Von Februar bis März 2019 fand ein Wettbewerb zur Rangfolge des sozialen Netzwerk-Feeds SNA Hackathon 2019 statt , bei dem unser Team den ersten Platz belegte. In diesem Artikel werde ich über die Organisation des Wettbewerbs, die Methoden, die wir ausprobiert haben, und die Catboost-Einstellungen für das Training mit Big Data sprechen.

SNA Hackathon
Der Hackathon unter diesem Namen findet zum dritten Mal statt. Es wird vom sozialen Netzwerk ok.ru organisiert, wobei die Aufgabe und die Daten in direktem Zusammenhang mit diesem sozialen Netzwerk stehen.
SNA (Social Network Analysis) wird in diesem Fall besser nicht als Analyse eines sozialen Graphen verstanden, sondern als Analyse eines sozialen Netzwerks.
- Im Jahr 2014 bestand die Aufgabe darin, die Anzahl der Likes vorherzusagen, die der Beitrag gewinnen würde.
- Im Jahr 2016 nähert sich das Ziel des VVZ (vielleicht kennen Sie es) der Analyse des sozialen Graphen.
- Im Jahr 2019 - Rangfolge des Feeds eines Benutzers nach der Wahrscheinlichkeit, dass dem Benutzer der Beitrag gefällt.
Ich kann nicht über 2014 sagen, aber in den Jahren 2016 und 2019 waren neben der Fähigkeit zur Datenanalyse auch Fähigkeiten im Umgang mit Big Data erforderlich. Ich denke, dass es die Kombination aus maschinellem Lernen und Big-Data-Verarbeitungsaufgaben war, die mich zu diesen Wettbewerben hingezogen hat, und die Erfahrung in diesen Bereichen hat zum Sieg beigetragen.
mlbootcamp
2019 wurde der Wettbewerb auf der Plattform https://mlbootcamp.ru organisiert .
Der Wettbewerb begann online am 7. Februar und bestand aus 3 Aufgaben. Jeder konnte sich auf der Website registrieren, die Baseline herunterladen und sein Auto für mehrere Stunden hochladen. Am Ende der Online-Phase am 15. März wurden die Top 15 jeder Show für die Offline-Phase, die vom 30. März bis 1. April stattfand, in das Mail.ru-Büro eingeladen.
Herausforderung
Die Quelldaten enthalten Benutzerkennungen (userId) und Post-IDs (objectId). Wenn dem Benutzer ein Beitrag angezeigt wurde, enthalten die Daten eine Zeile mit Benutzer-ID, Objekt-ID, Benutzerreaktionen auf diesen Beitrag (Feedback) und einer Reihe verschiedener Zeichen oder Links zu Bildern und Texten.
| userId | objectId | ownerId | Feedback | Bilder |
|---|
| 3555 | 22 | 5677 | [mochte, klickte] | [hash1] |
| 12842 | 55 | 32144 | [nicht gemocht] | [Hash2, Hash3] |
| 13145 | 35 | 5677 | [geklickt, erneut geteilt] | [hash2] |
Der Testdatensatz enthält eine ähnliche Struktur, aber das Rückmeldungsfeld fehlt. Ziel ist es, das Vorhandensein einer "Gefallen" -Reaktion im Rückkopplungsfeld vorherzusagen.
Die Übermittlungsdatei hat die folgende Struktur:
| userId | SortedList [objectId] |
|---|
| 123 | 78.13.54.22 |
| 128 | 35,61,55 |
| 131 | 35,68,129,11 |
Metrik - durchschnittliche ROC-AUC nach Benutzern.
Eine detailliertere Beschreibung der Daten finden Sie auf der Perfection-Site . Dort können Sie auch Daten herunterladen, einschließlich Tests und Bilder.
Online-Bühne
In der Online-Phase wurde die Aufgabe in drei Teile unterteilt
- Kollaboratives System - umfasst alle Zeichen außer Bildern und Texten;
- Bilder - enthält nur Informationen zu Bildern;
- Texte - Enthält nur Informationen zu Texten.
Offline-Bühne
In der Offline-Phase enthielten die Daten alle Attribute, während die Texte und Bilder spärlich waren. Der Datensatz enthielt 1,5-mal mehr Zeilen, von denen es bereits viele gab.
Problemlösung
Da ich bei der Arbeit einen Lebenslauf mache, habe ich meine Reise in diesem Wettbewerb mit der Aufgabe "Bilder" begonnen. Die bereitgestellten Daten sind userId, objectId, ownerId (die Gruppe, in der der Beitrag veröffentlicht wird), Zeitstempel zum Erstellen und Anzeigen des Beitrags und natürlich das Bild für diesen Beitrag.
Nachdem mehrere Features basierend auf dem Zeitstempel generiert wurden, bestand die nächste Idee darin, die vorletzte Schicht eines imagenet-vortrainierten Neurons zu nehmen und diese Einbettungen zum Boosten zu senden.
