Angesichts der jüngsten Fortschritte bei neuronalen Netzen im Allgemeinen und der Bilderkennung im Besonderen scheint es, dass die Erstellung einer NN-basierten Anwendung zur Bilderkennung eine einfache Routineoperation ist. Nun, bis zu einem gewissen Grad ist es wahr: Wenn Sie sich eine Anwendung der Bilderkennung vorstellen können, dann hat höchstwahrscheinlich schon jemand etwas Ähnliches getan. Alles, was Sie tun müssen, ist es zu googeln und zu wiederholen.
Es gibt jedoch noch unzählige kleine Details, die ... nicht unlösbar sind, nein. Sie nehmen einfach zu viel Zeit in Anspruch, besonders wenn Sie ein Anfänger sind. Was helfen würde, ist ein Schritt-für-Schritt-Projekt, das direkt vor Ihnen durchgeführt wird und von Anfang bis Ende durchgeführt wird. Ein Projekt, das keine Anweisungen "Dieser Teil ist offensichtlich, also überspringen wir es" enthält. Na ja, fast :)
In diesem Tutorial werden wir einen Hunderassen-Identifikator durchgehen: Wir werden ein neuronales Netzwerk erstellen und unterrichten, es dann auf Java für Android portieren und auf Google Play veröffentlichen.
Für diejenigen unter Ihnen, die ein Endergebnis sehen möchten, ist hier der Link zur
NeuroDog-App bei Google Play.
Website mit meiner Robotik:
robotics.snowcron.com .
Website mit:
NeuroDog User Guide .
Hier ist ein Screenshot des Programms:
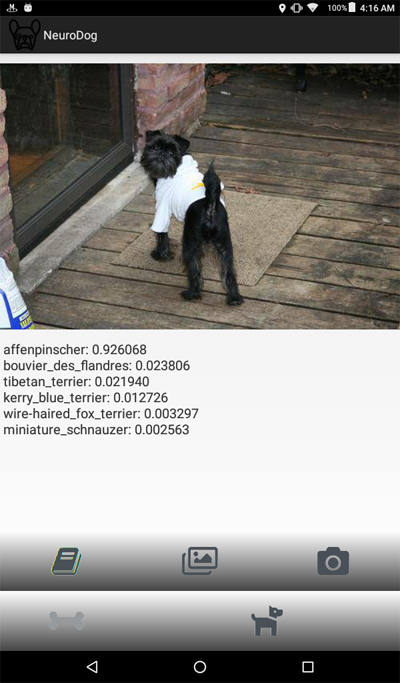
Ein Überblick
Wir werden Keras: Googles Bibliothek für die Arbeit mit neuronalen Netzen verwenden. Es ist auf hohem Niveau, was bedeutet, dass die Lernkurve steil sein wird, definitiv schneller als bei anderen mir bekannten Bibliotheken. Machen Sie sich damit vertraut: Es sind viele hochwertige Tutorials online.
Wir werden CNNs - Convolutional Neural Networks verwenden. CNNs (und auf ihnen basierende fortgeschrittenere Netzwerke) sind de facto Standard bei der Bilderkennung. Das richtige Unterrichten kann jedoch zu einer gewaltigen Aufgabe werden: Die Struktur des Netzwerks, die Lernparameter (all diese Lernraten, Impulse, L1 und L2 usw.) sollten sorgfältig angepasst werden, und da die Aufgabe viele Rechenressourcen erfordert, müssen wir kann nicht einfach alle möglichen Kombinationen ausprobieren.
Dies ist einer der wenigen Gründe, warum wir in den meisten Fällen die Verwendung des "Transferwissens" gegenüber dem sogenannten "Vanille" -Ansatz bevorzugen. Transfer Knowlege verwendet ein neuronales Netzwerk, das von einer anderen Person (z. B. Google) für eine andere Aufgabe trainiert wurde. Dann entfernen wir die letzten Schichten davon, fügen eigene Schichten hinzu ... und es wirkt Wunder.
Es mag seltsam klingen: Wir haben das Google-Netzwerk genutzt, um Katzen, Blumen und Möbel zu erkennen, und jetzt identifiziert es Hunderassen! Um zu verstehen, wie es funktioniert, werfen wir einen Blick auf die Funktionsweise von Deep Neural Networks, einschließlich solcher, die zur Bilderkennung verwendet werden.
Wir geben ihm ein Bild als Eingabe. Die erste Schicht eines Netzwerks analysiert das Bild auf einfache Muster wie "kurze horizontale Linie", "Bogen" usw. Die nächste Ebene nimmt diese Muster (und wo sie sich auf dem Bild befinden) und erzeugt Muster höherer Ebene, wie "Fell", "Augenwinkel" usw. Am Ende haben wir ein Puzzle, das zu einer Beschreibung eines Hundes kombiniert werden kann: Fell, zwei Augen, menschliches Bein im Mund und so weiter.
