In diesem Beitrag möchten wir Ihnen einen interessanten Umgang mit der Konfiguration eines verteilten Systems vorstellen.
Die Konfiguration wird typsicher direkt in der Scala-Sprache dargestellt. Eine Beispielimplementierung wird ausführlich beschrieben. Verschiedene Aspekte des Vorschlags werden erörtert, einschließlich des Einflusses auf den gesamten Entwicklungsprozess.
( auf Russisch )
Einführung
Der Aufbau robuster verteilter Systeme erfordert die Verwendung einer korrekten und kohärenten Konfiguration auf allen Knoten. Eine typische Lösung besteht darin, eine textuelle Bereitstellungsbeschreibung (Terraform, Ansible oder ähnliches) und automatisch generierte Konfigurationsdateien (häufig - für jeden Knoten / jede Rolle reserviert) zu verwenden. Wir möchten auch auf jedem Kommunikationsknoten dieselben Protokolle derselben Version verwenden (andernfalls treten Inkompatibilitätsprobleme auf). In der JVM-Welt bedeutet dies, dass mindestens die Messaging-Bibliothek auf allen kommunizierenden Knoten dieselbe Version haben sollte.
Was ist mit dem Testen des Systems? Natürlich sollten wir Unit-Tests für alle Komponenten durchführen, bevor wir zu Integrationstests kommen. Um Testergebnisse zur Laufzeit extrapolieren zu können, sollten wir sicherstellen, dass die Versionen aller Bibliotheken sowohl in der Laufzeit- als auch in der Testumgebung identisch sind.
Beim Ausführen von Integrationstests ist es oft viel einfacher, auf allen Knoten denselben Klassenpfad zu haben. Wir müssen nur sicherstellen, dass bei der Bereitstellung derselbe Klassenpfad verwendet wird. (Es ist möglich, verschiedene Klassenpfade auf verschiedenen Knoten zu verwenden, aber es ist schwieriger, diese Konfiguration darzustellen und korrekt bereitzustellen.) Um die Dinge einfach zu halten, werden nur identische Klassenpfade auf allen Knoten berücksichtigt.
Die Konfiguration entwickelt sich tendenziell zusammen mit der Software. Wir verwenden normalerweise Versionen, um verschiedene zu identifizieren
Stufen der Softwareentwicklung. Es erscheint sinnvoll, die Konfiguration unter Versionsverwaltung abzudecken und verschiedene Konfigurationen mit einigen Bezeichnungen zu identifizieren. Wenn es in der Produktion nur eine Konfiguration gibt, können wir eine einzelne Version als Kennung verwenden. Manchmal haben wir mehrere Produktionsumgebungen. Und für jede Umgebung benötigen wir möglicherweise einen separaten Konfigurationszweig. Konfigurationen können daher mit Zweig und Version gekennzeichnet sein, um verschiedene Konfigurationen eindeutig zu identifizieren. Jede Verzweigungsbezeichnung und -version entspricht einer einzelnen Kombination von verteilten Knoten, Ports, externen Ressourcen und Klassenpfadbibliotheksversionen auf jedem Knoten. Hier werden wir nur den einzelnen Zweig behandeln und Konfigurationen anhand einer dreikomponentigen Dezimalversion (1.2.3) identifizieren, genau wie andere Artefakte.
In modernen Umgebungen werden Konfigurationsdateien nicht mehr manuell geändert. Normalerweise generieren wir
Konfigurationsdateien zur Bereitstellungszeit und berühren Sie sie danach nie mehr . Man könnte sich also fragen, warum wir immer noch das Textformat für Konfigurationsdateien verwenden. Eine praktikable Option besteht darin, die Konfiguration in einer Kompilierungseinheit zu platzieren und von der Validierungskonfiguration zur Kompilierungszeit zu profitieren.
In diesem Beitrag werden wir die Idee untersuchen, die Konfiguration im kompilierten Artefakt beizubehalten.
Kompilierbare Konfiguration
In diesem Abschnitt werden wir ein Beispiel für eine statische Konfiguration diskutieren. Zwei einfache Dienste - der Echodienst und der Client des Echodienstes - werden konfiguriert und implementiert. Dann werden zwei verschiedene verteilte Systeme mit beiden Diensten instanziiert. Eine ist für eine Konfiguration mit einem Knoten und eine andere für die Konfiguration mit zwei Knoten.
Ein typisches verteiltes System besteht aus wenigen Knoten. Die Knoten könnten unter Verwendung eines Typs identifiziert werden:
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
oder einfach
case class NodeId(hostName: String)
oder sogar
object Singleton type NodeId = Singleton.type
Diese Knoten erfüllen verschiedene Rollen, führen einige Dienste aus und sollten über TCP / HTTP-Verbindungen mit den anderen Knoten kommunizieren können.
