
Hallo Habr! Ich veröffentliche weiterhin den Zyklus über die Innenseiten der Zahlungsplattform RBK.money, der in diesem Beitrag begonnen hat . Heute werden wir über das logische Verarbeitungsschema, bestimmte Microservices und ihre Beziehung zueinander sprechen, wie die Services, die die einzelnen Geschäftslogiken verarbeiten, logisch getrennt sind, warum der Verarbeitungskern nichts über die Anzahl Ihrer Zahlungskarten weiß und wie Zahlungen innerhalb der Plattform ausgeführt werden. Außerdem werde ich etwas detaillierter auf das Thema eingehen, wie wir Hochverfügbarkeit und Skalierung für hohe Lasten bereitstellen.
Übersichtslogik und allgemeine Ansätze
Im Allgemeinen sieht das Schema der Grundelemente des Teils der Verarbeitung, der für Zahlungen verantwortlich ist, so aus.
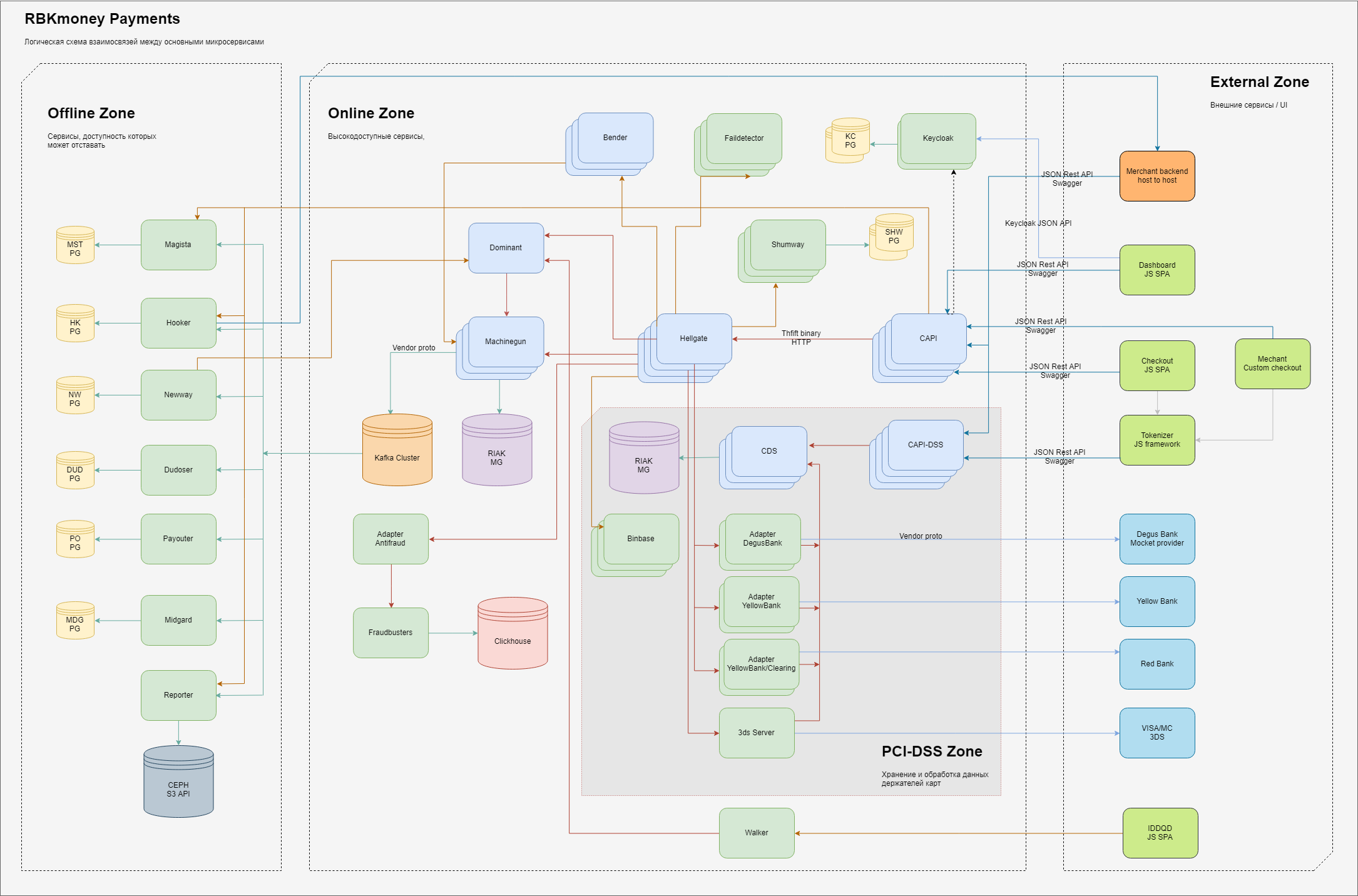
Logischerweise teilen wir die Verantwortungsbereiche in uns in drei Bereiche ein:
- externe Zone, Entitäten im Internet, wie JS-Anwendungen unseres Zahlungsformulars (Sie geben dort Ihre Kartendaten ein), Backends unserer Händlerkunden sowie die Verarbeitung von Gateways unserer Partnerbanken und Anbieter anderer Zahlungsmethoden;
- Als interne, gut zugängliche Zone leben dort Microservices, die die Arbeit des Zahlungsgateways direkt bereitstellen und die Abbuchung von Geld verwalten, wobei sie in unserem System und anderen Online-Diensten berücksichtigt werden, die durch die Anforderung gekennzeichnet sind, "trotz aller Ausfälle in unseren DCs immer verfügbar zu sein".