Dies alles wurde von einer Reihe vorgefertigter Ebenen erledigt (von Google oder einem anderen großen Player). Schließlich fügen wir unsere eigenen Schichten hinzu und bringen ihm bei, mit diesen Mustern zu arbeiten, um Hunderassen zu erkennen. Klingt logisch.
Zusammenfassend werden wir in diesem Tutorial "Vanilla" CNN und einige "Transfer Learning" -Netzwerke verschiedener Typen erstellen. Was "Vanille" betrifft: Ich werde es nur als Beispiel dafür verwenden, wie es gemacht werden kann, aber ich werde es nicht verfeinern, da "vorab trainierte" Netzwerke viel einfacher zu benutzen sind. Keras wird mit wenigen vorgefertigten Netzwerken geliefert. Ich werde einige Konfigurationen auswählen und vergleichen.
Damit unser neuronales Netzwerk Hunderassen erkennen kann, müssen wir ihm Beispielbilder verschiedener Rassen "zeigen". Glücklicherweise wurde für eine ähnliche Aufgabe ein
großer Datensatz erstellt (
Original hier ). In diesem Artikel werde ich die
Version von Kaggle verwendenDann werde ich den "Gewinner" auf Android portieren. Das Portieren von Keras NN auf Android ist relativ einfach, und wir werden alle erforderlichen Schritte ausführen.
Dann werden wir es auf Google Play veröffentlichen. Wie zu erwarten ist, wird Google nicht kooperieren, sodass nur wenige zusätzliche Tricks erforderlich sind. Zum Beispiel überschreitet unser neuronales Netzwerk die zulässige Größe von Android APK: Wir müssen das Bundle verwenden. Außerdem wird Google unsere App nicht in den Suchergebnissen anzeigen, es sei denn, wir tun bestimmte magische Dinge.
Am Ende werden wir eine voll funktionsfähige "kommerzielle" (in Anführungszeichen, da sie kostenlos, aber marktreif ist) Android NN-fähige Anwendung haben.
Entwicklungsumgebung
Je nach verwendetem Betriebssystem (Ubuntu wird empfohlen), Grafikkarte (oder nicht) usw. gibt es nur wenige unterschiedliche Ansätze für die Keras-Programmierung. Es ist nichts Falsches daran, die Entwicklungsumgebung auf Ihrem lokalen Computer zu konfigurieren und alle erforderlichen Bibliotheken usw. zu installieren. Außer ... es gibt einen einfacheren Weg.
Erstens dauert die Installation und Konfiguration mehrerer Entwicklungstools einige Zeit, und Sie müssen erneut Zeit aufwenden, wenn neue Versionen verfügbar werden. Zweitens erfordert das Training neuronaler Netze viel Rechenleistung. Sie können Ihren Computer mithilfe der GPU beschleunigen. Zum Zeitpunkt dieses Schreibens kostet eine Top-GPU für NN-bezogene Berechnungen 2000 bis 7000 US-Dollar. Und die Konfiguration braucht auch Zeit.
Wir werden also einen anderen Ansatz verwenden. Google ermöglicht es Nutzern, seine GPUs kostenlos für NN-bezogene Berechnungen zu verwenden. Außerdem wurde eine vollständig konfigurierte Umgebung erstellt. Alles in allem heißt es Google Colab. Der Dienst gewährt Ihnen Zugriff auf ein Jupiter-Notizbuch, in dem Python, Keras und unzählige zusätzliche Bibliotheken bereits installiert sind. Sie müssen lediglich ein Google-Konto einrichten (ein Google Mail-Konto einrichten und auf alles andere zugreifen).
Zum Zeitpunkt dieses Schreibens kann auf Colab
über diesen Link zugegriffen
werden , es kann sich jedoch ändern. Google einfach "Google Colab".
Ein offensichtliches Problem bei Colab ist, dass es sich um einen WEB-Dienst handelt. Wie werden Sie von dort aus auf IHRE Dateien zugreifen? Speichern neuronaler Netze nach Abschluss des Trainings, Laden von Daten, die für Ihre Aufgabe spezifisch sind, und so weiter?
Es gibt nur wenige (im Moment dieses Schreibens - drei) verschiedene Ansätze; Wir werden das verwenden, was ich für das Beste halte: Google Drive.
Google Drive ist ein Cloud-Speicher, der fast wie eine Festplatte funktioniert und Google Colab zugeordnet werden kann (siehe Code unten). Dann arbeiten Sie damit wie mit einer lokalen Festplatte. Wenn Sie beispielsweise auf Fotos von Hunden aus dem in Colab erstellten neuronalen Netzwerk zugreifen möchten, müssen Sie diese Fotos auf Ihr Google Drive hochladen. Das ist alles.
