Menschen lernen Architektur aus alten Büchern, die für Java geschrieben wurden. Die Bücher sind gut, aber sie bieten eine Lösung für die Probleme dieser Zeit mit Instrumenten dieser Zeit. Die Zeit hat sich geändert, C # ähnelt eher Light Scala als Java, und es gibt nur wenige neue gute Bücher.
In diesem Artikel untersuchen wir die Kriterien für guten und schlechten Code, wie und was zu messen ist. Wir werden einen Überblick über typische Aufgaben und Ansätze sehen, wir werden die Vor- und Nachteile analysieren. Am Ende finden Sie Empfehlungen und Best Practices für das Entwerfen von Webanwendungen.
Dieser Artikel ist eine Abschrift meines Berichts von der DotNext 2018-Konferenz in Moskau. Neben dem Text gibt es ein Video und einen Link zu den Folien unter dem Schnitt.

Folien und Berichtsseite auf der Site .
Kurz über mich: Ich komme aus Kasan und arbeite für die High Tech Group. Wir entwickeln Software für Unternehmen. Vor kurzem habe ich an der Kasaner Bundesuniversität einen Kurs namens Corporate Software Development unterrichtet. Von Zeit zu Zeit schreibe ich immer noch Artikel über Habr über technische Praktiken, über die Entwicklung von Unternehmenssoftware.
Wie Sie wahrscheinlich vermutet haben, werde ich heute über die Entwicklung von Unternehmenssoftware sprechen, nämlich über die Strukturierung moderner Webanwendungen:
- die Kriterien
- eine kurze Geschichte der Entwicklung des architektonischen Denkens (was war, was ist geworden, welche Probleme sind);
- Überblick über die Mängel der klassischen Puff-Architektur
- die Entscheidung
- Schritt-für-Schritt-Analyse der Implementierung, ohne auf Details einzugehen
- Ergebnisse.
Kriterien
Wir formulieren die Kriterien. Ich mag es wirklich nicht, wenn über Design im Stil von „Mein Kung Fu ist stärker als dein Kung Fu“ gesprochen wird. Ein Unternehmen hat im Prinzip ein bestimmtes Kriterium, das Geld genannt wird. Jeder weiß, dass Zeit Geld ist, daher sind diese beiden Komponenten meistens die wichtigsten.

Also die Kriterien. Im Prinzip fordert uns das Unternehmen am häufigsten auf, „so viele Funktionen wie möglich pro Zeiteinheit“ zu verwenden, aber mit einer Einschränkung: Diese Funktionen sollten funktionieren. Und der erste Schritt, bei dem es zu Problemen kommen kann, ist die Codeüberprüfung. Das heißt, es scheint, dass der Programmierer sagte: "Ich werde es in drei Stunden tun." Drei Stunden vergingen, die Überprüfung kam in den Code und der Teamleiter sagte: "Oh, nein, wiederholen Sie es." Es gibt drei weitere - und wie viele Iterationen die Codeüberprüfung bestanden hat, so viel, dass Sie drei Stunden multiplizieren müssen.
Der nächste Punkt ist die Rückkehr aus der Phase des Abnahmetests. Das selbe. Wenn die Funktion nicht funktioniert, wird sie nicht ausgeführt. Diese drei Stunden dauern eine Woche, zwei - wie üblich. Das letzte Kriterium ist die Anzahl der Regressionen und Fehler, die trotz Tests und Akzeptanz die Produktion durchlaufen haben. Das ist auch sehr schlecht. Bei diesem Kriterium gibt es ein Problem. Es ist schwierig zu verfolgen, da der Zusammenhang zwischen der Tatsache, dass wir etwas in das Repository verschieben, und der Tatsache, dass nach zwei Wochen etwas kaputt gegangen ist, schwierig zu verfolgen sein kann. Aber es ist trotzdem möglich.
Architekturentwicklung
Es war einmal, als Programmierer gerade anfingen, Programme zu schreiben, gab es noch keine Architektur, und jeder tat alles, was er wollte.

Deshalb haben wir so einen architektonischen Stil. Dies wird hier als "Nudelcode" bezeichnet, im Ausland heißt es "Spaghetti-Code". Alles ist mit allem verbunden: Wir ändern etwas an Punkt A - es bricht an Punkt B, es ist völlig unmöglich zu verstehen, was mit was verbunden ist. Natürlich erkannten die Programmierer schnell, dass dies nicht funktionieren würde und eine gewisse Struktur erforderlich war, und beschlossen, dass einige Ebenen uns helfen würden. Wenn Sie sich vorstellen, dass Hackfleisch Code ist und Lasagne solche Schichten, finden Sie hier eine Illustration der Schichtarchitektur. Das Hackfleisch blieb gehackt, aber jetzt kann das Hackfleisch aus Schicht Nr. 1 nicht einfach mit dem Hackfleisch aus Schicht Nr. 2 sprechen. Wir haben dem Code eine Form gegeben: Selbst auf dem Bild können Sie sehen, dass das Klettern mehr gerahmt ist.
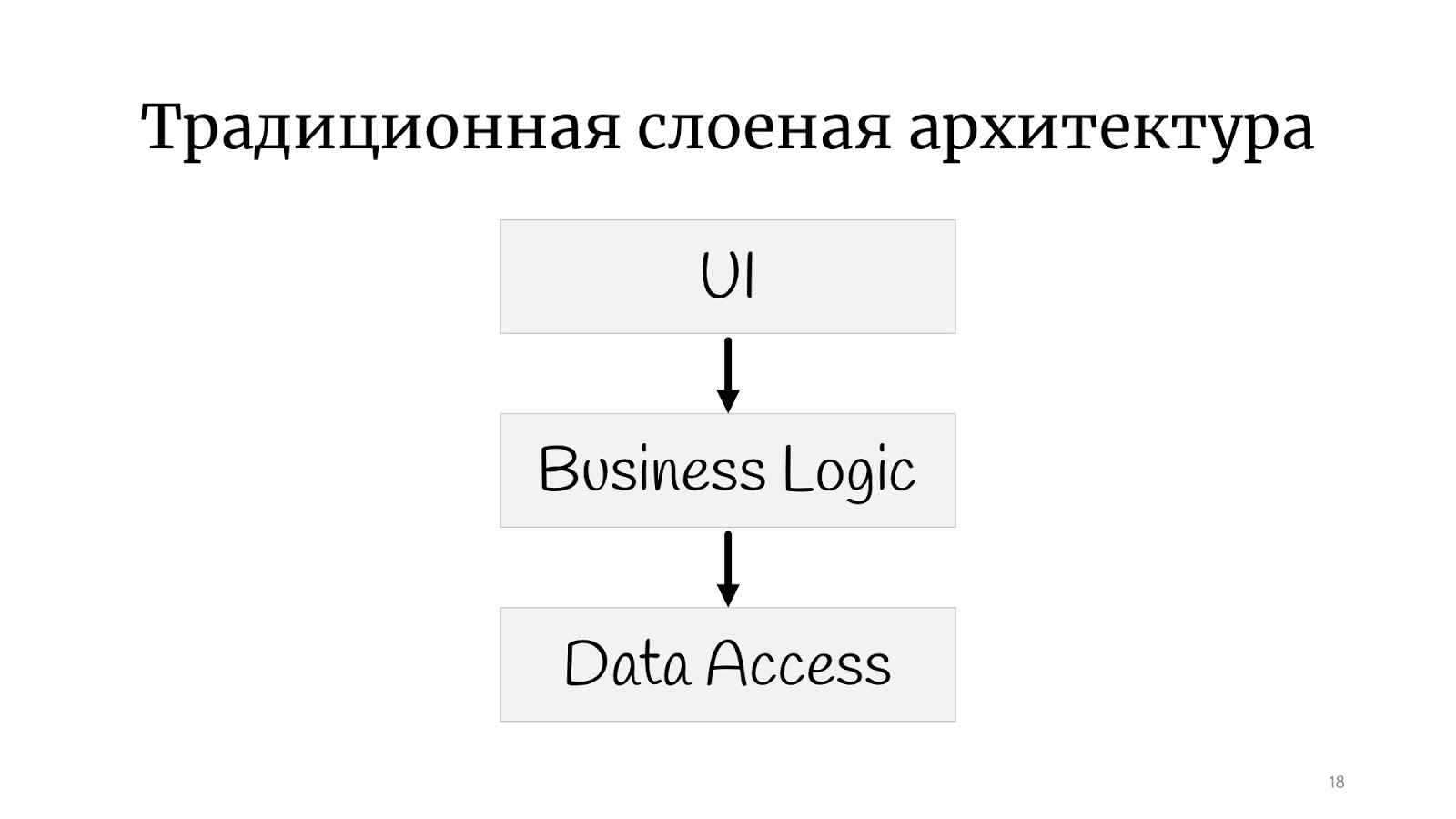
Jeder ist wahrscheinlich mit der
klassischen Schichtarchitektur vertraut: Es gibt eine Benutzeroberfläche, eine Geschäftslogik und eine Datenzugriffsschicht. Es gibt immer noch alle Arten von Dienstleistungen, Fassaden und Schichten, die nach dem Architekten benannt sind, der das Unternehmen verlassen hat. Es kann eine unbegrenzte Anzahl von ihnen geben.

Die nächste Stufe war die sogenannte
Zwiebelarchitektur . Es scheint, dass es einen großen Unterschied gibt: Vorher gab es ein kleines Quadrat, und hier gab es Kreise. Es scheint ganz anders zu sein.
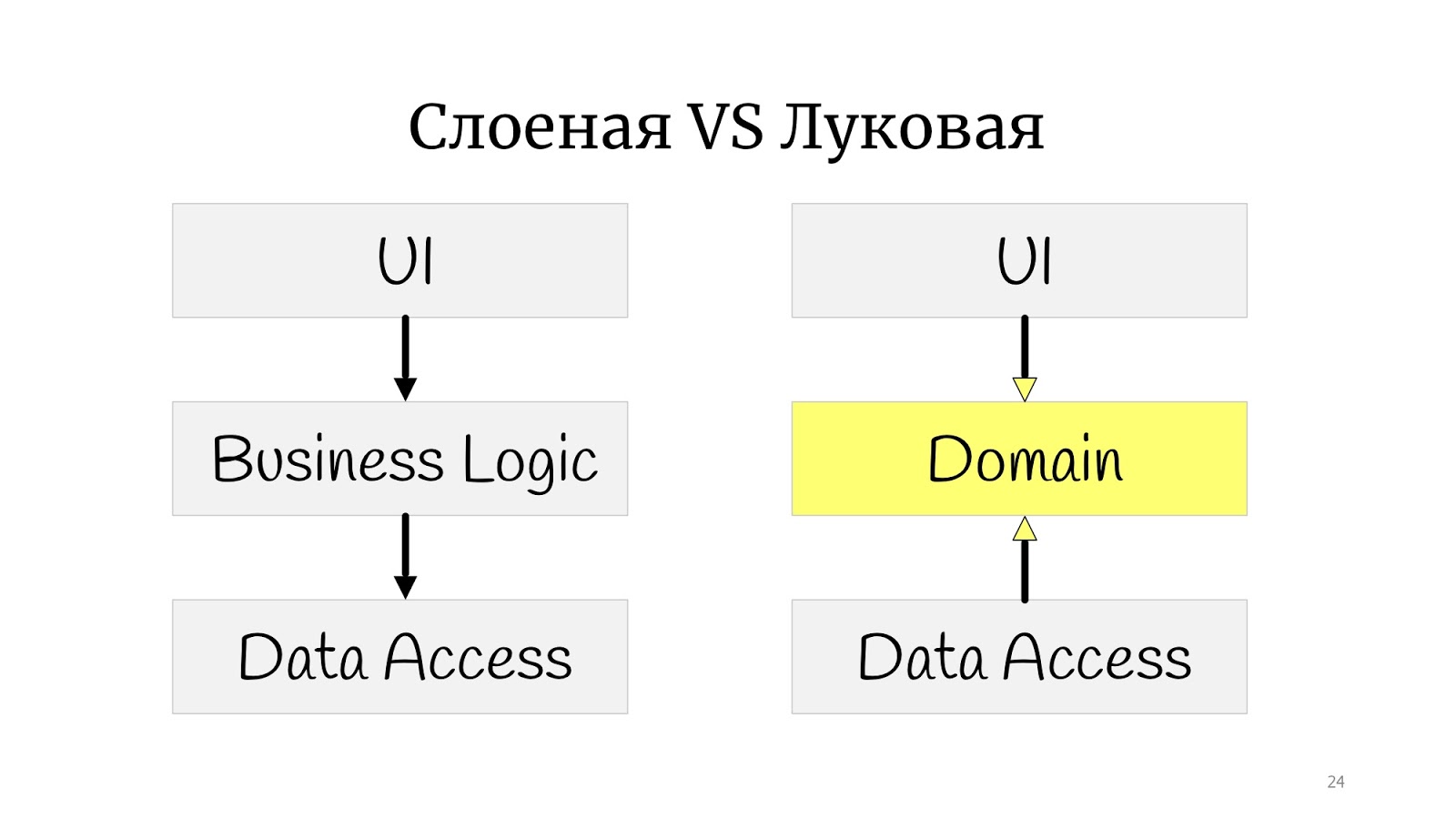
Nicht wirklich. Der ganze Unterschied besteht darin, dass irgendwann um diese Zeit die Prinzipien von SOLID formuliert wurden und sich herausstellte, dass es bei der klassischen Zwiebel ein Problem mit der Abhängigkeitsinversion gibt, da der abstrakte Domänencode aus irgendeinem Grund von der Implementierung und dem Datenzugriff abhängt. Daher haben wir uns für die Bereitstellung von Datenzugriff entschieden und haben Datenzugriff abhängig von der Domäne.

