
Am 28. Februar hielt ich eine Präsentation beim SphinxSearch-Treffen , das in unserem Büro stattfand. Er sprach darüber, wie wir aus der regelmäßigen Neuerstellung von Indizes für die Volltextsuche und dem Senden von Aktualisierungen des Codes „an Ort und Stelle“ an Bahnzeitindizes und der automatischen Synchronisierung des Status des Index und der MariaDB-Datenbank hervorgegangen sind. Eine Videoaufzeichnung meines Berichts ist über den Link verfügbar. Für diejenigen, die lieber lesen als das Video ansehen, habe ich diesen Artikel geschrieben.
Ich werde damit beginnen, wie unsere Suche arrangiert wurde und warum wir das alles begonnen haben.
Unsere Suche wurde nach einem völlig Standardschema organisiert.
Vom Front-End kommen Benutzeranforderungen an den in PHP geschriebenen Anwendungsserver, und dieser kommuniziert wiederum mit der Datenbank (wir haben MariaDB). Wenn wir eine Suche durchführen müssen, wendet sich der Anwendungsserver an den Balancer (wir haben Haproxy), der ihn mit einem der Server verbindet, auf denen searchd ausgeführt wird. Dieser Server führt bereits eine Suche durch und gibt das Ergebnis zurück.
Daten aus der Datenbank fallen auf ganz traditionelle Weise in den Index: Gemäß dem Zeitplan erstellen wir den Index alle paar Minuten mit den Dokumenten neu, die vor relativ kurzer Zeit aktualisiert wurden, und erstellen den Index mit den sogenannten "archivierten" Dokumenten (dh mit denen, mit denen Lange ist nichts passiert). Es sind einige Computer für die Indizierung zugewiesen. Dort wird nach einem Zeitplan ein Skript ausgeführt, das zuerst den Index erstellt, die Indexdateien dann auf besondere Weise umbenennt und dann in einem separaten Ordner ablegt. Und auf jedem der Server mit searchd wird rsync einmal pro Minute gestartet, wodurch die Dateien aus diesem Ordner in den Ordner searchd indexes kopiert werden. Wenn dann etwas kopiert wurde, wird die Anforderung RELOAD INDEX ausgeführt.
Für einige Änderungen bei Lebensläufen und offenen Stellen war es jedoch erforderlich, dass sie den Index so schnell wie möglich „erreichen“. Wenn beispielsweise eine öffentlich zugängliche Stelle aus der Veröffentlichung entfernt wird, ist aus Sicht des Benutzers zu erwarten, dass sie innerhalb weniger Sekunden nicht mehr aus dem Problem verschwindet. Daher werden diese Änderungen direkt über searchd mithilfe von UPDATE-Abfragen gesendet. Damit diese Änderungen auf alle Kopien von Indizes auf allen unseren Servern angewendet werden, wird für jede Suche ein verteilter Index eingerichtet, der Aktualisierungen der Attribute an alle Suchinstanzen sendet. Der Anwendungsserver stellt weiterhin eine Verbindung zum Balancer her und sendet eine Anforderung zum Aktualisieren des verteilten Index. Daher muss er weder die Liste der Server mit searchd im Voraus kennen, noch wird er genau wissen, zu welchem Server mit searchd.
Das alles hat ziemlich gut funktioniert, aber es gab Probleme.
- Die durchschnittliche Verzögerung zwischen der Erstellung eines Dokuments (dies ist ein Lebenslauf oder eine freie Stelle für uns) und seiner Aufnahme in den Index war direkt proportional zu ihrer Anzahl in unserer Datenbank.
- Da wir den verteilten Index zum Verteilen von Attributaktualisierungen verwendet haben, konnten wir nicht garantieren, dass diese Aktualisierungen auf alle Kopien des Index angewendet wurden.