Erstellen und Trainieren des NN
Im Folgenden werde ich den Python-Code durchgehen, einen Codeblock aus Jupiter Notebook nach dem anderen. Sie können diesen Code in Ihr Notizbuch kopieren und ausführen, da Blöcke unabhängig voneinander ausgeführt werden können.
Initialisierung
Lassen Sie uns zunächst das Google Drive einbinden. Nur zwei Codezeilen. Dieser Code muss nur einmal pro Colab-Sitzung ausgeführt werden (z. B. einmal pro sechs Arbeitsstunden). Wenn Sie es das zweite Mal ausführen, wird es übersprungen, da das Laufwerk bereits bereitgestellt ist.
from google.colab import drive drive.mount('/content/drive/')
Beim ersten Mal werden Sie aufgefordert, die Montage zu bestätigen - hier ist nichts kompliziert. Es sieht so aus:
>>> Go to this URL in a browser: ... >>> Enter your authorization code: >>> ·········· >>> Mounted at /content/drive/
Ein hübscher Standard-
Include- Abschnitt; höchstwahrscheinlich sind einige der Includes nicht erforderlich. Wenn ich verschiedene NN-Konfigurationen testen möchte, müssen Sie einige davon für einen bestimmten NN-Typ kommentieren / auskommentieren: Zum Beispiel InceptionV3 Typ NN, InceptionV3 auskommentieren und beispielsweise ResNet50 kommentieren. Oder auch nicht: Sie können diese Includes unkommentiert lassen, es wird mehr Speicher benötigt, aber das ist alles.
import datetime as dt import pandas as pd import seaborn as sns import matplotlib.pyplot as plt from tqdm import tqdm import cv2 import numpy as np import os import sys import random import warnings from sklearn.model_selection import train_test_split import keras from keras import backend as K from keras import regularizers from keras.models import Sequential from keras.models import Model from keras.layers import Dense, Dropout, Activation from keras.layers import Flatten, Conv2D from keras.layers import MaxPooling2D from keras.layers import BatchNormalization, Input from keras.layers import Dropout, GlobalAveragePooling2D from keras.callbacks import Callback, EarlyStopping from keras.callbacks import ReduceLROnPlateau from keras.callbacks import ModelCheckpoint import shutil from keras.applications.vgg16 import preprocess_input from keras.preprocessing import image from keras.preprocessing.image import ImageDataGenerator from keras.models import load_model from keras.applications.resnet50 import ResNet50 from keras.applications.resnet50 import preprocess_input from keras.applications.resnet50 import decode_predictions from keras.applications import inception_v3 from keras.applications.inception_v3 import InceptionV3 from keras.applications.inception_v3 import preprocess_input as inception_v3_preprocessor from keras.applications.mobilenetv2 import MobileNetV2 from keras.applications.nasnet import NASNetMobile
Auf Google Drive erstellen wir einen Ordner für unsere Dateien. Die zweite Zeile zeigt den Inhalt an:
working_path = "/content/drive/My Drive/DeepDogBreed/data/" !ls "/content/drive/My Drive/DeepDogBreed/data" >>> all_images labels.csv models test train valid
Wie Sie sehen können, werden Fotos von Hunden (solche, die aus dem Stanford-Datensatz (siehe oben) in Google Drive kopiert wurden, zunächst im Ordner
all_images gespeichert. Später werden sie in Ordner zum
Trainieren, Validieren und
Testen kopiert. Wir werden speichern trainierte Modelle im Modellordner. Die Datei labels.csv ist Teil eines Datensatzes und ordnet Bilddateien Hunderassen zu.
Es gibt viele Tests, die Sie ausführen können, um herauszufinden, was Sie haben. Lassen Sie uns nur einen ausführen:
Ok, GPU ist angeschlossen. Wenn nicht, suchen Sie es in den Jupiter Notebook-Einstellungen und schalten Sie es ein.
Jetzt müssen wir einige Konstanten deklarieren, die wir verwenden werden, wie die Größe eines Bildes, das das Neuronale Netz erwarten sollte, und so weiter. Beachten Sie, dass wir ein 256x256-Bild verwenden, da dieses auf der einen Seite groß genug ist und auf der anderen Seite in den Speicher passt. Einige Arten von neuronalen Netzen, die wir verwenden werden, erwarten jedoch ein 224x224-Bild. Kommentieren Sie dazu bei Bedarf die alte Bildgröße und kommentieren Sie eine neue aus.
