Ich möchte Ihnen einen interessanten Mechanismus für die Arbeit mit einer verteilten Systemkonfiguration vorstellen. Die Konfiguration wird direkt in einer kompilierten Sprache (Scala) unter Verwendung sicherer Typen dargestellt. In diesem Beitrag wird ein Beispiel für eine solche Konfiguration analysiert und verschiedene Aspekte der Einführung einer kompilierten Konfiguration in den gesamten Entwicklungsprozess werden berücksichtigt.
( Englisch )
Einführung
Der Aufbau eines zuverlässigen verteilten Systems setzt voraus, dass alle Knoten die richtige Konfiguration verwenden, die mit anderen Knoten synchronisiert ist. In der Regel werden DevOps-Technologien (Terraform, Ansible oder ähnliches) verwendet, um automatisch Konfigurationsdateien zu generieren (häufig eigene für jeden Knoten). Wir möchten auch sicherstellen, dass alle interagierenden Knoten identische Protokolle verwenden (einschließlich derselben Version). Andernfalls wird Inkompatibilität in unser verteiltes System eingebettet. In der JVM-Welt ist eine Konsequenz dieser Anforderung die Notwendigkeit, überall dieselbe Version einer Bibliothek zu verwenden, die Protokollnachrichten enthält.
Was ist mit verteilten Systemtests? Wir gehen natürlich davon aus, dass Unit-Tests für alle Komponenten bereitgestellt werden, bevor wir mit Integrationstests fortfahren. (Damit wir die Testergebnisse auf die Laufzeit extrapolieren können, müssen wir in der Testphase und zur Laufzeit auch einen identischen Satz von Bibliotheken bereitstellen.)
Bei der Arbeit mit Integrationstests ist es häufig überall einfacher, auf allen Knoten einen einzelnen Klassenpfad zu verwenden. Wir müssen nur sicherstellen, dass derselbe Klassenpfad zur Laufzeit beteiligt ist. (Trotz der Tatsache, dass es durchaus möglich ist, verschiedene Knoten mit unterschiedlichen Klassenpfaden auszuführen, führt dies zu Komplikationen bei der gesamten Konfiguration und zu Schwierigkeiten bei Bereitstellungs- und Integrationstests.) In diesem Beitrag wird davon ausgegangen, dass auf allen Knoten derselbe Klassenpfad verwendet wird.
Die Konfiguration entwickelt sich mit der Anwendung. Um die verschiedenen Phasen der Programmentwicklung zu identifizieren, verwenden wir Versionen. Es erscheint logisch, auch verschiedene Versionen der Konfigurationen zu identifizieren. Und die Konfiguration selbst sollte im Versionskontrollsystem platziert werden. Wenn es in der Produktion nur eine Konfiguration gibt, können wir nur die Versionsnummer verwenden. Wenn viele Produktionsinstanzen verwendet werden, benötigen wir mehrere
Konfigurationszweige und ein zusätzliches Label zusätzlich zur Version (z. B. der Name des Zweigs). Somit können wir die genaue Konfiguration eindeutig identifizieren. Jede Konfigurationskennung entspricht eindeutig einer bestimmten Kombination von verteilten Knoten, Ports, externen Ressourcen und Bibliotheksversionen. Im Rahmen dieses Beitrags gehen wir von der Tatsache aus, dass es nur einen Zweig gibt, und wir können die Konfiguration auf die übliche Weise anhand von drei durch einen Punkt getrennten Zahlen (1.2.3) identifizieren.
In modernen Umgebungen werden Konfigurationsdateien nur sehr selten manuell erstellt. Sie werden häufiger während der Bereitstellung generiert und nicht mehr berührt (um nichts zu beschädigen ). Es stellt sich die logische Frage, warum wir immer noch ein Textformat zum Speichern der Konfiguration verwenden. Eine völlig praktikable Alternative ist die Möglichkeit, regulären Code für die Konfiguration zu verwenden und bei der Kompilierung von Überprüfungen zu profitieren.