- Die „dringenden“ Änderungen, die während der Neuerstellung des Index aufgetreten sind, gingen bei der Ausführung des Befehls
RELOAD INDEX verloren (einfach, weil sie noch nicht im neu erstellten Index enthalten waren) und wurden erst nach der nächsten Neuindizierung in den Index aufgenommen. 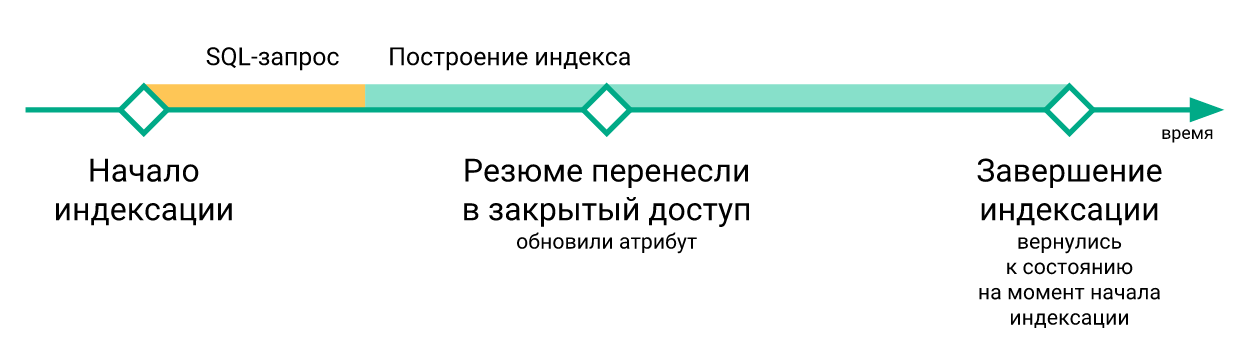
- Die Skripte zum Aktualisieren von Indizes auf Servern mit searchd wurden unabhängig voneinander ausgeführt, es gab keine Synchronisation zwischen ihnen. Aus diesem Grund kann die Verzögerung zwischen der Aktualisierung des Index auf verschiedenen Servern mehrere Minuten betragen.
- Wenn etwas im Zusammenhang mit der Suche getestet werden musste, musste der Index nach jeder Änderung neu erstellt werden.
Jedes dieser Probleme war für sich genommen keine grundlegende Überarbeitung der Suchinfrastruktur wert, aber zusammengenommen haben sie das Leben spürbar verdorben.
Wir haben uns entschlossen, die oben genannten Probleme mithilfe von Sphinx-Echtzeitindizes zu lösen. Darüber hinaus hat uns der Übergang zu RT-Indizes nicht gereicht. Um Datenrennen endgültig loszuwerden, musste sichergestellt werden, dass alle Aktualisierungen von der Anwendung auf den Index denselben Kanal durchlaufen haben. Außerdem mussten die Änderungen, die während der Neuerstellung des Index an der Datenbank vorgenommen wurden, irgendwo gespeichert werden (schließlich ist es manchmal erforderlich, ihn neu zu erstellen, aber die Prozedur erfolgt nicht sofort).
Wir haben beschlossen, die Verbindung über das MySQL-Replikationsprotokoll als Datenübertragungskanal herzustellen, und im MySQL-Binlog können die Änderungen gespeichert werden, während der Index neu erstellt wird. Mit dieser Lösung konnten wir das Schreiben in Sphinx aus dem Anwendungscode entfernen. Und da wir zu diesem Zeitpunkt bereits eine zeilenbasierte Replikation mit einer globalen Transaktions-ID verwendet hatten, konnte der Wechsel zwischen Datenbankreplikaten ganz einfach durchgeführt werden.
Die Idee, eine direkte Verbindung zur Datenbank herzustellen, um von dort Änderungen für das Senden an den Index zu erhalten, ist natürlich nicht neu: 2016 haben Kollegen von Avito eine Präsentation gehalten, in der sie ausführlich beschrieben haben, wie sie das Problem der Synchronisierung von Daten in Sphinx mit der Hauptdatenbank gelöst haben. Wir haben uns entschlossen, ihre Erfahrung zu nutzen und ein ähnliches System für uns zu entwickeln, mit dem Unterschied, dass wir nicht PostgreSQL, sondern MariaDB und den alten Sphinx-Zweig (nämlich Version 2.3.2) haben.