Der gleiche Ansatz (Kommentar eins - Kommentar aus dem anderen) gilt für Namen von Modellen, die wir speichern, einfach weil wir das Ergebnis eines vorherigen Tests nicht überschreiben möchten, wenn wir eine neue Konfiguration versuchen.
warnings.filterwarnings("ignore") os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' np.random.seed(7) start = dt.datetime.now() BATCH_SIZE = 16 EPOCHS = 15 TESTING_SPLIT=0.3
Daten laden
Laden
wir zunächst die Datei
label.csv und teilen ihren Inhalt in Schulungs- und Validierungsteile auf. Beachten Sie, dass es noch keinen Testteil gibt, da ich ein bisschen schummeln werde, um mehr Daten für das Training zu erhalten.
labels = pd.read_csv(working_path + 'labels.csv') print(labels.head()) train_ids, valid_ids = train_test_split(labels, test_size = TESTING_SPLIT) print(len(train_ids), 'train ids', len(valid_ids), 'validation ids') print('Total', len(labels), 'testing images') >>> id breed >>> 0 000bec180eb18c7604dcecc8fe0dba07 boston_bull >>> 1 001513dfcb2ffafc82cccf4d8bbaba97 dingo >>> 2 001cdf01b096e06d78e9e5112d419397 pekinese >>> 3 00214f311d5d2247d5dfe4fe24b2303d bluetick >>> 4 0021f9ceb3235effd7fcde7f7538ed62 golden_retriever >>> 7155 train ids 3067 validation ids >>> Total 10222 testing images
Als nächstes müssen wir die tatsächlichen Bilddateien in die Ordner für Training / Validierung / Testen kopieren, je nachdem, welche Dateinamen wir übergeben. Die folgende Funktion kopiert Dateien mit Namen in einen angegebenen Ordner.
def copyFileSet(strDirFrom, strDirTo, arrFileNames): arrBreeds = np.asarray(arrFileNames['breed']) arrFileNames = np.asarray(arrFileNames['id']) if not os.path.exists(strDirTo): os.makedirs(strDirTo) for i in tqdm(range(len(arrFileNames))): strFileNameFrom = strDirFrom + arrFileNames[i] + ".jpg" strFileNameTo = strDirTo + arrBreeds[i] + "/" + arrFileNames[i] + ".jpg" if not os.path.exists(strDirTo + arrBreeds[i] + "/"): os.makedirs(strDirTo + arrBreeds[i] + "/")
Wie Sie sehen, kopieren wir nur eine Datei für jede Hunderasse in einen Testordner. Beim Kopieren von Dateien erstellen wir auch Unterordner - einen Unterordner pro Hunderasse. Bilder für jede bestimmte Rasse werden in ihren Unterordner kopiert.
Der Grund dafür ist, dass Keras mit einer so organisierten Verzeichnisstruktur arbeiten kann, Bilddateien nach Bedarf lädt und Speicherplatz spart. Es wäre eine sehr schlechte Idee, alle 15.000 Bilder gleichzeitig in den Speicher zu laden.
Das Aufrufen dieser Funktion jedes Mal, wenn wir unseren Code ausführen, wäre ein Overkill: Bilder werden bereits kopiert. Warum sollten wir sie erneut kopieren? Kommentieren Sie es also bei der ersten Verwendung aus:
Zusätzlich benötigen wir eine Liste von Hunderassen:
breeds = np.unique(labels['breed']) map_characters = {}
Bilder verarbeiten
Wir werden die Keras-Funktion ImageDataGenerators verwenden. ImageDataGenerator kann ein Bild verarbeiten, seine Größe ändern, es drehen usw. Es kann auch eine
Verarbeitungsfunktion übernehmen , die benutzerdefinierte Bildmanipulationen ausführt.
def preprocess(img): img = cv2.resize(img, (IMAGE_SIZE, IMAGE_SIZE), interpolation = cv2.INTER_AREA)
Beachten Sie die folgende Zeile:
Wir können die Normalisierung (Anpassen des 0-255-Bereichs des Bildkanals an 0-1) in ImageDataGenerator selbst durchführen. Warum brauchen wir also einen Präprozessor? Als Beispiel habe ich die (auskommentierte)
Unschärfefunktion bereitgestellt: Dies ist eine benutzerdefinierte Bildmanipulation. Hier können Sie alles von Schärfen bis HDR verwenden.
Wir werden zwei verschiedene ImageDataGenerators verwenden, einen für das Training und einen für die Validierung. Der Unterschied besteht darin, dass wir für das Training Rotationen und Zoomen benötigen, um Bilder "vielfältiger" zu machen, aber wir brauchen sie nicht für die Validierung (nicht in dieser Aufgabe).
train_datagen = ImageDataGenerator( preprocessing_function=preprocess,
Neuronales Netzwerk erstellen
Wie oben erwähnt, werden wir einige Arten von neuronalen Netzen erstellen. Jedes Mal, wenn wir eine andere Funktion verwenden, unterscheiden sich die Include-Bibliotheken und in einigen Fällen die Bildgrößen. Um von einem neuronalen Netzwerktyp zum anderen zu wechseln, müssen Sie den entsprechenden Code kommentieren / auskommentieren.
