mit Zahlen. Es ist bequem, ein Taxi zu rufen und ins Auto zu steigen. Eine gute Lösung, aber es hat ein Minus, dass es nicht sehr skalierbar ist. Wir haben viele Länder, Hunderte von Städten, eine große Anzahl verschiedener Einkaufszentren, Flughäfen, schwierige Verkehrsknotenpunkte, unbekannte Orte, für die es schwierig ist, diese Punkte manuell zu ermitteln, und es ist noch schwieriger, sie auf dem neuesten Stand zu halten. Hier hilft uns das, was lautstark "künstliche Intelligenz" genannt wird. Ich nenne es lieber Data Mining oder maschinelles Lernen.
Maschinelles Lernen benötigt irgendeine Art von Daten, und wir haben diese Daten tatsächlich. Eine andere Möglichkeit, das Problem automatisch zu lösen, besteht darin, diese Daten zu verwenden. Die übergeordnete Idee ist, dass wir Daten über GPS, Anwendungsprotokolle und ein Straßendiagramm haben. Und wir können verstehen, wo Benutzer tatsächlich ins Auto steigen. Nicht die Punkte, an denen sie das Auto anrufen, sondern an denen sie landen. Und basierend darauf machen Sie so etwas.

Diese Punkte werden bereits automatisch für das Aurora Business Center erhalten, in dem derzeit unser Yandex.Taxi-Team sitzt.
Ich habe auf hohem Niveau über unsere Aufgabe gesprochen. Lassen Sie uns nun genauer darüber sprechen, aus welchen Phasen die Lösung dieses Problems besteht. Es ist klar, dass es eine Phase der Datenaufbereitung gibt.

Welche Daten haben wir? Erstens haben wir die GPS-Daten unserer Benutzer und die GPS-Daten unserer Fahrer. Wenn sie unsere Anwendung verwenden, kennen wir den ungefähren Standort der Benutzer. Es ist klar, dass GPS einen großen Fehler im Bereich von 13 bis 15 Metern aufweist, aber dennoch gibt es etwas. Zweitens haben wir Informationen, die in den Anwendungsprotokollen enthalten sind, wann der Treiber vom Status "Ich warte auf den Benutzer" zum Status "Ich nehme den Benutzer" gewechselt hat. Es ist davon auszugehen, dass der Fahrer ungefähr zu diesem Zeitpunkt auf den Benutzer gewartet hat, der Benutzer ins Auto gestiegen ist und losgefahren ist. Um diesen Ort herum wurde gelandet. Und wir haben eine Straßengrafik. Ein Straßendiagramm besteht nicht nur aus einer Reihe von Kanten, Straßen, sondern auch aus zusätzlichen Metainformationen: Barrieren, Informationen zum Parken usw. Basierend auf diesen Daten können Sie bereits eine Art automatische Punkte erhalten.
Dies waren die Quelldaten. Und am Ausgang wollen wir zwei Dinge. Dies sind einige sogenannte Landepunktkandidaten. Wie kommen sie zustande? Schade, dass das Video nicht gezeigt werden konnte. Folgendes passiert ungefähr. Wir haben viele GPS-Punkte, an denen wir wissen, dass der Fahrer vom Status „Warten auf einen Passagier“ zum Status „Los geht's“ gewechselt ist. Wir können sie bedingt in die Grafik zeichnen, dh auf die Straßengrafik projizieren, da sich das Auto in der Regel von einer Straße aus bewegt. Führen Sie in diesem Diagramm eine Art Clustering dieser Punkte durch. Und um eine große Anzahl von Kandidaten zu bekommen - dies sind Orte, an denen einige Benutzer ins Auto gestiegen sind, und es war normal und praktisch für sie. Nicht wo sie anriefen, sondern wo sie saßen.