In diesem Beitrag untersuchen wir nur die Idee, eine Konfiguration in einem kompilierten Artefakt darzustellen.
Kompilierte Konfiguration
Dieser Abschnitt beschreibt ein Beispiel für eine statisch kompilierte Konfiguration. Es sind zwei einfache Dienste implementiert - ein Echo-Dienst und ein Echo-Dienst-Client. Basierend auf diesen beiden Diensten werden zwei Versionen des Systems zusammengestellt. In einer Ausführungsform befinden sich beide Dienste auf demselben Knoten, in einer anderen Ausführungsform auf verschiedenen Knoten.
In der Regel enthält ein verteiltes System mehrere Knoten. Knoten können mit Werten eines NodeId Typs NodeId :
sealed trait NodeId case object Backend extends NodeId case object Frontend extends NodeId
oder
case class NodeId(hostName: String)
oder sogar
object Singleton type NodeId = Singleton.type
Knoten spielen verschiedene Rollen, Dienste werden auf ihnen gestartet und TCP / HTTP-Kommunikation kann zwischen ihnen hergestellt werden.
Zur Beschreibung der TCP-Kommunikation benötigen wir mindestens eine Portnummer. Wir möchten auch das Protokoll widerspiegeln, das an diesem Port unterstützt wird, um sicherzustellen, dass sowohl der Client als auch der Server dasselbe Protokoll verwenden. Wir werden die Verbindung mit dieser Klasse beschreiben:
case class TcpEndPoint[Protocol](node: NodeId, port: Port[Protocol])
Dabei ist Port nur eine Ganzzahl Int mit einem Bereich gültiger Werte:
type PortNumber = Refined[Int, Closed[_0, W.`65535`.T]]
Verfeinerte TypenSiehe verfeinerte Bibliothek und meinen Bericht . Kurz gesagt, mit der Bibliothek können Sie Typen Einschränkungen hinzufügen, die beim Kompilieren überprüft werden. In diesem Fall sind die gültigen Portnummernwerte ganzzahlige 16-Bit-Zahlen. Bei einer kompilierten Konfiguration ist die Verwendung der verfeinerten Bibliothek optional, kann jedoch die Fähigkeit des Compilers verbessern, die Konfiguration zu überprüfen.
Für HTTP (REST) -Protokolle benötigen wir neben der Portnummer möglicherweise auch einen Pfad zum Dienst:
type UrlPathPrefix = Refined[String, MatchesRegex[W.`"[a-zA-Z_0-9/]*"`.T]] case class PortWithPrefix[Protocol](portNumber: PortNumber, pathPrefix: UrlPathPrefix)
PhantomtypenUm das Protokoll in der Kompilierungsphase zu identifizieren, verwenden wir einen Typparameter, der in der Klasse nicht verwendet wird. Diese Entscheidung beruht auf der Tatsache, dass wir zur Laufzeit keine Protokollinstanz verwenden, aber wir möchten, dass der Compiler die Protokollkompatibilität überprüft. Dank des Protokolls können wir den ungeeigneten Dienst nicht als Abhängigkeit übertragen.
Ein gängiges Protokoll ist die REST-API mit Json-Serialisierung:
sealed trait JsonHttpRestProtocol[RequestMessage, ResponseMessage]
Dabei ist RequestMessage der Anforderungstyp, ResponseMessage der Antworttyp.
Natürlich können Sie auch andere Protokollbeschreibungen verwenden, die die von uns gewünschte Genauigkeit bieten.
Für die Zwecke dieses Beitrags verwenden wir eine vereinfachte Version des Protokolls:
sealed trait SimpleHttpGetRest[RequestMessage, ResponseMessage]
Hier ist die Anforderung eine Zeichenfolge, die der URL hinzugefügt wird, und die Antwort ist die zurückgegebene Zeichenfolge im Hauptteil der HTTP-Antwort.