Wir haben einen Dienst erstellt, der Änderungen in MariaDB abonniert und den Index in Sphinx aktualisiert. Seine Aufgaben sind wie folgt:
- Verbindung zum MariaDB-Server über das Replikationsprotokoll und Empfangen von Ereignissen aus dem Binlog;
- Verfolgen der aktuellen Binlog-Position und der Nummer der zuletzt abgeschlossenen Transaktion;
- Filtern von Binlog-Ereignissen;
- herauszufinden, welche Dokumente im Index hinzugefügt, gelöscht oder aktualisiert werden müssen und für aktualisierte Dokumente - welche Felder müssen aktualisiert werden;
- Anfrage nach fehlenden Daten von MariaDB;
- Generierung und Ausführung von Indexaktualisierungsanforderungen;
- Erstellen Sie den Index bei Bedarf neu.
Wir haben eine Verbindung mithilfe des Replikationsprotokolls mithilfe der go-mysql- Bibliothek hergestellt. Sie ist dafür verantwortlich, eine Verbindung mit MariaDB herzustellen, Replikationsereignisse zu lesen und an einen Handler weiterzuleiten. Dieser Handler startet in Goroutine, die von der Bibliothek gesteuert wird, aber wir schreiben den Handlercode selbst. Im Handlercode werden Ereignisse mit einer Liste von Tabellen überprüft, die uns interessieren, und die Änderungen an diesen Tabellen werden zur Verarbeitung gesendet. Unser Handler speichert auch den Transaktionsstatus. Dies liegt daran, dass die Ereignisse im Replikationsprotokoll in der richtigen Reihenfolge sind: GTID (Beginn der Transaktion) -> ROW (Änderung der Daten) -> XID (Ende der Transaktion) und nur die erste von ihnen enthält Informationen zur Transaktionsnummer. Es ist für uns bequemer, die Transaktionsnummer zusammen mit ihrem Abschluss zu übertragen, um Informationen darüber zu speichern, auf welche Position im Binlog die Änderungen angewendet wurden. Dazu müssen wir uns die Nummer der aktuellen Transaktion zwischen ihrem Beginn und ihrem Abschluss merken.
MySQL [(none)]> describe sync_state; +-----------------+--------+ | Field | Type | +-----------------+--------+ | id | bigint | | dummy_field | field | | binlog_position | uint | | binlog_name | string | | gtid | string | | flavor | string | +-----------------+--------+
Wir speichern die Nummer der zuletzt abgeschlossenen Transaktion in einem speziellen Index aus einem Dokument auf jedem Server mit searchd. Zu Beginn des Dienstes überprüfen wir, ob die Indizes initialisiert sind und die erwartete Struktur aufweisen sowie ob die gespeicherte Position auf allen Servern vorhanden und auf allen Servern gleich ist. Wenn diese Überprüfungen erfolgreich waren und wir das Binlog von der gespeicherten Position aus lesen konnten, beginnen wir mit dem Synchronisierungsvorgang. Wenn die Überprüfungen fehlschlagen oder das Binlog nicht von der gespeicherten Position aus gelesen werden konnte, setzen wir die gespeicherte Position auf die aktuelle Position des MariaDB-Servers zurück und erstellen den Index neu.
Die Verarbeitung von Replikationsereignissen beginnt mit der Bestimmung, welche Dokumente von einer bestimmten Änderung in der Datenbank betroffen sind. Zu diesem Zweck haben wir in der Konfiguration unseres Dienstes so etwas wie das Routing für Zeilenänderungsereignisse in den für uns interessanten Tabellen durchgeführt, dh eine Reihe von Regeln, um zu bestimmen, wie Änderungen in der Datenbank indiziert werden sollen.
