Ich habe Kube Eagle gegründet - einen Exporteur von Prometheus. Es stellte sich als coole Sache heraus, die hilft, die Ressourcen kleiner und mittlerer Cluster besser zu verstehen. Infolgedessen habe ich mehr als einhundert Dollar gespart, weil ich die richtigen Maschinentypen ausgewählt und Anwendungsressourcenlimits für Workloads konfiguriert habe.
Ich werde über die Vorteile des Kube Eagle sprechen, aber zuerst werde ich erklären, warum die Aufregung aufkam und warum eine qualitativ hochwertige Überwachung erforderlich war.
Ich habe mehrere Cluster von 4-50 Knoten verwaltet. In jedem Cluster - bis zu 200 Microservices und Anwendungen. Um die verfügbare Hardware besser nutzen zu können, wurden die meisten Bereitstellungen mit Burstable-RAM- und CPU-Ressourcen konfiguriert. Pods können also bei Bedarf verfügbare Ressourcen in Anspruch nehmen und gleichzeitig andere Anwendungen auf diesem Knoten nicht beeinträchtigen. Ist es nicht großartig?
Und obwohl der Cluster relativ wenig CPU (8%) und RAM (40%) verbrauchte, hatten wir ständig Probleme mit der Verdrängung von Herden, wenn versucht wurde, mehr Speicher zuzuweisen, als auf dem Knoten verfügbar ist. Dann hatten wir nur ein Dashboard zur Überwachung der Kubernetes-Ressourcen. Hier ist einer:
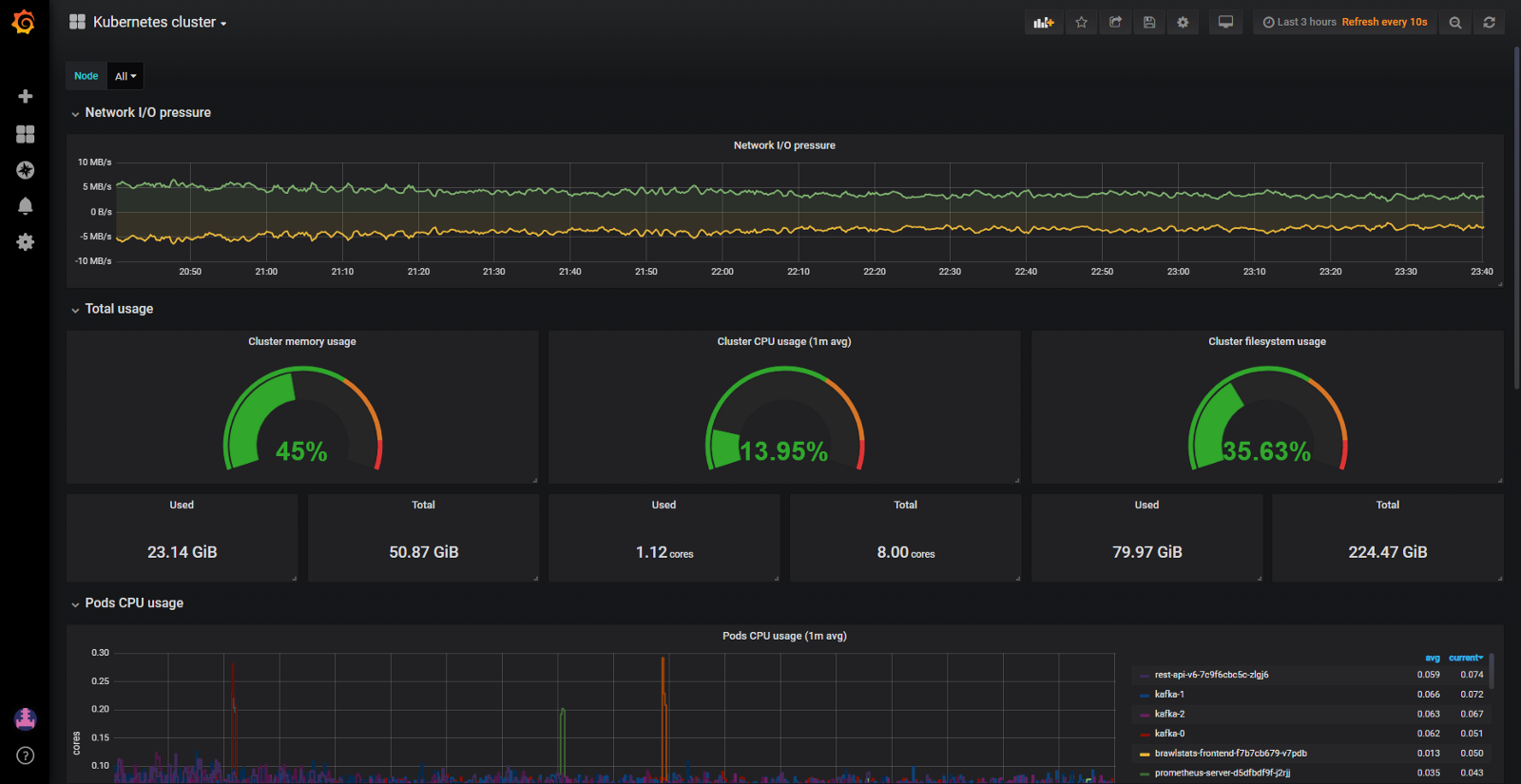
Grafana-Dashboard nur mit cAdvisor-Metriken