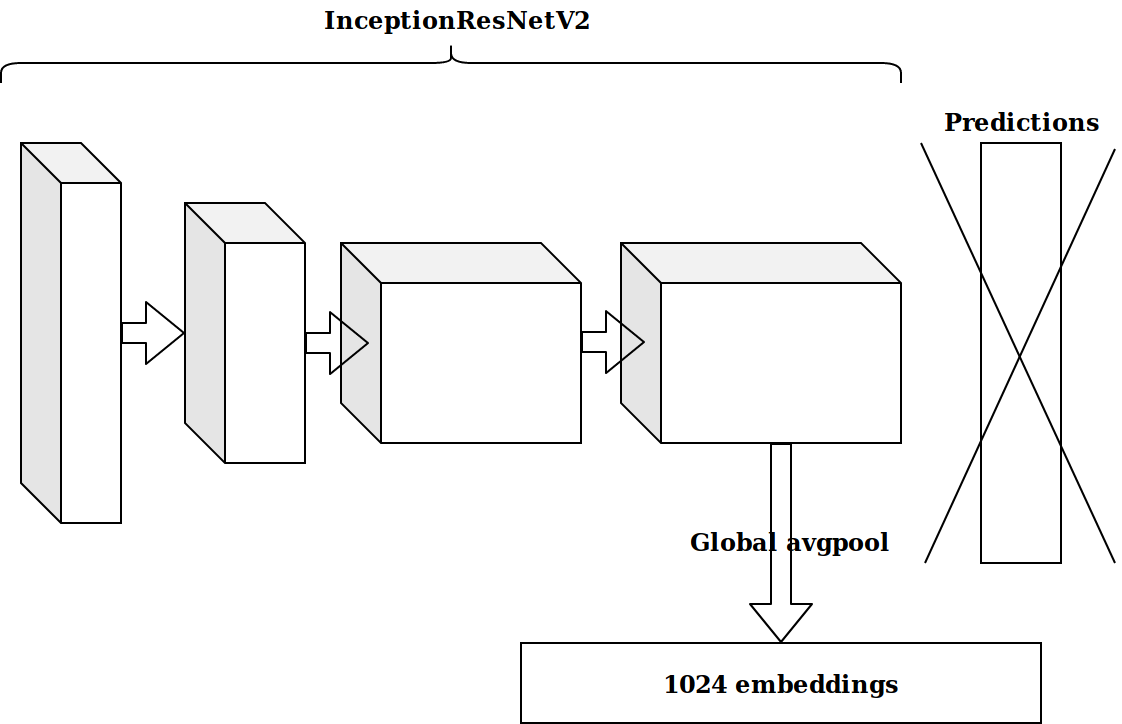
Die Ergebnisse waren nicht beeindruckend. Einbettungen aus dem Imagenet-Neuron sind irrelevant, dachte ich, ich muss meinen Auto-Encoder ablegen.
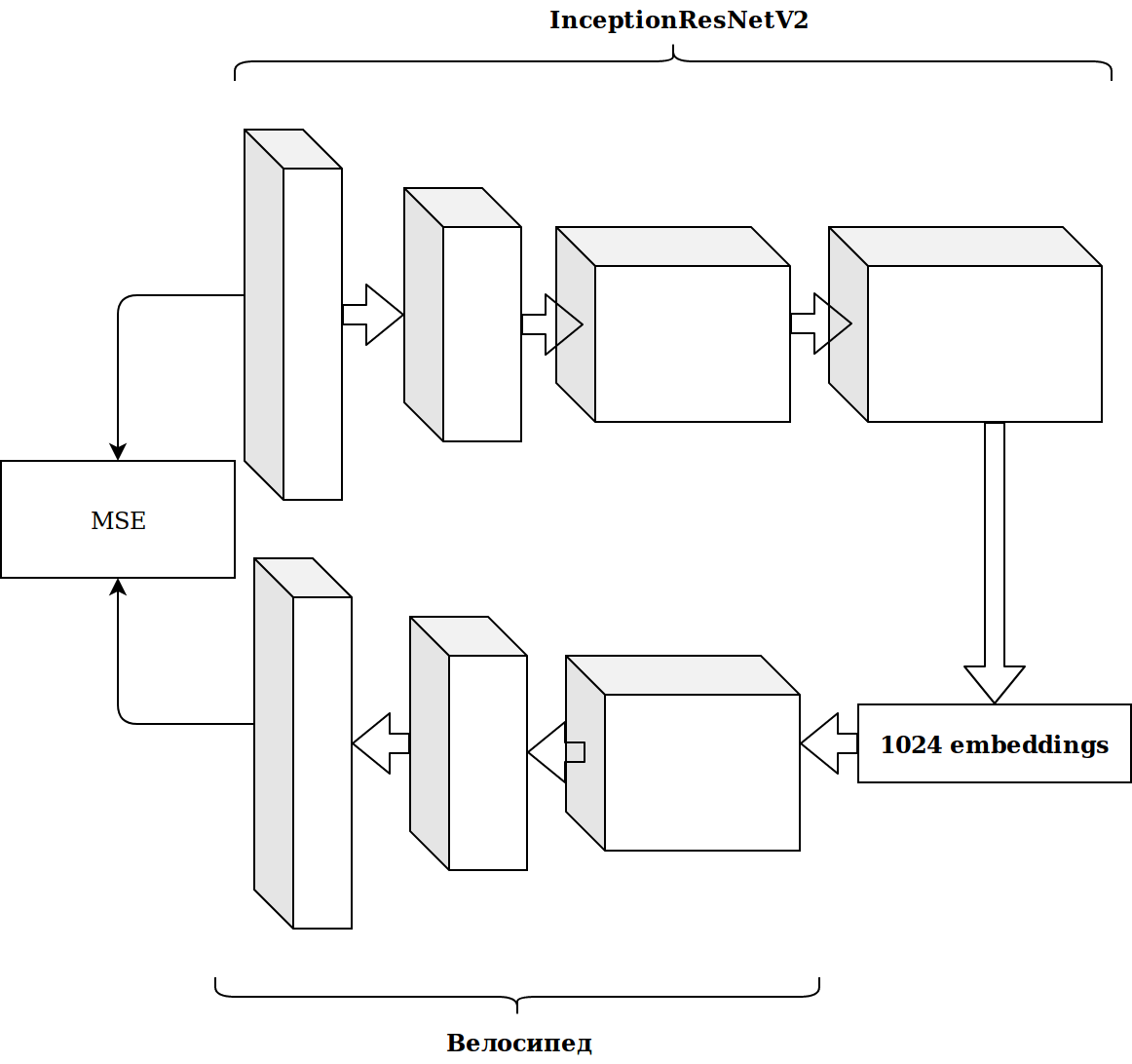
Es hat viel Zeit gekostet und das Ergebnis hat sich nicht verbessert.
Feature-Generierung
Die Arbeit mit Bildern nimmt viel Zeit in Anspruch, und ich habe beschlossen, etwas Einfacheres zu tun.
Wie Sie sofort sehen können, enthält der Datensatz mehrere kategoriale Zeichen, und um nicht viel zu stören, habe ich nur Catboost genommen. Die Lösung war ausgezeichnet, ohne Einstellungen kam ich sofort zur ersten Zeile der Rangliste.
Es gibt viele Daten und sie sind im Parkettformat angelegt. Ohne nachzudenken, nahm ich Scala und fing an, alles in Funken zu schreiben.
Die einfachsten Funktionen, die mehr Wachstum als Bildeinbettungen ermöglichten:
- Wie oft haben sich Objekt-ID, Benutzer-ID und Eigentümer-ID in den Daten getroffen (sollte mit der Popularität korrelieren)?
- Wie viele Benutzer-ID-Beiträge hat die Eigentümer-ID gesehen (sollte mit dem Interesse des Benutzers an der Gruppe korrelieren)?
- Wie viele eindeutige Benutzer-IDs wurden von ownerId angesehen (entspricht der Größe der Zielgruppe der Gruppe).
Aus Zeitstempeln konnte die Tageszeit ermittelt werden, zu der der Benutzer das Band angesehen hat (morgens / Tag / Abend / Nacht). Durch Kombinieren dieser Kategorien können Sie weiterhin Funktionen generieren:
- Wie oft hat sich die Benutzer-ID abends angemeldet?
- Wann wird dieser Beitrag oft angezeigt (objectId) und so weiter?
All dies verbesserte allmählich die Metrik. Die Größe des Trainingsdatensatzes beträgt jedoch etwa 20 Millionen Datensätze, sodass das Hinzufügen von Funktionen das Lernen erheblich verlangsamt.