Danach, wenn wir viele Kandidaten haben und einige Benutzer online sind, kennen wir seinen Standort. Er hat die Bewerbung geöffnet und möchte ein Taxi rufen. Dann können wir aus einer großen Anzahl von Kandidaten die besten fünf auswählen und ihnen zeigen. Die besten fünf werden durch ein Modell des maschinellen Lernens ermittelt, das lernt, alle Kandidaten nach der Wahrscheinlichkeit zu ordnen, dass der Benutzer zu diesem Zeitpunkt unter Berücksichtigung seines Standorts und seiner Reisegeschichte am bequemsten abreisen kann. Und ungefähr auf diese Weise können wir diese Punkte automatisch generieren. Wenn sie irgendwann irgendwo bedingt ausgraben, das heißt, es wird unangenehm, ein Taxi zu rufen, oder wenn sie irgendwo ein Schild anbringen, das das Anhalten verbietet, und Fahrer und Benutzer wirklich aufhören, an diesem Ort zu landen, dann an einigen Sobald der Algorithmus dies versteht und die Daten aktualisiert werden.
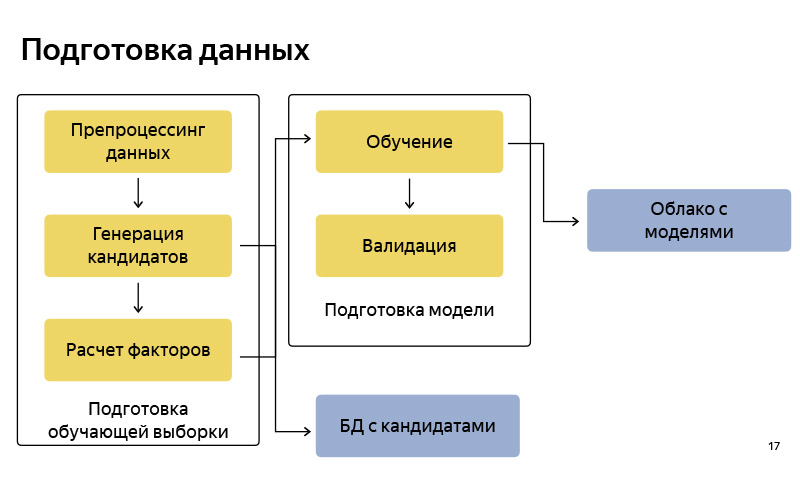
Dies ist ungefähr das Blockdiagramm, wie wir die Daten aufbereiten. Dementsprechend ist es ziemlich Standard, wie in jeder Pipeline für maschinelles Lernen. Es gibt Datenaufbereitung, es gibt eine Generation von Kandidaten nach dem Algorithmus, sagte ich einer vereinfachten Version. Wir speichern diese Kandidaten in einer bestimmten Datenbank. Danach bereiten wir einen Pool für das Training vor (Trainingsbeispiel), in dem sich unter bestimmten Bedingungen ein Benutzer, eine Zeit, Metainformationen und eine Reihe von Kandidaten befinden und bekannt ist, von welchem Punkt der Benutzer schließlich abgereist ist. Darauf trainieren wir das Klassifikationsmodell. Und dann ordnen wir nach den Vorhersagen der Wahrscheinlichkeit die Kandidaten. Wenn das Modell fertig ist, laden wir es in eine Cloud hoch, in der es gut gespeichert ist.
Welche Tools verwenden wir zur Aufbereitung der Daten? Grundsätzlich alle Datenvorbereitungen, die wir in Python auf dem Python-Stack geschrieben haben: Dies sind Standard-NumPy, Pandas, Scikit-Learn usw. Wir haben viele Daten. Wir haben Millionen von Reisen pro Monat. Viele Daten über GPS, über Fahrerspuren, Anwendungsprotokolle, daher müssen wir sie alle im Cluster gleich verarbeiten. Zu diesem Zweck verwenden wir MapReduce unserer Intra-Yandex-Version, die als YT bezeichnet wird, und es gibt eine in Python geschriebene Bibliothek, mit der einige Mapper und Reduzierer gestartet und einige Berechnungen für einen großen Cluster durchgeführt werden können.
Wenn die Pipeline fertig ist, müssen wir sie automatisieren, damit die Daten auf dem neuesten Stand sind, und dafür verwenden wir so etwas wie Nirvana und Hitman. Dies ist auch eine Intra-Yandex-Entwicklung. Nirvana ist ein Cluster-Computing-Management-Framework. Tatsächlich weiß sie, wie man fast jedes Programm ausführt, fehlertolerant ist, DC-überkreuzt (00:14:53). Und für den Fall, dass etwas herunterfällt, weiß sie, wie sie es neu starten kann, um beim Auftreten von Ereignissen Starts zu erstellen. usw.