Mit einem solchen Panel sind die Knoten, die viel Speicher und CPU verbrauchen, kein Problem. Das Problem ist, den Grund herauszufinden. Um die Pods an Ort und Stelle zu halten, können Sie natürlich garantierte Ressourcen für alle Pods konfigurieren (die angeforderten Ressourcen entsprechen dem Limit). Dies ist jedoch nicht die klügste Verwendung von Eisen. Es gab mehrere hundert Gigabyte Speicher im Cluster, während einige Knoten hungerten, während andere 4-10 GB Reserve hatten.
Es stellt sich heraus, dass der Kubernetes-Scheduler die Workloads ungleichmäßig auf die verfügbaren Ressourcen verteilt hat. Der Kubernetes Scheduler berücksichtigt verschiedene Konfigurationen: Affinitäts-, Verschmutzungs- und Toleranzregeln, Knotenselektoren, die die verfügbaren Knoten einschränken können. In meinem Fall gab es jedoch nichts Vergleichbares, und die Pods wurden abhängig von den angeforderten Ressourcen auf jedem Knoten geplant.
Für den Herd wurde ein Knoten ausgewählt, der über die meisten freien Ressourcen verfügt und die Anforderungsbedingungen erfüllt. Es stellte sich heraus, dass die angeforderten Ressourcen auf den Knoten nicht mit der tatsächlichen Verwendung übereinstimmen, und hier kamen Kube Eagle und seine Fähigkeit zur Überwachung von Ressourcen zur Rettung.