Lassen Sie uns zuerst "Vanille" CNN erstellen. Es funktioniert schlecht, da ich es nicht optimiert habe, aber es bietet zumindest ein Framework, mit dem Sie ein eigenes Netzwerk erstellen können (im Allgemeinen ist es eine schlechte Idee, da vorab trainierte Netzwerke verfügbar sind).
def createModelVanilla(): model = Sequential()
Wenn wir mithilfe von
Transferlernen ein neuronales Netzwerk erstellen, ändert sich das Verfahren:
def createModelMobileNetV2():
Das Erstellen anderer Arten von vorab trainierten NNs ist sehr ähnlich:
def createModelResNet50(): base_model = ResNet50(weights='imagenet', include_top=False, pooling='avg', input_shape=(IMAGE_SIZE, IMAGE_SIZE, 3)) x = base_model.output x = Dense(512)(x) x = Activation('relu')(x) x = Dropout(0.5)(x) predictions = Dense(NUM_CLASSES, activation='softmax')(x) model = Model(inputs=base_model.input, outputs=predictions)
Attn: der Gewinner! Dieser NN zeigte die besten Ergebnisse:
def createModelInceptionV3():
Noch eins:
def createModelNASNetMobile():
Verschiedene Arten von NNs werden in verschiedenen Situationen verwendet. Zusätzlich zu Präzisionsproblemen, Größenangelegenheiten (mobiles NN ist fünfmal kleiner als Inception 1) und Geschwindigkeit (wenn wir eine Echtzeitanalyse eines Videostreams benötigen, müssen wir möglicherweise die Präzision opfern).
Training des neuronalen Netzwerks
Zunächst
experimentieren wir, daher müssen wir in der Lage sein, zuvor gespeicherte NNs zu löschen, die wir jedoch nicht mehr benötigen. Die folgende Funktion löscht NN, wenn die Datei vorhanden ist:
Die Art und Weise, wie wir NNs erstellen und löschen, ist unkompliziert. Zuerst löschen wir. Wenn Sie jetzt nicht mit dem Zauberstab
löschen möchten , denken Sie daran, dass das Jupiter-Notizbuch über eine Funktion zum Ausführen der Auswahl verfügt. Wählen Sie nur das aus, was Sie benötigen, und führen Sie es aus.
Dann erstellen wir die NN, wenn ihre Datei nicht vorhanden ist, oder
laden sie, wenn die Datei vorhanden ist: Natürlich können wir nicht "delete" aufrufen und dann erwarten, dass die NN vorhanden ist. Um das zuvor gespeicherte Netzwerk zu verwenden, rufen Sie nicht
delete auf .
Mit anderen Worten, wir können eine neue NN erstellen oder eine vorhandene verwenden, je nachdem, was wir gerade experimentieren. Ein einfaches Szenario: Wir haben den NN trainiert und sind dann in den Urlaub gefahren. Google hat uns abgemeldet, daher müssen wir den NN neu laden: Kommentieren Sie den Teil "Löschen" aus und kommentieren Sie den Teil "Laden" aus.
deleteSavedNet(working_path + strModelFileName)
Checkpoints sind beim Unterrichten der NNs sehr wichtig. Sie können eine Reihe von Funktionen erstellen, die am Ende jeder Trainingsepoche aufgerufen werden sollen. Sie können beispielsweise die NN speichern, wenn bessere Ergebnisse als die zuletzt gespeicherte angezeigt werden.
checkpoint = ModelCheckpoint(working_path + strModelFileName, monitor='val_acc', verbose=1, save_best_only=True, mode='auto', save_weights_only=False) callbacks_list = [ checkpoint ]
Schließlich werden wir unsere NN anhand des Trainingssatzes unterrichten:
Hier sind Genauigkeits- und Verlustdiagramme für den Gewinner NN:
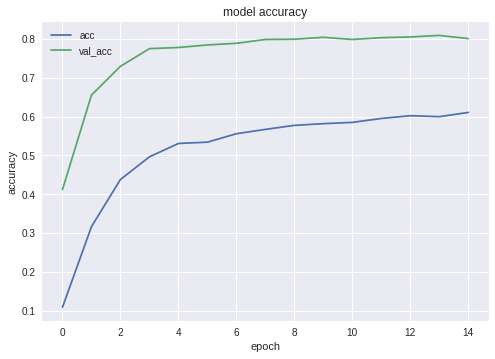

Wie Sie sehen können, lernt das Netzwerk gut.