Ich habe den Datennutzungsansatz neu definiert. Obwohl die Daten zeitabhängig sind, habe ich in Zukunft keine expliziten Informationslecks gesehen, dennoch habe ich sie für den Fall wie folgt gebrochen:
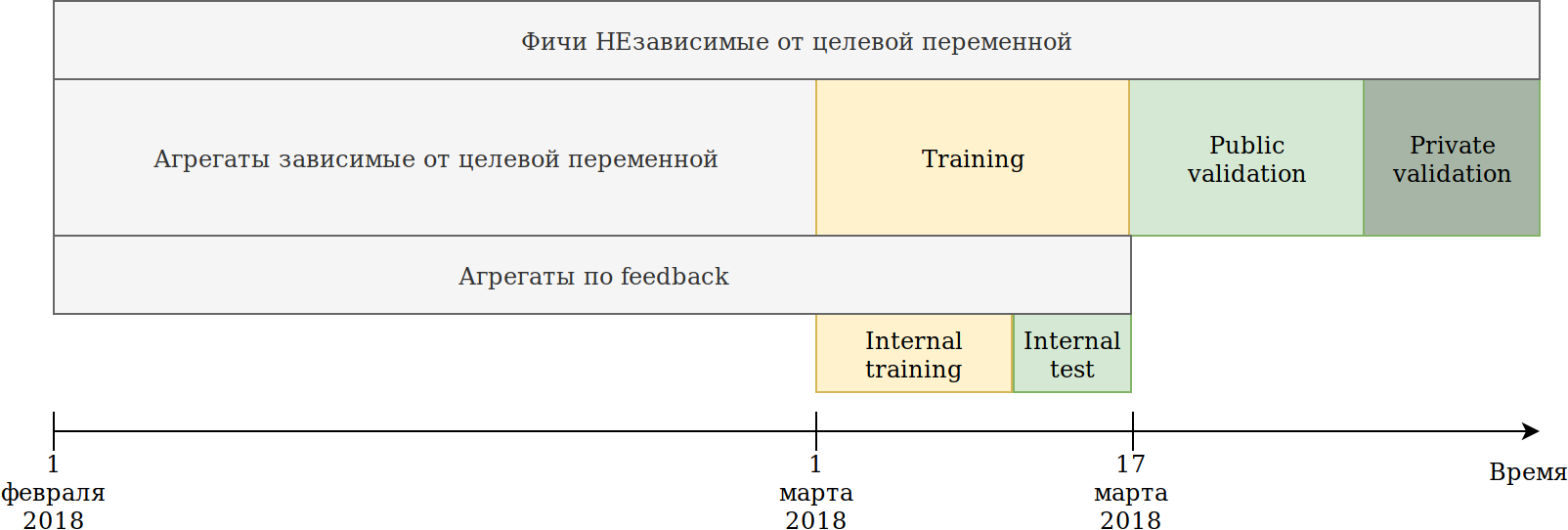
Das uns zur Verfügung gestellte Trainingsset (Februar und 2 Märzwochen) war in zwei Teile unterteilt.
Anhand der Daten der letzten N Tage trainierte er das Modell. Die oben beschriebenen Aggregationen wurden auf allen Daten einschließlich des Tests aufgebaut. Gleichzeitig erschienen Daten, auf denen verschiedene Encoder der Zielvariablen aufgebaut werden können. Der einfachste Ansatz besteht darin, den Code, der bereits neue Funktionen erstellt, wiederzuverwenden und ihn einfach mit Daten zu versorgen, die nicht trainiert werden, und Ziel = 1.
Somit haben wir ähnliche Funktionen erhalten:
- Wie oft hat userId einen Beitrag in der ownerId-Gruppe gesehen?
- Wie oft mochte userId den Beitrag zu ownerId;
- Der Prozentsatz der Beiträge, denen die Benutzer-ID die Eigentümer-ID gefallen hat.
Das heißt, es stellte sich heraus, dass die mittlere Zielcodierung seitens des Datensatzes nach verschiedenen Kombinationen von kategorialen Merkmalen erfolgt. Im Prinzip erstellt catboost auch eine Zielcodierung, und unter diesem Gesichtspunkt gibt es keinen Vorteil, aber es wurde beispielsweise möglich, die Anzahl der eindeutigen Benutzer zu zählen, die Beiträge in dieser Gruppe mögen. Gleichzeitig wurde das Hauptziel erreicht - mein Datensatz nahm mehrmals ab und es war möglich, weiterhin Features zu generieren.
Während Catboost Encoder nur entsprechend der gewünschten Reaktion erstellen kann, hat das Feedback andere Reaktionen: erneut geteilt, nicht gemocht, nicht gemocht, geklickt, ignoriert, was manuell erfolgen kann. Ich habe alle Arten von Aggregaten nachgezählt und Features mit geringer Bedeutung herausgesiebt, um den Datensatz nicht aufzublasen.
Zu diesem Zeitpunkt war ich mit großem Abstand auf dem ersten Platz. Die einzige Verlegenheit war, dass die Einbettung der Bilder fast keinen Gewinn brachte. Die Idee kam, alles für Catboost zu geben. Cluster K bedeutet Bilder und erhält eine neue kategoriale Funktion imageCat.
Hier sind einige Klassen nach dem manuellen Filtern und Zusammenführen von Clustern, die von KMeans erhalten wurden.

Basierend auf imageCat generieren wir:
- Neue kategoriale Funktionen:
- Welche imageCat sah am häufigsten nach userId aus?
- Welche imageCat wird am häufigsten von ownerId angezeigt?
- Welches imageCat mochte userId am häufigsten?
- Verschiedene Zähler:
- Wie viele eindeutige imageCat sahen userId aus;
- Etwa 15 ähnliche Funktionen plus Zielcodierung wie oben beschrieben.
