Heutzutage werden die meisten Softwareprodukte in Teams entwickelt. Erfolgsbedingungen für die Teamentwicklung können in Form eines einfachen Schemas dargestellt werden.
Nachdem Sie den Code geschrieben haben, müssen Sie sicherstellen, dass:
- Es funktioniert.
- Es wird nichts kaputt gemacht, einschließlich des Codes, den Ihre Kollegen geschrieben haben.
Wenn beide Bedingungen erfüllt sind, sind Sie auf dem Weg zum Erfolg. Um diese Bedingungen einfach zu überprüfen und einen profitablen Weg nicht auszuschalten, wurde eine kontinuierliche Integration entwickelt.
CI ist ein Workflow, in dem Sie Ihren Code so oft wie möglich in den allgemeinen Produktcode integrieren. Und nicht nur integrieren, sondern auch ständig überprüfen, ob alles funktioniert. Da Sie häufig und häufig nachsehen müssen, sollten Sie über Automatisierung nachdenken. Sie können alles auf manuelle Traktion überprüfen, aber es lohnt sich nicht, und deshalb.
- Leute sind teuer . Eine Arbeitsstunde eines Programmierers ist teurer als eine Arbeitsstunde eines Servers.
- Die Leute liegen falsch . Daher können Situationen auftreten, in denen Tests auf dem falschen Zweig ausgeführt oder das falsche Commit für Tester erfasst wurden.
- Die Leute sind faul . Wenn ich eine Aufgabe erledige, habe ich regelmäßig den Gedanken: „Aber was gibt es zu überprüfen? Ich habe zwei Zeilen geschrieben - stopudovo alles funktioniert! “ Ich denke, für einige von Ihnen kommen solche Gedanken manchmal in den Sinn. Aber Sie müssen immer überprüfen.
Laut Nikolay Nesterov (
nnesterov ), der an allen evolutionären Änderungen der CI / CD-Android-Anwendung teilnimmt, hat Continuous Integration im Avito Mobile-Entwicklungsteam eingeführt und entwickelt, wie es von 0 auf 450 Baugruppen pro Tag kam und dass Maschinen 200 Stunden am Tag sammeln .
Die Geschichte basiert auf dem Beispiel des Android-Teams, aber die meisten Ansätze gelten auch für iOS.
Es war einmal eine Person im Avito Android-Team. Per Definition brauchte er nichts von Continuous Integration: Es gab niemanden, in den er sich integrieren konnte.
Aber die Anwendung wuchs, es tauchten immer mehr neue Aufgaben auf, und das Team wuchs. Irgendwann war es an der Zeit, den Prozess der Code-Integration formeller zu gestalten. Es wurde beschlossen, Git Flow zu verwenden.

Das Konzept des Git-Flows ist bekannt: Es gibt einen gemeinsamen Entwicklungszweig im Projekt, und für jede neue Funktion schneiden Entwickler einen separaten Zweig ab, schreiben ihn fest, pushen ihn, und wenn sie ihren Code in den Entwicklungszweig einfügen möchten, öffnen Sie die Pull-Anforderung. Um Wissen auszutauschen und Ansätze zu diskutieren, haben wir eine Codeüberprüfung eingeführt. Das heißt, Kollegen müssen den Code des anderen überprüfen und bestätigen.
Schecks
Den Code mit den Augen zu sehen ist cool, aber nicht genug. Daher werden automatische Überprüfungen eingeführt.
- Zunächst überprüfen wir die Montage des ARC .
- Viele Junit-Tests .
- Wir berücksichtigen die Codeabdeckung , da wir die Tests ausführen.
Um zu verstehen, wie diese Überprüfungen ausgeführt werden sollen, schauen wir uns den Entwicklungsprozess in Avito an.
Schematisch kann es wie folgt dargestellt werden:
- Der Entwickler schreibt den Code auf seinen Laptop. Hier können Sie Integrationsprüfungen ausführen - entweder mit einem Commit-Hook oder einfach Überprüfungen im Hintergrund.
- Nachdem der Entwickler den Code ausgeführt hat, öffnet er die Pull-Anforderung. Damit sein Code in den Entwicklungszweig gelangt, müssen Sie eine Codeüberprüfung durchführen und die erforderliche Anzahl von Bestätigungen sammeln. Hier können Sie Prüfungen und Builds aktivieren: Bis alle Builds erfolgreich sind, kann die Pull-Anforderung nicht zusammengeführt werden.
- Nachdem die Pull-Anforderung zusammengeführt und der Code entwickelt wurde, können Sie einen geeigneten Zeitpunkt auswählen: Zum Beispiel nachts, wenn alle Server frei sind, und Laufwerksprüfungen nach Ihren Wünschen.
Niemand mochte es, Tests auf seinem Laptop durchzuführen. Wenn der Entwickler die Funktion beendet hat, möchte er sie schnell starten und die Pull-Anforderung öffnen. Wenn in diesem Moment einige lange Überprüfungen gestartet werden, ist dies nicht nur nicht sehr angenehm, sondern verlangsamt auch die Entwicklung: Während der Laptop etwas überprüft, ist es unmöglich, normal daran zu arbeiten.
