Im
ersten Teil des Artikels haben wir mit Ghidra automatisch ein einfaches Crack-Programm analysiert (das wir von crackmes.one heruntergeladen haben). Wir haben herausgefunden, wie "unverständliche" Funktionen direkt in der Dekompilerliste umbenannt werden können, und haben auch den Algorithmus des "Top Level" -Programms verstanden, d. H. was von
main () gemacht wird .
In diesem Teil werden wir, wie versprochen, die Analyse der Funktion
_construct_key () aufnehmen , die, wie wir herausgefunden haben, für das Lesen der an das Programm übertragenen Binärdatei und das Überprüfen der gelesenen Daten verantwortlich ist.
Schritt 5 - Übersicht über die Funktion _construct_key ()
Schauen wir uns gleich die vollständige Liste dieser Funktion an:
Listing _construct_key ()char ** __cdecl _construct_key(FILE *param_1) { int iVar1; size_t sVar2; uint uVar3; uint local_3c; byte local_36; char local_35; int local_34; char *local_30 [4]; char *local_20; undefined4 local_19; undefined local_15; char **local_14; int local_10; local_14 = (char **)__prepare_key(); if (local_14 == (char **)0x0) { local_14 = (char **)0x0; } else { local_19 = 0; local_15 = 0; _text(&local_19,1,4,param_1); iVar1 = _text((char *)&local_19,*(char **)local_14[1],4); if (iVar1 == 0) { _text(local_14[1] + 4,2,1,param_1); _text(local_14[1] + 6,2,1,param_1); if ((*(short *)(local_14[1] + 6) == 4) && (*(short *)(local_14[1] + 4) == 5)) { local_30[0] = *local_14; local_30[1] = *local_14 + 0x10c; local_30[2] = *local_14 + 0x218; local_30[3] = *local_14 + 0x324; local_20 = *local_14 + 0x430; local_10 = 0; while (local_10 < 5) { local_35 = 0; _text(&local_35,1,1,param_1); if (*local_30[local_10] != local_35) { _free_key(local_14); return (char **)0x0; } local_36 = 0; _text(&local_36,1,1,param_1); if (local_36 == 0) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x104) = (uint)local_36; _text(local_30[local_10] + 1,1,*(size_t *)(local_30[local_10] + 0x104),param_1); sVar2 = _text(local_30[local_10] + 1); if (sVar2 != *(size_t *)(local_30[local_10] + 0x104)) { _free_key(local_14); return (char **)0x0; } local_3c = 0; _text(&local_3c,1,1,param_1); local_3c = local_3c + 7; uVar3 = _text(param_1); if (local_3c < uVar3) { _free_key(local_14); return (char **)0x0; } *(uint *)(local_30[local_10] + 0x108) = local_3c; _text(param_1,local_3c,0); local_10 = local_10 + 1; } local_34 = 0; _text(&local_34,4,1,param_1); if (*(int *)(*local_14 + 0x53c) == local_34) { _text("Markers seem to still exist"); } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } else { _free_key(local_14); local_14 = (char **)0x0; } } return local_14; }
Mit dieser Funktion machen wir dasselbe wie zuvor mit
main () - zunächst werden wir die "verschleierten" Funktionsaufrufe durchgehen. Wie erwartet stammen alle diese Funktionen aus den Standard-C-Bibliotheken. Ich werde das Verfahren zum erneuten Umbenennen von Funktionen nicht beschreiben - kehren Sie gegebenenfalls zum ersten Teil des Artikels zurück. Durch das Umbenennen wurden folgende Standardfunktionen „gefunden“:
- fread ()
- strncmp ()
- strlen ()
- ftell ()
- fseek ()
- setzt ()
Wir haben die entsprechenden Wrapper-Funktionen in unserem Code umbenannt (diejenigen, die der Dekompiler dreist hinter dem Wort
_text versteckt
hat ), indem
wir Index 2 hinzugefügt haben (damit es nicht zu Verwechslungen mit den ursprünglichen C-Funktionen kommt). Fast alle diese Funktionen dienen zum Arbeiten mit Dateistreams. Es ist nicht überraschend - ein kurzer Blick auf den Code reicht aus, um zu verstehen, dass er nacheinander Daten aus einer Datei liest (deren Deskriptor als einziger Parameter an die Funktion übergeben wird) und die gelesenen Daten mit einem bestimmten zweidimensionalen Array von
local_14 Bytes vergleicht.