- Es gibt einen separaten Bereich von Diensten, die direkt mit den vollständigen Daten der Karteninhaber arbeiten. Für diese Dienste gelten separate Anforderungen, die vom Eisenbahnministerium festgelegt wurden und die einer obligatorischen Zertifizierung gemäß den PCI-DSS-Standards unterliegen. Wir werden im Folgenden näher erläutern, warum eine solche Trennung vorliegt.
- die innere Zone, in der im klassischen Sinne weniger Anforderungen an die Verfügbarkeit der erbrachten Dienstleistungen oder den Zeitpunkt ihrer Beantwortung gestellt werden - dies ist ein Backoffice. Obwohl wir hier natürlich auch versuchen, das Prinzip „immer verfügbar“ sicherzustellen, geben wir uns nur weniger Mühe dafür;
Innerhalb jeder Zone gibt es Microservices, die ihre Teile der Verarbeitung von Geschäftslogik ausführen. Sie empfangen RPC-Aufrufe am Eingang und generieren am Ausgang Daten, die mit eingebetteten Algorithmen verarbeitet wurden, die auch als Aufrufe anderer Mikrodienste entlang der Kette ausgeführt werden.
Um die Skalierbarkeit sicherzustellen, versuchen wir, Zustände an möglichst wenigen Stellen zu speichern. Statuslose Dienste im Diagramm haben keine Verbindungen zu persistenten Speichern, bzw. Stateful-Dienste sind mit ihnen verbunden. Im Allgemeinen verwenden wir mehrere eingeschränkte Dienste für die dauerhafte Speicherung von Status. Für den Hauptteil der Verarbeitung sind dies Riak-KV-Cluster, für verwandte Dienste - PostgreSQL - für die asynchrone Warteschlangenverarbeitung verwenden wir Kafka.
Um eine hohe Verfügbarkeit sicherzustellen, stellen wir Dienste in mehreren Fällen bereit, normalerweise von 3 bis 5.
Es ist einfach, zustandslose Dienste zu skalieren. Wir erhöhen einfach die Anzahl der Instanzen, die wir auf verschiedenen virtuellen Maschinen benötigen. Sie sind in Consul registriert. Sie können über das Konsolen-DNS aufgelöst werden und beginnen, Anrufe von anderen Diensten zu empfangen, die empfangenen Daten zu verarbeiten und weiter zu senden.
Stateful Services, oder besser gesagt unsere Hauptdienste, die im Diagramm als Machinegun dargestellt sind, implementieren eine leicht zugängliche Schnittstelle (die verteilte Architektur basiert auf Erlang Distribution), und die Synchronisierung über Consul KV wird verwendet, um Warteschlangen und verteiltes Sperren sicherzustellen. Dies ist eine kurze, detaillierte Beschreibung, die in einem separaten Beitrag veröffentlicht wird.
Riak bietet sofort einen hoch zugänglichen, dauerhaften, masterlosen Speicher. Wir bereiten ihn in keiner Weise vor. Die Konfiguration ist fast voreingestellt. Mit dem aktuellen Lastprofil haben wir 5 Knoten im Cluster, die auf separaten Hosts bereitgestellt werden. Ein wichtiger Hinweis: Wir verwenden praktisch keine Indizes und Stichproben mit großen Datenmengen, sondern arbeiten mit bestimmten Schlüsseln.
Wo die Implementierung des KV-Schemas zu teuer ist, verwenden wir PostgeSQL-Datenbanken mit Replikation oder sogar Single-Mode-Lösungen, da wir im Falle eines Fehlers immer die erforderlichen Ereignisse aus dem Online-Teil über Machinegun hochladen können.
Die Farbtrennung der Mikrodienste im Diagramm gibt die Sprachen an, in denen sie geschrieben sind - hellgrün - dies sind Java-Anwendungen, hellblau - Erlang.
Alle Dienste arbeiten in Docker-Containern, bei denen es sich um CI-Build-Artefakte handelt und die sich in der lokalen Docker-Registrierung befinden. Stellt Dienste für die SaltStack-Produktion bereit, deren Konfiguration sich im privaten Github-Repository befindet.
Entwickler fordern unabhängig Änderungen an diesem Repository an, in denen sie die Anforderungen für den Dienst beschreiben. Geben Sie die gewünschte Version und die gewünschten Parameter an, z. B. die Größe des für den Container zugewiesenen Speichers, der an Umgebungsvariablen und andere Dinge übertragen wird. Nach der manuellen Bestätigung der Änderungsanforderung durch autorisierte Mitarbeiter (wir haben DevOps, Support und Informationssicherheit) rollt die CD die Containerinstanzen mit den neuen Versionen automatisch auf die Hosts der Produktumgebung.