Wir haben es wirklich gemocht, nachts Kontrollen durchzuführen, da es viel Zeit und Server gibt, können Sie einen Spaziergang machen. Leider hat der Entwickler zu Beginn der Entwicklung des Feature-Codes bereits viel weniger Motivation, die von CI gefundenen Fehler zu beheben. Ich fing regelmäßig an zu denken, als ich im Morgenbericht über alle gefundenen Fehler nachdachte, dass ich sie irgendwann später beheben würde, denn jetzt liegt in Jira eine coole neue Aufgabe, mit der ich gerade anfangen möchte.
Wenn die Überprüfungen die Pull-Anforderung blockieren, gibt es genügend Motivation, da der Code erst entwickelt wird, wenn die Builds grün werden, was bedeutet, dass die Aufgabe nicht abgeschlossen wird.
Aus diesem Grund haben wir uns für diese Strategie entschieden: Nachts fahren wir die maximal möglichen und kritischsten Überprüfungen und führen vor allem eine Pull-Anforderung aus. Aber wir hören hier nicht auf - wir optimieren gleichzeitig die Geschwindigkeit, mit der Schecks bestanden werden, damit sie auf Pull-Anfrage vom Nachtmodus auf Schecks umschalten.
Zu diesem Zeitpunkt waren alle unsere Assemblys schnell genug, sodass wir nur die ARC-Assembly, Junit-Tests und die Berechnung der Codeabdeckung in den Pull-Request-Blocker aufgenommen haben. Sie schalteten es ein, überlegten es sich und gaben die Codeabdeckung auf, weil sie dachten, wir brauchten es nicht.
Wir haben zwei Tage gebraucht, um die grundlegende CI-Einrichtung abzuschließen (im Folgenden ist eine vorübergehende Schätzung ungefähr, die für die Skalierung erforderlich ist).Danach begannen sie weiter zu überlegen - überprüfen wir es richtig? Starten wir Builds auf Pull-Anfrage korrekt?
Wir haben den Build für das letzte Commit des Zweigs gestartet, mit dem die Pull-Anforderung geöffnet ist. Überprüfungen dieses Commits können jedoch nur zeigen, dass der vom Entwickler geschriebene Code funktioniert. Aber sie beweisen nicht, dass er nichts gebrochen hat. Tatsächlich müssen Sie den Status des Entwicklungszweigs überprüfen, nachdem das Feature in ihn eingefügt wurde.
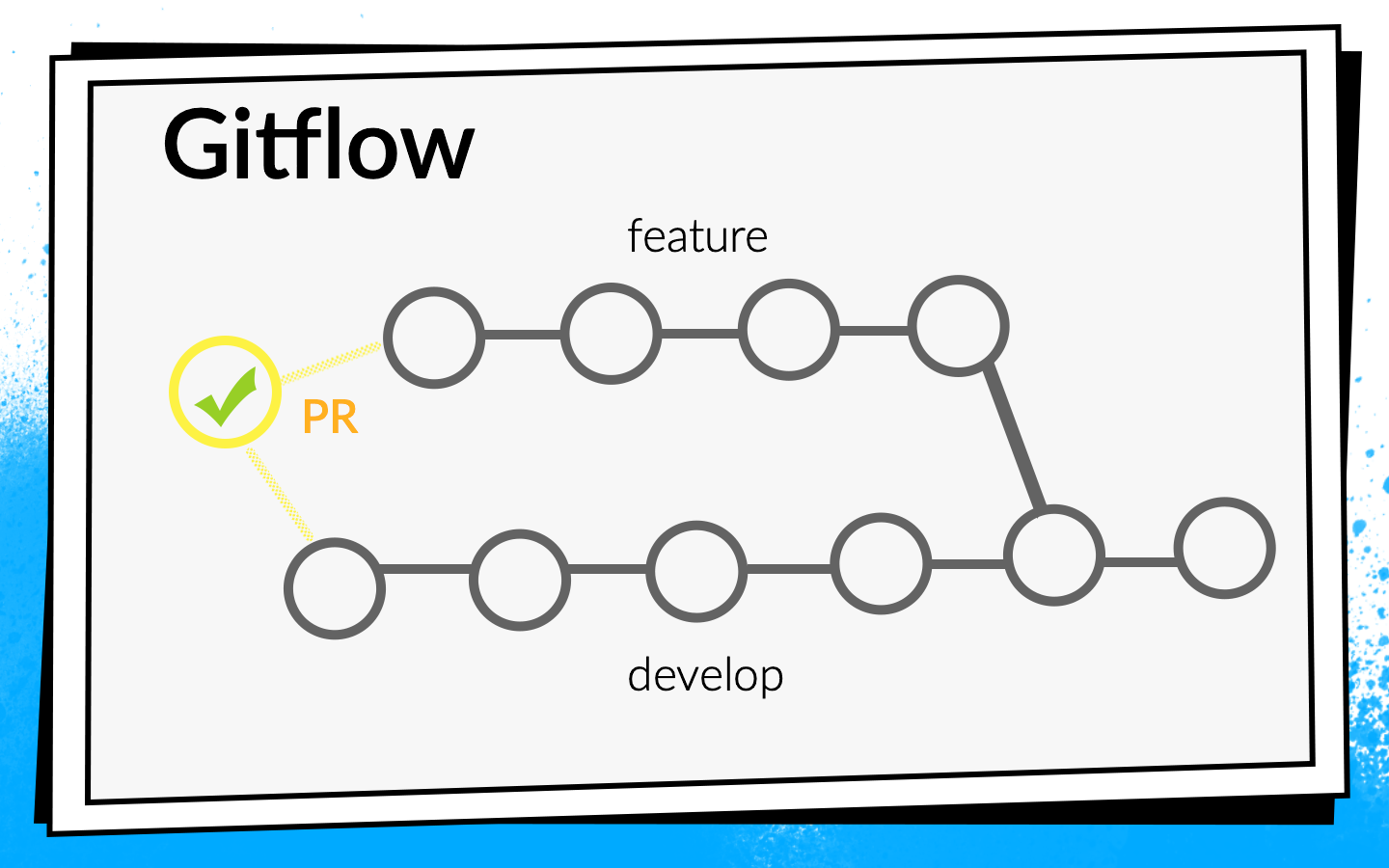
Zu diesem
Zweck haben wir ein einfaches Bash-Skript
premerge.sh geschrieben:
Hier werden die neuesten Änderungen aus der Entwicklung einfach abgerufen und in der aktuellen Branche zusammengeführt. Wir haben das Skript premerge.sh als ersten Schritt aller Builds hinzugefügt und begonnen, genau zu überprüfen, was wir wollen, dh
Integration .