Hier habe ich das Zeichnen geübt und die Zwiebelarchitektur gezeichnet, aber nicht klassisch mit den „Ringen“. Ich habe etwas zwischen einem Polygon und Kreisen. Ich habe dies nur getan, um zu zeigen, dass wenn Sie auf die Wörter "Zwiebel", "sechseckig" oder "Ports und Adapter" stoßen - es ist alles das Gleiche. Der Punkt ist, dass sich die Domäne in der Mitte befindet, in Dienste eingeschlossen ist, es können Domänen- oder Anwendungsdienste sein, wie Sie möchten. Und die Außenwelt in Form von Benutzeroberfläche, Tests und Infrastruktur, in die DAL umgezogen ist - sie kommunizieren über diese Serviceschicht mit der Domäne.
Ein einfaches Beispiel. E-Mail-Update
Mal sehen, wie ein einfacher Anwendungsfall in einem solchen Paradigma aussehen würde - Aktualisieren der E-Mail-Adresse des Benutzers.
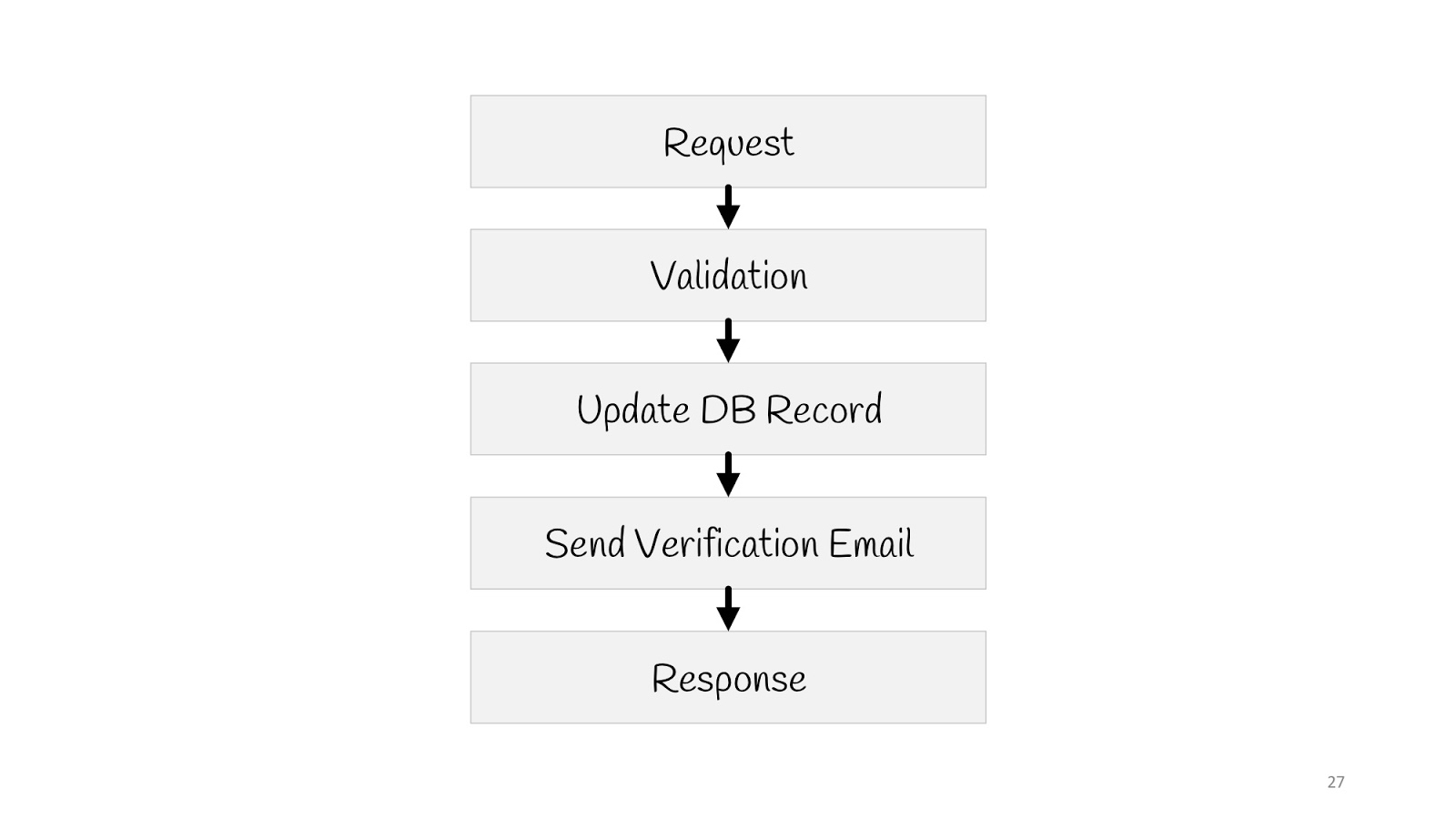
Wir müssen eine Anfrage senden, validieren, den Wert in der Datenbank aktualisieren, eine Benachrichtigung an eine neue E-Mail senden: "Alles ist in Ordnung, Sie haben Ihre E-Mail geändert, wir wissen, dass alles in Ordnung ist" und auf den Browser "200" antworten - alles ist in Ordnung.
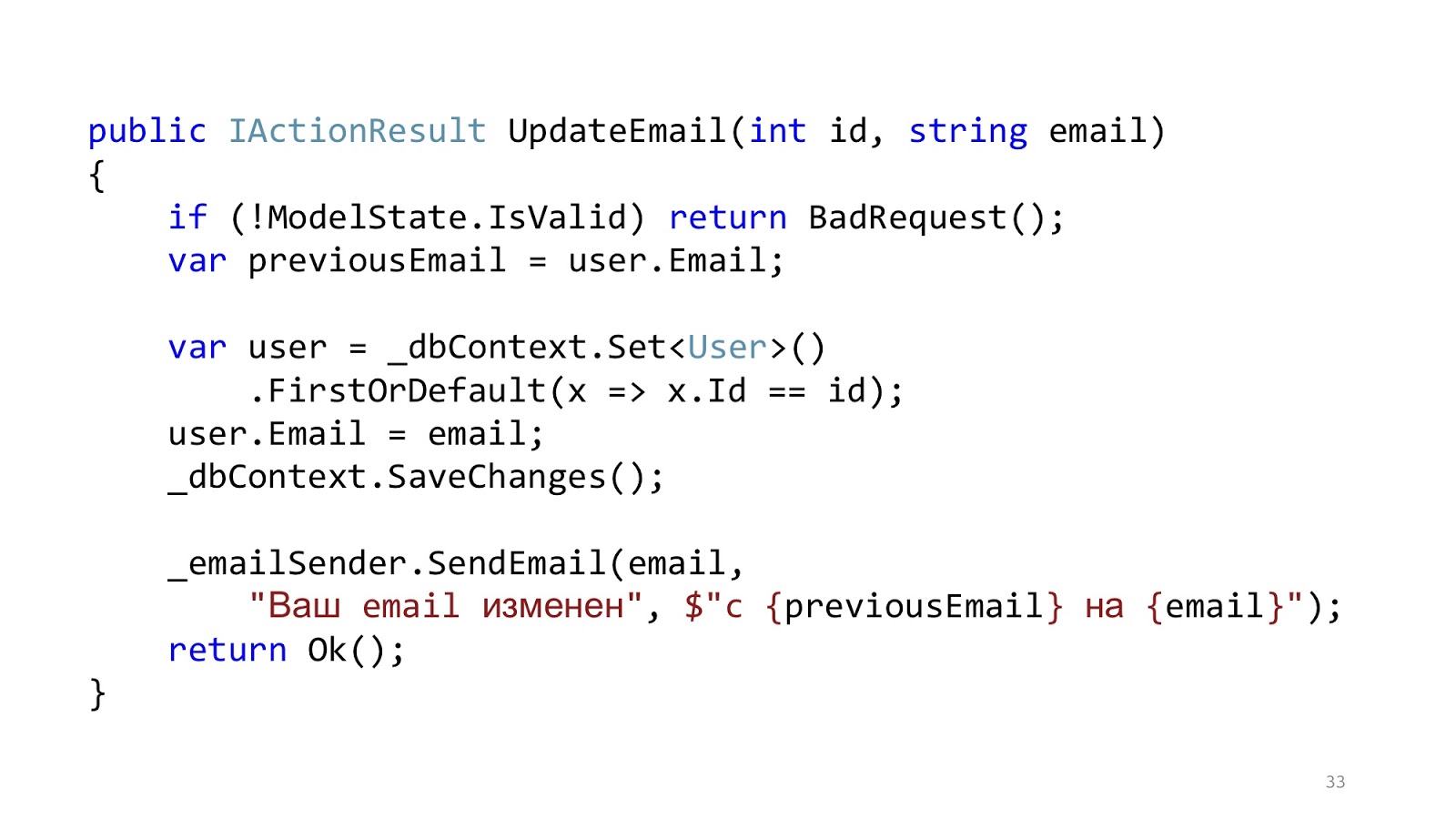
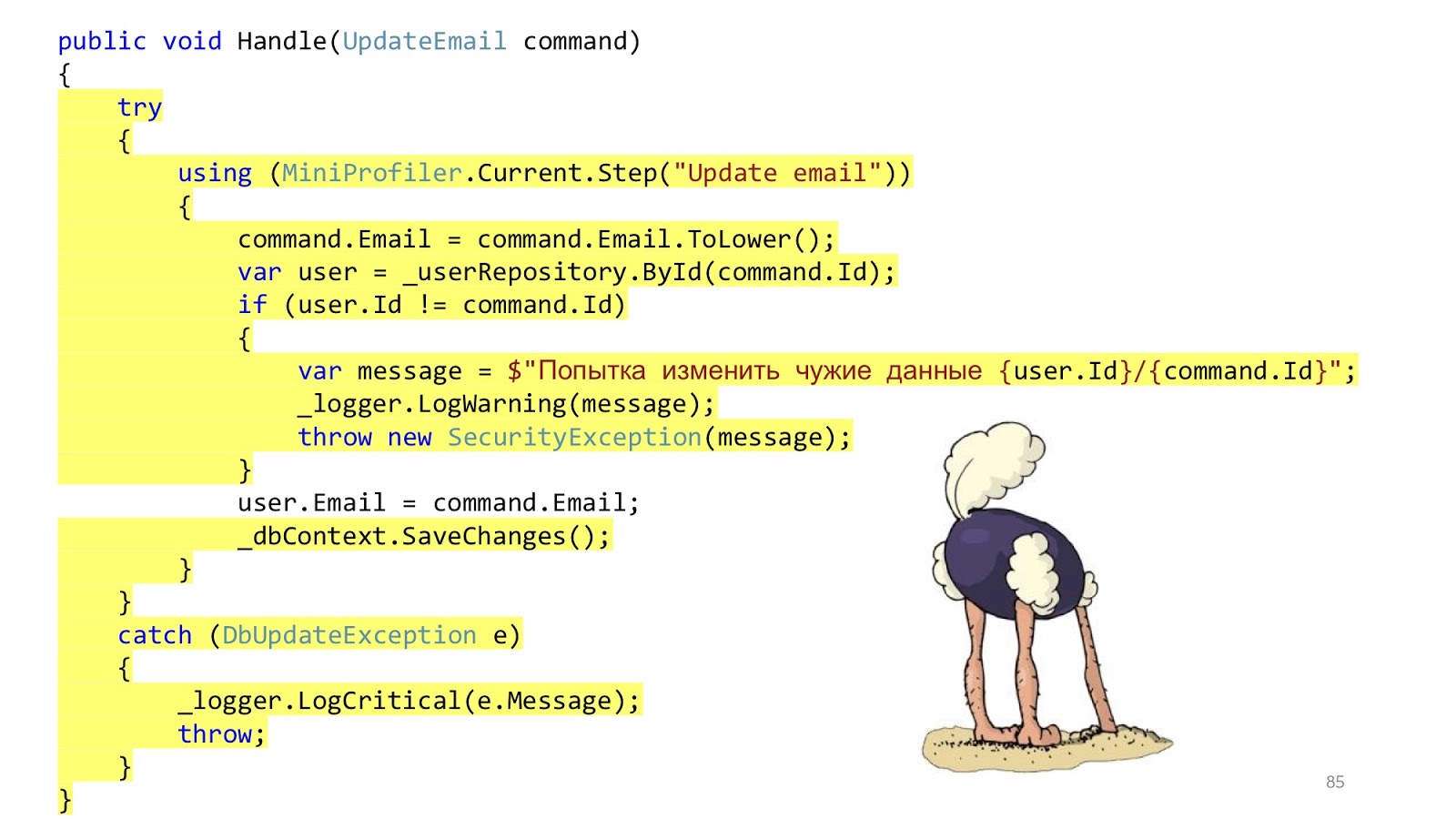
Der Code könnte ungefähr so aussehen. Hier haben wir die Standard-
ASP.NET- MVC-Validierung, es gibt ORM zum Lesen und Aktualisieren der Daten und es gibt eine Art E-Mail-Absender, der eine Benachrichtigung sendet. Es scheint, als wäre alles gut, oder? Eine Einschränkung - in einer idealen Welt.
In der realen Welt ist die Situation etwas anders. Es geht darum, Autorisierung, Fehlerprüfung, Formatierung, Protokollierung und Profilerstellung hinzuzufügen. Dies alles hat nichts mit unserem Anwendungsfall zu tun, aber es sollte alles sein. Und dieses kleine Stück Code wurde groß und beängstigend: mit viel Verschachtelung, mit viel Code, mit der Tatsache, dass es schwer zu lesen ist und vor allem, dass es mehr Infrastrukturcode als Domänencode gibt.

"Wo sind die Dienstleistungen?" - Du sagst. Ich habe die gesamte Logik an die Controller geschrieben. Natürlich ist dies ein Problem, jetzt werde ich Dienste hinzufügen und alles wird gut.