Für die TCP-Verbindung ist mindestens eine Portnummer erforderlich. Wir möchten auch sicherstellen, dass Client und Server dasselbe Protokoll sprechen. Um eine Verbindung zwischen Knoten zu modellieren, deklarieren wir die folgende Klasse:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
Dabei ist Port nur ein Int innerhalb des zulässigen Bereichs:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
Verfeinerte TypenSiehe verfeinerte Bibliothek. Kurz gesagt, es ermöglicht das Hinzufügen von Einschränkungen für die Kompilierungszeit zu anderen Typen. In diesem Fall darf Int nur 16-Bit-Werte haben, die die Portnummer darstellen können. Es ist nicht erforderlich, diese Bibliothek für diesen Konfigurationsansatz zu verwenden. Es scheint einfach sehr gut zu passen.
Für HTTP (REST) benötigen wir möglicherweise auch einen Pfad des Dienstes:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
PhantomtypUm das Protokoll während der Kompilierung zu identifizieren, verwenden wir die Scala-Funktion zum Deklarieren des Typargumentprotokolls, das in der Klasse nicht verwendet wird. Es ist ein sogenannter Phantomtyp . Zur Laufzeit benötigen wir selten eine Instanz der Protokollkennung, deshalb speichern wir sie nicht. Während der Kompilierung bietet dieser Phantomtyp zusätzliche Typensicherheit. Wir können keinen Port mit falschem Protokoll übergeben.
Eines der am häufigsten verwendeten Protokolle ist die REST-API mit Json-Serialisierung:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
Dabei ist RequestMessage der Basistyp von Nachrichten, die der Client an den Server senden kann, und ResponseMessage ist die Antwortnachricht vom Server. Natürlich können wir auch andere Protokollbeschreibungen erstellen, die das Kommunikationsprotokoll mit der gewünschten Genauigkeit angeben.
Für die Zwecke dieses Beitrags verwenden wir eine einfachere Version des Protokolls:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
In diesem Protokoll wird die Anforderungsnachricht an die URL angehängt und die Antwortnachricht als einfache Zeichenfolge zurückgegeben.
Eine Dienstkonfiguration kann durch den Dienstnamen, eine Sammlung von Ports und einige Abhängigkeiten beschrieben werden. Es gibt einige Möglichkeiten, wie all diese Elemente in Scala dargestellt werden können (z. B. HList , algebraische Datentypen). Für die Zwecke dieses Beitrags verwenden wir das Kuchenmuster und stellen kombinierbare Teile (Module) als Merkmale dar. (Kuchenmuster ist keine Voraussetzung für diesen kompilierbaren Konfigurationsansatz. Es ist nur eine mögliche Umsetzung der Idee.)
Abhängigkeiten können mithilfe des Kuchenmusters als Endpunkte anderer Knoten dargestellt werden:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
Für den Echo-Dienst muss nur ein Port konfiguriert werden. Und wir erklären, dass dieser Port das Echo-Protokoll unterstützt. Beachten Sie, dass wir derzeit keinen bestimmten Port angeben müssen, da das Merkmal abstrakte Methodendeklarationen zulässt. Wenn wir abstrakte Methoden verwenden, benötigt der Compiler eine Implementierung in einer Konfigurationsinstanz. Hier haben wir die Implementierung ( 8081 ) bereitgestellt und sie wird als Standardwert verwendet, wenn wir sie in einer konkreten Konfiguration überspringen.
Wir können eine Abhängigkeit in der Konfiguration des Echo-Service-Clients deklarieren:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
Die Abhängigkeit hat den gleichen Typ wie der echoService . Insbesondere erfordert es das gleiche Protokoll. Daher können wir sicher sein, dass diese beiden Abhängigkeiten ordnungsgemäß funktionieren, wenn wir sie verbinden.
Implementierung von DienstenEin Dienst benötigt eine Funktion zum Starten und ordnungsgemäßen Herunterfahren. (Die Fähigkeit, einen Dienst herunterzufahren, ist für das Testen von entscheidender Bedeutung.) Auch hier gibt es einige Möglichkeiten, eine solche Funktion für eine bestimmte Konfiguration anzugeben (wir könnten beispielsweise Typklassen verwenden). Für diesen Beitrag verwenden wir wieder Cake Pattern. Wir können einen Dienst mit cats.Resource Ressource, die bereits Klammern und Ressourcenfreigabe bereitstellt. Um eine Ressource zu erhalten, sollten wir eine Konfiguration und einen Laufzeitkontext bereitstellen. Die Dienststartfunktion könnte also folgendermaßen aussehen:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
wo
Config - Konfigurationstyp, der von diesem Servicestarter benötigt wirdAddressResolver - ein Laufzeitobjekt, mit dem reale Adressen anderer Knoten AddressResolver werden können (lesen Sie weiter, um Einzelheiten zu AddressResolver ).