[[ingest]] table = "vacancy" id_field = "id" index = "vacancy" [ingest.column_map] user_id = ["user_id"] edited_at = ["date_edited"] profession = ["profession"] latitude = ["latitude_deg", "latitude_rad"] longitude = ["longitude_deg", "longitude_rad"] [[ingest]] table = "vacancy_language" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] language_id = ["languages"] level = ["languages"] [[ingest]] table = "vacancy_metro_station" id_field = "vacancy_id" index = "vacancy" [ingest.column_map] metro_station_id = ["metro"]
Mit diesem vacancy_metro_station sollten sich beispielsweise Änderungen an den vacancy_metro_station vacancy , " vacancy_language und " vacancy_metro_station im vacancy_metro_station . Die vacancy_id kann im Feld id für die vacancy_id und im Feld vacancy_id für die beiden anderen Tabellen angegeben werden. Das Feld column_map ist eine Tabelle zur Abhängigkeit von Indexfeldern von den Feldern verschiedener Datenbanktabellen.
Wenn wir die Liste der von den Änderungen betroffenen Dokumente erhalten haben, müssen wir sie im Index aktualisieren, jedoch nicht sofort. Zuerst akkumulieren wir Änderungen für jedes Dokument und senden die Änderungen an den Index, sobald eine kurze Zeit (wir haben 100 Millisekunden) nach der letzten Änderung dieses Dokuments verstrichen sind.
Wir haben uns dazu entschlossen, um viele unnötige Indexaktualisierungen zu vermeiden, da in vielen Fällen eine einzelne logische Änderung an einem Dokument mithilfe mehrerer SQL-Abfragen erfolgt, die sich auf verschiedene Tabellen auswirken und manchmal in völlig unterschiedlichen Transaktionen ausgeführt werden.
Ich werde ein einfaches Beispiel geben. Angenommen, ein Benutzer hat eine freie Stelle bearbeitet. Der Code, der für das Speichern von Änderungen verantwortlich ist, wird der Einfachheit halber häufig folgendermaßen geschrieben:
BEGIN; UPDATE vacancy SET edited_at = NOW() WHERE id = 123; DELETE FROM vacancy_language WHERE vacancy_id = 123; INSERT INTO vacancy_language (vacancy_id, language_id, level) VALUES (123, 1, "fluent"), (123, 2, "technical"); DELETE FROM vacancy_metro_station WHERE vacancy_id = 123; INSERT INTO vacancy_metro_station (vacancy_id, metro_station_id) VALUES (123, 55); ... COMMIT;
Mit anderen Worten, zuerst werden alle alten Datensätze aus den verknüpften Tabellen gelöscht und dann neue eingefügt. Gleichzeitig werden im Binlog weiterhin Einträge zu diesen Löschungen und Einfügungen vorhanden sein, auch wenn sich im Dokument nichts geändert hat.
Um nur das zu aktualisieren, was benötigt wird, haben wir Folgendes getan: Sortieren Sie die geänderten Zeilen so, dass für jedes Index-Dokument-Paar alle Änderungen in chronologischer Reihenfolge abgerufen werden können. Anschließend können wir sie nacheinander anwenden, um festzustellen, welche Felder in welchen Tabellen sich letztendlich geändert haben und welche nicht. Anschließend können wir mithilfe der column_map eine Liste der Felder und column_map , die für jedes betroffene Dokument aktualisiert werden müssen. Darüber hinaus können Ereignisse, die sich auf ein Dokument beziehen, nicht nacheinander eintreffen, sondern als „anders“, wenn sie in verschiedenen Transaktionen ausgeführt werden. Wenn wir jedoch feststellen können, welche Dokumente sich geändert haben, hat dies keine Auswirkungen.
Gleichzeitig konnten wir mit diesem Ansatz nur die Attribute des Index aktualisieren, wenn keine Änderungen in den Textfeldern vorgenommen wurden, und das Senden von Änderungen an Sphinx kombinieren.
Jetzt können wir herausfinden, welche Dokumente im Index aktualisiert werden müssen.