Die Dienstkonfiguration wird durch den Dienstnamen, die Ports und die Abhängigkeiten beschrieben. Diese Elemente können in Scala auf verschiedene Arten dargestellt werden (z. B. HList , algebraische Datentypen). Für die Zwecke dieses Beitrags verwenden wir das Kuchenmuster und repräsentieren die Module mithilfe von trait . (Kuchenmuster ist kein notwendiges Element des beschriebenen Ansatzes. Es ist nur eine der möglichen Implementierungen.)
Abhängigkeiten zwischen Diensten können als Methoden dargestellt werden, die die EndPoint Ports anderer Knoten zurückgeben:
type EchoProtocol[A] = SimpleHttpGetRest[A, A] trait EchoConfig[A] extends ServiceConfig { def portNumber: PortNumber = 8081 def echoPort: PortWithPrefix[EchoProtocol[A]] = PortWithPrefix[EchoProtocol[A]](portNumber, "echo") def echoService: HttpSimpleGetEndPoint[NodeId, EchoProtocol[A]] = providedSimpleService(echoPort) }
Um einen Echodienst zu erstellen, sind nur eine Portnummer und ein Hinweis darauf, dass dieser Port das Echoprotokoll unterstützt, ausreichend. Wir konnten keinen bestimmten Port angeben, weil Mit Merkmalen können Sie Methoden ohne Implementierung deklarieren (abstrakte Methoden). In diesem Fall müsste der Compiler beim Erstellen einer bestimmten Konfiguration eine abstrakte Methodenimplementierung und eine Portnummer angeben. Da wir die Methode beim Erstellen einer bestimmten Konfiguration implementiert haben, können wir keinen anderen Port angeben. Der Standardwert wird verwendet.
In der Client-Konfiguration deklarieren wir eine Abhängigkeit vom Echo-Service:
trait EchoClientConfig[A] { def testMessage: String = "test" def pollInterval: FiniteDuration def echoServiceDependency: HttpSimpleGetEndPoint[_, EchoProtocol[A]] }
Die Abhängigkeit ist vom selben Typ wie der exportierte Dienst echoService . Insbesondere im Echo-Client benötigen wir dasselbe Protokoll. Daher können wir beim Verbinden der beiden Dienste sicher sein, dass alles ordnungsgemäß funktioniert.
Service-ImplementierungZum Starten und Stoppen des Dienstes ist eine Funktion erforderlich. (Die Möglichkeit, den Dienst zu stoppen, ist für das Testen von entscheidender Bedeutung.) Auch hier gibt es verschiedene Optionen zum Implementieren dieser Funktion (wir könnten beispielsweise Typklassen verwenden, die auf dem Konfigurationstyp basieren). Für die Zwecke dieses Beitrags verwenden wir das Kuchenmuster. Wir werden den Service mit der cats.Resource Klasse vertreten, weil In dieser Klasse sind bereits Mittel zur sicheren garantierten Freigabe von Ressourcen bei Problemen vorhanden. Um die Ressource zu erhalten, müssen wir eine Konfiguration und einen fertigen Laufzeitkontext bereitstellen. Die Funktion zum Starten des Dienstes kann folgendermaßen aussehen:
type ResourceReader[F[_], Config, A] = Reader[Config, Resource[F, A]] trait ServiceImpl[F[_]] { type Config def resource( implicit resolver: AddressResolver[F], timer: Timer[F], contextShift: ContextShift[F], ec: ExecutionContext, applicative: Applicative[F] ): ResourceReader[F, Config, Unit] }
wo
Config - Konfigurationstyp für diesen DienstAddressResolver - ein Laufzeitobjekt, mit dem Sie die Adressen anderer Knoten ermitteln können (siehe unten).
und andere Typen aus der cats :
F[_] - Art des Effekts (im einfachsten Fall kann F[A] nur eine Funktion sein () => A In diesem Beitrag werden wir cats.IOReader[A,B] - mehr oder weniger gleichbedeutend mit der Funktion A => Bcats.Resource - eine Ressource, die erhalten und freigegeben werden kannTimer - Timer (ermöglicht es Ihnen, eine Weile einzuschlafen und Zeitintervalle zu messen)ContextShift - Analogon von ExecutionContextApplicative - eine Effekttypklasse, mit der Sie einzelne Effekte kombinieren können (fast eine Monade). In komplexeren Anwendungen scheint es besser zu sein, Monad / ConcurrentEffect .