Es dauerte drei Tage, um das Problem zu lokalisieren, eine Lösung zu finden und dieses Skript zu schreiben.Die Anwendung entwickelte sich, es tauchten immer mehr Aufgaben auf, das Team wuchs und premerge.sh ließ uns manchmal im Stich. In der Entwicklung drangen widersprüchliche Veränderungen ein, die die Versammlung brachen.
Ein Beispiel dafür:

Zwei Entwickler beginnen gleichzeitig mit dem Sägen der Features A und B. Der Entwickler von Feature A entdeckt die nicht verwendete
answer() Funktion im Projekt und entfernt sie wie ein guter Scout. Gleichzeitig fügt der Entwickler von Feature B dieser Funktion in seiner Filiale einen neuen Aufruf hinzu.
Entwickler beenden die Arbeit und öffnen gleichzeitig die Pull-Anfrage. Builds starten, premerge.sh prüft beide Pull-Anforderungen auf einen neuen Entwicklungsstatus - alle Prüfungen sind grün. Nachdem diese Pull-Anforderungsfunktionen A zusammengeführt wurden, werden die Pull-Anforderungsfunktionen B zusammengeführt ... Boom! Entwicklungspausen, da im Entwicklungscode eine nicht vorhandene Funktion aufgerufen wird.
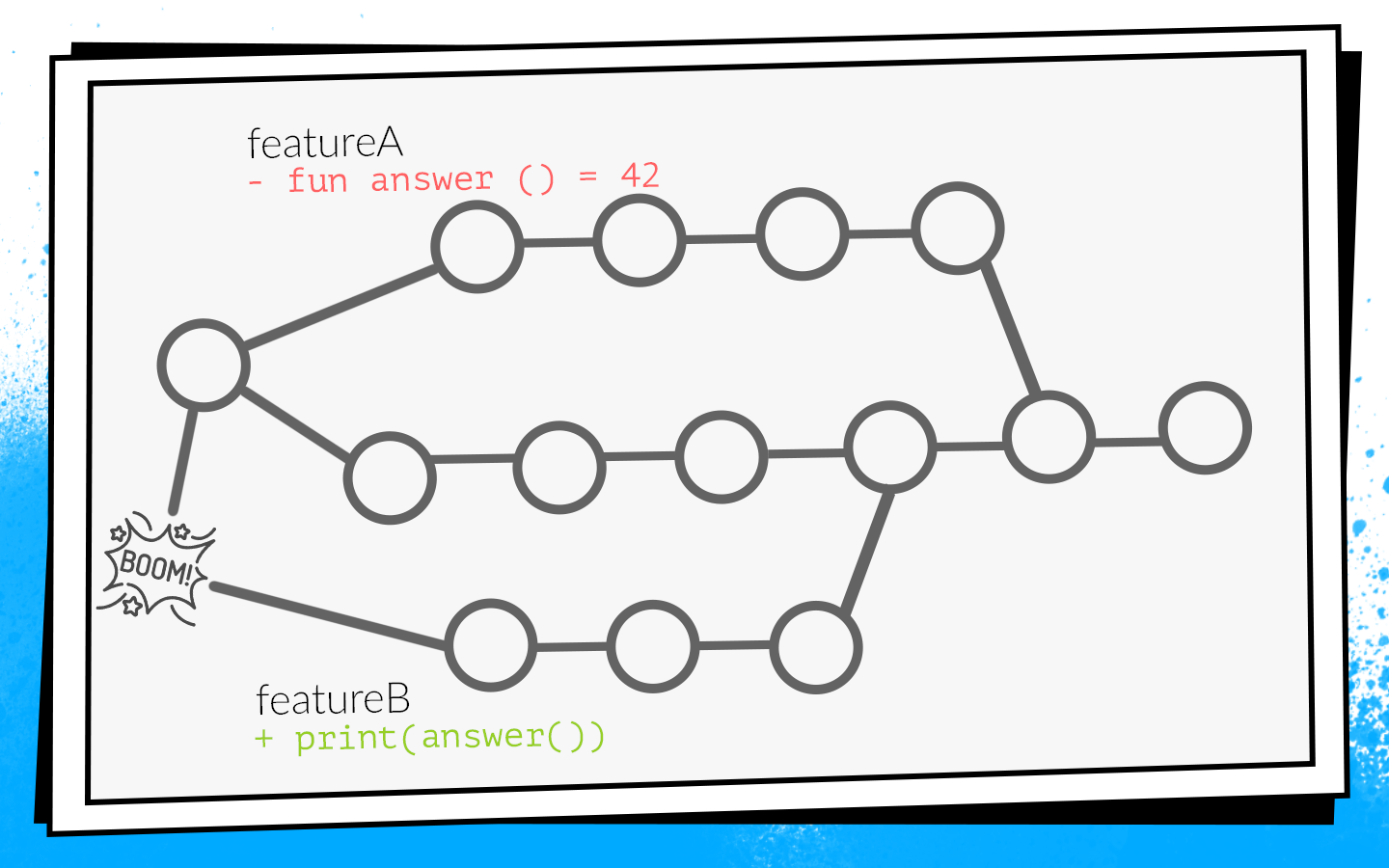
Wenn Sie sich nicht entwickeln, ist dies eine
lokale Katastrophe . Das gesamte Team kann nichts sammeln und zum Testen geben.