Wir fügen Dienste hinzu, und es wird wirklich besser, weil wir anstelle eines großen Fußtuchs eine kleine schöne Linie haben.
Ist es besser geworden? Es ist geworden! Und jetzt können wir diese Methode in verschiedenen Controllern wiederverwenden. Das Ergebnis ist offensichtlich. Schauen wir uns die Implementierung dieser Methode an.
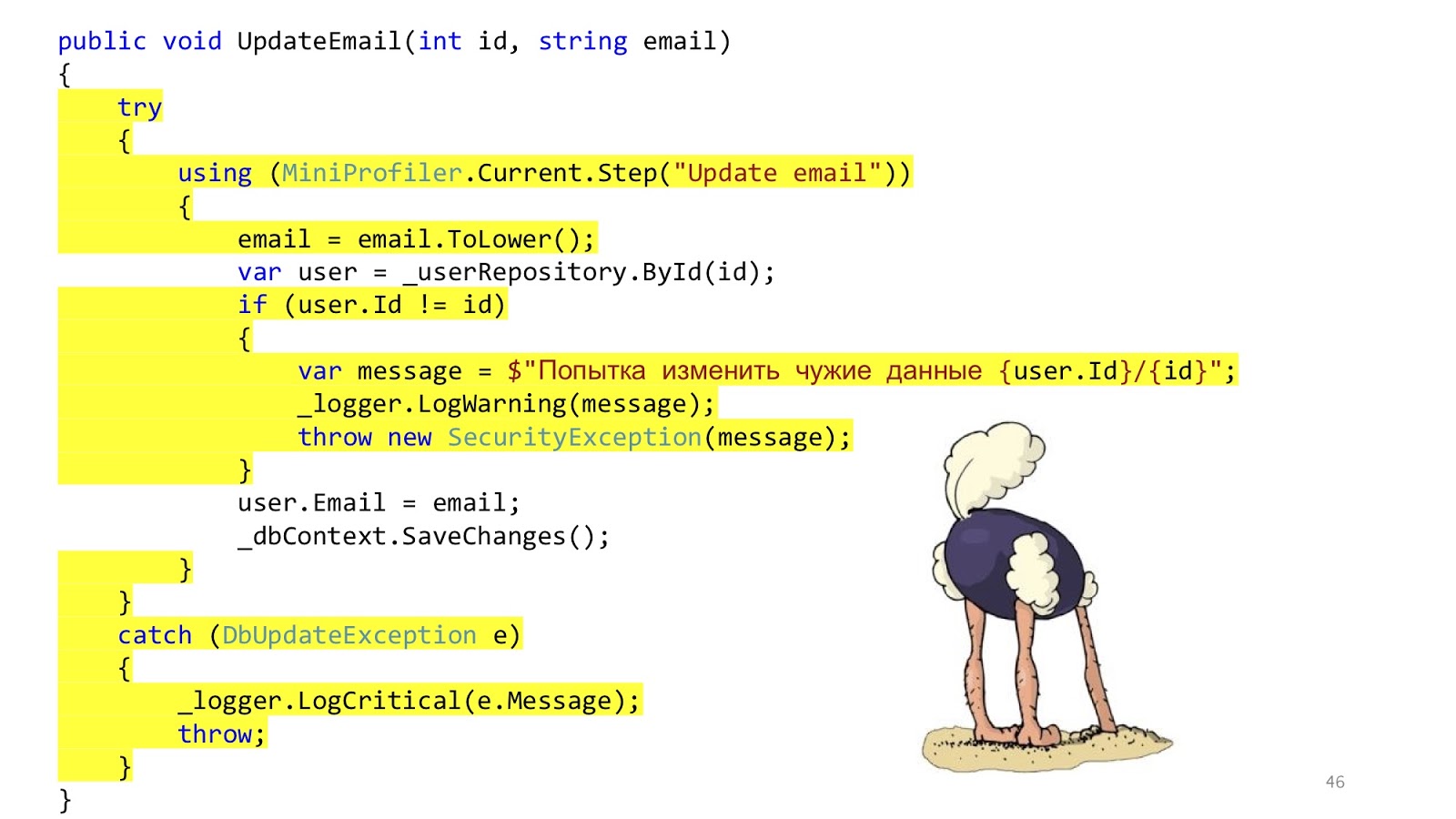
Aber hier ist nicht alles so gut. Dieser Code ist noch hier. Wir haben gerade das Gleiche auf die Dienste übertragen. Wir haben beschlossen, das Problem nicht zu lösen, sondern es einfach zu verschleiern und an einen anderen Ort zu übertragen. Das ist alles.

Darüber hinaus stellen sich einige andere Fragen. Sollten wir die Validierung im Controller oder hier durchführen? Na ja, irgendwie im Controller. Und wenn Sie in die Datenbank gehen müssen, um zu sehen, dass es eine solche ID gibt oder dass es keinen anderen Benutzer mit einer solchen E-Mail gibt? Hmm, na dann im Service. Aber Fehlerbehandlung hier? Diese Fehlerbehandlung ist wahrscheinlich hier und die Fehlerbehandlung, die auf den Browser in der Steuerung reagiert. Und die SaveChanges-Methode, ist sie im Dienst oder müssen Sie sie auf den Controller übertragen? Es kann so und so sein, denn wenn ein Dienst aufgerufen wird, ist es logischer, den Dienst aufzurufen, und wenn Sie drei Methoden von Diensten im Controller haben, die aufgerufen werden müssen, müssen Sie ihn außerhalb dieser Dienste aufrufen, damit die Transaktion eine ist. Diese Überlegungen legen nahe, dass die Schichten möglicherweise keine Probleme lösen.

Und diese Idee kam mehr als einer Person in den Sinn. Wenn Sie googeln, schreiben mindestens drei dieser angesehenen Ehemänner über dasselbe. Von oben nach unten: Stephen .NET Junkie (leider kenne ich seinen Nachnamen nicht, da sie nirgendwo im Internet erscheint), der Autor des IoC-Containers von
Simple Injector . Als nächstes ist Jimmy Bogard der Autor von
AutoMapper . Und unten ist Scott Vlashin, Autor von
F # für Spaß und Profit .
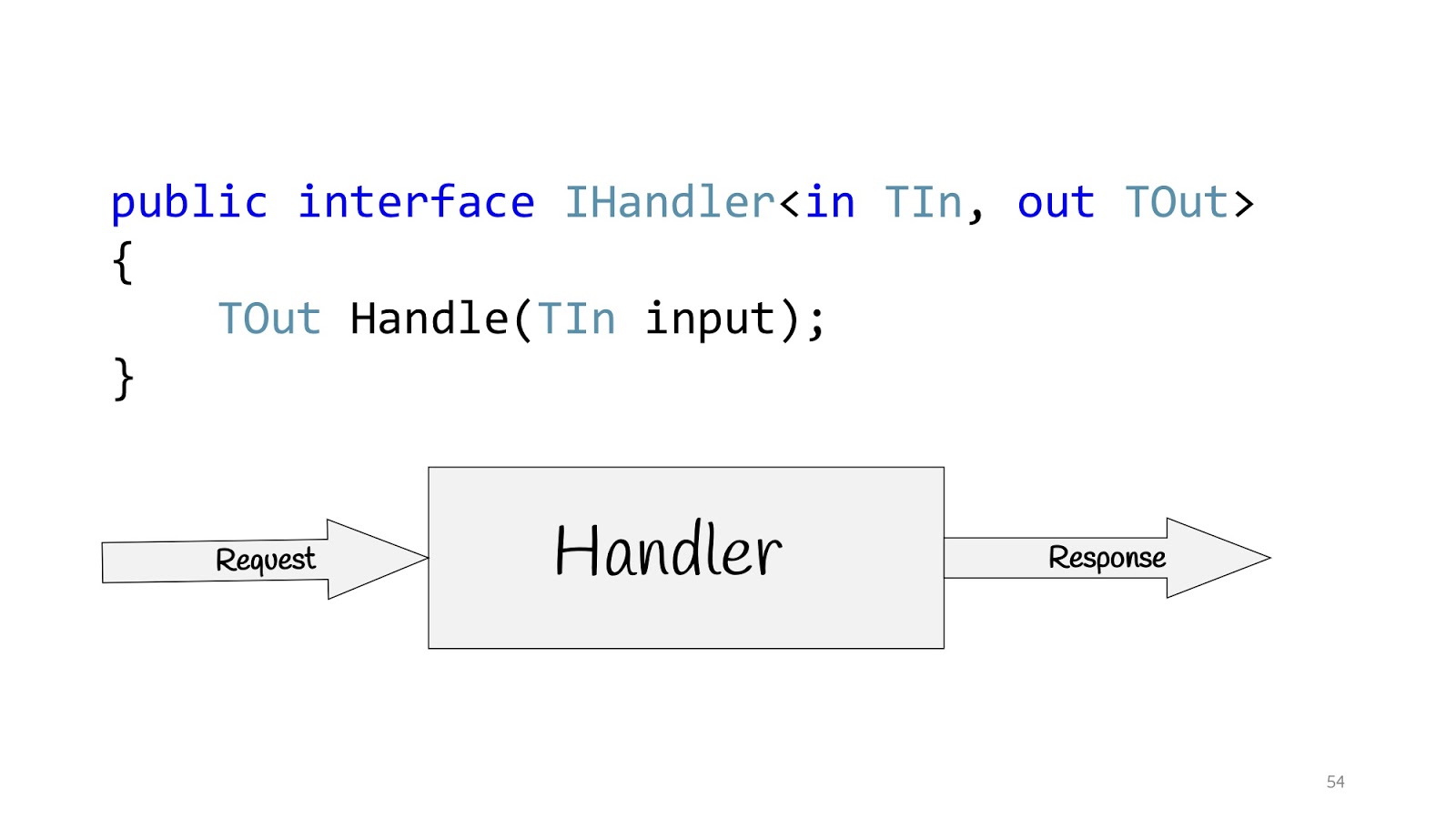
Alle diese Leute sprechen über dasselbe und schlagen vor, Anwendungen nicht auf der Grundlage von Ebenen zu erstellen, sondern auf der Grundlage von Anwendungsfällen, dh den Anforderungen, nach denen das Unternehmen uns fragt. Dementsprechend kann der Anwendungsfall in C # unter Verwendung der IHandler-Schnittstelle bestimmt werden. Es hat Eingabewerte, es gibt Ausgabewerte und es gibt eine Methode selbst, die diesen Anwendungsfall tatsächlich ausführt.

Und innerhalb dieser Methode kann es entweder ein Domänenmodell oder ein denormalisiertes Modell zum Lesen geben, möglicherweise mit Dapper oder mit Elastic Search, wenn Sie nach etwas suchen müssen und möglicherweise über Legacy verfügen -System mit gespeicherten Prozeduren - kein Problem sowie Netzwerkanforderungen - im Allgemeinen alles, was Sie dort benötigen könnten. Aber was tun, wenn keine Schichten vorhanden sind?

Lassen Sie uns zunächst UserService loswerden. Wir entfernen die Methode und erstellen eine Klasse. Und wir werden es entfernen und wir werden es wieder entfernen. Und dann nimm die Klasse und entferne sie.

Denken wir mal, sind diese Klassen gleichwertig oder nicht? Die GetUser-Klasse gibt Daten zurück und ändert nichts auf dem Server. Dies betrifft beispielsweise die Anfrage "Geben Sie mir die Benutzer-ID". Die Klassen UpdateEmail und BanUser geben das Ergebnis der Operation zurück und ändern den Status. Wenn wir dem Server beispielsweise mitteilen: "Bitte ändern Sie den Status, Sie müssen etwas ändern."
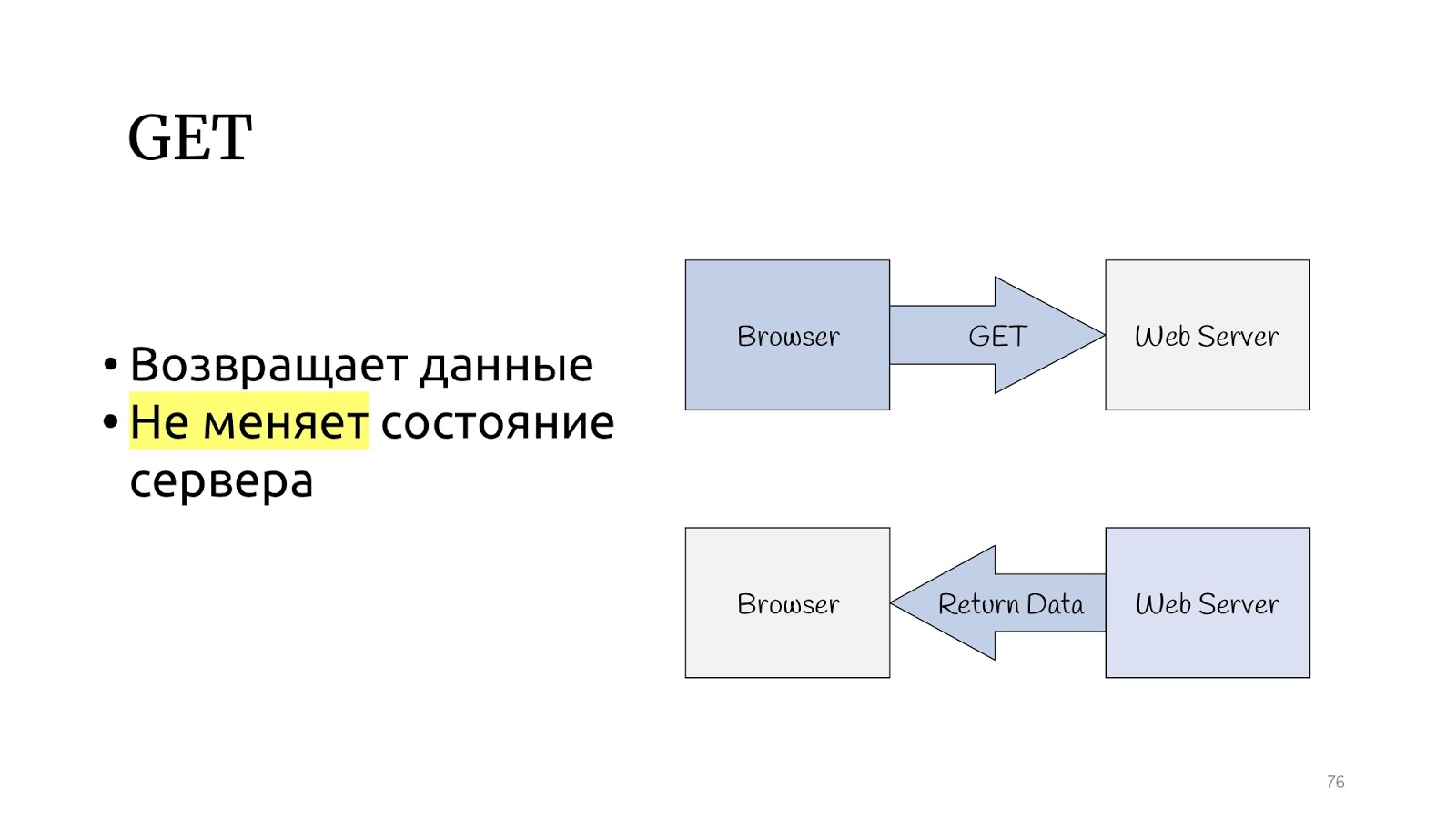
Schauen wir uns das HTTP-Protokoll an. Es gibt eine GET-Methode, die gemäß der Spezifikation des HTTP-Protokolls Daten zurückgeben und den Status des Servers nicht ändern soll.

Es gibt auch andere Methoden, die den Status des Servers ändern und das Ergebnis der Operation zurückgeben können.

