Hallo. Ende letzten Jahres haben wir begonnen, Kennzeichen automatisch auf Fotos in Avito-Ankündigungskarten zu verbergen. Lesen Sie den Artikel darüber, warum wir dies getan haben und wie solche Probleme gelöst werden können.

Herausforderung
Auf Avito wurden 2018 2,5 Millionen Autos verkauft. Das sind fast 7000 pro Tag. Alle Anzeigen zum Verkauf benötigen eine Illustration - Foto eines Autos. Anhand der Staatsnummer finden Sie jedoch viele zusätzliche Informationen zum Auto. Und einige unserer Benutzer versuchen, das Nummernschild selbst zu schließen.
Die Gründe, warum Benutzer das Kennzeichen ausblenden möchten, können unterschiedlich sein. Wir für unseren Teil möchten ihnen helfen, ihre Daten zu schützen. Und wir versuchen, die Kauf- und Verkaufsprozesse für Benutzer zu verbessern. Zum Beispiel arbeitet ein anonymer Nummerndienst schon lange mit uns zusammen: Wenn Sie ein Auto verkaufen, wird eine temporäre Handynummer für Sie erstellt. Um die Daten auf den Nummernschildern zu schützen, anonymisieren wir Fotos.

Lösungsübersicht
Um den Schutz von Benutzerfotos zu automatisieren, können Sie mithilfe von Faltungs-Neuronalen Netzen ein Polygon mit einem Nummernschild erkennen.
Zur Erkennung von Objekten werden nun Architekturen zweier Gruppen verwendet: zweistufige Netzwerke, z. B. Faster RCNN und Mask RCNN; einstufig (Einzelaufnahme) - SSD, YOLO, RetinaNet. Das Erkennen eines Objekts ist die Ableitung der vier Koordinaten des Rechtecks, in das das interessierende Objekt eingeschrieben ist.
Die oben genannten Netzwerke können viele Objekte verschiedener Klassen in Bildern finden, was für die Lösung des Problems der Kennzeichensuche bereits überflüssig ist, da wir normalerweise nur ein Auto auf den Bildern haben (es gibt Ausnahmen, wenn Leute Bilder von ihrem verkauften Auto und seinem zufälligen Nachbarn machen , aber das kommt ziemlich selten vor, so dass dies vernachlässigt werden könnte).
Ein weiteres Merkmal dieser Netzwerke ist, dass sie standardmäßig einen Begrenzungsrahmen mit Seiten parallel zu den Koordinatenachsen erzeugen. Dies geschieht, weil eine Reihe vordefinierter Arten von rechteckigen Rahmen, die als Ankerkästen bezeichnet werden, zur Erkennung verwendet werden. Genauer gesagt wird zuerst unter Verwendung eines Faltungsnetzwerks (zum Beispiel resnet34) eine Matrix von Attributen aus dem Bild erhalten. Dann erfolgt für jede Teilmenge von Attributen, die unter Verwendung des Schiebefensters erhalten werden, eine Klassifizierung: Gibt es ein Objekt für die k-Ankerbox oder nicht, und es wird eine Regression in die vier Koordinaten des Rahmens durchgeführt, die seine Position anpassen.
Lesen Sie hier mehr darüber.
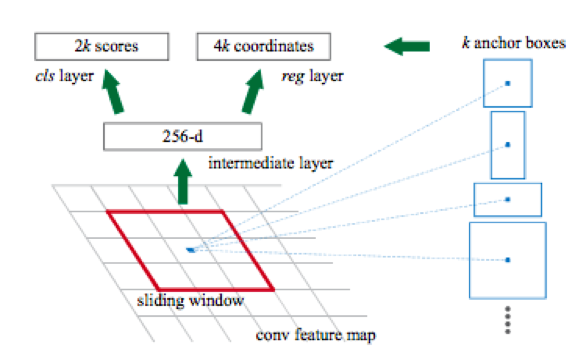
Danach gibt es zwei weitere Köpfe:
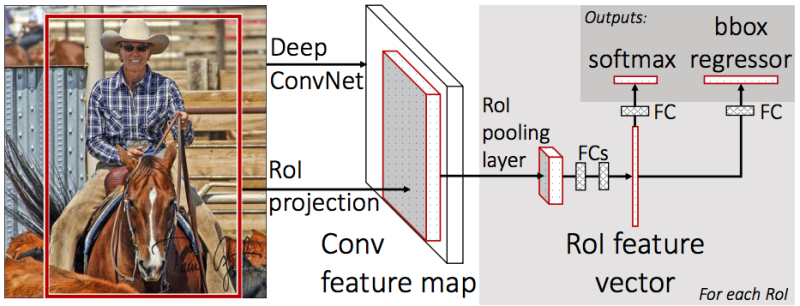
eine zur Klassifizierung des Objekts (Hund / Katze / Pflanze usw.),
der zweite (bbox-Regressor) - zur Regression der Koordinaten des Rahmens, die im vorherigen Schritt erhalten wurden, um das Verhältnis der Fläche des Objekts zur Fläche des Rahmens zu erhöhen.
Um den gedrehten Boxrahmen vorherzusagen, müssen Sie den bbox-Regressor so ändern, dass Sie auch den Drehwinkel des Rahmens erhalten. Wenn dies nicht getan wird, wird es sich irgendwie herausstellen.

