Am 26. Februar veranstalteten wir das Apache Ignite GreenSource-Mitap, bei dem die Mitwirkenden des Open Source-Projekts
Apache Ignite auftraten. Ein wichtiges Ereignis im Leben dieser Community war die Umstrukturierung der
Ignite Service Grid- Komponente, mit der Sie benutzerdefinierte Microservices direkt im Ignite-Cluster bereitstellen können.
Vyacheslav Daradur , ein hochrangiger Yandex-Entwickler und Apache Ignite-Mitarbeiter seit mehr als zwei Jahren, sprach auf dem Treffen über diesen schwierigen Prozess.
Was ist Apache Ignite im Allgemeinen? Dies ist eine Datenbank, bei der es sich um ein verteiltes Schlüssel- / Wert-Repository handelt, das SQL, Transaktions- und Caching unterstützt. Darüber hinaus können Sie mit Ignite Benutzerdienste direkt im Ignite-Cluster bereitstellen. Dem Entwickler stehen alle von Ignite bereitgestellten Tools zur Verfügung - verteilte Datenstrukturen, Messaging, Streaming, Compute und Data Grid. Wenn Sie beispielsweise das Datenraster verwenden, verschwindet das Problem der Verwaltung einer separaten Infrastruktur für das Data Warehouse und damit der daraus resultierende Overhead.

Mithilfe der Service Grid-API können Sie einen Service bereitstellen, indem Sie einfach das Bereitstellungsschema in der Konfiguration und entsprechend den Service selbst angeben.
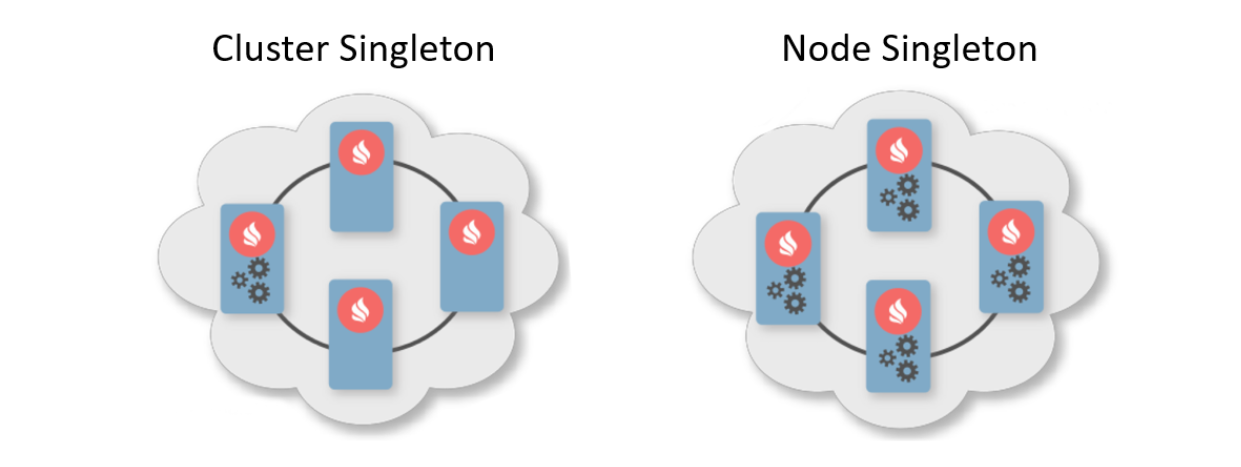
In der Regel gibt ein Bereitstellungsmuster an, wie viele Instanzen auf Clusterknoten bereitgestellt werden sollen. Es gibt zwei typische Bereitstellungsmuster. Das erste ist Cluster Singleton: Zu jedem Zeitpunkt im Cluster ist garantiert, dass eine Instanz des Benutzerdienstes verfügbar ist. Der zweite ist Node Singleton: Auf jedem Knoten des Clusters wird eine Instanz des Dienstes bereitgestellt.