Die anderen Arten stammen von cats :
F[_] - cats.IO (Im einfachsten Fall könnte F[A] nur () => A In diesem Beitrag verwenden wir cats.IO )Reader[A,B] - ist mehr oder weniger ein Synonym für eine Funktion A => Bcats.Resource - hat Möglichkeiten zu erwerben und freizugebenTimer - Ermöglicht das Schlafen / Messen der ZeitContextShift - analog zu ExecutionContextApplicative - Wrapper der tatsächlichen Funktionen (fast eine Monade) (wir könnten ihn eventuell durch etwas anderes ersetzen)
Über diese Schnittstelle können wir einige Dienste implementieren. Zum Beispiel ein Dienst, der nichts tut:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(Weitere Quellimplementierungen finden Sie unter Quellcode - Echo-Dienst ,
Echo-Client und Lifetime-Controller .)
Ein Knoten ist ein einzelnes Objekt, auf dem einige Dienste ausgeführt werden (das Starten einer Ressourcenkette wird durch das Kuchenmuster ermöglicht):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Beachten Sie, dass wir im Knoten den genauen Konfigurationstyp angeben, der von diesem Knoten benötigt wird. Der Compiler lässt nicht zu, dass wir das Objekt (Cake) mit unzureichendem Typ erstellen, da jedes Service-Merkmal eine Einschränkung für den Config Typ deklariert. Außerdem können wir den Knoten nicht starten, ohne eine vollständige Konfiguration bereitzustellen.
Auflösung der KnotenadresseUm eine Verbindung herzustellen, benötigen wir für jeden Knoten eine echte Hostadresse. Es ist möglicherweise später als andere Teile der Konfiguration bekannt. Daher benötigen wir eine Möglichkeit, eine Zuordnung zwischen der Knoten-ID und ihrer tatsächlichen Adresse bereitzustellen. Diese Zuordnung ist eine Funktion:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Es gibt einige Möglichkeiten, eine solche Funktion zu implementieren.
- Wenn wir die tatsächlichen Adressen vor der Bereitstellung kennen, können wir während der Instanziierung der Knotenhosts Scala-Code mit den tatsächlichen Adressen generieren und anschließend den Build ausführen (der die Kompilierungszeit überprüft und dann die Integrationstestsuite ausführt). In diesem Fall ist unsere Zuordnungsfunktion statisch bekannt und kann zu einer Art
Map[NodeId, NodeAddress] vereinfacht werden. - Manchmal erhalten wir tatsächliche Adressen erst zu einem späteren Zeitpunkt, wenn der Knoten tatsächlich gestartet wird, oder wir haben keine Adressen von Knoten, die noch nicht gestartet wurden. In diesem Fall verfügen wir möglicherweise über einen Erkennungsdienst, der vor allen anderen Knoten gestartet wird, und jeder Knoten gibt möglicherweise seine Adresse in diesem Dienst bekannt und abonniert Abhängigkeiten.
- Wenn wir
/etc/hosts ändern können, können wir vordefinierte Hostnamen (wie my-project-main-node und echo-backend ) verwenden und diesen Namen zur Bereitstellungszeit einfach mit der IP-Adresse verknüpfen.
In diesem Beitrag werden diese Fälle nicht näher erläutert. In unserem Spielzeugbeispiel haben alle Knoten dieselbe IP-Adresse - 127.0.0.1 .
In diesem Beitrag werden zwei verteilte Systemlayouts betrachtet:
- Einzelknotenlayout, bei dem alle Dienste auf dem Einzelknoten platziert werden.
- Zwei-Knoten-Layout, bei dem sich Service und Client auf verschiedenen Knoten befinden.
Die Konfiguration für ein einzelnes Knotenlayout lautet wie folgt:
Einzelknotenkonfiguration object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
Hier erstellen wir eine einzelne Konfiguration, die sowohl die Server- als auch die Client-Konfiguration erweitert. Außerdem konfigurieren wir einen Lifecycle-Controller, der normalerweise Client und Server nach lifetime beendet.