Neben dem zweistufigen Faster R-CNN gibt es einstufige Detektoren wie RetinaNet. Es unterscheidet sich von der vorherigen Architektur darin, dass es die Klasse und den Rahmen sofort vorhersagt, ohne dass im Vorfeld Abschnitte des Bildes vorgeschlagen werden müssen, die Objekte enthalten können. Um gedrehte Masken vorherzusagen, müssen Sie auch den Kopf des Box-Subnetzes ändern.
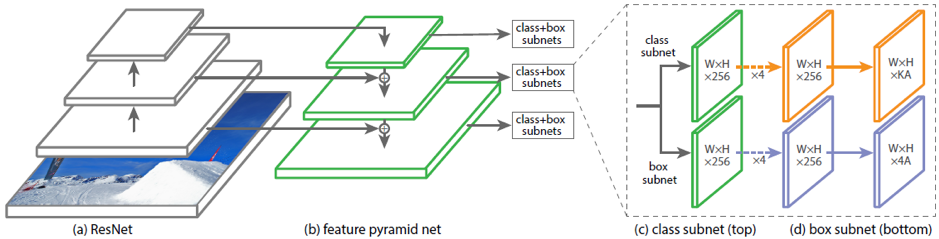
Ein Beispiel für vorhandene Architekturen zur Vorhersage gedrehter Begrenzungsrahmen ist DRBOX. Dieses Netzwerk verwendet nicht die vorläufige Phase des Vorschlags der Region wie in Faster RCNN, daher handelt es sich um eine Modifikation einstufiger Methoden. Um dieses Netzwerk zu trainieren, wird K verwendet, das in bestimmten Winkeln gedreht wird. Das Netzwerk sagt voraus, dass die Wahrscheinlichkeiten für jede K rbox das Zielobjekt, die Koordinaten, die bbox-Größe und den Drehwinkel enthalten.

Das Ändern der Architektur und das Umschulung eines der betrachteten Netzwerke für Daten mit gedrehten Begrenzungsrahmen ist eine realisierbare Aufgabe. Unser Ziel kann jedoch leichter erreicht werden, da der Umfang unseres Netzwerks viel enger ist - nur um Nummernschilder zu verbergen.
Aus diesem Grund haben wir uns entschlossen, mit einem einfachen Netzwerk zur Vorhersage der vier Punkte der Zahl zu beginnen. Anschließend wird es möglich sein, die Architektur zu komplizieren.
Daten
Die Zusammenstellung des Datensatzes ist in zwei Schritte unterteilt: Sammeln von Bildern von Autos und Markieren des Bereichs mit einem Nummernschild. Die erste Aufgabe wurde bereits in unserer Infrastruktur gelöst: Wir speichern sorgfältig alle Anzeigen, die jemals auf Avito geschaltet wurden. Um das zweite Problem zu lösen, verwenden wir Toloka. Auf
toloka.yandex.ru/requester erstellen
wir eine Aufgabe:
Die Aufgabe gab ein Foto des Autos. Es ist notwendig, das Nummernschild des Autos mit einem Viereck hervorzuheben. In diesem Fall sollte die Statusnummer so genau wie möglich vergeben werden.