Außerdem schreibt jeder Dienst Protokolle in einem Format, das für Elasticsearch verständlich ist. Protokolldateien werden vom Filebeat erfasst, der sie in den Elasticsearch-Cluster schreibt. Trotz der Tatsache, dass Entwickler keinen Zugriff auf die Produktumgebung haben, haben sie immer die Möglichkeit zu debuggen und zu sehen, was mit ihren Diensten passiert.
Interaktion mit der Außenwelt

Jede Änderung des Status der Plattform bei uns erfolgt ausschließlich durch Aufrufe der entsprechenden Methoden öffentlicher APIs. Wir verwenden keine klassischen Webanwendungen und keine serverseitige Inhaltsgenerierung. Alles, was Sie als Benutzeroberfläche sehen, sind JS-Ansichten über unsere öffentlichen APIs. Grundsätzlich kann jede Aktion auf der Plattform mit einer Kette von Curl-Aufrufen von der Konsole ausgeführt werden, die wir verwenden. Insbesondere zum Schreiben von Integrationstests (wir haben sie in JS als Bibliothek geschrieben), die in CI während jeder Assembly alle öffentlichen Methoden überprüfen.
Ein solcher Ansatz löst auch alle Probleme der externen Integration in unsere Plattform und ermöglicht es Ihnen, ein einziges Protokoll sowohl für den Endbenutzer in Form einer schönen Form der Eingabe von Zahlungsdaten als auch von Host zu Host für die direkte Integration in die Verarbeitung durch Dritte unter Verwendung ausschließlich der Interaktion zwischen Servern zu erhalten.
Zusätzlich zur vollständigen Abdeckung von Integrationstests verwenden wir die Ansätze des Staging-Updates. In einer verteilten Architektur ist dies recht einfach, indem beispielsweise nur ein Dienst aus jeder Gruppe in einem Durchgang bereitgestellt wird, gefolgt von einer Pause und Analyse von Protokollen und Grafiken.
Auf diese Weise können wir fast rund um die Uhr, einschließlich Freitagabend, etwas bereitstellen, das ohne große Angst außer Betrieb ist, oder schnell zurücksetzen und ein einfaches Zurücksetzen mit einer Änderung durchführen, bis es niemand bemerkt.

Vor jedem Aufruf der öffentlichen Methode müssen wir den Client autorisieren und authentifizieren. Damit ein Client auf der Plattform angezeigt werden kann, benötigen Sie einen Dienst, der die gesamte Interaktion mit dem Endbenutzer übernimmt und Schnittstellen zum Registrieren, Eingeben und Zurücksetzen von Kennwörtern, zur Sicherheitskontrolle und für andere Bindungen bereitstellt.
Hier haben wir kein Fahrrad erfunden, sondern einfach die Open-Source-Lösung von Redhat - Keycloak integriert . Bevor Sie mit uns interagieren können, müssen Sie sich auf der Plattform registrieren. Dies geschieht tatsächlich über Keycloak.
Nach erfolgreicher Authentifizierung im Dienst erhält der Client eine JWT. Wir werden es später für die Autorisierung verwenden. Auf der Keycloak-Seite können Sie beliebige Felder angeben, die Rollen beschreiben, die als einfache JSON-Struktur in JWT eingebettet und mit dem privaten Schlüssel des Dienstes signiert werden.
Eine der Funktionen von JWT ist, dass diese Struktur vom privaten Schlüssel des Servers signiert wird. Um die Liste der Rollen und ihrer anderen Objekte zu autorisieren, müssen wir nicht auf den Autorisierungsdienst zugreifen. Der Prozess ist vollständig entkoppelt. CAPI-Dienste lesen beim Start den öffentlichen Keycloak-Schlüssel und autorisieren damit Aufrufe an öffentliche API-Methoden.
Als wir das Schlüssel-Widerrufsschema entwickelten, ist die Geschichte getrennt und verdient einen eigenen Beitrag.
Wir haben das JWT erhalten und können es zur Authentifizierung verwenden. Hier kommt die Gruppe der Microservices Common API ins Spiel, die in dem als CAPI und CAPI-DSS angegebenen Diagramm die folgenden Funktionen implementiert:
- Autorisierung empfangener Nachrichten. Vor jedem öffentlichen API-Aufruf steht ein HTTP-Header Authorizaion: Bearer {JWT}. Die Dienste der Common API-Gruppe verwenden sie, um die signierten Daten mit dem vorhandenen öffentlichen Schlüssel des Autorisierungsdienstes zu überprüfen.
- Validierung der empfangenen Daten. Da das Schema als OpenAPI-Spezifikation, auch als Swagger bezeichnet, beschrieben wird, kann die Datenvalidierung sehr einfach sein und es besteht nur eine geringe Chance, Steuerbefehle im Datenstrom zu empfangen. Dies wirkt sich positiv auf die Sicherheit des gesamten Dienstes aus.
- Übersetzung von Datenformaten von öffentlichem REST JSON in internen binären Thrift;
- Framing der Transportbindung mit Daten wie einer eindeutigen trace_id und Weitergabe des Ereignisses weiter innerhalb der Plattform an einen Service, der die Geschäftslogik verwaltet und beispielsweise weiß, was Zahlung ist.