So sieht ungefähr die Weboberfläche unseres MapReduce-Clusters aus. Es ist hier zu sehen, dass wir viele Maschinen haben, solche Knoten, auf denen Berechnungen durchgeführt werden.
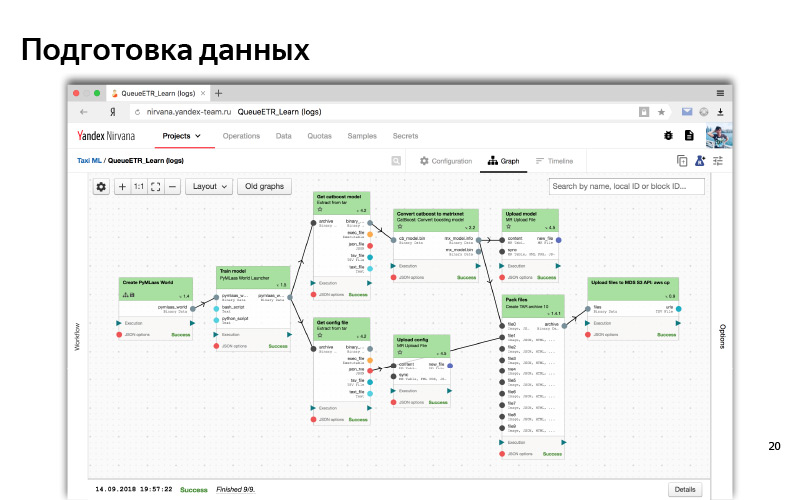
Und so sieht in der Weboberfläche ein typischer Prozess einer Art Datenvorverarbeitung und Modelltraining aus. Dies ist ein solcher Abhängigkeitsgraph. Abhängigkeiten sind wie Daten, wenn ein Teil (ein Würfel) auf Daten von einem anderen Würfel wartet. und logische Abhängigkeit (zuerst haben wir alle Daten vorbereitet und dann mit dem Training begonnen). Dies ist eine Art automatisiertes System. Für all dies verwenden wir normalerweise Python.
Wir haben das Problem formuliert, Erfolgskriterien formuliert, gelernt, es irgendwie offline zu lösen, sogar eine Art Modell erstellt, und es scheint nach einigen Offline-Metriken zu funktionieren - es sagt wirklich die Punkte voraus, von denen der Benutzer diese Punkte verlässt und findet Dies sollte anscheinend die Wartezeit und die Auslieferung des Autos verkürzen.

Versuchen wir diese Modelle, verwenden Sie diese Daten. Stellen Sie sich dazu den Yandex.Taxi-Service vor.
Ein sehr oberflächliches Diagramm sieht so aus. Es gibt Benutzer, sie haben eine Anwendung und es gibt Treiber, sie haben auch eine Anwendung namens "Taximeter". Diese Anwendungen kommunizieren irgendwie mit dem Backend, und das Backend ist eine Reihe von Microservices, die miteinander kommunizieren - Ilya hat
darüber gesprochen . Einer der Microservices ist unser Service, unser Team macht es, es heißt ML as a Service, MLaaS.

Alles, was Sie über ihn wissen müssen, ist in C ++ geschriebenes MLaaS, das auf dem sogenannten Fastcgi-Daemon basiert. Dies ist eine Open-Source-Bibliothek, die grob gesagt ein Framework zum Schreiben eines Webservers ist, der Anforderungen abrufen und veröffentlichen kann. Alles ist Standard. Es wurde einmal in Yandex geschrieben und in Open Source angelegt. Wir verwenden die dopped Version. Was kann dieser Service tun? Er weiß, wie man mit Modellen arbeitet: Wenden Sie sie an, behalten Sie sie zu Hause und aktualisieren Sie sie manchmal, gehen Sie in diese wunderbare Cloud, in der Modelle regelmäßig aktualisiert, gespeichert und heruntergeladen werden.