So kam es, dass ich am häufigsten an Infrastrukturaufgaben beteiligt war: Analyse, Netzwerk, Datenbanken. Das heißt, ich habe die Funktionen und Klassen geschrieben, die andere Entwickler verwenden. Aus diesem Grund bin ich sehr oft in solche Situationen geraten. Ich hatte sogar einmal so ein Bild.

Da dies nicht zu uns passte, begannen wir Optionen zu erarbeiten, wie dies verhindert werden kann.
Wie man nicht bricht, entwickelt sich
Erste Option:
Erstellen Sie alle Pull-Anforderungen neu, wenn Sie ein Upgrade entwickeln. Wenn in unserem Beispiel eine Pull-Anforderung mit Feature A zum ersten Mal entwickelt wird, wird die Pull-Anforderung von Feature B neu erstellt, und dementsprechend schlagen Überprüfungen aufgrund eines Kompilierungsfehlers fehl.
Um zu verstehen, wie lange es dauern wird, betrachten Sie ein Beispiel mit zwei PRs. Wir öffnen zwei PRs: zwei Builds, zwei Teststarts. Nachdem die erste PR in die Entwicklung gegossen wurde, muss die zweite wieder aufgebaut werden. Insgesamt erfordern zwei PR-Starts von Prüfungen drei PRs: 2 + 1 = 3.
Im Prinzip ist es normal. Aber wir haben uns die Statistiken angesehen, und eine typische Situation in unserem Team waren 10 offene PRs. Die Anzahl der Überprüfungen ist die Summe der Fortschritte: 10 + 9 + ... + 1 = 55. Das heißt, um 10 PRs zu akzeptieren, müssen Sie 55 Mal neu erstellen. Und dies ist eine ideale Situation, wenn alle Prüfungen beim ersten Mal bestanden werden und niemand eine zusätzliche Pull-Anforderung öffnet, während diese zehn verarbeitet werden.
Stellen Sie sich einen Entwickler vor, der Zeit haben muss, um zuerst auf die Schaltfläche "Zusammenführen" zu klicken. Wenn dies von einem Nachbarn durchgeführt wird, müssen Sie warten, bis alle Baugruppen erneut durchlaufen werden ... Nein, dies wird die Entwicklung nicht ernsthaft verlangsamen.
Der zweite mögliche Weg:
Pull-Anfrage nach Codeüberprüfung sammeln. Öffnen Sie also die Pull-Anforderung, sammeln Sie die erforderliche Anzahl von Updates von Kollegen, korrigieren Sie die erforderlichen Änderungen und führen Sie die Builds aus. Wenn sie erfolgreich sind, wird die Pull-Anforderung mit der Entwicklung zusammengeführt. In diesem Fall gibt es keine zusätzlichen Neustarts, aber das Feedback verlangsamt sich erheblich. Wenn ich als Entwickler eine Pull-Anfrage öffne, möchte ich sofort sehen, ob er dies tun wird. Wenn beispielsweise ein Test abstürzt, müssen Sie ihn schnell beheben. Bei einem verzögerten Build verlangsamt sich das Feedback, was die gesamte Entwicklung bedeutet. Das passte auch nicht zu uns.
Infolgedessen blieb nur die dritte Option übrig - das
Radfahren . Unser gesamter Code und alle unsere Quellen werden im Repository des Bitbucket-Servers gespeichert. Dementsprechend mussten wir ein Plugin für Bitbucket entwickeln.

Dieses Plugin überschreibt den Pull-Request-Merge-Mechanismus. Der Anfang ist Standard: PR wird geöffnet, alle Assemblys werden gestartet, die Codeüberprüfung wird bestanden. Nachdem die Codeüberprüfung abgeschlossen ist und der Entwickler auf "Zusammenführen" klickt, überprüft das Plugin, auf welchen Status die Entwicklungsprüfungen ausgeführt wurden. Wenn die Entwicklung nach dem Erstellen der Aktualisierung erfolgreich war, können Sie mit dem Plugin eine solche Pull-Anforderung nicht in den Hauptzweig einbinden. Die Builds werden einfach relativ zur Neuentwicklung neu gestartet.