Testen des neuronalen Netzes
Nach Abschluss der Schulungsphase müssen wir Tests durchführen. Dazu werden NN Bilder präsentiert, die sie nie gesehen haben. Wenn Sie sich erinnern, haben wir für jede Hundeart ein Bild beiseite gelegt.
NN nach Java exportieren
Zuerst müssen wir den NN laden. Der Grund dafür ist, dass der Export ein separater Codeblock ist, sodass wir ihn wahrscheinlich separat ausführen, ohne den NN neu zu trainieren. Wenn Sie meinen Code verwenden, ist es Ihnen eigentlich egal, aber wenn Sie Ihre eigene Entwicklung durchführen, würden Sie versuchen, zu vermeiden, dass
dasselbe Netzwerk einmal nach dem anderen umgeschult wird.
Aus dem gleichen Grund - dies ist irgendwie ein separater Codeblock - verwenden wir hier zusätzliche Includes. Nichts hindert uns natürlich daran, sie nach oben zu bringen:
from keras.models import Model from keras.models import load_model from keras.layers import * import os import sys import tensorflow as tf
Ein kleiner Test, nur um sicherzugehen, dass wir alles richtig geladen haben:
img = image.load_img(working_path + "test/affenpinscher.jpg")

Als nächstes müssen wir die Namen der Eingabe- und Ausgabeschichten unseres Netzwerks abrufen (es sei denn, wir haben beim Erstellen des Netzwerks den Parameter "name" verwendet, was wir nicht getan haben).
model.summary() >>> Layer (type) >>> ====================== >>> input_7 (InputLayer) >>> ______________________ >>> conv2d_283 (Conv2D) >>> ______________________ >>> ... >>> dense_14 (Dense) >>> ====================== >>> Total params: 22,913,432 >>> Trainable params: 1,110,648 >>> Non-trainable params: 21,802,784
Wir werden später beim Importieren des NN in eine Android Java-Anwendung die Namen der Eingabe- und Ausgabeebene verwenden.
Wir können auch den folgenden Code verwenden, um diese Informationen zu erhalten:
def print_graph_nodes(filename): g = tf.GraphDef() g.ParseFromString(open(filename, 'rb').read()) print() print(filename) print("=======================INPUT===================") print([n for n in g.node if n.name.find('input') != -1]) print("=======================OUTPUT==================") print([n for n in g.node if n.name.find('output') != -1]) print("===================KERAS_LEARNING==============") print([n for n in g.node if n.name.find('keras_learning_phase') != -1]) print("===============================================") print()
Der erste Ansatz ist jedoch bevorzugt.
Die folgende Funktion exportiert Keras Neural Network in das
pb- Format, das wir in Android verwenden werden.
def keras_to_tensorflow(keras_model, output_dir, model_name,out_prefix="output_", log_tensorboard=True): if os.path.exists(output_dir) == False: os.mkdir(output_dir) out_nodes = [] for i in range(len(keras_model.outputs)): out_nodes.append(out_prefix + str(i + 1)) tf.identity(keras_model.output[i], out_prefix + str(i + 1)) sess = K.get_session() from tensorflow.python.framework import graph_util from tensorflow.python.framework graph_io init_graph = sess.graph.as_graph_def() main_graph = graph_util.convert_variables_to_constants( sess, init_graph, out_nodes) graph_io.write_graph(main_graph, output_dir, name=model_name, as_text=False) if log_tensorboard: from tensorflow.python.tools import import_pb_to_tensorboard import_pb_to_tensorboard.import_to_tensorboard( os.path.join(output_dir, model_name), output_dir)
Verwenden Sie diese Funktionen, um eine Export-NN zu erstellen:
model = load_model(working_path + strModelFileName) keras_to_tensorflow(model, output_dir=working_path + strModelFileName, model_name=working_path + "models/dogs.pb") print_graph_nodes(working_path + "models/dogs.pb")
Die letzte Zeile gibt die Struktur unseres NN wieder.
Erstellen einer NN-fähigen Android-App
NN in Android App exportieren. ist gut formalisiert und sollte keine Schwierigkeiten bereiten. Es gibt wie üblich mehr als eine Möglichkeit, dies zu tun. Wir werden die beliebtesten verwenden (zumindest im Moment).
Verwenden Sie zunächst Android Studio, um ein neues Projekt zu erstellen. Wir werden ein wenig Abstriche machen, damit es nur eine einzige Aktivität gibt.

Wie Sie sehen können, haben wir den Ordner "Assets" hinzugefügt und dort unsere Neural Network-Datei kopiert.