In vielen Fällen reichen die Daten aus dem Binlog nicht aus, um eine Anforderung zum Aktualisieren des Index zu erstellen. Daher erhalten wir die fehlenden Daten von demselben Server, von dem aus wir das Binlog lesen. Hierzu gibt es in der Konfiguration unseres Dienstes eine Anforderungsvorlage zum Empfangen von Daten.
[data_source.vacancy] # # - id parts = 4 query = """ SELECT vacancy.id AS `:id`, vacancy.profession AS `profession_text:field`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages:attr_multi`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro:attr_multi` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id GROUP BY vacancy.id """
In dieser Vorlage sind alle Felder mit speziellen Aliasnamen gekennzeichnet: [___]:___ .
Es wird sowohl bei der Erstellung einer Anfrage zum Empfang der fehlenden Daten als auch bei der Erstellung des Index verwendet (dazu später mehr).
Wir bilden eine Anfrage dieser Art:
SELECT vacancy.id AS `id`, vacancy.profession AS `profession_text`, GROUP_CONCAT(DISTINCT vacancy_language.language_id) AS `languages`, GROUP_CONCAT(DISTINCT vacancy_metro_station.metro_station_id) AS `metro` FROM vacancy LEFT JOIN vacancy_language ON vacancy_language.vacancy_id = vacancy.id LEFT JOIN vacancy_metro_station ON vacancy_metro_station.vacancy_id = vacancy.id WHERE vacancy.id IN (< id , >) GROUP BY vacancy.id
Dann prüfen wir für jedes Dokument, ob es das Ergebnis dieser Anfrage ist. Wenn nicht, bedeutet dies, dass es aus der Haupttabelle gelöscht wurde und daher auch aus dem Index gelöscht werden kann (wir führen die DELETE Abfrage für dieses Dokument aus). Wenn dies der Fall ist, prüfen Sie, ob die Textfelder für dieses Dokument aktualisiert werden müssen. Wenn Textfelder nicht aktualisiert werden müssen, führen wir eine UPDATE Abfrage für dieses Dokument durch, andernfalls REPLACE .
Es ist anzumerken, dass die Logik, die Position beizubehalten, von der aus Sie bei Fehlern mit dem Lesen des Binlogs beginnen können, kompliziert sein musste, da jetzt eine Situation möglich ist, in der nicht alle aus dem Binlog gelesenen Änderungen angewendet werden.
Damit das erneute Lesen des binlog ordnungsgemäß funktioniert, haben wir Folgendes ausgeführt: Speichern Sie für jedes Zeilenänderungsereignis in der Datenbank die ID der zuletzt abgeschlossenen Transaktion zum Zeitpunkt des Auftretens dieses Ereignisses. Nachdem Sie die Änderungen an Sphinx gesendet haben, aktualisieren wir die Transaktionsnummer, von der aus Sie sicher mit dem Lesen beginnen können, wie folgt. Wenn wir nicht alle akkumulierten Änderungen verarbeitet haben (weil einige Dokumente nicht in der Warteschlange "aufgespürt" wurden), nehmen wir die Nummer der frühesten Transaktion von denen, die sich auf die Änderungen beziehen, die wir noch nicht angewendet haben. Und wenn es passiert ist, dass wir alle akkumulierten Änderungen angewendet haben, nehmen wir einfach die Nummer der zuletzt abgeschlossenen Transaktion.
Was als Ergebnis geschah, war für uns in Ordnung, aber es gab noch einen ziemlich wichtigen Punkt: Damit die Leistung des Echtzeitindex über die Zeit auf einem akzeptablen Niveau bleiben konnte, mussten Größe und Anzahl der „Chunks“ dieses Index klein bleiben. Zu diesem FLUSH RAMCHUNK Sphinx über eine FLUSH RAMCHUNK Anforderung, die einen neuen Festplattenblock erstellt, und eine OPTIMIZE INDEX Anforderung, mit der alle Festplattenblöcke zu einem zusammengeführt werden. Anfangs dachten wir, wir würden es nur regelmäßig durchführen und das ist alles. Leider stellte sich heraus, dass OPTIMIZE INDEX in Version 2.3.2 nicht funktioniert (nämlich mit einer relativ hohen Wahrscheinlichkeit zu einem Rückgang der Suche führt). Aus diesem Grund haben wir uns nur einmal am Tag entschlossen, den Index vollständig neu zu erstellen, zumal wir dies von Zeit zu Zeit noch tun müssen (z. B. wenn sich das Indexschema oder die Tokenizer-Einstellungen ändern).