In unserem Beispiel mit widersprüchlichen Änderungen schlagen solche Builds aufgrund eines Kompilierungsfehlers fehl. Dementsprechend muss der Entwickler von Feature B den Code korrigieren, die Überprüfungen neu starten, und das Plugin wendet die Pull-Anforderung automatisch an.
Vor der Implementierung dieses Plugins hatten wir durchschnittlich 2,7 Testläufe pro Pull-Anfrage. Mit dem Plugin gab es 3.6 Starts. Es hat uns gepasst.
Es ist erwähnenswert, dass dieses Plugin einen Nachteil hat: Es startet den Build nur einmal neu. Das heißt, es bleibt ein kleines Fenster, durch das sich widersprüchliche Änderungen entwickeln können. Die Wahrscheinlichkeit dafür ist jedoch nicht hoch, und wir haben diesen Kompromiss zwischen der Anzahl der Starts und der Wahrscheinlichkeit eines Ausfalls geschlossen. Zwei Jahre lang schoss es nur einmal, daher wahrscheinlich nicht umsonst.
Wir haben zwei Wochen gebraucht, um die erste Version des Plugins für Bitbucket zu schreiben.Neue Schecks
Inzwischen ist unser Team weiter gewachsen. Neue Schecks wurden hinzugefügt.
Wir dachten: Warum Fehler reparieren, wenn sie verhindert werden können? Und so führten sie eine
statische Code-Analyse ein . Wir haben mit Flusen begonnen, die im Android SDK enthalten sind. Zu diesem Zeitpunkt wusste er jedoch überhaupt nicht, wie man mit Kotlin-Code arbeitet, und wir haben bereits 75% der Anwendung in Kotlin geschrieben. Daher wurden Flusen integrierte
Android Studio-Überprüfungen hinzugefügt
.Dazu musste ich sehr pervers sein: Nehmen Sie Android Studio, packen Sie es in Docker und führen Sie es auf CI mit einem virtuellen Monitor aus, sodass es glaubte, auf einem realen Laptop zu laufen. Aber es hat funktioniert.
Zu dieser Zeit haben wir auch begonnen, viele
Instrumentierungstests zu schreiben und
Screenshot- Tests durchzuführen. In diesem Fall wird ein Referenz-Screenshot für eine separate kleine Ansicht generiert, und der Test besteht darin, dass ein Screenshot aus der Ansicht entnommen und Pixel für Pixel direkt mit der Referenz verglichen wird. Wenn es eine Diskrepanz gibt, bedeutet dies, dass ein Layout irgendwohin gegangen ist oder etwas in den Stilen nicht stimmt.
Instrumentierungstests und Screenshot-Tests müssen jedoch auf Geräten ausgeführt werden: auf Emulatoren oder auf realen Geräten. Angesichts der Tatsache, dass es viele Tests gibt und diese häufig durchgeführt werden, benötigen Sie eine ganze Farm. Es ist zu mühsam, eine eigene Farm zu gründen. Deshalb haben wir eine vorgefertigte Option gefunden - Firebase Test Lab.
Firebase-Testlabor
Es wurde ausgewählt, weil Firebase ein Google-Produkt ist, das heißt, es muss zuverlässig sein und es ist unwahrscheinlich, dass es jemals stirbt. Die Preise sind erschwinglich: 5 USD pro Stunde für ein echtes Gerät, 1 USD pro Stunde für einen Emulator.
Die Implementierung des Firebase-Testlabors in unserem CI dauerte ungefähr drei Wochen.Aber das Team wuchs weiter und Firebase begann uns leider im Stich zu lassen. Zu diesem Zeitpunkt hatte er keine SLA. Manchmal ließ uns Firebase warten, bis die erforderliche Anzahl von Geräten für Tests frei wurde, und begann nicht sofort, sie auszuführen, wie wir es wollten. Das Warten in der Schlange dauerte bis zu einer halben Stunde, und das ist eine sehr lange Zeit. Instrumentierungstests wurden bei jeder PR durchgeführt, Verzögerungen verlangsamten die Entwicklung erheblich, und dann kam eine monatliche Rechnung mit einer runden Summe. Im Allgemeinen wurde beschlossen, Firebase aufzugeben und im eigenen Haus zu sehen, da das Team genug gewachsen ist.
Docker + Python + Bash
Wir haben Docker genommen, Emulatoren hineingestopft, ein einfaches Python-Programm geschrieben, das zur richtigen Zeit die richtige Anzahl von Emulatoren in der richtigen Version erhöht und sie bei Bedarf stoppt. Und natürlich ein paar Bash-Skripte - wo ohne sie?
Die Erstellung unserer eigenen Testumgebung dauerte fünf Wochen.Infolgedessen verfügte jede Pull-Anforderung über eine umfangreiche, blockierende Zusammenführungsliste von Überprüfungen:
- Versammlung des ARC;
- Junit-Tests
- Fussel;
- Android Studio prüft;
- Instrumentierungstests;
- Screenshot-Tests.