Nehmen wir an, dass dieses Array Daten zur Schlüsselüberprüfung enthält. Nennen Sie es, sagen Sie
key_array . Da Sie mit Hydra nicht nur Funktionen, sondern auch Variablen umbenennen können, werden wir dies verwenden und das unverständliche
local_14 in ein verständlicheres
key_array umbenennen . Dies geschieht auf die gleiche Weise wie bei Funktionen: über das Menü der rechten Maustaste (
lokal umbenennen ) oder über die
L- Taste auf der Tastatur.
Unmittelbar nach der Deklaration lokaler Variablen wird eine bestimmte Funktion
_prepare_key () aufgerufen :
key_array = (char **)__prepare_key(); if (key_array == (char **)0x0) { key_array = (char **)0x0; }
Wir kehren zu
_prepare_key () zurück . Dies ist die 3. Verschachtelungsebene in unserer
Aufrufhierarchie :
main () -> _construct_key () -> _prepare_key () . In der Zwischenzeit akzeptieren wir, dass es dieses zweidimensionale "Test" -Array erstellt und irgendwie initialisiert. Und nur wenn dieses Array nicht leer ist, setzt die Funktion ihre Arbeit fort, wie der
else- Block unmittelbar nach der obigen Bedingung zeigt.
Als nächstes liest das Programm die ersten 4 Bytes aus der Datei und vergleicht sie mit dem entsprechenden Abschnitt des Arrays
key_array . (Der folgende Code ist nach dem Umbenennen, einschließlich der Variablen
local_19, ich habe
first_4bytes umbenannt.)
first_4bytes = 0; fread2(&first_4bytes,1,4,param_1); iVar1 = strncmp2((char *)&first_4bytes,*(char **)key_array[1],4); if (iVar1 == 0) { ... }
Eine weitere Ausführung erfolgt daher nur, wenn die ersten 4 Bytes übereinstimmen (denken Sie daran). Dann lesen wir 2 2-Byte-Blöcke aus der Datei (und dasselbe
key_array wird als Puffer zum Schreiben von Daten verwendet):
fread2(key_array[1] + 4,2,1,param_1); fread2(key_array[1] + 6,2,1,param_1);
Und wieder - weiter funktioniert die Funktion nur, wenn die nächste Bedingung erfüllt ist:
if ((*(short *)(key_array[1] + 6) == 4) && (*(short *)(key_array[1] + 4) == 5)) {
Es ist leicht zu erkennen, dass der erste der oben gelesenen 2-Byte-Blöcke die Nummer 5 und der zweite die Nummer 4 sein sollte (der Datentyp
short belegt auf 32-Bit-Plattformen nur 2 Byte).
Als nächstes ist dies:
local_30[0] = *key_array;
Hier sehen wir, dass das
local_30- Array (deklariert als char * local_30 [4]) die Offsets des
key_array- Zeigers enthält. Das heißt,
local_30 ist ein Array von Markierungszeilen, in die die Daten aus der Datei wahrscheinlich gelesen werden. Unter dieser Annahme habe ich
local_30 in
marker umbenannt. In diesem Codeabschnitt erscheint nur die letzte Zeile etwas verdächtig, wobei die Zuweisung des letzten Versatzes (bei Index 0x430, d. H. 1072) nicht vom nächsten
Markierungselement , sondern von einer separaten Variablen
local_20 (
char * ) ausgeführt wird. Aber wir werden es noch herausfinden, aber jetzt - lass uns weitermachen!