Gradle-Datei
Es gibt einige Änderungen, die wir vornehmen müssen, um die Datei zu gradeln. Zunächst müssen wir die
Tensorflow-Android- Bibliothek importieren. Es wird verwendet, um Tensorflow (und Keras entsprechend) von Java aus zu verarbeiten:
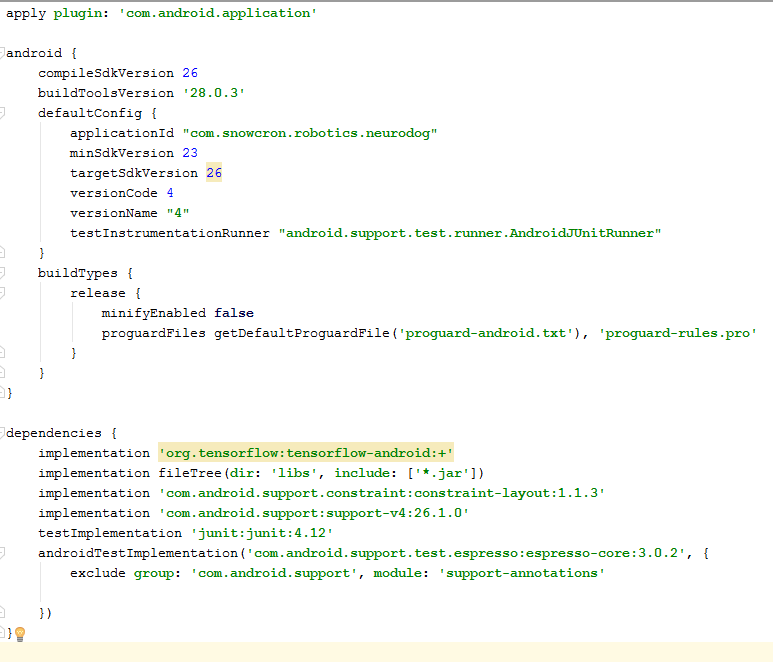
Beachten Sie als zusätzliches "schwer zu findendes" Detail die Versionen:
versionCode und
versionName . Während Sie an Ihrer App arbeiten, müssen Sie neue Versionen auf Google Play hochladen. Ohne die Aktualisierung der Versionen (etwa 1 -> 2 -> 3 ...) können Sie dies nicht tun.
Manifest
Zuallererst unsere App. wird "schwer" sein - ein 100-Mb-Neuronales Netzwerk passt problemlos in den Speicher moderner Telefone, aber jedes Mal, wenn der Benutzer ein Bild von Facebook "teilt", ist es definitiv keine gute Idee, eine separate Instanz davon zu öffnen.
Wir werden also sicherstellen, dass es nur eine Instanz unserer App gibt:
<activity android:name=".MainActivity" android:launchMode="singleTask">
Durch Hinzufügen von
android: launchMode = "singleTask" zu MainActivity weisen wir Android an, eine vorhandene App zu öffnen, anstatt eine andere Instanz zu starten.
Dann stellen wir sicher, dass unsere App. wird in einer Liste von Anwendungen angezeigt, die
gemeinsam genutzte Bilder verarbeiten können:
<intent-filter> <action android:name="android.intent.action.SEND" /> <category android:name="android.intent.category.DEFAULT" /> <data android:mimeType="image/*" /> </intent-filter>
Schließlich müssen wir Funktionen und Berechtigungen anfordern, damit die App auf die erforderlichen Systemfunktionen zugreifen kann:
<uses-feature android:name="android.hardware.camera" android:required="true" /> <uses-permission android:name= "android.permission.WRITE_EXTERNAL_STORAGE" /> <uses-permission android:name="android.permission.READ_PHONE_STATE" tools:node="remove" />
Wenn Sie mit der Android-Programmierung vertraut sind, sollte dieser Teil keine Fragen aufwerfen.
Layout der App.
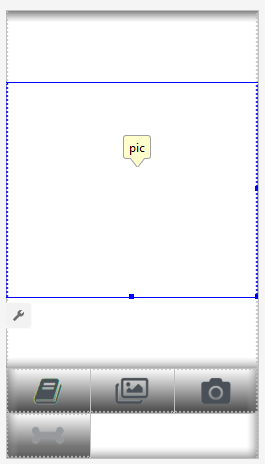
Wir werden zwei Layouts erstellen, eines für Hochformat und eines für Querformat. Hier ist das
Portrait-Layout .
Was wir hier haben: eine große Ansicht zum Anzeigen eines Bildes, eine ziemlich nervige Liste von Werbespots (angezeigt, wenn die Schaltfläche "Bone" gedrückt wird), Schaltflächen "Hilfe", Schaltflächen zum Laden eines Bildes aus Datei / Galerie und von Kamera und Zum Schluss eine (zunächst ausgeblendete) Schaltfläche "Verarbeiten".
In der Aktivität selbst werden wir eine Logik implementieren, die je nach Status der Anwendung Schaltflächen anzeigt / ausblendet und aktiviert / deaktiviert.