Dies verhinderte viele mögliche Ausfälle. Technisch hat alles funktioniert, aber die Entwickler haben sich beschwert, dass das Warten auf die Ergebnisse zu lang war.
Zu viel ist wie viel? Wir haben die Daten von Bitbucket und TeamCity in das Analysesystem hochgeladen und festgestellt, dass die
durchschnittliche Wartezeit 45 Minuten beträgt . Das heißt, ein Entwickler, der eine Pull-Anfrage öffnet, erwartet im Durchschnitt Build-Ergebnisse von 45 Minuten. Meiner Meinung nach ist das eine Menge, und so kann man nicht arbeiten.
Natürlich haben wir uns entschlossen, alle unsere Builds zu beschleunigen.
Beschleunigen Sie
Angesichts der Tatsache, dass häufig Builds im Einklang stehen, haben wir als erstes
Eisen gekauft - eine umfassende Entwicklung ist am einfachsten. Builds standen nicht mehr in der Schlange, aber die Wartezeit verkürzte sich nur geringfügig, da einige Schecks für sich selbst sehr lange nachjagten.
Wir entfernen zu lange Schecks
Unsere kontinuierliche Integration könnte diese Art von Fehlern und Problemen erkennen.
- Ich werde nicht gehen . CI kann einen Kompilierungsfehler abfangen, wenn aufgrund widersprüchlicher Änderungen etwas nicht funktioniert. Wie gesagt, dann kann niemand etwas sammeln, die Entwicklung steigt und jeder wird nervös.
- Ein Fehler im Verhalten . Zum Beispiel, wenn die Anwendung erstellt wird, aber wenn Sie auf die Schaltfläche klicken, stürzt sie ab oder die Schaltfläche wird überhaupt nicht gedrückt. Dies ist schlecht, da ein solcher Fehler den Benutzer erreichen kann.
- Fehler im Layout . Beispielsweise wird eine Taste gedrückt, aber 10 Pixel nach links verschoben.
- Zunahme der technischen Verschuldung .
Bei Betrachtung dieser Liste haben wir festgestellt, dass nur die ersten beiden Punkte kritisch sind. Wir wollen solche Probleme zuallererst auffangen. Fehler im Layout werden in der Entwurfsüberprüfungsphase erkannt und dann einfach behoben. Die Arbeit mit technischen Schulden erfordert einen separaten Prozess und eine separate Planung. Daher haben wir beschlossen, diese nicht auf Pull-Anforderungen zu überprüfen.
Basierend auf dieser Klassifizierung haben wir die gesamte Liste der Schecks durcheinander gebracht.
Lint durchgestrichen und der Start für die Nacht verschoben: Nur damit ein Bericht darüber veröffentlicht wird, wie viele Probleme das Projekt hat. Wir waren uns einig, separat mit den technischen Schulden zu arbeiten,
lehnten jedoch Android Studio-Prüfungen vollständig ab . Das Android Studio von Docker zum Starten von Inspektionen klingt interessant, bringt jedoch große Probleme bei der Unterstützung mit sich. Jedes Update auf Android Studio-Versionen ist ein Kampf gegen obskure Fehler. Es war auch schwierig, Screenshot-Tests durchzuführen, da die Bibliothek nicht sehr stabil funktionierte und es falsch positive Ergebnisse gab.
Screenshot-Tests wurden aus der Liste der Prüfungen entfernt .
Als Ergebnis haben wir verlassen:
- Versammlung des ARC;
- Junit-Tests
- Instrumentierungstests.
Gradle Remote-Cache
Ohne schwere Kontrollen wurde es besser. Der Perfektion sind jedoch keine Grenzen gesetzt!
Unsere Anwendung wurde bereits in ca. 150 Gradle-Module aufgeteilt. In diesem Fall funktioniert der Gradle-Remote-Cache normalerweise gut, und wir haben uns entschlossen, es zu versuchen.
Gradle Remote Cache ist ein Dienst, der Build-Artefakte für einzelne Aufgaben in separaten Modulen zwischenspeichern kann. Anstatt den Code tatsächlich zu kompilieren, stößt Gradle den Remote-Cache über HTTP um und fragt, ob jemand diese Aufgabe bereits ausgeführt hat. Wenn ja, laden Sie einfach das Ergebnis herunter.
Das Starten des Remote-Cache von Gradle ist einfach, da Gradle ein Docker-Image bereitstellt. Das haben wir in drei Stunden geschafft.Sie mussten lediglich Docker starten und eine Zeile im Projekt registrieren. Obwohl Sie es schnell starten können, damit alles gut funktioniert, wird es viel Zeit in Anspruch nehmen.
Unten sehen Sie eine Grafik mit Cache-Fehlern.

Zu Beginn betrug der Prozentsatz der Fehler nach dem Cache etwa 65. Drei Wochen später gelang es uns, diesen Wert auf 20% zu bringen. Es stellte sich heraus, dass die Aufgaben, die die Android-Anwendung sammelt, seltsame transitive Abhängigkeiten aufweisen, aufgrund derer Gradle den Cache übersehen hat.