Das Verfahren zum Wiederherstellen des Index erfolgt in mehreren Schritten.
Wir generieren eine Konfiguration für den Indexer
Wie oben erwähnt, befindet sich in der Dienstkonfiguration eine SQL-Abfragevorlage. Es wird auch verwendet, um die Indexer-Konfiguration zu bilden.
In der Konfiguration sind auch andere Einstellungen zum Erstellen des Index erforderlich (Tokenizer-Einstellungen, Wörterbücher, verschiedene Einschränkungen des Ressourcenverbrauchs).
Speichern Sie die aktuelle Position von MariaDB
Von dieser Position aus beginnen wir mit dem Lesen des Binlogs, nachdem der neue Index auf allen Servern mit searchd verfügbar ist.
Wir starten den Indexer
indexer --config tmp.vacancy.indexer.0.conf --all Befehle des Formularindexers indexer --config tmp.vacancy.indexer.0.conf --all und warten auf deren Abschluss. Wenn der Index in Teile unterteilt ist, beginnen wir außerdem mit der parallelen Konstruktion aller Teile.
Wir laden Indexdateien auf Server
Das Herunterladen auf jeden Server erfolgt ebenfalls parallel, aber wir warten natürlich, bis alle Dateien auf alle Server hochgeladen wurden. Zum Herunterladen von Dateien in der Dienstkonfiguration gibt es einen Abschnitt mit einer Befehlsvorlage zum Herunterladen von Dateien.
[index_uploader] executable = "rsync" arguments = [ "--files-from=-", "--log-file=<<.DataDir>>/rsync.<<.Host>>.log", "--no-relative", "--times", "--delay-updates", ".", "rsync://<<.Host>>/index/vacancy/", ]
Für jeden Server ersetzen wir einfach seinen Namen in der Host-Variablen und führen den resultierenden Befehl aus. Wir verwenden rsync zum Herunterladen, aber im Prinzip funktioniert jedes Programm oder Skript, das eine Liste von Dateien in stdin akzeptiert und diese Dateien in den Ordner herunterlädt, in dem searchd Indexdateien erwartet.
Wir stoppen die Synchronisation
Wir hören auf, das Binlog zu lesen, stoppen die Goroutine, die für die Anhäufung von Änderungen verantwortlich ist.
Ersetzen Sie den alten Index durch einen neuen
Für jeden Server mit searchd führen wir sequentielle Abfragen durch. RELOAD INDEX vacancy_plain , TRUNCATE INDEX vacancy_plain , ATTACH INDEX vacancy_plain TO vacancy . Wenn der Index in Teile unterteilt ist, führen wir diese Abfragen für jedes Teil nacheinander aus. Wenn wir uns in einer Produktionsumgebung befinden, entfernen wir vor dem Ausführen dieser Abfragen auf einem Server die Last über den Balancer (damit niemand SELECT-Abfragen an die Indizes zwischen TRUNCATE und ATTACH ) und sobald ATTACH die letzte ATTACH Anforderung abgeschlossen ist, geben wir die Last an diesen Server zurück.
Wiederaufnahme der Synchronisation von einer gespeicherten Position
Sobald wir alle Echtzeitindizes durch neu erstellte ersetzen, setzen wir das Lesen aus dem Binlog fort und synchronisieren Ereignisse aus dem Binlog, beginnend an der Position, die wir vor Beginn der Indizierung gespeichert haben.
Hier ist ein Beispiel eines Diagramms der Verzögerung des Index vom MariaDB-Server.