Jede Funktionalität, zum Beispiel diese Landepunkte - im Inneren nennen wir sie Abholpunkte - oder zum Beispiel die Tipps von Punkten B, über die Ilya im vorherigen Bericht gesprochen und ständig gebrochen hat, entspricht jeder dieser Funktionen, bei denen es eine Art maschinelles Lernen gibt Handler, der die Logik zum Empfangen einer Anforderung, zum Generieren von maschinellen Lernfaktoren, zum Anwenden von Modellen und zum Generieren einer Antwort speichert. Natürlich ist dieser Dienst nicht isoliert, da er auf einige zusätzliche Datenquellen, Datenbanken und einige andere Mikrodienste zugreifen kann.
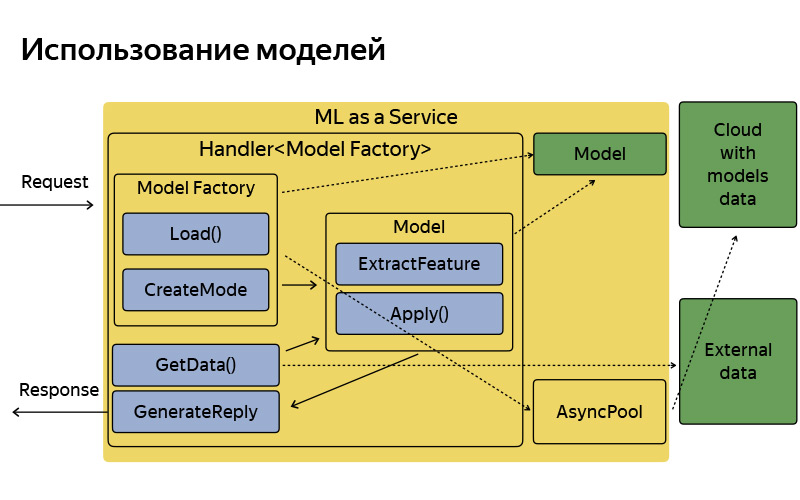
So ist es angeordnet, es hat eine ziemlich einfache Architektur. Ich wollte nicht im Detail auf diese Folie eingehen, ich wollte nur sagen, dass die Architektur konventionell sehr einfach ist. Die Anfrage kommt an, es gibt eine Fabrik von Modellen, die diese Modelle manchmal aus der Cloud herunterladen. Im Speicher werden sie in einer einzigen Kopie gespeichert. Für jede Anforderung wird ein relativ leichtes Modellobjekt erstellt, das Features extrahiert, anwendet und eine Antwort generiert.

Aber was haben wir für den aktuellen Moment? Ich habe Ihnen bereits gesagt, dass wir Datenvorbereitung, Schulung, verschiedene Studien, Experimente haben und all dies in Python Stack geschrieben ist. Es gibt einige Produktionen, die in C ++ geschrieben sind, einfach weil wir hohe Anforderungen an Effizienz und Produktivität stellen. Wenn Sie in einem solchen Ökosystem leben, treten zwei Probleme auf.
Dies ist vor allem ein Problem von Experimenten. Ein Datenwissenschaftler, der in unserem Team arbeitet, hatte beispielsweise eine Idee. Wenn Sie einen Clustering- oder Klassifizierungsalgorithmus mit leicht unterschiedlichen Parametern ausführen, können Sie eine bessere Qualität erzielen. Er hat versucht, seine Hypothese offline zu testen, sie in unseren Python-Prozess integriert, berechnet und es stellt sich wirklich heraus. Und jetzt möchte er, dass ein AB-Experiment, dh ein Teil der Benutzer, den neuen Algorithmus zeigt und einige bereits online gemessene Metriken misst: sinkt die Zeit wirklich, wartet, nimmt die Nutzung zu. Zu diesem Zweck verfügt er unter bestimmten Bedingungen über fünf Versionen seines Algorithmus, von denen er glaubt, dass sie offline eine gute Qualität bieten: Implementierung in C ++ und Durchführung eines AB-Experiments. Und nach diesem AB-Experiment werden vielleicht alle fünf verschwendet, das heißt, die Qualität der Online-Experimente wird schlechter als offline, dh schlechter als in der Produktion. Das heißt, der Experimentierprozess dauert lange, da bedingt zwei verschiedene Sprachen, zwei verschiedene Technologien.