Als nächstes warten wir auf einen Zyklus:
i = 0;
Das heißt, Nur 5 Iterationen von 0 bis einschließlich 4. In der Schleife beginnt sofort das Lesen aus der Datei und das Überprüfen der Übereinstimmung mit unserem
Marker- Array:
char c_marker = 0;
Das heißt, das nächste Byte aus der Datei wird in die Variable
c_marker (im ursprünglichen dekompilierten Code -
local_35 )
eingelesen und auf Übereinstimmung mit dem ersten Zeichen des i-ten
Markierungselements überprüft. Im Falle einer
Nichtübereinstimmung wird das Array
key_array aufgehoben und ein leerer Doppelzeiger zurückgegeben. Weiter unten im Code sehen wir, dass dies immer dann geschieht, wenn die gelesenen Daten nicht mit den Verifizierungsdaten übereinstimmen.
Aber hier, wie sie sagen, "ist der Hund begraben." Schauen wir uns diesen Zyklus genauer an. Es hat 5 Iterationen, wie wir herausgefunden haben. Sie können dies überprüfen, wenn Sie möchten, indem Sie sich den Assembler-Code ansehen:


In der Tat vergleicht der CMP-Befehl den Wert der Variablen
local_10 (wir haben bereits
i ) mit der Zahl 4, und wenn der Wert
kleiner oder gleich 4 ist (der JLE-Befehl), erfolgt der Übergang zur Bezeichnung
LAB_004017eb , d. H. Beginn des Zykluskörpers. Das heißt, Die Bedingung wird für
i = 0, 1, 2, 3 und 4 erfüllt - nur 5 Iterationen! Alles wäre in Ordnung, aber
Marker werden auch von dieser Variablen in einer Schleife indiziert, und schließlich wird dieses Array mit nur 4 Elementen deklariert:
char *markers [4];
Also versucht jemand eindeutig, jemanden zu täuschen :) Erinnerst du dich, ich sagte, dass diese Zeile zweifelhaft ist?
local_20 = *key_array + 0x430;
Einfach so! Schauen Sie sich einfach die gesamte Liste der Funktion an und versuchen Sie, mindestens einen weiteren Verweis auf die Variable
local_20 zu finden. Sie ist nicht da! Wir schließen daraus: Dieser Offset sollte auch im
Marker- Array gespeichert werden, und das Array selbst sollte 5 Elemente enthalten. Lass es uns reparieren. Gehen Sie zur Variablendeklaration,
drücken Sie Strg + L (Variable erneut eingeben) und ändern Sie die Größe des Arrays mutig auf 5:
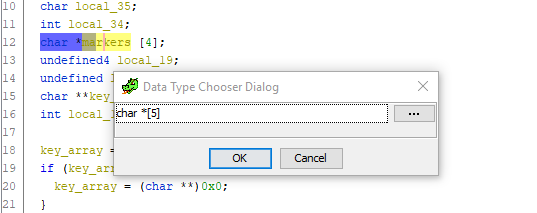
Fertig. Scrollen Sie nach unten zum Code, um
Markern Zeigerversätze
zuzuweisen , und - siehe da! - Eine unverständliche zusätzliche Variable verschwindet und alles passt zusammen:
markers[0] = *key_array; markers[1] = *key_array + 0x10c; markers[2] = *key_array + 0x218; markers[3] = *key_array + 0x324; markers[4] = *key_array + 0x430;
Wir kehren zu unserer
while-Schleife zurück (im Quellcode ist dies höchstwahrscheinlich der Fall, aber das ist uns egal). Als nächstes wird das Byte aus der Datei erneut gelesen und sein Wert überprüft:
byte n_strlen1 = 0;
OK, dieses
n_strlen1 muss ungleich Null sein. Warum? Sie werden es jetzt sehen, aber gleichzeitig werden Sie verstehen, warum ich dieser Variablen den folgenden Namen gegeben habe:
*(uint *)(markers[i] + 0x104) = (uint)n_strlen1; fread2(markers[i] + 1,1,*(size_t *)(markers[i] + 0x104),param_1); n_strlen2 = strlen2(markers[i] + 1);
Ich habe Kommentare hinzugefügt, zu denen alles klar sein sollte.