Mit dieser Funktionssignatur können wir mehrere Dienste implementieren. Zum Beispiel ein Dienst, der nichts tut:
trait ZeroServiceImpl[F[_]] extends ServiceImpl[F] { type Config <: Any def resource(...): ResourceReader[F, Config, Unit] = Reader(_ => Resource.pure[F, Unit](())) }
(Weitere Dienste finden Sie im Quellcode - Echo-Dienst , Echo-Client
und Lebensdauerkontrollen .)
Ein Knoten ist ein Objekt, das mehrere Dienste starten kann (der Start der Ressourcenkette wird durch das Kuchenmuster sichergestellt):
object SingleNodeImpl extends ZeroServiceImpl[IO] with EchoServiceService with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Bitte beachten Sie, dass wir den genauen Konfigurationstyp angeben, der für diesen Knoten erforderlich ist. Wenn wir vergessen, einen der Konfigurationstypen anzugeben, die von einem separaten Dienst benötigt werden, tritt ein Kompilierungsfehler auf. Außerdem können wir den Knoten nicht starten, wenn wir einem Objekt des entsprechenden Typs nicht alle erforderlichen Daten zur Verfügung stellen.
Auflösung des HostnamensUm eine Verbindung zu einem Remote-Host herzustellen, benötigen wir eine echte IP-Adresse. Es ist möglich, dass die Adresse später als der Rest der Konfiguration bekannt wird. Daher benötigen wir eine Funktion, die die Knotenkennung der Adresse zuordnet:
case class NodeAddress[NodeId](host: Uri.Host) trait AddressResolver[F[_]] { def resolve[NodeId](nodeId: NodeId): F[NodeAddress[NodeId]] }
Sie können eine solche Funktion auf verschiedene Arten implementieren:
- Wenn uns Adressen vor der Bereitstellung bekannt werden, können wir mit einen Scala-Code generieren
Adressen und starten Sie dann die Montage. Dadurch werden die Tests kompiliert und ausgeführt.
In diesem Fall ist die Funktion statisch bekannt und kann im Code als Kartenanzeige Map[NodeId, NodeAddress] . - In einigen Fällen wird eine gültige Adresse erst bekannt, nachdem der Knoten gestartet wurde.
In diesem Fall können wir einen "Erkennungsdienst" (Discovery) implementieren, der ausgeführt wird, bevor die anderen Knoten und alle Knoten sich in diesem Dienst registrieren und die Adressen anderer Knoten anfordern. - Wenn wir
/etc/hosts ändern können, können wir vordefinierte Hostnamen (wie my-project-main-node und echo-backend ) verwenden und diese Namen einfach binden
mit IP-Adressen während der Bereitstellung.
Im Rahmen dieses Beitrags werden wir diese Fälle nicht näher betrachten. Für unsere
In einem Spielzeugbeispiel haben alle Knoten eine IP-Adresse - 127.0.0.1 .
Als nächstes betrachten wir zwei Optionen für ein verteiltes System:
- Platzierung aller Dienste auf einem Knoten.
- Und die Platzierung des Echo-Dienstes und des Echo-Clients auf verschiedenen Knoten.
Konfiguration für einen einzelnen Knoten :
Einzelknotenkonfiguration object SingleNodeConfig extends EchoConfig[String] with EchoClientConfig[String] with FiniteDurationLifecycleConfig { case object Singleton // identifier of the single node // configuration of server type NodeId = Singleton.type def nodeId = Singleton override def portNumber: PortNumber = 8088
Das Objekt implementiert die Konfiguration von Client und Server. Die Konfiguration der Lebensdauer wird auch verwendet, um das Programm nach einer lifetime zu beenden. (Strg-C funktioniert auch und gibt alle Ressourcen korrekt frei.)