Texte
Die Ergebnisse des Bildwettbewerbs passten zu mir und ich beschloss, mich in den Texten zu versuchen. Früher habe ich nicht viel mit Texten gearbeitet und aus Dummheit einen Tag auf tf-idf und svd getötet. Dann habe ich mit doc2vec eine Baseline gesehen, die genau das tut, was ich brauche. Nachdem ich die Parameter von doc2vec leicht angepasst hatte, erhielt ich Texteinbettungen.
Und dann verwendete er einfach den Code für die Bilder wieder, in dem er die Bildeinbettungen durch Texteinbettungen ersetzte. Infolgedessen erreichte ich den 2. Platz im Textwettbewerb.
Kollaboratives System
Es gab nur einen Wettbewerb, bei dem ich noch keinen „Stock gestoßen“ hatte, aber nach Ansicht der AUC in der Rangliste hätten die Ergebnisse dieses speziellen Wettbewerbs den größten Einfluss auf die Offline-Phase haben müssen.
Ich nahm alle Zeichen, die in den Quelldaten enthalten waren, wählte die kategorialen aus und berechnete die gleichen Aggregate wie für die Bilder, mit Ausnahme der Merkmale aus den Bildern selbst. Wenn ich es einfach in Catboost stecke, komme ich auf den 2. Platz.
Die ersten Schritte zur Optimierung von Catboost
Ein erster und zwei zweite Plätze haben mir gefallen, aber ich war mir einig, dass ich nichts Besonderes getan habe, was bedeutet, dass wir mit einem Positionsverlust rechnen können.
Die Aufgabe des Wettbewerbs besteht darin, Beiträge innerhalb des Benutzerrahmens zu bewerten. Während dieser ganzen Zeit habe ich das Klassifizierungsproblem gelöst, dh die falsche Metrik optimiert.
Ich werde ein einfaches Beispiel geben:
| userId | objectId | Vorhersage | Grundwahrheit |
|---|
| 1 | 10 | 0,9 | 1 |
| 1 | 11 | 0,8 | 1 |
| 1 | 12 | 0,7 | 1 |
| 1 | 13 | 0,6 | 1 |
| 1 | 14 | 0,5 | 0 |
| 2 | 15 | 0,4 | 0 |
| 2 | 16 | 0,3 | 1 |
Wir machen eine kleine Permutation
| userId | objectId | Vorhersage | Grundwahrheit |
|---|
| 1 | 10 | 0,9 | 1 |
| 1 | 11 | 0,8 | 1 |
| 1 | 12 | 0,7 | 1 |
| 1 | 13 | 0,6 | 0 |
| 2 | 16 | 0,5 | 1 |
| 2 | 15 | 0,4 | 0 |
| 1 | 14 | 0,3 | 1 |
Wir erhalten folgende Ergebnisse:
| Modell | Auc | Benutzer1 AUC | User2 AUC | mittlere AUC |
|---|
| Variante 1 | 0,8 | 1,0 | 0,0 | 0,5 |
| Option 2 | 0,7 | 0,75 | 1,0 | 0,875 |
Wie Sie sehen können, bedeutet die Verbesserung der gesamten AUC-Metrik nicht die Verbesserung der durchschnittlichen AUC-Metrik innerhalb des Benutzers.
Catboost kann Ranking-Metriken sofort optimieren . Ich habe über Ranking-Metriken und Erfolgsgeschichten bei der Verwendung von Catboost gelesen und YetiRankPairwise so eingestellt, dass es für die Nacht studiert. Das Ergebnis war nicht beeindruckend. Nachdem ich festgestellt hatte, dass ich nicht gut gelernt hatte, änderte ich die Fehlerfunktion in QueryRMSE, das nach der Dokumentation von catboost schneller konvergiert. Infolgedessen erzielte ich die gleichen Ergebnisse wie während des Klassifikationstrainings, aber die Ensembles dieser beiden Modelle erzielten eine gute Steigerung, was mich in allen drei Wettbewerben auf den ersten Platz brachte.
5 Minuten vor dem Abschluss der Online-Phase des Collaborative Systems-Wettbewerbs brachte mich Sergey Shalnov auf den zweiten Platz. Den weiteren Weg gingen wir zusammen.
Vorbereitung auf die Offline-Phase
Der Sieg in der Online-Phase war uns auf der RTX 2080 TI-Grafikkarte garantiert, aber der Hauptpreis von 300.000 Rubel und sogar der letzte erste Platz zwangen uns, diese zwei Wochen zu arbeiten.
Wie sich herausstellte, verwendete Sergey auch Catboost. Wir tauschten Ideen und Features aus, und ich erfuhr von dem Bericht von Anna Veronika Dorogush, in dem es Antworten auf viele meiner Fragen gab, und sogar auf diejenigen, die ich noch nicht erschienen war.
Das Anzeigen des Berichts führte mich zu der Idee, dass es notwendig ist, alle Parameter auf den Standardwert zurückzusetzen und die Einstellungen sehr sorgfältig und erst nach dem Korrigieren einer Reihe von Zeichen zu optimieren. Jetzt dauerte ein Training ungefähr 15 Stunden, aber ein Modell schaffte es, die Geschwindigkeit besser zu machen als im Ensemble mit Rangliste.