Das CQRS-Paradigma scheint speziell für das HTTP-Protokoll entwickelt worden zu sein. Abfragen sind GET-Operationen und Befehle sind PUT, POST, DELETE - Sie müssen nichts erfinden.
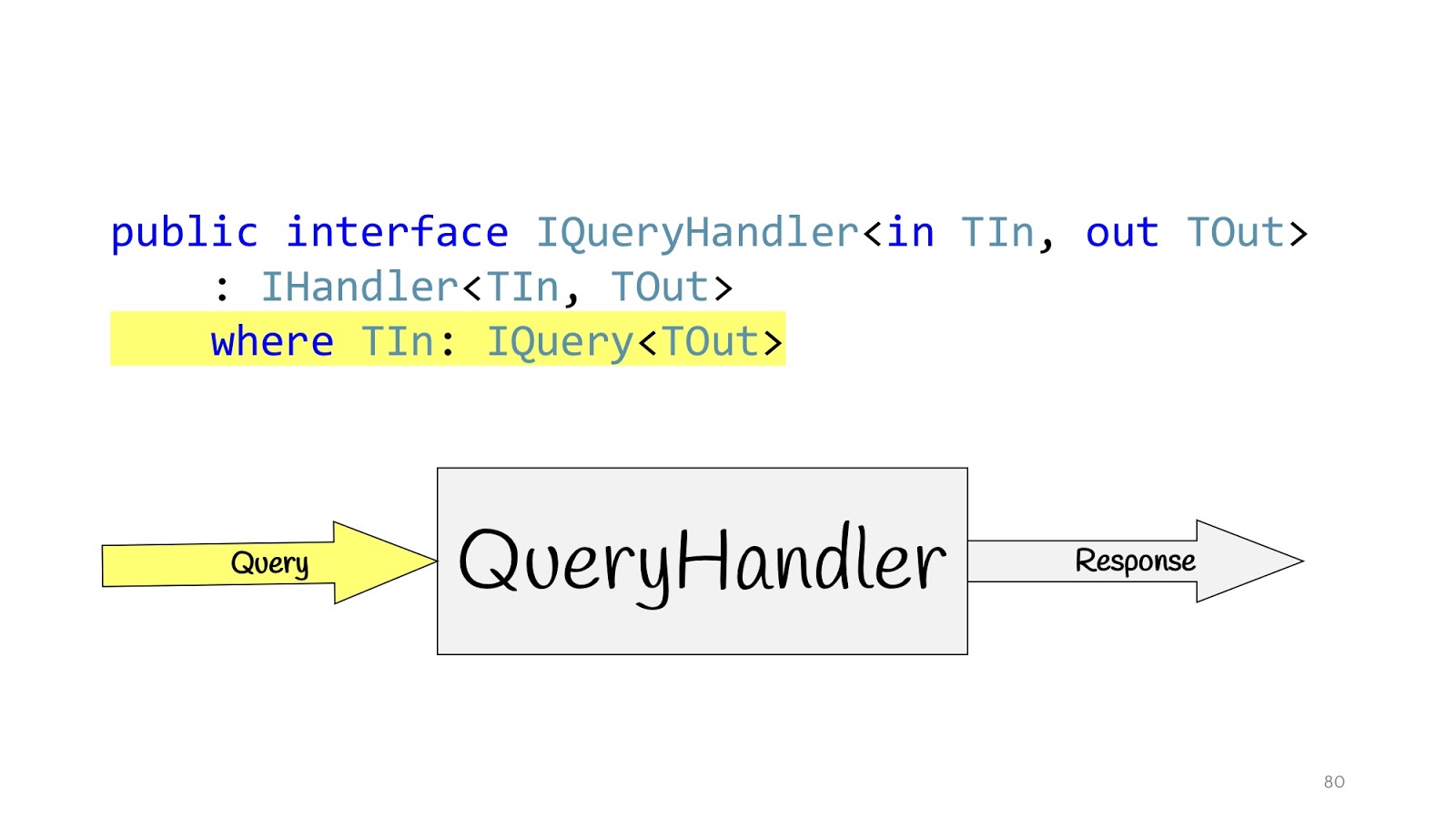
Wir definieren unseren Handler neu und definieren zusätzliche Schnittstellen. IQueryHandler, der sich nur dadurch unterscheidet, dass wir die Einschränkung aufgehängt haben, dass der Typ der Eingabewerte IQuery ist. IQuery ist eine Markierungsschnittstelle, es gibt nichts außer dieser generischen. Wir benötigen das Generikum, um Einschränkungen in den QueryHandler einzufügen, und jetzt, da wir QueryHandler deklarieren, können wir dort keine Abfrage übergeben, aber wenn wir das Query-Objekt dort übergeben, kennen wir seinen Rückgabewert. Dies ist praktisch, wenn Sie nur eine Schnittstelle haben, sodass Sie nicht nach deren Implementierung im Code suchen müssen, um nicht durcheinander zu kommen. Sie schreiben IQueryHandler, schreiben dort eine Implementierung und können in TOut keinen anderen Typ von Rückgabewert ersetzen. Es wird einfach nicht kompiliert. So können Sie sofort sehen, welche Eingabewerte welchen Eingabedaten entsprechen.

Die Situation ist für CommandHandler mit einer Ausnahme völlig ähnlich: Dieses Generikum wird für einen weiteren Trick benötigt, den wir etwas weiter unten sehen werden.
Handler-Implementierung
Handler, haben wir angekündigt, was ist ihre Implementierung?
Gibt es ein Problem, ja? Etwas scheint gescheitert zu sein.
Dekorateure eilen zur Rettung
Aber es hat nicht geholfen, da wir uns noch mitten auf der Straße befinden, müssen wir noch ein wenig finalisieren, und dieses Mal müssen wir das
Dekorationsmuster verwenden , nämlich die wunderbare Layoutfunktion. Der Dekorateur kann in einen Dekorateur, in einen Dekorateur oder in einen Dekorateur eingewickelt werden - fahren Sie fort, bis Sie sich langweilen.
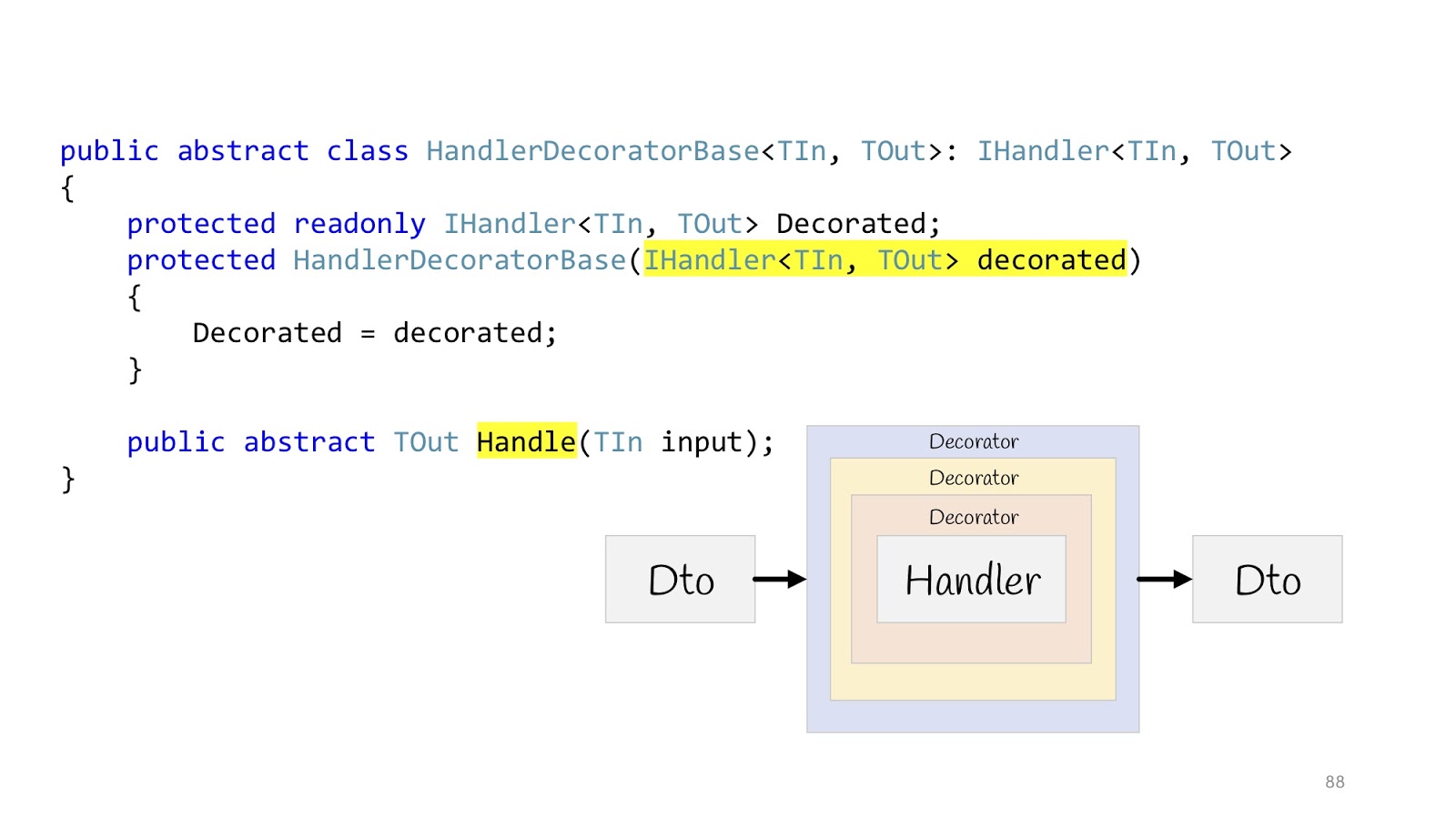
Dann sieht alles so aus: Es gibt eine Eingabe Dto, sie gibt den ersten Dekorator ein, den zweiten, dritten, dann gehen wir in den Handler und beenden ihn auch, gehen alle Dekoratoren durch und geben Dto im Browser zurück. Wir deklarieren eine abstrakte Basisklasse, um sie später zu erben. Der Body des Handlers wird an den Konstruktor übergeben, und wir deklarieren die abstrakte Handle-Methode, in der zusätzliche Dekoratorlogik aufgehängt wird.
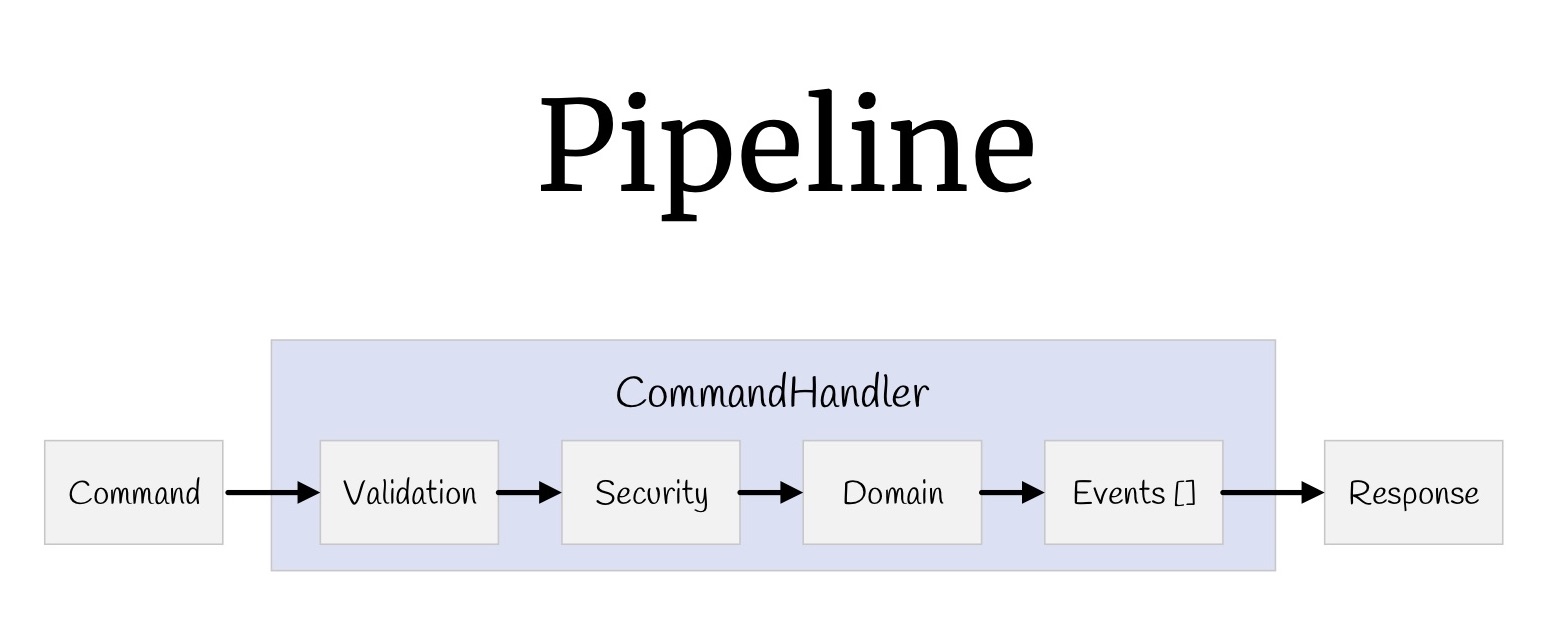
Jetzt können Sie mit Hilfe von Dekorateuren eine ganze Pipeline bauen. Beginnen wir mit den Teams. Was hatten wir? Eingabewerte, Validierung, Überprüfung der Zugriffsrechte, die Logik selbst, einige Ereignisse, die als Ergebnis dieser Logik auftreten, und Rückgabewerte.