Ich habe fast alle Kubernetes-Cluster nur mit Node Exporter und Kube State Metrics verfolgt . Node Exporter bietet Statistiken zur E / A- und Festplatten-, CPU- und RAM-Auslastung, und Kube State Metrics zeigt Kubernetes-Objektmetriken an, z. B. Anforderungen und Einschränkungen für CPU- und Speicherressourcen.
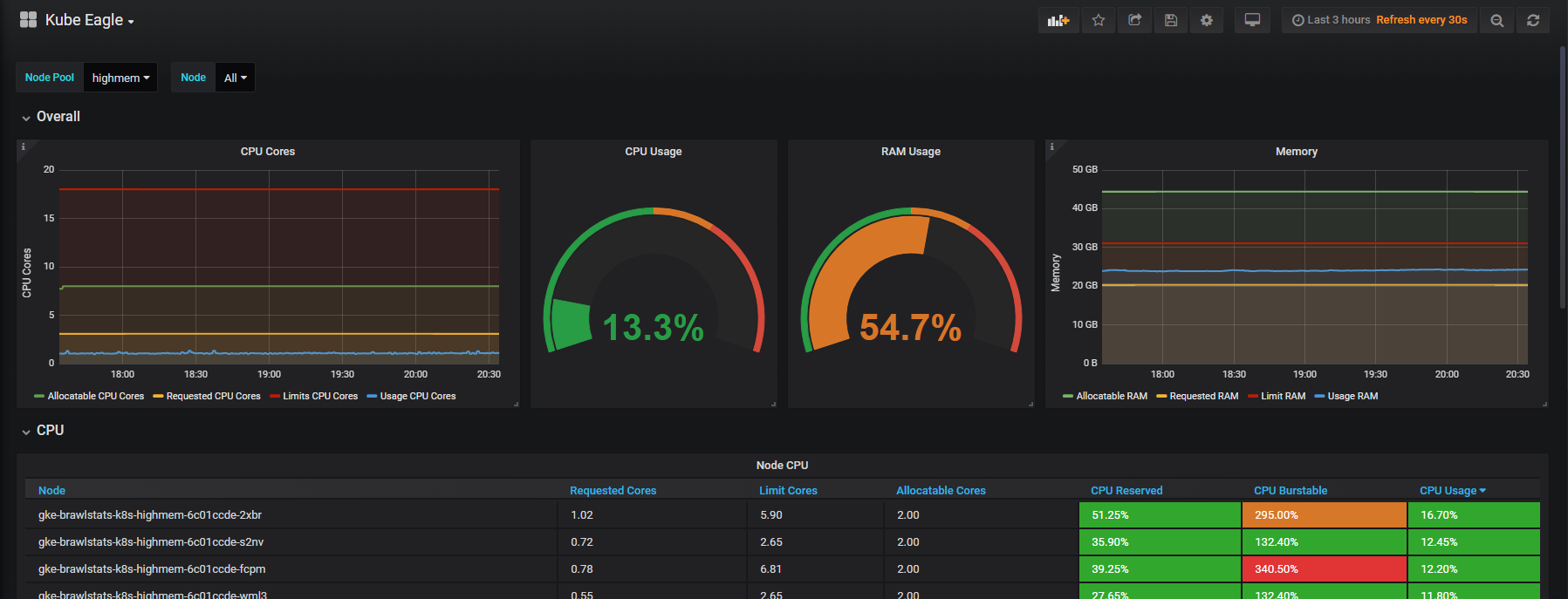
Wir müssen die Nutzungsmetriken mit den Anforderungs- und Grenzwertmetriken in Grafana kombinieren, und dann erhalten wir alle Informationen über das Problem. Es klingt einfach, aber tatsächlich werden die Beschriftungen in diesen beiden Tools unterschiedlich aufgerufen, und einige Metriken haben überhaupt keine Metadatenbeschriftungen. Kube Eagle macht alles alleine und das Panel sieht so aus:
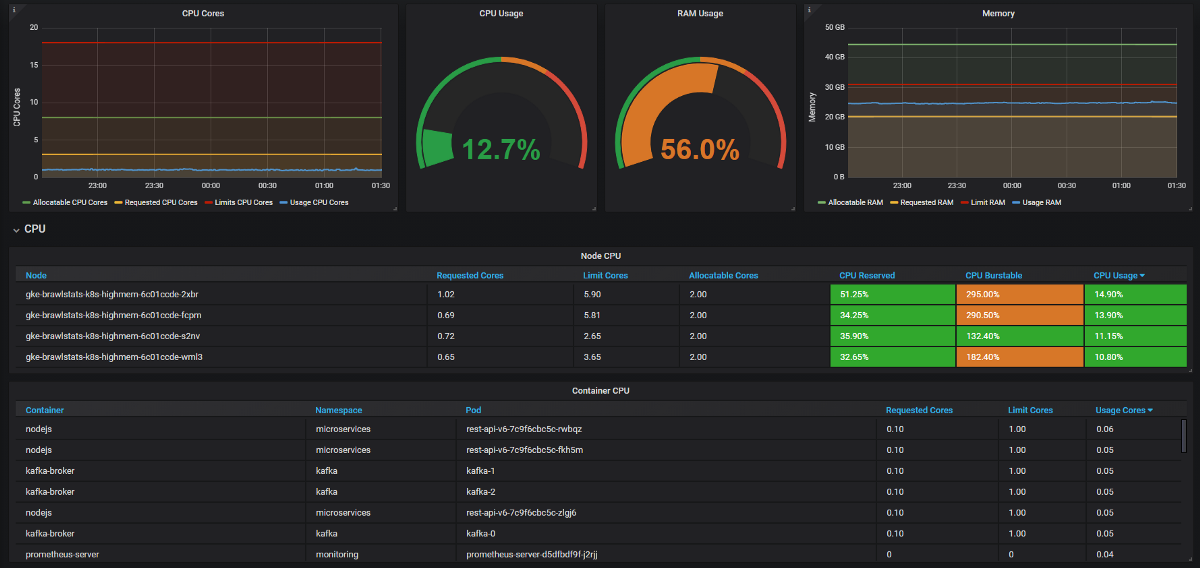
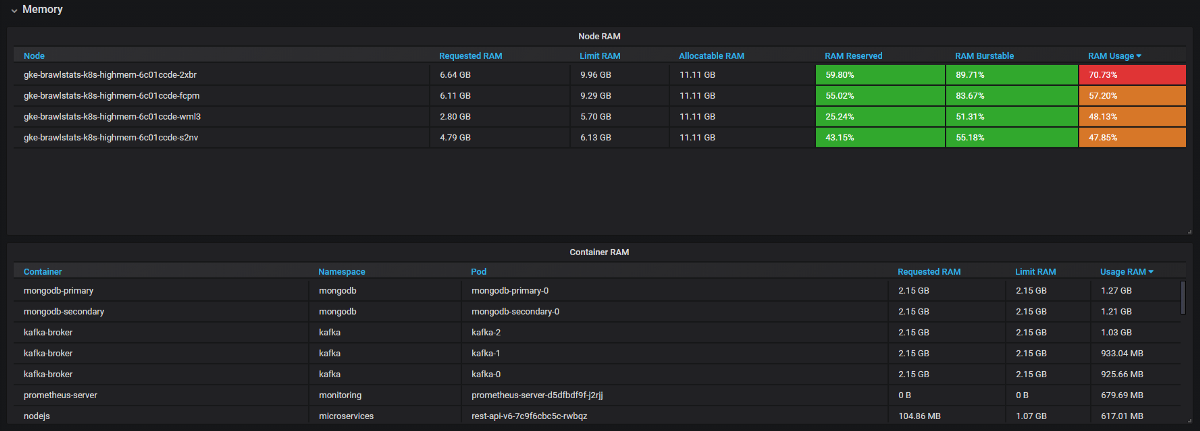
Kube Eagle Dashboard
Wir haben es geschafft, viele Probleme mit Ressourcen zu lösen und Ausrüstung zu sparen:
- Einige Entwickler wussten nicht, wie viele Ressourcen Microservices benötigten (oder kümmerten sich einfach nicht darum). Wir hatten nichts, um die falschen Anfragen nach Ressourcen zu finden - dafür müssen wir den Verbrauch plus Anfragen und Grenzen kennen. Jetzt sehen sie Prometheus-Metriken, überwachen die tatsächliche Nutzung und optimieren Abfragen und Grenzwerte.
- JVM-Anwendungen benötigen so viel RAM wie sie benötigen. Der Garbage Collector gibt nur dann Speicher frei, wenn mehr als 75% beteiligt sind. Und da die meisten Dienste über einen platzbaren Speicher verfügen, hat die JVM diesen immer belegt. Daher verbrauchten alle diese Java-Dienste viel mehr RAM als erwartet.