Hauptaktivität
Die Aktivität erweitert eine Standard-Android-Aktivität:
public class MainActivity extends Activity
Werfen wir einen Blick auf den Code, der für NN-Operationen verantwortlich ist.
Zunächst akzeptiert NN eine Bitmap. Ursprünglich ist es eine große Bitmap aus Datei oder Kamera (m_bitmap), dann transformieren wir sie in eine Standard-Bitmap 256x256 (m_bitmapForNn). Wir halten auch die Bildabmessungen (256) konstant:
static Bitmap m_bitmap = null; static Bitmap m_bitmapForNn = null; private int m_nImageSize = 256;
Wir müssen dem NN mitteilen, wie die Namen für die Eingabe- und Ausgabeebene lauten. Wenn Sie die obige Liste konsultieren, werden Sie feststellen, dass die Namen lauten (in unserem Fall! Ihr Fall kann anders sein!):
private String INPUT_NAME = "input_7_1"; private String OUTPUT_NAME = "output_1";
Dann deklarieren wir die Variable als TensofFlow-Objekt. Außerdem speichern wir den Pfad zur NN-Datei in den Assets:
private TensorFlowInferenceInterface tf;
private String MODEL_PATH =
"file: ///android_asset/dogs.pb";
Hunderassen, um dem Benutzer eine aussagekräftige Information anstelle von Indizes im Array zu präsentieren:
private String[] m_arrBreedsArray;
Zunächst laden wir eine Bitmap. NN selbst erwartet jedoch ein Array von RGB-Werten, und seine Ausgabe ist ein Array von Wahrscheinlichkeiten dafür, dass das dargestellte Bild eine bestimmte Rasse ist. Wir müssen also zwei weitere Arrays hinzufügen (beachten Sie, dass 120 die Anzahl der Rassen in unserem Trainingsdatensatz ist):
private float[] m_arrPrediction = new float[120]; private float[] m_arrInput = null;
Laden Sie die Tensorflow-Inferenzbibliothek
static { System.loadLibrary("tensorflow_inference"); }
Da der Betrieb von NN langwierig ist, müssen wir ihn in einem separaten Thread ausführen. Andernfalls besteht eine gute Chance, dass die System-App aufgerufen wird. nicht reagieren “Warnung, ganz zu schweigen von der Zerstörung der Benutzererfahrung.
class PredictionTask extends AsyncTask<Void, Void, Void> { @Override protected void onPreExecute() { super.onPreExecute(); }
In onCreate () der MainActivity müssen wir den onClickListener für die Schaltfläche "Process" hinzufügen: m_btn_process.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { processImage(); } });
Das processImage () ruft einfach den Thread auf, den wir oben gesehen haben: private void processImage() { try { enableControls(false);
Zusätzliche Details
Wir werden in diesem Tutorial nicht auf UI-bezogenen Code eingehen, da dieser trivial ist und definitiv nicht Teil der Aufgabe "NN portieren" ist. Es gibt jedoch einige Dinge, die geklärt werden sollten.Als wir unsere App vorstellten. Durch das Starten mehrerer Instanzen haben wir gleichzeitig einen normalen Kontrollfluss verhindert: Wenn Sie ein Bild von Facebook freigeben und dann ein anderes freigeben, wird die Anwendung nicht neu gestartet. Dies bedeutet, dass die "traditionelle" Art des Umgangs mit gemeinsam genutzten Daten durch Abfangen in onCreate in unserem Fall nicht ausreicht, da onCreate in einem gerade erstellten Szenario nicht aufgerufen wird.So können Sie mit der Situation umgehen:1. Rufen Sie in onCreate of MainActivity die Funktion onSharedIntent auf: protected void onCreate( Bundle savedInstanceState) { super.onCreate(savedInstanceState); .... onSharedIntent(); ....
Fügen Sie außerdem einen Handler für onNewIntent hinzu: @Override protected void onNewIntent(Intent intent) { super.onNewIntent(intent); setIntent(intent); onSharedIntent(); }
Die onSharedIntent-Funktion selbst: private void onSharedIntent() { Intent receivedIntent = getIntent(); String receivedAction = receivedIntent.getAction(); String receivedType = receivedIntent.getType(); if (receivedAction.equals(Intent.ACTION_SEND)) {
Jetzt verarbeiten wir entweder das freigegebene Image von onCreate (wenn die App gerade gestartet wurde) oder von onNewIntent, wenn eine Instanz im Speicher gefunden wurde.Viel Glück! Wenn Ihnen dieser Artikel gefällt, "mögen" Sie ihn bitte in sozialen Netzwerken. Außerdem gibt es auf einer Website selbst soziale Schaltflächen .