Beginnen wir mit der Validierung. Wir erklären einen Dekorateur. IEnumerable von Typ T-Validatoren kommt in den Konstruktor dieses Dekorators. Wir führen sie alle aus, prüfen, ob die Validierung fehlschlägt und der Rückgabetyp
IEnumerable<validationresult> , und können ihn zurückgeben, da die Typen übereinstimmen. Und wenn es sich um einen anderen Hander handelt, müssen Sie eine Ausnahme auslösen, da hier kein Ergebnis angezeigt wird, der Typ eines anderen Rückgabewerts.
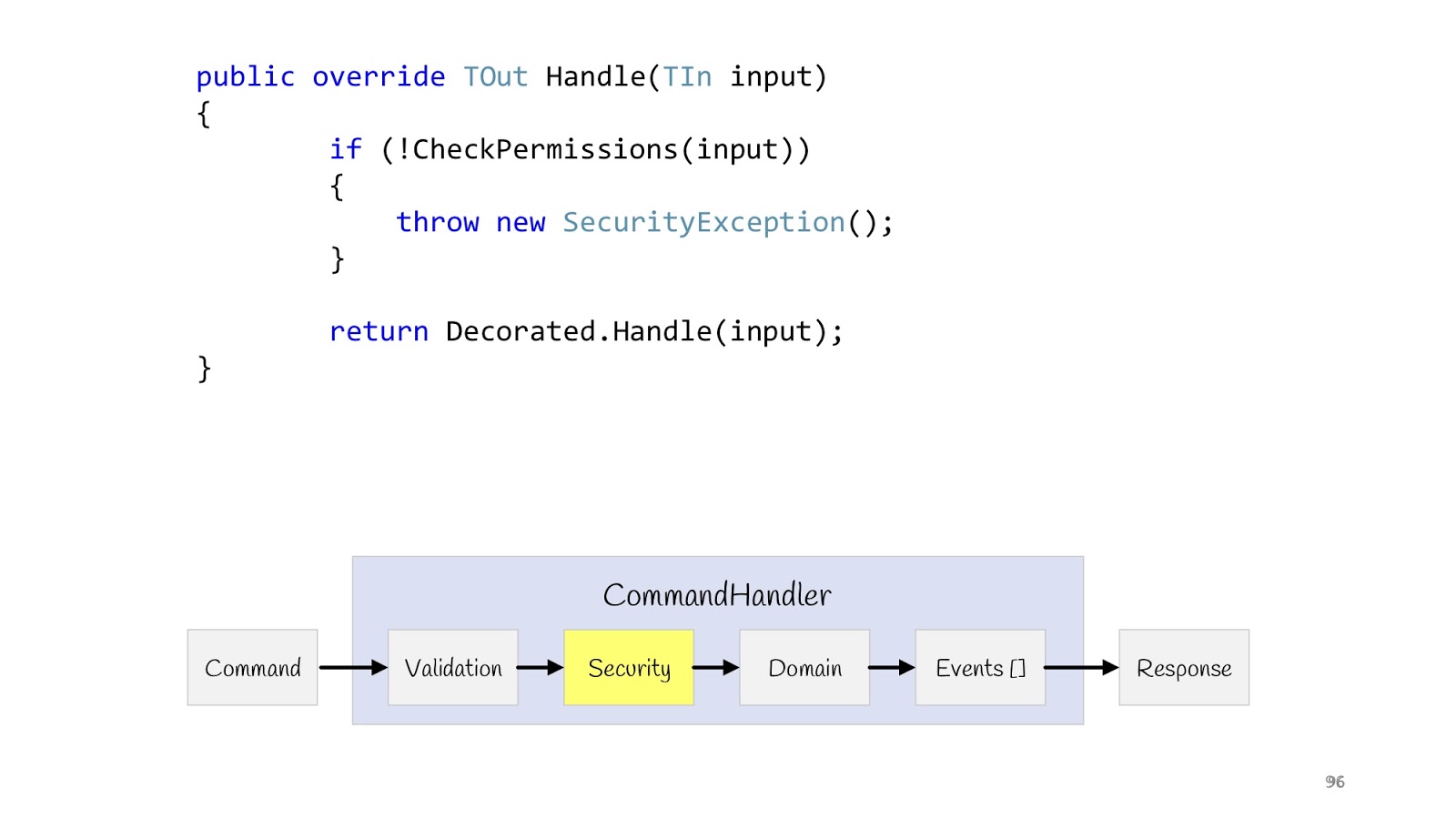
Der nächste Schritt ist Sicherheit. Wir deklarieren auch den Dekorateur, machen die CheckPermission-Methode und überprüfen. Wenn plötzlich etwas schief gelaufen ist, fahren wir nicht fort. Nachdem wir alle Überprüfungen abgeschlossen haben und sicher sind, dass alles in Ordnung ist, können wir unsere Logik erfüllen.
Bevor ich die Implementierung der Logik zeige, möchte ich etwas früher beginnen, nämlich mit den Eingabewerten, die dort ankommen.
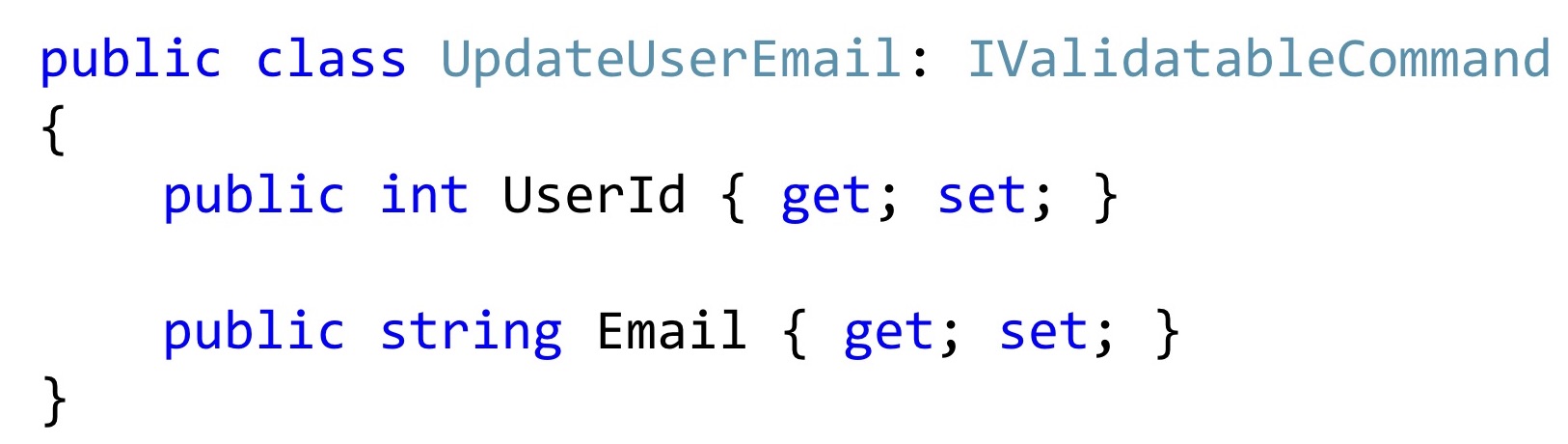
Wenn wir eine solche Klasse herausgreifen, sieht sie meistens so aus. Zumindest der Code, den ich in der täglichen Arbeit sehe.
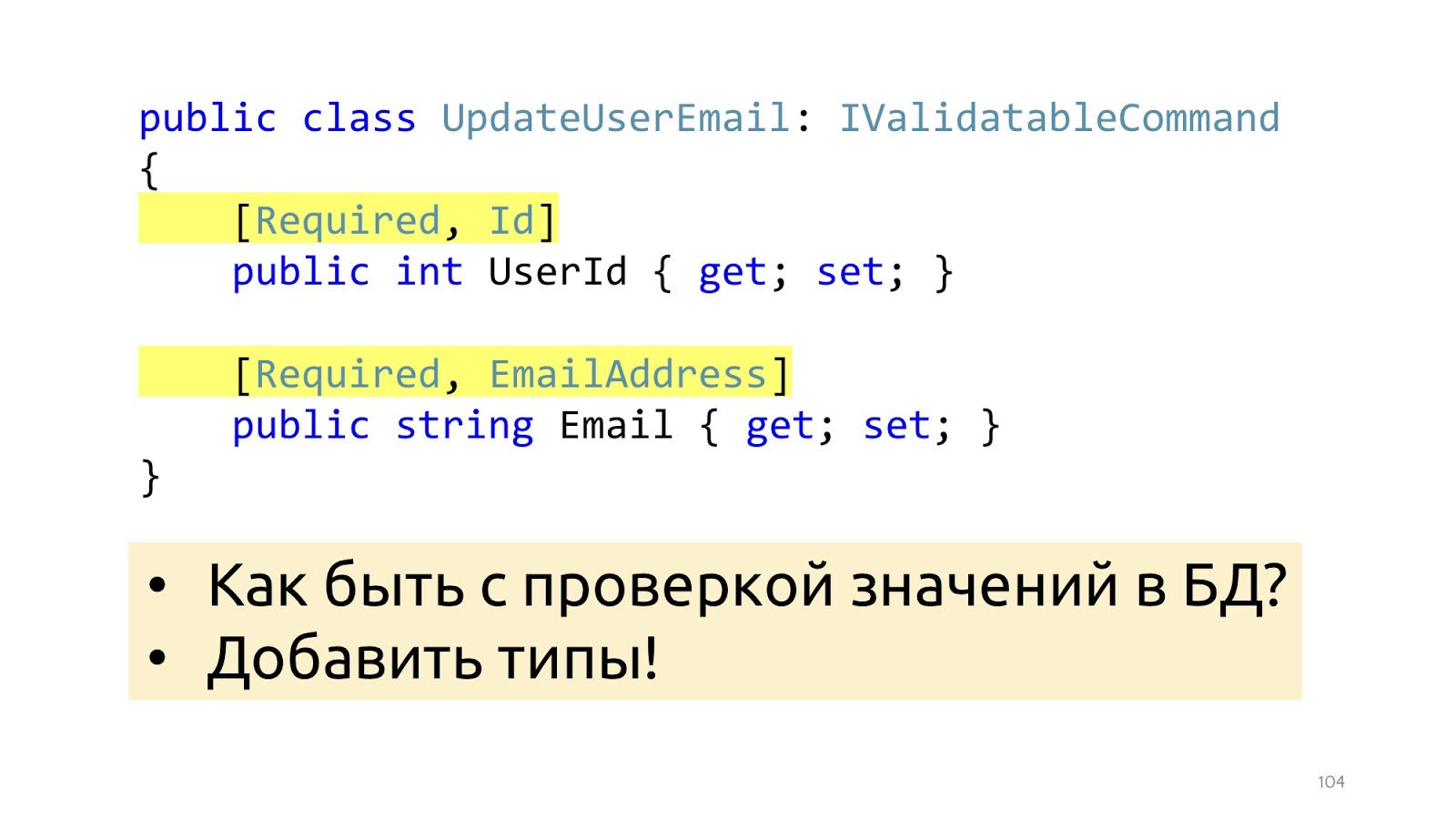
Damit die Validierung funktioniert, fügen wir hier einige Attribute hinzu, die Ihnen sagen, um welche Art von Validierung es sich handelt. Dies ist aus Sicht der Datenstruktur hilfreich, hilft jedoch nicht bei der Validierung wie der Überprüfung von Werten in der Datenbank. Es ist nur EmailAddress. Es ist nicht klar, wie und wo überprüft werden soll, wie diese Attribute verwendet werden, um zur Datenbank zu gelangen. Anstelle von Attributen können Sie zu speziellen Typen wechseln, dann wird dieses Problem gelöst.

Anstelle des
int Grundelements deklarieren wir einen ID-Typ mit dem generischen Namen, dass es sich um eine bestimmte Entität mit einem int-Schlüssel handelt. Und wir übergeben diese Entität entweder an den Konstruktor oder übergeben ihre ID, aber gleichzeitig müssen wir eine Funktion übergeben, die von Id übernommen und zurückgegeben werden kann, und prüfen, ob sie dort null ist oder nicht.
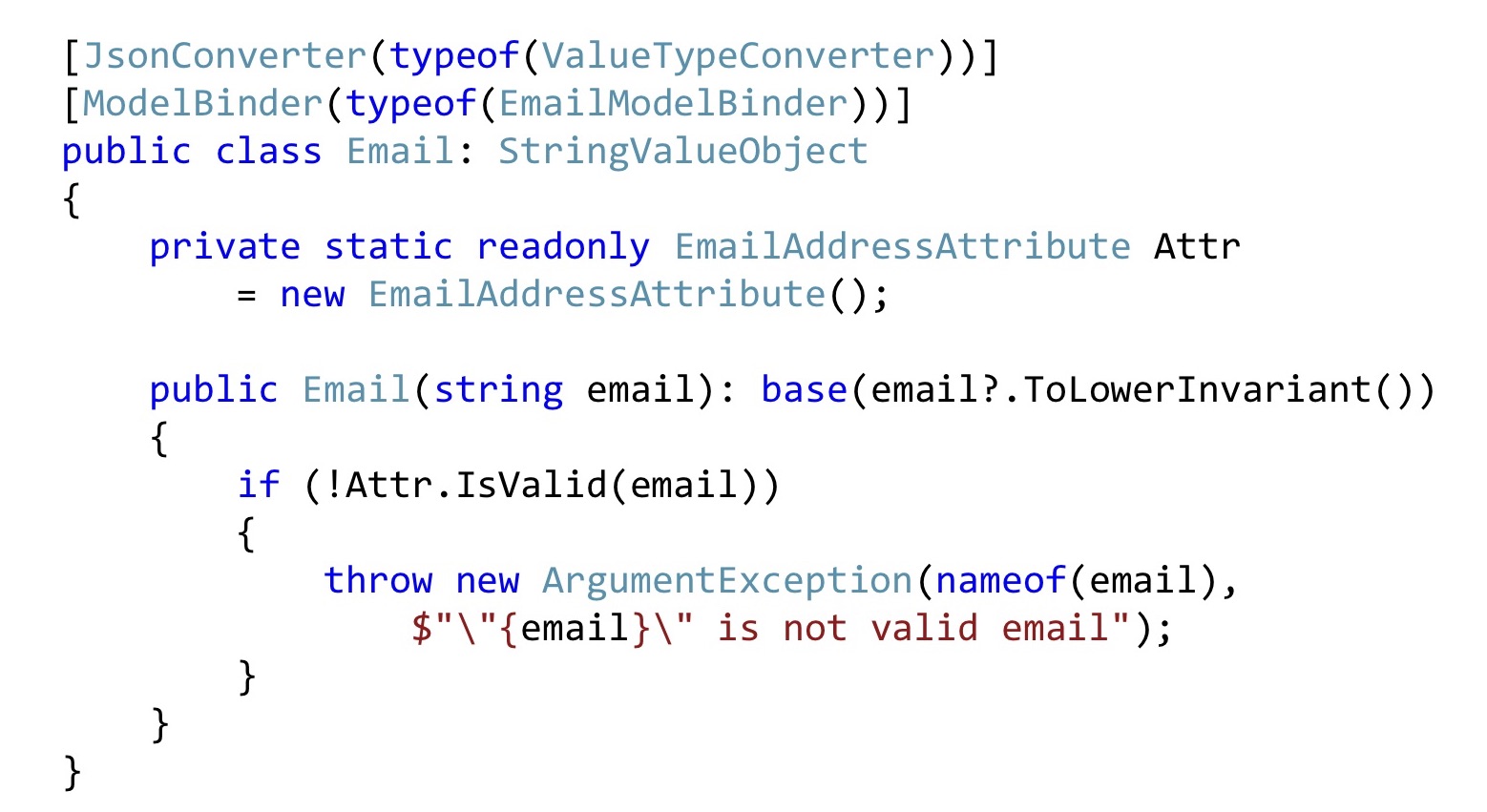
Wir machen das gleiche mit E-Mail. Konvertieren Sie alle E-Mails in das Endergebnis, damit für uns alles gleich aussieht. Als Nächstes nehmen wir das E-Mail-Attribut, deklarieren es aus Gründen der Kompatibilität mit der ASP.NET-Validierung als statisch und nennen es hier einfach. Das heißt, dies kann auch getan werden. Damit die ASP.NET-Infrastruktur all dies abfängt, müssen Sie die Serialisierung und / oder ModelBinding geringfügig ändern. Es gibt dort nicht viel Code, es ist relativ einfach, also werde ich hier nicht aufhören.
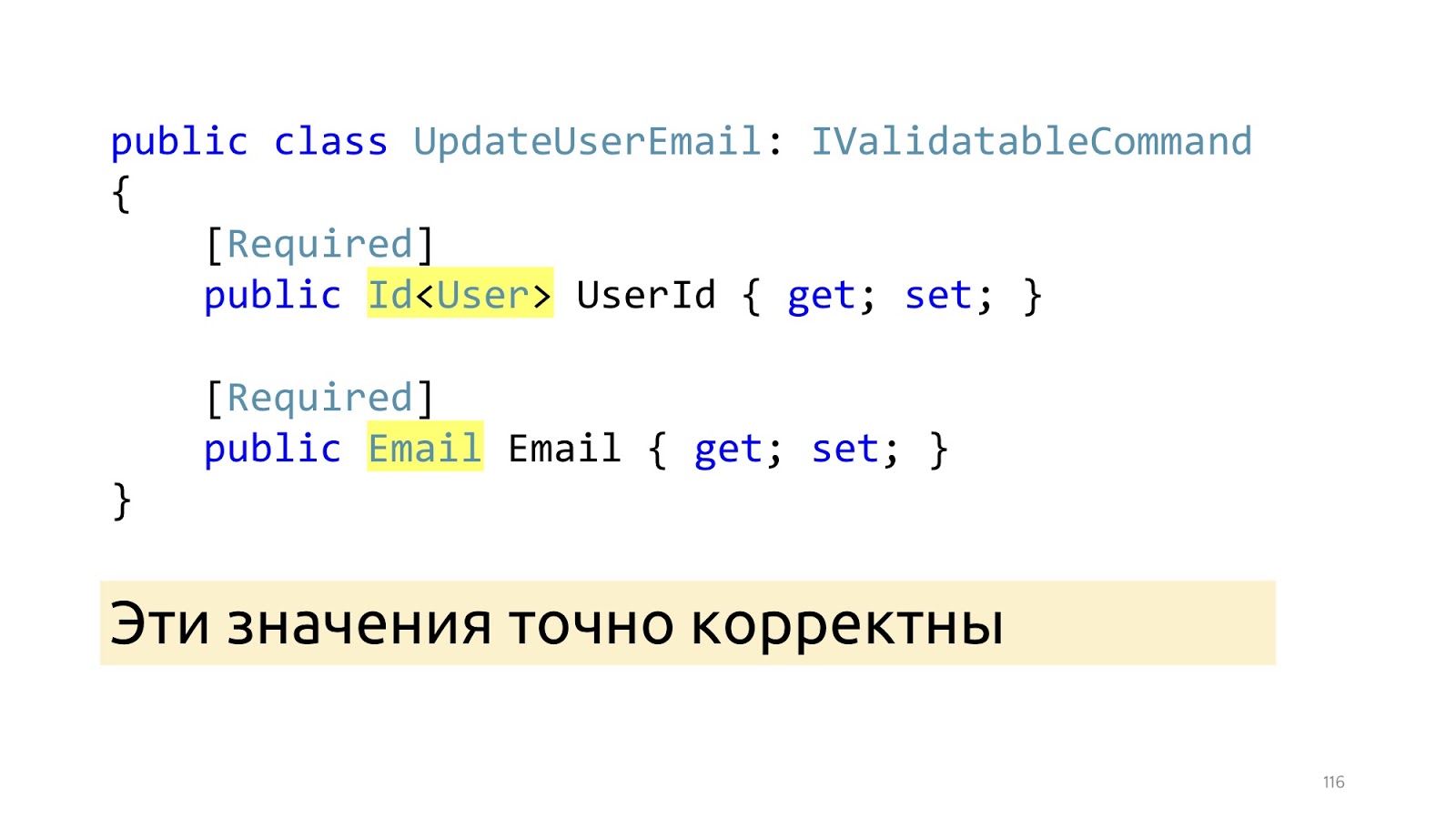
Nach diesen Änderungen werden hier anstelle primitiver Typen spezielle Typen angezeigt: ID und E-Mail. Und nachdem dieser ModelBinder und der aktualisierte Deserializer ausgearbeitet haben, wissen wir sicher, dass diese Werte korrekt sind, einschließlich der Tatsache, dass sich diese Werte in der Datenbank befinden. "Invarianten"