Mit denselben Konfigurationsmerkmalen und Implementierungen kann ein System erstellt werden, das aus zwei separaten Knoten besteht :
Konfiguration für zwei Knoten object NodeServerConfig extends EchoConfig[String] with SigTermLifecycleConfig { type NodeId = NodeIdImpl def nodeId = NodeServer override def portNumber: PortNumber = 8080 } object NodeClientConfig extends EchoClientConfig[String] with FiniteDurationLifecycleConfig {
Wichtig! Beachten Sie, wie die Servicebindung ausgeführt wird. Wir geben den von einem Knoten implementierten Dienst als Implementierung der Abhängigkeitsmethode eines anderen Knotens an. Die Art der Abhängigkeit wird vom Compiler überprüft, weil enthält die Art des Protokolls. Beim Start enthält die Abhängigkeit die korrekte Kennung des Zielknotens. Dank dieses Schemas geben wir die Portnummer genau einmal an und beziehen uns garantiert immer auf den richtigen Port.
Implementierung von zwei SystemknotenFür diese Konfiguration verwenden wir dieselbe Service-Implementierung ohne Änderungen. Der einzige Unterschied besteht darin, dass wir jetzt zwei Objekte haben, die unterschiedliche Sätze von Diensten implementieren:
object TwoJvmNodeServerImpl extends ZeroServiceImpl[IO] with EchoServiceService with SigIntLifecycleServiceImpl { type Config = EchoConfig[String] with SigTermLifecycleConfig } object TwoJvmNodeClientImpl extends ZeroServiceImpl[IO] with EchoClientService with FiniteDurationLifecycleServiceImpl { type Config = EchoClientConfig[String] with FiniteDurationLifecycleConfig }
Der erste Knoten implementiert den Server und benötigt nur die Serverkonfiguration. Der zweite Knoten wird vom Client implementiert und verwendet einen anderen Teil der Konfiguration. Beide Knoten müssen auch die Lebensdauer verwalten. Der Serverknoten wird unbegrenzt ausgeführt, bis er von SIGTERM gestoppt wird und der Clientknoten nach einiger Zeit beendet wird. Siehe die Startanwendung .