Mit denselben Service-Implementierungen und -Konfigurationen kann das Layout eines Systems mit zwei separaten Knoten erstellt werden. Wir müssen nur zwei separate Knotenkonfigurationen mit den entsprechenden Diensten erstellen:
Konfiguration mit zwei Knoten object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
Sehen Sie, wie wir die Abhängigkeit angeben. Wir erwähnen den bereitgestellten Dienst des anderen Knotens als Abhängigkeit vom aktuellen Knoten. Die Art der Abhängigkeit wird überprüft, da sie einen Phantomtyp enthält, der das Protokoll beschreibt. Und zur Laufzeit haben wir die richtige Knoten-ID. Dies ist einer der wichtigen Aspekte des vorgeschlagenen Konfigurationsansatzes. Es gibt uns die Möglichkeit, den Port nur einmal festzulegen und sicherzustellen, dass wir auf den richtigen Port verweisen.
Implementierung mit zwei KnotenFür diese Konfiguration verwenden wir genau die gleichen Service-Implementierungen. Überhaupt keine Änderungen. Wir erstellen jedoch zwei verschiedene Knotenimplementierungen, die unterschiedliche Dienste enthalten:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Der erste Knoten implementiert den Server und benötigt nur die serverseitige Konfiguration. Der zweite Knoten implementiert den Client und benötigt einen anderen Teil der Konfiguration. Beide Knoten erfordern eine Lebensdauerangabe. Für die Zwecke dieses Post-Service-Knotens hat er eine unendliche Lebensdauer, die mit SIGTERM beendet werden kann, während der Echo-Client nach der konfigurierten endlichen Dauer beendet wird. Einzelheiten finden Sie in der Starteranwendung .
Gesamtentwicklungsprozess
Mal sehen, wie dieser Ansatz die Art und Weise verändert, wie wir mit der Konfiguration arbeiten.
Die Konfiguration als Code wird kompiliert und erzeugt ein Artefakt. Es erscheint sinnvoll, Konfigurationsartefakte von anderen Code-Artefakten zu trennen. Oft können wir eine Vielzahl von Konfigurationen auf derselben Codebasis haben. Und natürlich können wir mehrere Versionen verschiedener Konfigurationszweige haben. In einer Konfiguration können wir bestimmte Versionen von Bibliotheken auswählen. Diese bleiben bei jeder Bereitstellung dieser Konfiguration konstant.
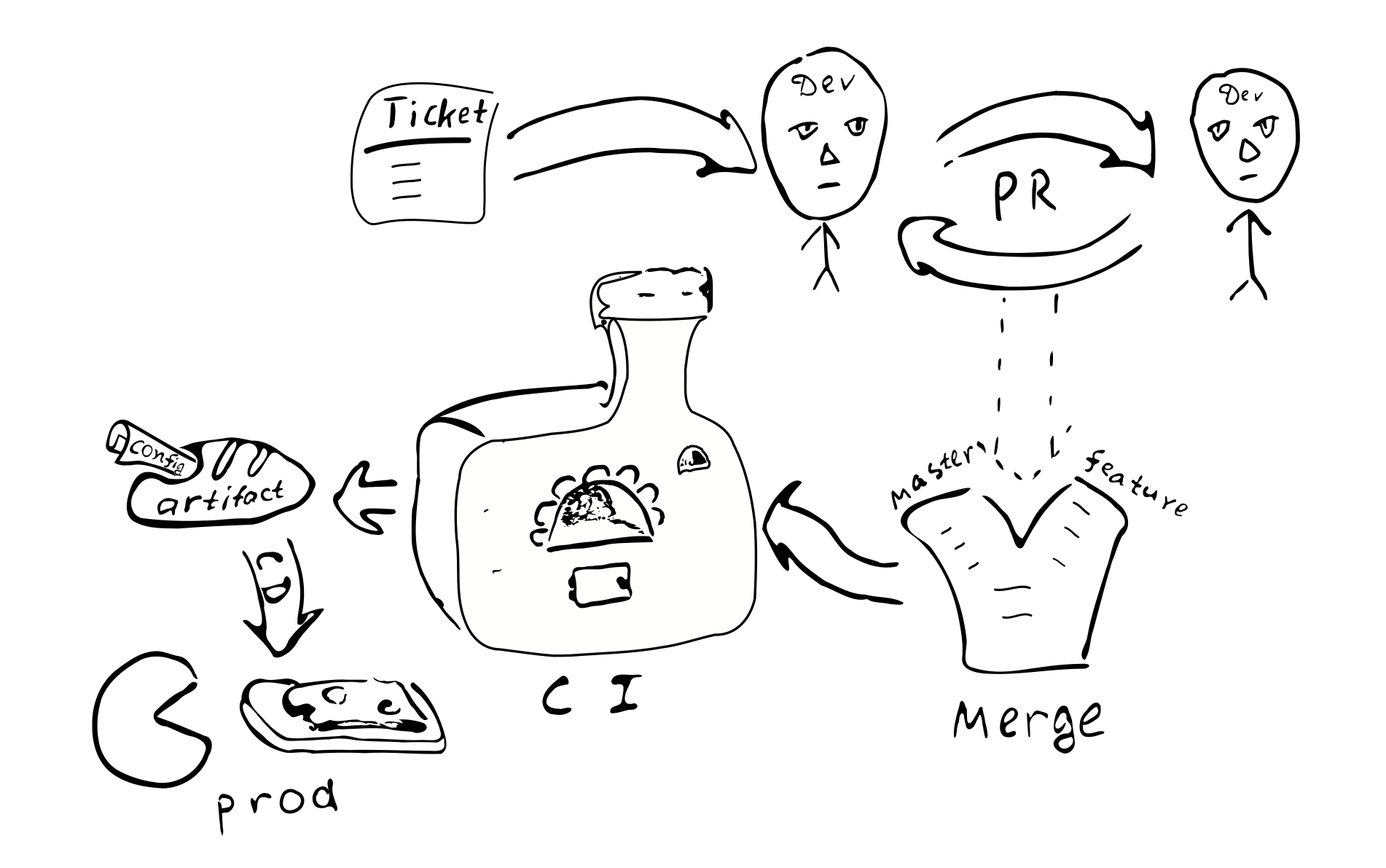
Eine Konfigurationsänderung wird zu einer Codeänderung. Es sollte also denselben Qualitätssicherungsprozess durchlaufen:
Ticket -> PR -> Überprüfung -> Zusammenführen -> kontinuierliche Integration -> kontinuierliche Bereitstellung