Feature-Generierung
Im Wettbewerb "Kollaborative Systeme" wird eine Vielzahl von Merkmalen als wichtig für das Modell bewertet. Zum Beispiel ist auditweights_spark_svd das wichtigste Attribut, und es gibt keine Informationen darüber, was es bedeutet. Ich dachte, es lohnt sich, die verschiedenen Einheiten anhand wichtiger Zeichen zu zählen. Zum Beispiel die durchschnittlichen auditweights_spark_svd pro Benutzer, pro Gruppe und pro Objekt. Dasselbe kann aus Daten berechnet werden, für die kein Training durchgeführt wird, und Ziel = 1, dh die durchschnittlichen auditweights_spark_svd pro Benutzer für die Objekte, die ihm gefallen haben. Neben auditweights_spark_svd gab es mehrere wichtige Anzeichen. Hier sind einige davon:
- auditweightsCtrGender
- auditweightsCtrHigh
- userOwnerCounterCreateLikes
Beispielsweise stellte sich heraus, dass der Durchschnittswert von auditweightsCtrGender nach Benutzer-ID ein wichtiges Merkmal ist, ebenso wie der Durchschnittswert von userOwnerCounterCreateLikes nach Benutzer-ID + Eigentümer-ID. Dies hätte uns darüber nachdenken lassen sollen, wie wir die Bedeutung der Felder verstehen können.
Weitere wichtige Funktionen waren auditweightsLikesCount und auditweightsShowsCount . Durch die Aufteilung wurde ein noch wichtigeres Merkmal erhalten.
Datenlecks
Wettbewerbs- und Produktionsmodelle sind sehr unterschiedliche Aufgaben. Bei der Vorbereitung der Daten ist es sehr schwierig, alle Details zu berücksichtigen und keine nicht trivialen Informationen über die Zielvariable im Test zu übertragen. Wenn wir eine Produktionslösung erstellen, werden wir versuchen, die Verwendung von Datenlecks beim Training des Modells zu vermeiden. Aber wenn wir den Wettbewerb gewinnen wollen, sind Datenlecks die besten Eigenschaften.
Nach Prüfung der Daten können Sie feststellen, dass sich die Werte von auditweightsLikesCount und auditweightsShowsCount gemäß objectId ändern. Dies bedeutet, dass das Verhältnis der Maximalwerte dieser Zeichen die Nachkonvertierung viel besser widerspiegelt als das Verhältnis zum Zeitpunkt der Lieferung.
Das erste Leck, das wir gefunden haben, war auditweightsLikesCountMax / auditweightsShowsCountMax .
Aber was ist, wenn Sie sich die Daten genauer ansehen? Nach Lieferdatum sortieren und erhalten:
| objectId | userId | auditweightsShowsCount | auditweightsLikesCount | Ziel (wird gemocht) |
|---|
| 1 | 1 | 12 | 3 | wahrscheinlich nicht |
| 1 | 2 | 15 | 3 | vielleicht ja |
| 1 | 3 | 16 | 4 | |
Es war überraschend, als ich das erste derartige Beispiel fand und es stellte sich heraus, dass meine Vorhersage nicht wahr wurde. Angesichts der Tatsache, dass die Maximalwerte dieser Zeichen im Rahmen des Objekts zunahmen, waren wir nicht zu faul und entschieden uns, auditweightsShowsCountNext und auditweightsLikesCountNext zu finden, dh Werte zum nächsten Zeitpunkt. Funktion hinzufügen
(auditweightsShowsCountNext-auditweightsShowsCount) / (auditweightsLikesCount-auditweightsLikesCountNext) Wir haben rund um die Uhr einen scharfen Sprung gemacht.
Ähnliche Lecks könnten verwendet werden, wenn die folgenden Werte für userOwnerCounterCreateLikes in userId + ownerId und beispielsweise auditweightsCtrGender in objectId + userGender gefunden würden. Wir haben 6 ähnliche Felder mit Lecks gefunden und so viele Informationen wie möglich daraus gezogen.
Zu diesem Zeitpunkt hatten wir ein Maximum an Informationen aus kollaborativen Attributen herausgepresst, kehrten jedoch nicht zu Wettbewerben mit Bildern und Texten zurück. Es gab eine gute Idee zu überprüfen: Wie viel geben Features direkt auf Bilder oder Texte in den entsprechenden Wettbewerben?