Mit Toloka können Sie Aufgaben zum Markieren von Daten erstellen. Bewerten Sie beispielsweise die Qualität der Suchergebnisse, markieren Sie verschiedene Objektklassen (Texte und Bilder), markieren Sie Videos usw. Sie werden von Toloka-Benutzern für die von Ihnen berechnete Gebühr durchgeführt. In unserem Fall müssen Toloker beispielsweise die Deponie mit dem Kennzeichen des Autos auf dem Foto markieren. Im Allgemeinen ist es sehr praktisch, einen großen Datensatz zu markieren, aber es ist ziemlich schwierig, eine hohe Qualität zu erzielen. Es gibt viele Bots in der Menge, deren Aufgabe es ist, Geld von Ihnen zu bekommen, indem Sie zufällig Antworten geben oder eine Strategie anwenden. Um diesen Bots entgegenzuwirken, gibt es ein System von Regeln und Kontrollen. Die Hauptprüfung ist das Mischen von Kontrollfragen: Sie markieren einen Teil der Aufgaben manuell über die Toloki-Oberfläche und mischen sie dann in die Hauptaufgabe. Wenn das Markup bei Kontrollfragen häufig falsch ist, blockieren Sie es und berücksichtigen das Markup nicht.
Für die Klassifizierungsaufgabe ist es sehr einfach zu bestimmen, ob die Markierung falsch ist oder nicht, und für das Problem des Hervorhebens einer Region ist es nicht so einfach. Der klassische Weg ist, IoU zu zählen.
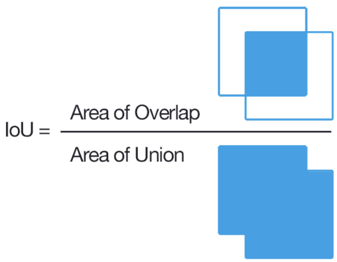
Wenn dieses Verhältnis für mehrere Aufgaben unter einem bestimmten Schwellenwert liegt, wird ein solcher Benutzer blockiert. Für zwei beliebige Vierecke ist die Berechnung der IoU jedoch nicht so einfach, zumal es in Tolok erforderlich ist, dies in JavaScript zu implementieren. Wir haben einen kleinen Hack gemacht und wir glauben, dass der Benutzer sich nicht geirrt hat, wenn für jeden Punkt des Quellpolygons in einer kleinen Nachbarschaft ein Punkt mit einem Schreiber markiert ist. Es gibt auch eine Regel für schnelle Antworten, um zu schnell antwortende Benutzer, Captcha, Diskrepanzen mit der Mehrheitsmeinung usw. zu blockieren. Nachdem Sie diese Regeln eingerichtet haben, können Sie ein ziemlich gutes Markup erwarten, aber wenn Sie wirklich qualitativ hochwertige und komplexe Markups benötigen, müssen Sie speziell Freiberufler-Schreiber einstellen. Infolgedessen belief sich unser Datensatz auf 4.000 markierte Bilder, und bei Tolok kostete alles 28 US-Dollar.
Modell
Erstellen wir nun ein Netzwerk, um die vier Punkte des Gebiets vorherzusagen. Wir erhalten die Zeichen mit resnet18 (11,7 Millionen Parameter gegenüber 21,8 Millionen Parametern für resnet34), dann machen wir einen Kopf für die Regression auf vier Punkte (acht Koordinaten) und einen Kopf für die Klassifizierung, ob das Bild ein Nummernschild enthält oder nicht. Der zweite Kopf wird benötigt, weil in Anzeigen für den Verkauf von Autos nicht alle Fotos mit Autos. Das Foto kann ein Detail des Autos sein.

Ähnlich wie bei uns ist es natürlich nicht notwendig zu erkennen.
Wir trainieren zwei Ziele gleichzeitig, indem wir dem Datensatz ein Foto ohne Nummernschild mit einem Begrenzungsrahmen (0,0,0,0,0,0,0,0,0) und einem Wert für den Klassifikator „Bild mit / ohne Nummernschild“ hinzufügen - (0, 1).
Anschließend können Sie für beide Ziele eine einzige Verlustfunktion als Summe der folgenden Verluste erstellen. Für die Regression zu den Koordinaten des Kennzeichenpolygons verwenden wir einen glatten L1-Verlust.
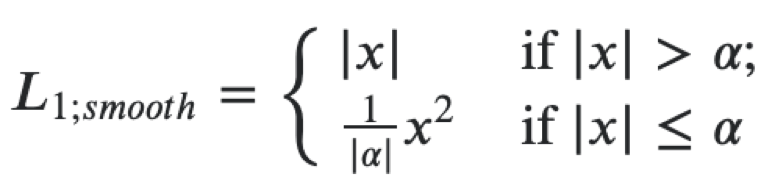
Es kann als eine Kombination von L1 und L2 interpretiert werden, die sich wie L1 verhält, wenn der Absolutwert des Arguments groß ist, und als L2, wenn der Wert des Arguments nahe Null liegt. Für die Klassifizierung verwenden wir Softmax- und Crossentropieverlust. Der Feature-Extraktor ist resnet18. Wir verwenden auf ImageNet vorab trainierte Gewichte. Anschließend werden wir den Extraktor und die Köpfe in unserem Datensatz weiter trainieren. In diesem Problem haben wir das mxnet-Framework verwendet, da es das Hauptframework für Computer Vision in Avito ist. Im Allgemeinen können Sie mit der Microservice-Architektur nicht an ein bestimmtes Framework gebunden sein. Wenn Sie jedoch über eine große Codebasis verfügen, ist es besser, diese zu verwenden und nicht denselben Code erneut zu schreiben.
Nachdem wir eine akzeptable Qualität für unseren Datensatz erhalten hatten, wandten wir uns an die Designer, um uns ein Nummernschild mit dem Avito-Logo zu besorgen. Zuerst haben wir es natürlich selbst versucht, aber es sah nicht sehr schön aus. Als nächstes müssen Sie die Helligkeit des Avito-Nummernschilds auf die Helligkeit des ursprünglichen Bereichs mit dem Nummernschild ändern, und Sie können das Logo auf dem Bild überlagern.