Dies gilt für vorhandene Funktionen. Und es gibt neue. Einmal waren diese Abholpunkte auch Ideen, die ich schnell überprüfen wollte. Verbringen Sie keine zwei Monate Entwicklungszeit damit - es ist ratsam, in drei Wochen etwas zu besorgen. Einen solchen Prototyp zu erstellen ist ziemlich mühsam. Schreiben Sie zunächst in Python die Extraktion von Features, einfach weil es bequem ist - bewegen Sie sich schnell, wie sie sagen. Sie können jeden Prototyp in Python erstellen. Es gibt viele Bibliotheken für die Datenanalyse. Sie haben auf Ihrem Laptop experimentiert und möchten nun die Benutzer überprüfen. Und einen Prototyp zu bauen, stellte sich als ziemlich schwierig heraus. Wir sind zu dem Schluss gekommen, dass wir einen zusätzlichen Service benötigen, um solche Prototypen relativ schnell zusammenzusetzen - bedingt, in einer Woche oder sogar an einem Tag - und auch AB-Experimente durchzuführen.
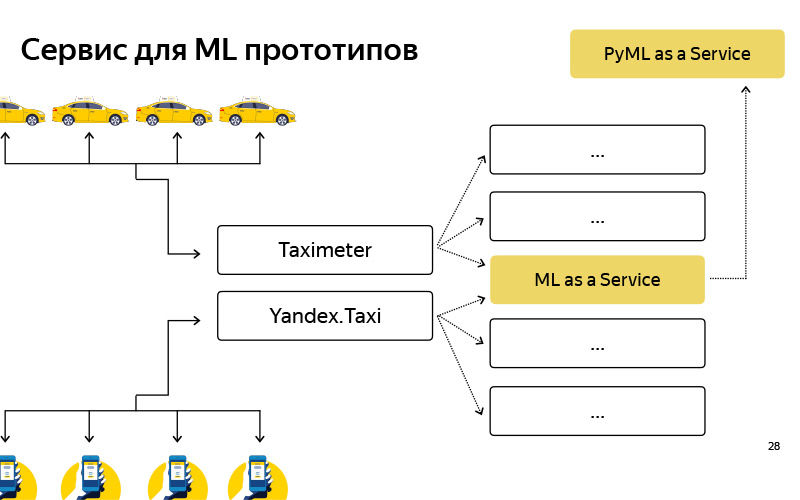
Wir haben einen solchen Dienst namens PyMLaaS erstellt. Wie ist er? Tatsächlich ist dies ein vollständiges Analogon von MLaaS, über das ich zuvor gesprochen habe, das jedoch in Python geschrieben wurde und auf Flask, Nginx und Gunicorn basiert. Die Architektur ist recht einfach, genau wie die von MLaaS, aber es besteht die Möglichkeit, schnell einen Prototyp aus Ihren Offline-Experimenten zu untersuchen. Darüber hinaus haben wir ein solches Proxying auf Nginx-Ebene arrangiert, sodass wir unter bestimmten Bedingungen die Möglichkeit hatten, einen Teil der Last von MLaaS an PyMLaaS weiterzuleiten und damit zu experimentieren.

Das heißt, wir haben einige Parameter verschoben und möchten überprüfen, wie sich dies auf Benutzer auswirkt. Wir haben 5% der PyMLaaS-Last gestartet und werden sehen, was im Experiment passiert. Schließlich ist es bequem, Prototypen zu erstellen. Ich habe einen Prototyp einer neuen Funktion erstellt, sie in PyMLaaS gesehen und Sie können sie sofort in der Produktion testen.
Es hat uns so gut gefallen, dass die Idee aufkam - warum nicht die ganze Zeit nutzen? Denn bedingt gibt es Funktionen, die eine große Last, 1000 RPS und einen großen Speicherbedarf erfordern. Ich möchte eine ziemlich flexible Parallelität haben. Für einige Funktionen, für einige Produkte oder Services, die keine so hohen Anforderungen an Last, Leistung, RPS usw. stellen, verwenden wir diesen Service jedoch recht erfolgreich.

Zusammenfassend. , . . . , - , , , -, - . - PyMLaaS, AB-, . , MLaaS, , .
pickup points — . . , . 30% , . .