Wir haben viele solcher Dienste, sie sind recht einfach und aus Eichenholz, speichern keine Zustände. Für die lineare Leistungsskalierung setzen wir sie einfach mit freien Kapazitäten in den Mengen ein, die wir benötigen.
PCI-DSS und offene Kartendaten

Wie Sie in der Abbildung sehen können, gibt es zwei solcher Dienstgruppen: Die Hauptgruppe, die Common API, ist für die Verarbeitung aller Datenströme verantwortlich, für die keine offenen Karteninhaberdaten vorliegen, und die zweite, die PCI-DSS Common API, die direkt mit diesen Karten funktioniert. Im Inneren sind sie genau gleich, aber wir haben sie physisch getrennt und auf verschiedenen Eisenstücken angeordnet.
Dies geschieht, um die Anzahl der Speicherorte für die Speicherung und Verarbeitung von Kartendaten zu minimieren, das Risiko eines Verlusts dieser Daten und des PCI-DSS-Zertifizierungsbereichs zu verringern. Glauben Sie mir, dies ist ein ziemlich zeitaufwändiger und kostspieliger Prozess. Als Zahlungsunternehmen müssen wir uns jedes Jahr einer kostenpflichtigen Zertifizierung unterziehen, um die Einhaltung der MPS-Standards zu gewährleisten. Je weniger Server und Dienste daran beteiligt sind, desto schneller und einfacher ist es, diesen Prozess abzuschließen. Nun, was die Sicherheit betrifft, spiegelt sich dies am positivsten wider.
Abrechnung und Tokenisierung
Wir möchten also mit der Zahlung beginnen und Geld von der Karte des Zahlers abschreiben.
Stellen Sie sich vor, die Anfrage dazu kam in Form einer Kette von Aufrufen der Methoden unserer öffentlichen API, die von Ihnen als Zahler initiiert wurde, nachdem Sie in den Online-Shop gegangen waren, einen Warenkorb abgeholt, auf "Kaufen" geklickt und Ihre Kartendaten in unsere Zahlung eingegeben hatten Formular und klickte auf die Schaltfläche "Bezahlen".
Wir bieten verschiedene Geschäftsprozesse zum Abschreiben von Geld an. Am interessantesten ist jedoch der Prozess der Verwendung von Kreditorenbuchhaltung. Auf unserer Plattform können Sie eine Rechnung für die Zahlung oder eine Rechnung erstellen, die ein Container für Zahlungen ist.
Innerhalb einer Rechnung können Sie versuchen, sie einzeln zu bezahlen, dh Zahlungen erstellen, bis die nächste Zahlung erfolgreich ist. Sie können beispielsweise versuchen, eine Rechnung mit verschiedenen Karten, Brieftaschen und anderen Zahlungsmethoden zu bezahlen. Wenn auf einer der Karten kein Geld vorhanden ist, können Sie eine andere versuchen und so weiter.
Dies wirkt sich positiv auf die Conversion und die Benutzererfahrung aus.
Rechnungszustandsmaschine

Innerhalb der Plattform verwandelt sich diese Kette auf folgendem Weg in Interaktionen:
- Vor der Übermittlung von Inhalten an Ihren Browser hat sich unser Client-Händler in unsere Plattform integriert, sich bei uns registriert und ein JWT zur Autorisierung erhalten.
- In seinem Backend hat der Händler die Methode createInvoice () aufgerufen, dh er hat eine Rechnung für die Zahlung auf unserer Plattform erstellt. Tatsächlich hat das Händler-Backend eine HTTP-POST-Anforderung mit folgendem Inhalt an unseren Endpunkt gesendet:
curl -X POST \ https://api.rbk.money/v2/processing/invoices \ -H 'Authorization: Bearer {JWT}' \ -H 'Content-Type: application/json; charset=utf-8' \ -H 'X-Request-ID: 1554417367' \ -H 'cache-control: no-cache' \ -d '{ "shopID": "TEST", "dueDate": "2019-03-28T17:41:32.569Z", "amount": 6000, "currency": "RUB", "product": "Order num 12345", "description": "Delicious meals", "cart": [ { "price": 5000, "product": "Sandwich", "quantity": 1, "taxMode": { "rate": "10%", "type": "InvoiceLineTaxVAT" } }, { "price": 1000, "product": "Cola", "quantity": 1, "taxMode": { "rate": "18%", "type": "InvoiceLineTaxVAT" } } ], "metadata": { "order_id": "Internal order num 13123298761" } }'
Die Anforderung wurde auf einer der erlang-Anwendungen der Common API-Gruppe abgewogen, die ihre Gültigkeit überprüfte, an den Bender-Dienst ging, wo sie den Idempotenzschlüssel erhielt, ihn an den Tift übertrug und eine Anforderung an die Hellgate-Dienstgruppe sendete. Die Hellgate-Instanz führte Geschäftsprüfungen durch, stellte beispielsweise sicher, dass der Eigentümer dieses JWT nicht grundsätzlich blockiert ist, Rechnungen erstellen und im Allgemeinen mit der Plattform interagieren kann, und begann mit der Erstellung einer Rechnung.