Der Benutzer kann auch die Anzahl der Dienstinstanzen im gesamten Cluster angeben und ein Prädikat zum Filtern geeigneter Knoten definieren. In diesem Szenario berechnet das Service Grid selbst die optimale Verteilung für die Bereitstellung von Services.
Darüber hinaus gibt es eine Funktion wie den Affinity Service. Affinität ist eine Funktion, die die Beziehung von Schlüsseln zu Partitionen und die Beziehung von Parteien zu Knoten in der Topologie definiert. Mit dem Schlüssel können Sie den Primärknoten bestimmen, auf dem Daten gespeichert sind. Auf diese Weise können Sie Ihren eigenen Dienst mit dem Schlüssel und dem Cache der Affinitätsfunktion verknüpfen. Wenn sich die Affinitätsfunktion ändert, erfolgt eine automatische Wiederholung. Der Dienst wird also immer neben den Daten platziert, die bearbeitet werden sollen, und reduziert dementsprechend den Aufwand für den Zugriff auf Informationen. Ein solches Schema kann als eine Art kollokiertes Rechnen bezeichnet werden.
Nachdem wir herausgefunden haben, was die Schönheit von Service Grid ist, werden wir Sie über seine Entwicklungsgeschichte informieren.
Was war vorher
Die vorherige Implementierung von Service Grid basierte auf dem replizierten replizierten Systemcache von Ignite. Das Wort "Cache" in Ignite bedeutet Speicher. Das heißt, dies ist nicht vorübergehend, wie Sie vielleicht denken. Trotz der Tatsache, dass der Cache replizierbar ist und jeder Knoten den gesamten Datensatz enthält, verfügt er im Cache über eine partitionierte Ansicht. Dies ist auf die Speicheroptimierung zurückzuführen.

Was ist passiert, als ein Benutzer einen Dienst bereitstellen wollte?
- Alle Knoten im Cluster haben sich angemeldet, um Daten im Repository mithilfe des integrierten Mechanismus für kontinuierliche Abfragen zu aktualisieren.
- Ein initiierender Knoten unter einer Transaktion mit festgeschriebenem Lesevorgang hat einen Datensatz in der Datenbank erstellt, der die Konfiguration des Dienstes einschließlich der serialisierten Instanz enthielt.
- Nach Erhalt der Benachrichtigung über einen neuen Datensatz berechnete der Koordinator die Verteilung basierend auf der Konfiguration. Das resultierende Objekt wird in die Datenbank zurückgeschrieben.
- Die Knoten lesen Informationen über die neue Verteilung und die bereitgestellten Dienste an
falls erforderlich.
Was passte nicht zu uns
Irgendwann kamen wir zu dem Schluss: Es ist unmöglich, mit Dienstleistungen zu arbeiten. Es gab mehrere Gründe.
Wenn während der Bereitstellung ein Fehler aufgetreten ist, können Sie dies nur anhand der Protokolle des Knotens herausfinden, auf dem alles passiert ist. Es gab nur eine asynchrone Bereitstellung. Nachdem die Steuerung von der Bereitstellungsmethode an den Benutzer zurückgegeben wurde, dauerte das Starten des Dienstes einige zusätzliche Zeit - und zu diesem Zeitpunkt konnte der Benutzer nichts steuern. Um Service Grid weiterzuentwickeln, neue Funktionen zu sehen, neue Benutzer anzulocken und das Leben für alle einfacher zu machen, müssen Sie etwas ändern.
Beim Entwurf des neuen Service Grid wollten wir zunächst eine synchrone Bereitstellungsgarantie bieten: Sobald der Benutzer die Kontrolle über die API zurückgegeben hat, kann er die Services sofort nutzen. Ich wollte dem Initiator auch die Möglichkeit geben, Bereitstellungsfehler zu behandeln.
Außerdem wollte ich die Implementierung erleichtern, nämlich von Transaktionen und Neuausrichtungen wegzukommen. Trotz der Tatsache, dass der Cache replizierbar ist und kein Ausgleich besteht, gab es während einer großen Bereitstellung mit vielen Knoten Probleme. Beim Ändern der Topologie müssen die Knoten Informationen austauschen. Bei einer großen Bereitstellung können diese Daten viel wiegen.