Hier können Sie sehen, dass der Status des Index nach der Neuerstellung zwar rechtzeitig zurückkehrt, dies jedoch sehr kurz geschieht.
Jetzt, da alles mehr oder weniger fertig ist, ist es Zeit für die Veröffentlichung. Wir haben es nach und nach gemacht. Zuerst haben wir einen Echtzeitindex auf einige Server gegossen, und der Rest zu dieser Zeit funktionierte genauso. Gleichzeitig unterschied sich die Struktur der Indizes auf den „neuen“ Servern nicht von den alten, sodass unsere PHP-Anwendung weiterhin eine Verbindung zum Balancer herstellen konnte, ohne sich Gedanken darüber zu machen, ob die Anforderung in einem Echtzeitindex oder in einem einfachen Index verarbeitet werden würde.
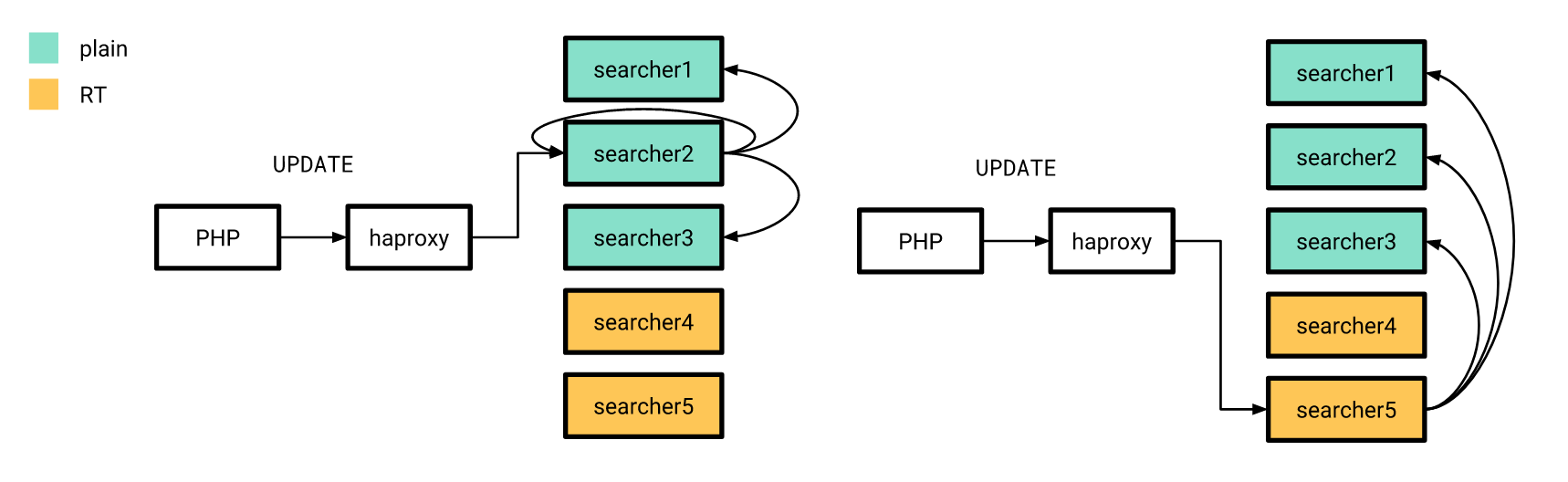
Attributaktualisierungen, über die ich zuvor gesprochen habe, wurden ebenfalls nach dem alten Schema gesendet, mit dem Unterschied, dass der verteilte Index auf allen Servern so konfiguriert wurde, dass UPDATE-Abfragen nur an Server mit einfachen Indizes gesendet werden. Wenn die UPDATE-Anforderung von der Anwendung den Server mit Echtzeitindizes erreicht, führt sie diese Anforderung nicht zu Hause aus, sondern sendet sie an die auf die alte Weise konfigurierten Server.