Wir können sagen, dass Hellgate der Kern unserer Verarbeitung ist, da es mit Geschäftseinheiten zusammenarbeitet und weiß, wie man eine Zahlung startet, wer gekickt werden muss, damit diese Zahlung zu einer echten Geldgebühr wird, wie man den Weg dieser Zahlung berechnet und wer angewiesen werden sollte, sie abzuschreiben Berechnen Sie in den Bilanzen Provisionen und andere Bindungen.
Normalerweise speichert es auch keine Zustände und ist auch leicht skalierbar. Wir möchten jedoch nicht die Rechnung verlieren oder eine doppelte Gebühr von der Karte erhalten, wenn das Netzwerk aufgeteilt wird oder Hellgate aus irgendeinem Grund ausfällt. Es ist notwendig, diese Daten dauerhaft zu speichern.
Hier kommt der dritte Microservice, nämlich Machinegun. Hellgate sendet Machinegun einen Aufruf zum "Erstellen eines Automaten" mit einer Nutzlast in Form von Abfrageparametern. Machinegun organisiert gleichzeitige Anforderungen und erstellt mit Hellgate das erste Ereignis aus den Parametern - InvoiceCreated. Welches dann selbst und schreibt in Riak und Warteschlangen. Danach wird eine erfolgreiche Antwort in umgekehrter Reihenfolge auf die ursprüngliche Anforderung in der Kette zurückgegeben.
Kurz gesagt, Machinegun ist ein solches DBMS mit Timern über jedes andere DBMS in der aktuellen Version der Plattform - über Riak. Es bietet eine Schnittstelle, über die Sie unabhängige Maschinen steuern können, und bietet Garantien für Idempotenz und Aufzeichnungsreihenfolge. Es ist MG, das nicht zulässt, dass das Ereignis automatisch aus der Warteschlange geschrieben wird, wenn plötzlich mehrere HGs mit einer solchen Anfrage zu ihm kommen.
Ein Automat ist eine eindeutige Entität innerhalb der Plattform, die aus einer Kennung, einem Datensatz in Form einer Ereignisliste und einem Timer besteht. Der Endzustand des Automaten wird aus der Verarbeitung aller seiner Ereignisse berechnet, die seinen Übergang in den entsprechenden Zustand einleiten. Wir verwenden diesen Ansatz, um mit Geschäftseinheiten zu arbeiten und sie als endliche Zustandsmaschinen zu beschreiben. Tatsächlich sind alle von unseren Händlern erstellten Rechnungen sowie die darin enthaltenen Zahlungen endliche Zustandsmaschinen mit ihrer eigenen Logik des Übergangs zwischen Staaten.
Über die Schnittstelle zum Arbeiten mit Timern in Machinegun können Sie eine Anfrage des Formulars "Ich möchte diese Maschine in 15 Jahren weiter verarbeiten" von einem anderen Dienst zusammen mit Ereignissen für die Aufzeichnung erhalten. Solche anstehenden Aufgaben werden auf eingebauten Timern implementiert. In der Praxis werden sie sehr häufig verwendet - regelmäßige Anrufe bei der Bank, automatische Aktionen mit Zahlungen aufgrund langer Inaktivität usw.
Machinegun-Quellcodes sind übrigens unter der Apache 2.0-Lizenz in unserem öffentlichen Repository geöffnet . Wir hoffen, dass dieser Service für die Community von Nutzen sein kann.
Eine detaillierte Beschreibung der Arbeit von Machinegun und im Allgemeinen der Vorbereitung des Vertriebssystems finden Sie in einem separaten großen Beitrag, sodass ich hier nicht näher darauf eingehen werde.
Die Nuancen der Autorisierung externer Kunden

Nach einem erfolgreichen Speichervorgang gibt Hellgate die Daten an das CAPI zurück und konvertiert die binäre Trift-Struktur in einen wunderschön gestalteten JSON, der an das Händler-Backend gesendet werden kann:
{ "invoice": { "amount": 6000, "cart": [ { "cost": 5000, "price": 5000, "product": "Sandwich", "quantity": 1, "taxMode": { "rate": "10%", "type": "InvoiceLineTaxVAT" } }, { "cost": 1000, "price": 1000, "product": "Cola", "quantity": 1, "taxMode": { "rate": "18%", "type": "InvoiceLineTaxVAT" } } ], "createdAt": "2019-04-04T23:00:31.565518Z", "currency": "RUB", "description": "Delicious meals", "dueDate": "2019-04-05T00:00:30.889000Z", "id": "18xtygvzFaa", "metadata": { "order_id": "Internal order num 13123298761" }, "product": "Order num 12345", "shopID": "TEST", "status": "unpaid" }, "invoiceAccessToken": { "payload": "{JWT}" } }
Es scheint, dass Sie Inhalte im Browser an den Zahler senden und den Zahlungsprozess starten können. Hier dachten wir jedoch, dass nicht alle Händler bereit wären, die Autorisierung auf Kundenseite unabhängig zu implementieren, und haben sie daher selbst implementiert. Der Ansatz besteht darin, dass CAPI ein weiteres JWT generiert, mit dem Sie Karten-Tokenisierungsprozesse starten, eine bestimmte Rechnung verwalten und der zurückgegebenen Rechnungsstruktur hinzufügen können.