N_strlen1 Bytes werden aus der Datei gelesen und als Folge von Zeichen (dh als Zeichenfolge) im
Marker [i] -Array gespeichert - also nach dem entsprechenden „
Stoppsymbol “, das dort bereits von
key_array geschrieben wurde . Das Speichern des Wertes
n_strlen1 in
Markern [i] bei Offset 0x104 (260) spielt hier keine Rolle (siehe erste Zeile im obigen Code). Tatsächlich kann dieser Code wie folgt optimiert werden (und dies ist sicherlich im Quellcode der Fall):
fread2(markers[i] + 1, 1, (size_t) n_strlen1, param_1); n_strlen2 = strlen2(markers[i] + 1); if (n_strlen2 != (size_t) n_strlen1) { ... }
Es wird auch überprüft, ob die Länge der gelesenen Zeile
n_strlen1 ist . Dies mag unnötig erscheinen, da dieser Parameter an die
Fread- Funktion übergeben wurde,
Fread jedoch nicht mehr als so viele angegebene Bytes liest und weniger als angegeben lesen kann, z. B. wenn der Dateiende-Marker (EOF) erreicht wird. Das heißt, alles ist streng: Die Länge der Zeile (in Bytes) wird in der Datei angegeben, dann geht die Zeile selbst - und genau fünfmal. Aber wir sind uns selbst voraus.
Weitere Gewässer dieser Code (den ich auch sofort kommentiert habe):
uint n_pos = 0;
Hier ist es noch einfacher: Wir nehmen das nächste Byte aus der Datei, addieren 7 und vergleichen den resultierenden Wert mit der aktuellen Cursorposition im Dateistream, die mit der Funktion
ftell () erhalten wurde . Der Wert von
n_pos darf nicht kleiner als die Cursorposition sein (d. H. Versetzt in Bytes vom Anfang der Datei).
Die letzte Zeile in der Schleife:
fseek2(param_1,n_pos,0);
Das heißt,
Ordnen Sie den
Dateicursor ( von Anfang an) an der Position an, die von
n_pos durch die Funktion
fseek () angegeben wird. OK, wir führen alle diese Operationen fünfmal in der Schleife aus. Die Funktion
_construct_key () endet mit dem folgenden Code:
int i_lastmarker = 0;
Daher sollte der letzte Datenblock in der Datei ein 4-Byte-Integer-Wert sein und dem Wert in
key_array [0] [1340] entsprechen . In diesem Fall erhalten wir eine Glückwunschbotschaft in der Konsole. Ansonsten kehrt das leere Array immer noch ohne Lob zurück :)
Schritt 6 - Übersicht über die Funktion __prepare_key ()
Wir haben nur noch eine nicht zusammengesetzte Funktion -
__prepare_key () . Wir haben bereits vermutet, dass darin die Verifizierungsdaten in Form des Arrays
key_array generiert werden, das dann in der Funktion
_construct_key () verwendet wird, um die Daten aus der Datei zu überprüfen. Es bleibt abzuwarten, welche Art von Daten es gibt!
Ich werde diese Funktion nicht im Detail analysieren und sofort eine vollständige Auflistung mit Kommentaren nach allen notwendigen Umbenennungen von Variablen geben:
__Prepare_key () Funktionsliste void ** __prepare_key(void) { void **key_array; void *pvVar1; key_array = (void **)calloc2(1,8); if (key_array == (void **)0x0) { key_array = (void **)0x0; } else { pvVar1 = calloc2(1,0x540); *key_array = pvVar1; pvVar1 = calloc2(1,8); key_array[1] = pvVar1; *(undefined4 *)key_array[1] = 0x404024; *(undefined2 *)((int)key_array[1] + 4) = 5; *(undefined2 *)((int)key_array[1] + 6) = 4; *(undefined *)*key_array = 0x62; *(undefined4 *)((int)*key_array + 0x104) = 3; *(undefined *)((int)*key_array + 0x218) = 0x57; *(undefined *)((int)*key_array + 0x324) = 0x70; *(undefined *)((int)*key_array + 0x10c) = 0x6c; *(undefined *)((int)*key_array + 0x430) = 0x98; *(undefined4 *)((int)*key_array + 0x53c) = 0x462; } return key_array; }
Der einzige Ort, der in Betracht gezogen werden sollte, ist diese Zeile:
*(undefined4 *)key_array[1] = 0x404024;
Wie verstehe ich, dass hier die Zeile "VOID" liegt? Tatsache ist, dass 0x404024 die Adresse im Adressraum des Programms ist, das
zum Abschnitt
.rdata führt . Durch Doppelklicken auf diesen Wert können wir klar erkennen, was sich dort befindet:

Dasselbe kann übrigens aus dem Assembler-Code für diese Zeile verstanden werden:
004015da c7 00 24 MOV dword ptr [EAX], .rdata = 56h V
40 40 00
Die der VOID-Zeile entsprechenden Daten befinden sich ganz am Anfang des
.rdata- Abschnitts (bei einem Versatz von Null von der entsprechenden Adresse).