Wie wir gehofft hatten, hat sich nach der Veröffentlichung herausgestellt, dass sich die Verzögerung zwischen der Änderung eines Lebenslaufs oder einer Vakanz in der Datenbank und der Eingabe der entsprechenden Änderungen in den Index erheblich verringert.
Nach dem Wechsel zu einem Echtzeitindex musste der Index nach jeder Änderung auf den Testservern nicht neu erstellt werden. Und so wurde es möglich, End-to-End-Autotests unter Beteiligung der Suche relativ kostengünstig zu schreiben. Da wir die Änderungen aus dem Binlog jedoch asynchron verarbeiten (aus Sicht der Clients, die in die Datenbank schreiben), mussten wir warten müssen, bis die Änderungen bezüglich des am Autotest teilnehmenden Dokuments von unserem Service verarbeitet und an searchd gesendet wurden .
Zu diesem Zweck haben wir in unserem Service einen Endpunkt erstellt, der genau das tut, dh wartet, bis alle Änderungen auf die angegebene Transaktionsnummer angewendet wurden. Zu diesem @@gtid_current_pos wir unmittelbar nach den erforderlichen Änderungen an der Datenbank bei MariaDB @@gtid_current_pos und übertragen sie an den Endpunkt unseres Dienstes. Wenn wir zu diesem Zeitpunkt bereits alle Transaktionen auf diese Position angewendet haben, antwortet der Service sofort, dass wir fortfahren können. Wenn nicht, erstellen wir in der Goroutine, die für die Anwendung der Änderungen verantwortlich ist, ein Abonnement für diese GTID. Sobald sie (oder eine darauf folgende) angewendet wird, können wir dem Client auch erlauben, den Autotest fortzusetzen.
Im PHP-Code sieht es ungefähr so aus:
<?php declare(strict_types=1); use GuzzleHttp\ClientInterface; use GuzzleHttp\RequestOptions; use PDO; class RiverClient { private const REQUEST_METHOD = 'post'; /** * @var ClientInterface */ private $httpClient; public function __construct(ClientInterface $httpClient) { $this->httpClient = $httpClient; } public function waitForSync(PDO $mysqlConnection, PDO $sphinxConnection, string $riverAddr): void { $masterGTID = $mysqlConnection->query('SELECT @@gtid_current_pos')->fetchColumn(); $this->httpClient->request( self::REQUEST_METHOD, "http://{$riverAddr}/wait", [RequestOptions::FORM_PARAMS => ['gtid' => $masterGTID]] ); } }
Ergebnisse
Infolgedessen konnten wir die Verzögerung zwischen der Aktualisierung von MariaDB und Sphinx erheblich reduzieren.


Wir sind auch viel sicherer geworden, dass alle Updates alle unsere Sphinx-Server pünktlich erreichen.
Darüber hinaus sind Suchtests (sowohl manuell als auch automatisch) viel angenehmer geworden.
Leider wurde uns dies nicht kostenlos zur Verfügung gestellt: Die Performance des Echtzeitindex im Vergleich zum einfachen Index erwies sich als etwas schlechter.
Die Verteilung der Verarbeitungszeit von Suchanfragen in Abhängigkeit von der Zeit für einen einfachen Index ist unten dargestellt.

Und hier ist das gleiche Diagramm für den Echtzeitindex.

Sie können sehen, dass der Anteil der "schnellen" Anfragen leicht zurückgegangen ist, während der Anteil der "langsamen" Anfragen gestiegen ist.
Anstelle einer Schlussfolgerung
Es bleibt zu sagen, dass wir den Code des in diesem Artikel beschriebenen Dienstes öffentlich zugänglich gemacht haben . Leider gibt es noch keine detaillierte Dokumentation, aber wenn Sie möchten, können Sie ein Beispiel für die Verwendung dieses Dienstes über docker-compose ausführen.
Referenzen
- Video- und Berichtsfolien
- Videobericht von Andrey Smirnov und Vyacheslav Kryukov über Highload ++
- Go-MySQL-Bibliothek
- Servicecode mit Verwendungsbeispiel