Es gab keine Lecks in den Wettbewerben für Bilder und Texte, aber zu diesem Zeitpunkt hatte ich die Standardparameter von catboost zurückgegeben, den Code gekämmt und einige Funktionen hinzugefügt. Gesamtergebnis:
| Lösung | Geschwindigkeit |
|---|
| Maximum mit Bildern | 0,6411 |
| Maximal keine Bilder | 0,6297 |
| Ergebnis des zweiten Platzes | 0,6295 |
| Lösung | Geschwindigkeit |
|---|
| Maximal mit Texten | 0,666 |
| Maximum ohne Texte | 0,660 |
| Ergebnis des zweiten Platzes | 0,656 |
| Lösung | Geschwindigkeit |
|---|
| Maximum in Zusammenarbeit | 0,745 |
| Ergebnis des zweiten Platzes | 0,723 |
Es stellte sich heraus, dass es unwahrscheinlich war, dass viele Texte und Bilder herausgedrückt wurden, und nachdem wir einige der interessantesten Ideen ausprobiert hatten, hörten wir auf, mit ihnen zu arbeiten.
Die weitere Generierung von Funktionen in kollaborativen Systemen brachte kein Wachstum, und wir begannen mit dem Ranking. In der Online-Phase gab mir das Ensemble aus Klassifikation und Ranking einen kleinen Anstieg, wie sich herausstellte, weil ich die Klassifikation unterausgebildet hatte. Keine der Fehlerfunktionen, einschließlich YetiRanlPairwise, lieferte sogar genaue Ergebnisse, die LogLoss lieferte (0,745 gegenüber 0,725). Es gab Hoffnung auf eine QueryCrossEntropy, die nicht gestartet werden konnte.
Offline-Bühne
In der Offline-Phase ist die Datenstruktur gleich geblieben, es wurden jedoch kleine Änderungen vorgenommen:
- Bezeichner userId, objectId, ownerId wurden neu randomisiert;
- mehrere Zeichen wurden entfernt und einige umbenannt;
- Daten sind ungefähr 1,5 mal größer geworden.
Zusätzlich zu den aufgeführten Schwierigkeiten gab es ein großes Plus: Dem Team wurde ein großer Server mit RTX 2080TI zugewiesen. Ich habe htop lange genossen.
Die Idee war eine - nur um zu reproduzieren, was bereits da ist. Nachdem wir einige Stunden damit verbracht hatten, die Umgebung auf dem Server einzurichten, begannen wir nach und nach zu überprüfen, ob die Ergebnisse reproduziert wurden. Das Hauptproblem, mit dem wir konfrontiert sind, ist die Zunahme des Datenvolumens. Wir haben uns entschlossen, die Last leicht zu reduzieren und den Parameter catboost ctr_complexity = 1 zu setzen. Dies senkt die Geschwindigkeit ein wenig, aber mein Modell begann zu funktionieren, das Ergebnis war gut - 0,733. Im Gegensatz zu mir hat Sergei die Daten nicht in zwei Teile geteilt und alle Daten trainiert. Obwohl dies das beste Ergebnis in der Online-Phase ergab, gab es in der Offline-Phase viele Schwierigkeiten. Wenn wir alle von uns generierten Funktionen nutzen und versuchen, sie in Catboost „auf die Stirn“ zu setzen, wäre im Online-Stadium nichts passiert. Sergey hat die Typoptimierung durchgeführt, z. B. float64-Typen in float32 konvertiert. In diesem Artikel finden Sie Informationen zur Speicheroptimierung bei Pandas. Infolgedessen trainierte Sergey alle Daten auf der CPU und es stellte sich heraus, dass es ungefähr 0,735 waren.
Diese Ergebnisse reichten aus, um zu gewinnen, aber wir versteckten unsere tatsächliche Geschwindigkeit und konnten nicht sicher sein, dass andere Teams nicht dasselbe taten.
Kampf bis zum letzten
Catboost einstellen
Unsere Lösung wurde vollständig reproduziert. Wir haben Funktionen für Textdaten und Bilder hinzugefügt, sodass nur noch die Catboost-Parameter angepasst werden mussten. Sergey studierte auf der CPU mit einer kleinen Anzahl von Iterationen und ich studierte mit ctr_complexity = 1. Es war nur noch ein Tag übrig, und wenn Sie nur Iterationen hinzufügen oder ctr_complexity erhöhen, können Sie am Morgen noch schneller werden und den ganzen Tag laufen.
In der Offline-Phase können die Ergebnisse sehr leicht ausgeblendet werden, indem einfach nicht die beste Lösung auf der Website ausgewählt wird. Wir haben in den letzten Minuten vor dem Abschluss der Einreichungen starke Änderungen in der Rangliste erwartet und beschlossen, nicht aufzuhören.
Aus dem Video von Anna habe ich gelernt, dass es zur Verbesserung der Qualität des Modells am besten ist, die folgenden Parameter auszuwählen:
- learning_rate - Der Standardwert wird basierend auf der Größe des Datensatzes berechnet. Bei einer Verringerung der Lernrate ist es zur Aufrechterhaltung der Qualität erforderlich, die Anzahl der Iterationen zu erhöhen.
- l2_leaf_reg - Regularisierungskoeffizient, Standardwert 3, vorzugsweise von 2 bis 30. Eine Abnahme des Wertes führt zu einer Zunahme der Überanpassung.