Der nächste Punkt, auf den ich näher eingehen möchte, ist der Zustand der Invarianten in der Klasse, da häufig ein
anämisches Modell verwendet wird, in dem es nur eine Klasse gibt, viele Getter-Setter. Es ist völlig unklar, wie sie zusammenarbeiten sollen. Wir arbeiten mit komplexer Geschäftslogik, daher ist es für uns wichtig, dass sich der Code selbst dokumentiert. Stattdessen ist es besser, den realen Konstruktor zusammen mit leer für ORM zu deklarieren. Er kann als geschützt deklariert werden, damit Programmierer in ihrem Anwendungscode ihn nicht aufrufen können und ORM. Hier übergeben wir nicht den primitiven Typ, sondern den E-Mail-Typ, er ist bereits korrekt korrekt. Wenn er null ist, lösen wir immer noch eine Ausnahme aus. Sie können Fody, PostSharp, verwenden, aber C # 8 wird bald verfügbar sein. Dementsprechend wird es einen Referenztyp geben, der nicht nullbar ist, und es ist besser, auf die Unterstützung in der Sprache zu warten. Wenn wir im nächsten Moment den Vor- und Nachnamen ändern möchten, möchten wir sie höchstwahrscheinlich gemeinsam ändern. Daher muss es eine geeignete öffentliche Methode geben, die sie gemeinsam ändert.

Bei dieser öffentlichen Methode überprüfen wir auch, ob die Länge dieser Zeilen mit der in der Datenbank verwendeten übereinstimmt. Und wenn etwas nicht stimmt, stoppen Sie die Ausführung. Hier benutze ich den gleichen Trick. Ich deklariere ein spezielles Attribut und rufe es einfach im Anwendungscode auf.
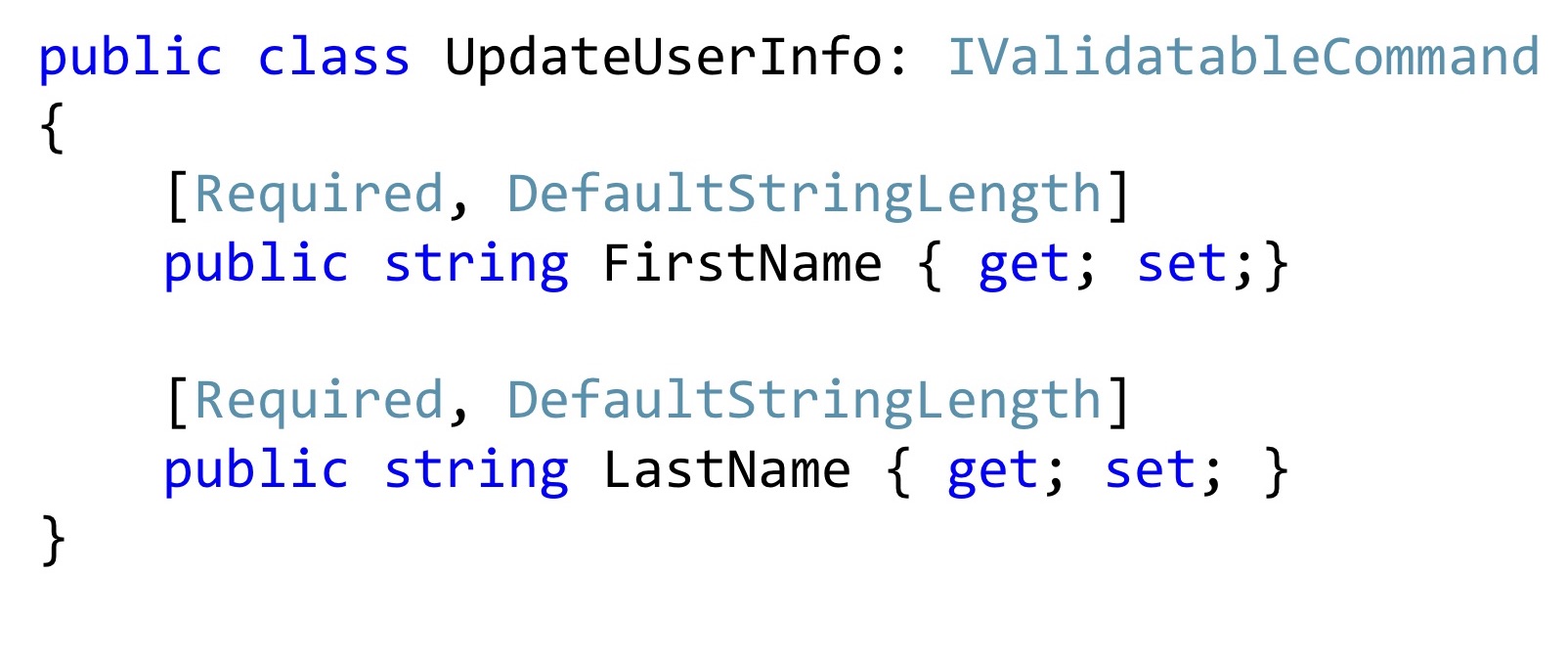
Darüber hinaus können solche Attribute in Dto wiederverwendet werden. Wenn ich nun den Vor- und Nachnamen ändern möchte, habe ich möglicherweise einen solchen Änderungsbefehl. Lohnt es sich, hier einen speziellen Konstruktor hinzuzufügen? Es scheint sich zu lohnen. Es wird besser werden, niemand wird diese Werte ändern, sie nicht brechen, sie werden genau richtig sein.

Eigentlich nicht wirklich. Tatsache ist, dass Dto überhaupt keine Objekte sind. Dies ist ein solches Wörterbuch, in das wir deserialisierte Daten einfügen. Das heißt, sie geben natürlich vor, Objekte zu sein, aber sie haben nur eine Verantwortung - sie müssen serialisiert und deserialisiert werden. Wenn wir versuchen, diese Struktur zu bekämpfen, werden wir einige ModelBinders mit Designern bekannt geben. So etwas zu tun ist unglaublich anstrengend und vor allem wird es mit neuen Versionen neuer Frameworks brechen. All dies wurde von Mark Simon in dem Artikel
"An den Grenzen des Programms sind nicht objektorientiert" gut beschrieben . Wenn es interessant ist, ist es besser, seinen Beitrag zu lesen, dort wird er ausführlich beschrieben.

Kurz gesagt, wir haben eine schmutzige Außenwelt, wir überprüfen den Eingang, konvertieren ihn in unser sauberes Modell und übertragen ihn dann wieder in die Serialisierung, in den Browser und wieder in die schmutzige Außenwelt.
Handler
Wie wird der Hander nach all diesen Änderungen hier aussehen?

Ich habe hier zwei Zeilen geschrieben, um das Lesen zu vereinfachen, aber im Allgemeinen kann es in einer geschrieben werden. Die Daten sind genau korrekt, da wir ein Typsystem haben, es gibt eine Validierung, dh die Daten sind Stahlbeton, Sie müssen sie nicht erneut überprüfen. Ein solcher Benutzer existiert auch, es gibt keinen anderen Benutzer mit einer so geschäftigen E-Mail, alles kann getan werden. Es gibt jedoch immer noch keinen Aufruf der SaveChanges-Methode, es gibt keine Benachrichtigung und es gibt keine Protokolle und Profiler, oder? Wir gehen weiter.
Ereignisse
Domänenereignisse.

Wahrscheinlich das erste Mal, dass dieses Konzept von Udi Dahan in seinem Beitrag
„Domain Events - Salvation“ populär gemacht wurde. Dort schlägt er vor, einfach eine statische Klasse mit der Raise-Methode zu deklarieren und solche Ereignisse auszulösen. Wenig später schlug Jimmy Bogard eine bessere Implementierung vor, die als
"Ein besseres Muster für Domänenereignisse" bezeichnet wird .
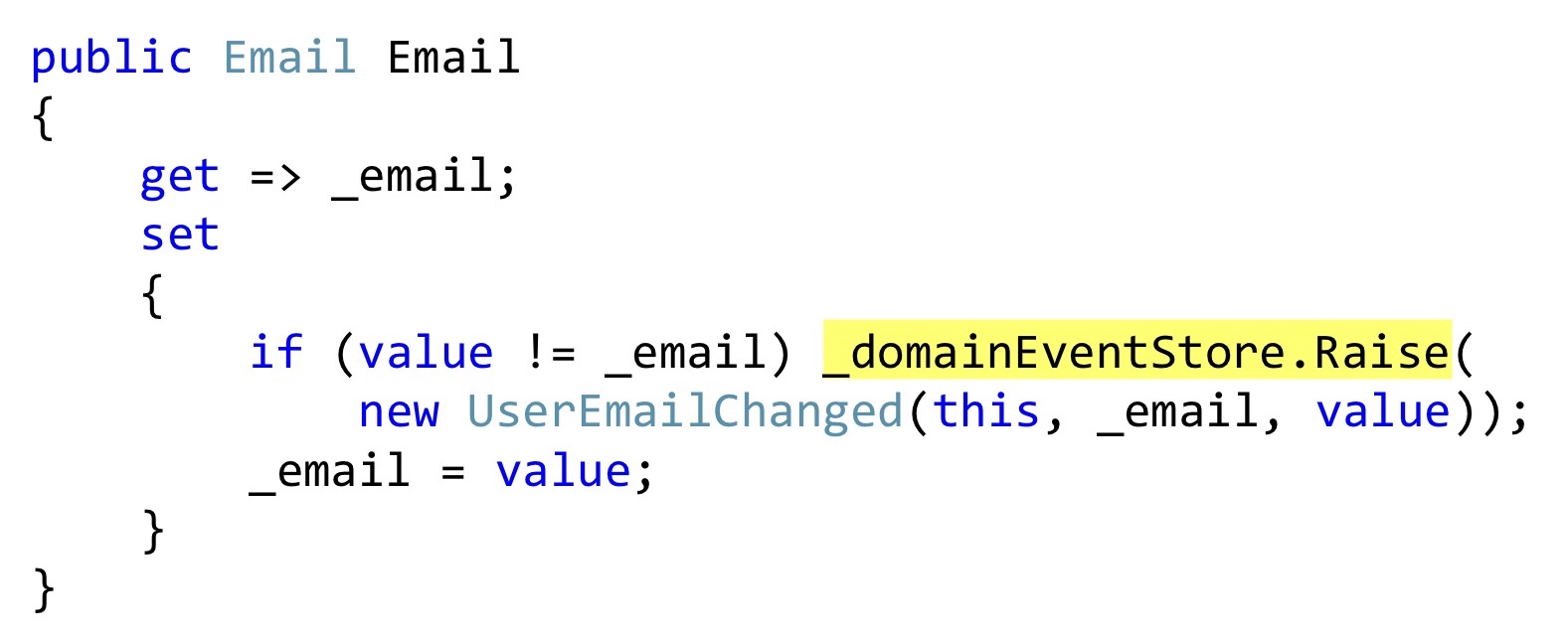
Ich werde die Serialisierung von Bogard mit einer kleinen, aber wichtigen Änderung zeigen. Anstatt Ereignisse auszulösen, können wir eine Liste deklarieren und an den Stellen, an denen eine Reaktion stattfinden sollte, direkt innerhalb der Entität, um diese Ereignisse zu speichern. In diesem Fall ist dieser
email Getter auch eine Benutzerklasse, und diese Klasse gibt nicht vor, eine Eigenschaft mit automatischen Gettern und Setzern zu sein, sondern fügt dem wirklich etwas hinzu. Das heißt, dies ist eine echte Verkapselung, keine Obszönität. Beim Ändern überprüfen wir, ob die E-Mail anders ist, und lösen ein Ereignis aus. Dieses Ereignis hat noch nirgendwo erreicht, wir haben es nur in der internen Liste der Entitäten.