Wenn die Topologie instabil war, musste der Koordinator die Verteilung der Dienste neu berechnen. Wenn Sie mit Transaktionen in einer instabilen Topologie arbeiten müssen, kann dies im Allgemeinen zu schwer vorhersehbaren Fehlern führen.
Die Probleme
Welche globalen Veränderungen ohne begleitende Probleme? Die erste davon war eine Änderung der Topologie. Sie müssen verstehen, dass ein Knoten auch zum Zeitpunkt der Dienstbereitstellung jederzeit in einen Cluster eintreten oder diesen verlassen kann. Wenn der Knoten zum Zeitpunkt der Bereitstellung in den Cluster eintritt, müssen außerdem alle Informationen zu den Diensten konsistent auf den neuen Knoten übertragen werden. Und wir sprechen nicht nur über das, was bereits bereitgestellt wurde, sondern auch über aktuelle und zukünftige Bereitstellungen.
Dies ist nur eines der Probleme, die in einer separaten Liste zusammengefasst werden können:
- Wie werden statisch konfigurierte Dienste beim Starten eines Knotens bereitgestellt?
- Knoten verlassen den Cluster - was ist, wenn der Host Host-Dienste?
- Was tun, wenn sich der Koordinator geändert hat?
- Was tun, wenn der Client erneut eine Verbindung zum Cluster herstellt?
- Muss ich Aktivierungs- / Deaktivierungsanfragen verarbeiten und wie?
- Aber was ist, wenn sie den Destroy-Cache aufrufen und wir damit verbundene Affinitätsdienste haben?
Und das ist noch nicht alles.
Lösung
Als Ziel haben wir den ereignisgesteuerten Ansatz mit der Implementierung von Kommunikationsprozessen unter Verwendung von Nachrichten gewählt. Ignite hat bereits zwei Komponenten implementiert, mit denen Knoten Nachrichten untereinander weiterleiten können - Communication-SPI und Discovery-SPI.
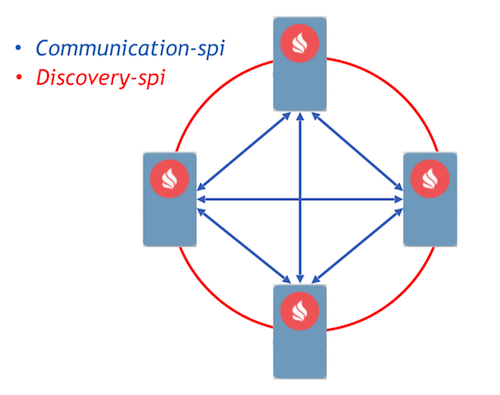
Mit Communication-SPI können Knoten Nachrichten direkt kommunizieren und weiterleiten. Es eignet sich gut zum Senden großer Datenmengen. Mit Discovery-spi können Sie eine Nachricht an alle Knoten im Cluster senden. In einer Standardimplementierung erfolgt dies gemäß der Ringtopologie. Es gibt auch eine Integration mit Zookeeper. In diesem Fall wird die Sterntopologie verwendet. Ein weiterer wichtiger Punkt: Discovery-SPI garantiert, dass die Nachricht in der richtigen Reihenfolge an alle Knoten übermittelt wird.
Betrachten Sie das Bereitstellungsprotokoll. Alle Benutzeranforderungen für die Bereitstellung und Verteilung werden über Discovery-SPI gesendet. Dies gibt folgende
Garantien :
- Die Anforderung wird von allen Knoten im Cluster empfangen. Auf diese Weise können Sie die Anforderung weiter bearbeiten, wenn Sie den Koordinator ändern. Dies bedeutet auch, dass in einer Nachricht jeder Knoten alle erforderlichen Metadaten enthält, z. B. die Konfiguration des Dienstes und seiner serialisierten Instanz.
- Mit einer strengen Reihenfolge für die Zustellung von Nachrichten können Sie Konfigurationskonflikte und konkurrierende Anforderungen lösen.