Der Ansatz hat folgende Konsequenzen:
Die Konfiguration ist für die Instanz eines bestimmten Systems kohärent. Es scheint, dass es keine Möglichkeit gibt, eine falsche Verbindung zwischen Knoten herzustellen.
Es ist nicht einfach, die Konfiguration nur in einem Knoten zu ändern. Es erscheint unvernünftig, sich anzumelden und einige Textdateien zu ändern. Dadurch wird eine Konfigurationsdrift weniger möglich.
Kleine Konfigurationsänderungen sind nicht einfach vorzunehmen.
Die meisten Konfigurationsänderungen folgen demselben Entwicklungsprozess und werden überprüft.
Benötigen wir ein separates Repository für die Produktionskonfiguration? Die Produktionskonfiguration enthält möglicherweise vertrauliche Informationen, die wir für viele Menschen unerreichbar halten möchten. Es kann sich daher lohnen, ein separates Repository mit eingeschränktem Zugriff zu führen, das die Produktionskonfiguration enthält. Wir können die Konfiguration in zwei Teile aufteilen - einen, der die offensten Produktionsparameter enthält, und einen, der den geheimen Teil der Konfiguration enthält. Dies würde den Zugriff der meisten Entwickler auf die meisten Parameter ermöglichen und gleichzeitig den Zugriff auf wirklich sensible Dinge einschränken. Dies lässt sich leicht mit Zwischenmerkmalen mit Standardparameterwerten erreichen.
Variationen
Lassen Sie uns die Vor- und Nachteile des vorgeschlagenen Ansatzes im Vergleich zu den anderen Konfigurationsmanagementtechniken sehen.
Zunächst werden einige Alternativen zu den verschiedenen Aspekten der vorgeschlagenen Art des Umgangs mit der Konfiguration aufgeführt:
- Textdatei auf dem Zielcomputer.
- Zentraler Schlüsselwertspeicher (wie
etcd / zookeeper ). - Unterprozesskomponenten, die ohne Neustart des Prozesses neu konfiguriert / neu gestartet werden können.
- Konfiguration außerhalb der Artefakt- und Versionskontrolle.
Die Textdatei bietet eine gewisse Flexibilität in Bezug auf Ad-hoc-Korrekturen. Der Administrator eines Systems kann sich beim Zielknoten anmelden, Änderungen vornehmen und den Dienst einfach neu starten. Dies ist möglicherweise nicht so gut für größere Systeme. Hinter der Änderung bleiben keine Spuren zurück. Die Änderung wird nicht von einem anderen Augenpaar überprüft. Es könnte schwierig sein herauszufinden, was die Änderung verursacht hat. Es wurde nicht getestet. Aus Sicht des verteilten Systems kann ein Administrator einfach vergessen, die Konfiguration auf einem der anderen Knoten zu aktualisieren.