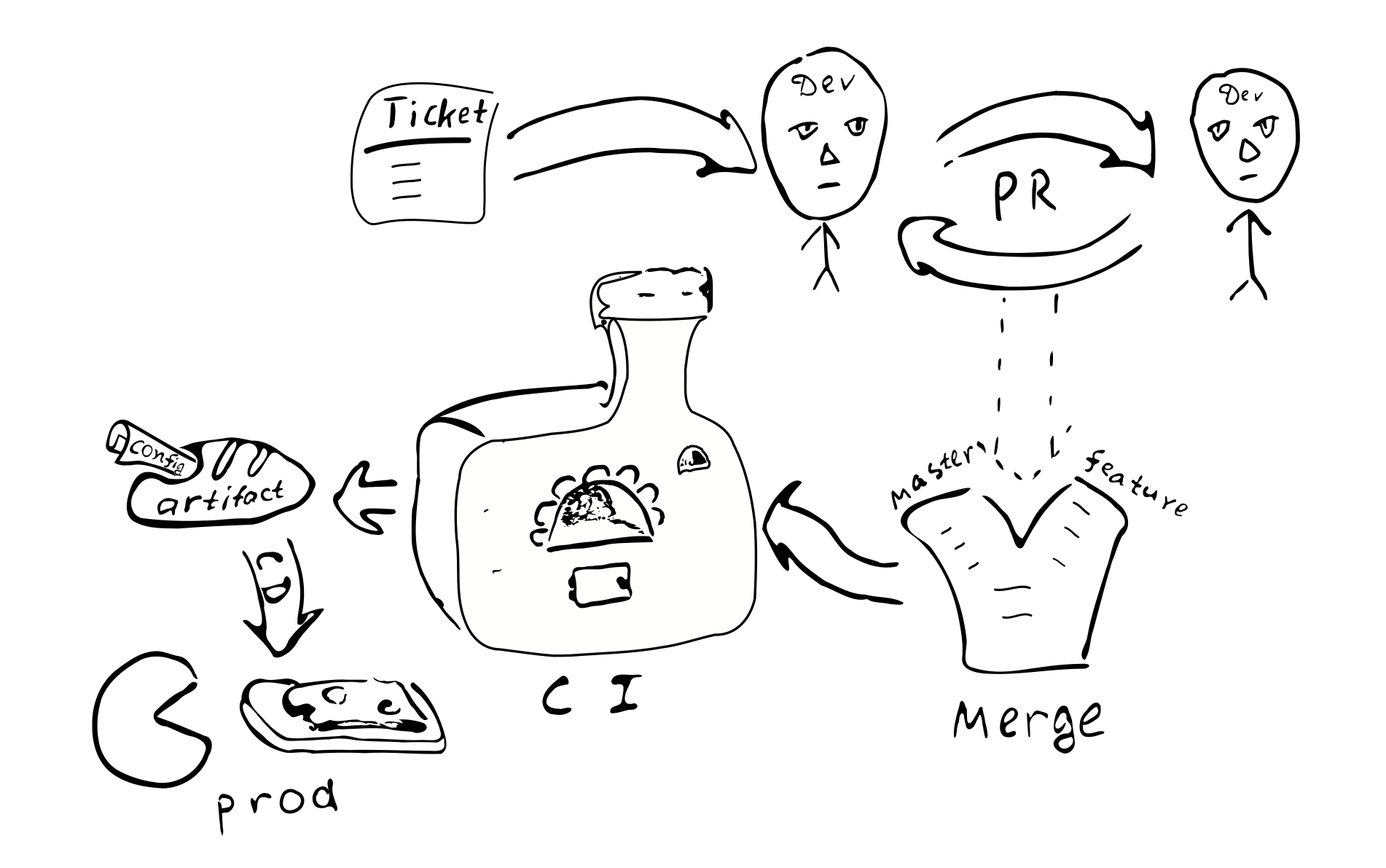
Allgemeiner Entwicklungsprozess
Lassen Sie uns sehen, wie sich dieser Konfigurationsansatz auf den gesamten Entwicklungsprozess auswirkt.
Die Konfiguration wird zusammen mit dem Rest des Codes kompiliert und ein Artefakt (.jar) wird generiert. Anscheinend ist es sinnvoll, die Konfiguration in einem separaten Artefakt zu platzieren. Dies liegt an der Tatsache, dass wir viele Konfigurationen basierend auf demselben Code haben können. Auch hier können Sie Artefakte generieren, die verschiedenen Konfigurationszweigen entsprechen. Zusammen mit der Konfiguration bleiben Abhängigkeiten von bestimmten Versionen von Bibliotheken erhalten, und diese Versionen bleiben für immer erhalten, wenn wir uns entscheiden, diese Version der Konfiguration bereitzustellen.
Jede Konfigurationsänderung wird zu einer Codeänderung. Und deshalb jeder solche
Änderungen werden durch den üblichen Qualitätssicherungsprozess abgedeckt:
Ein Ticket im Bugtracker -> PR -> Review -> mit den entsprechenden Filialen zusammenführen ->
Integration -> Bereitstellung
Die Hauptfolgen der Implementierung einer kompilierten Konfiguration:
Die Konfiguration wird auf allen Knoten des verteilten Systems koordiniert. Aufgrund der Tatsache, dass alle Knoten dieselbe Konfiguration von einer einzigen Quelle erhalten.
Es ist problematisch, die Konfiguration nur in einem der Knoten zu ändern. Daher ist eine „Konfigurationsdrift“ unwahrscheinlich.
Es wird schwieriger, kleine Konfigurationsänderungen vorzunehmen.
Die meisten Konfigurationsänderungen werden im Rahmen des gesamten Entwicklungsprozesses vorgenommen und überprüft.