- Da die Eingabe des Knotens in die Topologie auch von Discovery-SPI verarbeitet wird, werden alle für die Arbeit mit Diensten erforderlichen Daten auf den neuen Knoten übertragen.
Nach Erhalt der Anforderung validieren die Knoten im Cluster diese und bilden Aufgaben zur Verarbeitung. Diese Aufgaben werden in die Warteschlange gestellt und dann von einem separaten Mitarbeiter in einem anderen Thread verarbeitet. Dies wird auf diese Weise implementiert, da eine Bereitstellung eine beträchtliche Zeit in Anspruch nehmen kann und eine Verzögerung eines teuren Erkennungsdatenstroms nicht akzeptabel ist.
Alle Anforderungen aus der Warteschlange werden vom Deployment Manager verarbeitet. Er hat einen speziellen Mitarbeiter, der eine Aufgabe aus dieser Warteschlange zieht und sie initialisiert, um mit der Bereitstellung zu beginnen. Danach werden folgende Aktionen ausgeführt:
- Jeder Knoten berechnet die Verteilung dank einer neuen deterministischen Zuweisungsfunktion unabhängig.
- Die Knoten bilden eine Nachricht mit den Ergebnissen der Bereitstellung und senden sie an den Koordinator.
- Der Koordinator aggregiert alle Nachrichten und generiert das Ergebnis des gesamten Bereitstellungsprozesses, der über Discovery-SPI an alle Knoten im Cluster gesendet wird.
- Nach Erhalt des Ergebnisses ist der Bereitstellungsprozess abgeschlossen, wonach die Aufgabe aus der Warteschlange entfernt wird.
 Neues ereignisgesteuertes Design: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.java
Neues ereignisgesteuertes Design: org.apache.ignite.internal.processors.service.IgniteServiceProcessor.javaWenn zum Zeitpunkt der Bereitstellung ein Fehler aufgetreten ist, nimmt der Knoten diesen Fehler sofort in die Nachricht auf, die ihn an den Koordinator sendet. Nach der Nachrichtenaggregation verfügt der Koordinator über Informationen zu allen Fehlern während der Bereitstellung und sendet diese Nachricht über Discovery-SPI. Fehlerinformationen sind auf jedem Knoten im Cluster verfügbar.
Nach diesem Algorithmus werden alle wichtigen Ereignisse im Service Grid verarbeitet. Beispielsweise ist eine Topologieänderung auch eine Discovery-SPI-Nachricht. Im Allgemeinen erwies sich das Protokoll im Vergleich zu dem, was es war, als recht leicht und zuverlässig. So viel, um jede Situation während der Bereitstellung zu bewältigen.
Was wird als nächstes passieren?
Nun zu den Plänen. Jede größere Entwicklung im Ignite-Projekt wird als Initiative zur Verbesserung von Ignite, dem sogenannten IEP, durchgeführt. Das Service Grid-Redesign hat auch einen IEP -
IEP Nr. 17 mit dem Banter-Namen „Oil Change in Service Grid“. Tatsächlich haben wir jedoch nicht das Öl im Motor gewechselt, sondern den gesamten Motor.
Wir haben die Aufgaben im IEP in zwei Phasen unterteilt. Die erste ist eine Hauptphase, die darin besteht, das Bereitstellungsprotokoll zu ändern. Es ist bereits in den Assistenten eingefüllt. Sie können das neue Service Grid ausprobieren, das in Version 2.8 angezeigt wird. Die zweite Phase umfasst viele andere Aufgaben:
- Hot redeep
- Service-Versionierung
- Erhöhte Ausfallsicherheit
- Dünner Client
- Tools zum Überwachen und Zählen verschiedener Metriken
Schließlich können wir Ihnen Service Grid für den Bau fehlertoleranter Hochverfügbarkeitssysteme empfehlen. Wir laden Sie auch zur
Entwickler- und
Benutzerliste ein, um Ihre Erfahrungen
zu teilen. Ihre Erfahrung ist wirklich wichtig für die Community. Sie hilft Ihnen zu verstehen, wohin Sie als Nächstes gehen und wie Sie die Komponente in Zukunft entwickeln können.