(Übrigens, wenn irgendwann die Verwendung von Textkonfigurationsdateien erforderlich sein muss, müssen wir nur Parser + Validator hinzufügen, der denselben Config erzeugen kann und der ausreicht, um Textkonfigurationen zu verwenden. Dies zeigt auch, dass die Die Komplexität der Konfiguration zur Kompilierungszeit ist etwas geringer als die Komplexität textbasierter Konfigurationen, da wir in der textbasierten Version zusätzlichen Code benötigen.)
Der zentralisierte Schlüsselwertspeicher ist ein guter Mechanismus zum Verteilen von Anwendungsmetaparametern. Hier müssen wir darüber nachdenken, was wir als Konfigurationswerte betrachten und was nur Daten sind. Bei einer Funktion C => A => B wir normalerweise selten wechselnde Werte C "Konfiguration", während häufig geänderte Daten A - nur Daten eingeben. Die Funktion sollte früher als die Daten A konfiguriert werden A Angesichts dieser Idee können wir sagen, dass es die erwartete Häufigkeit von Änderungen ist, die verwendet werden könnten, um Konfigurationsdaten von nur Daten zu unterscheiden. Außerdem stammen Daten normalerweise aus einer Quelle (Benutzer) und die Konfiguration aus einer anderen Quelle (Administrator). Der Umgang mit Parametern, die nach der Prozessinitialisierung geändert werden können, führt zu einer Erhöhung der Anwendungskomplexität. Für solche Parameter müssen wir ihren Übermittlungsmechanismus, das Parsen und die Validierung sowie falsche Werte behandeln. Um die Programmkomplexität zu verringern, sollten wir daher die Anzahl der Parameter reduzieren, die sich zur Laufzeit ändern können (oder sie sogar ganz eliminieren).
Aus der Perspektive dieses Beitrags sollten wir zwischen statischen und dynamischen Parametern unterscheiden. Wenn die Servicelogik zur Laufzeit eine seltene Änderung einiger Parameter erfordert, können wir sie als dynamische Parameter bezeichnen. Andernfalls sind sie statisch und können mit dem vorgeschlagenen Ansatz konfiguriert werden. Für die dynamische Rekonfiguration sind möglicherweise andere Ansätze erforderlich. Beispielsweise können Teile des Systems mit den neuen Konfigurationsparametern ähnlich wie beim Neustart separater Prozesse eines verteilten Systems neu gestartet werden.
(Meine bescheidene Meinung ist, eine Neukonfiguration der Laufzeit zu vermeiden, da dies die Komplexität des Systems erhöht.
Es ist möglicherweise einfacher, sich beim Neustart von Prozessen nur auf die Unterstützung des Betriebssystems zu verlassen. Dies ist jedoch möglicherweise nicht immer möglich.)
Ein wichtiger Aspekt bei der Verwendung der statischen Konfiguration, der manchmal dazu führt, dass Benutzer eine dynamische Konfiguration in Betracht ziehen (ohne andere Gründe), ist die Ausfallzeit des Dienstes während der Konfigurationsaktualisierung. Wenn wir Änderungen an der statischen Konfiguration vornehmen müssen, müssen wir das System neu starten, damit neue Werte wirksam werden. Die Anforderungen an Ausfallzeiten variieren für verschiedene Systeme, daher ist dies möglicherweise nicht so kritisch. Wenn es kritisch ist, müssen wir einen Neustart des Systems im Voraus planen. Zum Beispiel könnten wir das Entleeren von AWS ELB-Verbindungen implementieren. In diesem Szenario starten wir bei jedem Neustart des Systems parallel eine neue Instanz des Systems und schalten dann ELB darauf um, während das alte System die Wartung bestehender Verbindungen abschließen kann.
Was ist mit der Konfiguration innerhalb eines versionierten Artefakts oder außerhalb? Wenn Sie die Konfiguration in einem Artefakt behalten, bedeutet dies in den meisten Fällen, dass diese Konfiguration denselben Qualitätssicherungsprozess wie andere Artefakte durchlaufen hat. Man könnte also sicher sein, dass die Konfiguration von guter Qualität und vertrauenswürdig ist. Im Gegenteil, die Konfiguration in einer separaten Datei bedeutet, dass keine Spuren davon vorhanden sind, wer und warum Änderungen an dieser Datei vorgenommen haben. Ist das wichtig Wir glauben, dass es für die meisten Produktionssysteme besser ist, eine stabile und qualitativ hochwertige Konfiguration zu haben.