Am Ende dieser Funktion sollte also ein zweidimensionales Array mit den folgenden Daten gebildet werden:
[0] [0]:'b' [268]:'l' [536]:'W' [804]:'p' [1072]:152 [1340]:1122
[1] [0-3]:"VOID" [4-5]:5 [6-7]:4
Schritt 7 - Bereiten Sie die Binärdatei für den Riss vor
Jetzt können wir mit der Synthese der Binärdatei beginnen. Alle ersten Daten in unseren Händen:
1) Verifizierungsdaten ("Stoppsymbole") und ihre Positionen im Verifizierungsarray;
2) die Reihenfolge der Daten in der Datei
Stellen wir die Struktur der
gesuchten Datei gemäß dem Algorithmus der Funktion
_construct_key () wieder her . Die Reihenfolge der Daten in der Datei ist also wie folgt:
Dateistruktur- 4 Bytes == key_array [1] [0 ... 3] == "VOID"
- 2 Bytes == key_array [1] [4] == 5
- 2 Bytes == key_array [1] [6] == 4
- 1 Byte == key_array [0] [0] == 'b' (Token)
- 1 Byte == (nächste Zeilenlänge) == n_strlen1
- n_strlen1 Bytes == (beliebiger String) == n_strlen1
- 1 Byte == (+7 == nächster Token) == n_pos
- 1 Byte == key_array [0] [0] == 'l' (Token)
- 1 Byte == (nächste Zeilenlänge) == n_strlen1
- n_strlen1 Bytes == (beliebiger String) == n_strlen1
- 1 Byte == (+7 == nächster Token) == n_pos
- 1 Byte == key_array [0] [0] == 'W' (Token)
- 1 Byte == (nächste Zeilenlänge) == n_strlen1
- n_strlen1 Bytes == (beliebiger String) == n_strlen1
- 1 Byte == (+7 == nächster Token) == n_pos
- 1 Byte == key_array [0] [0] == 'p' (Token)
- 1 Byte == (nächste Zeilenlänge) == n_strlen1
- n_strlen1 Bytes == (beliebiger String) == n_strlen1
- 1 Byte == (+7 == nächster Token) == n_pos
- 1 Byte == key_array [0] [0] == 152 (Token)
- 1 Byte == (nächste Zeilenlänge) == n_strlen1
- n_strlen1 Bytes == (beliebiger String) == n_strlen1
- 1 Byte == (+7 == nächster Token) == n_pos
- 4 Bytes == (key_array [1340]) == 1122
Aus Gründen der Übersichtlichkeit habe ich in Excel ein solches Tablet mit den Daten der gewünschten Datei erstellt:

Hier in der 7. Zeile - die Daten selbst in Form von Zeichen und Zahlen, in der 6. Zeile - ihre hexadezimalen Darstellungen, in der 8. Zeile - die Größe jedes Elements (in Bytes), in der 9. Zeile - der Versatz relativ zum Anfang der Datei. Diese Ansicht ist sehr praktisch, weil Mit dieser Option können Sie beliebige Zeilen in die zukünftige Datei eingeben (mit einer gelben Füllung markiert), während die Werte der Längen dieser Zeilen sowie die Positionsversätze des nächsten Stoppsymbols automatisch durch Formeln berechnet werden, wie es der Programmalgorithmus erfordert. Oben (in den Zeilen 1 bis 4) ist die Struktur des Check-Arrays
key_array dargestellt .
Das Excel selbst sowie andere Quellenmaterialien für den Artikel können hier heruntergeladen
werden .