Benötige ich ein separates Repository zum Speichern der Produktionskonfiguration? Eine solche Konfiguration kann Passwörter und andere geheime Informationen enthalten, auf die wir den Zugriff beschränken möchten. Auf dieser Grundlage erscheint es sinnvoll, die endgültige Konfiguration in einem separaten Repository zu speichern. Sie können die Konfiguration in zwei Teile unterteilen - einen mit öffentlichen Konfigurationseinstellungen und einen mit Einstellungen für eingeschränkten Zugriff. Dadurch können die meisten Entwickler auf allgemeine Parameter zugreifen. Diese Trennung ist leicht mit Zwischenmerkmalen zu erreichen, die Standardwerte enthalten.
Mögliche Abweichungen
Versuchen wir, die kompilierte Konfiguration mit einigen gängigen Alternativen zu vergleichen:
- Eine Textdatei auf dem Zielcomputer.
- Zentraler Schlüsselwertspeicher (
etcd / zookeeper ). - Prozesskomponenten, die neu konfiguriert / neu gestartet werden können, ohne den Prozess neu zu starten.
- Speicherung der Konfiguration außerhalb der Artefakt- und Versionskontrolle.
Textdateien bieten erhebliche Flexibilität in Bezug auf kleine Änderungen. Der Systemadministrator kann zum Remote-Knoten wechseln, Änderungen an den entsprechenden Dateien vornehmen und den Dienst neu starten. Für große Systeme kann eine solche Flexibilität jedoch unerwünscht sein. Von den vorgenommenen Änderungen gibt es keine Spuren in anderen Systemen. Niemand überprüft Änderungen. Es ist schwierig festzustellen, wer die Änderungen aus welchem Grund vorgenommen hat. Änderungen werden nicht getestet. Wenn das System verteilt ist, vergisst der Administrator möglicherweise, die entsprechenden Änderungen auf anderen Knoten vorzunehmen.
(Es sollte auch beachtet werden, dass die Verwendung einer kompilierten Konfiguration die Möglichkeit der zukünftigen Verwendung von Textdateien nicht blockiert. Es reicht aus, einen Parser und einen Validator hinzuzufügen, die den gleichen Config als Ausgabe verwenden, und Sie können Textdateien verwenden. Daraus folgt unmittelbar, dass die Komplexität des Systems mit der kompilierten Konfiguration etwas ist weniger als die Komplexität eines Systems, das Textdateien verwendet, da Textdateien zusätzlichen Code erfordern.)
Der zentralisierte Schlüsselwertspeicher ist ein guter Mechanismus zum Verteilen von Metaparametern einer verteilten Anwendung. Wir sollten entscheiden, was Konfigurationsparameter sind und was nur Daten sind. Angenommen, wir haben eine Funktion C => A => B , wobei sich die Parameter C selten ändern und die Daten A häufig. In diesem Fall können wir sagen, dass C die Konfigurationsparameter und A die Daten sind. Es scheint, dass sich die Konfigurationsparameter von den Daten dadurch unterscheiden, dass sie sich im Allgemeinen weniger häufig ändern als die Daten. Außerdem stammen Daten normalerweise von einer Quelle (vom Benutzer) und Konfigurationsparameter von einer anderen Quelle (vom Systemadministrator).
Wenn selten geänderte Parameter aktualisiert werden müssen, ohne das Programm neu zu starten, kann dies häufig zu einer Komplikation des Programms führen, da wir die Parameter irgendwie liefern, speichern, analysieren und überprüfen sowie falsche Werte verarbeiten müssen. Unter dem Gesichtspunkt der Verringerung der Komplexität des Programms ist es daher sinnvoll, die Anzahl der Parameter zu verringern, die sich während des Programms ändern können (oder solche Parameter überhaupt nicht zu unterstützen).