Mit der Version des Artefakts können Sie herausfinden, wann es erstellt wurde, welche Werte es enthält, welche Funktionen aktiviert / deaktiviert sind und wer für jede Änderung in der Konfiguration verantwortlich war. Es kann einige Anstrengungen erfordern, die Konfiguration in einem Artefakt zu halten, und es ist eine Designentscheidung, die getroffen werden muss.
Vor- und Nachteile
Hier möchten wir einige Vorteile hervorheben und einige Nachteile des vorgeschlagenen Ansatzes diskutieren.
Vorteile
Merkmale der kompilierbaren Konfiguration eines vollständig verteilten Systems:
- Statische Überprüfung der Konfiguration. Dies gibt ein hohes Maß an Sicherheit, dass die Konfiguration bei Typbeschränkungen korrekt ist.
- Reichhaltige Konfigurationssprache. Typischerweise beschränken sich andere Konfigurationsansätze auf höchstens variable Substitution.
Mit Scala kann man eine Vielzahl von Sprachfunktionen verwenden, um die Konfiguration zu verbessern. Zum Beispiel können wir Merkmale verwenden, um Standardwerte bereitzustellen, Objekte, um unterschiedliche val festzulegen. Wir können auf Werte verweisen, die nur einmal im äußeren Bereich (DRY) definiert sind. Es ist möglich, Literalsequenzen oder Instanzen bestimmter Klassen ( Seq , Map usw.) zu verwenden. - DSL Scala hat gute Unterstützung für DSL-Autoren. Mit diesen Funktionen kann eine Konfigurationssprache eingerichtet werden, die bequemer und benutzerfreundlicher ist, sodass die endgültige Konfiguration zumindest für Domänenbenutzer lesbar ist.
- Integrität und Kohärenz über Knoten hinweg. Einer der Vorteile einer Konfiguration für das gesamte verteilte System an einem Ort besteht darin, dass alle Werte streng einmal definiert und dann an allen Stellen wiederverwendet werden, an denen wir sie benötigen. Geben Sie außerdem sichere Portdeklarationen ein, um sicherzustellen, dass die Knoten des Systems in allen möglichen korrekten Konfigurationen dieselbe Sprache sprechen. Es gibt explizite Abhängigkeiten zwischen Knoten, die es schwierig machen, die Bereitstellung einiger Dienste zu vergessen.
- Hohe Qualität der Änderungen. Der Gesamtansatz, Konfigurationsänderungen durch einen normalen PR-Prozess zu übergeben, legt auch in der Konfiguration hohe Qualitätsstandards fest.
- Gleichzeitige Konfigurationsänderungen. Wenn wir Änderungen an der Konfiguration vornehmen, stellt die automatische Bereitstellung sicher, dass alle Knoten aktualisiert werden.
- Vereinfachung der Anwendung. Die Anwendung muss die Konfiguration nicht analysieren und validieren und falsche Konfigurationswerte verarbeiten. Dies vereinfacht die Gesamtanwendung. (Die Konfiguration selbst nimmt etwas an Komplexität zu, ist jedoch ein bewusster Kompromiss zur Sicherheit.) Es ist ziemlich einfach, zur normalen Konfiguration zurückzukehren - fügen Sie einfach die fehlenden Teile hinzu. Es ist einfacher, mit der kompilierten Konfiguration zu beginnen und die Implementierung zusätzlicher Teile auf einen späteren Zeitpunkt zu verschieben.
- Versionierte Konfiguration. Aufgrund der Tatsache, dass Konfigurationsänderungen dem gleichen Entwicklungsprozess folgen, erhalten wir ein Artefakt mit einer eindeutigen Version. Dadurch können wir die Konfiguration bei Bedarf zurückschalten. Wir können sogar eine Konfiguration bereitstellen, die vor einem Jahr verwendet wurde, und sie funktioniert genauso. Eine stabile Konfiguration verbessert die Vorhersagbarkeit und Zuverlässigkeit des verteilten Systems. Die Konfiguration ist zur Kompilierungszeit festgelegt und kann auf einem Produktionssystem nicht einfach manipuliert werden.
- Modularität Das vorgeschlagene Framework ist modular aufgebaut und Module können auf verschiedene Arten kombiniert werden
unterstützen verschiedene Konfigurationen (Setups / Layouts). Insbesondere ist es möglich, ein kleines Einzelknotenlayout und eine große Mehrknoteneinstellung zu haben. Es ist vernünftig, mehrere Produktionslayouts zu haben. - Testen Zu Testzwecken kann man einen Mock-Service implementieren und ihn typsicher als Abhängigkeit verwenden. Einige verschiedene Testlayouts mit verschiedenen Teilen, die durch Mocks ersetzt wurden, konnten gleichzeitig beibehalten werden.