Durch das Verbinden des Caches haben wir die Assembly erheblich beschleunigt. Aber abgesehen von der Montage jagen Instrumentierungstests immer noch und sie jagen lange. Möglicherweise müssen nicht alle Tests für jede Pull-Anforderung verfolgt werden. Um dies herauszufinden, verwenden wir eine Wirkungsanalyse.
Wirkungsanalyse
Auf Pull-Anfrage bauen wir Git Diff und finden die modifizierten Gradle-Module.

Es ist sinnvoll, nur die Instrumentierungstests durchzuführen, die modifizierte Module und alle davon abhängigen Module testen. Es macht keinen Sinn, Tests für benachbarte Module durchzuführen: Der Code hat sich dort nicht geändert, und nichts kann kaputt gehen.
Instrumentierungstests sind nicht so einfach, da sie sich im Anwendungsmodul der obersten Ebene befinden müssen. Wir haben eine Heuristik zur Bytecode-Analyse angewendet, um zu verstehen, zu welchem Modul jeder Test gehört.
Das Upgrade der Instrumentierungstests dauerte ungefähr acht Wochen, um nur die beteiligten Module zu testen.Maßnahmen zur Beschleunigung der Überprüfung haben erfolgreich funktioniert. Ab 45 Minuten erreichten wir ungefähr 15. Eine Viertelstunde, um auf den Bau zu warten, ist bereits normal.
Aber jetzt haben die Entwickler angefangen sich zu beschweren, dass ihnen nicht klar ist, welche Builds gestartet werden, wo das Protokoll aussehen wird, warum der Build rot ist, welcher Test gefallen ist usw.
Feedback-Probleme verlangsamen die Entwicklung, daher haben wir versucht, die verständlichsten und detailliertesten Informationen zu jedem PR und Build bereitzustellen. Wir haben mit Kommentaren zu Bitbucket für PR begonnen, die angeben, welcher Build gefallen ist und warum, und gezielte Nachrichten in Slack geschrieben haben. Am Ende erstellten sie ein Dashboard für die PR-Seite mit einer Liste aller derzeit ausgeführten Builds und ihrem Status: In Linie, Start, Absturz oder Ende. Sie können auf den Build klicken und zu dessen Protokoll gelangen.
 Sechs Wochen wurden für detailliertes Feedback aufgewendet.
Sechs Wochen wurden für detailliertes Feedback aufgewendet.Pläne
Wir gehen zur neuesten Geschichte über. Nachdem wir die Frage des Feedbacks gelöst hatten, gingen wir auf eine neue Ebene - wir beschlossen, eine eigene Farm von Emulatoren zu bauen. Wenn es viele Tests und Emulatoren gibt, sind sie schwer zu verwalten. Infolgedessen sind alle unsere Emulatoren in einen k8s-Cluster mit flexiblem Ressourcenmanagement umgezogen.
Darüber hinaus gibt es weitere Pläne.
- Return Lint (und andere statische Analysen). Wir arbeiten bereits in diese Richtung.
- Führen Sie alle End-to-End-Tests auf dem PR-Blocker in allen Versionen des SDK aus.
Wir haben also die Geschichte der Entwicklung der kontinuierlichen Integration in Avito nachverfolgt. Jetzt möchte ich einige Ratschläge aus der Sicht der Erfahrenen geben.
Tipps
Wenn ich nur einen Rat geben könnte, wäre dies folgender:
Bitte seien Sie vorsichtig mit Shell-Skripten!
Bash ist ein sehr flexibles und leistungsstarkes Tool. Es ist sehr bequem und schnell, Skripte darauf zu schreiben. Aber mit ihm kann man in die Falle tappen, und wir sind leider hineingefallen.
Alles begann mit einfachen Skripten, die auf unseren Build-Maschinen ausgeführt wurden:
Aber wie Sie wissen, entwickelt sich alles und wird mit der Zeit kompliziert - lassen Sie uns ein Skript von einem anderen ausführen, lassen Sie uns dort einige Parameter übergeben - am Ende musste ich eine Funktion schreiben, die bestimmt, auf welcher Ebene der Verschachtelung wir jetzt sind, um die erforderlichen Anführungszeichen zu ersetzen. damit alles beginnt.

Sie können sich vorstellen, wie viel Arbeit mit der Entwicklung solcher Skripte verbunden ist. Ich rate Ihnen, nicht in diese Falle zu tappen.
Was kann ersetzt werden?
- Beliebige Skriptsprache. Das Schreiben in Python- oder Kotlin- Skripten ist bequemer, da es sich um Programmierung und nicht um Skripte handelt.
- Oder beschreiben Sie die gesamte Erstellungslogik in Form von benutzerdefinierten Gradle-Aufgaben für Ihr Projekt.
Wir haben uns für die zweite Option entschieden und löschen nun systematisch alle Bash-Skripte und schreiben viele benutzerdefinierte Gradle-Shuffles.
Tipp 2: Halten Sie Ihre Infrastruktur im Code.Dies ist praktisch, wenn die Continuous Integration-Konfiguration nicht in der Jenkins- oder TeamCity-Benutzeroberfläche usw., sondern als Textdateien direkt im Projekt-Repository gespeichert wird. Dies gibt die Versionsfähigkeit. Es wird nicht schwierig sein, Code in einem anderen Zweig zurückzusetzen oder zu sammeln.