- bagging_temperature - Fügt den Gewichten von Objekten in der Auswahl eine Randomisierung hinzu. Der Standardwert ist 1, bei dem Gewichte aus der Exponentialverteilung ausgewählt werden. Eine Wertminderung führt zu einer Zunahme der Überanpassung.
- random_strength - Beeinflusst die Auswahl der Teilungen für eine bestimmte Iteration. Je höher die random_strength ist, desto höher ist die Wahrscheinlichkeit, dass ein Split von geringer Bedeutung ausgewählt wird. Bei jeder nachfolgenden Iteration nimmt die Zufälligkeit ab. Eine Wertminderung führt zu einer Zunahme der Überanpassung.
Andere Parameter wirken sich wesentlich weniger auf das Endergebnis aus, daher habe ich nicht versucht, sie auszuwählen. Eine Trainingsiteration für mein GPU-Dataset mit ctr_complexity = 1 dauerte 20 Minuten, und die ausgewählten Parameter für das reduzierte Dataset unterschieden sich geringfügig von den optimalen Parametern für das gesamte Dataset. Infolgedessen habe ich ungefähr 30 Iterationen für 10% der Daten und dann ungefähr 10 weitere Iterationen für alle Daten durchgeführt. Es stellte sich ungefähr Folgendes heraus:
- Ich habe die Lernrate gegenüber dem Standard um 40% erhöht.
- l2_leaf_reg hat dasselbe verlassen;
- bagging_temperature und random_strength auf 0.8 reduziert.
Wir können daraus schließen, dass das Modell mit Standardparametern untertrainiert ist.
Ich war sehr überrascht, als ich das Ergebnis auf der Rangliste sah:
| Modell | Modell 1 | Modell 2 | Modell 3 | Ensemble |
|---|
| Keine Abstimmung | 0,7403 | 0,7404 | 0,7404 | 0,7407 |
| Mit Tuning | 0,7406 | 0,7405 | 0,7406 | 0,7408 |
Ich bin zu dem Schluss gekommen, dass es besser ist, die Auswahl der Parameter durch ein Ensemble mehrerer Modelle mit nicht optimierten Parametern zu ersetzen, wenn Sie keine schnelle Anwendung des Modells benötigen.
Sergey war damit beschäftigt, die Größe des Datasets zu optimieren, um es auf der GPU auszuführen. — , :
- ( ), ;
- ;
- userId, ;
- userId, .
— .
, 0,742. ctr_complexity=2 30 5 . 4 , , 0,7433.
, , . predict(prediction_type='RawFormulaVal') scale_pos_weight=neg_count/pos_count.
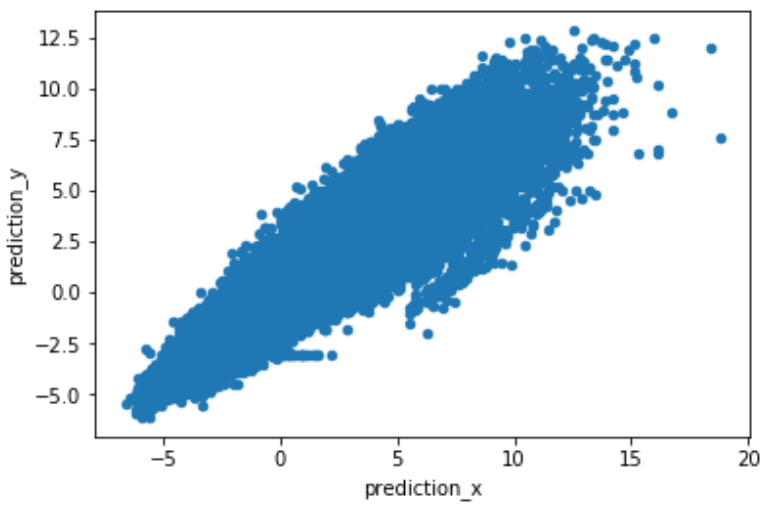
.
. , , , 2 .
Fazit
:
- , target encoding, catboost.
- , , learning_rate iterations. — .
- GPU. Catboost GPU, .
- rsm~=0.2 (CPU only) ctr_complexity=1.
- Im Gegensatz zu anderen Teams hat das Ensemble unserer Modelle stark zugenommen. Wir haben uns ausgetauscht und in verschiedenen Sprachen geschrieben. Wir hatten einen anderen Ansatz zum Aufteilen von Daten, und ich denke, jeder hatte seine eigenen Fehler.
- Es ist nicht klar, warum die Ranking-Optimierung schlechtere Ergebnisse lieferte als die Klassifizierungsoptimierung.
- Ich habe ein wenig Erfahrung mit Texten und ein Verständnis dafür, wie Empfehlungssysteme gemacht werden.

Vielen Dank an die Organisatoren für die erhaltenen Emotionen, Kenntnisse und Preise.