- Einige Anwendungen forderten zu viel Speicher an, und der Kubernetes-Scheduler gab diese Knoten nicht an andere Anwendungen weiter, obwohl sie tatsächlich freier waren als andere Knoten. Ein Entwickler fügte der Anfrage versehentlich eine zusätzliche Ziffer hinzu und griff nach einem großen Stück RAM: 20 GB statt 2. Niemand bemerkte es. Die Anwendung hatte 3 Replikate, sodass 3 Knoten betroffen waren.
- Wir haben Ressourcenlimits eingeführt, die Pods mit den richtigen Anforderungen neu geplant und das perfekte Gleichgewicht zwischen der Verwendung von Eisen über alle Knoten hinweg erzielt. Im Allgemeinen können einige Knoten geschlossen werden. Und dann haben wir gesehen, dass wir die falschen Maschinen hatten (CPU-orientiert, nicht speicherorientiert). Wir haben den Typ geändert und einige weitere Knoten gelöscht.
Zusammenfassung
Mit platzbaren Ressourcen in einem Cluster können Sie vorhandene Hardware effizienter nutzen, aber der Kubernetes-Scheduler plant Pods für Ressourcenanforderungen, was sehr umfangreich ist. Um zwei Fliegen mit einer Klappe zu schlagen: Um Probleme zu vermeiden und die Ressourcen optimal zu nutzen, ist eine gute Überwachung erforderlich. Hierfür ist Kube Eagle (Prometheus-Exporteur und Grafana-Dashboard) nützlich.