Skripte können im Projekt gespeichert werden. Und was tun mit der Umwelt?
Tipp 3: Docker kann der Umwelt helfen.Es wird definitiv Android-Entwicklern helfen, iOS leider noch nicht.
Dies ist ein Beispiel für eine einfache Docker-Datei, die jdk und android-sdk enthält:
FROM openjdk:8 ENV SDK_URL="https://dl.google.com/android/repository/sdk-tools-linux-3859397.zip" \ ANDROID_HOME="/usr/local/android-sdk" \ ANDROID_VERSION=26 \ ANDROID_BUILD_TOOLS_VERSION=26.0.2 # Download Android SDK RUN mkdir "$ANDROID_HOME" .android \ && cd "$ANDROID_HOME" \ && curl -o sdk.zip $SDK_URL \ && unzip sdk.zip \ && rm sdk.zip \ && yes | $ANDROID_HOME/tools/bin/sdkmanager --licenses # Install Android Build Tool and Libraries RUN $ANDROID_HOME/tools/bin/sdkmanager --update RUN $ANDROID_HOME/tools/bin/sdkmanager "build-tools;${ANDROID_BUILD_TOOLS_VERSION}" \ "platforms;android-${ANDROID_VERSION}" \ "platform-tools" RUN mkdir /application WORKDIR /application
Nachdem Sie diese Docker-Datei geschrieben haben (ich werde Ihnen ein Geheimnis verraten, Sie können sie nicht schreiben, sondern aus GitHub herausholen) und das Image sammeln, erhalten Sie eine virtuelle Maschine, auf der Sie die Anwendung erstellen und Junit-Tests ausführen können.
Die beiden Hauptargumente, warum dies sinnvoll ist, sind Skalierbarkeit und Wiederholbarkeit. Mit Docker können Sie schnell ein Dutzend Build-Agenten aufrufen, die genau dieselbe Umgebung wie die alte haben. Dies erleichtert CI-Ingenieuren das Leben. Android-SDK in Docker zu schieben ist ganz einfach, mit Emulatoren etwas komplizierter: Sie müssen ein wenig trainieren (naja, oder laden Sie das fertige erneut von GitHub herunter).
Tipp Nummer 4: Vergessen Sie nicht, dass die Überprüfungen nicht zum Zwecke der Überprüfung, sondern für Personen durchgeführt werden.Schnelles und vor allem klares Feedback ist für Entwickler sehr wichtig: Was sie kaputt gemacht haben, welcher Test gefallen ist, wo das Build-Protokoll.
Tipp 5: Seien Sie pragmatisch bei der kontinuierlichen Integration.Verstehen Sie genau, welche Arten von Fehlern Sie verhindern möchten, wie viel Sie bereit sind, Ressourcen, Zeit und Computerzeit aufzuwenden. Zu lange Schecks können beispielsweise über Nacht verschoben werden. Und diejenigen, die nicht sehr wichtige Fehler fangen, sollten völlig aufgegeben werden.
Tipp 6: Verwenden Sie vorgefertigte Werkzeuge.Mittlerweile gibt es viele Unternehmen, die Cloud-CI anbieten.

Für kleine Teams ist dies ein guter Ausweg. Sie müssen nichts warten, nur etwas Geld bezahlen, Ihre Bewerbung abholen und sogar Instrumentierungstests durchführen.
Tipp 7: In einem großen Team sind interne Lösungen rentabler.Aber früher oder später werden mit dem Wachstum des Teams rentablere interne Lösungen. Bei diesen Entscheidungen gibt es einen Punkt. In der Wirtschaft gibt es ein Gesetz zur Verringerung der Rendite: In jedem Projekt wird jede nachfolgende Verbesserung immer schwieriger, erfordert immer mehr Investitionen.
Die Wirtschaft beschreibt unser ganzes Leben, einschließlich der kontinuierlichen Integration. Ich habe für jede Phase unserer kontinuierlichen Integrationsentwicklung einen Arbeitsplan erstellt.

Es ist ersichtlich, dass jede Verbesserung immer schwieriger wird. Wenn wir uns dieses Diagramm ansehen, können wir verstehen, dass die Entwicklung der kontinuierlichen Integration mit dem Wachstum der Teamgröße vereinbar sein muss. Für ein Zwei-Personen-Team ist es eine mittelmäßige Idee, 50 Tage lang eine interne Emulatorfarm zu entwickeln. Gleichzeitig ist es für ein großes Team jedoch auch eine schlechte Idee, die kontinuierliche Integration überhaupt nicht durchzuführen, da Integrationsprobleme auftreten, die Kommunikation repariert wird usw. es wird noch länger dauern.
Wir haben mit der Tatsache begonnen, dass Automatisierung erforderlich ist, weil Menschen teuer, falsch und faul sind. Menschen automatisieren aber auch. Daher gelten alle diese Probleme auch für die Automatisierung.
- Automatisieren ist teuer. Denken Sie an den Arbeitsplan.
- In der Automatisierung machen Menschen Fehler.
- Automatisierung ist manchmal sehr faul, weil alles so funktioniert. Warum noch verbessern, warum all diese kontinuierliche Integration?
: 20% . , . , , , - , develop, . , , - .
Continuous Integration. ., , AppsConf . . 22-23 .