Ein Beispiel für die in einem ähnlichen JWT beschriebenen Rollen:
"resource_access": { "common-api": { "roles": [ "invoices.18xtygvzFaa.payments:read", "invoices.18xtygvzFaa.payments:write", "invoices.18xtygvzFaa:read", "payment_resources:write" ] } }
Diese JWT hat eine begrenzte Anzahl von Versuchen und die von uns konfigurierte Lebensdauer, sodass Sie sie im Browser des Zahlers veröffentlichen können. Selbst wenn es abgefangen wird, kann ein Angreifer maximal die Rechnung eines anderen bezahlen oder seine Daten lesen. Da der Zahlungsautomat nicht mit offenen Kartendaten arbeitet, kann ein Angreifer maximal eine maskierte Kartennummer vom Typ 4242 42** **** 4242 , den Zahlungsbetrag und optional einen Warenkorb sehen.
Mit der erstellten Rechnung und dem Zugriffsschlüssel können Sie den Zahlungsgeschäftsprozess starten. Wir geben die Rechnungs-ID und deren JWT an den Zahlerbrowser weiter und übertragen die Kontrolle auf unsere JS-Anwendungen.
Unsere Checkout JS-Anwendung implementiert eine Schnittstelle für die Interaktion mit Ihnen als Zahler - zeichnet ein Zahlungsdateneingabeformular, startet eine Zahlung, erhält den endgültigen Status, zeigt einen lustigen oder traurigen Punkt.
Tokenisierung und Kartendaten

Checkout funktioniert jedoch nicht mit Kartendaten. Wie oben erwähnt, möchten wir sensible Daten in Form von Karteninhaberdaten an möglichst wenigen Orten speichern. Dazu implementieren wir die Tokenisierung.
Hier kommt die Tokenizer JS-Bibliothek ins Spiel. Wenn Sie Ihre Karte in die Eingabefelder eingeben und auf "Bezahlen" klicken, werden diese Daten abgefangen und asynchron zur Verarbeitung an uns gesendet, indem die Methode createPaymentResource () aufgerufen wird.
Diese Anforderung wird für einzelne CAPI-DSS-Anwendungen ausgeglichen, die die Anforderung auch nur durch Überprüfen der Rechnungs-JWT autorisieren, die Daten validieren und per tront an den Kartendatenspeicherdienst senden. In der Abbildung wird es als CDS - Card Data Storage angezeigt.
Die Hauptziele dieses Dienstes:
- Empfangen sensibler Daten über eine Eingabe, in unserem Fall - Daten Ihrer Karte;
- diese Daten mit einem Datenverschlüsselungsschlüssel verschlüsseln;
- einen zufälligen Wert erzeugen, der als Schlüssel verwendet wird;
- Speichern Sie verschlüsselte Daten auf diesem Schlüssel in Ihrem Riak-Cluster.
- Senden Sie den Schlüssel in Form eines Zahlungsdaten-Tokens an den CAPI-DSS-Dienst zurück.
Unterwegs löst der Dienst eine Reihe wichtiger Aufgaben, z. B. das Generieren von Schlüsseln zum Verschlüsseln von Schlüsseln, das sichere Eingeben dieser Schlüssel, das erneute Verschlüsseln von Daten, das Steuern des Löschens von CVV nach der Zahlung usw. Dies geht jedoch über den Rahmen dieses Beitrags hinaus.
Es war nicht ohne Schutz vor der Möglichkeit, sich in den Fuß zu schießen. Es besteht eine Wahrscheinlichkeit ungleich Null, dass ein privates JWT, mit dem Anforderungen vom Backend autorisiert werden sollen, im Internet im Browser des Clients veröffentlicht wird. Um dies zu verhindern, haben wir einen integrierten Schutz eingerichtet. Sie können die Methode createPaymentResource () nur mit dem Rechnungsautorisierungsschlüssel aufrufen. Wenn Sie versuchen, eine private JWT-Plattform zu verwenden, wird ein HTTP / 401-Fehler zurückgegeben.
Nach Abschluss der Tokenisierungsanforderung sendet der Tokenizer das empfangene Token an Checkout zurück und beendet seine Arbeit daran.
Geschäftsprozess der Zahlungsmaschine

Checkout startet den Zahlungsvorgang, indem es die Methode createPayment () aufruft , das Token der zuvor empfangenen Kartendaten übergibt und den Vorgang des Abrufs von Ereignissen startet. Tatsächlich wird die API-Methode getInvoiceEvents () einmal pro Sekunde aufgerufen .
Diese Anforderungen über CAPI fallen in Hellgate, das mit der Implementierung eines Zahlungsgeschäftsprozesses beginnt, ohne Kartendaten zu verwenden:
- Zunächst wechselt Hellgate zum Konfigurationsverwaltungsdienst Dominant und erhält die aktuelle Version der Domänenkonfiguration. Es enthält alle Regeln, nach denen diese Zahlung erfolgt, für welche Bank die Autorisierung erfolgt, welche Transaktionsgebühren erfasst werden usw.