In dem Moment, in dem wir die SaveChanges-Methode aufrufen, nehmen wir ChangeTracker und prüfen, ob es Entitäten gibt, die die Schnittstelle implementieren, ob sie Domänenereignisse haben. Wenn dies der Fall ist, nehmen wir alle diese Domänenereignisse und senden sie an einen Dispatcher, der weiß, was mit ihnen zu tun ist.
Die Implementierung dieses Dispatchers ist ein Thema für eine weitere Diskussion. Es gibt einige Schwierigkeiten beim Mehrfachversand in C #, dies wird jedoch auch durchgeführt. Bei diesem Ansatz gibt es einen weiteren nicht offensichtlichen Vorteil. Wenn wir jetzt zwei Entwickler haben, kann einer Code schreiben, der diese E-Mail ändert, und der andere kann ein Benachrichtigungsmodul ausführen. Sie sind absolut nicht miteinander verbunden, sie schreiben unterschiedlichen Code, sie sind nur auf der Ebene dieses Domänenereignisses einer Dto-Klasse verbunden. Der erste Entwickler wirft diese Klasse einfach irgendwann weg, der zweite antwortet darauf und weiß, dass sie per E-Mail, SMS, Push-Benachrichtigungen an das Telefon und alle anderen Millionen Benachrichtigungen gesendet werden muss, wobei alle normalerweise auftretenden Benutzereinstellungen berücksichtigt werden.
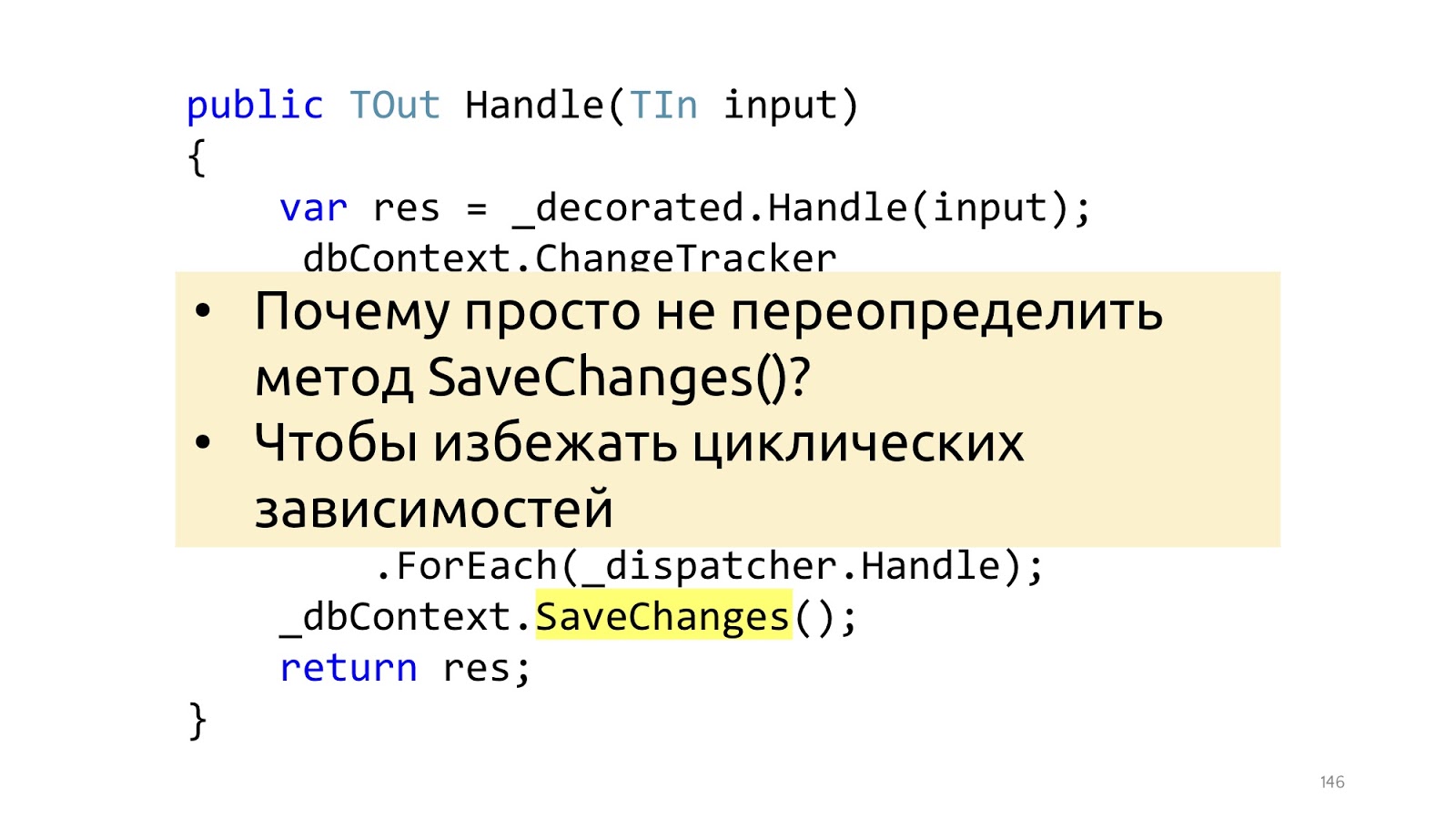
Hier ist der kleinste, aber wichtige Punkt. Jimmys Artikel verwendet eine Überladung der SaveChanges-Methode, und es ist am besten, dies nicht zu tun. Und es ist besser, dies im Dekorator zu tun, denn wenn wir die SaveChanges-Methode überladen und dbContext in Handler benötigen, erhalten wir zirkuläre Abhängigkeiten. Sie können damit arbeiten, aber die Lösungen sind etwas weniger bequem und etwas weniger schön. Wenn die Pipeline auf Dekorateuren basiert, sehe ich keinen Grund, dies anders zu machen.
Protokollierung und Profilerstellung

Die Verschachtelung des Codes blieb erhalten, aber im ersten Beispiel hatten wir zuerst MiniProfiler verwendet, dann Catch und dann If. Insgesamt gab es drei Verschachtelungsebenen, jetzt befindet sich jede dieser Verschachtelungsebenen in einem eigenen Dekorateur. Und innerhalb des Dekorateurs, der für die Profilerstellung verantwortlich ist, haben wir nur eine Verschachtelungsebene, der Code wird perfekt gelesen. Darüber hinaus ist klar, dass es bei diesen Dekorateuren nur eine Verantwortung gibt. Wenn der Dekorateur für die Protokollierung verantwortlich ist, protokolliert er nur, wenn für die Profilerstellung bzw. nur das Profil alles andere an anderen Orten ist.
Antwort
Nachdem die gesamte Pipeline funktioniert hat, können wir nur Dto nehmen und weiter an den Browser senden und JSON serialisieren.
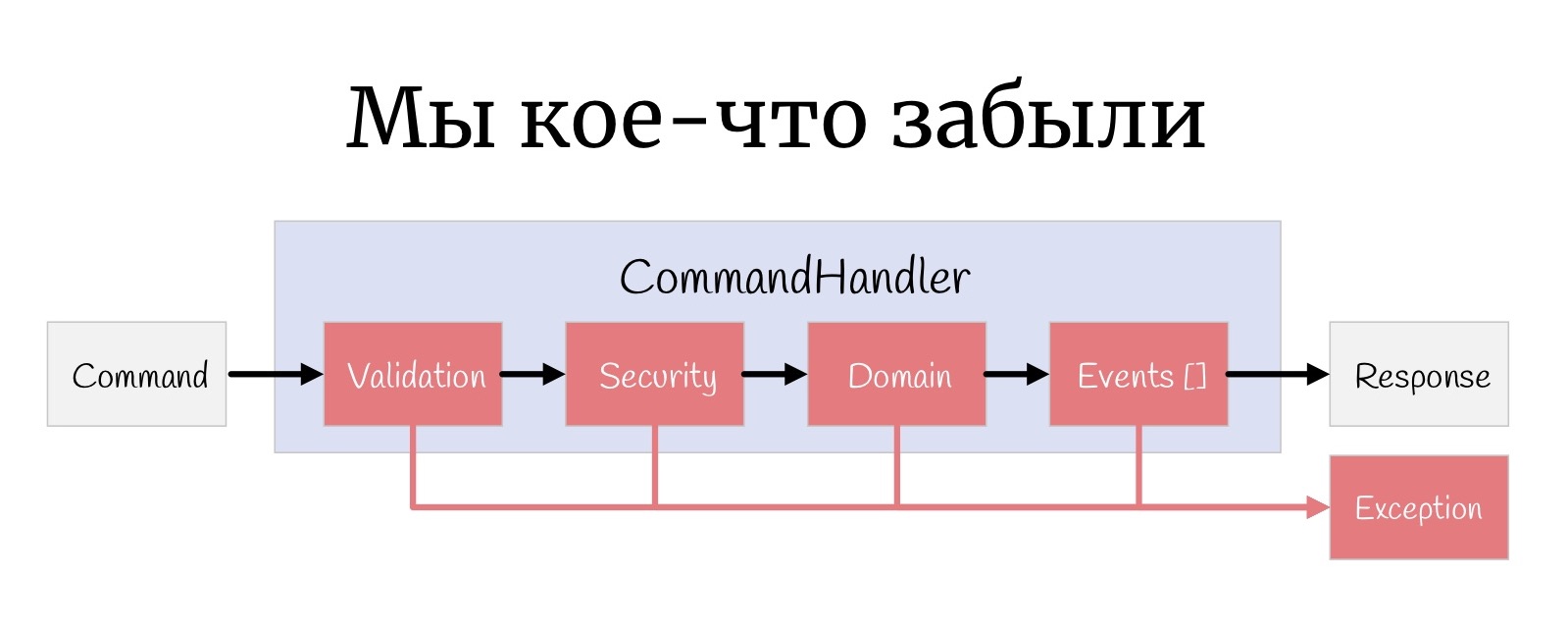
Aber noch eine kleine Sache, die manchmal vergessen wird: In jeder Phase kann hier eine Ausnahme passieren, und tatsächlich muss man irgendwie damit umgehen.

Ich kann Scott Vlashin und seinen Bericht
„Eisenbahnorientierte Programmierung“ hier noch einmal erwähnen. Warum? Der ursprüngliche Bericht widmet sich ausschließlich der Arbeit mit Fehlern in der F # -Sprache, der etwas anderen Organisation des Ablaufs und der Frage, warum ein solcher Ansatz der Verwendung von Exception'ov vorzuziehen ist. In F # funktioniert dies wirklich sehr gut, da F # eine funktionale Sprache ist und Scott die Funktionalität einer funktionalen Sprache verwendet.

Da wahrscheinlich die meisten von Ihnen immer noch in C # schreiben, sieht dieser Ansatz ungefähr so aus, wenn Sie
ein Analogon in C # schreiben. Anstatt Ausnahmen auszulösen, deklarieren wir eine Ergebnisklasse mit einem erfolgreichen und einem nicht erfolgreichen Zweig. Dementsprechend zwei Designer. Eine Klasse kann sich nur in einem Zustand befinden. Diese Klasse ist ein Sonderfall vom Typ Union, der von F # unterschieden wird, jedoch in C # neu geschrieben wurde, da in C # keine integrierte Unterstützung vorhanden ist.

Anstatt öffentliche Getter zu deklarieren, dass jemand im Code möglicherweise nicht auf Null prüft, wird Pattern Matching verwendet. Wiederum wäre es in F # eine integrierte Pattern Matching-Sprache. In C # müssen wir eine separate Methode schreiben, in die wir eine Funktion übergeben, die weiß, was mit dem erfolgreichen Ergebnis der Operation zu tun ist, wie sie weiter unten in der Kette konvertiert wird und die mit einem Fehler. Das heißt, egal welcher Zweig für uns gearbeitet hat, wir müssen dies auf ein einziges zurückgegebenes Ergebnis umstellen. In F # funktioniert das alles sehr gut, weil es eine funktionale Komposition gibt, und alles andere, was ich bereits aufgelistet habe. In .NET funktioniert dies etwas schlechter, da sobald Sie mehr als ein Ergebnis haben, aber viele - und fast jede Methode kann aus dem einen oder anderen Grund fehlschlagen - fast alle resultierenden Funktionstypen zu Ergebnistypen werden und Sie sie als benötigen etwas kombinieren.

Der einfachste Weg, sie zu kombinieren, ist die
Verwendung von LINQ , da LINQ tatsächlich nicht nur mit IEnumerable funktioniert. Wenn Sie die Methoden SelectMany und Select richtig neu definieren, erkennt der C # -Compiler, dass Sie die LINQ-Syntax für diese Typen verwenden können. Im Allgemeinen stellt sich heraus, dass Transparentpapier mit Haskell-Notation oder mit denselben Berechnungsausdrücken in F # erstellt wurde. Wie soll das gelesen werden? Hier haben wir drei Ergebnisse der Operation, und wenn dort in allen drei Fällen alles in Ordnung ist, nehmen Sie diese Ergebnisse r1 + r2 + r3 und fügen Sie sie hinzu. Der Typ des resultierenden Werts ist ebenfalls Ergebnis, aber das neue Ergebnis, das wir in Select deklarieren. Im Allgemeinen ist dies sogar ein funktionierender Ansatz, wenn nicht einer, aber.

Für alle anderen Entwickler sieht es so aus, sobald Sie anfangen, solchen Code in C # zu schreiben. „Das sind böse beängstigende Ausnahmen, schreib sie nicht! Sie sind böse! Schreiben Sie besser Code, den niemand versteht und der nicht debuggen kann! “

C # ist nicht F #, es ist etwas anders, es gibt keine unterschiedlichen Konzepte, auf deren Grundlage dies getan wird, und wenn wir versuchen, eine Eule auf den Globus zu ziehen, stellt sich heraus, gelinde gesagt, ungewöhnlich.

Stattdessen können Sie die
integrierten normalen Tools verwenden , die dokumentiert sind, die jeder kennt und die bei Entwicklern keine kognitiven Dissonanzen verursachen. ASP.NET hat eine globale Handler-Ausnahme.