In prod starten
Das Problem der Reproduzierbarkeit der Ergebnisse, der Unterstützung und der Entwicklung von Projekten, das in der Welt der Backend- und Frontend-Entwicklung mit einigen Fehlern gelöst wurde, bleibt offen, wenn maschinelle Lernmodelle verwendet werden müssen. Sie mussten wahrscheinlich das Legacy-Codemodell verstehen. Es ist gut, wenn die Readme-Datei Links zu Artikeln oder Open Source-Repositorys enthält, auf denen die Lösung basiert. Das Skript zum Starten der Umschulung kann mit Fehlern fehlschlagen. Beispielsweise hat sich die cudnn-Version geändert, und diese Version von tensorflow funktioniert nicht mehr mit dieser Version von cudnn, und cudnn funktioniert nicht mit dieser Version von nvidia-Treibern. Vielleicht haben wir zum Training einen Iterator gemäß den Daten verwendet und zum Testen in der Produktion einen anderen. Dies kann noch einige Zeit dauern. Im Allgemeinen bestehen Reproduzierbarkeitsprobleme.
Wir versuchen, sie mithilfe der nvidia-docker-Umgebung für Trainingsmodelle zu entfernen, sie enthält alle erforderlichen Abhängigkeiten für cuda und wir installieren dort auch Abhängigkeiten für Python. Die Version der Bibliothek mit einem Iterator nach Daten, Erweiterungen und Inferenzmodellen ist für die Trainings- / Experimentierphase und für die Produktion üblich. Um das Modell auf neue Daten zu trainieren, müssen Sie das Repository auf den Server pumpen und das Shell-Skript ausführen, das die Docker-Umgebung sammelt, in der sich das Jupiter-Notebook befindet. Im Inneren finden Sie alle Notebooks zum Trainieren und Testen, die mit Sicherheit nicht mit einem Fehler aufgrund der Umgebung versagen. Es ist natürlich besser, eine train.py-Datei zu haben, aber die Praxis zeigt, dass Sie immer mit Ihren Augen auf das schauen müssen, was das Modell gibt, und etwas im Lernprozess ändern müssen, damit Sie am Ende immer noch jupyter ausführen.
Modellgewichte werden in git lfs gespeichert - dies ist eine spezielle Technologie zum Speichern großer Dateien in einem git. Vorher haben wir Artefakte verwendet, aber die Verwendung von git lfs ist bequemer, da Sie beim Herunterladen des Repositorys mit dem Dienst sofort die aktuelle Version der Waage erhalten, wie in der Produktion. Autotests werden für Modellinferenzen geschrieben, sodass Sie keinen Service mit Gewichten bereitstellen können, die diese nicht bestehen. Der Dienst selbst wird im Docker innerhalb der Microservice-Infrastruktur des Kubernetes-Clusters gestartet. Zur Überwachung der Leistung verwenden wir Grafana. Nach dem Rolling erhöhen wir die Belastung von Service-Instanzen schrittweise mit einem neuen Modell. Bei der Einführung eines neuen Features erstellen wir A / B-Tests und fällen auf der Grundlage statistischer Tests ein Urteil über das zukünftige Schicksal des Features.
Als Ergebnis: Wir haben das Glänzen von Zahlen auf Anzeigen in der Auto-Kategorie für private Händler gestartet. Das 95. Perzentil der Verarbeitungszeit eines Bildes zum Ausblenden der Zahl beträgt 250 ms.