- Vom Mitgliederverwaltungsdienst, der jetzt Teil von HG ist, erfährt er Daten über die internen Nummern der Konten des Händlers, für die die Zahlung erfolgt, wendet den Gebührenbetrag an, erstellt einen Buchungsplan und stellt ihn in den Shumway-Dienst. Dieser Dienst ist für die Verwaltung von Informationen über die Geldbewegung auf den Konten der Teilnehmer einer Transaktion bei der Zahlung verantwortlich. Der Buchungsplan enthält die Anweisung, "die mögliche Bewegung von Geldern auf den Konten der Teilnehmer an der im Plan angegebenen Transaktion einzufrieren";
- bereichert Zahlungsdaten durch Bezugnahme auf zusätzliche Dienste, beispielsweise in Binbase, um das Land der ausstellenden Bank, die die Karte ausgestellt hat, und deren Typ herauszufinden, z. B. „Gold, Kredit“;
- Ruft in der Regel den Inspektorendienst an. Dies ist Antifraud, um eine Zahlungsbewertung zu erhalten und über die Wahl eines Terminals zu entscheiden, das das durch die Bewertung ausgegebene Risikograd abdeckt. Beispielsweise kann ein Terminal ohne 3D-Secure für Zahlungen mit geringem Risiko verwendet werden, und eine Zahlung, die ein schwerwiegendes Risiko erhalten hat, endet damit.
- ruft den Fehlererkennungsdienst, den Fehlerdetektor, auf und wählt auf der Grundlage der von ihm empfangenen Daten den Zahlungsweg aus - den Bankprotokolladapter, der derzeit die wenigsten Fehler und die höchste Wahrscheinlichkeit für eine erfolgreiche Zahlung aufweist;
- sendet eine Anfrage an den ausgewählten Bankprotokolladapter, sei es der YellowBank-Adapter, in diesem Fall "autorisiere den angegebenen Betrag von diesem Token".
Der Protokolladapter für das empfangene Token geht an CDS, empfängt die entschlüsselten Kartendaten, überträgt sie an ein bankspezifisches Protokoll und erhält im Allgemeinen eine Autorisierung - Bestätigung von der erwerbenden Bank, dass der angegebene Betrag auf dem Konto des Zahlers eingefroren wurde.
In diesem Moment erhalten Sie eine SMS mit einer Nachricht über die Abbuchung von Guthaben von Ihrer Karte von Ihrer Bank, obwohl das Guthaben tatsächlich nur auf Ihrem Konto eingefroren wurde.
Der Adapter benachrichtigt HG über die erfolgreiche Autorisierung, Ihr CVV-Code wird aus dem CDS-Dienst entfernt und dies ist das Ende der Interaktionsphase. Das Management kehrt zu HG zurück.

Abhängig von dem Aufruf von createPayment () , der vom Händler des Zahlungsgeschäftsprozesses angegeben wurde, erwartet HG Aufrufe von der externen API zur Autorisierungserfassungsmethode, dh Bestätigung des Abhebens von Geld von Ihrer Karte, oder sofort selbst, wenn der Händler das Schema gewählt hat einstufige Zahlung.
In der Regel verwenden die meisten Händler eine einstufige Zahlung. Es gibt jedoch Geschäftskategorien, die zum Zeitpunkt der Autorisierung den belasteten Gesamtbetrag noch nicht kennen. Dies ist in der Tourismusbranche häufig der Fall, wenn Sie eine Tour für einen Betrag buchen. Nach Bestätigung der Reservierung wird der Betrag angegeben und kann von dem zu Beginn genehmigten Betrag abweichen.
Trotz der Tatsache, dass der Bestätigungsbetrag ausschließlich gleich oder kleiner als der Autorisierungsbetrag sein kann, gibt es hier Fallstricke. Stellen Sie sich vor, Sie bezahlen ein Produkt oder eine Dienstleistung mit einer Karte in einer anderen Währung als der Währung Ihres Bankkontos, mit dem die Karte verknüpft ist.
Zum Zeitpunkt der Autorisierung wird der auf Ihrem Konto gesperrte Betrag basierend auf dem Wechselkurs am Tag der Autorisierung gesperrt. Da die Zahlung möglicherweise mehrere Tage lang den Status „genehmigt“ hat (obwohl das Eisenbahnministerium Empfehlungen für einen Höchstzeitraum hat und jetzt 3 Tage beträgt), erfolgt die Erfassung der Genehmigung zum Tagessatz.
Sie tragen also Währungsrisiken, die sowohl zu Ihren Gunsten als auch gegen Sie sein können, insbesondere in einer Situation hoher Volatilität am Devisenmarkt.
Um die Autorisierung zu erfassen, erfolgt der gleiche Kommunikationsprozess mit dem Protokolladapter wie für den Empfang. Bei Erfolg wendet HG den Kontobuchungsplan in Shumway an und überträgt die Zahlung in den Status "Bezahlt". In diesem Moment haben wir als Zahlungssystem finanzielle Verpflichtungen gegenüber den Teilnehmern der Transaktion.