Aus der Sicht dieses Beitrags werden wir zwischen statischen und dynamischen Parametern unterscheiden. Wenn die Logik des Dienstes das Ändern von Parametern während des Programms erfordert, werden wir diese Parameter als dynamisch bezeichnen. Andernfalls sind die Parameter statisch und können mithilfe einer kompilierten Konfiguration konfiguriert werden. Für die dynamische Neukonfiguration benötigen wir möglicherweise einen Mechanismus, um Teile des Programms mit neuen Parametern neu zu starten, ähnlich wie die Prozesse des Betriebssystems neu gestartet werden. (Unserer Meinung nach ist es ratsam, eine Neukonfiguration in Echtzeit zu vermeiden, da die Systemkomplexität zunimmt. Wenn möglich, ist es besser, die Standardfunktionen des Betriebssystems zum Neustarten von Prozessen zu verwenden.)
Ein wichtiger Aspekt bei der Verwendung einer statischen Konfiguration, die Benutzer dazu zwingt, eine dynamische Neukonfiguration in Betracht zu ziehen, ist die Zeit, die das System nach einem Konfigurationsupdate (Ausfallzeit) benötigt, um neu zu starten. Wenn wir Änderungen an der statischen Konfiguration vornehmen müssen, müssen wir das System neu starten, damit die neuen Werte wirksam werden. Das Ausfallzeitproblem hat für verschiedene Systeme einen unterschiedlichen Schweregrad. In einigen Fällen können Sie einen Neustart zu einem Zeitpunkt planen, an dem die Last minimal ist. Wenn Sie einen kontinuierlichen Service bieten möchten, können Sie die "Entwässerungsanschlüsse" (AWS ELB-Verbindungsentleerung) implementieren. Wenn wir das System neu starten müssen, starten wir gleichzeitig eine parallele Instanz dieses Systems, schalten den Balancer darauf um und warten, bis die alten Verbindungen hergestellt sind. Nachdem alle alten Verbindungen hergestellt wurden, deaktivieren wir die alte Systeminstanz.
Betrachten wir nun das Problem des Speicherns der Konfiguration innerhalb oder außerhalb des Artefakts. Wenn wir die Konfiguration im Artefakt speichern, hatten wir zumindest während der Montage des Artefakts die Möglichkeit, sicherzustellen, dass die Konfiguration korrekt war. Wenn sich die Konfiguration außerhalb des kontrollierten Artefakts befindet, ist es schwierig zu verfolgen, wer und warum Änderungen an dieser Datei vorgenommen haben. Wie wichtig ist das? Unserer Meinung nach ist es für viele Produktionssysteme wichtig, eine stabile und qualitativ hochwertige Konfiguration zu haben.
Mit der Version des Artefakts können Sie bestimmen, wann es erstellt wurde, welche Werte es enthält, welche Funktionen aktiviert / deaktiviert sind und wer für Änderungen in der Konfiguration verantwortlich ist. Das Speichern der Konfiguration innerhalb des Artefakts erfordert natürlich einige Anstrengungen, sodass Sie eine fundierte Entscheidung treffen müssen.
Dafür und dagegen
Ich möchte auf die Vor- und Nachteile der vorgeschlagenen Technologie eingehen.
Die Vorteile
Im Folgenden finden Sie eine Liste der Hauptfunktionen einer kompilierten verteilten Systemkonfiguration:
- Statische Konfigurationsprüfung. Ermöglicht es Ihnen, sicher zu sein
Die Konfiguration ist korrekt. - . . Scala , . ,
trait' , , val', (DRY) . ( Seq , Map , ). - DSL. Scala , DSL. , , , . , , .
- . , , , , . , . , .
- . , , .
- . , .
- . , . . ( , , , , -.) — . , , , , .
- . , . , , . . . , production'.
- . , . , , — . production- .
- Testen. mock-, , .
- . . , , , .
. :
- . production', . . . .
- . , , .
- . , , . / .
- . DevOps . .
- . (CI/CD). .
, :
- , , . , Cake Pattern' , ,
HList (case class') . - , : (
package , import , ; override def ' , ). , DSL. , (, XML), . - .
Fazit
Scala. xml- . , Scala, ( Kotlin, C#, Swift, ...). , , , , , .
, . .
:
- .
- DSL .
- . , , (1) ; (2) .
, .