- Integrationstests. In verteilten Systemen ist es manchmal schwierig, Integrationstests durchzuführen. Mit dem beschriebenen Ansatz zur typsicheren Konfiguration des gesamten verteilten Systems können wir alle verteilten Teile auf kontrollierbare Weise auf einem einzigen Server ausführen. Es ist einfach, die Situation zu emulieren
wenn einer der Dienste nicht mehr verfügbar ist.
Nachteile
Der kompilierte Konfigurationsansatz unterscheidet sich von der "normalen" Konfiguration und entspricht möglicherweise nicht allen Anforderungen. Hier sind einige der Nachteile der kompilierten Konfiguration:
- Statische Konfiguration. Es ist möglicherweise nicht für alle Anwendungen geeignet. In einigen Fällen muss die Konfiguration in der Produktion unter Umgehung aller Sicherheitsmaßnahmen schnell repariert werden. Dieser Ansatz macht es schwieriger. Die Kompilierung und erneute Bereitstellung ist erforderlich, nachdem Änderungen an der Konfiguration vorgenommen wurden. Dies ist sowohl das Merkmal als auch die Belastung.
- Konfigurationsgenerierung. Wenn die Konfiguration von einem Automatisierungstool generiert wird, erfordert dieser Ansatz eine nachfolgende Kompilierung (die wiederum fehlschlagen kann). Die Integration dieses zusätzlichen Schritts in das Build-System erfordert möglicherweise zusätzlichen Aufwand.
- Instrumente. Heutzutage werden viele Tools verwendet, die auf textbasierten Konfigurationen basieren. Einige von ihnen
gilt nicht, wenn die Konfiguration kompiliert wird. - Eine Änderung der Denkweise ist erforderlich. Entwickler und DevOps sind mit Textkonfigurationsdateien vertraut. Die Idee, die Konfiguration zu kompilieren, mag ihnen seltsam erscheinen.
- Vor der Einführung einer kompilierbaren Konfiguration ist ein qualitativ hochwertiger Softwareentwicklungsprozess erforderlich.
Das implementierte Beispiel weist einige Einschränkungen auf:
- Wenn wir eine zusätzliche Konfiguration bereitstellen, die von der Knotenimplementierung nicht verlangt wird, hilft uns der Compiler nicht dabei, die fehlende Implementierung zu erkennen. Dies könnte durch die Verwendung von
HList oder ADTs ( HList ) für die Knotenkonfiguration anstelle von Merkmalen und HList . - Wir müssen ein Boilerplate in der Konfigurationsdatei bereitstellen: (
package , import , object ;
override def für Parameter mit Standardwerten override def ). Dies kann teilweise mit einem DSL behoben werden. - In diesem Beitrag behandeln wir nicht die dynamische Rekonfiguration von Clustern ähnlicher Knoten.
Fazit
In diesem Beitrag haben wir die Idee diskutiert, die Konfiguration direkt im Quellcode typsicher darzustellen. Der Ansatz könnte in vielen Anwendungen als Ersatz für XML- und andere textbasierte Konfigurationen verwendet werden. Obwohl unser Beispiel in Scala implementiert wurde, könnte es auch in andere kompilierbare Sprachen (wie Kotlin, C #, Swift usw.) übersetzt werden. Man könnte diesen Ansatz in einem neuen Projekt ausprobieren und, falls er nicht gut passt, auf die altmodische Weise wechseln.
Natürlich erfordert eine kompilierbare Konfiguration einen qualitativ hochwertigen Entwicklungsprozess. Im Gegenzug verspricht es eine ebenso hochwertige robuste Konfiguration.
Dieser Ansatz könnte auf verschiedene Arten erweitert werden:
- Man könnte Makros verwenden, um die Konfigurationsvalidierung durchzuführen und zur Kompilierungszeit fehlzuschlagen, falls geschäftslogische Einschränkungen fehlschlagen.
- Ein DSL könnte implementiert werden, um die Konfiguration domänenbenutzerfreundlich darzustellen.
- Dynamisches Ressourcenmanagement mit automatischen Konfigurationsanpassungen. Wenn wir beispielsweise die Anzahl der Clusterknoten anpassen, möchten wir möglicherweise (1), dass die Knoten eine leicht modifizierte Konfiguration erhalten; (2) Cluster-Manager zum Empfangen neuer Knoteninformationen.
Danke
Ich möchte mich bei Andrey Saksonov, Pavel Popov und Anton Nehaev für das inspirierende Feedback zum Entwurf dieses Beitrags bedanken, das mir geholfen hat, ihn klarer zu machen.