Generierung und Validierung von Binärdateien
Das einzige, was noch übrig bleibt, ist, die gewünschte Datei im Binärformat zu generieren und sie mit unserem Crack zu füttern. Um die Datei zu generieren, habe ich ein einfaches Python-Skript geschrieben:
Skript zum Generieren der Datei import sys, os import struct import subprocess out_str = ['!', 'I', ' solved', ' this', ' crackme!'] def write_file(file_path): try: with open(file_path, 'wb') as outfile: outfile.write('VOID'.encode('ascii')) outfile.write(struct.pack('2h', 5, 4)) outfile.write('b'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[0]))) outfile.write(out_str[0].encode('ascii')) pos = 10 + len(out_str[0]) outfile.write(struct.pack('B', pos - 6)) outfile.write('l'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[1]))) outfile.write(out_str[1].encode('ascii')) pos += 3 + len(out_str[1]) outfile.write(struct.pack('B', pos - 6)) outfile.write('W'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[2]))) outfile.write(out_str[2].encode('ascii')) pos += 3 + len(out_str[2]) outfile.write(struct.pack('B', pos - 6)) outfile.write('p'.encode('ascii')) outfile.write(struct.pack('B', len(out_str[3]))) outfile.write(out_str[3].encode('ascii')) pos += 3 + len(out_str[3]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('B', 152)) outfile.write(struct.pack('B', len(out_str[4]))) outfile.write(out_str[4].encode('ascii')) pos += 3 + len(out_str[4]) outfile.write(struct.pack('B', pos - 6)) outfile.write(struct.pack('i', 1122)) except Exception as err: print(err) raise def main(): if len(sys.argv) != 2: print('USAGE: {this_script.py} path_to_crackme[.exe]') return if not os.path.isfile(sys.argv[1]): print('File "{}" unavailable!'.format(sys.argv[1])) return file_path = os.path.splitext(sys.argv[1])[0] + '.dat' try: write_file(file_path) except: return try: outputstr = subprocess.check_output('"{}" -f "{}"'.format(sys.argv[1], file_path), stderr=subprocess.STDOUT) print(outputstr.decode('utf-8')) except Exception as err: print(err) if __name__ == '__main__': main()
Das Skript nimmt den Pfad zu den Rissen als einen einzelnen Parameter, generiert dann eine Binärdatei mit dem Schlüssel im selben Verzeichnis und ruft die Risse mit dem entsprechenden Parameter auf, wodurch die Programmausgabe in die Konsole übersetzt wird.
Verwenden Sie das
Strukturpaket, um Textdaten in Binärdaten zu konvertieren. Mit der
pack () -Methode können Sie Binärdaten in einem Format schreiben, in dem der Datentyp angegeben ist ("B" = "Byte", "i" = int usw.), und Sie können auch die Reihenfolge angeben (">" = "Big" -endian "," <"=" Little-endian "). Die Standardreihenfolge ist Little-Endian. Weil Wir haben bereits im ersten Artikel festgestellt, dass dies genau unser Fall ist, dann geben wir nur den Typ an.
Der gesamte Code gibt den gefundenen Programmalgorithmus wieder. Als die Zeile, die gedruckt werden soll, wenn sie erfolgreich ist, habe ich angegeben "Ich habe dieses Crackme gelöst!" (Sie können dieses Skript so ändern, dass eine beliebige Zeile angegeben werden kann.)
Überprüfen Sie die Ausgabe:

Hurra, alles funktioniert! Nachdem wir ein wenig geschwitzt und einige Funktionen aussortiert hatten, konnten wir den Programmalgorithmus vollständig wiederherstellen und ihn „knacken“. Natürlich ist dies nur ein einfacher Riss, ein Testprogramm und sogar das des 2. Schwierigkeitsgrades (von 5, die auf dieser Site angeboten werden). In der Realität werden wir uns mit einer komplexen Hierarchie von Aufrufen und Dutzenden - Hunderten von Funktionen und in einigen Fällen - verschlüsselten Abschnitten von Daten, Müllcode und anderen Verschleierungstechniken bis hin zur Verwendung interner virtueller Maschinen und P-Codes befassen ... Aber das ist, wie sie sagen, bereits eine ganz andere Geschichte.
Materialien für den Artikel.