Wir wissen, dass Sie bei Problemen mit der Validierung den Code 400 oder 422 (Unprocessable Entity) zurückgeben müssen. Wenn bei der Authentifizierung und Autorisierung ein Problem auftritt, gibt es 401 und 403. Wenn ein Fehler aufgetreten ist, ist ein Fehler aufgetreten. Und wenn etwas schief gelaufen ist und Sie dem Benutzer genau mitteilen möchten, was ist, definieren Sie Ihren Ausnahmetyp, sagen Sie, dass es sich um IHasUserMessage handelt, deklarieren Sie einen Nachrichten-Getter in dieser Schnittstelle und überprüfen Sie einfach: Wenn diese Schnittstelle implementiert ist, können Sie eine Nachricht entgegennehmen von Ausnahme und übergeben Sie es in JSON an den Benutzer. Wenn diese Schnittstelle nicht implementiert ist, liegt ein Systemfehler vor, und wir teilen den Benutzern einfach mit, dass ein Fehler aufgetreten ist. Wir alle tun dies bereits, wir alle wissen - wie immer.
Abfrage-Pipeline
Wir schließen dies mit den Teams ab und schauen uns an, was wir im Read-Stack haben. Was die Anfrage, Validierung und direkte Antwort betrifft - dies ist ungefähr dasselbe, wir werden nicht separat aufhören. Möglicherweise gibt es noch einen zusätzlichen Cache, aber im Allgemeinen gibt es auch keine großen Probleme mit dem Cache.
Sicherheit
Schauen wir uns eine Sicherheitsüberprüfung genauer an. Möglicherweise gibt es auch denselben Sicherheitsdekorateur, der prüft, ob diese Anforderung gestellt werden kann oder nicht:

Es gibt jedoch einen anderen Fall, in dem wir mehr als einen Datensatz und eine Liste anzeigen. Für einige Benutzer müssen wir eine vollständige Liste anzeigen (z. B. für einige Superadministratoren), und für andere Benutzer müssen wir begrenzte Listen auflisten, dritte - begrenzte Nun, und wie es in Unternehmensanwendungen häufig der Fall ist, können Zugriffsrechte äußerst komplex sein. Sie müssen also sicherstellen, dass Daten, die nicht auf diese Benutzer abzielen, nicht in diese Listen aufgenommen werden.
Das Problem ist
ganz einfach gelöst. Wir können die Schnittstelle (IPermissionFilter) neu definieren, in die das ursprüngliche abfragbare Element eintrifft und das abfragbare zurückgibt. Der Unterschied besteht darin, dass wir für die Rückgabe, die zurückgibt, bereits zusätzliche Bedingungen festgelegt haben, bei denen der aktuelle Benutzer überprüft und gesagt wurde: "Hier nur diese Daten an diesen Benutzer zurückgeben ..." - und dann Ihre gesamte Logik, die sich auf Berechtigungen bezieht . Wenn Sie zwei Programmierer haben, schreibt ein Programmierer Berechtigungen. Er weiß, dass er nur viele Berechtigungsfilter schreiben und überprüfen muss, ob sie für alle Entitäten ordnungsgemäß funktionieren. Und andere Programmierer wissen nichts über Berechtigungen, in ihrer Liste werden einfach immer die richtigen Daten übergeben, das ist alles. Weil sie an der Eingabe nicht mehr das ursprünglich von dbContext abfragbare empfangen, sondern auf Filter beschränkt sind. Ein solcher Berechtigungsfilter hat auch eine Layout-Eigenschaft. Wir können alle Berechtigungsfilter hinzufügen und anwenden. Als Ergebnis erhalten wir den resultierenden Berechtigungsfilter, der die Datenauswahl unter Berücksichtigung aller für diese Entität geeigneten Bedingungen auf das Maximum einschränkt.

Warum nicht mit integrierten ORM-Tools, z. B. globalen Filtern in einem Entitätsframework? Auch hier, um keine zyklischen Abhängigkeiten für sich selbst herzustellen und keine zusätzliche Geschichte über Ihre Geschäftsschicht in den Kontext zu ziehen.
Abfrage-Pipeline. Modell lesen
Es bleibt das Lesemodell zu betrachten. Das CQRS-Paradigma verwendet nicht das Domänenmodell im Lesestapel, sondern erstellt sofort das Dto, das der Browser gerade benötigt.

Wenn wir in C # schreiben, verwenden wir höchstwahrscheinlich LINQ, wenn es nicht nur ungeheure Leistungsanforderungen gibt und wenn es welche gibt, haben Sie möglicherweise keine Unternehmensanwendung. Im Allgemeinen kann dieses Problem mit einem solchen LinqQueryHandler ein für alle Mal gelöst werden. Hier ist eine ziemlich beängstigende Einschränkung für das Generikum: Dies ist Query, das eine Liste von Projektionen zurückgibt und diese Projektionen weiterhin filtern und diese Projektionen sortieren kann. Sie arbeitet auch nur mit einigen Arten von Entitäten und weiß, wie diese Entitäten in Projektionen konvertiert und die Liste solcher Projektionen in Form von Dto an den Browser zurückgegeben werden.

Die Implementierung der Handle-Methode kann recht einfach sein. Überprüfen Sie für alle Fälle, ob dieser TQuery-Filter für die ursprüngliche Entität implementiert ist. Weiter machen wir eine Projektion, es ist abfragbare Erweiterung AutoMapper'a. Wenn jemand es immer noch nicht weiß, kann AutoMapper Projektionen in LINQ erstellen, dh solche, die die Select-Methode erstellen und nicht im Speicher zuordnen.
Dann wenden wir Filterung, Sortierung an und zeigen alles im Browser an. , DotNext, ,
, , , , expression' , .
. , DotNext', — SQL. Select , , , queryable- .
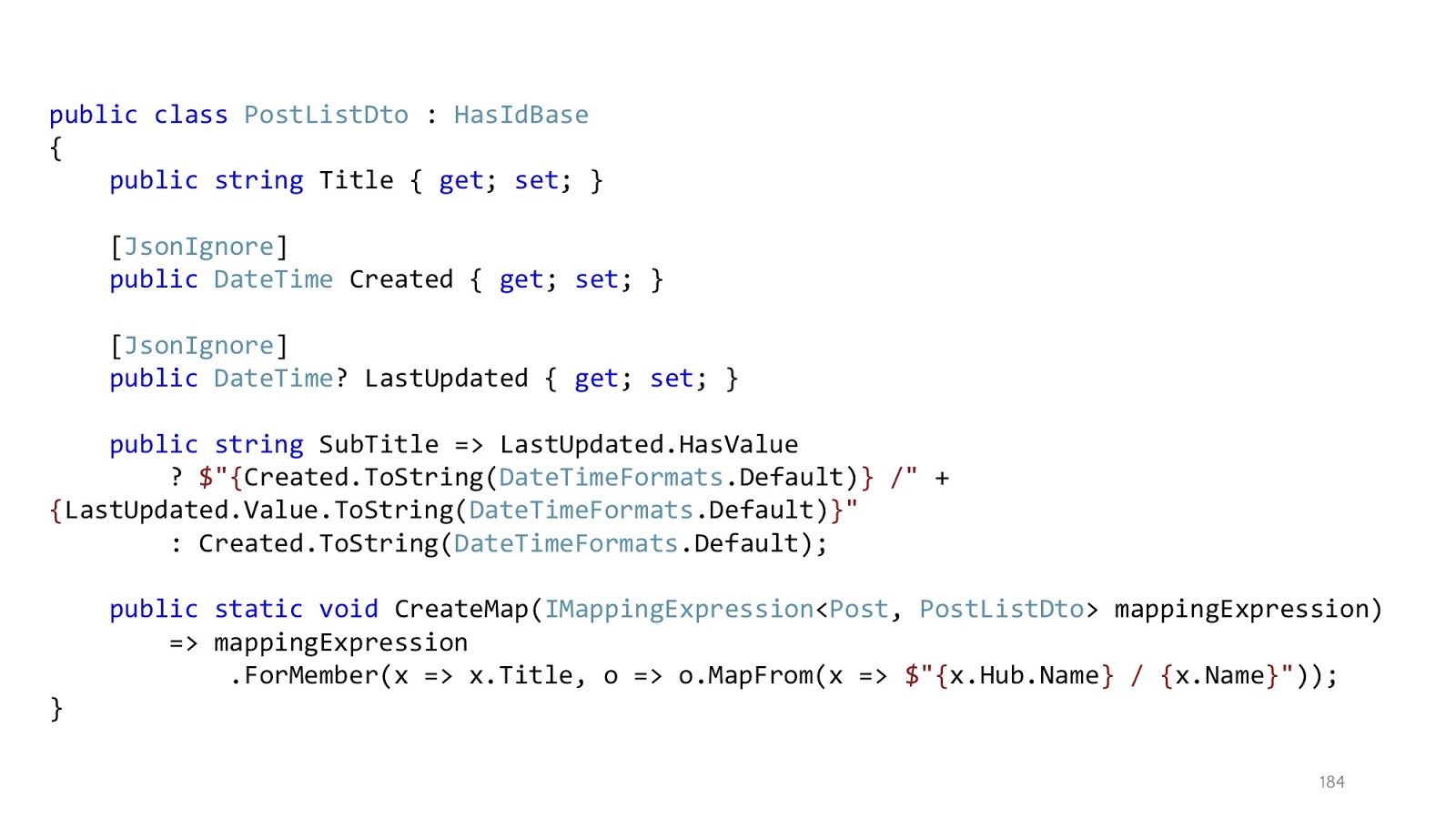
, . , Title, Title , . , . SubTitle, , , - , queryable- . , .
, . , , . , , . «JsonIgnore», . , , Dto. , , . JSON, , Created LastUpdated , SubTitle — , . , , , , , . , - .

. , -, , . , pipeline, . — , , . , SaveChanges, Query SaveChanges. , , , NuGet, .
. , - , , . , , , , , — . , , : « », — . .
, ?

- . .

, , , . MediatR , . , , — , MediatR pipeline behaviour. , Request/Response, RequestHandler' . Simple Injector, — .

, , , , TIn: ICommand.

Simple Injector' constraint' . , , , constraint', Handler', constraint. , constraint ICommand, SaveChanges constraint' ICommand, Simple Injector , constraint' , Handler'. , , , .
? Simple Injector MeriatR — , , Autofac', -, , , . , .
,
, «».
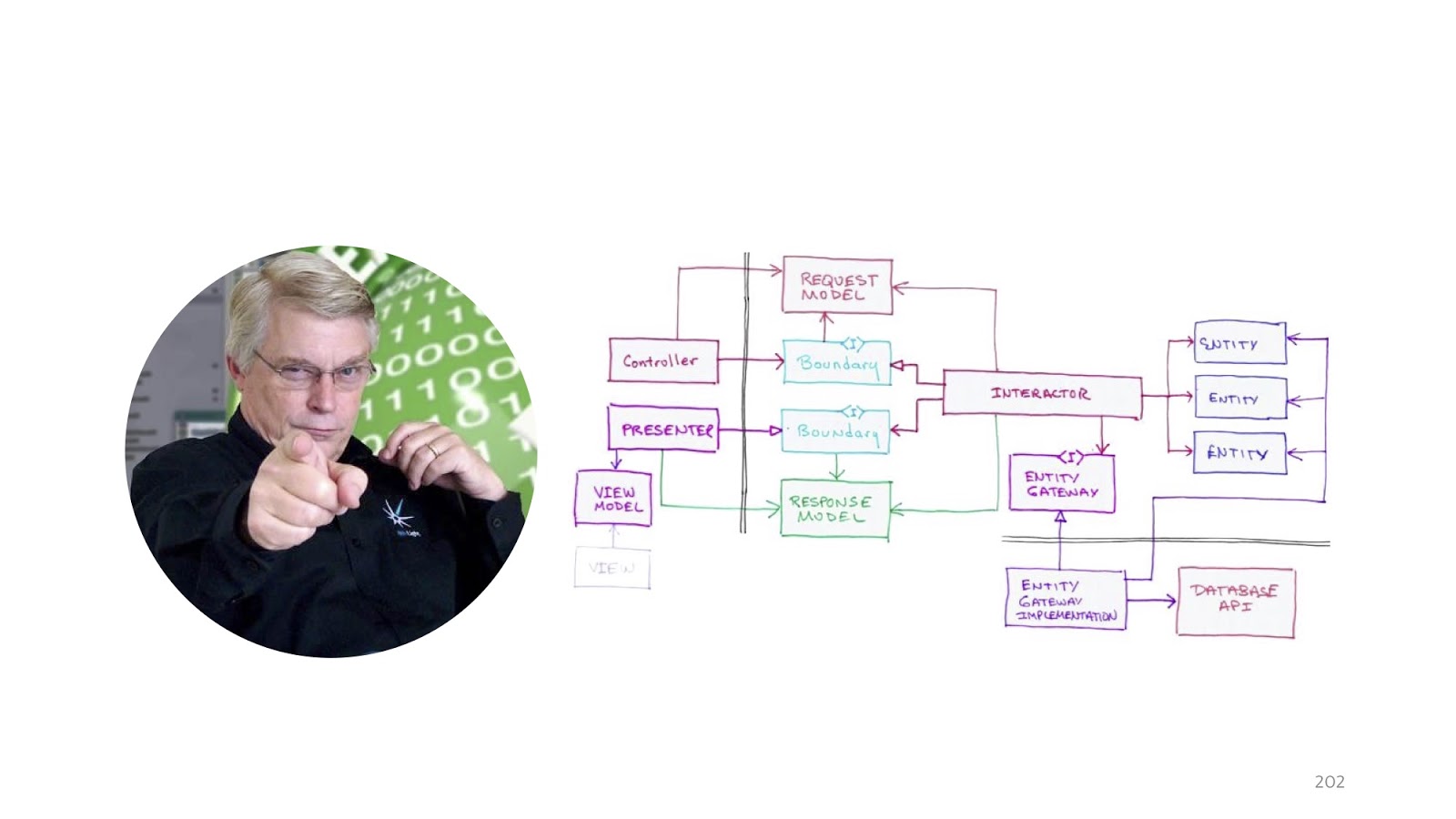
, «Clean architecture». .

- - , MVC, , .

, , , Angular, , , , . , : « — MVC-», : « Features, : , Blog - Import, - ».
, , , , MVC-, , - , . MVC . , , — . .


- , - -, .
-, , . , . , - , User Service, pull request', , User Service , . , - , - , . - , .
. , . , , , . , , , , , , , - . , ( , ), , «Delete»: , , . .
— «», , , , . , : , , , . , . , , . , , .
: . « », : , , . , , , , , , , . , . , - pull request , — , — - , . VCS : - , ? , - , , .

, , , . : . , . , , , , . , , , . , , . « », , . , , — , , .
: , - , . . - , , , , . - , - , , , , . .

. , IHandler . .
IHandler ICommandHandler IQueryHandler , . , , . , CommandHandler, CommandHandler', .
Warum so? , Query , Query — . , , , Hander, CommandHandler QueryHandler, - use case, .
— , , , , : , .
, . , . , -.
C# 8, nullable reference type . , , , , .
ChangeTracker' ORM.
Exception' — , F#, C#. , - , - , . , , Exception', , LINQ, , , , , , Dapper - , , , .NET.
, LINQ, , permission' — . , , - , , . , — .
. :
- Vertical Slices
- Domain Events
- DDD
- ROP
- LINQ Expressions:
- Clean Architecture

— . . — «Domain Modeling Made Functional», F#, F#, , , , , . C# , , Exception'.
, , — «Entity Framework Core In Action». , Entity Framework, , DDD ORM, , ORM DDD .
Minute der Werbung. 15-16 2019 .NET- DotNext Piter, . , .