Es ist auch erwähnenswert, dass alle Änderungen im Status des Rechnungsautomaten, einschließlich des Zahlungsvorgangs, von Hellgate in Machinegun aufgezeichnet werden, um die Datenpersistenz sicherzustellen und die Rechnung mit neuen Ereignissen anzureichern.
Statussynchronisation eines Zahlungsautomaten und der Benutzeroberfläche
Während der Hintergrundzahlungsprozess innerhalb der Plattform stattfindet, gießt Checkout die Verarbeitung durch Anfordern von Ereignissen. Nach Erhalt bestimmter Ereignisse zeichnet er den aktuellen Status der Zahlung in einer für eine Person verständlichen Form - zeichnet einen Preloader, zeigt den Bildschirm "Ihre Zahlung wurde erfolgreich verarbeitet" oder "Zahlung konnte nicht abgeschlossen werden" an oder leitet den Browser auf die Seite Ihrer ausstellenden Bank weiter, um das 3D-Secure-Passwort einzugeben.
Wenn dies fehlschlägt, bietet Checkout Ihnen an, eine andere Zahlungsmethode zu wählen oder es erneut zu versuchen, um eine neue Zahlung als Teil der Rechnung zu starten.
Ein solches Schema mit Abfrage von Ereignissen ermöglicht es, den Status auch nach dem Schließen der Browser-Registerkarte wiederherzustellen. Bei wiederholtem Start erhält Checkout die aktuelle Liste der Ereignisse und zeichnet das aktuelle Szenario der Benutzerinteraktion, schlägt beispielsweise die Eingabe des 3D-Secure-Codes vor oder zeigt an, dass die Zahlung bereits erfolgreich abgeschlossen wurde.
Replikation von Ereignissen in der Offline-Zone
Zusammen mit den Maschinensteuerungsschnittstellen implementiert Machinegun einen Dienst, der für den Überlauf des Ereignisflusses zu Diensten verantwortlich ist, die für andere, weniger Online-Aufgaben der Plattform verantwortlich sind.
Als Warteschlangenmakler im Finale haben wir uns für Kafka entschieden, obwohl wir diese Funktionalität zuvor mit Machinegun selbst implementiert haben. Im allgemeinen Fall handelt es sich bei diesem Dienst um die Aufrechterhaltung eines garantierten geordneten Ereignisstroms oder um die Herausgabe einer bestimmten Liste von Ereignissen auf Anfrage an andere Verbraucher.
Wir haben auch zunächst ein Ereignis-Deduplizierungsschema implementiert, das garantiert, dass dasselbe Ereignis nicht zweimal repliziert wird. Die Belastung von Riak, die durch ein ähnliches Ereignis generiert wurde, hat uns jedoch gezwungen, es aufzugeben - schließlich ist die Indexsuche nicht das Beste KV speicherfähig. Jetzt ist jeder Service-Consumer unabhängig für die Ereignis-Deduplizierung verantwortlich.
Im Allgemeinen endet die Replikation von Ereignissen durch Machinegun mit der Bestätigung der Datenspeicherung in Kafka. Die Verbraucher sind bereits mit den Kafka-Themen verbunden und laden die Liste der Ereignisse herunter, die sie interessieren.
Typische Offline-Zonenanwendungsvorlage
Der Dudoser-Dienst ist beispielsweise dafür verantwortlich, Ihnen eine E-Mail-Benachrichtigung über eine erfolgreiche Zahlung zu senden. Beim Start wird eine Liste der Ereignisse erfolgreicher Zahlungen ausgepumpt, von dort werden Informationen zu Adresse und Betrag abgerufen, in einer lokalen PostgreSQL-Instanz gespeichert und zur weiteren Verarbeitung der Geschäftslogik verwendet.
Alle anderen ähnlichen Dienste arbeiten nach derselben Logik, z. B. der Magista-Dienst, der für die Suche nach Rechnungen und Zahlungen auf dem persönlichen Konto des Händlers verantwortlich ist, oder der Hooker-Dienst, der asynchrone Rückrufe an das Backend an Händler sendet, die aus dem einen oder anderen Grund keine Abrufereignisse durch Kontaktaufnahme organisieren können direkt an die Verarbeitungs-API.
Dieser Ansatz ermöglicht es uns, die Verarbeitung zu entlasten, maximale Ressourcen zuzuweisen, eine hohe Geschwindigkeit und Verfügbarkeit der Zahlungsverarbeitung bereitzustellen und eine hohe Conversion zu erzielen. Schwere Anfragen wie "Geschäftskunden möchten Statistiken über Zahlungen im letzten Jahr sehen" werden von Diensten verarbeitet, die die aktuelle Auslastung des Online-Verarbeitungsteils nicht beeinflussen und Sie als Zahler und Händler daher nicht als unsere Kunden betreffen.
Vielleicht hören wir damit auf, um den Beitrag nicht zu lang zu machen. In zukünftigen Artikeln werde ich Ihnen auf jeden Fall die Nuancen der Sicherstellung der Atomizität von Änderungen, Garantien und Ordnungen in einem geladenen verteilten System anhand von Machinegun, Bender, CAPI und Hellgate als Beispiel erläutern.
Nun, über Salt Stack beim nächsten Mal ¯\_(ツ)_/¯